一、awk工具基础概述
awk是一门文本处理编程语言/数据处理引擎,由Aho、Weinberger、Kernighan三位开发者创造。
- 核心能力:基于模式匹配逐行检查输入文本,逐行处理并输出结果
- 典型用途:Shell脚本中提取指定数据、单独使用时做文本统计与分析
- 工作模式:一行一行处理文本,自动循环遍历所有行
二、awk命令格式与常用选项
1. 两种核心使用格式
- 管道符结合使用
shell
前置命令 | awk [选项] '[条件] {指令}'- 直接处理文件
shell
awk [选项] '[条件] {指令}' 文件- 多个指令用**分号;**隔开
- print 是最常用输出指令
- {}代表逐行任务
- (默认shell命令与awk是不互通的)
{ "" }中的双引号 圈定常量(代表普通字符串)并直接输出。例:

shell
[root@server ~]# vim test.txt #编写测试文件
hello the world
welcome to beijing
#以空格作为分隔符,输出test.txt文件的第1列,第3列,逗号表示空格
[root@server ~]# awk '{print $1,$3}' test.txt
hello world
welcome beijing逗号表示空格 ,如果不加逗号输出为:
helloworld
welcomebeijing
print$0代表所有,不写也代表所有。
默认print自带换行,如果命令是:awk '{print 1,print3}' test.txt,结果为:
hello
world
welcome
beijing
2. 常用选项:-F 指定分隔符
- 默认分隔符:空格、Tab键
- 自定义分隔符:
-F符号
-F可以不写,默认就是空格为分隔符
bash
[root@server ~]# head -1 /etc/passwd | awk '{print $1,$3}' #使用默认分隔符(空格或者tab),如果一行没有空格则直接把整行当作只有一列
root:x:0:0:root #当作一整列
[root@server ~]# head -1 /etc/passwd | awk -F: '{print $1,$3}' #使用-F指定:为分隔符
root 0 #把:当作分隔符3. 基础实用案例
shell
# 筛选登录失败的IP
[root@server ~]# awk '/Failed/{print $11}' /var/log/secure #过滤文件中包含Failed的行,输出相应行的第11列
192.168.8.1
...
# 查看内存剩余容量
[root@server ~]# free -h | awk '/Mem/{print $4}' #检查内存的剩余容量
# 查看网卡ens160入站流量
[root@server ~]# ifconfig ens160 | awk '/RX p/{print $5}' #过滤网卡入站流量
# 查看根分区剩余空间
[root@server ~]# df -h / | awk '{print $4}' #过滤根分区剩余空间容量三、awk内置变量(直接使用)
awk提供多个有特殊含义的内置变量,无需定义,可以在单引号之内直接调用:
- 验证NR、NF内置变量,$NF表示每行的最后一列
- $(NF-1)代表倒数第二列
- NR输出的是每行的行号
- 在逐行任务{}中使用""引起来的是常量,也就是普通字符串

(-FS与-F用法功能一致,所以更常用-F)
print 后面不写任何内容,默认就是代表 0,如'{print}'等同于'{print 0}'
使用拓展:
当需要指定第n行时,直接"$NR==n{}"即可
此外,可以根据元素直接精准指定特定的行,如:

内置变量使用示例
shell
[root@server ~]# awk -F: '{print NR,NF}' /etc/passwd #输出每行的行号和每行的总列数
[root@server ~]# awk -F: '{print $NF}' /etc/passwd #输出每行的最后一列
[root@server ~]# awk -F: '{print "用户: "$1,"解释器为: "$NF}' /etc/passwd #输出用户名和解释器
用户: root 解释器为: /bin/bash
用户: bin 解释器为: /sbin/nologin
...- 双引号
""包裹内容为普通字符串常量,直接原样输出
例题:
第 1 题(基础字段提取) 请用 awk 命令,以 冒号 : 为分隔符,读取 /etc/passwd 文件,只输出第 1
行,并按下面格式输出: 用户名: root, UID: 0
head -1 /etc/passwd | awk -F: '{print "用户名: "1", UID: "3}'
第 2 题(内置变量 NR / NF) 请用 awk 命令读取 /etc/passwd,输出每行的行号、总列数、最后一列内容,以空格分隔。
awk -F: '{print NR, NF, $NF}' /etc/passwd
第 3 题(模式匹配 + 统计) 请用 awk 命令统计 /etc/passwd 中以 /bin/bash
结尾的行一共有多少行,输出结果只显示数字。
解法一:awk '//bin/bash$/{print}' /etc/passwd | wc -l
解法二:awk 'BEGIN{x=0} //bin/bash$/{x++} END{print x}' /etc/passwd
四、awk的三个处理时机
awk执行分为三个阶段,可单独使用,也可组合使用:
1. BEGIN{}:逐行前处理
- 读入第一行文本之前执行
- 用途:初始化变量、打印表头、简单计算
2. {}:逐行处理
- 逐行读入文本并执行指令
- 最常用、默认执行块
逐行处理可以在一个awk命令中同时使用多个,例:

