近日,澳鹏与全球知名AI开源平台Hugging Face达成合作,为开放ASR(自动语音识别)榜单引入了一套非公开、高质量的英语音频数据集。此次合作旨在提升语音识别模型评估的真实性与公信力,帮助开发者在更贴近实际应用的条件下衡量模型性能。

榜单影响力越大,"刷榜"风险越高
自2023年9月上线以来,**Hugging Face开放ASR榜单已累计访问超过70万次,成为语音识别领域最具影响力的评估基准之一。**该榜单以词错误率为核心指标,对各类ASR模型进行排名。
然而,随着榜单影响力持续扩大,模型开发者通过针对性优化以提升公开测试集得分的现象也日益普遍。 正如**古德哈特定律(Goodhart's Law)**所言:"当某个衡量指标本身成为优化目标时,它就不再是一个好的衡量标准。"
可靠的AI评估始于高质量的数据。我们很高兴能与澳鹏合作,在开放ASR榜单中推出这一新的评测模块。
------Eric Bezzam,Hugging Face音频机器学习工程师
非公开数据集:从源头防止过度拟合
为应对这一挑战,澳鹏向该榜单提供了7个全新的非公开英语音频数据集。 这些数据集涵盖朗读式与对话式两类语音内容,并包含澳大利亚、加拿大、印度、美国等多种地区口音。所有数据集仅由Hugging Face用于评估,不予公开,从源头上降低了"刷榜"的可能,确保排名结果更能体现模型的真实泛化能力。
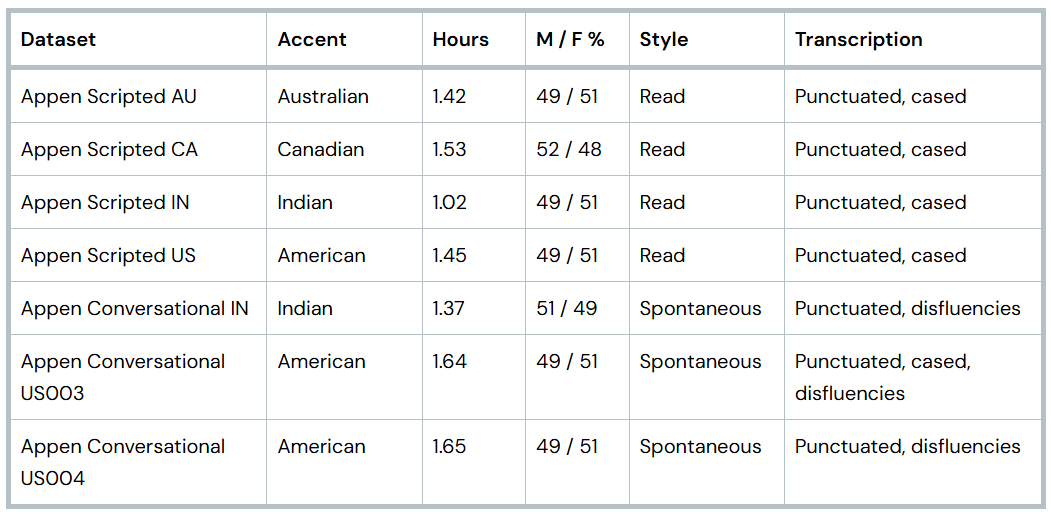
数据构建方面,澳鹏对参与者的口音、录音环境、设备类型等维度 进行了同步筛选与控制。每段录音均经过自动化检测与人工复核两道质检流程,确保数据集的高质量与高一致性。

非公开数据集如何参与评估
