PyTorch实战(41)------Hugging Face在PyTorch中的应用
-
- [0. 前言](#0. 前言)
- [1. Hugging Face 在 PyTorch 中的应用](#1. Hugging Face 在 PyTorch 中的应用)
-
- [1.1 与 PyTorch 相关的 Hugging Face 组件](#1.1 与 PyTorch 相关的 Hugging Face 组件)
- [1.2 PyTorch与Hugging Face的深度集成](#1.2 PyTorch与Hugging Face的深度集成)
- [2. 使用 Hugging Face Hub 加载预训练模型](#2. 使用 Hugging Face Hub 加载预训练模型)
- [3. 在 PyTorch 中使用 Hugging Face Datasets 库](#3. 在 PyTorch 中使用 Hugging Face Datasets 库)
- [4. 使用 Accelerate 加速 PyTorch 模型训练](#4. 使用 Accelerate 加速 PyTorch 模型训练)
- [5. 使用 Optimum 优化 PyTorch 模型部署](#5. 使用 Optimum 优化 PyTorch 模型部署)
- 小结
- 系列链接
0. 前言
我们已经在《使用 PyTorch 进行文本生成》和《文本到图像生成》了解了 Hugging Face 的部分内容。作为开源平台与社区驱动的资源库,Hugging Face 提供了一套完整的人工智能 (Artificial Intelligence, AI) 工具链、预训练模型以及用于开发和共享前沿模型的协作生态系统,现已成为当代 AI 领域的基础平台之一。
本节将深入探讨 Hugging Face,并介绍在 PyTorch 中如何借助该平台提升深度学习模型的研究、训练、评估、优化及部署效率。通过本节的学习,将能够在深度学习项目中使用 Hugging Face,能够使用 Hugging Face Hub 中的预训练模型,结合 PyTorch 使用 transformers 库,使用 Accelerate 加速模型训练,使用 Optimum 优化已训练的 PyTorch 模型以便进行部署。
1. Hugging Face 在 PyTorch 中的应用
Hugging Face 不仅提供了一系列与训练、评估、优化和部署 AI 模型相关的库,同时也是各类 AI 模型、数据集和实时 AI 演示( Hugging Face 中称为 Spaces )的枢纽平台。该平台正迅速发展成为开发者共享 AI 成果、开展前沿技术讨论的社区生态。
1.1 与 PyTorch 相关的 Hugging Face 组件
如下图所示,我们可以将 Hugging Face 视为一个包含多种组件的平台。在图中,可以看到多个组件都明确标注了 PyTorch 支持------Hugging Face 的模型库、工具集及数据集均与 PyTorch 完全兼容。
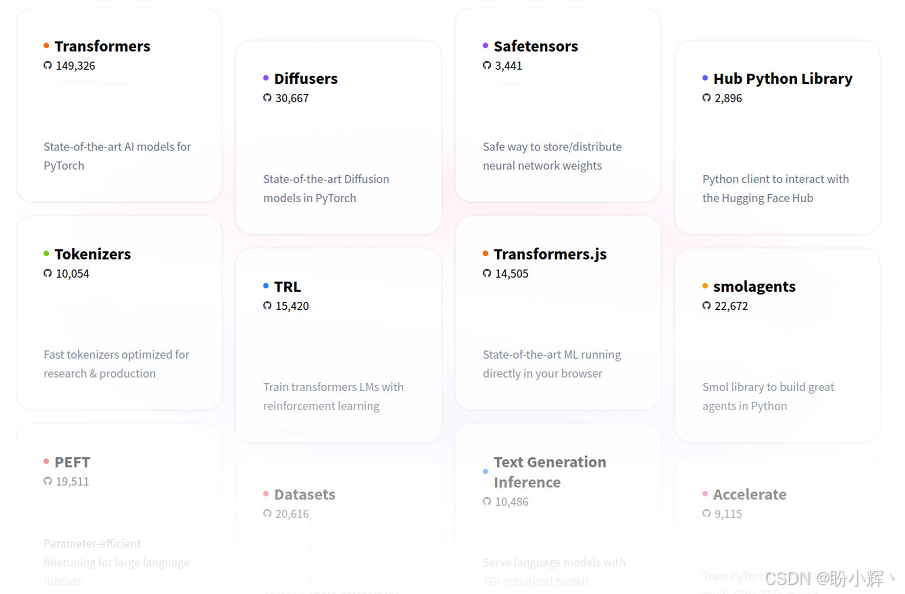
在上图所示的各个组件中,我们将重点讨论以下组件:
Hub和Hub library:作为访问所有AI模型、数据集和演示空间 (Spaces) 的核心门户,这是Hugging Face最广受欢迎的功能之一。开发者可便捷获取前沿AI模型与数据集,既支持模型二次开发,也支持直接推理应用。Hub库提供了通过Python代码访问该Hub的编程接口Datasets(数据集库):除了PyTorch内置的数据集库,Hugging Face的Datasets库使PyTorch能够轻松使用Hugging Face的数据集,甚至是非Hugging Face的第三方数据集Accelerate(加速库):这个工程导向的工具库能有效利用多GPU/TPU配置来训练和推理大型AI模型,并支持混合精度等优化技术Optimum(优化库):另一个工程优化库,专注于部署阶段的模型优化,可在指定目标硬件上实现峰值性能。它能确保最优的效率、速度与资源利用率,显著降低运营成本并提升用户体验
1.2 PyTorch与Hugging Face的深度集成