3. END{}:逐行后处理
- 处理完最后一行之后执行
- 用途:统计结果输出、汇总计算
注意:即使只使用了end,没有begin和逐行处理,依旧默认进行了逐行,只是逐行没有进行操作而已。所以如果单独使用END{print NR}依旧有输出
执行时机示例
shell
[root@server ~]# awk 'BEGIN{a=34;print a+12}' #计算34+12
46
#统计文件中bash结尾的行数量
[root@server ~]# awk 'BEGIN{x=0} /bash$/{x++} END{print x}' /etc/passwd #统计以bash结尾的行的数量
#预处理时,行数为0,全部处理完以后,行数为已读文本的行数
[root@server ~]# awk 'BEGIN{print NR} END{print NR}' /etc/passwd
0
38同一个命令在三个不同的时机实现的效果也不一样。接下来会使用NR的一个例子来演示他们的区别:
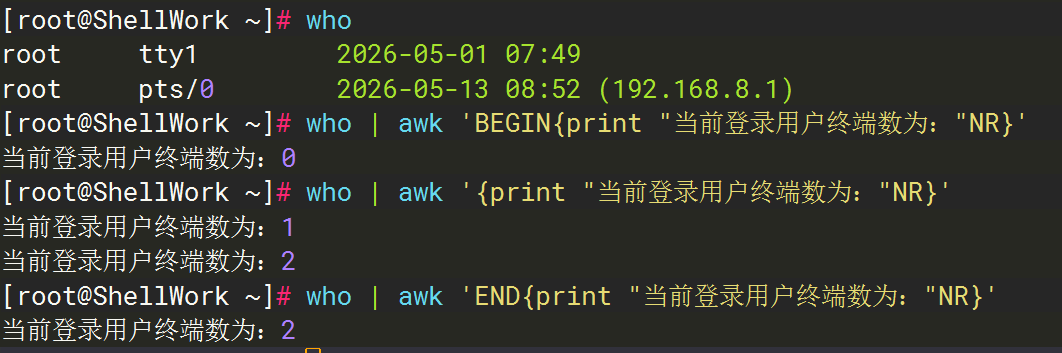
可以看得出来:
- BEGIN因为是"行前处理",行前自然是没有行,也没有行号的,所以输出为0
- 所以行前处理初始化变量、打印表头、简单计算
- {}逐行处理,就是逐行输出一次,因此输出为:
1
2 - END"逐行后处理",也就是逐行操作完之后再输出一次
- 因此END更适合用于统计结果输出、汇总计算
五、awk条件过滤(精准筛选行)
awk支持按条件处理指定行,条件分为4类:
- 正则表达式
- 数值/字符串比较
- 逻辑比较
- 运算符
1. 正则表达式条件
- 写法:
/正则表达式/ - 匹配/包含:
~;不匹配:!~
shell
[root@server ~]# awk '/^root/{print}' /etc/passwd #输出root开头的行
[root@server ~]# awk -F: '$7~/bash$/{print $1,$3}' /etc/passwd #输出第7列包含bash结尾的第1列,第3列2. 数值/字符串比较
- 符号:
== != > < >= <= - 字符串比较必须加双引号
shell
awk -F: 'NR==2{print $1}' /etc/passwd #输出NR==2的行 的第1列
awk -F: '$3==0{print $1}' /etc/passwd #输出第3列等于0的行 的第1列
awk -F: 'NR<=2{print}' /etc/passwd #输出行号小于等于2整行
awk -F: '$1=="root"{print}' /etc/passwd #输入第1列等于"root"关键字的整行3. 逻辑组合条件
&&:逻辑与(所有条件成立)||:逻辑或(任一条件成立)
shell
# UID大于0且小于2
awk -F: '$3>0 && $3<2{print}' /etc/passwd
# UID=1 或 UID=7
awk -F: '$3==1 || $3==7 {print}' /etc/passwd
# UID=1 或 用户名=root
awk -F: '$3==1 || $1=="root" {print}' /etc/passwd4. 运算符条件
支持:+ - * / %、++ --、+= -= *= /=
shell
# 输出奇数行
awk 'NR%2==1 {print}' test.txt
# 输出偶数行
awk 'NR%2==0 {print}' test.txt
# 统计1-200能同时被3和13整除的数的整数个数
seq 200 | awk 'BEGIN{i=0} $1%3==0 && $1%13==0{i++} END{print i}'seq是造数命令,seq200是造数1到200
六、awk高级应用:数组与遍历
什么是数组?
数组是在内存中连续存储的 、相同数据类型的 ,固定长度的有序元素集合,是编程中最基础、最常用的线性数据结构。
简单理解:数组就像一排编号连续的储物柜,每个柜子只能放同一种东西(相同类型),柜子总数固定不变,通过编号(索引) 就能直接找到对应物品。
数组的特点?
- 元素独立且类型统一 :数组里每一个元素都是独立个体 ,互不影响;数组中所有元素必须是同一种数据类型(比如全是整数、全是字符串,不能混合存放)
- 长度固定不可变:数组一旦创建,容量(能存多少个元素)就不能修改,不能直接扩容或缩容。
- 索引访问(核心优势) :用索引(下标) 定位元素,访问速度极快。若数组有
n个元素,下标范围固定为 0 ~ n-1。 - 有序且可重复:元素有固定的先后顺序,且允许存储重复的值。
- 内存连续分配:元素在计算机内存中是紧挨着存储的,这是数组能快速访问的核心原因。
下标不一定是数字。如果是字符串,必须加双引号。如:

数组定义与使用
- 定义数组格式:数组名下标=元素值
- 调用数组格式:数组名下标
shell
#创建数组name,并为数组name赋值两个元素,值分别为jim、tom,输出两个元素的值
[root@server ~]# awk 'BEGIN{name[0]="jim";name[1]="tom";print name[0];print name[1],name[0]}'
jim
tom jim
#为数组name赋值两个元素,值分别为jim、tom,输出一个元素的值
[root@server ~]# awk 'BEGIN{name[0]="jim";name[1]="tom";print name[0]}'
jim- 遍历数组:for(变量 in 数组名) {print 数组名变量}
- 注意:在awk中使用for循环遍历数组名,实际上循环的是下标
数组遍历示例:for(i in name) {print namei}
七、awk真实业务案例(面试真题)
案例一:Web访问日志IP访问量统计
- 获得结果:客户机的地址、访问次数
- 按照访问次数排名
- 环境准备
shell
[root@server ~]# dnf -y install httpd httpd-tools #安装httpd服务及提供ab命令的软件包
[root@server ~]# ab -c 1000 -n 1000 http://127.0.0.1/ #模拟1000人访问1000次本机web服务
#使用Windows浏览器多访问几次:http://192.168.8.101,模拟访问次数,略
[root@server ~]# less /var/log/httpd/access_log #查看httpd的访问日志
127.0.0.1 - - [06/May/2026:19:05:02 +0800] "GET / HTTP/1.0" 403 7621 "-" "ApacheBench/2.3"
127.0.0.1 - - [06/May/2026:19:05:02 +0800] "GET / HTTP/1.0" 403 7621 "-" "ApacheBench/2.3"
127.0.0.1 - - [06/May/2026:19:05:02 +0800] "GET / HTTP/1.0" 403 7621 "-" "ApacheBench/2.3"
127.0.0.1 - - [06/May/2026:19:05:02 +0800] "GET / HTTP/1.0" 403 7621 "-" "ApacheBench/2.3"
...
#此日志文件中的第1列,就是对应客户机的IP地址- 思路分析
- 利用awk提取客户机IP地址,计算访问次数
- 定义数组ip,以$1作为下标(下标不一定是数字)
- 最后利用awk的for循环输出数组下标、对应数组元素值
利用了 数组下标 可以定位一个元素的特性
统计IP与访问次数
shell
[root@server ~]# awk '{ip[$1]++} END{for (i in ip) {print i,ip[i]}}' /var/log/httpd/access_log #定义ip数组时,将$1作为下标,但是$1代表着IP地址。加上数组循环的是下标,所以这里输出的i就是IP地址
192.168.8.1 16
127.0.0.1 1000- 利用sort对提取结果排序
- -n:按数字升序排序
- -k:针对指定的列排序
- -r:反向排序
shell
[root@server ~]# awk '{ip[$1]++} END{for (i in ip) {print i,ip[i]}}' /var/log/httpd/access_log | sort -nrk 2 - sort参数:
-n数字排序、-r倒序、-k指定列
案例二:SSH暴力破解IP安全检测
- 任务需求:安全检测
- 分析日志格式,找到正在暴力破解ssh远程登录密码的IP
- 找到具体IP地址,并汇总访问次数进行排名
shell
[root@server ~]# awk '/Failed/{ip[$11]++} END{for (i in ip) {print i,ip[i]}}' /var/log/secure | sort -nrk 2
#ip的下标是包含Failed的第11列的内容思路分析:
sshd服务登录日志为:/var/log/secure
- 分析日志格式,找到正在暴力破解密码的IP
- 找出用户名一级密码错误的规律,提取有效数据
- 对有效数据进行汇总统计
八、本章完整知识总结
- 掌握awk基本语法与两种命令格式
- 熟练使用awk内置变量:NR、NF、$NF
- 理解awk三个执行时机:BEGIN、逐行处理、END
- 会用四类条件过滤:正则、数值、逻辑、运算符
- 掌握awk数组定义、赋值、for循环遍历
- 能独立完成日志统计、IP分析、系统数据提取等实战场景
请添加图片描述