
【HuggingFace】开源 AI 界的"GitHub"------从平台介绍到明星模型一文搞懂
本文系统梳理 HuggingFace 平台的核心功能与生态,并选取若干典型模型做简要说明,适合初次接触的读者建立全局认知。
文章目录
- [【HuggingFace】开源 AI 界的"GitHub"------从平台介绍到明星模型一文搞懂](#【HuggingFace】开源 AI 界的"GitHub"——从平台介绍到明星模型一文搞懂)
- [1. 什么是 HuggingFace](#1. 什么是 HuggingFace)
- [2. 平台核心模块](#2. 平台核心模块)
-
- [2.1 Model Hub(模型库)](#2.1 Model Hub(模型库))
- [2.2 Datasets(数据集库)](#2.2 Datasets(数据集库))
- [2.3 Spaces(应用演示)](#2.3 Spaces(应用演示))
- [2.4 Transformers 库](#2.4 Transformers 库)
- [3. 几个绕不开的核心概念](#3. 几个绕不开的核心概念)
-
- [3.1 Pipeline](#3.1 Pipeline)
- [3.2 Tokenizer](#3.2 Tokenizer)
- [3.3 AutoModel](#3.3 AutoModel)
- [4. 明星模型一览](#4. 明星模型一览)
-
- [4.1 BERT --- NLP 时代的奠基之作](#4.1 BERT — NLP 时代的奠基之作)
- [4.2 GPT-2 --- 生成式语言模型的早期里程碑](#4.2 GPT-2 — 生成式语言模型的早期里程碑)
- [4.3 T5 --- "万事皆 Seq2Seq"](#4.3 T5 — "万事皆 Seq2Seq")
- [4.4 ViT --- Transformer 杀进计算机视觉](#4.4 ViT — Transformer 杀进计算机视觉)
- [4.5 CLIP --- 视觉与语言的桥梁](#4.5 CLIP — 视觉与语言的桥梁)
- [4.6 Stable Diffusion --- 文生图的"爆款担当"](#4.6 Stable Diffusion — 文生图的"爆款担当")
- [4.7 Llama 系列 --- 开源大语言模型的主力军](#4.7 Llama 系列 — 开源大语言模型的主力军)
- [4.8 Whisper --- 语音识别的开源天花板](#4.8 Whisper — 语音识别的开源天花板)
- [5. 快速上手------用 Pipeline 三行代码跑起来](#5. 快速上手——用 Pipeline 三行代码跑起来)
- [6. 与哪些公司合作](#6. 与哪些公司合作)
- [7. 总结](#7. 总结)
1. 什么是 HuggingFace
HuggingFace(官网:https://huggingface.co)成立于 2016 年,最初做的是一个聊天机器人 app,后来转型专注 NLP 开源工具链,一跃成为 AI 开源社区的核心枢纽。
