MYSQL
0. 数据库分类
数据库按以下维度分类:
- 关系型(SQL) --- MySQL, PostgreSQL, Oracle, SQL Server
- 非关系型(NoSQL):
- 文档型 --- MongoDB, CouchDB
- 键值型 --- Redis, DynamoDB
- 列族型 --- Cassandra, HBase
- 图数据库 --- Neo4j, ArangoDB
- 时序数据库 --- InfluxDB, TimescaleDB
- 搜索引擎 --- Elasticsearch, Meilisearch
- NewSQL --- CockroachDB, TiDB (兼具SQL与水平扩展)
- 嵌入式 --- SQLite, DuckDB
1.MySQL 基础架构与执行流程
执行引擎
SQL 查询执行过程
查询缓存在mysql8已经移除
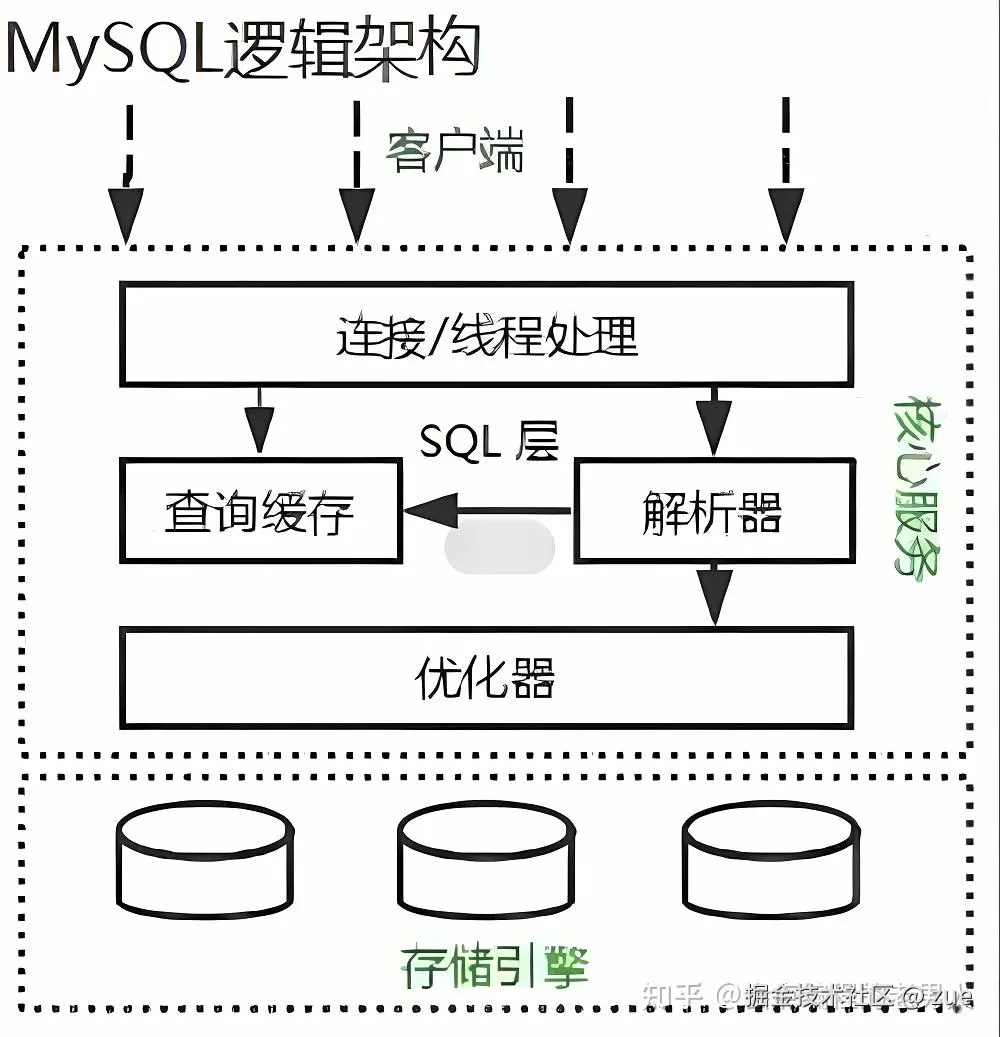
连接器、分析器、优化器、执行器
一个 SQL 查询经过的完整链路: 客户端 → 连接器 → 查询缓存(8.0移除) → 分析器 → 优化器 → 执行器 → 存储引擎 各阶段详解
- 连接器
- 管理连接,验证用户名密码
- 获取用户权限并缓存(连接生命周期内有效)
- 参数控制:wait_timeout、max_connections
- 查询缓存(MySQL 8.0 已完全移除)
- 之前版本中,以 key-value 形式缓存 SQL 及其结果集
- 表一旦有更新,该表所有缓存失效,命中率低
- 分析器(Parser)
- 词法分析:识别关键字(SELECT、FROM、WHERE)、表名、列名
- 语法分析:根据语法规则判断 SQL 是否合法,生成语法树
- 语法错误在此阶段报出(You have an error in your SQL syntax)
- 优化器(Optimizer)
- 决定使用哪个索引、多表 JOIN 顺序等执行策略
- 生成多个执行计划,基于代价估算选出最优
- 可通过 explain 查看最终选中的执行计划
- 执行器(Executor)
- 调用存储引擎接口,按执行计划逐行读取数据
- 权限校验也在这一步(连接时查权限,运行时校验)
- 将结果集返回给客户端
- 存储引擎(InnoDB)
- 真正负责数据的存储与读取
- 涉及缓存池(Buffer Pool)、redo log、undo log 等机制
- 对执行器提供 read/write 等底层接口
2.索引
索引数据结构(B+树 vs Hash)
MySQL 索引主要使用以下数据结构:
- B+ Tree(默认,最核心)
- InnoDB 和 MyISAM 的主键索引、普通索引默认结构
- 非叶子节点只存键值指针,叶子节点存全部数据/主键
- 叶子节点双向链表,支持范围查询(BETWEEN、>、<)和排序
- 高度通常 3-4 层,千万级数据只需 3-4 次 IO
- Hash(Memory 引擎默认,InnoDB 自适应)
- 精确等值查询极快(O(1)),但不支持范围查询和排序
