文章目录
前言
**图是一种重要的非线性数据结构,广泛应用于网络路由、社交关系、交通规划、最小生成树(MST)等场景。**在实际算法实现中,如何高效地存储图的顶点与边,直接影响程序的时间和空间性能。最经典的两种存储结构是邻接矩阵和邻接表:前者基于二维数组,以空间换时间,能够常数时间内判断两点是否相邻;后者基于链表或动态数组,以时间换空间,只存储实际存在的边。理解二者的定义、构成、特点及适用场景,是正确选用图算法(如 Prim、Kruskal、Dijkstra)的基础,也是优化图处理效率的关键所在。
一、邻接矩阵
(一)定义
用一个 N × N 的二维数组(矩阵)表示图 ,matrixij 存储从顶点 i 到顶点 j 的边的权值(无权图可存 1/0)。
(二)构成元素
一个二维数组,大小为 N×N(通常用 vector<vector>)。
有边处存权值,无边处存一个极大值(如 INF 或 0,具体视场景而定)
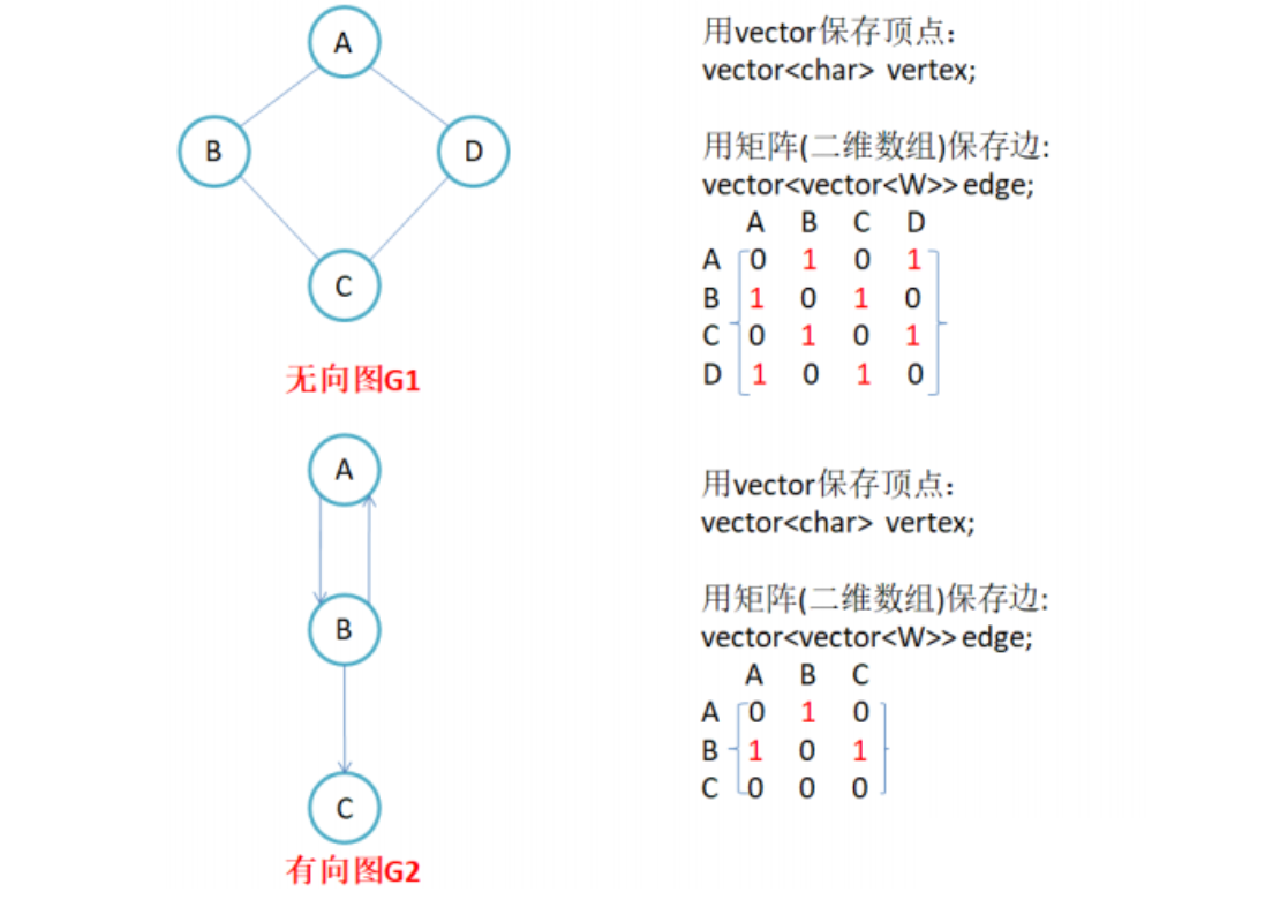
(三)特点
1.无向图
无向图的邻接矩阵是对称的,第i行(列)元素之和,就是顶点i的度(边没有权值,只存0/1的情况下,元素和就是度)
2.有向图
有向图的邻接矩阵则不一定是对称的,第i行(列)元素之和就是顶点i 的出(入)度(边没有权值,只存0/1的情况下)
(四)特别说明
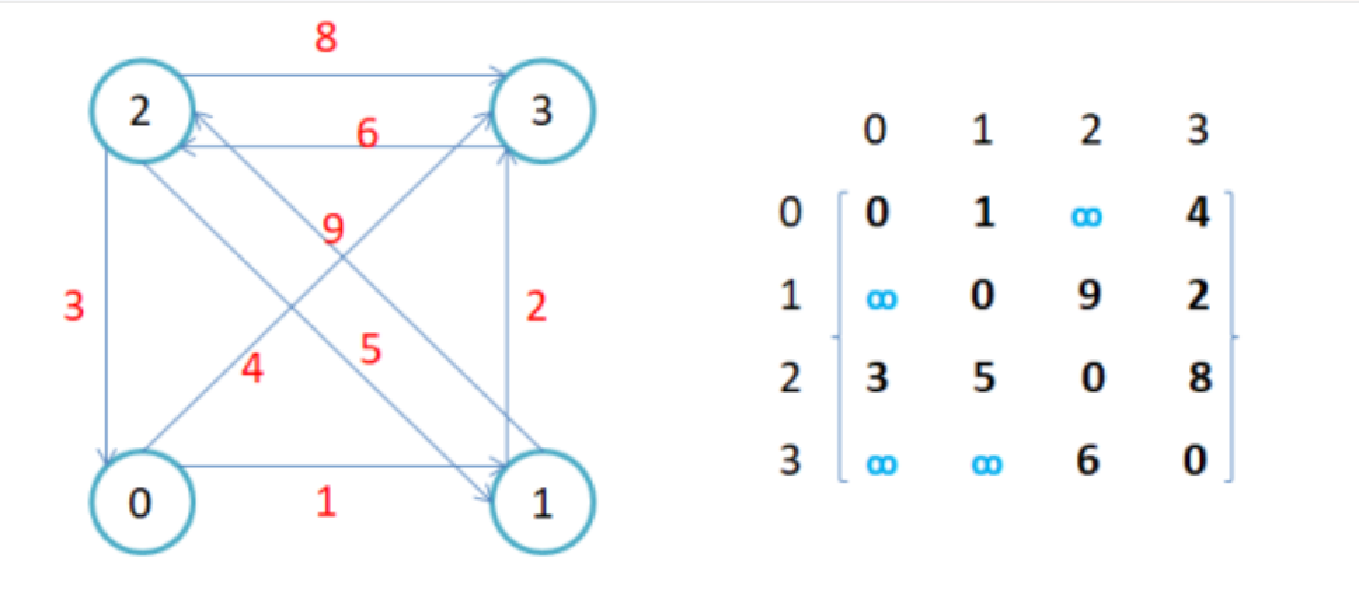
1. 带有权值的情况
