
一、软件环境
-
Cent OS 7.9 官方下载地址:CentOS-7-x86_64-DVD-2009.iso
-
Hadoop 3.1.1 官方下载地址:Hadoop 3.1.1
-
Hive 3.1.0 官方下载地址:Hive 3.1.0
-
PostgreSQL 16.13 官方下载地址:PostgreSQL 16.13(用于存储hive的无数据)
-
BiSheng-jdk-8u482-b13 官方下载地址: BiSheng-jdk-8u482-b13 (可用openjdk或oracle jdk替代)
-
NTP 官方下载地址:ntp-4.2.6p5-29.el7.centos.x86_64 (非必需,但稳定运行需要)
-
Zookeeper-3.8.6 官方下载地址: Zookeeper-3.8.6 (非必需,但高可用集群需要)
二、Hadoop集群安装
# 3台机器
10.21.**.184 master.hadoop
10.21.**.185 slave1.hadoop
10.21.**.186 slave2.hadoop
所有步骤使用root用户执行
第一步:上传hadoop压缩包
略。可使用FileZilla
第二步:解压hadoop压缩包
解压++++hadoop-3.1.1.tar.gz++++ 解压到++++/usr++++
说明:如果只是为了演示或学习可不做高可用集群,只做普通集群,
普通集群$HADOOP_HOME/etc/hadoop/core-site.xml中可以不配zookeeper
即:/usr/hadoop-3.1.1/etc/hadoop/core-site.xml
第三步:更改主机名称
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master.hadoop
#HOSTNAME=slave1.hadoop
#HOSTNAME=slave2.hadoop
查看主机名 hostname(文件修改后没有重启主机名没有生效,可以用hostname临时生效)
hostname master.hadoop
hostname slave1.hadoop
hostname slave2.hadoop
第四步:建立主机名和ip的映射
vi /etc/hosts
10.21.**.184 master.hadoop
10.21.**.185 slave1.hadoop
10.21.**.186 slave2.hadoop
IP修改为实际三台机器的IP
第五步:配置root用户ssh免密钥登录
略
第六步:关闭防火墙
bash
systemctl stop firewalld 第七步:安装JDK
安装jdk1.8
第八步:安装postgresql(建意安排在主节点)
安装PostgreSQL 16.13 ,端口:5432
略。
第九步:设置时区
三台主机执行都要执行下面的命令
bash
