本文提供是一款通用化、高鲁棒性的 Hugging Face 模型缓存文件处理代码,能直接复制模型的缓存文件,成为通用的大模型权重。
- 核心能力:自动解析 Hugging Face snapshot 目录下的软链接,生成 "文件名→blobs 真实文件" 的映射关系,无需硬编码文件哈希 / 名称,适配任意 HF 缓存的模型(不再局限于特定 Qwen 模型)。
- 适配性:只要是 HF 标准缓存结构(snapshot+blobs),均可自动识别处理。
~/.cache/huggingface/hub目录是 Hugging Face transformers/datasets 库默认的模型 / 数据集权重缓存目录
首先看一下huggingface的权重缓存目录:
(base) lgp@lgp-Rack-Server:~/.cache/huggingface/hub$ ls
datasets--hiyouga--geometry3k models--OpenGVLab--InternVL3_5-1B-HF
models--google--siglip-so400m-patch14-384 models--Qwen--Qwen3-VL-2B-Instruct.tar
models--IDEA-Research--grounding-dino-tiny models--Qwen--Qwen3-VL-4B-Instruct
models--IDEA-Research--Rex-Omni models--Qwen--Qwen3-VL-4B-Instruct-FP8
models--laion--CLIP-ViT-B-32-laion2B-s34B-b79K models--THUDM--CogVideoX-5b-I2V
models--openai--clip-vit-base-patch32 version.txt
目录名的格式是 类型--作者/机构--模型/数据集名,其中 -- 是分隔符:
datasets--xxx:表示缓存的是数据集权重 / 文件models--xxx:表示缓存的是模型权重 / 文件
以models--Qwen--Qwen3-VL-4B-Instruct为例,看一下模型缓存目录里面具体的内容:
| 文件夹名 | 核心作用 |
|---|---|
blobs |
存储所有模型文件的原始二进制数据(以哈希值命名),是真正的文件内容存储区,每个文件对应一个唯一的哈希值(SHA-1/SHA-256),避免重复存储。 |
refs |
存储版本引用 (类似 Git 的分支 / 标签),指向 snapshots 中的具体版本,通常包含 main 等默认引用。 |
snapshots |
存储特定版本的模型文件结构 (以 commit hash 命名目录),里面的文件是指向 blobs 中哈希文件的软链接 / 硬链接,还原了标准的 Hugging Face 模型文件结构。 |
进入models--Qwen--Qwen3-VL-4B-Instruct/snapshots/目录中,看到"一个目录",比如ebb281ec70b05090aa6165b016eac8ec08e71b17
看到的 snapshots/ebb281ec70b05090aa6165b016eac8ec08e71b17/ 是该模型的一个具体版本(ebb281ec... 是 commit hash),里面的文件是 Qwen3-VL-4B-Instruct 模型的核心组件:
| 文件名 | 作用 |
|---|---|
config.json |
模型核心配置文件,包含模型架构(如层数、隐藏维度、注意力头数)、归一化方式、多模态配置等关键参数。 |
generation_config.json |
生成式任务默认配置,包含温度(temperature)、top_k、max_new_tokens 等文本生成参数。 |
chat_template.json |
对话模板配置,定义多轮对话的格式(如用户 / 助手消息的包装方式),适配 OpenAI 风格的聊天接口。 |
model-00001-of-00002.safetensors``model-00002-of-00002.safetensors |
模型权重文件(分 2 个分片),采用 safetensors 格式(安全、快速的权重存储格式,替代传统的 .bin),包含模型所有层的参数。 |
model.safetensors.index.json |
权重分片索引文件,记录每个分片包含的权重参数范围,方便加载时拼接。 |
tokenizer_config.json |
分词器配置文件,定义分词器类型(Qwen 自定义分词器)、特殊符号、最大长度等。 |
tokenizer.json |
分词器的核心词典文件,包含所有词汇的编码 / 解码映射关系。 |
vocab.json |
基础词汇表,补充分词器的核心词汇映射。 |
merges.txt |
BPE(字节对编码)合并规则文件,定义分词器的词汇合并逻辑。 |
preprocessor_config.json``video_preprocessor_config.json |
多模态预处理配置,定义图像 / 视频的预处理规则(如尺寸、归一化均值 / 方差、裁剪方式),是 VL(视觉 - 语言)模型的核心配置。 |
- blobs 目录的哈希文件 :
snapshots中的.safetensors、.json等文件本质是指向blobs中对应哈希文件的链接(硬链接 / 符号链接),Hugging Face 用这种方式实现:① 文件内容去重(多个版本共用相同内容的文件);② 版本追溯(每个 snapshot 对应一个固定的文件集合)。 - 分片权重文件 :模型权重分为 2 个分片(
00001-of-00002/00002-of-00002),是因为 4B 参数量的模型权重文件较大(单文件约 8GB 左右),分片便于传输和存储,加载时transformers库会自动拼接。 - 多模态特性 :
video_preprocessor_config.json说明该模型不仅支持图像,还支持视频输入,是 Qwen3-VL 的核心特性之一。

实现源代码:
python
#!/usr/bin/env python3
"""
通用版:从Hugging Face缓存复制/创建软链接到指定目录
支持自动解析snapshot中的软链接,无需硬编码文件映射
"""
import os
import shutil
from pathlib import Path