Hugging Face 在 PyTorch 集成方面实现了无缝兼容------其工具库可原生支持 PyTorch 张量、数据加载器及 GPU 加速。这使得熟悉 PyTorch 的开发者无需完全学习新 API,即可直接利用预训练模型的强大能力。
只需安装对应库即可快速启用 Hugging Face 功能,以 transformers 库为例,执行以下安装命令:
shell
$ pip install torch transformerstransformers 库涵盖了丰富的预训练模型资源,可便捷实现最前沿的自然语言处理技术,并为文本分类、翻译和生成等任务提供广泛支持------所有这些功能都通过统一友好的 API 接口实现。我们可以使用以下代码通过 transformers 库加载一个预训练模型:
python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)在以上代码中,我们从 transformers 库中导入了 AutoTokenizer 和 AutoModelForSequenceClassification 类,并使用 BERT (Bidirectional Encoder Representations from Transformers) 模型的预训练权重 (bert-base-uncased) 进行初始化。将句子编码为词元后,通过以下代码执行模型推理:
python
input_text = "I love PyTorch!"
inputs = tokenizer(input_text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
predicted_class = torch.argmax(outputs.logits, dim=1).item()当输入数据馈入 BERT 模型时,会返回包含上下文语义表征的隐藏状态(存储于 outputs 变量)。我们提取模型输出的 logits 值,并通过 argmax 运算获取预测概率最高的类别(存入 predicted_class 变量)。
以上代码产生的输出结果并非重点,关键在于演示了如何将 PyTorch 库与 transformers 库协同使用。总体而言,PyTorch 通过强大的张量运算与 transformers 完美配合,既能充分发挥深度学习模型效能,又可构建鲁棒、可扩展且高度定制化的机器学习应用。
我们可以使用预训练模型的参数初始化优化器,用于进行预训练模型的微调:
python
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)上面的代码再次展示了 transformers 库与 torch 库之间的协同使用。通过 PyTorch 的 Adam 优化器,可以直接访问来自 Hugging Face 的预训练模型的参数。
以上代码使用 CPU 来执行模型推理,但如果我们希望利用机器上 GPU,只需添加以下代码:
python
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
inputs.to(device)
outputs = model(**inputs)以上代码同样印证了 transformers 与 PyTorch 对象之间的协同性。在本节中我们完成了 PyTorch 库与 Hugging Face 的 transformers 库协同使用的初步探索。类似的 PyTorch 兼容性也适用于 Hugging Face 其他生态库------例如 Diffusers、Accelerate 以及 Optimum 等。
本节中,我们使用了预训练的 bert-base-uncased 模型,下一节将探索 Hugging Face Hub 中更丰富的资源生态------包括各类可用模型、数据集等。
2. 使用 Hugging Face Hub 加载预训练模型
我们已经以 BERT 预训练模型为例,介绍了 transformers 与 torch 库的交互接口,我们通过 Hugging Face Hub 下载并加载了预训练 BERT 模型。在本节中,我们将进一步探索如何使用 Hugging Face Hub 加载预训练模型,并演示如何通过 Python 库和 Hugging Face 官网两种方式使用 Hugging Face Hub。
