窗口函数
窗口函数的特点是可以分组,而且可以在分组内排序。另外,窗口函数不会因为分组而减少原表中的行数,这对我们在原表数据的基础上进行统计和排序非常有用。
使用窗口函数前后对比
前
sql
CREATE TEMPORARY TABLE a -- 创建临时表
SELECT SUM(sales_value) AS sales_value -- 计算总计金额
FROM sales;
CREATE TEMPORARY TABLE b -- 创建临时表
SELECT city,SUM(sales_value) AS sales_value -- 计算城市销售合计
FROM sales
GROUP BY city;
SELECT s.city AS 城市,s.county AS 区,s.sales_value AS 区销售额,
b.sales_value AS 市销售额,s.sales_value/b.sales_value AS 市比率,
a.sales_value AS 总销售额,s.sales_value/a.sales_value AS 总比率
FROM sales s
JOIN b ON (s.city=b.city) -- 连接市统计结果临时表
JOIN a -- 连接总计金额临时表
ORDER BY s.city,s.county;后
sql
SELECT city AS 城市,county AS 区,sales_value AS 区销售额,
SUM(sales_value) OVER(PARTITION BY city) AS 市销售额, -- 计算市销售额
sales_value/SUM(sales_value) OVER(PARTITION BY city) AS 市比率,
SUM(sales_value) OVER() AS 总销售额, -- 计算总销售额
sales_value/SUM(sales_value) OVER() AS 总比率
FROM sales
ORDER BY city,county;窗口函数分类
窗口函数的作用类似于在查询中对数据进行分组,不同的是,分组操作会把分组的结果聚合成一条记录最终结果是一条记录,而窗口函数是将结果置于每一条数据记录中最终结果是多条记录。
窗口函数可以分为 静态窗口函数 和 动态窗口函数 。
静态窗口函数的窗口大小是固定的,不会因为记录的不同而不同;
动态窗口函数的窗口大小会随着记录的不同而变化。
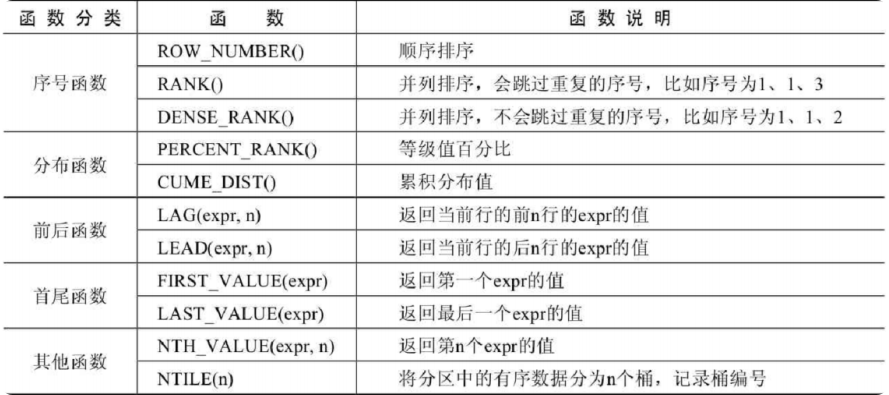
语法结构
sql
函数 OVER([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])
sql
函数 OVER 窗口名 ... WINDOW 窗口名 AS ([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])应用
序号函数
ROW_NUMBER()函数
sql
#查询 goods 数据表中每个商品分类下价格降序排列的各个商品信息。
SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id, category_id, category, NAME, price, stock
FROM goods;
sql
# 查询 goods 数据表中每个商品分类下价格最高的3种商品信息。
SELECT *
FROM (
SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id, category_id, category, NAME, price, stock
FROM goods) t
WHERE row_num <= 3;RANK()函数在排序过程中遇见值相同的情况下,定义序号相同,但存在跳跃
sql
# 使用RANK()函数获取 goods 数据表中各类别的价格从高到低排序的各商品信息
SELECT RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id, category_id, category, NAME, price, stock
FROM goods;DENSE_RANK()函数在排序过程中遇见值相同的情况下,定义序号相同,但不跳跃,编号连续
sql
#使用DENSE_RANK()函数获取 goods 数据表中各类别的价格从高到低排序的各商品信息。
SELECT DENSE_RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id, category_id, category, NAME, price, stock
FROM goods;分布函数
PERCENT_RANK()函数
sql
(rank - 1) / (rows - 1)
sql
#计算 goods 数据表中名称为"女装/女士精品"的类别下的商品的PERCENT_RANK值。
#写法一:
SELECT RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS r,
PERCENT_RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS pr,
id, category_id, category, NAME, price, stock
FROM goods
WHERE category_id = 1;
#写法二:
mysql> SELECT RANK() OVER w AS r,
PERCENT_RANK() OVER w AS pr,
id, category_id, category, NAME, price, stock