总部:
- New York City
创始人:
- Clément Delangue(CEO)
- Julien Chaumond
- Thomas Wolf
如果用一句话概括它的定位:它是 AI 模型界的 GitHub。
- 你可以在上面 host 模型(push / pull,和 git 几乎一致的操作体验)
- 你可以 fork 别人的模型,fine-tune 之后再发布回去
- 有完整的 issue 讨论区,有 star、like 系统
- 截至 2025 年,平台上已有超过 100 万个 公开模型、20 万个数据集
不夸张地说,现在 AI 领域发论文,不把模型传到 HuggingFace 上几乎等同于"没有开源"。
2. 平台核心模块
2.1 Model Hub(模型库)
地址:https://huggingface.co/models
这是 HuggingFace 的核心资产。每个模型页面都包含:
- Model Card:说明文档,包括用途、训练数据、局限性、使用示例
- Files and versions :实际权重文件(
.safetensors/.bin)、配置文件(config.json)、tokenizer 文件等 - Inference API:右侧栏可以直接在网页上测试模型推理,不需要本地环境
- Spaces 示例:指向相关的可交互 demo(都是别人基于这个模型构建的应用,点进去可以直接在浏览器里体验)
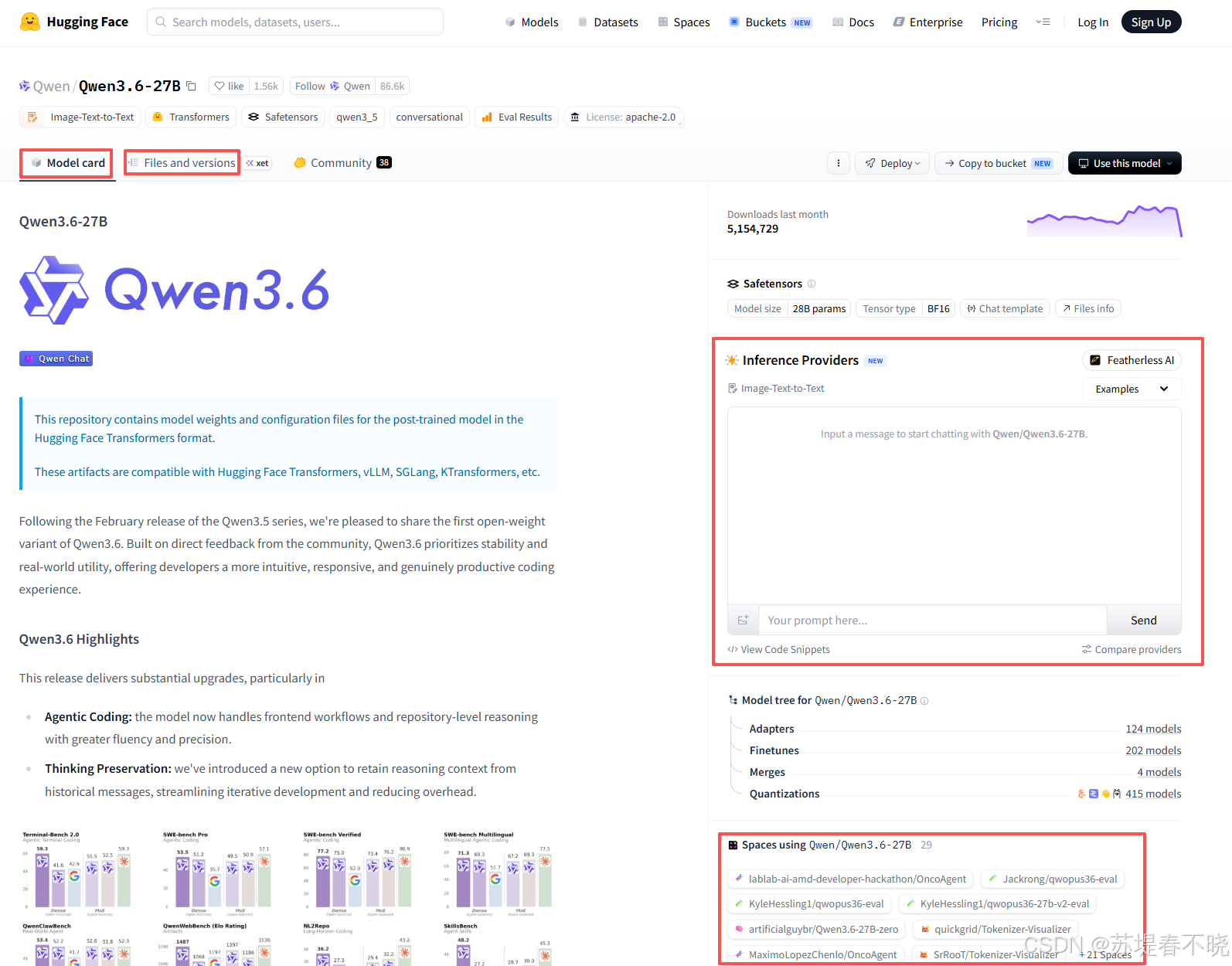
模型可以按任务类型筛选,常见的 task 有:
| 任务类型 | 举例 |
|---|---|
| text-generation | GPT-2、Llama |
| fill-mask | BERT、RoBERTa |
| image-classification | ViT、ResNet |
| text-to-image | Stable Diffusion |
| automatic-speech-recognition | Whisper |
| zero-shot-classification | CLIP |
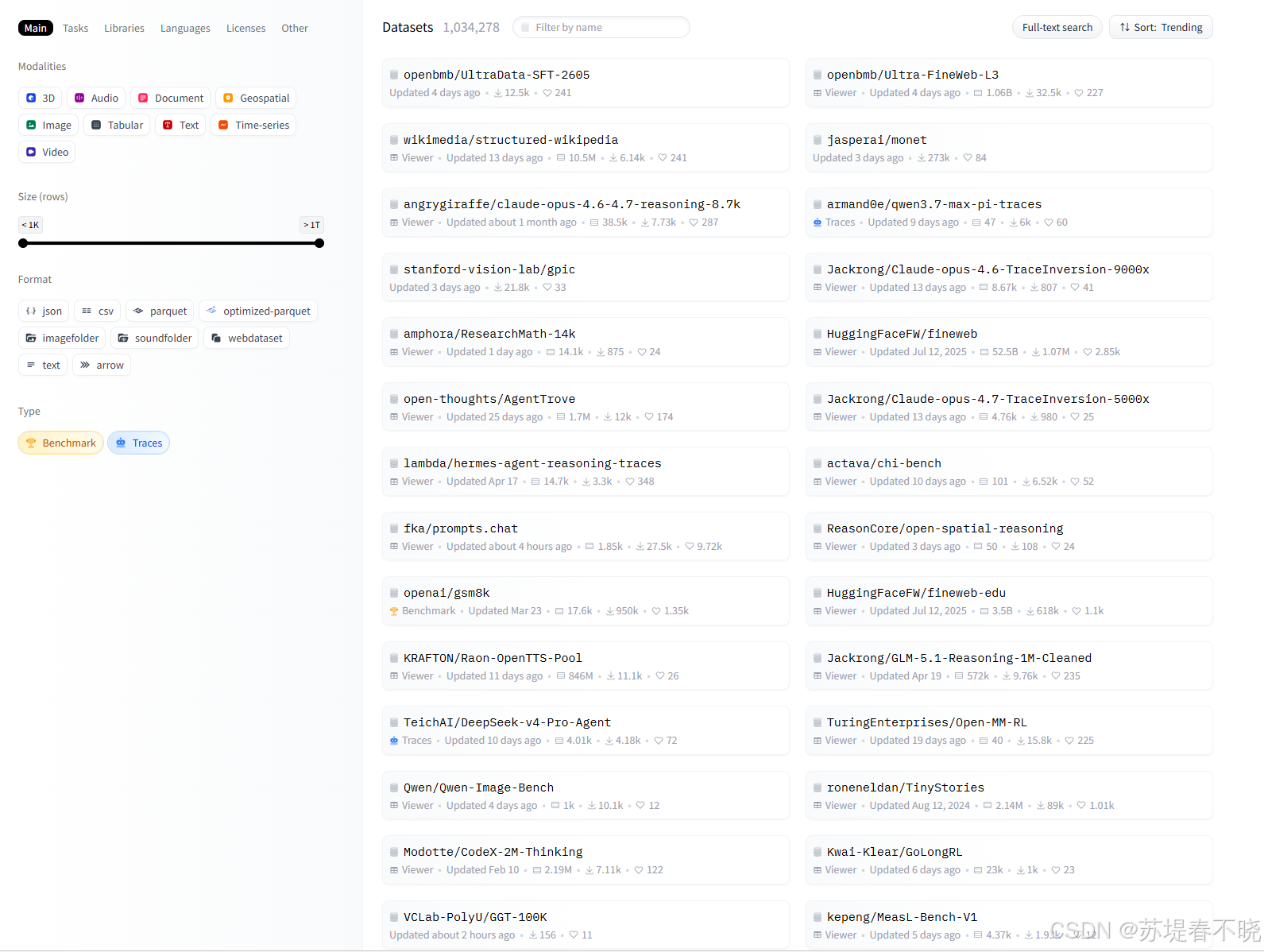
2.2 Datasets(数据集库)
地址:https://huggingface.co/datasets
与 Model Hub 同构,专门存放数据集。可以一行代码加载:
python
from datasets import load_dataset
dataset = load_dataset("squad")支持流式加载(streaming=True),这对几百 GB 的大数据集来说尤其重要------不需要把整个数据集下到本地,按需读取。
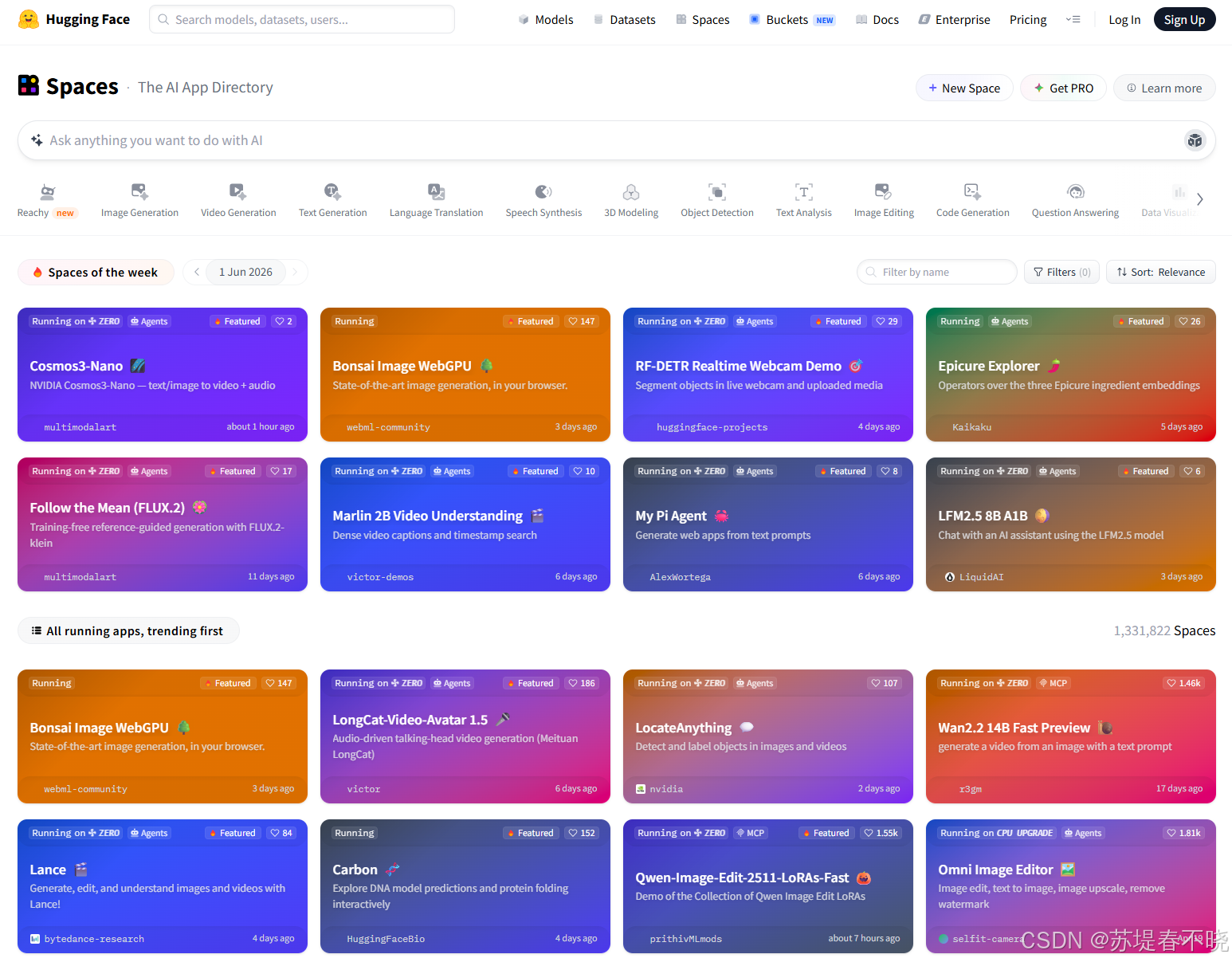
2.3 Spaces(应用演示)
地址:https://huggingface.co/spaces
