小肥柴的Hadoop之旅 快速实验篇(0-1)虚拟机模拟完全分布式环境搭建
-
- 目录
- [0. 概要](#0. 概要)
- [1. 前置准备](#1. 前置准备)
-
- [1.1 宿主机要求](#1.1 宿主机要求)
- [1.2 软件下载](#1.2 软件下载)
- [1.3 集群拓扑规划](#1.3 集群拓扑规划)
- [2. 母机 (master) 安装与基础配置](#2. 母机 (master) 安装与基础配置)
-
- [2.1 创建虚拟机](#2.1 创建虚拟机)
- [2.2 首次连接 FinalShell](#2.2 首次连接 FinalShell)
-
- [2.3 更换为清华 APT 源](#2.3 更换为清华 APT 源)
- [2.4 安装 open-vm-tools(实现文件拖拽、剪贴板共享)](#2.4 安装 open-vm-tools(实现文件拖拽、剪贴板共享))
- [2.5 配置时区与时间同步](#2.5 配置时区与时间同步)
- [2.6 优化 SSH 连接速度(关闭 DNS 反向解析和 GSSAPI 认证)](#2.6 优化 SSH 连接速度(关闭 DNS 反向解析和 GSSAPI 认证))
- [3. 网络配置(静态 IP + 幽灵动态 IP 根治)](#3. 网络配置(静态 IP + 幽灵动态 IP 根治))
-
- [3.1 前置:VMware 虚拟网络编辑器修改子网](#3.1 前置:VMware 虚拟网络编辑器修改子网)
- [3.2 修改主机名](#3.2 修改主机名)
- [3.3 配置 hosts 文件](#3.3 配置 hosts 文件)
- [3.4 使用 systemd-networkd 静态配置文件(推荐根治方案)](#3.4 使用 systemd-networkd 静态配置文件(推荐根治方案))
- [3.5 手动清除残留的 DHCP 租约和进程(如果仍存在幽灵 IP)](#3.5 手动清除残留的 DHCP 租约和进程(如果仍存在幽灵 IP))
- [3.6 重启终极验证](#3.6 重启终极验证)
- [4. 安装 JDK 与 Hadoop](#4. 安装 JDK 与 Hadoop)
-
- [4.1 安装 OpenJDK 8](#4.1 安装 OpenJDK 8)
- [4.2 下载并部署 Hadoop 3.3.6](#4.2 下载并部署 Hadoop 3.3.6)
- [4.3 配置环境变量](#4.3 配置环境变量)
- [4.4 Hadoop 核心配置文件](#4.4 Hadoop 核心配置文件)
-
- [4.4.1 hadoop-env.sh](#4.4.1 hadoop-env.sh)
- [4.4.2 core-site.xml](#4.4.2 core-site.xml)
- [4.4.3 hdfs-site.xml](#4.4.3 hdfs-site.xml)
- [4.4.4 mapred-site.xml](#4.4.4 mapred-site.xml)
- [4.4.5 yarn-site.xml](#4.4.5 yarn-site.xml)
- [4.4.6 workers 文件](#4.4.6 workers 文件)
- [4.5 创建本地数据目录](#4.5 创建本地数据目录)
- [5. 克隆节点与修改身份](#5. 克隆节点与修改身份)
-
- [5.1 关闭母机](#5.1 关闭母机)
- [5.2 拍摄母机快照(可选)](#5.2 拍摄母机快照(可选))
- [5.3 完全克隆四台子节点](#5.3 完全克隆四台子节点)
- [5.4 逐台修改子节点主机名与 IP](#5.4 逐台修改子节点主机名与 IP)
- [5.5 修改所有子节点的 hosts 文件](#5.5 修改所有子节点的 hosts 文件)
- [5.6 重启所有子节点](#5.6 重启所有子节点)
- [6. SSH 免密登录配置](#6. SSH 免密登录配置)
- [7. 格式化 HDFS 并启动集群](#7. 格式化 HDFS 并启动集群)
- [8. 调整 standby 节点角色(SecondaryNameNode + JobHistoryServer)](#8. 调整 standby 节点角色(SecondaryNameNode + JobHistoryServer))
