🔥 本文专栏:C++高阶数据结构
🌸作者主页:努力努力再努力wz



💪 今日博客励志语录 :
真正属于你的机会,不一定来得早,但它一定更偏爱那个一直在准备的人。
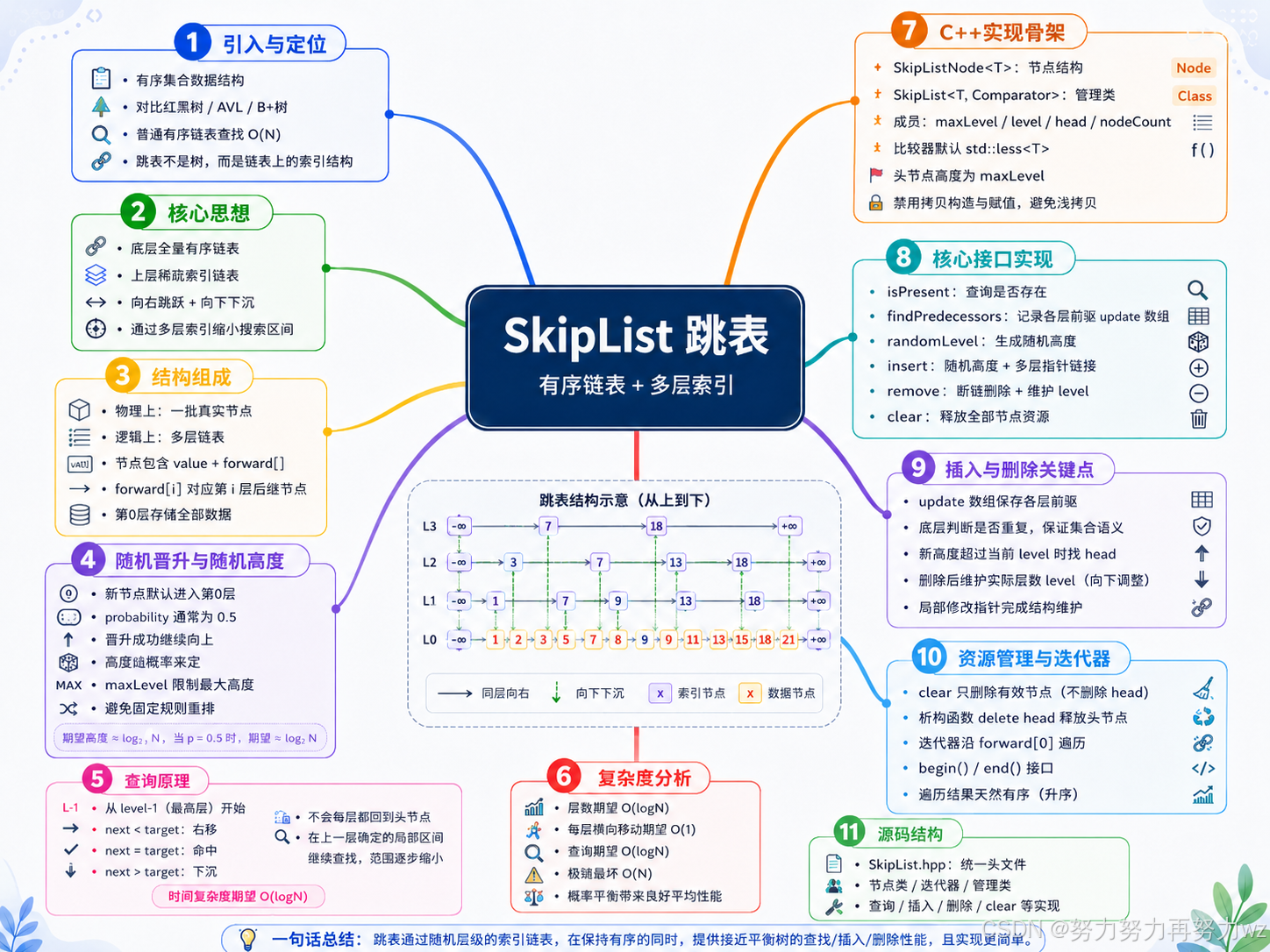
思维导图
引入
在此前的学习中,我们已经接触过多种用于维护有序数据的数据结构,比如红黑树、AVL 树以及 B+ 树等。
其中,红黑树和 AVL 树本质上都属于二叉搜索树。它们在满足"左子树节点小于根节点,右子树节点大于根节点"这一基本性质的基础上,又引入了额外的平衡约束,从而尽可能压缩树的高度,使查找、插入和删除操作能够维持在 O(logN) 级别。
而 B+ 树则更多应用在外存查找场景中。比如在 MySQL 的 InnoDB 存储引擎中,索引和数据就是通过 B+ 树来组织的。相比于普通的二叉搜索树,B+ 树是一种多路平衡搜索树,一个节点中可以存放多个 key,因此能够有效降低树的高度,减少磁盘 IO 次数。同时,B+ 树的叶子节点之间还会通过链表连接起来,因此也非常适合范围查询场景。
不过,本文要介绍的并不是上述这些树形结构,而是另一种同样可以用于维护有序集合的数据结构------跳表。
接下来,我们就正式进入跳表的学习。
跳表的结构与查询原理:多层索引如何实现高效查找
跳表的核心思想:在有序链表之上构建多层索引
在前面的学习中,我们已经知道,跳表也是一种用于维护有序集合的数据结构。
不过,跳表实现有序性的方式并不是依赖树形结构,而是建立在有序链表的基础之上。对于链表这种数据结构,我们并不陌生。一个普通单链表中的每个节点通常由数据域和指针域组成,节点之间通过指针依次串联起来。
如果我们希望使用单链表来维护一个有序集合,那么最直接的方式就是让每个节点存储一个元素,并且让这些节点按照升序排列。这样一来,链表本身就具备了有序性。
但是,普通有序链表存在一个很明显的问题:当我们需要查找某个元素,或者插入一个新元素时,都必须从头节点开始向后线性遍历,直到找到目标节点或者找到合适的插入位置。因此,普通有序链表的查找复杂度是 O(N);而插入操作虽然修改指针本身是 O(1),但是定位插入位置仍然需要 O(N) 的时间,所以整体插入复杂度也是 O(N)。
很显然,如果只是单纯使用普通有序链表,是无法实现高效查找的。
而跳表的核心改进,正是在普通有序链表的基础上增加了多层索引结构。也就是说,跳表的最底层仍然是一条完整的有序链表,用来存储所有元素;而在这条链表之上,跳表会从部分节点中抽取出一些节点,组成更高一层的索引链表。由于底层链表本身是有序的,因此从中抽取出来的索引节点也天然保持有序。
这个思想其实和我们此前学习过的 B+ 树有些相似。
对于 B+ 树来说,它是一种多路平衡搜索树,整体结构可以分为内部节点和叶子节点。内部节点并不存储完整的数据记录,而是主要存储 key 和子节点指针,用来起到导航作用;真正的数据则存储在叶子节点中。由于 B+ 树的节点大小通常会和磁盘页大小相匹配,一个节点中可以存放大量 key 和子节点指针,因此可以显著降低树的高度,从而减少磁盘 IO 次数。查找数据时,我们从根节点开始,根据内部节点中的 key 逐层向下定位,最终找到目标数据所在的叶子节点。
跳表中的索引层也可以理解为一种"导航结构"。只不过,B+ 树是通过树形结构自上而下地选择子节点,而跳表则是在链表结构上通过"向右跳跃"和"向下下沉"的方式逐步逼近目标节点。
具体来说,跳表会在底层有序链表之上建立一层索引链表;在这一层索引链表之上,还可以继续抽取部分节点,再建立更高一层的索引链表。这样一来,越往上的索引层,节点数量越少,跳跃跨度越大;越往下的链表,节点数量越多,信息越完整。最底层链表则保存所有元素。
当我们查找一个目标值时,并不会直接从底层链表的头节点开始线性遍历,而是先从最高层索引开始查找。
在当前层中,如果下一个节点的值小于目标值,说明目标节点一定还在更靠后的位置,于是继续向右移动;如果下一个节点的值等于目标值,说明查找成功;如果下一个节点的值大于目标值,说明目标值不可能出现在下一个节点之后,此时就不能继续向右移动,而应该从当前位置下沉到下一层链表中,继续进行更细粒度的查找。
也就是说,跳表的查找过程可以概括为:
next 小于目标值,就向右移动;
next 等于目标值,就查找成功;
next 大于目标值,就向下移动。
所以,跳表提升查找效率的核心思想,就是在底层有序链表的基础上,构建多层索引结构。
首先,跳表的最底层是一条完整的有序链表,用来存储所有元素。由于底层链表中的节点本身就是按照升序排列的,因此它天然能够维护数据的有序性。在此基础上,跳表会从底层链表中选取一部分节点,让这些节点额外参与更高一层的链表,从而形成索引层。接着,又可以从这一层索引节点中继续选取部分节点,让它们参与更高一层的链表。如此反复,最终就形成了多层索引结构。
例如,一个跳表的逻辑结构可以抽象成下面这样:
text
第3层索引: 80
|
第2层索引: 40 -------- 80
| |
第1层索引: 20 --- 40 --- 60 --- 80
| | | |
第0层链表: 10 -> 20 -> 30 -> 40 -> 50 -> 60 -> 70 -> 80可以看到,最底层的第 0 层链表保存了所有节点,而越往上的索引层,节点数量越少,节点之间的跨度也越大。这样在查找目标元素时,就可以先在高层索引中快速跳过大量不可能的节点,然后再逐层下沉到更低层继续查找。
从逻辑上看,跳表好像是在底层链表之上额外维护了多条索引链表;但从实现角度来看,通常并不是单独创建一批只存储指针的索引节点,而是让同一个节点维护多个 forward 指针。
也就是说,跳表中的每个节点除了保存数据之外,还会维护一个指针数组。这个指针数组中的每一个元素,都是指向后继节点的指针。不同下标位置对应不同层级的链表。
例如,对于节点 40 来说,如果它的高度为 3,那么它的内部结构可以抽象成下面这样:
text
节点 40
+-------------+
| value = 40 |
+-------------+
| forward[2] | ---> 第2层中的后继节点,比如 80
+-------------+
| forward[1] | ---> 第1层中的后继节点,比如 60
+-------------+
| forward[0] | ---> 第0层中的后继节点,比如 50
+-------------+其中,forward[0] 表示该节点在第 0 层,也就是底层全量链表中的后继节点;forward[1] 表示该节点在第 1 层索引链表中的后继节点;forward[2] 表示该节点在第 2 层索引链表中的后继节点。
因此,一个节点的高度越高,就说明它参与的索引层级越多;一个节点的高度越低,就说明它只出现在较低层的链表中。
不过,跳表的层数并不会无限增长。因为每增加一层索引,就意味着节点可能需要额外维护一个 forward 指针,这会带来额外的内存开销。同时,如果完全不限制高度,也可能出现极端情况:某个节点在随机晋升时连续成功,就像连续抛硬币都抛到了正面一样,一直向上晋升。因此,在具体实现中,跳表通常会设置一个最大高度,用来限制节点最多能够参与多少层链表。
在理解最大高度之后,我们再来看一个重要概念:节点的随机高度。
所谓随机高度,本质上就是通过概率生成出来的节点层数。当一个新节点插入跳表时,它一定会出现在第 0 层,也就是底层全量链表中。随后,跳表会通过随机判断来决定这个节点是否继续晋升到更高一层。如果晋升成功,该节点就会继续出现在第 1 层索引链表中;如果再次晋升成功,它还可以继续出现在第 2 层索引链表中。这个过程会一直持续,直到某一次晋升失败,或者节点高度已经达到跳表设置的最大高度为止。
这个过程可以类比为抛硬币:如果硬币朝正面,那么节点就继续晋升到更高一层;如果硬币朝反面,那么节点的晋升过程就停止。
例如,插入节点 50 时,它的随机晋升过程可能是下面这样:
text
第3层: 停止晋升
↑
第2层: [50] 晋升失败
↑
第1层: [50] 晋升成功
↑
第0层: [50] 新节点默认进入底层链表在这个例子中,节点 50 最终出现在第 0 层和第 1 层中,因此它的高度就是 2。也就是说,节点高度表示这个节点一共参与了多少层链表。
需要注意的是,节点高度和层下标不是一回事。如果一个节点的高度为 2,那么它参与的是第 0 层和第 1 层;如果一个节点的高度为 3,那么它参与的是第 0 层、第 1 层和第 2 层。
text
节点高度 = 3
forward[2] -> 第2层后继节点
forward[1] -> 第1层后继节点
forward[0] -> 第0层后继节点由于节点是否继续晋升是由概率决定的,所以不同节点最终得到的高度可能不同。有的节点只存在于底层链表中,有的节点则会被提升到更高层索引中。正是这种随机生成高度的方式,使跳表能够在不依赖固定位置规则的情况下,形成多层稀疏索引结构。
那么,为什么跳表不按照固定规则来选择索引节点呢?
比如,我们完全可以设想这样一种规则:在第 0 层链表中,每隔两个节点提升一个节点;在第 1 层链表中,每隔四个节点提升一个节点;或者按照奇数位置、偶数位置来决定哪些节点进入上层索引。
如果跳表只是一个只读结构,那么这种固定规则确实可以构建出比较均匀的索引层。例如:
text
第2层索引: 40 ---------------- 80
| |
第1层索引: 20 --- 40 --- 60 -------- 80
| | | |
第0层链表: 10 -> 20 -> 30 -> 40 -> 50 -> 60 -> 70 -> 80但是,跳表通常不是只读结构,它还需要支持插入和删除操作。一旦插入或者删除一个元素,底层链表中节点之间的位置关系就会发生变化。此时,原本符合固定规则、已经出现在上层索引链表中的节点,可能因为位置编号改变而不再符合规则;而原本没有出现在上层索引中的节点,也可能变成了应该被提升的节点。
比如,在底层链表中插入一个新节点 25:
text
插入前:
10 -> 20 -> 30 -> 40 -> 50 -> 60 -> 70 -> 80
插入后:
10 -> 20 -> 25 -> 30 -> 40 -> 50 -> 60 -> 70 -> 80如果索引层严格依赖"第几个节点"这种位置规则,那么插入 25 之后,后面很多节点的位置编号都会发生变化。为了继续维持固定规则,跳表就不得不重新调整索引层结构:有些节点需要从上层索引链表中删除,有些节点又需要被提升到上层索引链表中。随着链表规模增大,这种调整可能会影响大量节点,从而带来很高的维护成本。
而随机晋升的优势就在于:一个节点是否能够进入上层索引,是由它自身的随机高度决定的,而不是由它在链表中的位置决定的。换句话说,各个节点的晋升结果是相对独立的,不会因为其他节点的插入或删除而发生整体性的变化。
因此,当跳表插入一个新节点时,只需要根据这个新节点随机生成的高度,把它插入到对应层级的链表中即可;删除节点时,也只需要修改该节点参与的那些层级中的前驱指针。这样就把维护范围限制在局部,避免了固定规则索引可能带来的大规模重排问题。
跳表查询原理:向右跳跃、向下下沉与期望 O(logN)
根据前面的分析,我们已经认识了跳表的基本存储结构:跳表由底层全量有序链表和上层多级索引链表组成。底层链表负责保存所有节点,而上层索引链表则是由部分节点通过随机晋升形成的。
在理解了跳表的基本结构之后,接下来我们就进一步分析跳表中最核心的操作之一:查询操作。
由于跳表由多层链表组成,因此查询并不是直接从底层链表的头节点开始线性遍历,而是从当前跳表的最高层索引链表开始查找。
在正式分析查询过程之前,我们还需要明确一点:如果一个节点的随机高度为 n,那么这个节点会同时出现在第 0 层到第 n - 1 层中。也就是说,一个高度为 n 的节点,并不是只存在于最高层,而是从底层链表开始,连续参与了多层链表。