Spaces 是托管交互式 demo 的地方,底层支持 Gradio 和 Streamlit 两种框架。
说白了就是:你训练好模型,写几行 Gradio 代码,推到 Spaces,任何人都可以在浏览器里实时跑你的模型。免费版有 CPU 资源,也可以付费挂 GPU。
对于学术界来说,这是一个极其低成本的"开源 demo"方案。
2.4 Transformers 库
这是 HuggingFace 最核心的 Python 库,GitHub 地址:https://github.com/huggingface/transformers
bash
pip install transformers它的设计理念是:统一的 API,覆盖几乎所有主流模型。
不管你用 BERT 还是 Llama,不管做文本分类还是图像生成,调用方式都相当一致。这大大降低了上手成本。
3. 几个绕不开的核心概念
3.1 Pipeline
pipeline 是最高层的抽象,把"加载模型 + 预处理 + 推理 + 后处理"全部打包了。
python
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
result = classifier("I love HuggingFace!")
# [{'label': 'POSITIVE', 'score': 0.9998}]三行代码,模型自动下载,推理结果直接拿到。对于快速验证想法来说非常方便。
当然,pipeline 背后做了很多事情------tokenize、forward pass、decode------只是帮你藏起来了。
3.2 Tokenizer
Tokenizer 负责把原始文本转换成模型能理解的 token id 序列。不同模型的 tokenizer 不一样(BERT 用 WordPiece,GPT 系列用 BPE),所以要和模型配套使用。
python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
inputs = tokenizer("Hello, HuggingFace!", return_tensors="pt")
# {'input_ids': tensor([[...]]), 'attention_mask': tensor([[...]])}3.3 AutoModel
AutoModel 系列类根据 config.json 里的 model_type 字段,自动推断并加载对应的模型架构,不需要你手动指定是 BertModel 还是 GPT2Model。
python
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-uncased")常见的 Auto 类还有:AutoModelForSequenceClassification、AutoModelForCausalLM、AutoModelForSeq2SeqLM 等,按任务选即可。
4. 明星模型一览
下面选取几个在社区中影响力极大的模型,简要介绍其背景与特点。