-
- [8.1 将 SecondaryNameNode 从 master 迁移到 standby](#8.1 将 SecondaryNameNode 从 master 迁移到 standby)
- [8.2 在 standby 上配置 JobHistoryServer](#8.2 在 standby 上配置 JobHistoryServer)
- [9. 集群启停规范与快照管理](#9. 集群启停规范与快照管理)
-
- [9.1 启动顺序](#9.1 启动顺序)
- [9.2 关闭顺序](#9.2 关闭顺序)
- [9.3 快照节点](#9.3 快照节点)
- [10. 常见问题 (FAQ)](#10. 常见问题 (FAQ))
-
- [Q1 FinalShell 连接慢/失败排查](#[Q1] FinalShell 连接慢/失败排查)
- [Q2 幽灵动态 IP (192.168.10.128/129) 反复出现](#[Q2] 幽灵动态 IP (192.168.10.128/129) 反复出现)
- [Q3 SSH 免密登录后 start-dfs.sh 仍 Permission denied](#[Q3] SSH 免密登录后 start-dfs.sh 仍 Permission denied)
- [Q4 格式化 HDFS 后再次格式化导致 DataNode 无法启动](#[Q4] 格式化 HDFS 后再次格式化导致 DataNode 无法启动)
- [Q5 worker 节点 jps 缺少 DataNode 或 NodeManager](#[Q5] worker 节点 jps 缺少 DataNode 或 NodeManager)
- [Q6 虚拟机运行卡顿或性能不佳](#[Q6] 虚拟机运行卡顿或性能不佳)
目录
0. 概要
(1)目标 :在本地 VMware 虚拟机中搭建 5 节点完全分布式 Hadoop 3.3.6 集群(1主 + 1备 + 3工作),并打通后续扩展 ZooKeeper、Kafka、Spark 的基础。
(2)适用环境 :Windows 宿主机 + VMware Workstation Pro 17 + Ubuntu Server 22.04 LTS。
【注】所有软件均从国内清华镜像站获取。
1. 前置准备
1.1 宿主机要求
- CPU ≥ 8 核,内存 ≥ 16 GB(推荐 32 GB),磁盘 ≥ 150 GB 可用空间(SSD 更佳)。
- 已安装 VMware Workstation Pro 17(已对个人免费)。
- 已安装 FinalShell(SSH + 文件传输 + 监控一体化)。
1.2 软件下载
| 软件 | 下载地址 |
|---|---|
| Ubuntu Server 22.04.5 LTS | 清华镜像 |
| Hadoop 3.3.6 二进制包 | 清华镜像 |
注意 :不要下载
desktop版或src源码包。文件名必须为ubuntu-22.04.5-live-server-amd64.iso和hadoop-3.3.6.tar.gz。
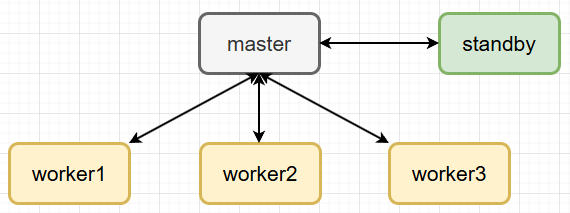
1.3 集群拓扑规划
| 节点 | 主机名 | 静态 IP | 角色 |
|---|---|---|---|
| VM1 | master | 192.168.10.101/24 | NameNode, ResourceManager |
| VM2 | standby | 192.168.10.102/24 | SecondaryNameNode, JobHistoryServer |
| VM3 | worker1 | 192.168.10.103/24 | DataNode, NodeManager |
| VM4 | worker2 | 192.168.10.104/24 | DataNode, NodeManager |
| VM5 | worker3 | 192.168.10.105/24 | DataNode, NodeManager |
- 网络模式:VMware NAT 模式,虚拟子网
