【CVPR2024】用Diffusion"造"遥感分割数据:SatSynth论文解读
遥感影像并不缺。真正缺的是高质量像素级标注。对于semantic segmentation任务来说,模型需要知道每一个像素属于什么类别,比如building、road、water、tree、agriculture land等。问题在于,遥感图像通常分辨率高、场景复杂、类别尺度差异大,人工标注既耗时又昂贵。尤其是小目标类别,例如车辆、船只、飞机、网球场、桥梁等,在图像中占比很低,但又对精细化识别非常重要。
CVPR 2024论文SatSynth: Augmenting Image-Mask Pairs through Diffusion Models for Aerial Semantic Segmentation 提出了一个直接而有启发性的思路:既然真实标注难获得,那能不能用diffusion model生成新的image-mask pairs,再把这些合成样本加入训练集,提升下游语义分割模型的表现?
这篇论文的核心不是"用diffusion直接预测segmentation mask",而是把diffusion model当成一个合成数据工厂。它学习遥感图像和语义标签的联合分布,生成新的图像和对应mask,然后用这些合成数据增强segmentation model的训练集。论文在iSAID、LoveDA和OpenEarthMap三个遥感语义分割数据集上验证了这一策略的有效性。
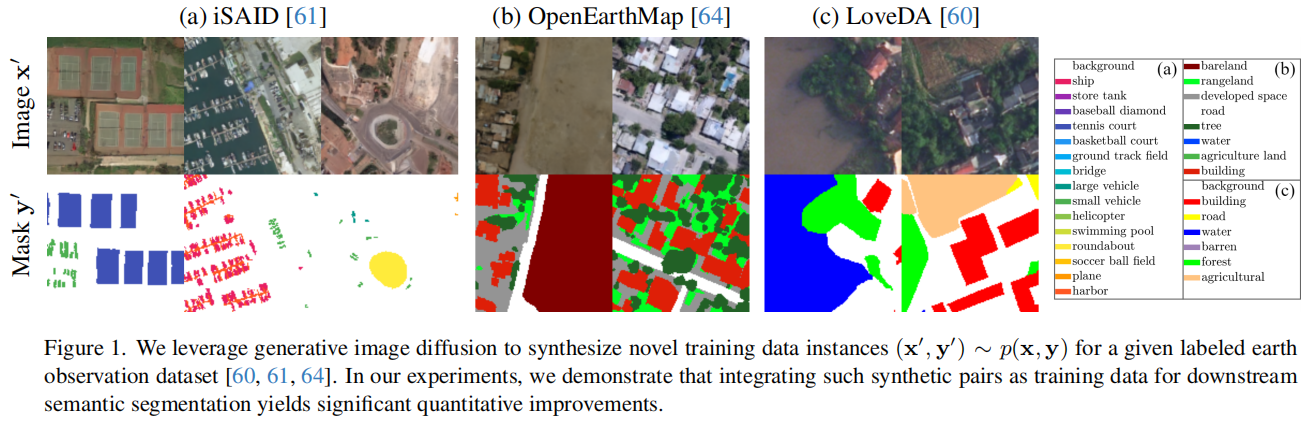
图中展示了iSAID、OpenEarthMap和LoveDA三个数据集上的合成图像及对应mask。它直观说明SatSynth并不是只生成遥感图像,而是同时生成图像和语义标签。
一、问题背景:为什么遥感分割需要合成数据?