4.1 BERT --- NLP 时代的奠基之作
- 来源:Google,2018 年,NAACL Best Paper
- 论文 :BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- HuggingFace 地址 :
bert-base-uncased
BERT 的核心创新是 双向 Transformer Encoder + Masked Language Model (MLM) 预训练任务。
区别于 GPT 的单向(从左到右)语言模型,BERT 在预训练时同时看左边和右边的上下文,因此对理解类任务(分类、问答、NER)特别有效。
预训练任务:
- MLM:随机 mask 掉 15% 的 token,让模型预测被 mask 的词
- NSP(Next Sentence Prediction):判断两个句子是否相邻
BERT 出来之后,把当时 NLP 各项 benchmark 几乎全刷新了一遍,影响深远。
变体:RoBERTa(去掉 NSP,更大数据,更长训练)、ALBERT(参数共享,更轻量)、DistilBERT(知识蒸馏,速度提升 60%)。
4.2 GPT-2 --- 生成式语言模型的早期里程碑
- 来源:OpenAI,2019 年
- 论文 :Language Models are Unsupervised Multitask Learners
- HuggingFace 地址 :
gpt2
GPT-2 是 Decoder-only 架构,使用标准的 Causal Language Modeling (CLM) 预训练------即从左到右预测下一个 token。
当时 OpenAI 以"模型太危险"为由分批次发布,反倒引发了巨大关注。现在来看,GPT-2 的能力放在今天只是个入门水平,但它为后来的 GPT-3、ChatGPT 铺好了路。
参数规模从 117M 到 1.5B,HuggingFace 上有完整的 gpt2、gpt2-medium、gpt2-large、gpt2-xl 四个版本。
4.3 T5 --- "万事皆 Seq2Seq"
- 来源:Google,2019 年
- 论文 :Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- HuggingFace 地址 :
t5-base
T5 的核心思路非常优雅:把所有 NLP 任务统一成文本到文本的格式。
- 翻译:
translate English to French: The cat sat on the mat. - 摘要:
summarize: <长文本> - 分类:
sentiment: This movie is great.→positive
说白了就是,不管什么任务,输入是文本,输出也是文本,模型结构始终是 Encoder-Decoder。这个统一范式极大地简化了多任务学习的复杂度。
T5 在 C4(Colossal Clean Crawled Corpus)上预训练,参数规模从 60M(small)到 11B(11B 版本)。