例如,节点 40 的高度为 3,那么它会参与第 0 层、第 1 层和第 2 层:
text
节点高度 = 3
forward[2] -> 第2层后继节点
forward[1] -> 第1层后继节点
forward[0] -> 第0层后继节点这一点非常关键,因为跳表查询过程中之所以能够从当前层向下一层下沉,本质上就是因为当前节点同时存在于更低层链表中。
需要再次强调的是,这里所谓的"索引链表",并不是额外创建出一批独立的索引节点。跳表在物理上只有一批真实节点,每个节点只保存一份数据;但是这些节点内部维护了一个 forward 指针数组,不同下标位置的指针将节点串联起来,从逻辑上形成了不同层级的链表。
也就是说:
text
forward[2] 串联起来:第2层索引链表
forward[1] 串联起来:第1层索引链表
forward[0] 串联起来:第0层全量链表因此,跳表可以理解为:
text
物理上:一批节点
逻辑上:多层链表接下来,我们来看跳表的查询过程。
假设我们要查找目标值 target,查询会从跳表最高层的头节点开始。此时我们会观察当前节点在当前层的后继节点,也就是 cur->forward[level]。
如果后继节点的值小于目标值,说明目标值还在当前节点的右侧,因此继续向右移动;如果后继节点的值等于目标值,说明查找成功;如果后继节点的值大于目标值,说明目标值不可能出现在这个后继节点之后,此时就不能继续向右移动,而应该从当前节点下沉到下一层链表中继续查找。
这个过程可以概括为:
text
next < target :向右移动
next = target :查找成功
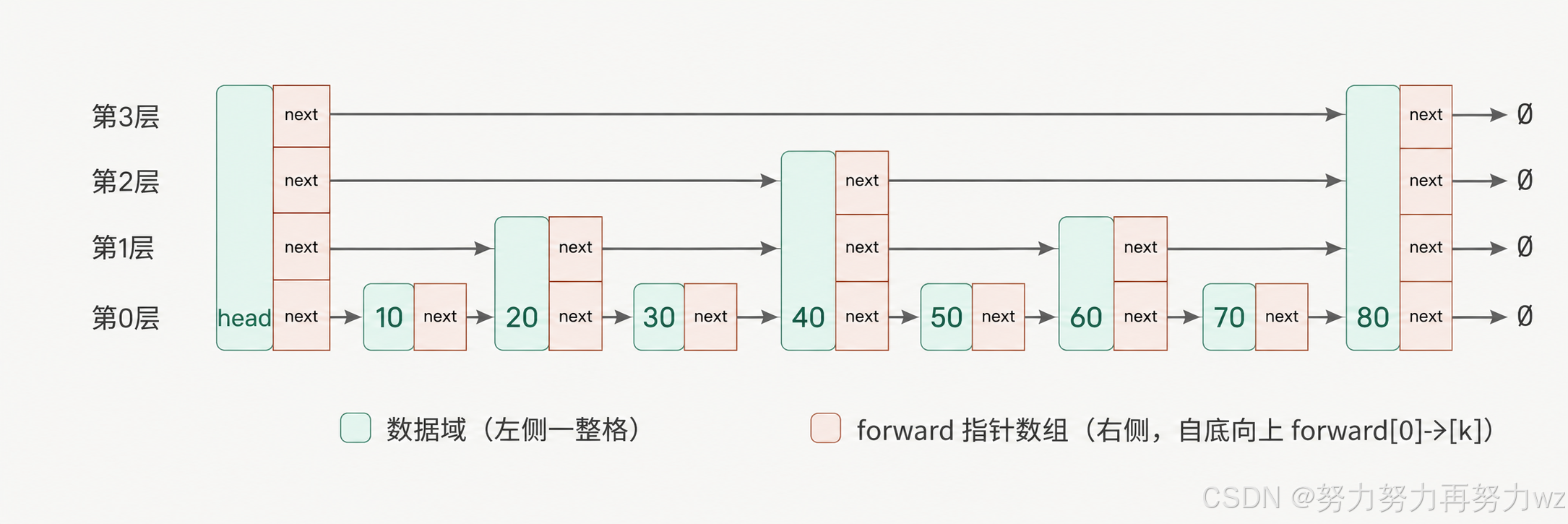
next > target :向下移动例如,假设跳表结构如下:
text
第3层索引: 80
|
第2层索引: 40 -------- 80
| |
第1层索引: 20 --- 40 --- 60 --- 80
| | | |
第0层链表: 10 -> 20 -> 30 -> 40 -> 50 -> 60 -> 70 -> 80如果我们要查找 50,查询过程大致如下:
text
第3层:head -> 80
80 > 50,不能右移,下沉
第2层:head -> 40 -> 80
40 < 50,右移到 40
80 > 50,不能右移,下沉
第1层:40 -> 60
60 > 50,不能右移,下沉
第0层:40 -> 50
50 == 50,查找成功可以看到,跳表查找目标节点的过程,本质上就是不断进行"向右跳跃"和"向下下沉"。
这里还有一个关键问题:当某一层无法继续向右移动时,为什么进入下一层之后不需要从头节点重新开始查找,而是可以直接从当前节点继续向右查找?
原因在于,跳表中的每一层链表都是有序的。当我们在某一层已经移动到当前节点时,就说明当前节点左侧的所有节点都已经小于目标值,不可能再命中目标。因此,目标值只可能出现在当前节点的右侧区间中。
例如,当我们在第 2 层已经走到节点 40,并且发现下一个节点 80 大于目标值 50 时:
text
第2层: 40 -------- 80
↑ ↑
当前节点 next此时可以确定,目标值 50 只可能出现在 40 和 80 之间。因此下沉到第 1 层或者第 0 层时,就没有必要再从头节点重新开始,而是可以直接从节点 40 继续向右查找。
这也是跳表提升查找效率的核心原因。
如果只遍历底层有序链表,那么每次只能跨过一个节点:
text
第0层链表:10 -> 20 -> 30 -> 40 -> 50 -> 60 -> 70 -> 80而跳表在上层维护了稀疏索引链表,上层相邻节点之间的跨度更大,因此一次右移就可以跳过底层的大量节点。查找时,跳表会先在高层索引中进行大跨度跳跃,快速缩小目标值可能所在的区间;当无法继续大跨度跳跃时,再下沉到更低层链表中,以更小的跨度继续查找。
也就是说,跳表的查找过程可以理解为:
text
高层索引:节点少,跨度大,负责快速缩小范围
低层索引:节点多,跨度小,负责进一步细化范围
底层链表:保存全量数据,负责最终确认目标是否存在因此,跳表并不是单纯地减少了底层链表的节点数量,而是通过多层索引结构,让查找过程可以不断跳过不可能的区间。
索引链表的稀疏程度和节点晋升概率有关。如果晋升概率越大,节点越容易进入更高层索引,那么上层索引链表中的节点就越密集;如果晋升概率越小,节点越不容易进入更高层索引,那么上层索引链表就越稀疏。
在很多跳表实现中,晋升概率通常会选择 0.5,也就是类似抛硬币的概率。这样一来,从期望角度来看,每一层的节点数量大约是下一层的一半:
text
第0层:N 个节点
第1层:N / 2 个节点
第2层:N / 4 个节点
第3层:N / 8 个节点
...因此,跳表的层数期望大约是 O(logN)。
不过这里需要注意,跳表的索引层是随机生成的,所以我们不能说每一层的节点数量严格等于下一层的一半,而只能说在期望意义下大致符合这个规律。
同样地,跳表的查找复杂度通常也是从期望角度分析的。由于跳表的高度期望为 O(logN),并且查找过程中每一层横向移动的次数在期望上是常数级的。
这里还需要进一步解释一下:为什么说跳表在查询过程中,每一层横向移动的次数在期望上是常数级的?
所谓"常数级",并不是说每一层最多只能横向移动 1 次或者 2 次,而是指在随机晋升的平均效果下,每一层横向移动的次数不会随着数据规模 N 的增大而增大。
也就是说,当跳表进入某一层之后,平均情况下并不会在这一层横向遍历很多节点,而是大概走少量几个节点之后,就会继续向下层下沉。比如当 N = 1000 时,某一层平均可能横向移动 2 次左右;当 N = 1000000 时,平均横向移动次数也仍然是一个较小的固定数量,而不会变成几千次或者几万次。
为什么会这样呢?