(1) 访问 Hugging Face Hub 上的一些模型需使用 API 令牌,可以通过以下页面获取 API 令牌:
shell
https://huggingface.co/settings/tokens(2) 要使用 Hugging Face Hub Python 库,需要通过以下命令进行安装:
shell
$ pip install huggingface_hub(3) 安装完成后,运行以下命令来导入库并获取 Hugging Face Hub 上所有可用的预训练模型:
python
from huggingface_hub import hf_api
models = hf_api.list_models()(4) 可以通过以下命令查询 Hugging Face Hub 上提供的预训练模型数量:
python
len([t for t in models])(5) 虽然无法逐一查看所有模型,但我们可以通过以下代码查看Hub上最受欢迎的文本生成模型:
python
text_gen_models = [model.id for model in models if 'text-generation-inference' in model and model.downloads>1000000]
print(text_gen_models)输出结果如下所示:
shell
['distilgpt2', 'gpt2', 't5-base', 't5-small', ...]这些模型列表也可以通过 Hugging Face 的模型页面查看,如下图所示:
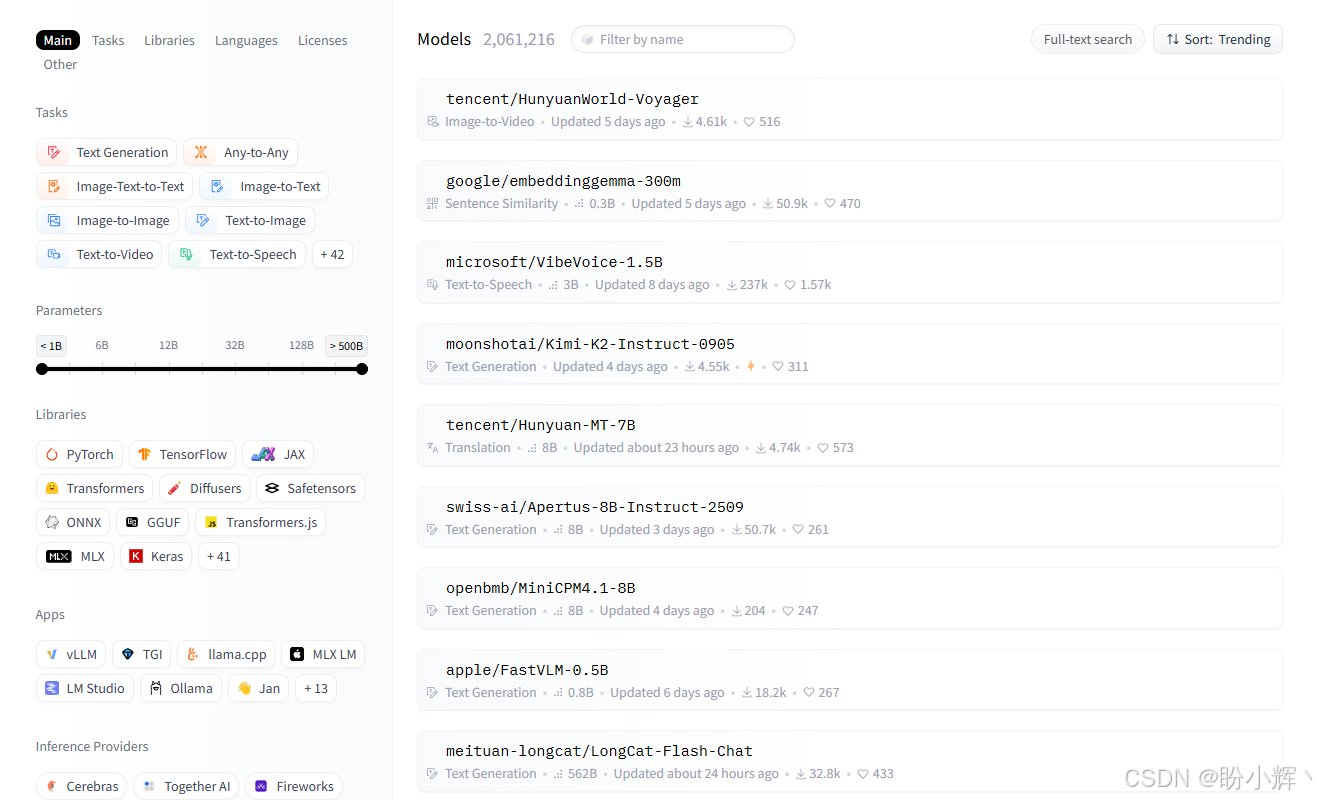
接下来,我们将使用另一个流行的文本生成模型,Text-to-Text Transfer Transformer (T5) 模型。
(1) 从Hugging Face Hub加载t5-small模型:
python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5ForConditionalGeneration.from_pretrained("t5-small")那么我们如何确定该导入哪些 transformers 对象 (T5Tokenizer 或 T5ForConditionalGeneration) 来加载 T5 模型呢?Hugging Face 在 T5 模型页面提供了使用示例(见下图所示),这是我们判断需要导入哪些组件的依据。

(2) 我们已经加载了 T5 模型,接下来使用 t5-small 模型将英文句子翻译成德语:
python
input_ids = tokenizer("translate English to German: I love PyTorch.", return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))输出结果如下所示:
shell
Ich liebe PyTorch.本节演示的流程可轻松适配 Hugging Face Hub 上各类模型------从自然语言处理到计算机视觉,乃至多模态模型皆可适用。
接下来,我们将介绍另一个可与 PyTorch 协同工作的 Hugging Face 组件------Datasets 数据集库。
3. 在 PyTorch 中使用 Hugging Face Datasets 库
通过 Hugging Face datasets 库,能便捷访问数千个公开数据集,并简化自定义数据集的处理流程。可通过以下代码查询数据集数量:
python
from huggingface_hub import hf_api
datasets = hf_api.list_datasets()
len([d for d in datasets])(1) 开始使用 datasets 库前,需要安装以下依赖项:
shell
$ pip install datasets(2) 首先,导入所需的库并配置环境:
python
import torch
from datasets import load_dataset
from transformers import BertTokenizer从 datasets 库导入 load_dataset 函数,由于本节将使用 BERT 模型,因此同时导入 BertTokenizer 进行文本分词处理。