4.4 ViT --- Transformer 杀进计算机视觉
- 来源:Google,2020 年,ICLR 2021
- 论文 :An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- HuggingFace 地址 :
google/vit-base-patch16-224
ViT 把图像切成若干 16×16 的 patch,每个 patch 展平后线性投影成一个 token embedding,然后直接喂给标准的 Transformer Encoder。
- 位置编码用可学习的 1D positional embedding
- 在序列头部加一个
[CLS]token,其最终输出用于分类 - 在足够大的数据(JFT-300M)上预训练后,效果超越了同期 CNN
ViT 的出现打破了"Transformer 只适合 NLP"的固有印象,此后 Swin Transformer、DeiT、BEiT 等一大批视觉 Transformer 相继涌现。
4.5 CLIP --- 视觉与语言的桥梁
- 来源:OpenAI,2021 年
- 论文 :Learning Transferable Visual Models From Natural Language Supervision
- HuggingFace 地址 :
openai/clip-vit-base-patch32
CLIP 的思路是:用自然语言监督来训练图像编码器。
训练数据是从互联网爬取的 4 亿张图文对,训练目标是对比学习(Contrastive Learning)------让配对的图文 embedding 相互靠近,不配对的相互远离。
这样训练出来的模型有一个惊人的性质:zero-shot 图像分类。不需要任何微调,只需要把类别名称写成文本(比如 "a photo of a cat"),计算图像和所有类别文本的相似度,取最高的即为预测类别。
CLIP 后来成了众多多模态模型的视觉 backbone,包括 Stable Diffusion 里的文本编码部分就用了 CLIP 的文本编码器。
4.6 Stable Diffusion --- 文生图的"爆款担当"
- 来源:Stability AI + CompVis + LAION,2022 年
- 论文 :High-Resolution Image Synthesis with Latent Diffusion Models
- HuggingFace 地址 :
stabilityai/stable-diffusion-2-1
Stable Diffusion 是一个 Latent Diffusion Model(LDM)。区别于在像素空间做扩散的 DALL-E,它在潜空间(latent space)里做扩散,大幅降低了计算量。
核心组件:
- VAE(Variational Autoencoder):把图像压缩到 latent,推理时再解码回像素