import argparse
from typing import Dict, List, Tuple
def validate_snapshot_dir(snapshot_dir: Path) -> bool:
"""
验证是否为有效的Hugging Face snapshot目录
"""
if not snapshot_dir.exists():
print(f"错误:snapshot目录不存在 - {snapshot_dir}")
print("提示:请检查默认路径是否正确,或通过 -s/--source 指定正确的snapshot目录")
return False
if not snapshot_dir.is_dir():
print(f"错误:不是有效的目录 - {snapshot_dir}")
return False
# 检查blobs目录是否存在
blobs_dir = snapshot_dir.parent.parent / "blobs"
if not blobs_dir.exists():
print(f"错误:blobs目录不存在 - {blobs_dir}")
return False
# 检查目录下是否有软链接文件(Hugging Face缓存的特征)
has_symlinks = any(file.is_symlink() for file in snapshot_dir.iterdir() if file.is_file())
if not has_symlinks:
print(f"警告:该目录未检测到Hugging Face缓存特征的软链接文件")
return True
def parse_symlink_mappings(snapshot_dir: Path) -> Tuple[Dict[str, Path], Path]:
"""
自动解析snapshot目录中的软链接,生成文件名称到blobs文件的映射
返回:(文件映射字典, blobs目录路径)
"""
# 获取blobs目录路径
blobs_dir = snapshot_dir.parent.parent / "blobs"
# 遍历snapshot目录下的所有文件,解析软链接
file_mappings = {}
for file_path in snapshot_dir.iterdir():
# 只处理文件,跳过目录
if not file_path.is_file():
continue
# 只处理软链接文件(Hugging Face缓存的文件都是软链接到blobs)
if file_path.is_symlink():
# 获取软链接指向的真实路径
real_path = file_path.resolve()
# 只处理指向blobs目录的软链接
if blobs_dir in real_path.parents:
file_mappings[file_path.name] = real_path
if not file_mappings:
print("警告:未解析到任何有效的软链接文件映射")
return file_mappings, blobs_dir
def process_files(
file_mappings: Dict[str, Path],
target_dir: Path,
use_symlink: bool = False
) -> Tuple[List[str], List[str]]:
"""
处理文件:复制文件或创建软链接
参数:
file_mappings: 文件名到源文件路径的映射
target_dir: 目标目录
use_symlink: 是否创建软链接(False则复制文件)
返回:(成功的文件列表, 失败的文件列表)
"""
target_dir.mkdir(parents=True, exist_ok=True)
copied_files = []
failed_files = []
for target_name, source_file in file_mappings.items():
target_file = target_dir / target_name
# 检查源文件是否存在
if not source_file.exists():
print(f"警告:源文件不存在: {source_file}")
failed_files.append(target_name)
continue
try:
action = "创建软链接" if use_symlink else "复制"
print(f"{action}: {target_name}")
print(f" 从: {source_file}")
print(f" 到: {target_file}")
# 先删除已存在的目标文件(避免冲突)
if target_file.exists():
if target_file.is_symlink() or target_file.is_file():
target_file.unlink()
else:
print(f" ✗ 错误:目标路径是目录,无法覆盖")
failed_files.append(target_name)
continue
if use_symlink:
# 创建软链接
target_file.symlink_to(source_file)
# 验证软链接
if target_file.is_symlink() and target_file.resolve().exists():
print(f" ✓ 完成 (软链接)")
copied_files.append(target_name)
else:
print(f" ✗ 错误:软链接创建失败")
failed_files.append(target_name)
else:
# 复制文件(保留元数据)
shutil.copy2(source_file, target_file)
# 验证文件大小
source_size = source_file.stat().st_size
target_size = target_file.stat().st_size
if source_size == target_size:
size_gb = source_size / (1024**3)
print(f" ✓ 完成 ({size_gb:.2f} GB)")
copied_files.append(target_name)
else:
print(f" ✗ 错误:文件大小不匹配!")