192.168.10.0/24,网关192.168.10.2;【注】可以视情况更改虚拟机IP设定,不冲突即可。 - 硬件参考:master 4 核/8 GB,standby 2 核/4 GB,worker1~3 各 2 核/4 GB;每节点磁盘 50 GB。
2. 母机 (master) 安装与基础配置
2.1 创建虚拟机
【概要】
-
VMware 新建虚拟机,选择
ubuntu-22.04.5-live-server-amd64.iso。 -
硬件配置:双核(先预设 2 核即可,克隆后可改)、内存 2 GB(母机安装时 2 GB 足够,注意合理使用,4GB正好)。
-
网络类型:NAT 模式。
-
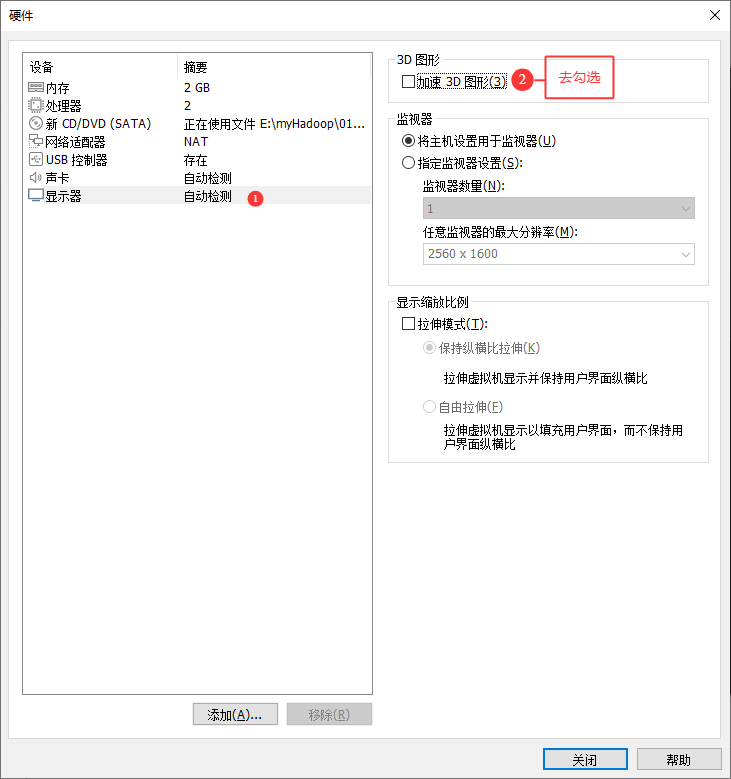
图形显示 :在"显示器"选项中,务必取消勾选"加速3D图形",以优化服务器环境性能。
-
安装 Ubuntu Server 简要流程如下:(细节键本节后续内容)
- 语言 English,键盘 English (US)。
- 软件源镜像 :手动输入
http://mirrors.tuna.tsinghua.edu.cn/ubuntu/。 - 磁盘分区:使用整个磁盘 (Use an entire disk)。
- 用户创建 :新建用户
hadoop,设置密码(牢记)。 - SSH 服务 :务必勾选 Install OpenSSH server。
- 其他保持默认,安装完成后重启。
【安装 Ubuntu Server细节】启动虚拟机,进入安装界面,请参考以下关键设置(已经顺序排好):
(1)Language: 选择 English。
(2)Installer update: 选择 Continue without updating。
(3)Keyboard: 保持默认 English (US)。
(4)Network connections: 系统会尝试通过DHCP获取IP,先保持默认,我们后续会配置静态IP。
(5)Configure proxy: 留空。
(6)Configure Ubuntu archive mirror: 输入清华镜像源地址 http://mirrors.tuna.tsinghua.edu.cn/ubuntu/。
(7)Guided storage configuration: 选择 Use an entire disk,然后选中磁盘,选择 Done。
(8)Storage configuration: 确认分区信息后,选择 Continue。
(9)Profile setup: 创建一个名为 hadoop 的用户,并设置密码。
(10)SSH Setup: 按空格键勾选 Install OpenSSH server。
(11)Featured server snaps: 直接选择 Done。
(12)等待安装:安装完成后选择 Reboot Now。
2.2 首次连接 FinalShell
-
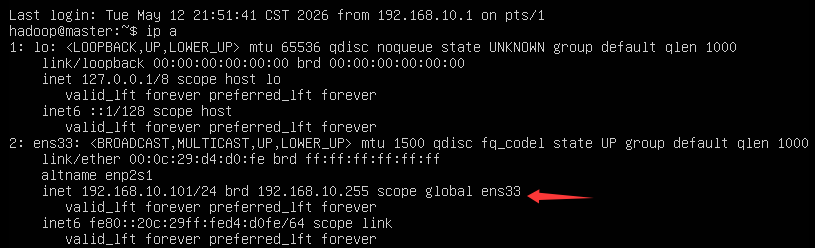
在母机终端
ip a查看当前 DHCP 分配的临时 IP(类似 如192.168.148.128)。
-
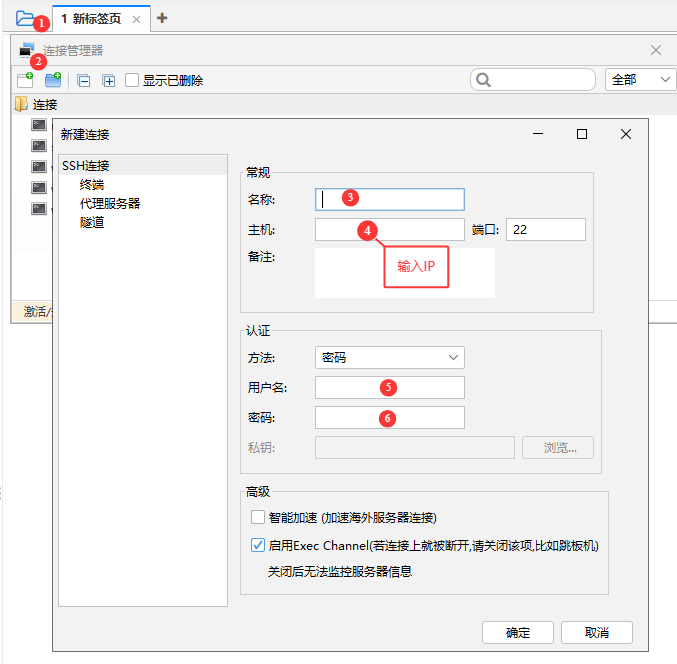
宿主机打开 FinalShell,新建 SSH 连接:
- 主机:临时 IP
- 端口:22
- 用户名:
hadoop - 密码:安装时设置的密码
-
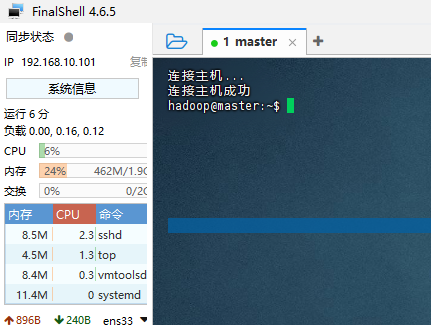
连接成功即可继续。若连接不上 ,参考 10.1 FinalShell 连接慢/失败排查 。
2.3 更换为清华 APT 源
【注】第一次接触Linux的朋友要适应命令行操作,vi就是一个常见的编辑器。
bash
sudo cp /etc/apt/sources.list /etc/apt/sources.list.backup
sudo vi /etc/apt/sources.list清空内容,粘贴以下内容(代号 jammy 对应 22.04):
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-security main restricted universe multiverse更新软件包列表:
bash
sudo apt update2.4 安装 open-vm-tools(实现文件拖拽、剪贴板共享)