(3) 接下来,只需一行代码就可以轻松加载数据集:
python
dataset = load_dataset("rotten_tomatoes")在本节中,我们选用 Hugging Face 上的 rotten_tomatoes 数据集。我们可以通过查看 Hugging Face Datasets 页面来找到属于特定任务的数据集,例如文本分类任务,然后按下载量从高到低对数据集进行排序,以便选取最受欢迎的数据集,如下图所示:
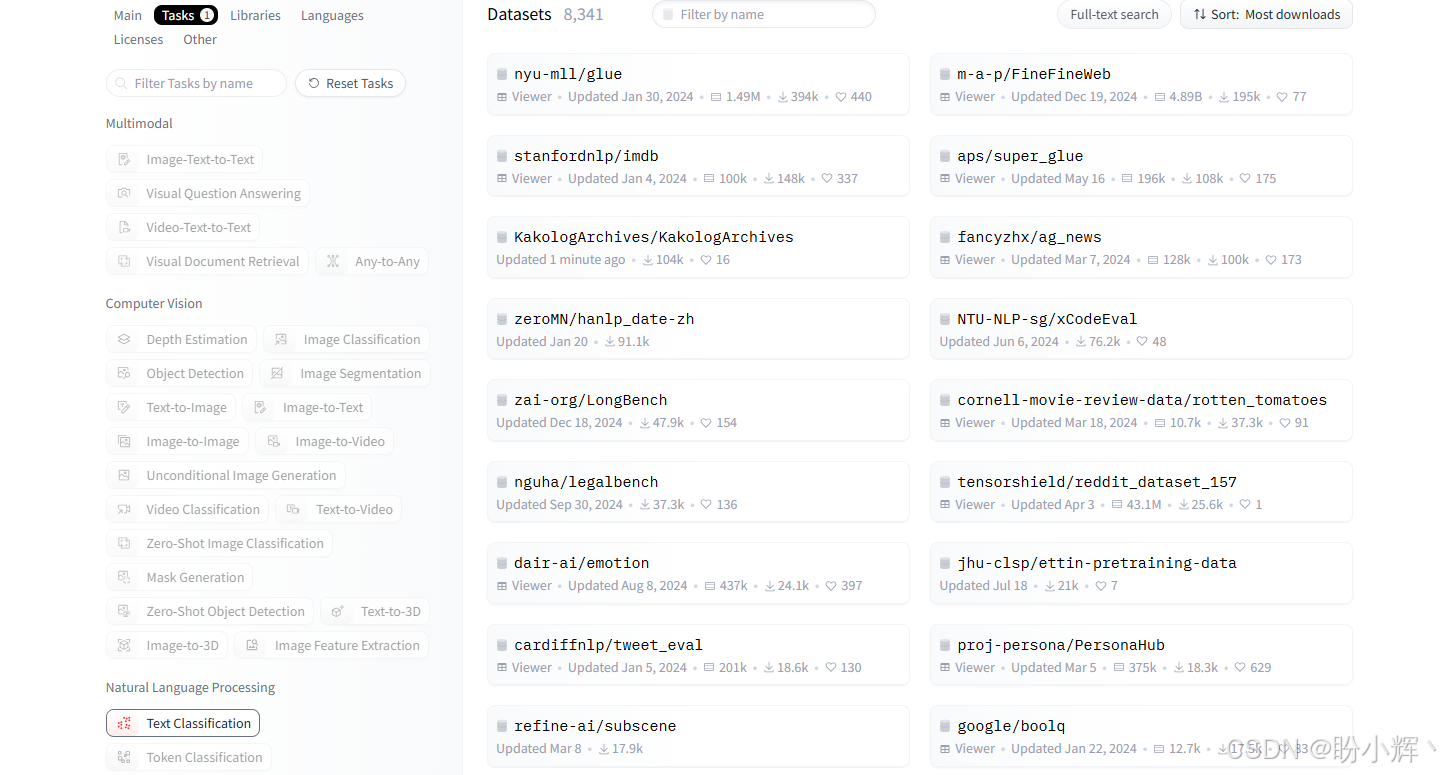
在显示的热门数据集中,我们选定 rotten_tomatoes 数据集。该数据集包含带有情感标签(正面评价标为 1,负面标为 0)的电影评论,其数据结构如下图所示:
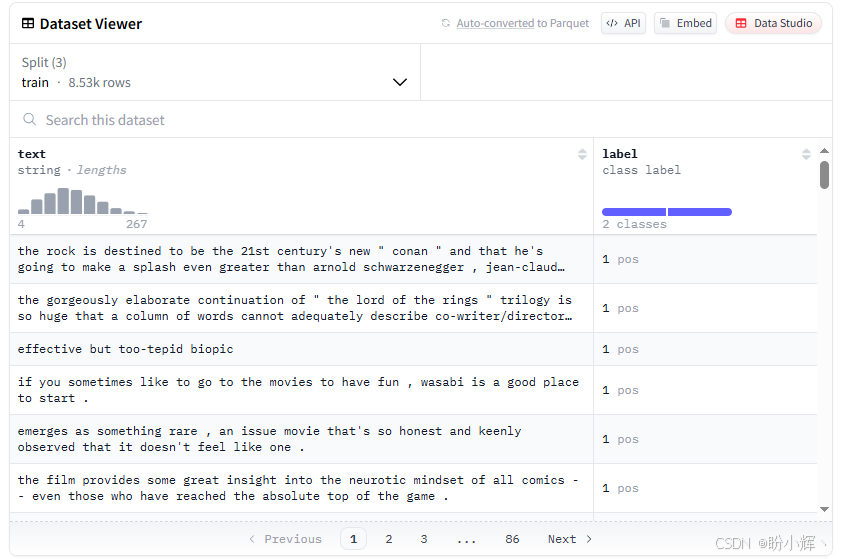
(4) 加载数据集后,需要对文本进行分词,以便将其输入到 BERT 模型中:
python
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
def tokenize_function(example):
return tokenizer(example["text"], padding="max_length", truncation=True)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
tokenized_dataset.set_format(type='torch', columns=['input_ids', 'attention_mask', 'label'])我们通过数据集对象的 map 方法,将 tokenize_dataset 函数应用于每个文本样本(电影评论)。完成分词处理后,将数据集转换为 PyTorch 格式。
(5) 接下来,创建训练和验证的数据加载器:
python
train_dataloader = torch.utils.data.DataLoader(tokenized_dataset['train'], batch_size=8, shuffle=True)
eval_dataloader = torch.utils.data.DataLoader(tokenized_dataset['test'], batch_size=8)(6) 数据准备就绪后,我们从 Hugging Face Hub 加载预训练的 BERT 模型 (bert-base-uncased),并初始化 AdamW 优化器来微调模型。AdamW 是对 Adam 优化器的改进,它将权重衰减与梯度更新解耦,从而在深度学习模型中实现更有效的正则化,通常能获得更好的泛化性能:
python
from tqdm import tqdm
from transformers import BertForSequenceClassification
from torch.optim import AdamW
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
optimizer = AdamW(model.parameters(), lr=5e-5)(7) 最后,使用以下 PyTorch 训练和验证代码微调预训练的 BERT 模型:
python
for epoch in range(3): # Train for 3 epochs as an example
model.train()
for batch in tqdm(train_dataloader):
optimizer.zero_grad()
input_ids = batch['input_ids']
attention_mask = batch['attention_mask']
labels = batch['label']
outputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
model.eval()
total_correct = 0
total_samples = 0
for batch in tqdm(eval_dataloader):
