一、开头:同一个词,两个意思
上篇文章留下了一个问题。
Embedding 让大模型在高维空间里建立了词与词之间的语义关系------"法国"和"巴黎"靠近,"猫"和"狗"是邻居。但 Embedding 有一个根本缺陷:它只描述词本身,不描述词所处的环境。
来看两个句子:
"我今天买了一个苹果。"
"苹果发布了新款 iPhone。"
两句话里的"苹果",Embedding 向量是完全相同的------训练完成后就固定了。同一个向量,一个指水果,一个指科技公司。大模型怎么用固定的向量表达动态的含义?
核心思想是:不要只看这个词是什么,要看它周围有什么。
二、Embedding 向量如何变成 Q、K、V
每个 token 经过 Embedding 查表后,得到一个固定向量------这个词的"静态语义档案"。要让这个档案看见上下文,还需要一次变形。
一句话回答这个问题
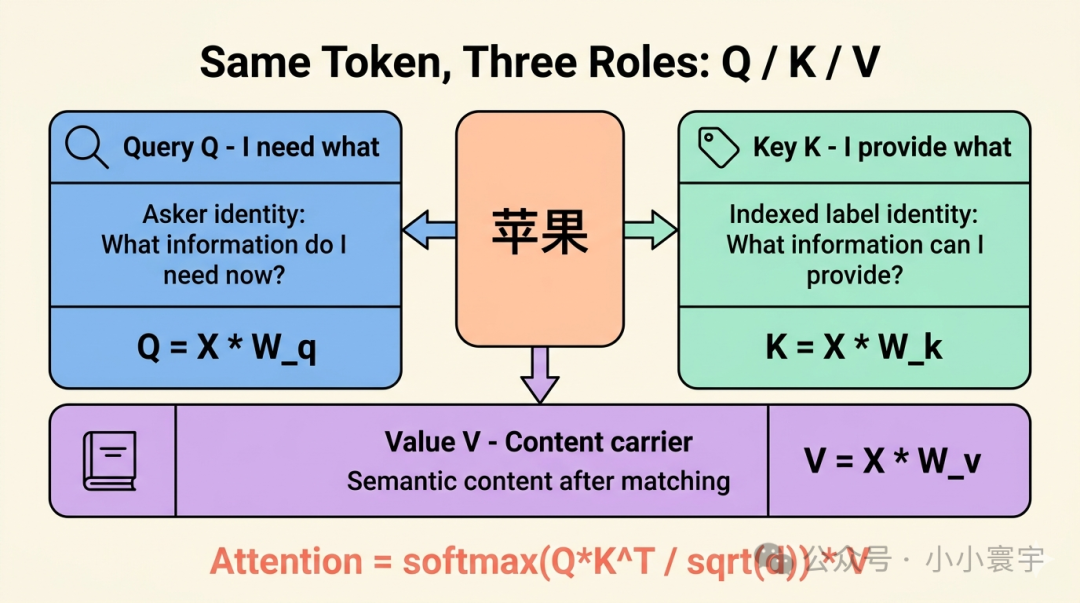
Embedding 向量同时乘以三个权重矩阵,分别得到 Query、Key、Value:
bash
Q = X · W_q (X 是 Embedding 向量,形状 1×768)
K = X · W_k
V = X · W_vW_q、W_k、W_v 是模型在训练中学习到的参数,三个矩阵互不相同。同一个 Embedding 向量经过三次线性变换,得到三个不同"身份"的投影------同一个词可以同时是提问者、索引标签、和内容提供者。
真实模型中,W_q、W_k、W_v 的形状是 768 × d_head,d_head 通常是 64。Embedding 向量从 768 维投影到 64 维,所有词的 Q、K、V 打包成三个 N×d_head 的矩阵。数学原理和下面的例子完全一样,只是数字更大。
用一个 2 维例子,走完 Attention 的完整流程
为便于验算,这里把维度压缩到最小,直接指定 Q、K、V 向量(相当于经过权重矩阵变换后的结果),来完整展示一次注意力计算。
设定两个 token:"苹"和"果"(取自"苹果"一词,代表同一个词的内部协作关系)。
bash
场景:输入序列 ["苹", "果"],共 2 个 token
第一步:为每个 token 定义 Q、K、V 向量
苹:Q₁=[3, 1],K₁=[3, 1],V₁=[6, 0.5]
果:Q₂=[1, 3],K₂=[1, 3],V₂=[0.5, 6]
("苹"在第一维更强,"果"在第二维更强,Q 和 K 方向一致)
第二步:计算所有 QK^T 注意力分数(每个 Q 和每个 K 做点积)
分数矩阵:
Q₁ · K₁ = [3,1] · [3,1] = 3×3 + 1×1 = 10 (苹→苹,自己和自己)
Q₁ · K₂ = [3,1] · [1,3] = 3×1 + 1×3 = 6 (苹→果)
Q₂ · K₁ = [1,3] · [3,1] = 1×3 + 3×1 = 6 (果→苹)
Q₂ · K₂ = [1,3] · [1,3] = 1×1 + 3×3 = 10 (果→果,自己和自己)