非公开数据集存放在榜单中一个专门的"Private data/非公开数据"标签页下。**评分以聚合形式呈现,不暴露单个数据集的得分,从而防止模型针对特定数据提供商或口音进行优化。**榜单报告五个聚合指标:
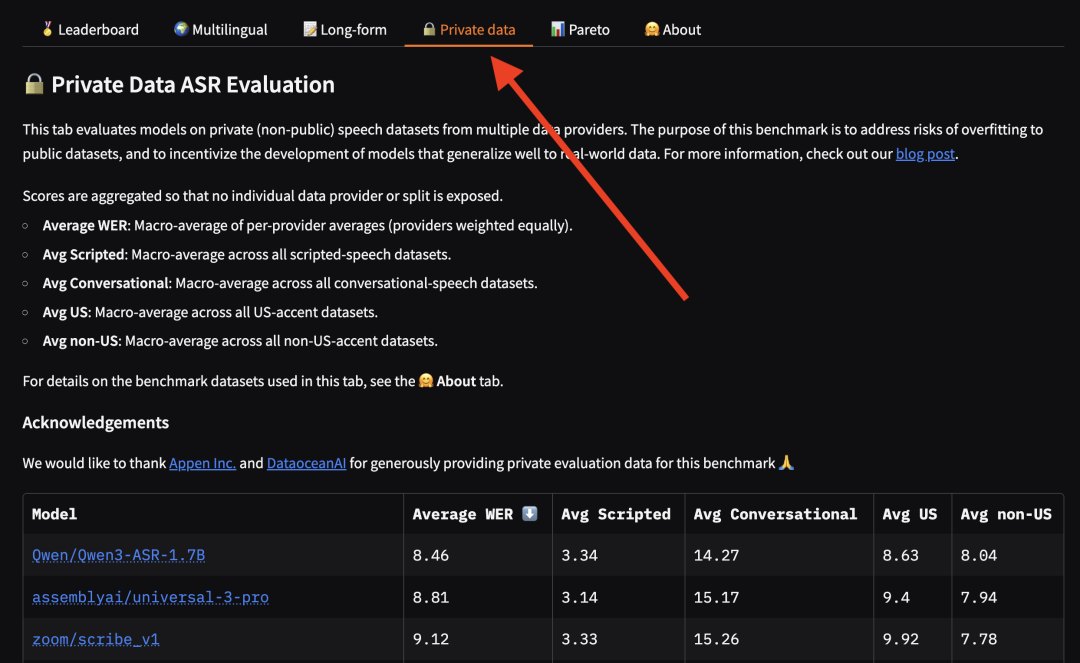
*非公开数据标签页的指标定义及顶部模型排名(Qwen/Qwen3-ASR-1.7B: 8.46 | assemblyai/universal-3-pro: 8.81 | zoom/scribe_v1: 9.12)
默认情况下,非公开数据集不参与主榜单的平均值计算。在主榜单页面上,新增了两个可切换的列:"非公开数据(朗读)"和"非公开数据(对话)"。
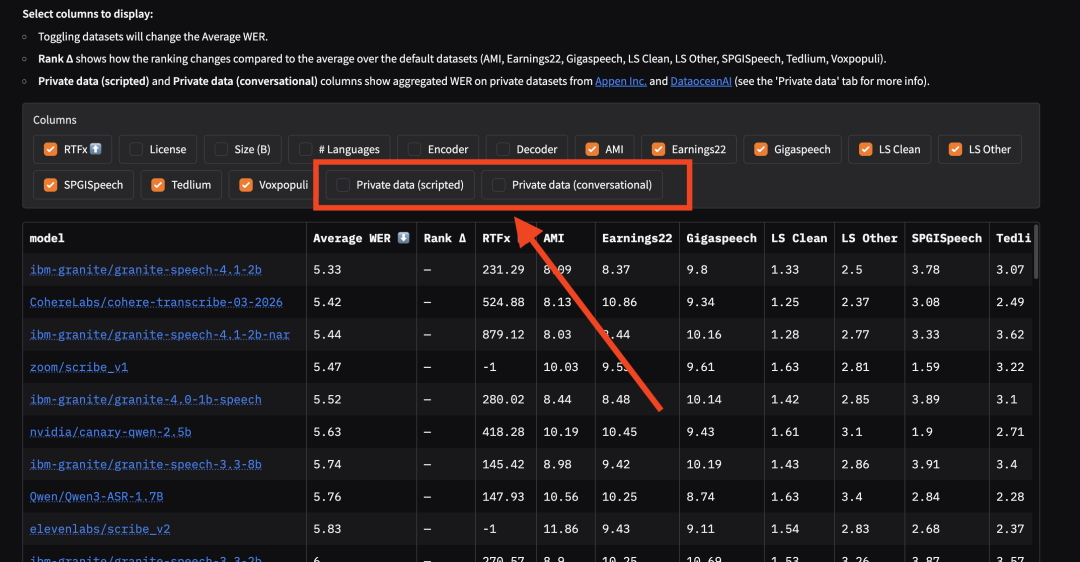
*非公开数据列处于关闭状态的主榜单,列选择器中显示两个未勾选的非公开数据选项
当用户开启这两列后,非公开数据便会被纳入平均值计算,同时"排名变化"列会显示相对于仅使用公开数据时的模型排位变化。
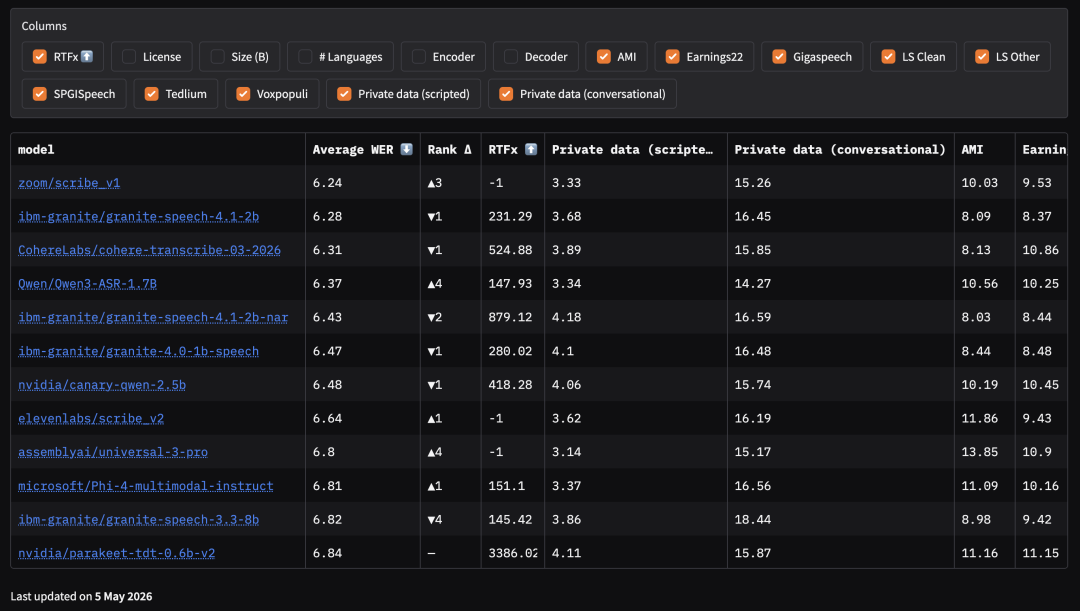
*两列非公开数据均开启后的主榜单,zoom/scribe_v1上升3位至第1名(平均词错误率6.24),"排名变化"列完整可见
揭示模型真实能力: 新增多维度评估指标
借助这些非公开数据集,榜单新增了以下评估维度:
-
**朗读语音平均词错误率:**涵盖多种受控环境下的朗读内容
-
**对话语音平均词错误率:**捕捉包含打断、填充词及自然变化的对话内容
-