with torch.no_grad():
input_ids = batch['input_ids']
attention_mask = batch['attention_mask']
labels = batch['label']
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
predictions = torch.argmax(outputs.logits, dim=1)
total_correct += (predictions == labels).sum().item()
total_samples += len(labels)
accuracy = total_correct / total_samples
print(f"Epoch {epoch + 1} - Evaluation Accuracy: {accuracy}")以上代码将在 rotten_tomatoes 数据集上微调 BERT 模型,完成将电影评论分类为正面或负面情感(二分类)的文本分类任务,最终输出结果如下所示:

Hugging Face 的 datasets 库提供了便捷的功能,能够直接在 PyTorch 项目中使用大量公开可用的数据集。该库能显著节省时间和资源,使开发者可以专注于构建更健壮的机器学习模型。下一小节我们将探讨如何通过 Hugging Face 的 accelerate 库来优化 PyTorch 模型的训练过程。
4. 使用 Accelerate 加速 PyTorch 模型训练
Accelerate 是 Hugging Face 开发的一款强大工具,专为管理跨多 CPU、GPU 和 TPU 的分布式训练而设计,同时支持 Amazon Web Services (AWS)、Google Cloud Platform (GCP) 和 Microsoft Azure 等云服务。它抽象了数据和模型的并行性,能够高效地将计算任务分配到多个 CPU、GPU 或 TPU 上,降低系统开销并优化执行流程,从而实现轻松扩展。而且,只需要在现有的 PyTorch 代码中添加五行 accelerate 代码,即可最大化硬件利用率,如下图所示。

为了介绍 accelerate 的使用,我们继续以微调 BERT 模型进行文本分类为例,并在训练代码中使用 accelerate 来优化训练过程。
(1) 在继续之前,首先使用以下命令安装 accelerate:
shell
$ pip install accelerate(2) 我们需要在 PyTorch 代码中添加的前两行代码仅涉及导入 accelerate 库并实例化 accelerate 对象:
python
import torch
from datasets import load_dataset
from transformers import BertTokenizer
from accelerate import Accelerator
# Initialize the accelerator
accelerator = Accelerator(cpu=False, mixed_precision="fp16")我们传递了几个参数来实例化 accelerator 对象,可以在 Hugging Face 的官方网站上找到完整的参数列表。
(3) 接下来,我们需要在实例化模型对象和数据加载器对象之后,添加以下代码:
python
model, train_dataloader, eval_dataloader = accelerator.prepare(model, train_dataloader, eval_dataloader)这行代码能确保模型和数据被分配到可用硬件设备(如 GPU 或 TPU )上。
(4) 第四行代码属于替换而非新增------原本在模型训练循环中执行反向传播的代码如下:
python
loss.backward()需要将其替换为以下代码:
python
accelerator.backward(loss)这样做是为了管理多 GPU 分布式训练中的梯度,因为 accelerator 能高效处理梯度累积和设备间同步,从而在多设备配置中优化反向传播过程。
(5) 第五行也是最后一行代码同样属于替换操作,在模型训练循环的评估部分,原始训练代码中,我们通过以下代码计算测试集上的正确预测总数:
python
total_correct += (predictions.eq(labels)).sum().item()需要将其替换为以下代码:
python
total_correct += accelerator.gather(predictions.eq(labels)).sum().item()gather 方法能聚合分布式计算中的正确预测结果,确保在分布式训练环境下跨多设备准确统计总正确预测数。
在分布式环境中,直接使用 predictions == labels 的操作可能效率较低,因为这涉及跨多设备的数据处理和同步。而 accelerator.gather(predictions.eq(labels)) 通过减少跨设备通信并高效聚合结果,对此过程进行了优化。
在本节中,我们简要介绍了 accelerate 库,以及如何轻松将其集成到 PyTorch 代码中以提升硬件利用效率。我们可以访问 Hugging Face 上的 accelerate 库页面,以深入了解如何在运行 PyTorch 时充分利用硬件。
在下一节中,我们将介绍 Hugging Face 的另一个库,Optimum,它能帮助我们在 PyTorch 模型推理阶段实现硬件性能的最大化。
5. 使用 Optimum 优化 PyTorch 模型部署
机器学习生命周期中,模型部署是关键环节。Hugging Face 的 Optimum 致力于简化 AI 模型跨平台、跨语言、跨框架、跨设备的部署复杂度,Optimum 还能帮助我们在部署前对模型进行优化。
在本节中,我们将从 Hugging Face Hub 获取一个预训练好的 PyTorch 模型,并将其转换为开放神经网络交换 (Open Neural Network Exchange, ONNX)格式,以便通过 ONNX 运行时 (ONNX Runtime) 进行推理,如下图所示。

ONNX Runtime 是由微软开发的开源高性能推理引擎,专门用于在各种硬件平台(如 Intel CPU、NVIDIA GPU、Jetson Nano、安卓手机等)上高效运行符合 ONNX 格式的模型。我们在模型部署一节已经学习了 ONNX。将 PyTorch 模型转换为 ONNX 格式可实现跨平台、框架无关的部署,并通过 Optimum 等库在不同硬件加速器上实现性能优化。
我们还将学习如何使用 Optimum 对 ONNX 模型进行量化,以牺牲少量精度为代价来减小模型体积。在每个优化步骤中,我们都会在固定样本输入上运行模型推理,确保模型优化不会改变其在给定输入下的输出结果。
量化是通过降低神经网络模型的参数和激活值的精度,来减少内存占用和计算复杂度的过程,同时尽量保持模型的性能和推理准确性。
(1) 在使用 Optimum 之前,首先需要安装以下依赖包:
shell
$ pip install onnx onnxruntime optimum(2) 首先,导入所需的库,用于加载预训练的 bert-base-uncased 文本分类模型( PyTorch 格式),以及将 BERT 模型转换为 ONNX 格式所需的 ORTModelForSequenceClassification 库:
python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from optimum.onnxruntime import ORTModelForSequenceClassification(3) 接下来,定义要从 Hugging Face Hub 下载的模型名称,并指定我们希望存储 ONNX 模型文件的目录:
python
model_name = "bert-base-uncased"
onnx_directory = "bert-base-uncased_onnx"(4) 从 Hugging Face Hub 加载预训练的 PyTorch 格式 BERT 模型:
python
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased", export=True)