第三步:Softmax 归一化(逐行分别归一化)
对"苹"的行:[10, 6] 做 softmax
e^10 = 22026,e^6 = 403
总和 = 22429
苹→苹 = 22026/22429 ≈ 98.2%
苹→果 = 403/22429 ≈ 1.8%
对"果"的行:[6, 10] 做 softmax
e^6 = 403,e^10 = 22026
总和 = 22429
果→苹 = 403/22429 ≈ 1.8%
果→果 = 22026/22429 ≈ 98.2%
第四步:用归一化后的权重,对所有 V 加权求和
"苹"的输出 = 0.982 × V₁ + 0.018 × V₂
= 0.982 × [6, 0.5] + 0.018 × [0.5, 6]
= [5.89, 0.49] + [0.01, 0.11]
≈ [5.90, 0.60]
"果"的输出 = 0.018 × V₁ + 0.982 × V₂
= 0.018 × [6, 0.5] + 0.982 × [0.5, 6]
= [0.11, 0.01] + [0.49, 5.89]
≈ [0.60, 5.90]发生了什么?"苹"和"果"各自主要在关注自己(98.2%),只从对方那里吸收了约 1.8% 的信息。
这不是 bug,而是 Attention 的自然规律:在词内关系中,每个 token 最需要的信息首先来自自己。"苹"的主要工作是搞清自己是"苹"而不是别的字,从"果"那里只获取"我后面的搭档是'果'"这类辅助信息。
什么时候跨 token 的注意力权重会变大?
"我买了苹果。"
这时代表"苹果"的 token 应该更多关注"买了"和"我"------"苹"和"果"之间的注意力会相对下降,因为语境词"买"的存在价值超过了字与字之间的搭配。
具体来说,如果"买"的 Key 和"苹"的 Query 高度匹配("买水果"是高频共现),"苹"给自己的权重就会从 98.2% 下降到比如 70%,把更多注意力分给"买"。
Attention 权重的分布,取决于 Q 和 K 的匹配强度------这两者都来自 Embedding 向量经过训练学到的权重矩阵。这就是它能根据上下文动态分配注意力的数学原理。
三、一个比方:图书馆找书
想象你走进一座图书馆,要找关于"量子物理"的资料。
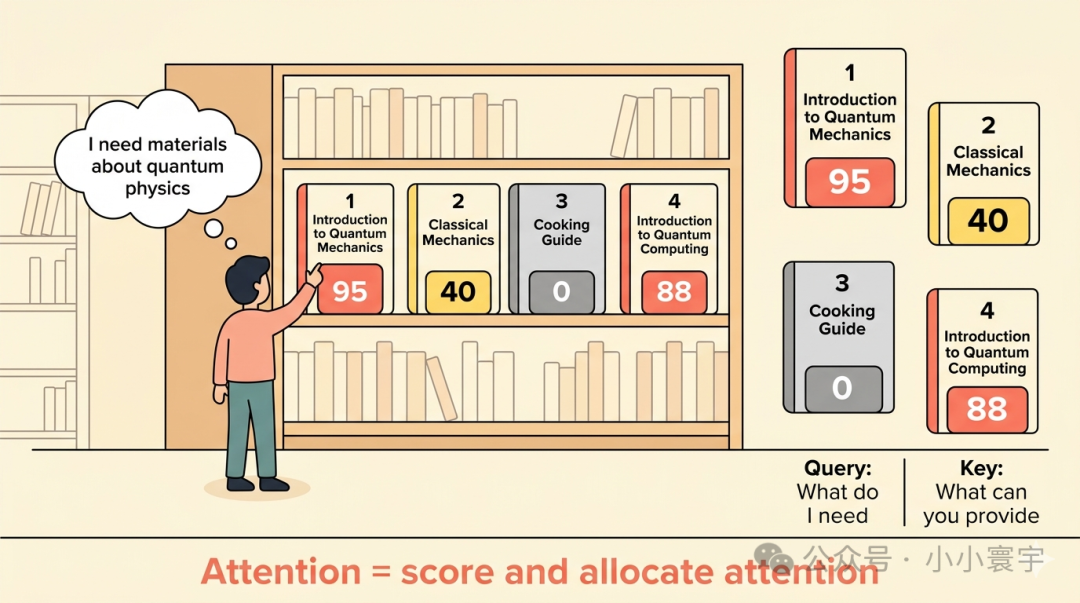
你不会把每排书架从头走到尾,把每一本书都翻一遍------太慢了。
你的大脑会自动做一件事:扫视书架标签,给每本书打分。
《量子力学入门》------95分,高度相关。
《经典力学》------40分,有点关系,但不是我要的。
《烹饪指南》------0分,完全不相关。
《量子计算导论》------88分,非常相关。
你把大部分精力花在读那几本高分书上,低分的瞟都不瞟一眼。
Attention 机制在做的事,和这完全一样:打分 和分配注意力。
每个词向上下文中的所有词发起询问:"你们跟我有什么关系?关系大的,多贡献信息;没关系的,把权重降到最低。"