如果边带有权值,并且两个节点之间是连通的,上图中的边的关系(1/0)就用权值代替,如果两个顶点不通,可以使用无穷大代替(后面我们实现的时候就要增加一个表示无穷大的模板参数)
2...优缺点
- 用邻接矩阵存储图的优点是能够快速知道两个顶点是否连通,取到权值
- 缺陷是如果顶点比较多,边比较少时,矩阵中存储了大量的0成为系数矩阵,比较浪费空间;所以邻接矩阵比较适合存储稠密图(边比较多的图),不适合存储稀疏图(边比较少的图) 而且要求两个节点之间的路径不好求; 还有求一个顶点相连的顶点有哪些也不好求(O(N),这个用邻接表结构存储的话就很好求)。
二、邻接表
(一)定义
用一个长度为 N 的数组,每个元素是一个链表或动态数组,存储该顶点的所有邻接点及边权。
(二)组成元素
一个数组(如 vector<vector<pair<int,int>>>),索引代表顶点,每个元素是一个列表 。
列表中每个条目通常是一个 (邻接点, 边权) 的二元组。
(三)分类
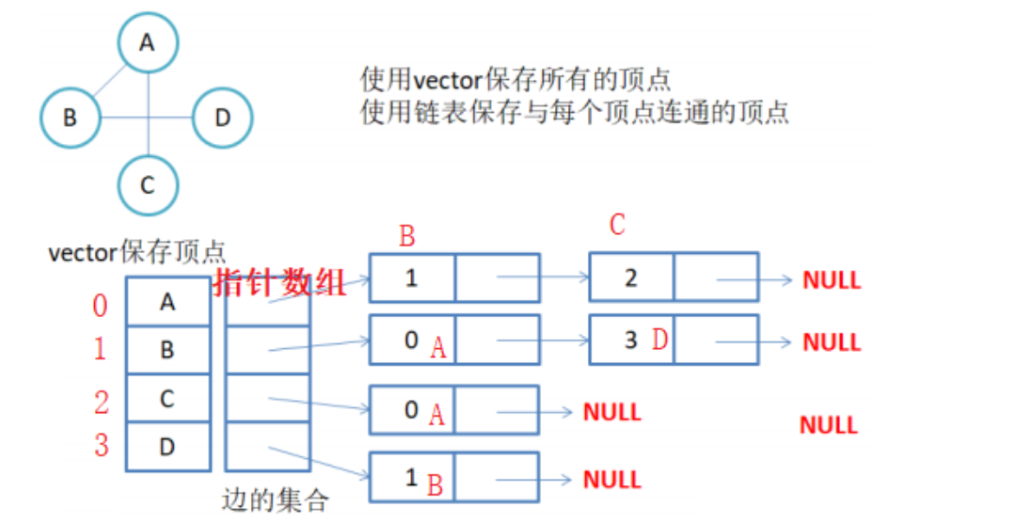
1.无向图
-
一个顶点与哪些顶点相连,相连的顶点就存到这个顶点对应的链表中,当然如果带权的话也要存上对应边的权值。 (每个顶点都有一个对应的链表,多条链表用一个指针数组就可以维护起来)
-
注意:无向图中同一条边在邻接表中出现了两次。如果想知道顶点vi的度,只需要知道顶点vi 对应链表集合中结点的数目即可
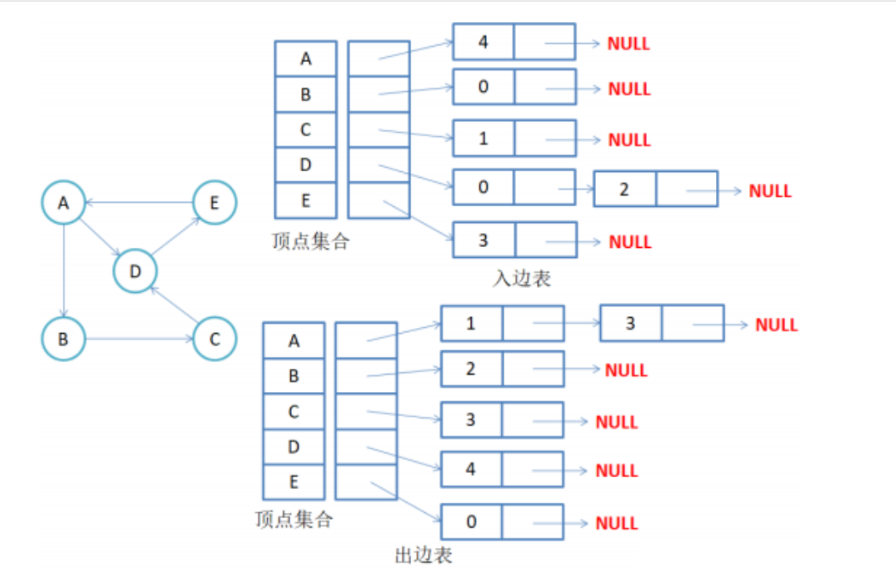
2.有向图
(四)注意
-
