最近想明白一个点:Agent 做长任务,难点不是模型不会干活,而是模型说"完成了",不代表任务真的完成了。
你告诉它测试不通过不能停,它还是可能停。你告诉它所有需求完成后才能结束,它还是可能做一半就开始总结。
所以问题不只是 prompt 不够好,而是缺一个外部的完成判定和继续调度系统。
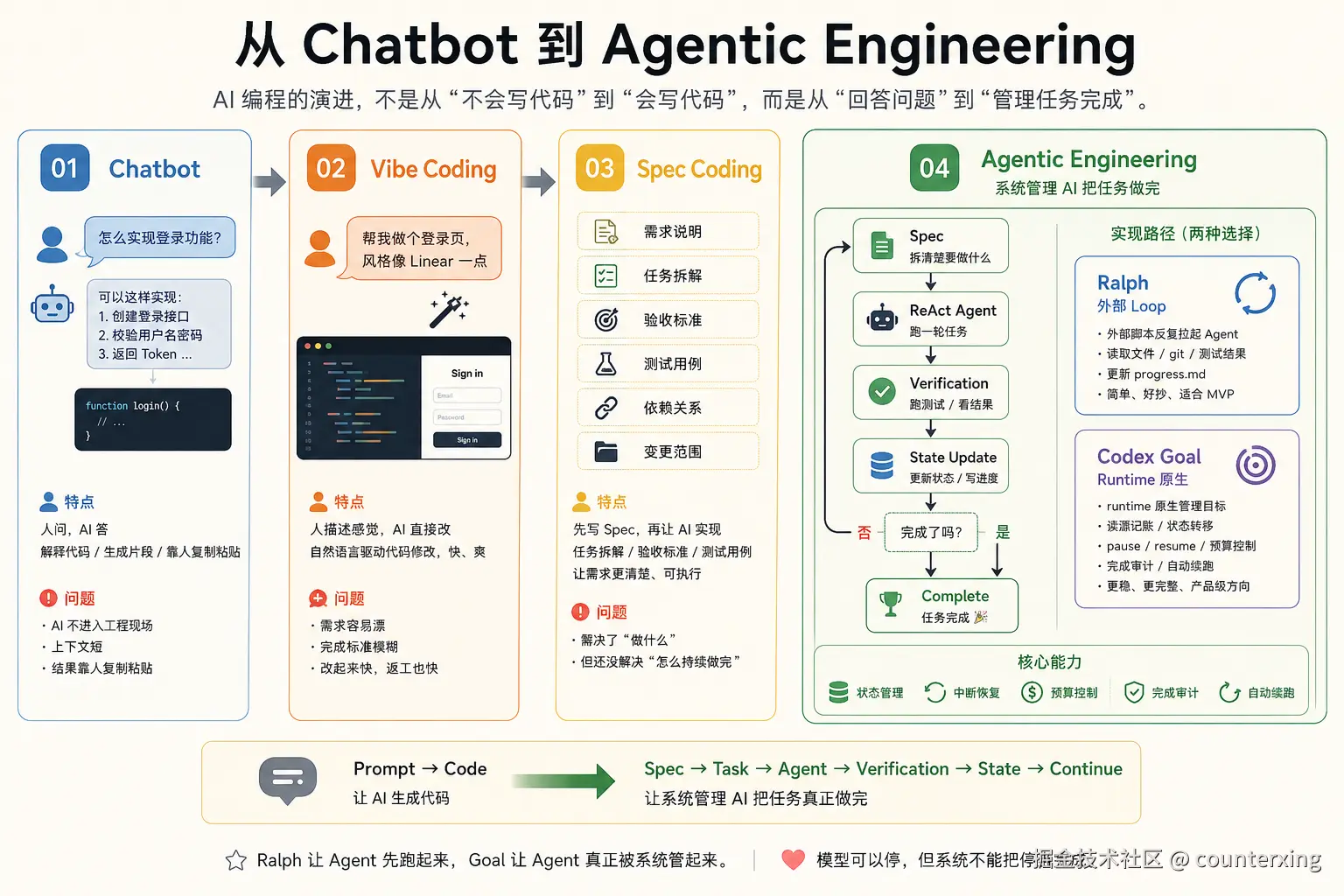
AI Coding 正在从 Chatbot、Vibe Coding、Spec Coding,走到 Agentic Engineering。前面几步主要解决"怎么让 AI 写代码",后面真正要解决的是"怎么让系统管理 AI 把任务做完"。
Spec:先把任务拆清楚

Spec / OpenSpec 解决的是:要做什么?做到什么算完成?