timedatectl set-timezone Asia/Shanghai第十步:安装时间同步服务(NTP)
三台需要安装
yum install ntp
修改配置
vi /etc/ntp.conf
时间服务使用一台就行
server master.hadoop iburst
启停
bash
systemctl start ntpd
systemctl status ntpd
# 同步时间,ip为ntp服务地址
ntpdate 10.21.**.**说明:
在 Hadoop 3.1.1 集群中,强烈建议配置 NTP 时间同步服务,尤其是在生产环境或内网环境中。虽然从技术上讲,不配置 NTP Hadoop 也能启动,但时间不同步会导致严重的数据一致性问题和任务执行错误
第十一步:添加环境变量
vi /etc/profile
export JAVA_HOME=/app/jdk1.8.0_391
export CLASSPATH=.:JAVA_HOME/lib/dt.jar:JAVA_HOME/lib/tools.jar
export JRE_HOME=$JAVA_HOME/jre
export HADOOP_HOME=/usr/hadoop-3.1.1
export HIVE_HOME=/usr/hive-3.1.0
export PATH=JAVA_HOME/bin:HADOOP_HOME/bin:HIVE_HOME/bin:PATH
第十二步:创建hadoop数据目录
mkdir -p /home/hadoop/hadoop3.1.1/dfs/name
mkdir -p /home/hadoop/hadoop3.1.1/dfs/data
mkdir -p /home/hadoop/hadoop3.1.1/temp
mkdir -p /home/hadoop/hadoop3.1.1/dfs/journaldata
mkdir -p /home/hadoop/hadoop3.1.1/hive/warehouse
第十三步:修改配置
core-site.xml
vi $HADOOP_HOME/etc/core-site.xml
XML
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master.hadoop:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop3.1.1/temp/</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
<description>Allow root user to connect from any host</description>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