FROM goods
WHERE category_id = 1 WINDOW w AS (PARTITION BY category_id ORDER BY priceDESC);CUME_DIST()函数
sql
# 查询goods数据表中小于或等于当前价格的比例。
SELECT CUME_DIST() OVER(PARTITION BY category_id ORDER BY price ASC) AS cd,
id, category, NAME, price
FROM goods;前后函数
LAG(expr,n)函数
sql
# 查询goods数据表中前一个商品价格与当前商品价格的差值。
SELECT id, category, NAME, price, pre_price, price - pre_price AS diff_price
FROM (
SELECT id, category, NAME, price,LAG(price,1) OVER w AS pre_price
FROM goods
WINDOW w AS (PARTITION BY category_id ORDER BY price)) t;LEAD(expr,n)函数
sql
# 查询goods数据表中后一个商品价格与当前商品价格的差值。
SELECT id, category, NAME, behind_price, price,behind_price - price AS diff_price
FROM(
SELECT id, category, NAME, price,LEAD(price, 1) OVER w AS behind_price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price)) t;首尾函数
FIRST_VALUE(expr)函数
sql
# 按照价格排序,查询第1个商品的价格信息。
SELECT id, category, NAME, price, stock,FIRST_VALUE(price) OVER w AS first_price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);LAST_VALUE(expr)函数
sql
SELECT id, category, NAME, price, stock,LAST_VALUE(price) OVER w AS last_price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);其他函数
NTH_VALUE(expr,n)函数
sql
#查询goods数据表中排名第2和第3的价格信息。
SELECT id, category, NAME, price,NTH_VALUE(price,2) OVER w AS second_price,
NTH_VALUE(price,3) OVER w AS third_price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);NTILE(n)函数
sql
# 将goods表中的商品按照价格分为3组。
SELECT NTILE(3) OVER w AS nt,id, category, NAME, price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);公共表表达式
公用表表达式(或通用表表达式)简称为CTE(Common Table Expressions)。CTE是一个命名的临时结果集,作用范围是当前语句。CTE可以理解成一个可以复用的子查询,当然跟子查询还是有点区别的,CTE可以引用其他CTE,但子查询不能引用其他子查询。所以,可以考虑代替子查询。
普通公用表表达式格式
sql
WITH CTE名称
AS (子查询)
SELECT|DELETE|UPDATE 语句;应用
sql
SELECT * FROM departments
WHERE department_id IN (
SELECT DISTINCT department_id
FROM employees
);
sql
WITH emp_dept_id
AS (SELECT DISTINCT department_id FROM employees)
SELECT *
FROM departments d JOIN emp_dept_id e
ON d.department_id = e.department_id;递归公用表表达式格式可以调用自己
sql
WITH RECURSIVE
CTE名称 AS (子查询)
SELECT|DELETE|UPDATE 语句;应用
sql
WITH RECURSIVE cte
AS
(
SELECT employee_id,last_name,manager_id,1 AS n FROM employees WHERE employee_id = 100
-- 种子查询,找到第一代领导
UNION ALL
SELECT a.employee_id,a.last_name,a.manager_id,n+1 FROM employees AS a JOIN cte
ON (a.manager_id = cte.employee_id) -- 递归查询,找出以递归公用表表达式的人为领导的人
)
SELECT employee_id,last_name FROM cte WHERE n >= 3;递归公用表表达式对于查询一个有共同的根节点的树形结构数据,非常有用。它可以不受层级的限制,轻松查出所有节点的数据。