比如"实现登录功能",就不能只写一句话。它需要拆成需求说明、任务拆解、验收标准、测试用例、依赖关系和变更范围。
这一步很重要。没有 Spec,Agent 就会边做边猜。猜得准的时候看起来很聪明,猜偏的时候就会改出一堆你没要的东西。
但 Spec 只是任务说明书。它能告诉模型做什么,不能保证模型一直做下去。
一句话:Spec 负责拆清楚,不负责跑到底。
ReAct:模型只是在跑一轮
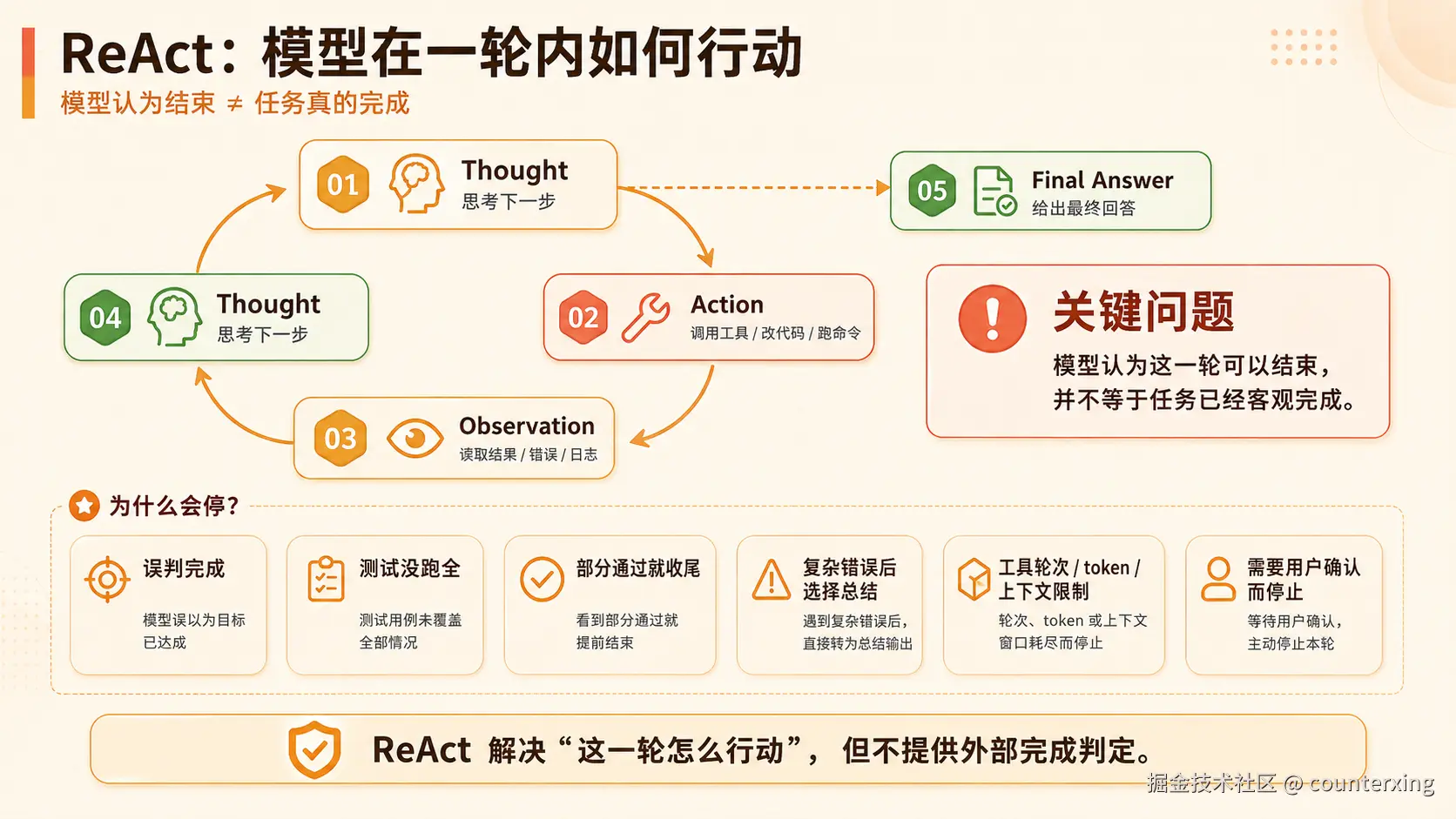
ReAct 是模型的一轮执行方式:Thought → Action → Observation → Final Answer。
它可以思考、调工具、看结果、改代码、跑测试。也正是因为有了 ReAct,模型才从"回答问题"变成了"进入工程现场做事"。
但问题在 Final Answer。
Final Answer 只是模型认为这一轮可以结束了,不代表任务真的完成。它可能测试没跑全,看到部分通过就收尾;也可能遇到复杂错误后开始总结,把问题留给人;还可能因为 token、工具轮次、上下文限制而停止。