- U-Net:在 latent 上做去噪(denoising)
- CLIP Text Encoder:把文本 prompt 编码成条件向量,注入 U-Net 的 cross-attention
它是首个真正意义上让普通消费级 GPU(8GB 显存)能跑起来的高质量文生图模型,开源后社区爆炸式增长,WebUI、ComfyUI、LoRA 微调等生态迅速形成。
4.7 Llama 系列 --- 开源大语言模型的主力军
- 来源:Meta AI,Llama 1(2023)→ Llama 2(2023)→ Llama 3(2024)
- HuggingFace 地址 :
meta-llama/Meta-Llama-3-8B
Llama 系列是当前开源 LLM 生态的绝对主力。
Llama 2 有 7B / 13B / 70B 三个规模,Llama 3 进一步提升了数据质量和上下文长度(8K → 128K tokens for Llama 3.1)。
架构上的改进点(相比原始 Transformer):
- RoPE(Rotary Position Embedding):相对位置编码,更好地外推到长序列
- SwiGLU 激活函数:替换 FFN 里的 ReLU,性能更好
- GQA(Grouped Query Attention):在多头注意力上引入分组,减少 KV cache 显存
Llama 的出现带动了 Mistral、Qwen、DeepSeek 等大量中文社区开源模型的跟进,形成了以 Llama 架构为核心的开源 LLM 生态。
4.8 Whisper --- 语音识别的开源天花板
- 来源:OpenAI,2022 年
- 论文 :Robust Speech Recognition via Large-Scale Weak Supervision
- HuggingFace 地址 :
openai/whisper-large-v3
Whisper 用 68 万小时的多语种音频数据(含多语言字幕)做弱监督训练,模型是标准的 Encoder-Decoder Transformer。
输入:音频的 log-Mel spectrogram(80 维,30 秒窗口)
输出:转录文本,同时支持语言检测、时间戳对齐、翻译
参数规模从 39M(tiny)到 1.55B(large-v3),在多语言 ASR 上效果极强,中文识别质量在开源模型里属于第一梯队。
5. 快速上手------用 Pipeline 三行代码跑起来
安装依赖:
bash
pip install transformers torch文本情感分类:
python
from transformers import pipeline
pipe = pipeline("sentiment-analysis")
print(pipe("HuggingFace is amazing!"))
# [{'label': 'POSITIVE', 'score': 0.9998}]文本生成:
python
pipe = pipeline("text-generation", model="gpt2")