适合存储稀疏图(边比较少的图),因为邻接表的话有多少边链表里面就存几个对应的顶点,不需要额外的空间;而上面邻接矩阵不论边多边少都要开一个N*N的矩阵(二维数组),边少的时候那就大部分位置都存的是0
-
方便查找从一个顶点连接出去的边有哪些,因为它对应的边链表里面存的就是与这个顶点相连的顶点
-
但是不方便确定两个顶点是否相连和获取权值(要遍历其中一个顶点的边链表查找O(N)
三、邻接表和邻接矩阵的区别
(一)空间复杂度的对比
| 存储方式 | 空间复杂度 | 备注 |
|---|---|---|
| 邻接矩阵 | O(N²) | 无论实际边数多少,始终占据 N×N 空间 |
| 邻接表 | O(N + M) | 只存储实际存在的边,M 是边数 |
(二)主要操作的效率对比
| 操作 | 邻接矩阵 | 邻接表 |
|---|---|---|
查询 (u,v) 是否直接相连 |
O(1) 直接访问 matrix[u][v] |
O(degree(u)) 需遍历邻居列表找 v |
| 获取某顶点所有邻居 | O(N) 需扫描整行 | O(degree(u)) 直接读取列表 |
| 添加一条边 | O(1) | O(1) 追加到列表末尾 |
| 删除一条边 | O(1) | O(degree(u)) 需查找并删除 |
| 遍历图中所有边 | O(N²) 扫描整个矩阵 | O(N+M) 恰好扫描所有真实边 |
四、在MST中的适用场景
(一)邻接矩阵适合
稠密图(M 接近 N²)
顶点数 N 较小(例如 ≤ 1000)