所以 ReAct 解决的是:这一轮怎么做。
它不解决:没做完怎么办。
这就是 Ralph 和 Codex Goal 要继续补的洞。
Ralph:在外面套一个 loop
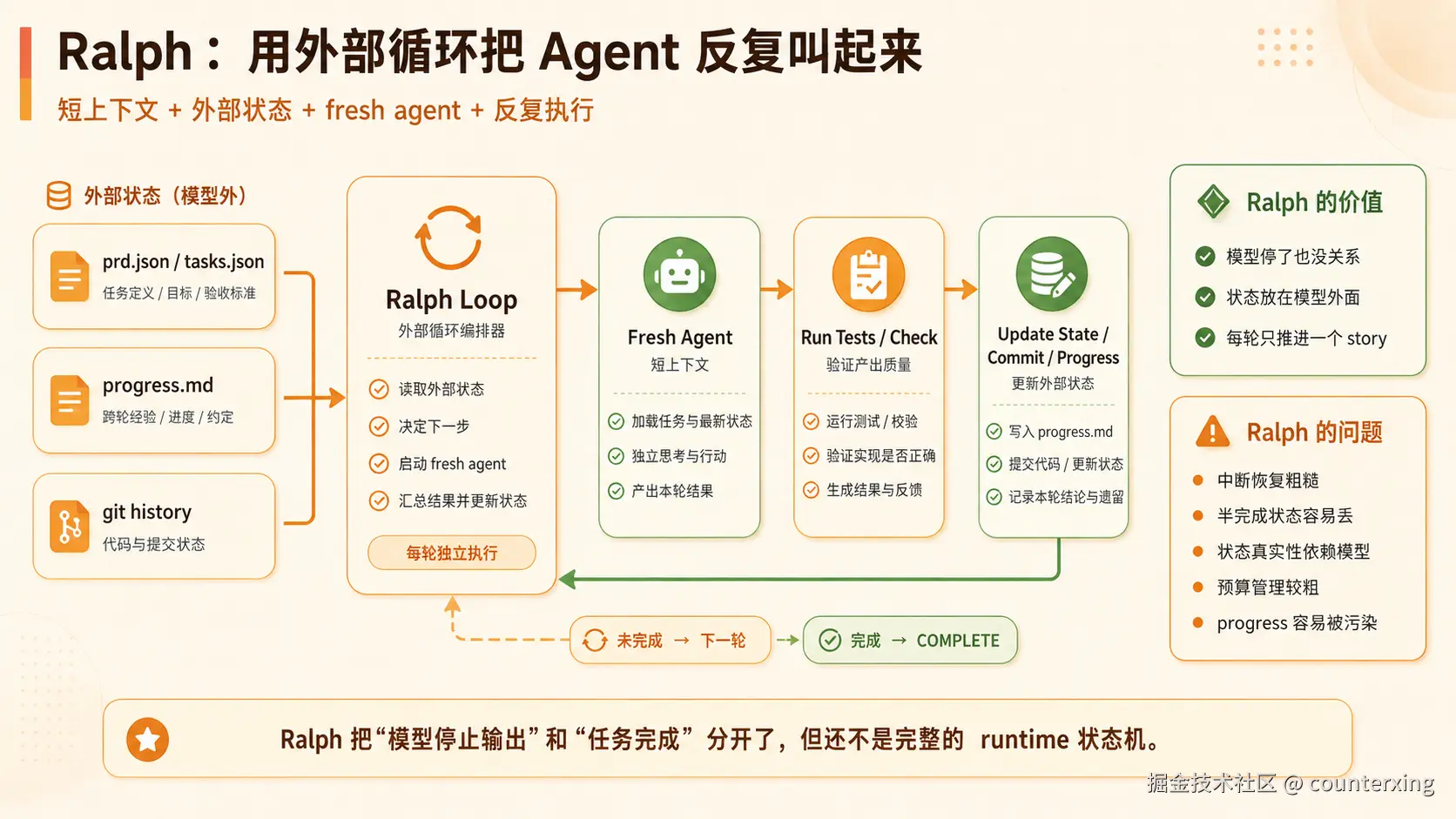
Ralph 的思路很简单:既然模型会停,那就在外面反复把它叫起来。
它大概会读取 tasks.json / prd.json,再读 progress.md 和 git history,然后启动一个 fresh agent。这个 agent 只做一个小任务,跑测试,更新状态。如果没完成,就进入下一轮。
Ralph 的价值在于,它把"模型停止输出"和"任务完成"分开了。
普通 ReAct 里,模型说完了,事情通常就结束了。Ralph 里,模型说完了不算数,还要看任务状态、测试结果、git 变更和 progress。
这已经比单轮 ReAct 稳很多。
但 Ralph 的问题也明显。中断恢复比较粗,半完成状态容易丢,progress.md 可能被污染,状态真实性还依赖模型,预算管理也比较粗。