遥感semantic segmentation的难点不只是"图像复杂",更关键的是标注数据覆盖不足。一张遥感图像里可能同时出现道路、建筑、水体、树木、农田、裸地、车辆等多种对象。不同类别的尺度差异很大,building可能占据大片区域,而small vehicle可能只占几个像素。原论文提到,在iSAID数据集中,foreground pixels比例只有2.85%,而VOC2012中foreground pixels比例约为29.75%,这说明遥感分割中的前景目标更稀疏,小目标和长尾类别问题更明显。
传统augmentation方法,例如flip、rotation、crop、resize、color jitter,能够增加表观扰动,但它们本质上仍然围绕已有样本做几何或颜色变换,无法真正创造新的场景组合。比如原数据里没有"港口+大量船只+复杂道路"的组合,普通augmentation也很难凭空生成这种新场景。
SatSynth想解决的正是这个问题:用diffusion model学习真实遥感图像和mask的联合分布,然后采样生成新的训练样本。从机器学习角度看,真实数据集可以写成:D={(xi,yi)∣xi∈RH×W×3,yi∈{0,...,K−1}H×W,1≤i≤N}\mathcal{D}=\{(x_i,y_i)\mid x_i\in\mathbb{R}^{H\times W\times3},y_i\in\{0,\ldots,K-1\}^{H\times W},1\leq i\leq N\}D={(xi,yi)∣xi∈RH×W×3,yi∈{0,...,K−1}H×W,1≤i≤N}
其中,xix_ixi表示RGB遥感图像,yiy_iyi表示对应的像素级语义标签,KKK是类别数。
传统segmentation模型直接学习:p(y∣x)p(y|x)p(y∣x),也就是给定图像,预测mask。而SatSynth先学习p(x,y)p(x,y)p(x,y)
也就是图像和mask共同出现的联合分布。学到这个分布之后,模型就可以生成新的样本对(xi′,yi′)∼p(x,y)(x_i',y_i')\sim p(x,y)(xi′,yi′)∼p(x,y),
然后用真实数据D\mathcal{D}D和合成数据D′\mathcal{D}'D′一起训练segmentation模型:Dtrain=D∪D′\mathcal{D}_{train}=\mathcal{D}\cup\mathcal{D}'Dtrain=D∪D′
这个思路的关键转变是:不再只增强图像,而是增强"图像+标注"这一完整训练单元。
二、SatSynth的核心想法:直接生成image-mask pair
SatSynth的方法可以拆成四步。
第一步,给定真实数据集D\mathcal{D}D,其中每个样本都有图像xix_ixi和maskyiy_iyi。
第二步,把离散mask转成bit-space表示,使它能和RGB图像一起输入diffusion model。
第三步,训练一个DDPM,让它学习图像和mask的联合分布p(x,y)p(x,y)p(x,y)。
第四步,从噪声中采样,生成新的合成图像xi′x_i'xi′和对应maskyi′y_i'yi′,再用于下游segmentation training。
用流程图表示就是:
python
真实遥感图像 x + 真实语义mask y
↓
mask y 转换为 bit-space 表示
↓
RGB图像与bit-space mask拼接为多通道输入
↓
训练DDPM学习联合分布 p(x,y)
↓
采样生成 synthetic image-mask pairs
↓
加入训练集,训练semantic segmentation模型这种设计有一个明显优势:它避免了"先生成图像,再额外标注mask"的麻烦。生成模型本身就输出成对样本。
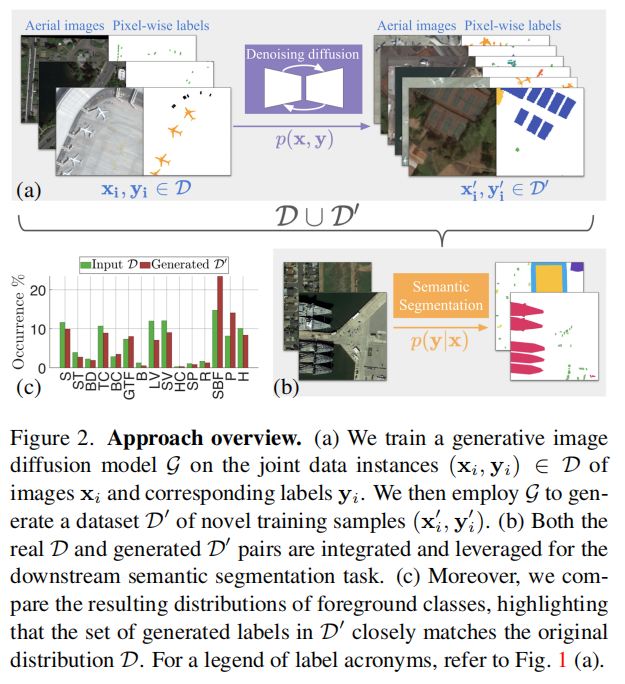
该图展示了SatSynth的整体流程:先训练生成模型GGG学习真实image-mask pair分布,再生成合成数据D′\mathcal{D}'D′,最后将真实数据D\mathcal{D}D与合成数据D′\mathcal{D}'D′共同用于下游语义分割训练。图中还比较了真实标签和生成标签的前景类别分布。
三、技术关键:为什么要把mask转成bit-space?