同样是"苹果",在"买了一个苹果"里,它向"买"和"了一个"提问,发现自己在"购买"语义框架里;在"发布了新款 iPhone"里,它向"发布"和"iPhone"提问,发现自己在"公司发布产品"框架里。
同一个向量,通过上下文重新加权,获得了不同的含义。
四、Q、K、V:三个角色各司其职
Attention 机制的核心公式只有三步:打分、归一化、加权求和。
Attention(Q, K, V) = softmax(Q · K^T / √d) · V
Query(Q):我需要什么
每个词在某个位置产生一个 Query,向整个上下文提问:"我当前需要什么信息?"
回到图书馆的比喻:你带着一个问题走进图书馆------"我需要关于量子物理的资料"。这就是 Query。
在语言处理中,"我感冒了"里的"感冒",它产生的 Query 大约是在问:"在这个句子里,我该是什么意思?"
Key(K):我能提供什么
每个词除了发出 Query,也同时携带自己的 Key------这是它的"索引标签",代表"我能提供什么信息"。
图书馆里每本书的书脊上贴的标签,就是 Key。它告诉搜索者:这本书是关于什么的、适合什么程度的读者、涉及哪些主题。
Query 问的是"我在找什么",Key 回答的是"我能提供什么"。两者的匹配度越高,分数越高。
Value(V):匹配成功后提供什么
Key 解决了"该问谁"的问题。问到之后,真正拿到的"内容"来自 Value。
书找到了,内容是 Value。Key 告诉你这本书跟量子物理有关,Value 就是书里的实际文字、公式和图表。
在 Attention 里,Value 才是最终参与加权求和的信息载体。
完整流程:
整个过程没有循环,没有条件判断,只有矩阵乘法和 Softmax 函数。
五、为什么要三个不同的向量
Query、Key、Value 都是从同一个词的向量变过来的。为什么不能直接用原始向量做匹配?
因为同一个词在不同场景下,需要展示不同的面。
以"感谢"为例:
-
• 作为 Query:它在问"我前面有哪些词和我搭配?哪些词帮我构成了感谢的语气?"
-
• 作为 Key:它在对其他词广播"我是一个表达感谢的词"
-
• 作为 Value:它提供"感谢"的实质内容------情感强度、礼貌程度
原始 Embedding 是"感谢"的静态档案,Query 是提问者的身份,Key 是被检索标签的身份,Value 是语义实质。
六、Softmax:把分数变成关注度
打分之后,分数是一串数值。以"我买了一个苹果"为例,简化为 5 个 token:
bash
Query("苹果") 对 Key 的匹配分数:
"我" → 0.3
"买" → 0.6
"了" → 0.1
"一个" → 0.1这四个分数加起来只有 1.1,不等于 1------直接用它们做权重显然不对,但它们之间的相对大小已经表明了语义关联的强弱。"买"的分数最高,说明"苹果"在问上下文"我是谁"的时候,最需要从"买"那里获取信息。
具体该给"买"多少注意力?