bash
sudo apt install -y open-vm-tools-desktop2.5 配置时区与时间同步
bash
sudo timedatectl set-timezone Asia/Shanghai
sudo timedatectl set-ntp true
sudo sed -i 's/^#NTP=/NTP=ntp.aliyun.com ntp.ustc.edu.cn/' /etc/systemd/timesyncd.conf
sudo systemctl restart systemd-timesyncd
date # 确认时间正常2.6 优化 SSH 连接速度(关闭 DNS 反向解析和 GSSAPI 认证)
bash
sudo vi /etc/ssh/sshd_config添加或修改:
bash
UseDNS no
GSSAPIAuthentication no重启 SSH:
bash
sudo systemctl restart sshd3. 网络配置(静态 IP + 幽灵动态 IP 根治)
背景 :VMware NAT 模式默认 DHCP 分配 IP,集群必须使用固定 IP。即使 Netplan 中关闭 DHCP,
systemd-networkd仍可能在后台获取动态 IP,导致网卡同时存在两个 IP(俗称"幽灵 IP"),造成集群通信混乱。以下方案永久解决此问题。
3.1 前置:VMware 虚拟网络编辑器修改子网
- VMware 菜单 → 编辑 → 虚拟网络编辑器。
- 选中 VMnet8(NAT 模式) ,将 子网 IP 改为
192.168.10.0,掩码255.255.255.0。 - 点击 NAT 设置 ,将 网关 IP 改为
192.168.10.2。保存退出。
3.2 修改主机名
bash
sudo hostnamectl set-hostname master3.3 配置 hosts 文件
bash
sudo vi /etc/hosts删除 127.0.1.1 <旧主机名> 行(如 127.0.1.1 kluniv),确保本机主机名通过静态 IP 解析。最终内容:
127.0.0.1 localhost
192.168.10.101 master
192.168.10.102 standby
192.168.10.103 worker1
192.168.10.104 worker2
192.168.10.105 worker3
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters验证:
bash
getent hosts master # 必须返回 192.168.10.1013.4 使用 systemd-networkd 静态配置文件(推荐根治方案)
出现DHCP无法禁用的情况时,需要查询当前是哪一个进程自动触发了它。现象类似:
hadoop@worker1:~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:4e:b4:d4 brd ff:ff:ff:ff:ff:ff
altname enp2s1
inet 192.168.10.103/24 brd 192.168.10.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.10.129/24 metric 100 brd 192.168.10.255 scope global secondary dynamic ens33
valid_lft 1694sec preferred_lft 1694sec
inet6 fe80::20c:29ff:fe4e:b4d4/64 scope link
valid_lft forever preferred_lft forever此处经检测发现是 dhclient 导致,因此不依赖 Netplan,直接给 systemd-networkd 写静态配置。
bash
sudo tee /etc/systemd/network/10-ens33.network << EOF
[Match]
Name=ens33
[Network]
DHCP=no
Address=192.168.10.101/24