遥感图像xxx是连续RGB值,比较适合diffusion model处理。但mask yyy是离散类别图。每个像素的值是类别编号,例如:
0 = background
1 = road
2 = building
3 = water
...如果直接把类别编号当作连续值生成,会有明显问题。类别编号本身没有连续语义,road=1、building=2并不意味着building比road"大1"。模型生成出的中间值也很难稳定还原成合法类别。
常见方法是one-hot encoding。若有KKK类,则每个像素变成KKK维向量:OH(y)k=Iy=kOH(y)_k=\mathbb{I}y=kOH(y)k=Iy=k
但one-hot的通道数随类别数线性增长。如果类别很多,输入维度会明显增加。SatSynth采用的是bit-space encoding 。它把类别编号转为二进制编码:bin:{0,...,K−1}→{0,1}⌈log2K⌉\mathrm{bin}:\{0,\dots,K-1\}\to\{0,1\}^{\lceil \log_2K\rceil}bin:{0,...,K−1}→{0,1}⌈log2K⌉
如果有K=16K=16K=16类,one-hot需要16个通道,而bit-space只需要:⌈log216⌉=4\lceil \log_2 16\rceil=4⌈log216⌉=4个通道。
因此,模型的联合输入通道数为:C=3+⌈log2K⌉C=3+\lceil \log_2K\rceilC=3+⌈log2K⌉,其中3是RGB通道数,⌈log2K⌉\lceil \log_2K\rceil⌈log2K⌉是mask的bit通道数。例如iSAID有16类,则输入通道数是C=3+4=7C=3+4=7C=3+4=7
这比直接使用one-hot的3+16=193+16=193+16=19个通道更紧凑,也更利于模型稳定训练。原论文的ablation study也证明,bit-space encoding优于one-hot encoding。
从直觉上说,SatSynth不是让diffusion model生成一张普通RGB图,而是生成一张"多通道联合图":
前3个通道:合成遥感图像
后若干通道:合成mask的bit-space表示生成完成后,再把bit-space mask转换回类别mask。
四、模型细节:DDPM如何生成成对样本?
SatSynth使用的是标准Denoising Diffusion Probabilistic Model,即DDPM。
DDPM的基本思想是:先不断给真实样本加噪声,使其逐步变成高斯噪声;再训练一个U-Net学习反向去噪过程,从纯噪声一步步恢复出真实样本。
前向加噪可以写成:xt=1−βtxt−1+βtϵ,ϵ∼N(0,I)x_t=\sqrt{1-\beta_t}x_{t-1}+\sqrt{\beta_t}\epsilon,\quad \epsilon\sim\mathcal{N}(0,I)xt=1−βt xt−1+βt ϵ,ϵ∼N(0,I)
其中,xtx_txt表示第ttt步的噪声样本,βt\beta_tβt控制每一步加入的噪声强度,ϵ\epsilonϵ是高斯噪声。
对于SatSynth来说,这里的xtx_txt不是普通RGB图像,而是图像与mask拼接后的joint sample。更准确地说,模型处理的是:si=(xi,bin(yi))∈0,1H×W×Cs_i=(x_i,\mathrm{bin}(y_i))\in0,1^{H\times W\times C}si=(xi,bin(yi))∈0,1H×W×C,其中:C=3+⌈log2K⌉C=3+\lceil \log_2K\rceilC=3+⌈log2K⌉
训练时,DDPM学习从sts_tst预测噪声ϵ\epsilonϵ,从而逐步恢复s0s_0s0。采样时,模型从随机噪声开始,生成:s^=(x^,y^bit)\hat{s}=(\hat{x},\hat{y}{bit})s^=(x^,y^bit),再经过threshold和nearest-neighbor assignment,将y^bit\hat{y}{bit}y^bit转换回类别mask:(x′,y′)=(x^,bin−1(y^bit))(x',y')=(\hat{x},\mathrm{bin}^{-1}(\hat{y}_{bit}))(x′,y′)=(x^,bin−1(y^bit))
原论文设置T=1000T=1000T=1000个denoising steps,并使用linear noise schedule。模型默认生成128×128128\times128128×128的样本,随后可通过super-resolution module生成256×256256\times256256×256样本。
五、为什么还需要super-resolution?
