前言
随着物联网应用不断深入,边缘计算正从局部试点走向规模化落地。对企业而言,挑战已不再只是"能否将数据采集上来",而是如何在节点分布广泛、资源条件受限、网络环境复杂的情况下,构建一套能够稳定运行、持续演进的云边协同体系。
在这一过程中,真正制约规模化落地的核心瓶颈,往往不是单个节点的性能上限,而是边云之间能否高效、稳定地完成大规模数据同步,同时将资源消耗控制在边端设备可承受的范围之内。这一问题如果解决不好,边缘计算就很难从"局部跑通"真正走向"大规模复制"。
作为高性能实时分析平台,DolphinDB 在云边协同场景中,围绕这一核心问题提供了系统性支撑。本文将从部署可行性、同步性能与资源控制两个维度展开分析,并结合机器人巡检场景的实测数据加以验证。
核心痛点:边云数据同步
边缘计算进入规模化阶段后,单个节点能否跑通已不再是主要问题,真正的挑战在于大量节点能否在复杂环境下持续稳定运行,以及边端持续产生的数据能否高效同步至云端用于集中分析。
这背后有几个相互关联的约束:边端设备通常算力有限,无法承担过重的中间件和组件堆叠;网络条件不稳定,传输带宽往往受限;同时,云端需要实时接收来自多个边缘节点的数据,对同步效率有较高要求。在这种条件下,边云数据同步的性能与资源开销,直接决定了方案能否在更多节点、更多场景中被稳定复制。
统一架构,降低部署门槛
边云数据同步要真正落地,首先要解决"能不能部署下去"的问题。如果平台本身依赖过多组件,或者云端与边端需要维护两套完全不同的技术体系,无论同步性能多高,大规模现场落地都会面临巨大的部署和运维压力。
DolphinDB 在这一点上的优势在于,云端与边端采用同一套技术底座------云端以集群形态承担数据汇聚与集中分析,边端以单机形态完成数据接入、本地处理和结果上送,部署形态不同,但底层技术体系保持一致。这样一来,开发人员无需在两套系统之间切换,运维思路也可以保持统一,从而有效控制规模化复制过程中的工程成本。
在边云数据交互上,DolphinDB 通过 RPC 机制实现同步与指令传递,支持压缩传输,无需额外引入复杂中间件。这对于需要在大量站点快速复制部署的边缘项目而言,意味着更低的环境依赖和更简洁的部署链路。
部署可行,是边云同步得以真正运转的前提。在这个基础之上,同步性能与资源控制才是方案能否持续运行的关键。
核心能力:高效同步与可控的资源消耗
在边端数据持续产生、云端需要实时接收的场景下,同步机制的设计直接影响整体性能。