比如上一轮 Agent 写了一句"这个测试可以忽略",下一轮 Agent 可能真的信了。
所以 Ralph 很适合 MVP,但它不是最终形态。
Codex Goal:更好的方式是 runtime 原生管理目标
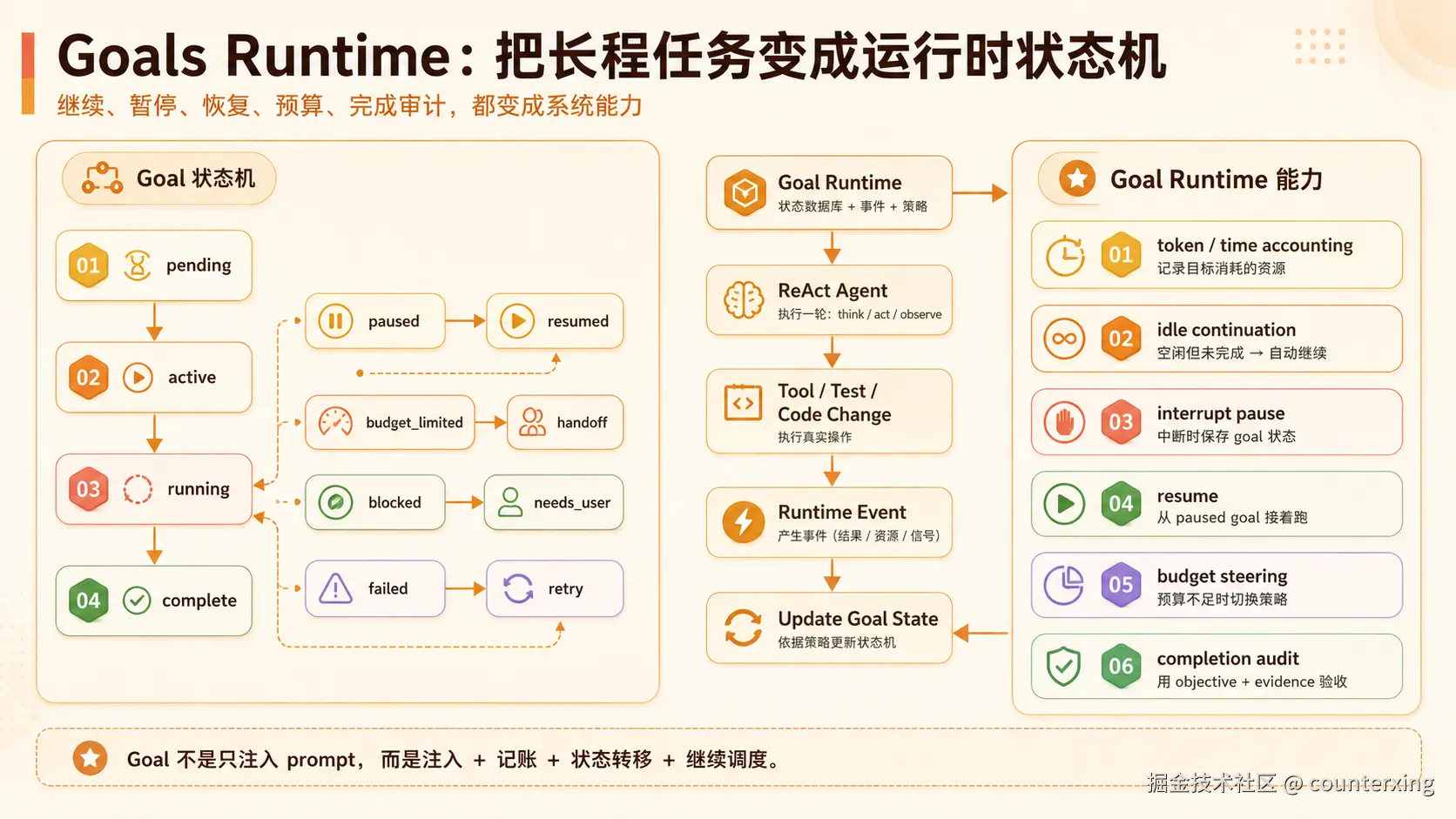
Codex Goal 更进一步。它不是在外面套一个脚本,而是让 runtime 原生知道:现在有一个长期目标正在执行。
它要管理当前 goal 是什么,跑到哪一步,用了多少 token / 时间,模型停了要不要继续,中断后怎么 pause / resume,预算不够时怎么收尾,什么时候才能 complete。
所以 Goal 不是简单地"每次把目标注入 prompt"。
更准确地说,Goal 是:注入目标 + 资源记账 + 状态转移 + 继续调度 + 完成审计。
这比 Ralph 高一层。
它和 Ralph 最大的不同,就发生在 runtime 阶段。
Ralph 的 loop 在模型外面。外部脚本读文件、看状态、发现没完成,再拉起下一轮模型。它能续跑,但 runtime 本身并不知道"目标生命周期"这件事。
Codex Goal 则把 goal 放进 runtime。runtime 原生知道目标还在运行,知道它是 paused、blocked、budget_limited 还是 complete,也知道什么时候应该继续调度、什么时候应该停下来做 handoff。
所以 Ralph 更像外部续命,Goal 更像运行时托管。
为什么 Goal 更好?
因为它把很多靠 prompt 自觉的事情,变成了系统能力。
模型停了,不代表任务结束。Goal 可以判断 turn 结束了,但 goal 没 complete,所以继续。
中断也不再是事故,而是状态。中断后可以进入 paused,下次 resume。
预算也不是"最多跑几轮"。Goal 可以知道这个目标用了多少 token,还剩多少预算,是否应该继续,是否应该 handoff。
更关键的是,完成不是模型说了算。模型说完成,不一定算。真正应该看 objective 是否满足、验收标准是否满足、测试是否通过、有没有 evidence。
一句话:完成权不应该交给模型记忆,而应该交给审计。
Ralph 和 Goal 怎么选?