遥感图像和自然图像有一个很大区别:细节很重要。在遥感分割中,很多类别本身就很小,例如车辆、飞机、船只、桥梁边界、道路细线。如果分辨率太低,目标可能只剩几个像素,甚至完全消失。但直接训练高分辨率image-space diffusion model成本很高,也容易训练不稳定。因此SatSynth采用两阶段策略:
第一阶段,训练基础生成模型GGG,生成128×128128\times128128×128的image-mask pair。
第二阶段,训练super-resolution diffusion model GSRG_{\mathrm{SR}}GSR,把低分辨率pair提升到256×256256\times256256×256。论文将super-resolution模型写为:GSR:RL×RH×W×C→R2H×2W×CG_{\mathrm{SR}}:\mathbb{R}^{L}\times\mathbb{R}^{H\times W\times C}\to\mathbb{R}^{2H\times2W\times C}GSR:RL×RH×W×C→R2H×2W×C
测试时的生成过程可以写成:(x^i,y^i)=GSR(z1,G(z0))(\hat{x}i,\hat{y}i)=G{\mathrm{SR}}(z_1,G(z_0))(x^i,y^i)=GSR(z1,G(z0)),也就是说,先用GGG从噪声生成低分辨率pair,再用GSRG{\mathrm{SR}}GSR进一步放大。

该图展示了SatSynth在iSAID数据集上的超分辨率生成效果。左侧为128×128128\times128128×128低分辨率生成结果,右侧为256×256256\times256256×256超分辨率结果。该图适合用来说明作者并没有直接训练高分辨率生成模型,而是采用低分辨率生成加超分辨率的折中方案。
六、实验结果:合成数据真的有用吗?
论文从两个层面评估SatSynth。一是生成样本质量,二是下游segmentation performance。
1. 生成图像质量
作者将SatSynth与SemGAN和vanilla DDPM进行比较,使用FID、sFID和IS等指标评估生成图像质量。
在iSAID上,SatSynth的FID为8.66,优于SemGAN的10.21和DDPM的17.50。
在LoveDA上,SatSynth的FID为13.87,优于SemGAN的37.47和DDPM的22.70。
在OpenEarthMap上,SatSynth的FID为12.09,也优于SemGAN的16.20和DDPM的15.35。
这说明联合生成image-mask pair并没有损害图像生成质量,甚至可能因为mask提供了结构约束,使图像生成更稳定。不过需要注意,FID主要衡量合成图像分布与真实图像分布的接近程度,并不能直接证明mask一定准确。图像看起来真实,不代表标签一定完全正确。

2. 下游segmentation性能
SatSynth真正要证明的不是"图像生成得像不像",而是"合成数据能不能提升segmentation model"。论文将合成数据D′\mathcal{D}'D′加入真实训练集D\mathcal{D}D,训练FPN segmentation backbone,并与SemGAN、SegDiff等方法比较。结果显示,SatSynth在三个数据集上都明显优于这些生成式分割baseline:
| 数据集 | SemGAN IoU | SegDiff IoU | SatSynth IoU |
|---|---|---|---|
| iSAID | 13.01 | 41.25 | 52.13 |
| LoveDA | 31.75 | 36.60 | 48.97 |
| OpenEarthMap | 40.43 | 51.23 | 62.24 |
这个结果说明,与其让diffusion model直接输出segmentation prediction,不如让它生成新的训练数据,再交给成熟的segmentation model学习。
这也是本文最值得借鉴的观点:
生成模型不一定要替代判别模型,它可以作为数据增强工具,为判别模型提供更丰富的训练样本。
七、合成数据越多越好吗?