<description>Allow root user to impersonate users from any group</description>
</property>
</configuration>hdfs-site.xml
vi $HADOOP_HOME/etc/hdfs-site.xml
XML
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop3.1.1/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop3.1.1/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>5</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>yarn-site.xml
vi $HADOOP_HOME/etc/yarn-site.xml
XML
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master.hadoop</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/hadoop-3.1.1/etc/hadoop:/usr/hadoop-3.1.1/share/hadoop/common/lib/*:/usr/hadoop-3.1.1/share/hadoop/common/*:/usr/hadoop-3.1.1/share/hadoop/hdfs:/usr/hadoop-3.1.1/share/hadoop/hdfs/lib/*:/usr/hadoop-3.1.1/share/hadoop/hdfs/*:/usr/hadoop-3.1.1/share/hadoop/mapreduce/lib/*:/usr/hadoop-3.1.1/share/hadoop/mapreduce/*:/usr/hadoop-3.1.1/share/hadoop/yarn:/usr/hadoop-3.1.1/share/hadoop/yarn/lib/*:/usr/hadoop-3.1.1/share/hadoop/yarn/*</value>
</property>
</configuration>获取 yarn.application.classpath
bash
# 即该命令执行结果
yarn classpath
mapred-site.xml
vi $HADOOP_HOME/etc/mapred-site.xml
XML
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master.hadoop:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master.hadoop:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>workers