假设节点晋升到上一层的概率是 0.5,也就是类似抛硬币的概率。那么从期望角度来看,每一层的节点数量大约是下一层的一半:
text
第0层:N 个节点
第1层:N / 2 个节点
第2层:N / 4 个节点
第3层:N / 8 个节点
...换句话说,在下一层链表中,平均每隔少量几个节点,就会有一个节点出现在上一层索引链表中。因此,当查找过程从上一层下沉到下一层时,下一层中两个上层索引节点之间的间隔,在期望上并不会特别大,而是一个常数级别的区间。
例如:
text
第2层: 20 -------- 50 -------- 80
| | |
第1层: 20 -- 30 -- 50 -- 60 -- 80假设我们在第 2 层已经走到节点 20,并且发现下一个节点 50 已经大于目标值,于是查找过程会下沉到第 1 层。此时并不会从第 1 层的头节点重新开始查找,而是直接从节点 20 开始,在 20 和 50 之间继续向右遍历:
text
第1层: 20 -- 30 -- 50
↑
从这里继续由于节点晋升到上一层的概率通常取 0.5,因此从期望上看,当前层中大约每隔少量几个节点,就会有一个节点出现在上一层索引链表中。
而跳表在查找过程中,每次从上一层下沉到当前层时,并不是从当前层的头节点重新开始遍历,而是在上一层已经确定出来的两个相邻索引节点之间继续查找。也就是说,当前层的横向遍历范围,实际上被限制在上一层相邻节点所划分出来的局部区间中。
由于这个局部区间的长度在期望上是常数级的,所以跳表在每一层中的横向移动次数,在期望意义下也是常数级的。
从整体上看,跳表的高度在期望上是 O(logN),而每一层横向移动次数在期望上是 O(1),因此一次查询的总路径长度就是:
text
跳表高度:O(logN)
每层横向移动次数:O(1)
总查找路径长度:
O(logN) × O(1) = O(logN)因此,跳表查询操作的期望时间复杂度是 O(logN)。这里的关键点在于:跳表不是每一层都从头开始扫描,而是在上一层已经缩小出来的区间内继续查找;并且由于随机晋升使索引层保持合理的稀疏程度,所以每一层需要横向移动的节点数量在期望上是常数级的。
示意图
C++ 实现跳表:从结构设计到核心接口完整实现
C++ 实现跳表:节点结构与整体骨架设计
根据前面的分析,我们已经理解了跳表的核心思想:跳表通过底层全量有序链表保存所有数据,同时利用上层稀疏索引链表加速查找过程。
在理解了跳表的原理之后,接下来我们就尝试使用 C++ 来实现一个简单的跳表结构。这里的实现思路是:先确定跳表的整体骨架以及相关成员变量,然后再逐步实现跳表的核心接口,例如随机高度生成、查询、插入和删除等操作。
首先需要明确的是,跳表虽然在逻辑上可以看成由"底层链表 + 多级索引链表"组成,但它并不是为每一层索引都单独创建一批节点。更准确地说,跳表在物理上只有一批真实节点,每个节点只保存一份数据;而这些节点内部会维护一个 forward 指针数组,不同下标位置的指针将节点串联起来,从而在逻辑上形成不同层级的链表。
也就是说:
text
物理上:一批真实节点
逻辑上:多层链表结构
实现上:每个节点维护一个 forward 指针数组因此,我们首先需要定义跳表的节点结构。由于跳表中存储的数据类型不一定固定,所以节点类应该设计成模板类。节点内部主要包含两部分:一个是数据域 value,用于保存当前节点的值;另一个是 forward 指针数组,用于保存当前节点在不同层级中的后继节点指针。
cpp
template<typename T>
class SkipListNode
{
public:
SkipListNode(int level, const T& value)
: value(value)
, forward(level, nullptr)
{}
public:
T value;
std::vector<SkipListNode<T>*> forward;
};其中,构造函数中的 level 表示当前节点的高度,也就是该节点参与了多少层链表。比如一个节点的高度为 3,那么它的 forward 数组大小就是 3,分别对应第 0 层、第 1 层和第 2 层中的后继节点指针。
text
节点高度 = 3
forward[2] -> 第2层后继节点
forward[1] -> 第1层后继节点
forward[0] -> 第0层后继节点定义完节点结构之后,接下来就可以定义跳表本身。
由于 C++ 是一门面向对象语言,因此我们可以使用一个 SkipList 类来描述整个跳表结构。需要注意的是,SkipList 类本身并不直接存储所有数据,真正的数据存储在各个节点中。SkipList 类主要负责保存跳表的管理信息,例如最大高度、当前实际高度、节点个数、头节点以及比较器等。
同时,为了让跳表能够支持不同类型的数据,SkipList 也应该设计成模板类。除了数据类型 T 之外,还需要额外引入一个比较器类型 Comparator。这是因为跳表需要根据元素大小关系来维护有序性,而对于自定义类型来说,不一定能够直接使用内置的 < 运算符进行比较。
因此,模板参数可以设计成下面这样:
cpp
template<typename T, typename Comparator = std::less<T>>
class SkipList
{
// ...
};如果用户在实例化 SkipList 对象时没有显式传入自定义比较器,那么 Comparator 就会使用默认的 std::less<T>。
std::less<T> 本质上是一个仿函数对象,它重载了 operator()。该运算符重载函数会接收两个参数 a 和 b,其作用就是判断 a 是否小于 b。可以简单理解为,其内部逻辑类似于:
cpp
return a < b;因此,对于内置类型来说,std::less<T> 会直接按照对应类型的 < 运算符进行比较;而如果 T 是自定义类型,那么这里就要求该类型支持 < 运算符重载。此时,std::less<T> 在比较两个对象时,实际调用的就是该类中定义的 < 运算符重载函数。
接下来给出跳表类的基本骨架:
cpp
#include <vector>
#include <functional>
#include <cstddef>
template<typename T>
class SkipListNode
{
public:
SkipListNode(int level, const T& value)
: value(value)
, forward(level, nullptr)
{}
public:
T value;
std::vector<SkipListNode<T>*> forward;
};
template<typename T, typename Comparator = std::less<T>>
class SkipList
{
public:
using Node = SkipListNode<T>;
SkipList(int maxLevel = 32, float probability = 0.5f, Comparator comp = Comparator())
: maxLevel(maxLevel)
, level(1)
, head(nullptr)
, nodeCount(0)
, comp(comp)
, probability(probability)
{
head = new Node(maxLevel, T());
}
//....
SkipList(const SkipList&) = delete;
SkipList& operator=(const SkipList&) = delete;
private:
int maxLevel; // 跳表允许的最大高度
int level; // 当前跳表的实际层数
Node* head; // 头节点,作为每一层链表的入口
size_t nodeCount; // 当前跳表中的有效节点个数
Comparator comp; // 比较器,用于维护节点之间的有序关系
float probability; // 节点晋升到上一层的概率
};这里对几个成员变量做一下说明。
maxLevel 表示跳表允许的最大高度。由于跳表的层数不能无限增长,否则会带来额外的指针开销,因此通常需要设置一个最大高度。
level 表示当前跳表的实际层数。初始化时跳表中还没有有效数据节点,因此只需要保留第 0 层,所以这里将其初始化为 1。
head 表示跳表的头节点。头节点本身不用于存储有效数据,而是作为每一层链表的入口。正因为头节点需要能够访问所有层级的链表,所以它的 forward 数组大小需要初始化为 maxLevel。
nodeCount 用来记录当前跳表中的有效节点个数。
comp 是比较器对象,用于决定节点之间的有序关系。由于跳表本质上是一个有序结构,因此无论是查询、插入还是删除,都需要借助比较器来判断节点值之间的大小关系。
probability 表示节点晋升到上一层的概率。比如当 probability = 0.5 时,就可以理解为每个节点有一半概率继续晋升到更高一层。
接下来重点看一下 SkipList 的构造函数:
cpp
SkipList(int maxLevel = 32, float probability = 0.5f, Comparator comp = Comparator())
: maxLevel(maxLevel)
, level(1)
, head(nullptr)
, nodeCount(0)
, comp(comp)
, probability(probability)
{
head = new Node(maxLevel, T());
}这个构造函数一共接收三个参数:maxLevel、probability 和 comp。
其中,maxLevel 表示跳表允许的最大高度,用来限制索引层级的数量,避免节点无限向上晋升;probability 表示节点晋升到上一层的概率,默认值为 0.5,也就是类似抛硬币的概率;comp 表示比较器对象,用来决定节点之间的大小关系,从而维护跳表的有序性。
这三个参数都提供了缺省值,因此用户在实例化 SkipList 对象时,可以直接使用默认配置:
cpp
SkipList<int> list;此时跳表的最大高度默认为 32,节点晋升概率默认为 0.5,比较器默认使用 std::less<int>。
在构造函数的初始化列表中,首先会初始化跳表的管理信息。maxLevel 保存跳表允许的最大高度;level 初始化为 1,表示当前跳表至少包含第 0 层;head 先初始化为空指针;nodeCount 初始化为 0,表示当前还没有有效数据节点;comp 和 probability 分别保存比较器和晋升概率。
构造函数体内部则会申请头节点:
cpp
head = new Node(maxLevel, T());这里需要注意,头节点本身并不存储有效数据,它的作用是作为每一层链表的入口。由于头节点需要能够访问跳表中的所有层级,所以头节点的高度必须设置为 maxLevel。这样一来,头节点内部的 forward 指针数组大小也会被初始化为 maxLevel,并且数组中的每个指针都会被初始化为空指针。
也就是说,构造函数完成之后,跳表虽然还没有存储任何有效数据节点,但是它的基本管理信息和头节点结构已经初始化完成,后续的查询、插入和删除操作都可以从这个头节点开始执行。
此外,还需要注意的是,由于跳表内部管理了动态申请的节点资源,为了避免默认拷贝构造和赋值运算导致浅拷贝问题,这里直接禁用了拷贝构造函数和赋值运算符。
到这里,跳表的节点结构以及整体管理类的骨架就已经搭建完成了。接下来,我们就可以继续实现跳表中的核心接口,例如随机高度生成函数、查询函数、插入函数以及删除函数。
跳表查询接口实现:isPresent 函数的查找逻辑
接下来,我们首先关注跳表的查询函数 isPresent 的实现。
isPresent 函数接收一个目标值 value,返回值类型为 bool。它的作用是判断目标值是否存在于当前跳表中:如果存在,则返回 true;如果不存在,则返回 false。