failed_files.append(target_name)
except Exception as e:
print(f" ✗ {action}失败: {e}")
failed_files.append(target_name)
print()
return copied_files, failed_files
def main():
"""主函数:处理命令行参数并执行核心逻辑"""
# 定义默认的source路径
DEFAULT_SOURCE = "/home/user/.cache/huggingface/hub/models--Qwen--Qwen3-VL-4B-Instruct/snapshots/ebb281ec70b05090aa6165b016eac8ec08e71b17"
# 解析命令行参数
parser = argparse.ArgumentParser(description='从Hugging Face缓存复制/创建软链接到指定目录')
parser.add_argument('--source', '-s', type=str, default=DEFAULT_SOURCE,help=f'Hugging Face snapshot目录路径(默认:{DEFAULT_SOURCE})')
parser.add_argument('--output', '-o', type=str, default='./Qwen3-VL-4B-Instruct-raw',help='输出目录路径(默认:./hf_model_weights)')
parser.add_argument('--symlink', '-l', action='store_true',help='创建软链接而非复制文件(节省磁盘空间)')
args = parser.parse_args()
# 路径处理
source_dir = Path(args.source).resolve()
target_dir = Path(args.output).resolve()
# 验证源目录
if not validate_snapshot_dir(source_dir):
exit(1)
# 解析软链接映射
print(f"源目录: {source_dir}")
print(f"目标目录: {target_dir}")
print(f"操作模式: {'创建软链接' if args.symlink else '复制文件'}")
print("-" * 50)
file_mappings, blobs_dir = parse_symlink_mappings(source_dir)
print(f"解析到 {len(file_mappings)} 个文件需要处理")
print("-" * 50)
# 处理文件
copied_files, failed_files = process_files(file_mappings, target_dir, args.symlink)
# 打印总结
print("=" * 50)
print("操作完成!")
print(f"成功处理: {len(copied_files)}/{len(file_mappings)} 个文件")
if copied_files:
print("已处理的文件:")
for f in sorted(copied_files):
print(f" ✓ {f}")
if failed_files:
print("失败的文件:")
for f in sorted(failed_files):
print(f" ✗ {f}")
print(f"\n模型文件已保存到: {target_dir.absolute()}")
if __name__ == "__main__":
main()代码参数说明:
--source/-s:可选参数,预设 Qwen3-VL-4B-Instruct 的缓存路径为默认值,也可手动指定任意 snapshot 目录,兼顾易用性和灵活性;--output/-o:可选参数,默认输出到./Qwen3-VL-4B-Instruct-raw,支持自定义目标目录;--symlink/-l:开关参数,默认复制文件,显式指定则创建软链接(大幅节省磁盘空间)。
特点:
- 复制模式(默认):使用
shutil.copy2复制文件并保留元数据,验证源 / 目标文件大小一致性,确保文件完整; - 软链接模式:创建指向原缓存文件的软链接,避免大文件重复存储,操作后验证软链接有效性。
- 异常捕获:捕获文件复制 / 链接过程中的通用异常,记录失败文件并给出具体错误信息;
运行信息:
==================================================
操作完成!