vi $HADOOP_HOME/etc/workers
Matlab
slave1.hadoop
slave2.hadoop第十四步:修改脚本
hadoop-env.sh
vi $HADOOP_HOME/etc/hadoop-env.sh
bash
export JAVA_HOME=/app/jdk1.8.0_391
export HADOOP_HOME=/usr/hadoop-3.1.1
export HDFS_DATANODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# shell
export HADOOP_SHELL_EXECNAME=root
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
case ${HADOOP_OS_TYPE} in
Darwin*)
export HADOOP_OPTS="${HADOOP_OPTS} -Djava.security.krb5.realm= "
export HADOOP_OPTS="${HADOOP_OPTS} -Djava.security.krb5.kdc= "
export HADOOP_OPTS="${HADOOP_OPTS} -Djava.security.krb5.conf= "
;;
esacstart-dfs.sh
vi $HADOOP_HOME/sbin/start-dfs.sh
添加下面几行脚本
bash
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=rootstop-dfs.sh
vi vi $HADOOP_HOME/sbin/stop-dfs.sh
start-yarn.sh
vi $HADOOP_HOME/sbin/start-yarn.sh
添加下面几行脚本
bash
YARN_RESOURCEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=root
YARN_NODEMANAGER_USER=rootstop-yarn.sh
第十五步: 格式化namenode
只需在第一次启动的时候在Master节点上执行
hdfs namenode -format
第十六步:hadoop服务启停
启
bash
./sbin/start-all.sh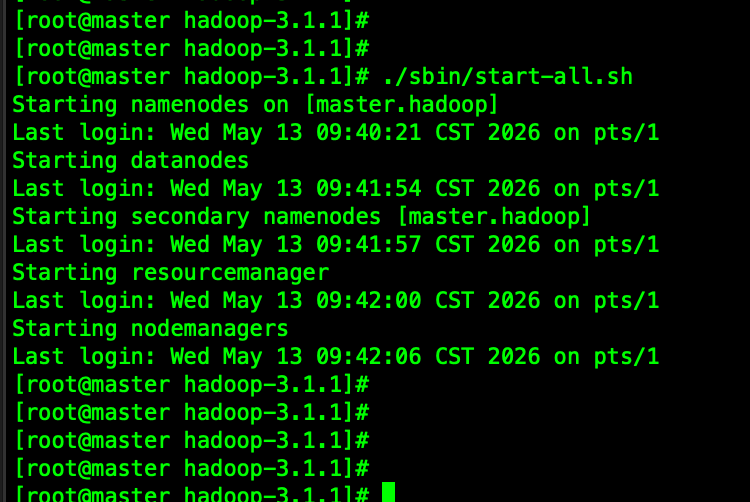
检查master、node1、node2上进程的命令
bash
jpsmaster
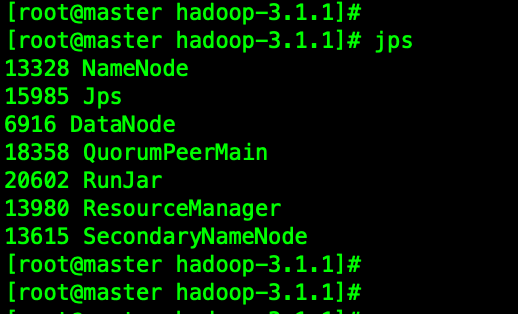
停
bash