Gateway=192.168.10.2
DNS=114.114.114.114
DNS=8.8.8.8
EOF注意 :网卡名可能为 ens33 或 ens160,请用 ip a 确认后替换。
重启服务并验证:
bash
sudo systemctl restart systemd-networkd
ip a此时应只显示 192.168.10.101,无任何 dynamic 字样。
3.5 手动清除残留的 DHCP 租约和进程(如果仍存在幽灵 IP)
bash
# 停止服务及 socket
sudo systemctl stop systemd-networkd.service systemd-networkd.socket
# 删除幽灵 IP
sudo ip addr del 192.168.10.xxx/24 dev ens33 2>/dev/null
# 清除租约缓存
sudo rm -f /var/lib/systemd/network/*
sudo rm -f /run/systemd/netif/leases/*
sudo rm -f /run/systemd/netif/links/*
# 处理可能存在的独立 dhclient 进程
sudo pkill dhclient
sudo mv /sbin/dhclient /sbin/dhclient.bak 2>/dev/null
# 重启服务
sudo systemctl start systemd-networkd.service3.6 重启终极验证
bash
sudo reboot重启后再次用 FinalShell 连接新 IP 192.168.10.101,连续执行两次 ip a,确认幽灵 IP 彻底消失。
4. 安装 JDK 与 Hadoop
4.1 安装 OpenJDK 8
bash
sudo apt update
sudo apt install -y openjdk-8-jdk-headless
java -version # 应输出 1.8.0_xxx4.2 下载并部署 Hadoop 3.3.6
bash
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
sudo tar -zxvf hadoop-3.3.6.tar.gz -C /usr/local
sudo mv /usr/local/hadoop-3.3.6 /usr/local/hadoop
sudo chown -R hadoop:hadoop /usr/local/hadoop4.3 配置环境变量
bash
vi ~/.bashrc末尾添加:
bash
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin生效:
bash
source ~/.bashrc
hadoop version # 验证4.4 Hadoop 核心配置文件
进入配置目录:
bash
cd /usr/local/hadoop/etc/hadoop4.4.1 hadoop-env.sh
在文件末尾添加:
bash
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd644.4.2 core-site.xml
xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data/tmp</value>
</property>
</configuration>4.4.3 hdfs-site.xml
xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>4.4.4 mapred-site.xml
xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>4.4.5 yarn-site.xml
xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>4.4.6 workers 文件
编辑文件:
bash
vi /usr/local/hadoop/etc/hadoop/workers用以下内容完全替换:
worker1
worker2
worker3【注】为什么要改这个文件?
