一、二叉树的表示
前面我们讲过了二叉树的顺序表示(堆),现在来看一下如何用链式结构表示二叉树。
要储存二叉树,就要存储各个节点,每个节点包含该节点的值和指向左右子树的指针
cpp
typedef int BTDataType;
typedef struct BinaryTreeNode
{
BTDataType data;
struct BinaryTreeNode* left;
struct BinaryTreeNode* right;
}BTNode;二、二叉树的遍历
二叉树的遍历方式主要分为两大类:深度优先遍历(DFS) 和 广度优先遍历(BFS)
1.深度优先遍历(DFS)
| 遍历方式 | 访问顺序 | 应用举例 |
|---|---|---|
| 前序遍历(Preorder) | 根 → 左子树 → 右子树 | 复制树、前缀表达式求值 |
| 中序遍历(Inorder) | 左子树 → 根 → 右子树 | 二叉搜索树(BST)可得到有序序列 |
| 后序遍历(Postorder) | 左子树 → 右子树 → 根 | 释放树节点、后缀表达式求值 |
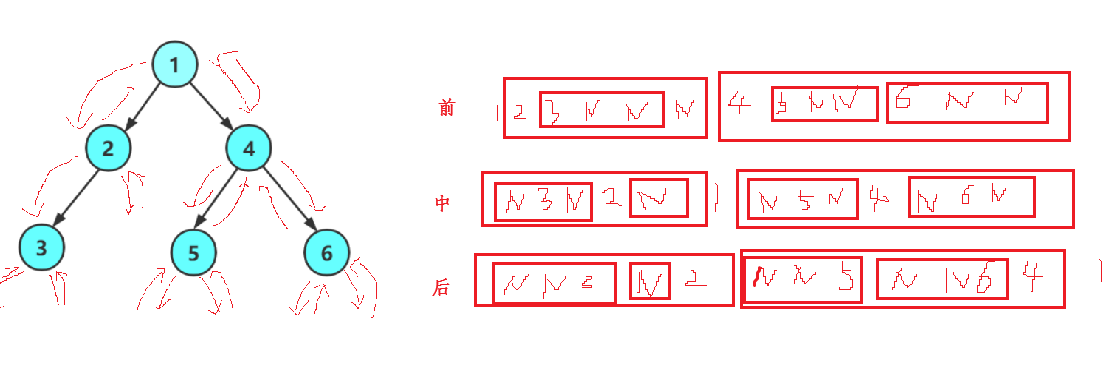
(1)前序遍历
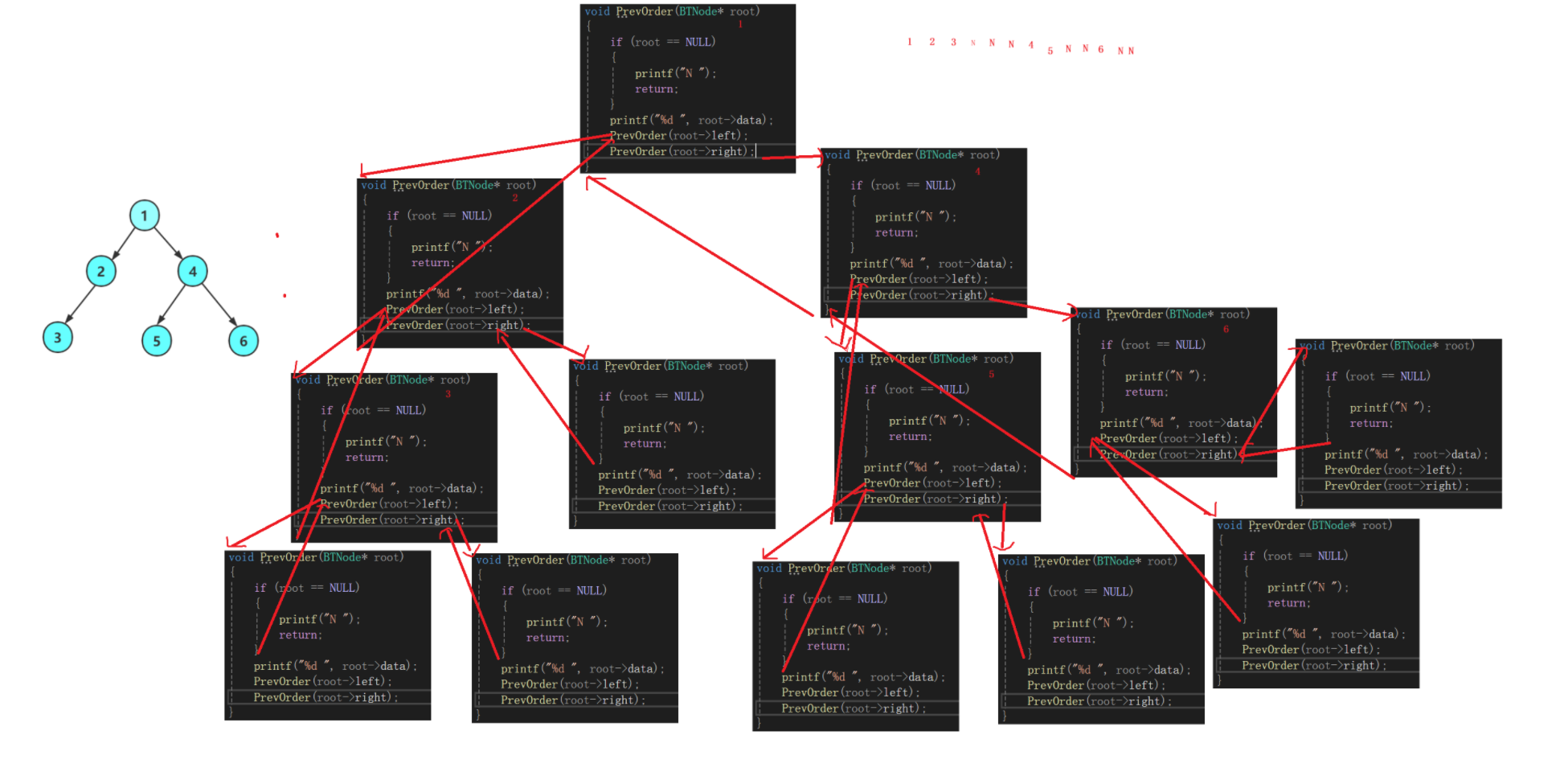
这里详细展示前序遍历过程
cpp
void PrevOrder(BTNode* root)
{
if (root == NULL)
{
printf("N ");
return;
}
printf("%d ", root->data);
PrevOrder(root->left);
PrevOrder(root->right);
}按照红色箭头执行,前序遍历二叉树的逻辑过程
-
逻辑上:每个函数调用都有自己"独立"的栈帧,互不干扰。
-
物理上 :系统会高效重用已释放的栈内存,从而避免频繁分配/释放物理页,提升性能。
-
这种重用对程序员透明,不需要(也不能)主动控制。
(2)中序遍历
cpp
void InOrder(BTNode* root)
{
if (root == NULL)
{
printf("N ");
return;
}
InOrder(root->left);
printf("%d ", root->data);
InOrder(root->right);
}(3)后序遍历
cpp
void PostOrder(BTNode* root)
{
if (root == NULL)
{
printf("N ");
return;
}
PostOrder(root->left);
PostOrder(root->right);
printf("%d ", root->data);
}2.广度优先遍历(BFS)
三、二叉树的节点计算
1.树的节点总数
树的节点总数的计算,类似统计全校在校师生个数,让校长一个一个计数,计算起来是很麻烦的,也不可能用这种方式实现,应该从最底层开始计数,让每一层上报。
若为空,则返回0,否则就返回左子树与右子树节点个数之和+1。