需要频繁查询任意两点是否相连(如 Floyd-Warshall 算法)
在 MST 中:用于朴素 Prim 算法(O(N²)),当图很稠密时效率极高
(二)邻接表适合
稀疏图(M 远小于 N²,常见 M ≈ N 量级)
顶点数 N 很大(如 10⁵ 级别)
需要频繁遍历邻居的操作(DFS、BFS、Dijkstra、堆优化 Prim 等)
在 MST 中:用于堆优化 Prim 算法(O((N+M) log N)),Kruskal 算法甚至可只存边列表而不依赖完整邻接表
五、总结
邻接矩阵与邻接表各有优劣,不存在绝对"更好"的存储方式,只有"更适合"的场景。邻接矩阵采用 O(N²) 空间,适合顶点数较少(如 N ≤ 1000)且边稠密(M 接近 N²) 的图,其 O(1) 的边查询能力在 Floyd-Warshall 或朴素 Prim 算法中优势明显;但面对稀疏图(M 远小于 N²)时,大量空间被浪费,且遍历所有邻居需要 O(N) 开销。邻接表占用 O(N+M) 空间,更适应顶点数很大(如 10⁵ 级别)或边稀疏(M ≈ N) 的图,能高效遍历邻居(O(degree))、快速完成 BFS/DFS 和堆优化的 Dijkstra/Prim 算法;但判断两点是否直接相连需 O(degree) 时间。在最小生成树问题中,稠密图倾向采用邻接矩阵的朴素 Prim 算法,稀疏图则适用邻接表的堆优化 Prim 或纯边列表的 Kruskal 算法。实践时应根据图的规模、密度以及核心操作(查边、遍历邻居、增删边)的频率做出合理选择。