(1)这个 workers 文件(Hadoop 2.x 时代叫 slaves,3.x 改名为 workers)专门用来告诉 Hadoop 集群:哪些节点是 DataNode 和 NodeManager。
(2)启动 HDFS 时,start-dfs.sh 脚本会读取这个文件,依次 SSH 到每一行所列的主机名去启动 DataNode 进程。
(3)启动 YARN 时,start-yarn.sh 脚本也会根据它启动 NodeManager 进程。
该文件等母机配好之后会随整个 /usr/local/hadoop 目录一起分发到各节点,所以目前只需要在 master 上修改,克隆/分发后不需要再单独改每个节点。
4.5 创建本地数据目录
bash
mkdir -p /usr/local/hadoop/data/tmp
mkdir -p /usr/local/hadoop/data/namenode
mkdir -p /usr/local/hadoop/data/datanode5. 克隆节点与修改身份
5.1 关闭母机
bash
sudo shutdown now5.2 拍摄母机快照(可选)
VMware 为 master 拍摄快照 Master-Configured,防止后续克隆出错时可回退。
5.3 完全克隆四台子节点
VMware → 右键 master → 管理 → 克隆 → 创建完整克隆 ,依次克隆出 standby、worker1、worker2、worker3。
5.4 逐台修改子节点主机名与 IP
每台启动后,以 hadoop 登录,按如下脚本化修改(以 standby 为例):
bash
# 主机名
sudo hostnamectl set-hostname standby
# 修改 systemd-networkd 配置文件中的地址
sudo sed -i 's/192.168.10.101\/24/192.168.10.102\/24/' /etc/systemd/network/10-ens33.network
# 重启网络
sudo systemctl restart systemd-networkd其他节点对应 IP 替换(worker1: 103, worker2: 104, worker3: 105)。
5.5 修改所有子节点的 hosts 文件
每个子节点的 /etc/hosts 中删除 127.0.1.1 <旧主机名> 行,并确保五条映射都存在(内容同 master 的 /etc/hosts)。验证 getent hosts $(hostname) 返回自己的静态 IP。
5.6 重启所有子节点
bash
sudo reboot重启后检查 ip a 和 hostname,确保网络干净、主机名正确。
6. SSH 免密登录配置
仅需在 master 上操作,实现 master 到所有节点(包括自己)的无密码 SSH。
bash
ssh-keygen -t rsa -P '' # 一路回车,后续一条一条的执行
ssh-copy-id hadoop@master
ssh-copy-id hadoop@standby
ssh-copy-id hadoop@worker1
ssh-copy-id hadoop@worker2
ssh-copy-id hadoop@worker3测试:ssh hadoop@worker1 应无需密码直接登录。
7. 格式化 HDFS 并启动集群
仅在 master 上执行一次格式化:
bash
hdfs namenode -format日志中应有 ... has been successfully formatted 和 Exiting with status 0。
启动集群:
bash
start-dfs.sh
start-yarn.sh验证各节点进程(jps):
- master:NameNode, ResourceManager
- standby:(暂时无)
- worker1~3:DataNode, NodeManager
Web UI 验证:
- HDFS:
http://192.168.10.101:9870(可见 3 个 Live DataNode) - YARN:
http://192.168.10.101:8088(可见 3 个 Active NodeManager)
确认无误后,关闭所有虚拟机并拍摄快照 Stage1-Hadoop-Base。
8. 调整 standby 节点角色(SecondaryNameNode + JobHistoryServer)
8.1 将 SecondaryNameNode 从 master 迁移到 standby
编辑 hdfs-site.xml 增加:
xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>standby:9868</value>
</property>同步到所有节点:
bash
for node in standby worker1 worker2 worker3; do