cpp
int TreeSize(BTNode* root)
{
if (root == NULL)
{
return 0;
}
return TreeSize(root->left) + TreeSize(root->right) + 1;
}2.树的叶子节点数
若root==NULL,则返回0,若该节点指向左右子树的指针都为空,则返回1,否则返回左子树节点数+右子树节点数
cpp
int TreeSizeLeaf(BTNode* root)
{
if (root == NULL)
{
return 0;
}
if (root->left == NULL && root->right == NULL)
{
return 1;
}
return TreeSizeLeaf(root->left) + TreeSizeLeaf(root->right);
}3.树的层数
如果root==NULL,返回0,否则返回左右子树中较大的层数+1
cpp
int TreeHeihgt(BTNode* root)
{
if (root == NULL)
{
return 0;
}
return TreeHeihgt(root->left) > TreeHeihgt(root->right) ? TreeHeihgt(root->left) + 1 : TreeHeihgt(root->right) + 1;
}但其实这样没有记录每次算出来的层数,会重复执行多次,当数据量较大的时候,效率会低,应该用变量将其记录下来
cpp
int TreeHeihgt(BTNode* root)
{
if (root == NULL)
{
return 0;
}
int leftHeight = TreeHeihgt(root->left);
int rightHeight = TreeHeihgt(root->right);
return leftHeight> rightHeight ? leftHeight + 1 : rightHeight + 1;
}四、递归调用的本质
-
代码只有一份 :函数的机器指令存储在内存的代码段中,每次调用(包括递归调用)都是执行同一段指令。
-
数据不同 :每次调用会创建新的栈帧(stack frame),其中存放:
-
参数(如当前节点指针)
-
局部变量
-
返回地址(决定了递归返回后继续执行的指令位置)
-
-
结果不同:正是由于栈帧中的数据不同(例如当前遍历到的节点不同),同一份指令才会产生不同的执行效果和最终结果。
一个形象的类比
就像一本烹饪书(一份指令),不同的人(不同的栈帧数据)按照同样的步骤做菜,但因为各自拿到的食材不同(参数不同),做出来的菜自然不同。做菜时,每人都有自己的操作台(栈帧),互不干扰。
补充一点:返回地址也是"数据"
"压进栈的数据"不仅包括参数和局部变量,还包括返回地址。返回地址决定了函数执行完毕后该回到哪里继续执行。即便都是调用同一个递归函数,每次调用返回后会回到调用点下一行代码,这个控制流差异也是依靠栈帧中保存的返回地址实现的。