./sbin/stop-all.sh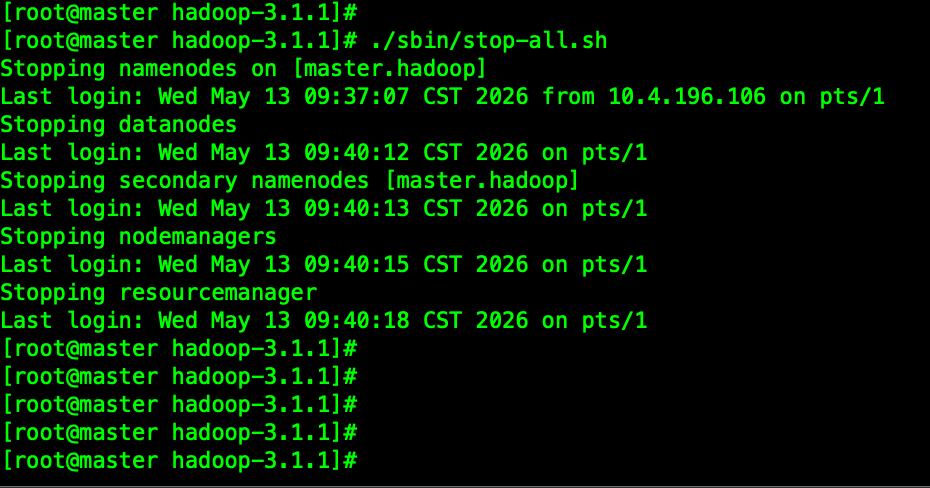
第十五步:访问HDFS、YARN管理页面
访问HDFS的WEB界面
http://10.21.**.184:9870
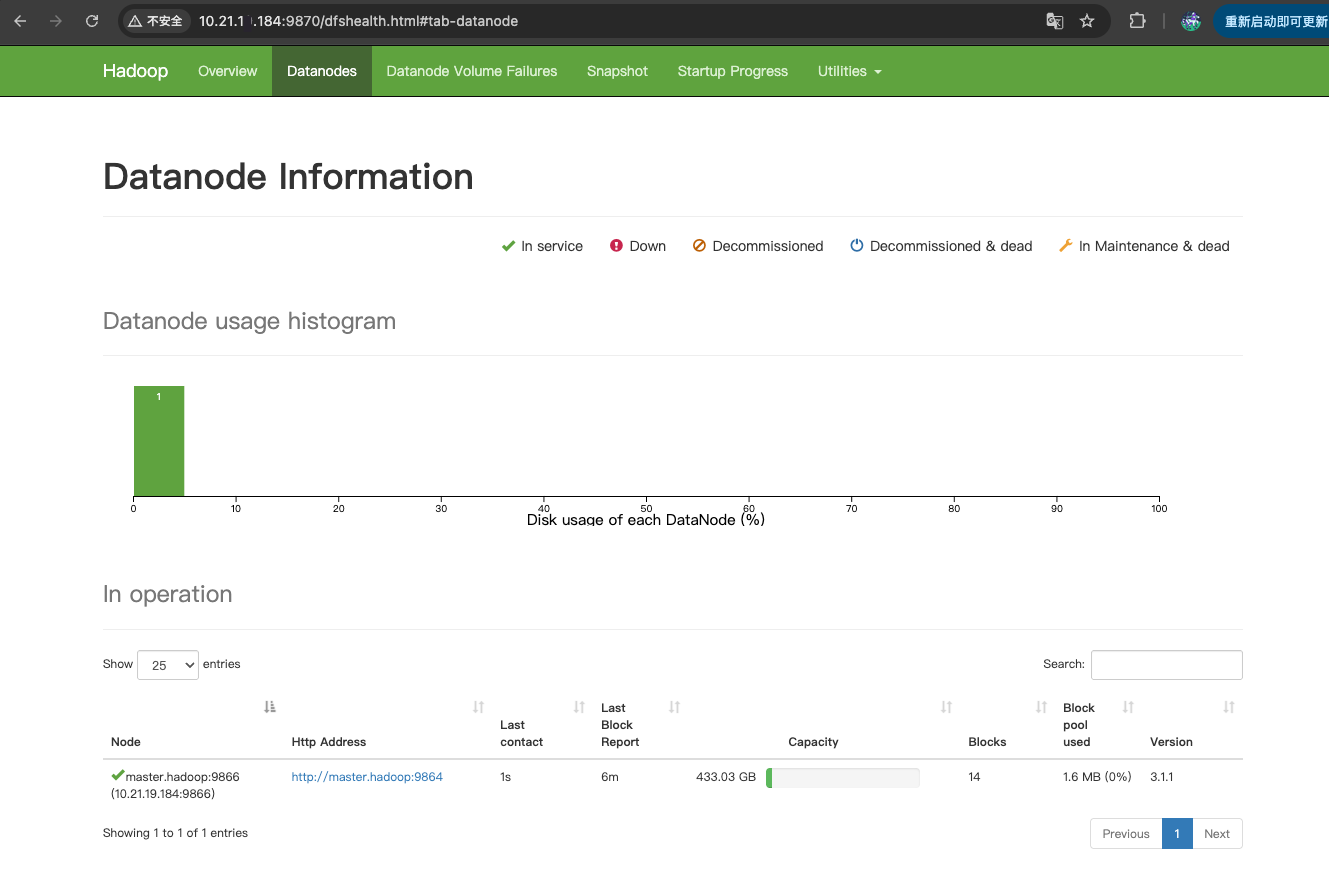
访问YARN的WEB界面
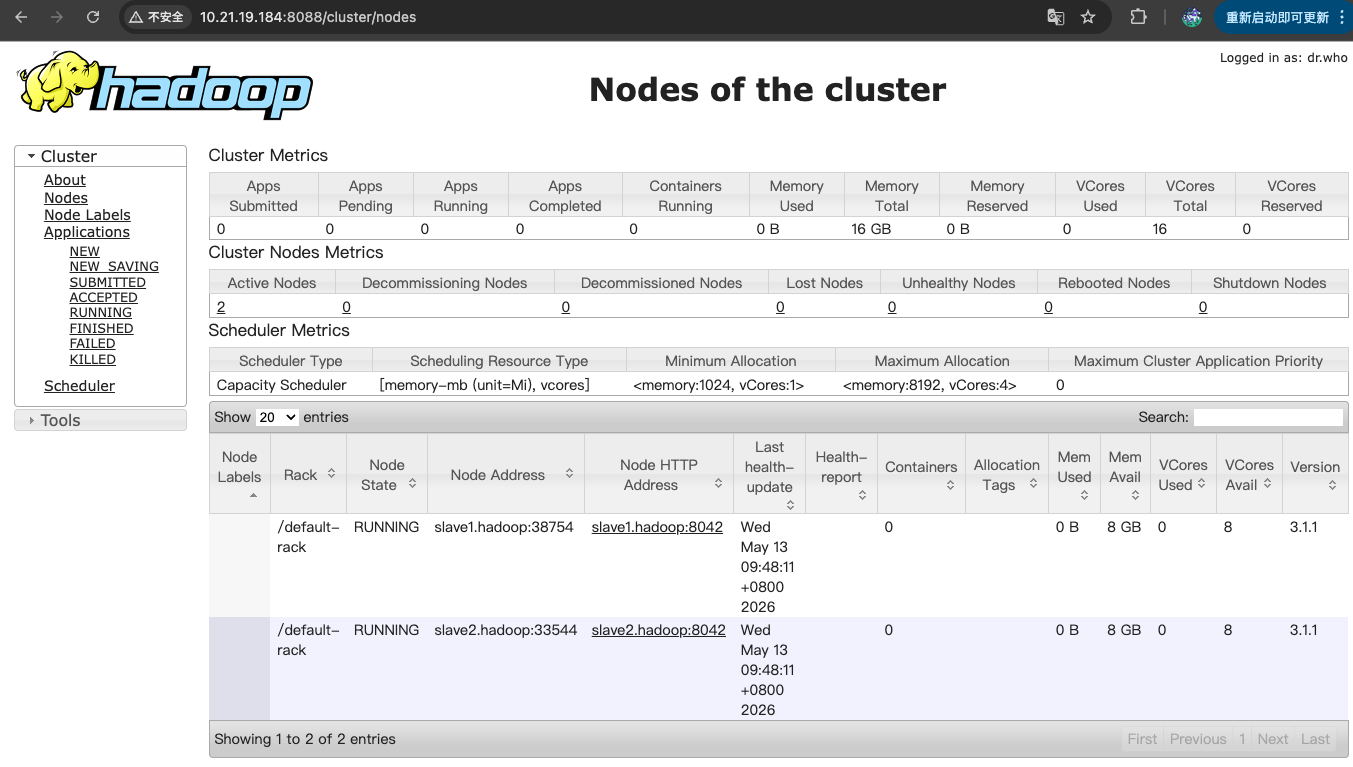
http://10.21.**.184:8088
Hive安装
装一台就行了,就安装在master.hadoop上
第一步:上传hive压缩包
获取位置:root@10.21.**.184:/usr/hive-3.1.0.tar.gz
上传到3台准备安装hadoop集群的主机
说明:并非官方源包,而是在集群环境上验证过的程序(带一套完整配置)
第二步:解压hive压缩包
解压hive-3.1.0.tar.gz解压到/usr
第三步:初始化元数据 hive
schematool -initSchema -dbType postgres -verbose
说明:hive环境变量在hadoop第十一步一起加了
第四步:启动Hive
hive --service metastore &
hive --service hiveserver2 &
第五步: 启动数据节点( 第 个 节点 都执行一下)
hdfs --daemon start datanode
说明:避免hadoop服务启动时没有启动导致不可用
第五步:验证
hive命令行:
hive
beeline 命令行
beeline -u jdbc:hive2://10.21.19.***:10000
use fefault;
select 1 union all select 2;
附件一:可能用得到的脚本
上传后传到其他2台主机(3台版)master上root执行
scp -r /usr/hadoop-3.1.1.tar.gz root@slave1.hadoop:/usr/
scp -r /usr/hadoop-3.1.1.tar.gz ++++root@slave2.hadoop:/usr/++++
集群间传配置(3台版)master上root执行
scp -r /usr/hadoop-3.1.1/etc/ root@slave1.hadoop:/usr/hadoop-3.1.1/
scp -r /usr/hadoop-3.1.1/etc/ ++++root@slave2.hadoop:/usr/hadoop-3.1.1/++++
scp -r /usr/hadoop-3.1.1/sbin/ root@slave1.hadoop:/usr/hadoop-3.1.1/
scp -r /usr/hadoop-3.1.1/sbin/ ++++root@slave2.hadoop:/usr/hadoop-3.1.1/++++