在实现查询函数之前,需要先明确一个细节:虽然跳表中设置了最大高度 maxLevel,但是当前跳表的实际高度并不一定能够达到 maxLevel。maxLevel 只是跳表允许的最大高度,而 level 才表示当前跳表实际使用到的层数。
也就是说,当前跳表的最高层并不是 maxLevel - 1,而是 level - 1。因此,查询时应该从头节点的 forward[level - 1] 开始,也就是从当前跳表实际存在的最高层开始向后遍历。
查询过程本质上仍然遵循前面分析过的规则:从最高层开始,能向右就向右,不能向右就向下。
具体来说,假设当前节点为 current,当前所在层数为 i,那么当前层的后继节点就是:
cpp
current->forward[i]如果当前层的后继节点存在,并且后继节点的值小于目标值 value,说明目标值还在右侧,因此继续向右移动:
cpp
current = current->forward[i];如果当前层的后继节点等于目标值,说明查找成功,直接返回 true。
如果当前层的后继节点大于目标值,说明当前层已经不能继续向右移动,此时就需要下沉到下一层,也就是让层数 i 减一,然后重复同样的查找过程。
这里还需要注意比较方式。由于我们的跳表是一个模板类,并且支持用户传入自定义比较器,所以在比较节点值时,不应该直接写死使用 < 或者 ==。判断大小关系时,应该使用比较器 comp;判断两个值是否相等时,也可以通过比较器间接推导。
如果 a 不小于 b,并且 b 也不小于 a,那么就可以认为二者在当前比较规则下相等:
cpp
!comp(a, b) && !comp(b, a)因此,isPresent 函数可以实现如下:
cpp
bool isPresent(const T& value) const
{
if(nodecount==0)
{
return false;
}
Node* current=head;
for(int i=level-1;i>=0;i--)
{
while(current->forward[i] && comp(current->forward[i]->value,value))
{
current=current->forward[i];
}
if(current->forward[i] && !comp(current->forward[i]->value,value) && !comp(value,current->forward[i]->value))
{
return true;
}
}
return false;
}这段代码中,外层 for 循环负责从当前跳表的最高层一路向下遍历到底层链表;内层 while 循环负责在当前层中不断向右移动,直到当前层的后继节点为空,或者后继节点的值不再小于目标值。
当内层循环结束时,说明当前层已经无法继续向右移动。此时如果当前层的后继节点刚好等于目标值,就说明查找成功,返回 true;否则外层循环会继续向下一层查找。
如果从最高层一直查找到第 0 层,仍然没有找到目标值,那么就说明该元素不存在于跳表中,最终返回 false。
所以,isPresent 函数的核心逻辑可以概括为:
text
next < value :继续向右移动
next = value :查找成功
next > value :下沉到下一层需要注意的是,查询过程中 current 并不会在每一层都重新回到头节点,而是从当前节点直接下沉到下一层继续查找。正因为如此,跳表能够借助上层索引快速缩小搜索范围,从而在期望意义下实现 O(logN) 的查询效率。
跳表插入接口实现:update 数组、随机高度与多层挂接
认识了跳表的查询操作之后,接下来我们再来分析跳表的插入操作。
跳表的插入函数同样会接收一个目标值 value,其功能就是将该值插入到跳表中。不过,跳表的插入并不能只找到第 0 层链表中的直接前驱节点。原因在于,新节点插入之后,不一定只出现在底层链表中,它还可能根据随机高度出现在多层索引链表中。
比如一个新节点的随机高度为 4,那么它就需要同时插入到第 0 层、第 1 层、第 2 层和第 3 层中。此时,如果我们只知道它在第 0 层中的前驱节点,就无法完成更高层索引链表中的指针挂接。
因此,插入操作的关键在于:在定位插入位置的过程中,同时记录每一层中目标值的前驱节点。
为此,我们可以使用一个 update 数组来保存这些前驱节点。数组下标对应跳表的层级,update[i] 表示新节点在第 i 层中的前驱节点。其中,update[0] 表示底层全量链表中的前驱节点,update[1] 表示第 1 层索引链表中的前驱节点,以此类推。
这个过程本质上和查询操作类似,都是从当前跳表的最高层开始向右移动,并在无法继续向右时下沉到下一层。不同的是,查询操作只关心目标值是否存在,而插入操作还需要在每一层下沉之前记录当前节点,因为这个当前节点就是目标值在该层中的前驱节点。
因此,我们可以单独封装一个 findPredecessors 函数,用来查找并返回各层的前驱节点:
cpp
std::vector<Node*> findPredecessors(const T& value) const
{
std::vector<Node*> update(maxLevel, nullptr);
Node* current = head;
for (int i = level - 1; i >= 0; --i)
{
while (current->forward[i] && comp(current->forward[i]->value, value))
{
current = current->forward[i];
}
update[i] = current;
}
return update;
}这段代码中,外层 for 循环依然是从当前跳表的最高层 level - 1 开始,逐层向下查找。内层 while 循环负责在当前层中不断向右移动,直到当前层的后继节点为空,或者后继节点的值不再小于目标值 value。
当内层循环结束时,说明当前层已经无法继续向右移动。此时,current 就是目标值在当前层中的前驱节点,因此将其记录到 update[i] 中。
需要注意的是,这里的"前驱节点"不是单纯指第 0 层链表中的物理前驱节点,而是指目标值在每一层链表中的前驱节点:
text
update[0] -> 第0层中的前驱节点
update[1] -> 第1层中的前驱节点
update[2] -> 第2层中的前驱节点
...有了 update 数组之后,我们就可以进一步判断待插入的值是否已经存在。
由于跳表中要求元素不重复,因此插入前需要进行去重判断。常规做法是先调用一次查询函数判断元素是否存在,如果不存在再执行插入。但这样会导致插入前后重复进行两次查找。
这里可以采用更直接的方式:因为 update[0] 已经记录了目标值在底层全量链表中的前驱节点,而第 0 层保存了所有数据,所以我们只需要检查 update[0] 的后继节点是否等于目标值即可。
cpp
Node* next = current->forward[0];
if(next && !comp(next->value, value) && !comp(value, next->value))
{
return;
}如果第 0 层前驱节点的后继节点刚好等于目标值,就说明该值已经存在于跳表中,直接返回即可,不需要重复插入。
在确认目标值不存在之后,接下来就需要为新节点生成随机高度。这里可以单独定义一个 randomLevel 函数:
cpp
int randomLevel()
{
int newlevel=1;
while(newlevel<maxLevel)
{
if(rand()/double(RAND_MAX)<probability)
{
newlevel++;
}else
{
break;
}
}
return newlevel;
}新节点默认至少会出现在第 0 层,因此初始高度为 1。随后,通过 rand() 生成一个随机数,并将其转换到 [0, 1] 范围内。如果该随机数小于晋升概率 probability,就说明晋升成功,节点高度加一;否则晋升失败,停止继续向上提升。
这个过程会一直持续,直到某一次晋升失败,或者新节点高度已经达到 maxLevel 为止。
当随机高度生成之后,就可以创建新节点,并将其挂接到跳表对应层级中:
cpp
void insert(const T& value)
{
std::vector<Node*> update(maxLevel, nullptr);
Node* current=head;
for(int i=level-1;i>=0;i--)
{
while(current->forward[i] && comp(current->forward[i]->value,value))
{
current=current->forward[i];
}
update[i]=current;
}
Node* next = current->forward[0];
if(next && !comp(next->value, value) && !comp(value, next->value))
{
return;
}
int newlevel=randomLevel();
// 如果新节点高度超过当前跳表高度,高出来的层前驱都是 head
if(newlevel > level)
{
for(int i = level; i < newlevel; i++)
{
update[i] = head;
}
level = newlevel;
}
Node* newNode=new Node(newlevel,value);
for(int i=0;i<newlevel;i++)
{
Node* next=update[i]->forward[i];
update[i]->forward[i]=newNode;
newNode->forward[i]=next;
}
nodecount++;
return;
}这段插入逻辑可以分为几个步骤来看。
首先,通过 findPredecessors(value) 查找目标值在各层中的前驱节点,并保存到 update 数组中。
接着,通过 update[0]->forward[0] 判断目标值是否已经存在。如果已经存在,就直接返回,避免重复插入。
然后,调用 randomLevel() 生成新节点的随机高度 newLevel。如果 newLevel 大于当前跳表的实际层数 level,说明新节点会成为更高层索引链表中的第一个有效节点。对于这些新增层来说,新节点的前驱节点都应该是头节点 head,因此需要将对应层的 update[i] 设置为 head,并更新跳表当前实际层数 level。
最后,创建新节点,并根据 update 数组逐层修改指针。对于第 i 层来说,新节点需要插入到 update[i] 和 update[i]->forward[i] 之间,因此指针修改过程如下:
cpp
newNode->forward[i] = update[i]->forward[i];
update[i]->forward[i] = newNode;这个过程和普通单链表插入节点的指针修改类似,只不过跳表中一个节点可能参与多层链表,因此需要在每一层都执行一次类似的挂接操作。
所以,跳表插入操作的核心可以总结为:
text
1. 查找每一层中的前驱节点,并保存到 update 数组中
2. 通过第 0 层前驱节点的后继节点判断是否重复
3. 生成新节点的随机高度
4. 如果新节点高度超过当前跳表高度,则补充高层前驱为 head
5. 创建新节点,并在对应层级中修改 forward 指针
6. 更新跳表节点数量可以看到,跳表插入操作并不是只在底层链表中插入一个节点,而是根据新节点的随机高度,将其同时插入到多层链表中。而 update 数组正是实现这一点的关键,它保存了新节点在每一层中的前驱节点,使得插入操作可以通过局部修改指针完成。
跳表删除接口实现:update 数组、指针断开与高度维护
认识了跳表的插入操作之后,接下来我们再来分析跳表的删除操作。