答案是否定的。
论文研究了合成数据比例RRR的影响:∣D′∣=R⋅∣D∣|\mathcal{D}'|=R\cdot|\mathcal{D}|∣D′∣=R⋅∣D∣
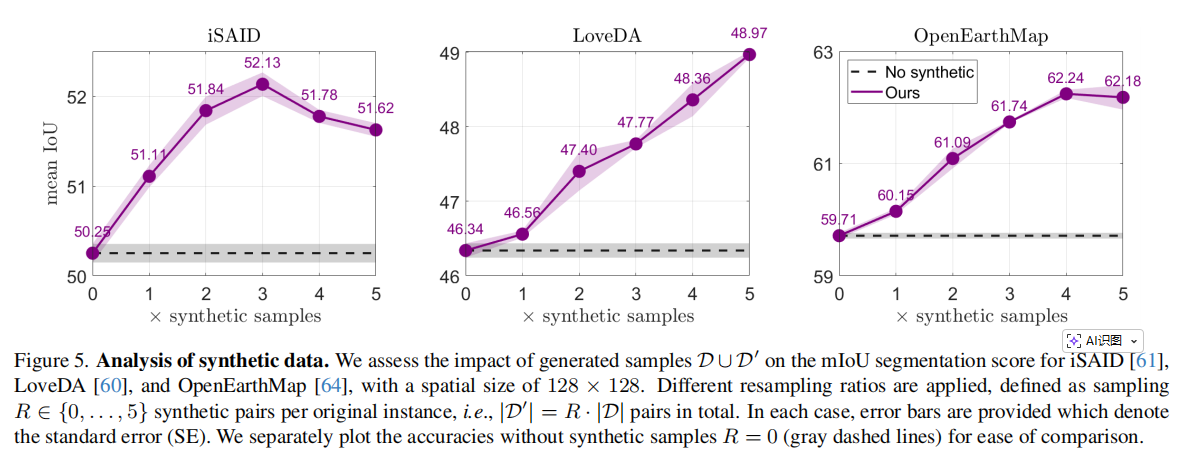
其中,RRR表示每个真实样本对应生成多少个合成样本。结果显示,不同数据集的最优RRR不同。iSAID在R=3R=3R=3时达到较优表现,之后继续增加合成数据,performance反而下降;LoveDA随着RRR增加持续提升,在R=5R=5R=5达到最好;OpenEarthMap大约在R=4R=4R=4附近达到平台。T
这说明synthetic data augmentation存在边际收益递减。生成太多样本后,合成数据可能变得冗余,甚至放大生成模型自身的偏差。换句话说,合成数据不是越多越好,而是需要寻找合适比例。
八、对不同segmentation backbone是否有效?
为了验证方法的通用性,论文在iSAID上测试了多个segmentation backbone,包括PFSegNet、FarSeg、SegFormer、FPN和PSPNet。加入合成数据后,这些模型的IoU均有提升:
| Model | 只用真实数据IoU | 真实+合成数据IoU | 提升 |
|---|---|---|---|
| PFSegNet | 60.93 | 63.71 | +2.78 |
| FarSeg | 62.28 | 62.95 | +0.67 |
| SegFormer | 60.95 | 62.13 | +1.18 |
| FPN | 59.52 | 60.65 | +1.13 |
| PSPNet | 48.95 | 56.54 | +7.59 |
这说明SatSynth不是只对某个特定模型有效,而是能够作为一种通用data augmentation策略。但这个表也透露出一个现象:强baseline的提升有限。例如FarSeg本身已经比较强,加入合成数据后IoU只提升0.67。相反,PSPNet提升较大。这说明SatSynth对弱模型的帮助可能更明显,而对强模型的边际增益会变小。

该表展示了在iSAID数据集上,不同segmentation backbone加入SatSynth合成数据前后的性能变化。建议以表格截图形式插入,突出"多个模型均有提升,但提升幅度不同"。
九、消融实验:bit-space和预测噪声为什么重要?