Softmax 的作用是把一组分数转换成概率分布:先对每个分数取指数,再归一化:
bash
e^0.6 = 1.82
e^0.3 = 1.35
e^0.1 = 1.11
e^0.1 = 1.11
总和 = 5.39
归一化后:
"我" → 1.35 / 5.39 = 25%
"买" → 1.82 / 5.39 = 34%
"了" → 1.11 / 5.39 = 21%
"一个" → 1.11 / 5.39 = 21%这就是 Attention 的权重分配:"苹果"把 34% 的注意力给了"买",25% 给了"我","了"和"一个"各占 21%------语境词"买"拿到了最多的权重,正是因为它和"苹果"作为购买对象的语义关系最近。
为什么要取指数,而不是直接归一化(直接除以四数之和)?
关键在于比例的放大。原始分数里 0.6 和 0.3 的差值只有 0.3,比例是 2 倍;经过指数变换后,e^0.6 和 e^0.3 的差值扩大到 1.82 - 1.35 = 0.47------这个更大的绝对差值在归一化时产生了显著效果:如果直接用原始分数归一化,"买"只能拿到 0.6 / 1.1 ≈ 55%;用了指数放大后,它拿到了 34%。看起来反而少了?
这就是指数函数真正做的事:在归一化之前,把分数之间的绝对差距拉开。原本 0.6 只比 0.3 大 0.3,优势看起来微弱;e^0.6 把这个差距"翻译"成指数世界的 1.82,使得最终概率由这个更大的底数来决定。这样设计的好处是:softmax 的梯度永远不为零(指数函数光滑无零值),模型在训练时能持续收到有效的梯度信号进行学习------这个过程,和系列第二篇里语言模型预测下一个词时用的 Softmax,是同一个数学操作。
七、多头注意力:一个人读,不如十二个人读
到这里,我们讲的都是单个 Attention 的运作方式。但实际大模型里,Attention 从来不是单独运作的。
以 GPT-2 为例,每一层有 12 个注意力头,它们同时工作,各自独立地做 Attention 运算。
为什么要 12 个?因为一个角度不够。
同样读"我感冒了"这句话,不同的注意力头会关注不同的方面:
-
• 头 0 可能关注语法结构:动词和主语的关系
-
• 头 3 可能关注情感色彩:"感冒"在大陆口语里表示感兴趣
-
• 头 7 可能关注词的搭配习惯:"感冒"在中文里常见的主语搭配
没有人提前规定哪个头关注哪个方面。这是训练过程中自动形成的分工------每个头学到了一种有用的"关注模式",共同拼出对句子的完整理解。
八、n² 的代价:注意力机制的天花板
Attention 机制有一个不可忽视的局限:它的计算量随序列长度呈平方增长。
如果有 N 个 token,Attention 需要计算 N × N 个注意力分数。1000 个 token 是 100 万次计算;扩展到 10000 个 token,就是 1 亿次。长度增加 10 倍,计算量增加 100 倍。这也是长文本处理对大模型格外昂贵的原因,各种"高效 Attention"优化技术因此层出不穷。
显存也是个现实问题:10000 个 token 的 Attention 矩阵,用 FP16 格式存储需要约 200MB。这还只是一层 Attention,GPT-2 有 12 层。
上下文窗口的扩展不只是技术问题:计算要更快,显存要更大,算法要更高效,是个系统工程。
九、把 Attention 嵌入完整的链路
现在把这套机制放回完整的输入处理流程。
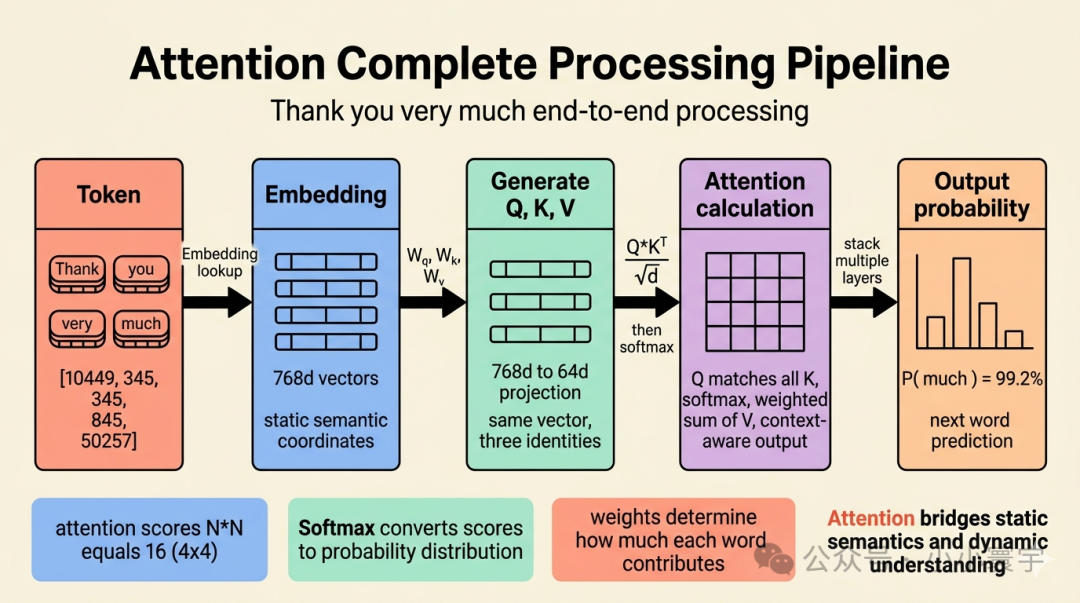