一个更现实的长任务范式是:拆清楚、跑一轮、验硬证据、写状态,没完成就继续。
我的判断是:Ralph 是外部 loop,Goal 是原生 runtime。Goal 肯定更完整,但 Ralph 更容易起步。
如果现在做产品,比较现实的路线是先做 Ralph-style loop,用文件、git、测试命令和日志把循环跑起来;再补状态机、预算管理、pause / resume、completion audit、自动续跑;最后慢慢演进成 Goal Runtime。
这个路线不漂亮,但很工程。
最后总结
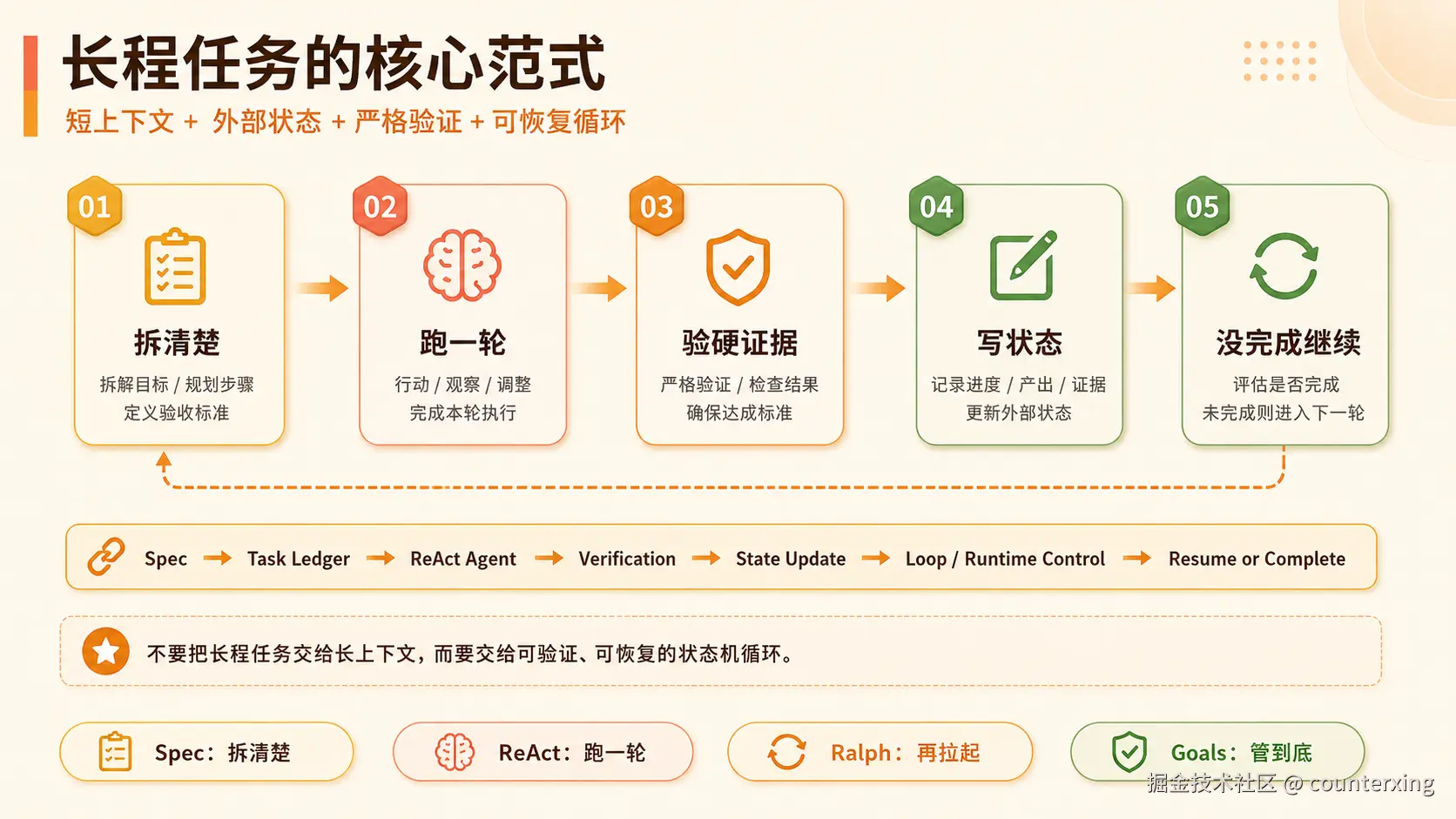
这件事可以拆成四层:Spec 拆清楚,ReAct 跑一轮,Ralph 停了再拉起,Goal 把继续、暂停、恢复、预算、完成审计做成 runtime 能力。
Agent 做长任务,不能只靠长上下文,也不能只靠一句 prompt。
Ralph 能快速跑起来。
Codex Goal 才是更正确的架构方向。
最后一句话:模型可以停,但系统不能把停当完成。