成功处理: 12/12 个文件
已处理的文件:
✓ chat_template.json
✓ config.json
✓ generation_config.json
✓ merges.txt
✓ model-00001-of-00002.safetensors
✓ model-00002-of-00002.safetensors
✓ model.safetensors.index.json
✓ preprocessor_config.json
✓ tokenizer.json
✓ tokenizer_config.json
✓ video_preprocessor_config.json
✓ vocab.json
模型文件已保存到: /home/lgp/model_path/Qwen3-VL-4B-Instruct-raw
看到复制后的权重文件:
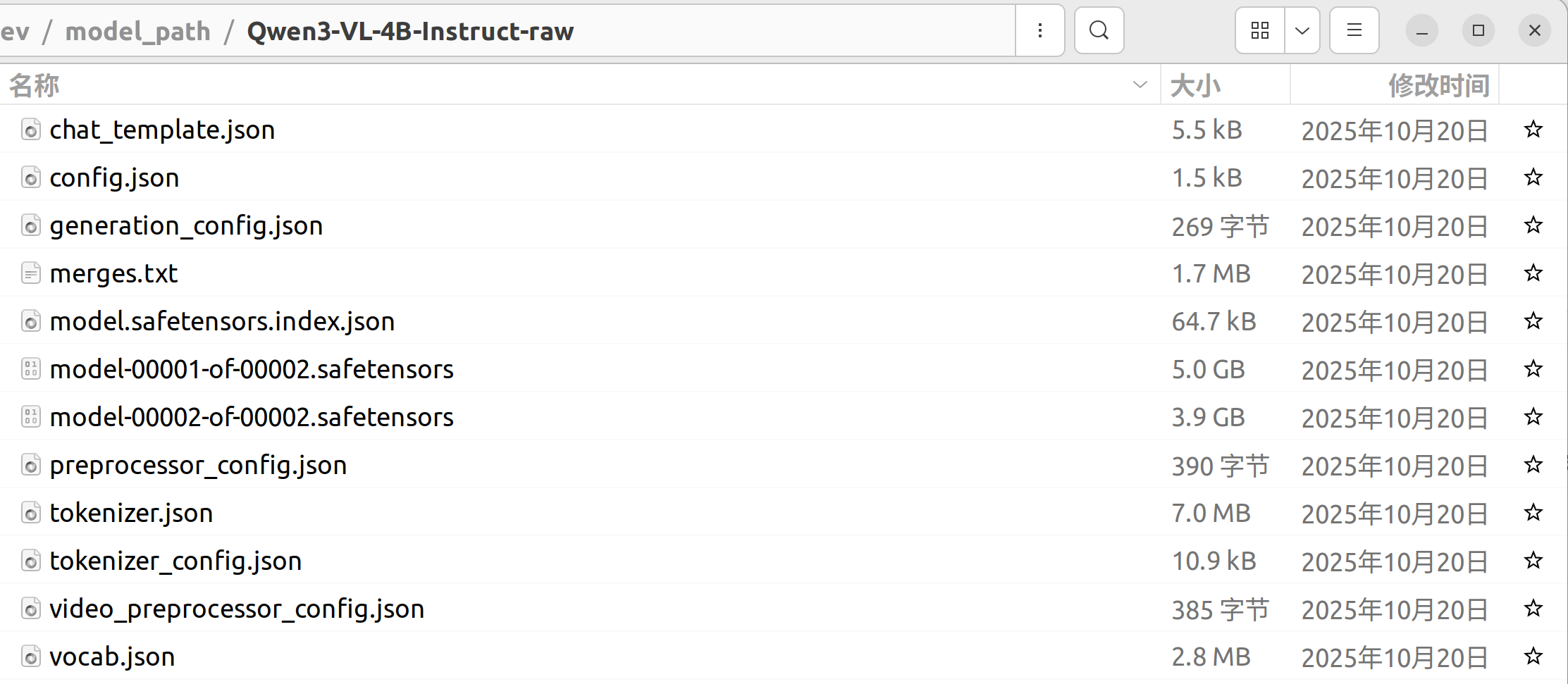
分享完成~