论文的消融实验主要验证两个设计:
第一,mask encoding方式。
第二,diffusion model预测目标。
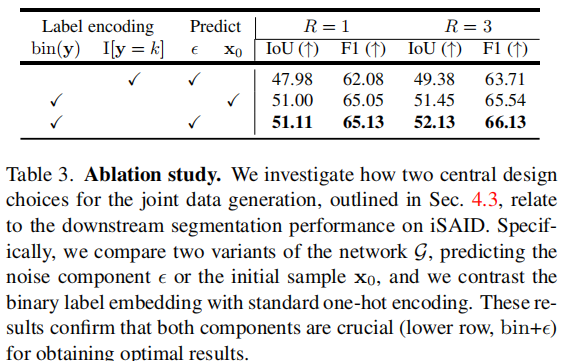
作者比较了bit-space encoding和one-hot encoding,也比较了预测ϵ\epsilonϵ与预测x0x_0x0。结果显示,最优组合是bit-space encoding + noise prediction ε
这说明两个选择都很关键:一方面,bit-space encoding减少了label通道数,使联合生成更紧凑;另一方面,预测噪声ϵ\epsilonϵ符合DDPM经典训练范式,比直接预测x0x_0x0更稳定。从公式上看,预测ϵ\epsilonϵ相当于让网络学习ϵθ(st,t)≈ϵ\epsilon_\theta(s_t,t)\approx \epsilonϵθ(st,t)≈ϵ,其中sts_tst是第ttt步的noisy joint sample,s0=(x,bin(y))s_0=(x,\mathrm{bin}(y))s0=(x,bin(y))是真实joint sample。
其训练目标可以概括为:LDDPM=Es0,ϵ,t∥ϵ−ϵθ(st,t)∥22\mathcal{L}{DDPM}=\mathbb{E}{s_0,\epsilon,t}\left\\\|\\epsilon-\\epsilon_\\theta(s_t,t)\\\|_2\^2\\rightLDDPM=Es0,ϵ,t∥ϵ−ϵθ(st,t)∥22
这个目标比较稳定,也与标准DDPM设定一致。
十、批判性分析:这篇论文强在哪里,又弱在哪里?
SatSynth是一篇思路清晰、实验完整度较高的论文,但它也不是没有问题。下面从更严谨的研究视角分析。
1. 优点一:它把生成模型的角色定位得很准确
很多diffusion for segmentation论文容易走向一个路线:让diffusion model直接预测mask。
但SatSynth选择了另一条更务实的路径:**用生成模型造数据,而不是直接承担最终预测任务。**这很合理。因为在semantic segmentation中,FPN、SegFormer、FarSeg、PFSegNet等判别式模型已经非常成熟。强行让diffusion model直接做分割,未必比现有segmentation architecture更高效。
2. 优点二:它真正生成了image-mask pair,而不是只生成image
这点非常关键。如果只生成图像,仍然需要伪标签或人工标注。SatSynth直接生成(x′,y′)(x',y')(x′,y′),理论上可以绕过标注瓶颈。从数据增强角度看,这比普通synthetic image generation更有价值。因为segmentation需要的是完整训练样本,而不是单独图像。
3. 优点三:实验没有只停留在生成质量,而是看下游任务
这篇论文没有只展示FID、sFID、IS,也验证了segmentation mIoU和F1。这是很重要的。因为生成质量好,不等于下游任务有用。SatSynth通过多个数据集和多个segmentation backbone证明,合成样本确实能带来一定性能提升。
4. 问题一:image-mask一致性评估还不够
这是我认为这篇论文最大的不足。SatSynth生成的是图像和mask的联合样本,但论文主要通过可视化和下游性能间接说明二者匹配。问题是,遥感图像中很多类别视觉相似,例如bare land、road、roof、developed space、水体阴影等,生成mask看起来合理,不代表它一定准确。
更严格的评估应该包括:
- 人工检查synthetic image-mask consistency
- 使用强segmentation teacher评估合成mask与合成图像的一致性
- 分类别统计mask noise
- 统计边界误差和小目标错标率
- 分析生成mask的拓扑结构是否合理
5. 问题二:高分辨率能力仍然有限
SatSynth默认生成128×128128\times128128×128,再超分到256×256256\times256256×256。这个设置有工程合理性,但遥感任务往往需要更高分辨率。尤其是iSAID这种object-centric segmentation,小目标类别很多。如果生成分辨率不足,小车辆、船只、飞机等小目标的形态可能不稳定。超分辨率可以提升视觉清晰度,但不一定能恢复真实语义边界。所以SatSynth更像是一个有效的proof-of-concept,还不能说已经完全解决高分辨率遥感标注数据生成问题。
6. 问题三:与传统augmentation的比较不够充分
论文主要比较了SemGAN、DDPM、SegDiff等生成式方法。但从data augmentation角度看,读者自然会问:
和Copy-Paste相比如何?