删除操作的功能是从跳表中删除指定元素值对应的节点。不过,跳表的删除并不是只在物理上释放目标节点这么简单。因为一个节点可能同时参与多层链表,所以删除目标节点之前,还需要先修改该节点在各层链表中的前驱节点指针,让这些前驱节点直接绕过目标节点,指向目标节点原来的后继节点。
也就是说,如果目标节点出现在第 0 层、第 1 层和第 2 层,那么删除时就需要分别修改这几层中的前驱节点指针:
text
update[0]->forward[0] 需要跳过目标节点
update[1]->forward[1] 需要跳过目标节点
update[2]->forward[2] 需要跳过目标节点因此,删除操作和插入操作类似,也需要先调用 findPredecessors 函数,找到目标值在每一层中的前驱节点,并将这些前驱节点保存到 update 数组中。
拿到 update 数组之后,可以通过第 0 层前驱节点的后继节点来判断目标值是否存在。因为第 0 层链表保存了跳表中的所有节点,所以如果目标值存在,那么它一定会出现在第 0 层中。
如果 target 为空,或者 target 的值不等于目标值,就说明跳表中不存在该元素,直接返回即可。
如果目标节点存在,那么接下来就需要根据目标节点的高度,逐层修改前驱节点的 forward 指针。由于目标节点的 forward 数组长度就是它的随机高度,所以可以通过 target->forward.size() 得到目标节点参与的层数。
删除某一层中的目标节点时,指针修改逻辑如下:
cpp
update[i]->forward[i] = target->forward[i];这句代码的含义是:让第 i 层中的前驱节点不再指向目标节点,而是直接指向目标节点在第 i 层中的后继节点。这样一来,目标节点就从第 i 层链表中被断开了。
对应的删除函数可以实现如下:
cpp
void remove(const T& value)
{
if (nodecount == 0)
{
return;
}
std::vector<Node*> update = findPredecessors(value);
Node* target = update[0]->forward[0];
if(target!= nullptr && !comp(target->value, value) && !comp(value, target->value))
{
size_t targetLevel = target->forward.size();
for (size_t i = 0; i < targetLevel; ++i)
{
update[i]->forward[i] = target->forward[i];
}
delete target;
--nodecount;
while (level > 1 && head->forward[level - 1] == nullptr)
{
--level;
}
}
}这段代码的整体流程可以分为几步。
首先,如果当前跳表为空,直接返回。
接着,通过 findPredecessors(value) 找到目标值在各层中的前驱节点,并保存到 update 数组中。
然后,通过 update[0]->forward[0] 定位到底层链表中可能的目标节点。由于第 0 层保存了所有数据,所以只需要判断这个节点是否存在,并且值是否等于目标值,就可以确定待删除元素是否存在于跳表中。
如果目标节点存在,就根据目标节点的高度,遍历它参与的每一层。在第 i 层中,如果 update[i]->forward[i] 确实指向目标节点,就让它直接指向 target->forward[i],从而将目标节点从这一层链表中断开。
等所有层级的指针关系都修改完成之后,才可以真正释放目标节点:
cpp
delete target;
--nodeCount;最后,还需要更新跳表的实际高度 level。
这是因为删除节点之后,最高层索引链表可能会变空。比如当前最高层只有一个有效节点,而这个节点刚好被删除了,那么此时:
cpp
head->forward[level - 1] == nullptr就说明当前最高层已经没有有效节点了。此时需要不断降低 level,直到找到一个仍然存在有效节点的层,或者最终降到第 0 层为止。
cpp
while (level > 1 && head->forward[level - 1] == nullptr)
{
--level;
}所以,跳表删除操作的核心可以总结为:
text
1. 通过 findPredecessors 找到各层前驱节点
2. 通过第 0 层前驱节点的后继节点判断目标是否存在
3. 如果目标存在,则在目标节点参与的每一层中修改前驱节点的 forward 指针
4. 释放目标节点,并更新节点数量
5. 如果最高层索引链表变空,则更新跳表的实际高度可以看到,跳表删除操作和插入操作一样,核心都离不开 update 数组。插入时,update 数组用于确定新节点在各层中的插入位置;删除时,update 数组则用于找到目标节点在各层中的前驱节点,从而完成局部指针修改。
clear 清空函数与析构函数:释放节点资源并重置跳表状态
接下来,我们再实现跳表的 clear 函数。
clear 函数的作用是清空跳表中的所有有效数据节点。需要注意的是,头节点 head 本身并不存储有效数据,它只是作为各层链表的入口,因此 clear 函数只需要释放头节点之后的所有普通节点,而不需要释放头节点本身。
由于第 0 层链表保存了跳表中的所有节点,所以清理节点时,只需要沿着第 0 层链表依次向后遍历即可。遍历过程中,需要先记录当前节点的后继节点,然后再释放当前节点,否则一旦当前节点被 delete,就无法继续访问它的后继节点了。
代码实现如下:
cpp
void clear()
{
if(nodecount==0)
{
return;
}
Node* current=head->forward[0];
while(current)
{
Node* next=current->forward[0];
delete current;
current=next;
}
for(int i = 0; i < maxLevel; ++i)
{
head->forward[i] = nullptr;
}
level = 1;
nodecount = 0;
}这段代码中,current 首先指向第 0 层链表中的第一个有效节点。随后在循环中不断记录 next 节点,释放当前节点,并让 current 继续向后移动,直到所有有效节点都被释放。
当所有节点释放完成后,还需要将头节点的 forward 指针数组全部置空。因为普通节点虽然已经被释放,但头节点中的部分 forward 指针之前仍然可能指向这些节点,如果不清空,就会留下悬空指针。
最后,将跳表的实际层数 level 重置为 1,表示当前跳表只保留第 0 层;同时将节点个数 nodeCount 重置为 0,表示跳表中已经没有有效数据节点。
有了 clear 函数之后,析构函数就可以直接复用它。因为 clear 只负责释放普通数据节点,不会释放头节点,所以析构函数中还需要额外释放 head:
cpp
~SkipList()
{
clear();
delete head;
}这样一来,当 SkipList 对象生命周期结束时,析构函数会先释放所有有效数据节点,再释放头节点本身,从而避免动态申请的节点内存发生泄漏。
跳表迭代器实现:沿第 0 层链表完成有序遍历
由于跳表本质上是一个有序结构,因此除了提供查询、插入和删除操作之外,我们还可以为跳表定义一个迭代器,用来按照有序顺序遍历跳表中的所有元素。
虽然跳表在逻辑上由多层链表组成,但需要注意的是,只有第 0 层链表保存了全部数据节点。上层索引链表只是由部分节点组成,用来加速查找。如果迭代器沿着上层索引链表遍历,就会跳过很多没有出现在该层的节点,导致遍历结果不完整。
因此,跳表迭代器的遍历逻辑应该非常明确:始终沿着第 0 层链表向后移动。也就是说,迭代器每次执行自增操作时,都应该让当前指针移动到 forward[0] 指向的下一个节点。
基于这个思路,我们可以定义一个 SkipListIterator 类。该类内部保存一个指向当前节点的指针 current,并通过重载 operator*、operator++ 和 operator!= 来支持基本的迭代器操作。
代码实现如下:
cpp
template<typename T>
class SkipListIterator
{
public:
SkipListIterator(SkipListNode<T>* node)
:current(node)
{
}
T& operator*() const
{
return current->value;
}
SkipListIterator& operator++()
{
current=current->forward[0]; // 移动到最底层的下一个节点
return *this;
}
bool operator!=(const SkipListIterator& other) const
{
return current!=other.current;
}
private:
SkipListNode<T>* current;
};这里的 current 指针表示迭代器当前指向的节点。
当我们对迭代器进行解引用时,也就是调用 operator*,就会返回当前节点中保存的 value 值:
cpp
T& operator*() const
{
return current->value;
}当我们对迭代器执行前置 ++ 操作时,就会让 current 沿着第 0 层链表移动到下一个节点:
cpp
current = current->forward[0];这里再次强调,迭代器必须沿着 forward[0] 遍历。因为 forward[0] 串联的是底层全量链表,只有这一层包含跳表中的所有元素。
而 operator!= 用于判断两个迭代器是否指向同一个节点:
cpp
bool operator!=(const SkipListIterator& other) const
{
return current != other.current;
}定义完迭代器类之后,还需要在 SkipList 类中为该迭代器取一个别名,并提供 begin 和 end 函数:
cpp
public:
using Iterator = SkipListIterator<T>;
Iterator begin()
{
return Iterator(head->forward[0]);
}
Iterator end()
{
return Iterator(nullptr);
}其中,begin 函数返回第 0 层链表中第一个有效节点对应的迭代器,也就是 head->forward[0];而 end 函数返回一个空迭代器,用 nullptr 表示遍历结束位置。
这样一来,我们就可以像遍历普通容器一样遍历跳表:
cpp
SkipList<int> list;
list.insert(30);
list.insert(10);
list.insert(20);
for (auto it = list.begin(); it != list.end(); ++it)
{
std::cout << *it << " ";
}由于跳表底层链表本身就是有序的,因此遍历结果也是有序的:
text
10 20 30所以,跳表迭代器的核心并不复杂。它不需要关心上层索引链表,只需要沿着第 0 层链表依次向后移动即可。因为第 0 层保存了跳表中的全部数据节点,而上层索引只是用来加速查询的辅助结构。
源码
SKipList.hpp:
cpp
#pragma once
#include<iostream>
#include<vector>
#include<functional>
#include<cstdlib>
#include<ctime>
template<typename T>
class SkipListNode
{
public:
SkipListNode(int level, const T& value)
: value(value)