model = AutoModelForSequenceClassification.from_pretrained(model_name)(5) 需要注意的是,我们在 tokenizer 初始化语句中添加了 export=True 参数,因为我们需要将从 Hugging Face Hub 加载的 tokenizer 保存到本地存储。现在通过以下代码验证加载的模型在样本输入上是否能正常运行:
python
input_ids = tokenizer("I love PyTorch!", return_tensors="pt")
model(**input_ids)输出结果如下所示:
shell
SequenceClassifierOutput(loss=None, logits=tensor([[-0.1089, -0.1465]], grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None)(6) 接下来,将加载的 PyTorch 模型转换为 ONNX 模型:
python
model_onnx = ORTModelForSequenceClassification.from_pretrained("bert-base-uncased", export=True)需要注意的是,本节我们仅用一行代码就将模型从 PyTorch 格式转换为 ONNX 格式,使用的是从 optimum.onnxruntime 库中导入的 ORTModelForSequenceClassification 类。相比之下,在模型部署一节中,我们使用多行代码来实现相同的格式转换。
(7) 获得 ONNX 模型后,通过以下代码验证该模型在相同示例输入上是否能正常运行:
python
model_onnx(**input_ids)输出结果如下所示,可以看到,ONNX 模型同样能正常运行:
shell
SequenceClassifierOutput(loss=None, logits=tensor([[ 0.0865, -0.0238]]), hidden_states=None, attentions=None)(8) 通过以下代码将 ONNX 模型保存到指定目录:
python
model_onnx.save_pretrained(onnx_directory)
tokenizer.save_pretrained(onnx_directory)(9) 在命令行中执行以下命令检查 ONNX 模型目录的内容:
python
!du -sh bert-base-uncased_onnx/*输出结果如下所示,可以看到当前 ONNX 模型大小约为 400MB:

(10) 借助 optimum 库,我们可以将 ONNX 模型量化为体积更小、速度更快的量化版本。首先需要导入量化所需的依赖项:
python
from optimum.onnxruntime.configuration import AutoQuantizationConfig
from optimum.onnxruntime import ORTQuantizer(11) 实现 ONNX 模型的量化处理:
python
qconfig = AutoQuantizationConfig.arm64(is_static=False, per_channel=False)
quantizer = ORTQuantizer.from_pretrained(model_onnx)
quantizer.quantize(save_dir=onnx_directory, quantization_config=qconfig)首先我们需要配置量化过程的相关参数设置,在本节中,我们将 is_static 设为 False,表示采用动态量化方案。动态量化是指在推理过程中对神经网络权重和激活值进行量化(无需重新训练模型),通过根据输入数据范围动态调整张量精度,实现内存和推理速度的优化。而静态量化则是在推理前(通常在训练期间或训练后)就对模型权重和激活值进行量化,预先固定精度级别以获得内存和计算效率。
(12) 以上代码将量化后的模型保存在原先的 ONNX 模型目录中。再次通过命令查看该目录中的内容:
python
!du -sh bert-base-uncased_onnx/*输出结果如下所示:

可以看到,目录中新增的 model_quantized.onnx 文件大小约为 100MB,仅为原始 ONNX 模型的四分之一。这表明通过 Optimum 的动态量化技术,我们成功将模型体积压缩了 75%。
(13) 接下来,将量化模型加载到新的 ONNX 模型对象中:
python
model_quantized = ORTModelForSequenceClassification.from_pretrained(onnx_directory, file_name="model.onnx")(14) 最后,检查量化后的模型是否能在样本输入上正常工作:
python
model_quantized(**input_ids)输出结果如下所示:
shell
SequenceClassifierOutput(loss=None, logits=tensor([[ 0.0865, -0.0238]]), hidden_states=None, attentions=None)可以看到,这个体积缩小 4 倍的量化模型与原始 ONNX 模型产生了完全一致的输出结果。
小结
在本节中,首先介绍了 PyTorch 开发者需要关注的 Hugging Face 核心组件。随后我们深入探讨了如何将 transformers 库与 PyTorch 结合使用。接着了解了预训练模型库 Hugging Face Hub,并通过 Hub 加载 BERT 模型进行推理。还探索了 datasets 数据集库,通过微调预训练模型的实例掌握其与 PyTorch 的配合使用方法。
接着,我们了解了 Hugging Face 的 accelerate 库,及其如何仅通过五行代码的更改来加速 PyTorch 的训练代码。然后,探索了 Hugging Face 的 Optimum 库,并用它将一个 PyTorch 模型转换为 ONNX 模型,并通过 ONNX Runtime 执行推理。最终使用 Optimum 将 ONNX 模型量化为体积缩小 4 倍的版本,并验证了量化模型在 ONNX Runtime 上的推理效果。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术
PyTorch实战(16)------基于LSTM实现音乐生成
PyTorch实战(17)------神经风格迁移
PyTorch实战(18)------自编码器(Autoencoder,AE)
PyTorch实战(19)------变分自编码器(Variational Autoencoder,VAE)
PyTorch实战(20)------生成对抗网络(Generative Adversarial Network,GAN)
PyTorch实战(21)------扩散模型(Diffusion Model)
PyTorch实战(22)------MuseGAN详解与实现
PyTorch实战(23)------基于Transformer生成音乐
PyTorch实战(24)------深度强化学习
PyTorch实战(25)------使用PyTorch构建DQN模型
PyTorch实战(26)------PyTorch分布式训练
PyTorch实战(27)------自动混合精度训练
PyTorch实战(28)------PyTorch深度学习模型部署
PyTorch实战(29)------使用TorchServe部署PyTorch模型
PyTorch实战(30)------使用TorchScript和ONNX导出通用PyTorch模型
PyTorch实战(31)------在Android上部署PyTorch模型
PyTorch实战(32)------在iOS上构建PyTorch应用
PyTorch实战(33)------使用fastai进行快速原型开发
PyTorch实战(34)------基于PyTorch Lightning的跨硬件模型训练
PyTorch实战(35)------使用PyTorch Profiler分析模型推理性能
PyTorch实战(36)------PyTorch自动机器学习
PyTorch实战(37)------使用Optuna搜索最优超参数
PyTorch实战(38)------深度学习模型可解释性
PyTorch实战(39)------使用Captum解释深度学习模型
PyTorch实战(40)------使用PyTorch构建推荐系统