和CutMix / ClassMix相比如何?
和class-balanced crop相比如何?
和strong color jitter + scale augmentation相比如何?如果简单传统augmentation也能带来接近收益,那么训练diffusion model的成本是否值得,就需要进一步讨论。SatSynth要证明的不只是"比其他生成模型好",还应该证明:
Diffusion synthetic augmentation>Strong conventional augmentation\text{Diffusion synthetic augmentation}>\text{Strong conventional augmentation}Diffusion synthetic augmentation>Strong conventional augmentation
至少从正文展示来看,这方面还不够充分。
7. 问题四:rare classes分析不足
遥感分割的核心难点之一是long-tail distribution。整体mIoU提升固然重要,但更关键的问题是:
小目标类别是否明显提升?
稀有类别是否明显提升?
合成数据是否真的改善类别不平衡?
错误主要集中在哪些类别?
论文Fig.2中展示了真实标签和生成标签的前景类别分布对比,但类别分布相似并不代表形态、尺度、空间上下文也相似。
如果把SatSynth用于其他领域,有什么启发?
SatSynth的思想不只适用于遥感,也可以迁移到医学影像、工业缺陷检测、病理图像分析等领域。
只要任务中存在image-mask pair,就可以考虑学习:p(x,y)p(x,y)p(x,y),然后生成新的成对样本。例如医学图像中:
CT + organ mask
MRI + tumor mask
pathology image + lesion mask
endoscopy image + lesion boundary
但医学场景的风险会更高。因为医学mask涉及解剖结构、病灶边界和临床判断,合成错误标签可能造成更严重的模型偏差。因此,如果把SatSynth思想迁移到医学影像,需要额外加入:
- 医生人工审核
- 解剖结构约束
- 病灶形态合理性评估
- 3D连续性约束
- 合成数据对模型错误模式的影响分析
这也是为什么医学3D生成模型通常不能简单照搬2D遥感方法。
总结:SatSynth真正证明了什么?
SatSynth最重要的贡献,不是提出了一个特别复杂的网络结构,而是提出了一种清晰的数据生成范式:
用diffusion model学习图像和语义标签的联合分布,生成新的image-mask pairs,再作为数据增强用于下游semantic segmentation。
它证明了三件事:
第一,diffusion model可以不只生成图像,也可以生成与图像匹配的语义mask。
第二,合成image-mask pairs确实能提升遥感segmentation performance。
第三,合成数据比例需要控制,过多合成样本可能带来冗余和边际收益下降。
但它也留下了几个关键问题:合成mask是否足够可靠?小目标和稀有类别是否真正受益?与强传统augmentation相比是否仍有明显优势?高分辨率遥感场景下能否继续扩展?这些问题决定了SatSynth能否从一个有效的benchmark方法,进一步走向更稳健的真实应用。
如果用一句话概括这篇论文:
SatSynth不是试图让diffusion替代segmentation model,而是让diffusion成为一个可生成标注数据的数据工厂;这个思路很有价值,但合成标签的可靠性和可控性仍然是后续研究必须解决的问题。