{
forward.resize(level, nullptr);
}
T value;
std::vector<SkipListNode<T>*> forward;
};
/**
* 跳表迭代器类模板
* T 跳表中存储的数据类型
*/
template <typename T>
class SkipListIterator
{
public:
/**
* 构造函数
* node 指向跳表节点的指针
*/
SkipListIterator(SkipListNode<T>* node)
:current(node) // 初始化当前节点指针
{
}
/**
* 重载解引用运算符
* 返回当前节点的值引用
*/
T& operator*() const
{
return current->value;
}
/**
* 重载前置++运算符
* 返回迭代器的引用
* 移动到最底层的下一个节点
*/
SkipListIterator& operator++()
{
current=current->forward[0]; // 移动到最底层的下一个节点
return *this;
}
/**
* 重载不等于运算符
* other 另一个迭代器对象
* 如果当前节点指针不等于另一个迭代器的节点指针,返回true,否则返回false
*/
bool operator!=(const SkipListIterator& other) const
{
return current!=other.current;
}
private:
SkipListNode<T>* current; // 指向当前节点的指针
};
template<typename T,typename Comparator =std::less<T>>
class SkipList
{
public:
using Node= SkipListNode<T>;
using Iterator=SkipListIterator<T>;
SkipList(int _maxLevel=32, float _probability=0.5, Comparator comp = Comparator())
: maxLevel(_maxLevel)
, level(1)
, head(nullptr)
, nodecount(0)
, comp(comp)
, probability(_probability)
{
head = new Node(maxLevel, T());
}
~SkipList()
{
clear();
delete head;
}
void insert(const T& value)
{
// 1. 准备工作:记录每一层插入位置的前驱节点
// update[i] 表示在第 i 层中,新节点应该插入在 update[i] 之后
std::vector<Node*> update(maxLevel, nullptr);
Node* current = head; // 从跳表的头节点开始遍历
// 2. 查找插入位置:从最高层开始查找,逐层下降
for(int i = level - 1; i >= 0; i--)
{
// 在当前层向右查找,直到找到第一个大于或等于 value 的节点的前驱
// comp(a, b) 通常是一个比较器(如 std::less),comp(a, b) 为真表示 a < b
while(current->forward[i] && comp(current->forward[i]->value, value))
{
current = current->forward[i]; // 当前节点的值比 value 小,继续向右移动
}
// 退出 while 循环时,current->forward[i] 要么为空,要么 >= value
// 此时 current 就是第 i 层中插入新节点的直接前驱
update[i] = current;
}
// 3. 检查值是否已存在(跳表通常不允许插入重复键值)
// 因为上面的循环结束在第 0 层的插入前驱位置,所以检查第 0 层的下一个节点即可
Node* next = current->forward[0];
// 如果 next 存在,且 next->value 既不小于 value,value 也不小于 next->value
// 这意味着 next->value == value(严格弱序下的等价判断)
if(next && !comp(next->value, value) && !comp(value, next->value))
{
return; // 值已存在,跳过插入,直接返回
}
// 4. 随机生成新节点的高度(层数)
// 跳表的核心特性:通过随机层数来维持概率性平衡
int newlevel = randomLevel();
// 5. 处理新节点层数超过当前跳表最大层数的情况
if(newlevel > level)
{
// 高出来的这些层(从原 level 到 newlevel-1),目前没有任何节点
// 所以新节点在这些层的前驱节点只能是 head
for(int i = level; i < newlevel; i++)
{
update[i] = head;
}
// 更新跳表当前的 最大层数
level = newlevel;
}
// 6. 创建新节点
Node* newNode = new Node(newlevel, value);
// 7. 核心插入操作:逐层修改指针,将新节点插入到跳表中
for(int i = 0; i < newlevel; i++)
{
// 经典的链表插入两步曲(在第 i 层进行):
// 1. newNode 的 forward[i] 指向原前驱节点的后继
Node* next = update[i]->forward[i];
newNode->forward[i] = next;
// 2. 原前驱节点的 forward[i] 指向 newNode
update[i]->forward[i] = newNode;
// 注意:上面两行也可以简写为:
// newNode->forward[i] = update[i]->forward[i];
// update[i]->forward[i] = newNode;
}
// 8. 节点计数加一
nodecount++;
return;
}
bool isPresent(const T& value) const
{
// 优化:如果跳表中没有节点,直接返回 false,避免不必要的空指针判断
if(nodecount == 0)
{
return false;
}
// 从跳表的头节点开始遍历
Node* current = head;
// 从最高层开始向下搜索,逐层下降
for(int i = level - 1; i >= 0; i--)
{
// 在当前层向右移动:
// 只要当前节点的右指针不为空,且右节点的值严格小于 value,就继续向右走
while(current->forward[i] && comp(current->forward[i]->value, value))
{
current = current->forward[i];
}
// 退出 while 循环时,说明当前层的下一个节点要么为空,要么 >= value
// 检查当前层的下一个节点是否就是我们要找的 value
// 逻辑与 insert 相同:既不小于 value,value 也不小于它,即两者等价
if(current->forward[i] && !comp(current->forward[i]->value, value) && !comp(value, current->forward[i]->value))
{
// 找到精确匹配,直接返回 true
return true;
}
// 如果当前层没找到,循环会自动让 i-- 降到下一层继续寻找
}
// 遍历完所有层(直到最底层的第 0 层)都没有找到等价的值,说明元素不存在
return false;
}
void remove(const T& value)
{
// 1. 边界检查:如果跳表为空,无需删除,直接返回
if (nodecount == 0)
{
return;
}
// 2. 查找前驱节点:
// 调用 findPredecessors 获取每一层中值小于 value 的最大节点(即前驱节点)
// update[i] 记录了在第 i 层中,待删除节点的前一个节点
std::vector<Node*> update = findPredecessors(value);
// 3. 定位待删除节点:
// 因为第 0 层包含所有节点,所以待删除节点一定是第 0 层前驱节点的直接后继
Node* target = update[0]->forward[0];
// 4. 判断节点是否存在:
// 如果 target 存在,且 target->value 与 value 等价(既不小于也不大于,即相等)
if(target != nullptr && !comp(target->value, value) && !comp(value, target->value))
{
// 获取待删除节点的层数,决定了我们需要修改多少层的指针
size_t targetLevel = target->forward.size();
// 5. 核心删除操作:逐层修改指针,将 target 从链表中摘除
for (size_t i = 0; i < targetLevel; ++i)
{
// 经典的链表删除操作:让前驱节点直接跨过 target,指向 target 的后继
// 相当于:update[i]->forward[i] = target->forward[i];
update[i]->forward[i] = target->forward[i];
}
// 6. 释放内存,防止内存泄漏
delete target;
// 7. 节点计数减一
--nodecount;
// 8. 维护跳表的最大层数 level:
// 如果删除的是最高层的节点,且最高层已经没有其他节点了,需要降低跳表的总层数
// 这是为了避免跳表层数无限增长,维持结构的紧凑性
while (level > 1 && head->forward[level - 1] == nullptr)
{
--level; // 当前最高层为空,层数减 1,继续检查下一层
}
}
// 如果 target 为空或者值不相等,说明要删除的值不存在,什么都不做
}
void clear()
{
// 1. 优化:如果跳表已经为空,直接返回,避免无意义的操作
if(nodecount == 0)
{
return;
}
// 2. 遍历并删除所有数据节点
// 核心技巧:跳表的第 0 层(最底层)是一个包含所有节点的完整有序链表。
// 因此,我们只需要像遍历普通单链表一样,沿着第 0 层遍历即可访问到所有节点,
// 而不需要逐层去删除,这大大简化了清空逻辑并保证了 O(N) 的时间复杂度。
Node* current = head->forward[0]; // 获取第 0 层的头节点的下一个节点(即第一个真实数据节点)
while(current)
{
// 先保存当前节点的下一个节点指针,因为删除当前节点后,将无法通过它获取下一个节点
Node* next = current->forward[0];
// 释放当前节点占用的堆内存,防止内存泄漏
delete current;
// 移动到下一个节点继续处理
current = next;
}
// 3. 重置头节点的所有前向指针
// 此时所有数据节点已被 delete,但头节点 head 仍然存在于栈或堆上(取决于实现)。
// 必须将 head 的所有层的前向指针置为 nullptr,防止出现悬空指针。
for(int i = 0; i < maxLevel; ++i)
{
head->forward[i] = nullptr;
}
// 4. 重置跳表的状态变量