scp /usr/local/hadoop/etc/hadoop/hdfs-site.xml hadoop@$node:/usr/local/hadoop/etc/hadoop/
done重启 HDFS:
bash
stop-dfs.sh
start-dfs.sh登陆 standby,jps 应出现 SecondaryNameNode。
8.2 在 standby 上配置 JobHistoryServer
编辑 mapred-site.xml 增加:
xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>standby:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>standby:19888</value>
</property>同步配置,然后在 standby 上执行:
bash
hdfs dfs -mkdir -p /tmp/hadoop-yarn/staging/history/done_intermediate
hdfs dfs -chmod -R 1777 /tmp/hadoop-yarn/staging
mapred --daemon start historyserver
jps # 应有 SecondaryNameNode 和 JobHistoryServer浏览器访问 http://192.168.10.102:19888 检查 JobHistory 界面。
9. 集群启停规范与快照管理
9.1 启动顺序
- master:
start-dfs.sh→start-yarn.sh - standby:
mapred --daemon start historyserver
9.2 关闭顺序
- standby:
mapred --daemon stop historyserver→hdfs --daemon stop secondarynamenode - master:
stop-yarn.sh→stop-dfs.sh
9.3 快照节点
关键节点务必拍摄快照:
Master-Configured:母机 Hadoop 配置完毕Stage1-Hadoop-Base:基础集群运行成功Stage1-Hadoop-Base-v2:standby 角色完善后
10. 常见问题 (FAQ)
Q1 FinalShell 连接慢/失败排查
- 检查虚拟机 SSH 服务:
sudo systemctl status ssh,若未启动sudo systemctl enable ssh --now。 - 防火墙放行 22 端口:
sudo ufw allow ssh。 - 关闭 SSH 的 DNS 反向解析:编辑
/etc/ssh/sshd_config,添加UseDNS no,重启 ssh。 - 关闭 GSSAPI 认证:同上文件加
GSSAPIAuthentication no。 - 宿主机
ping虚拟机 IP,不通则检查 VMware 虚拟网络编辑器 NAT 模式是否启用。
Q2 幽灵动态 IP (192.168.10.128/129) 反复出现
根本原因 :systemd-networkd 在没有明确静态配置时会在接口上尝试 DHCP。
永久解决 :直接创建 /etc/systemd/network/10-ens33.network(参照 3.4 节),并重启服务。
若仍复发,检查是否有独立的 dhclient 进程,将其重命名:sudo mv /sbin/dhclient /sbin/dhclient.bak。
Q3 SSH 免密登录后 start-dfs.sh 仍 Permission denied
- 确认在所有节点上都是用
ssh-copy-id分发过公钥。 - 确认 master 自己也需要
ssh-copy-id hadoop@master。 - 确认各节点
/etc/ssh/sshd_config中PubkeyAuthentication yes未被注释。 - 检查目标节点
/home/hadoop/.ssh/authorized_keys权限为 600,.ssh目录权限为 700。
Q4 格式化 HDFS 后再次格式化导致 DataNode 无法启动
格式化会生成新的 NameNode ID,旧 DataNode 的 ID 不匹配。需要清空各 DataNode 的数据目录后重新格式化,或直接回滚到快照重新操作。
Q5 worker 节点 jps 缺少 DataNode 或 NodeManager
检查 master 的 workers 文件中主机名是否正确、主机名解析是否正常(getent hosts worker1)。
Q6 虚拟机运行卡顿或性能不佳
- 检查显示器设置 ,确认"加速3D图形 "选项处于取消勾选状态。
- 检查各虚拟机分配的总内存是否超出宿主机物理内存。
- 检查宿主机虚拟化设置是否已开启(BIOS中开启VT-x/AMD-V)。
(不断补充新问题和新现象)