DolphinDB 通过流表订阅实时捕获边端新增数据,结合 remoteRun 将压缩后的数据发送至云端,由云端解压入库,形成一条轻量而完整的同步链路。
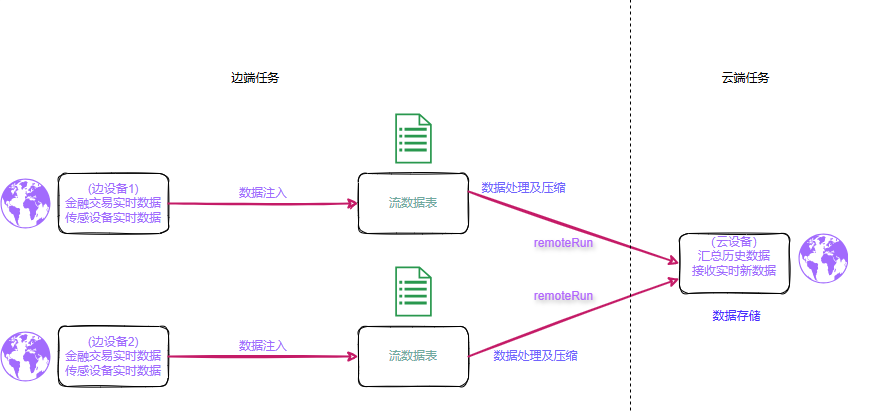
云边实时数据汇聚架构模型
在具体实现上,DolphinDB 支持 lz4 与 zstd 两种压缩方式,能够在保证传输效率的同时,有效降低对网络带宽的占用------这对网络条件不稳定或带宽受限的边缘场景尤为重要。
与此同时,DolphinDB 具备向量化执行能力,能够在有限的边端资源条件下提升计算效率,避免因本地处理压力过大而拖累同步性能。流批一体的处理框架也使得边端在完成实时过滤、聚合和异常识别等操作后,可以将结果直接推送至云端,缩短处理链路,降低整体延迟。
实测验证:机器人巡检场景下的边云同步性能
机器人巡检是边缘计算的典型应用场景之一。巡检机器人需要持续采集设备状态、环境参数及运行事件等数据,对异常情况进行实时识别与上报,同时将历史数据同步至云端用于集中存储和后续分析。这类场景对边云同步的实时性、稳定性和资源控制均有较高要求。
本次测试模拟了 100 个机器人连续 30 天的活动数据,共计 14,400,000 条,数据总量约 3.3 GB。测试使用两台物理服务器分别模拟云端与边端环境,边端持续写入数据并实时同步至云端,重点考察不同数据量条件下的传输性能及资源消耗表现。
硬件配置
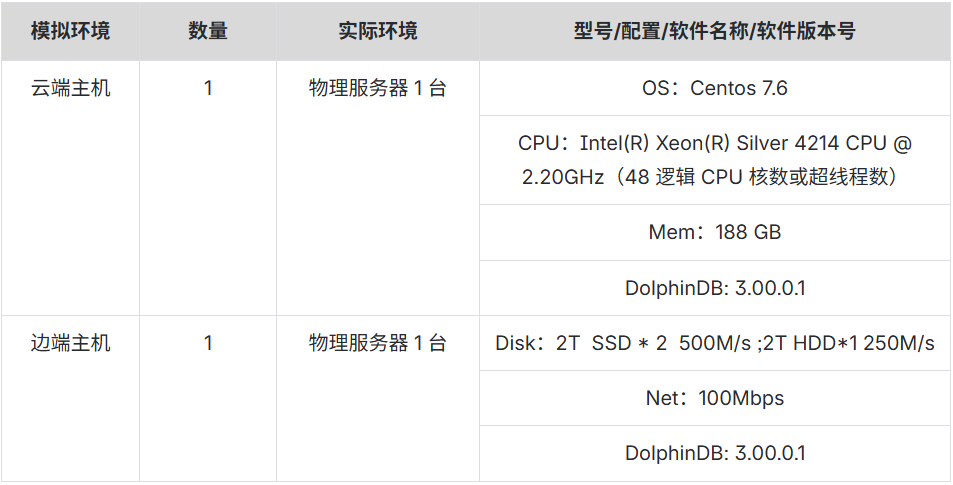
云端设备配置信息如下:
cpp
```ini
localSite=localhost:8848:local8848
mode=single
maxMemSize=32
maxConnections=512
workerNum=4
localExecutors=3
maxBatchJobWorker=4
dataSync=1
OLAPCacheEngineSize=2
TSDBCacheEngineSize=1
newValuePartitionPolicy=add
maxPubConnections=64
subExecutors=4
perfMonitoring=true
lanCluster=0
subThrottle=1
persistenceWorkerNum=1
maxPubQueueDepthPerSite=100000000为模拟边端设备资源受限的情况,边端设备配置为 4C8G,具体信息如下:
cpp
localSite=localhost:8848:local8848