level = 1; // 当前层数重置为初始值 1(通常跳表默认只有最底层)
nodecount = 0; // 节点计数归零
}
Iterator begin() const
{
return Iterator(head->forward[0]);
}
Iterator end() const
{
return Iterator(nullptr);
}
bool empty() const
{
return nodecount==0;
}
size_t size() const
{
return nodecount;
}
int maxlevel() const
{
return maxLevel;
}
int currentlevel() const
{
return level;
}
SkipList(const SkipList&) = delete;
SkipList& operator=(const SkipList&) = delete;
private:
/**
* 查找指定值在跳表中的所有前驱节点
* value 要查找的值
* return 包含各层前驱节点指针的向量
*/
std::vector<Node*> findPredecessors(const T& value) const
{
// 初始化更新向量,用于存储各层的前驱节点指针
// 向量大小为跳表的最大层级,初始值为nullptr
std::vector<Node*> update(maxLevel, nullptr);
// 从跳表的最高层开始查找,逐层向下
Node* current=head;
for(int i=level-1;i>=0;i--)
{
// 在当前层中向右移动,直到找到第一个大于或等于目标值的节点
// comp函数用于比较节点值和目标值的大小关系
while(current->forward[i] && comp(current->forward[i]->value,value))
{
// 向右移动指针
current=current->forward[i];
}
// 记录当前层的前驱节点
update[i]=current;
}
return update;
}
/**
* 随机生成跳表节点的层级
* 返回随机生成的层级,范围在1到maxLevel之间
*/
int randomLevel()
{
// 初始化新层级为1,因为跳表至少有第一层
int newlevel=1;
// 当当前层级小于最大允许层级时,继续尝试提升层级
while(newlevel<maxLevel)
{
// 以一定概率决定是否提升层级
// 使用rand()函数生成0到1之间的随机数,与预设概率比较
if(rand()/double(RAND_MAX)<probability)
{
// 如果随机数小于预设概率,则层级加1
newlevel++;
}else
{
// 否则终止循环,不再提升层级
break;
}
}
// 返回最终生成的随机层级
return newlevel;
}
int maxLevel;
int level;
Node* head;
size_t nodecount;
Comparator comp;
float probability;
};
test.cpp:
cpp
#include <iostream>
#include <ctime>
#include <cstdlib>
#include "SkipList.hpp"
int main()
{
std::srand((unsigned int)std::time(nullptr));
SkipList<int> list(8, 0.5f);
std::cout << "===== SkipList Test Start =====" << std::endl;
std::cout << "Initial state:" << std::endl;
std::cout << "Empty: " << (list.empty() ? "true" : "false") << std::endl;
std::cout << "Size: " << list.size() << std::endl;
std::cout << "Max level: " << list.maxlevel() << std::endl;
std::cout << "Current level: " << list.currentlevel() << std::endl;
std::cout << std::endl;
std::cout << "Insert values: 30, 10, 50, 20, 40, 30" << std::endl;
list.insert(30);
list.insert(10);
list.insert(50);
list.insert(20);
list.insert(40);
list.insert(30); // duplicate value, should not be inserted again
std::cout << "After insertion:" << std::endl;
std::cout << "Empty: " << (list.empty() ? "true" : "false") << std::endl;
std::cout << "Size: " << list.size() << std::endl;
std::cout << "Current level: " << list.currentlevel() << std::endl;
std::cout << "Elements in order: ";
for (auto it = list.begin(); it != list.end(); ++it)
{
std::cout << *it << " ";
}
std::cout << std::endl << std::endl;
std::cout << "Search test:" << std::endl;
std::cout << "Contains 10: " << (list.isPresent(10) ? "true" : "false") << std::endl;
std::cout << "Contains 30: " << (list.isPresent(30) ? "true" : "false") << std::endl;
std::cout << "Contains 35: " << (list.isPresent(35) ? "true" : "false") << std::endl;
std::cout << "Contains 50: " << (list.isPresent(50) ? "true" : "false") << std::endl;
std::cout << std::endl;
std::cout << "Remove value 10." << std::endl;
list.remove(10);
std::cout << "Elements after removing 10: ";
for (auto it = list.begin(); it != list.end(); ++it)
{
std::cout << *it << " ";
}
std::cout << std::endl;
std::cout << "Size: " << list.size() << std::endl;
std::cout << "Contains 10: " << (list.isPresent(10) ? "true" : "false") << std::endl;
std::cout << std::endl;
std::cout << "Remove value 30." << std::endl;
list.remove(30);
std::cout << "Elements after removing 30: ";
for (auto it = list.begin(); it != list.end(); ++it)
{
std::cout << *it << " ";
}
std::cout << std::endl;
std::cout << "Size: " << list.size() << std::endl;
std::cout << "Contains 30: " << (list.isPresent(30) ? "true" : "false") << std::endl;
std::cout << std::endl;
std::cout << "Remove missing value 999." << std::endl;
list.remove(999);
std::cout << "Elements after trying to remove 999: ";
for (auto it = list.begin(); it != list.end(); ++it)
{
std::cout << *it << " ";
}
std::cout << std::endl;
std::cout << "Size: " << list.size() << std::endl;
std::cout << std::endl;
std::cout << "Clear the skip list." << std::endl;
list.clear();
std::cout << "After clear:" << std::endl;
std::cout << "Empty: " << (list.empty() ? "true" : "false") << std::endl;
std::cout << "Size: " << list.size() << std::endl;
std::cout << "Current level: " << list.currentlevel() << std::endl;
std::cout << "Elements after clear: ";
for (auto it = list.begin(); it != list.end(); ++it)
{
std::cout << *it << " ";
}
std::cout << std::endl << std::endl;
std::cout << "Reinsert values: 7, 3, 9" << std::endl;
list.insert(7);
list.insert(3);
list.insert(9);
std::cout << "Elements after reinsertion: ";
for (auto it = list.begin(); it != list.end(); ++it)
{
std::cout << *it << " ";
}
std::cout << std::endl;
std::cout << "Size: " << list.size() << std::endl;
std::cout << "Empty: " << (list.empty() ? "true" : "false") << std::endl;
std::cout << "===== SkipList Test End =====" << std::endl;
return 0;
}运行截图:
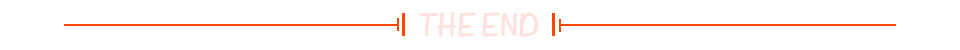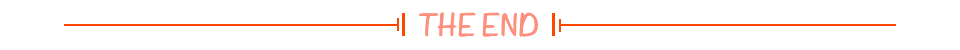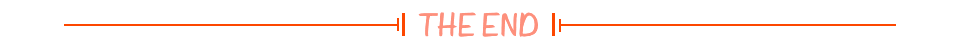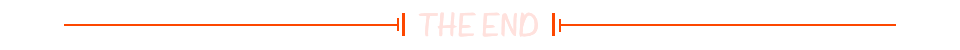
结语
那么这就是本篇文章的全部内容,带你掌握以及实现时间轮,我会持续更新,希望你能够多多关注,如果本文有帮助到你的话,还请三连加关注,你的支持就是我创作的最大动力!