**美国口音与非美国口音平均词错误率:**对比模型在标准美式英语与更多元口音上的表现差异
**这些指标揭示了一个重要事实:没有一种ASR模型是"万能"的。**在标准美式英语、朗读式语音上表现优异的系统,可能在对话式语音或非母语口音场景下显著失准。此次合作使这些权衡变得更加透明。

排名变化: 非公开数据如何影响评估结果
在仅使用公开数据的主榜单上,ibm-granite/granite-speech-4.1-2b以5.33的平均词错误率领先。
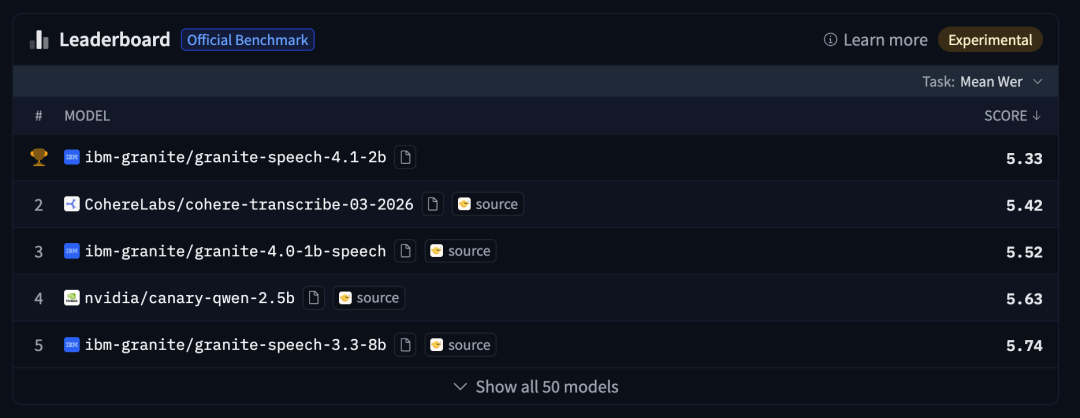
*公开数据主榜单(默认视图)前五名:ibm-granite/granite-speech-4.1-2b (5.33)、CohereLabs/cohere-transcribe-03-2026 (5.42)、ibm-granite/granite-4.0-1b-speech (5.52)、nvidia/canary-qwen-2.5b (5.63)、ibm-granite/granite-speech-3.3-8b (5.74)
当引入澳鹏的非公开数据集后,模型排名出现明显变化。例如,zoom/scribe_v1从第4位上升至第1位。这种变化正是非公开评估机制的价值所在:揭示真实场景下的泛化能力,而非对公开测试集的过度拟合。
为语音社区建立更可靠的评估基础: 语音AI技术在模型性能上取得了长足进步,但衡量这一进步的评估基准却未能同步跟上。只有当底层数据真实反映了语音技术的实际使用方式时,榜单才能呈现完整的故事。
此次澳鹏与Hugging Face的合作,是行业向更严谨、更贴近实际应用的评估基准迈进的一部分。未来,双方还将进一步拓展更多语种的评估覆盖,为全球语音识别社区提供更全面、更具公信力的评测资源。