bash
"Thank you very much"
第一步:分词(Token)
["Thank", "you", "very", "much"]
→ [10449, 345, 845, 50257]
第二步:Embedding 查表
→ 向量₁, 向量₂, 向量₃, 向量₄
(每个 token 获得一个 768 维的静态语义坐标)
第三步:生成 Q、K、V
→ 每个 Embedding 向量同时乘以 W_q、W_k、W_v
→ 768 维 → 64 维投影(多头注意力的一个头)
→ 同一个向量获得三种不同的"身份投影"
第三步(续):Attention 打分与加权
→ 当前词的 Q 与上下文中所有词的 K 逐一做点积,得注意力分数
→ Softmax 把分数归一化为概率分布
→ 用这个分布对所有词的 V 加权求和
→ 输出融合了上下文信息的新向量
第四步:继续多层处理
→ 重复上述过程 N 次(GPT-2 是 12 次)
第五步:输出概率
→ P("much") = 99.2%Attention 是连接"静态语义"和"动态理解"的那座桥。没有它,模型只是在查一张固定的语义地图。有了它,模型才能根据每个词所处的上下文,动态调整它的表达含义。
十、回到那个"苹果"问题
现在回答上篇文章末尾的问题。
"苹果"在 Embedding 表里只有一个固定向量。但当模型处理"我今天买了一个苹果"这句话时:
"苹果"的 Query 向量向"买了""一个""今天"这些词的 Key 发起询问。匹配结果显示,"买"的 Key 与"苹果"的 Query 匹配度最高------购买对象和消费品在语义空间里天然接近。"苹果"的 Value 被加权求和之后,融合了"购买"这个语境信息。
当模型处理"苹果发布了新款 iPhone"时,情况完全不同。"苹果"的 Query 向量向"发布""新款""iPhone"提问,发现自己在"公司发布产品"这个框架里。iPhone 是苹果公司的产品,这是训练语料中高频出现的共现关系,被编码在了 Key 匹配的分数里。
同一个 Embedding 向量,经过 Attention 的上下文加权,输出了两种不同的语义表示。不是"苹果"这个 token 变了,而是它周围的词帮它选择了自己的含义。
十一、结语
Attention 机制的核心,说白了就是:让每个词都能看见上下文中的所有其他词,并根据相关性动态分配注意力。
没有循环,没有记忆,只有矩阵运算和概率归一化。
这个简单的机制解决了两件事:
上下文感知。 同一个词在不同语境下可以被区别对待。"苹果"是水果还是公司,"bank"是银行还是河岸------这些歧义不再无解,Attention 通过上下文加权自动完成区分。
全局视野。 在 Transformer 出现之前,RNN 处理长文本时,早期信息要经过很多层传递才能影响后期输出,距离远了信号就衰减。Attention 让每个词同时看见整个上下文,不需要逐层传递,解决了长距离依赖问题。
2017 年 Google 发表了《Attention is All You Need》这篇论文,标题出奇地准确------在之后的几年里,Attention 重塑了整个自然语言处理领域。
但 Attention 只是 Transformer 架构的一半。另一半是什么?各种"积木"是怎么组装成完整大厦的?下一篇再讲。
相关文章
-
下篇:《Transformer 全景:积木如何搭成大厦》------ FFN、残差连接与完整的模型架构
文章首发于 「小小寰宇」