print(pipe("Once upon a time", max_length=50))语音识别:
python
pipe = pipeline("automatic-speech-recognition", model="openai/whisper-base")
result = pipe("audio.mp3")
print(result["text"])图像分类:
python
pipe = pipeline("image-classification", model="google/vit-base-patch16-224")
result = pipe("cat.jpg")
print(result)模型第一次运行会自动下载到本地缓存(默认在 ~/.cache/huggingface/),后续直接从缓存加载。
6. 与哪些公司合作
Hugging Face 与许多大型科技公司和研究机构合作,包括:
许多知名开源模型都会首先或同步发布到 Hugging Face,例如:
- Llama
- Qwen
- DeepSeek
- Mistral
- Gemma
从当前 AI 开源生态来看,Hugging Face 已经成为全球最大的开源 AI 模型社区和模型分发平台之一。
7. 总结
| 模型 | 机构 | 任务 | 核心创新 |
|---|---|---|---|
| BERT | NLU(Natural Language Understanding) | 双向 Encoder + MLM 预训练 | |
| GPT-2 | OpenAI | 文本生成 | Decoder-only,自回归语言模型 |
| T5 | 多任务 NLP | 统一 Seq2Seq 范式 | |
| ViT | 图像分类 | 图像 patch 当 token | |
| CLIP | OpenAI | 多模态 | 图文对比学习,zero-shot 分类 |
| Stable Diffusion | Stability AI | 文生图 | Latent Diffusion Model |
| Llama 3 | Meta | LLM | 高质量开源大语言模型 |
| Whisper | OpenAI | 语音识别 | 大规模弱监督多语言 ASR |
HuggingFace 不只是一个模型托管平台,更是整个开源 AI 生态的基础设施。无论是做研究、工程落地,还是学习入门,熟悉它的使用都是绕不过去的一步。
参考资料:
- HuggingFace 官方文档
- Transformers 官方 GitHub
- BERT 论文:Devlin et al., 2018
- T5 论文:Raffel et al., 2019
- ViT 论文:Dosovitskiy et al., 2020
- CLIP 论文:Radford et al., 2021
- Whisper 论文:Radford et al., 2022
- LDM 论文:Rombach et al., 2022