mode=single
maxMemSize=8
maxConnections=512
workerNum=4
localExecutors=3
maxBatchJobWorker=4
dataSync=1
OLAPCacheEngineSize=2
TSDBCacheEngineSize=2
newValuePartitionPolicy=add
maxPubConnections=64
subExecutors=4
perfMonitoring=true
lanCluster=0
subThrottle=1
persistenceWorkerNum=1测试结果
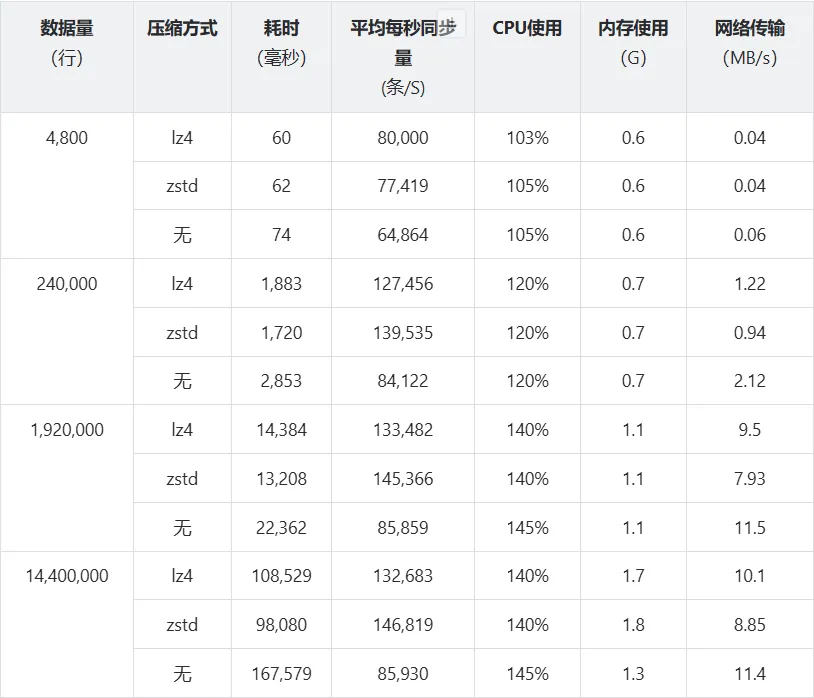
测试结论
从结果来看,有几点值得关注:
-
同步效率随数据量增大保持稳定。在数据量从 4,800 行扩展至 14,400,000 行的过程中,采用压缩方式的平均同步速率基本稳定在 13 万条/秒以上,说明 DolphinDB 在持续大规模数据传输场景下具备较好的性能稳定性。
-
压缩传输显著提升同步效率、降低带宽占用。与无压缩方式相比,lz4 和 zstd 均能将平均同步速率提升约 50%--70%,同时大幅降低网络带宽消耗。在 14,400,000 行的测试中,zstd 压缩下的网络占用(8.85 MB/s)仅为无压缩(11.4 MB/s)的约 78%,而同步速率反而更高。这对于网络带宽受限的边缘场景具有直接的实用价值。
-
资源消耗整体可控。各组测试中,CPU 使用率随数据量增大略有上升但幅度有限,内存占用在最大数据量下也仅为 1.7--1.8 GB,说明在资源受限的边端设备上,DolphinDB 的同步机制不会造成明显的资源压力,具备在实际边缘环境中稳定运行的基础。
结语
边缘计算的规模化,本质上是一个工程问题。单个节点跑通不难,难的是在几十、几百个节点上把同样的方案稳定复制下去,同时控制住每个节点的资源消耗和运维成本。
测试结果表明,在 100Mbps 网络、边端资源受限的条件下,DolphinDB 能够实现每秒 13 万条以上的稳定同步速率,资源消耗保持在可控范围内,压缩传输机制也有效降低了带宽压力。这些特性共同构成了边缘计算方案从试点走向规模化复制的基础支撑。
对于真正面临多节点、多站点部署挑战的企业而言,边云数据同步的效率与稳定性,往往是方案能否持续演进的关键所在。DolphinDB 在这一维度上所提供的平台化能力,正是其在边缘计算场景中的核心价值所在。