- InnoDB 有自适应哈希索引(AHI):自动为频繁访问的热数据在内存中建立 hash 索引,对用户透明
- 全文索引(Full-Text,倒排索引)
- 用于 MATCH ... AGAINST 全文检索
- 本质是倒排索引,记录"词 → 文档"的映射关系
- InnoDB 从 MySQL 5.6 开始支持
补充:为什么不选其他结构?
- 二叉查找树:数据量大时树太高,IO 次数多
- 红黑树:同上,深度不可控
- B-Tree:非叶子节点也存数据,单节点能存的指针少,树更高;且范围查询需中序遍历效率低
聚簇索引 vs 二级索引
聚簇索引(Clustered Index)
- InnoDB 中主键索引就是聚簇索引
- 叶子节点存储整行数据,数据即索引,索引即数据
- 每个表只有一个聚簇索引
- 逻辑顺序与物理存储顺序一致(近似有序) 主键选择策略:自增整型 > 业务唯一字段 > 隐式 row_id 二级索引(Secondary Index / 非聚簇索引)
- 除主键索引外的索引(普通索引、唯一索引、联合索引)
- 叶子节点存储主键值(而非行数据)
- 理论上可以有多个 回表(回表查询) 二级索引找到主键后,通过主键到聚簇索引中取整行数据的过程叫回表。 二级索引扫描:idx_name → 找到 id=5 → 回表查聚簇索引 → 得到整行 覆盖索引优化 如果二级索引已包含查询所需的所有列,则无需回表,称为覆盖索引。 -- name 上有索引,只需查 name 和 id(id 在二级索引中已有) SELECT id, name FROM user WHERE name = '张三'; -- 无需回表 -- age 不在索引中,需回表 SELECT * FROM user WHERE name = '张三'; -- 需要回表
索引下推
MySQL 5.6 引入的优化,核心思想:在存储引擎层就过滤数据,减少回表次数。 无 ICP 时(5.6 之前) -- 联合索引 (name, age) SELECT * FROM user WHERE name LIKE '张%' AND age = 18;
- 存储引擎根据 name LIKE '张%' 在二级索引上找到所有满足 name 条件的记录(假设 100 条)
- 对这 100 条记录逐一回表取整行
- Server 层再对 age = 18 进行过滤 问题:本可以提前过滤掉大部分行,白白回了 90+ 次表。 有 ICP 时(5.6+)
- 存储引擎根据 name LIKE '张%' 找到二级索引记录
- 直接在索引层面判断 age = 18 是否满足(因为 age 也在联合索引中)
- 只有满足条件的那几条(假设 3 条)才回表 回表次数从 100 降为 3。
关键点
- 适用于二级索引,不适用于聚簇索引(聚簇索引本身就有全行数据)
- 条件中必须包含索引中的列才能下推
- 可通过 EXPLAIN 看到 Using index condition 表示命中了 ICP -- Extra 字段显示 Using index condition EXPLAIN SELECT * FROM user WHERE name LIKE '张%' AND age = 18;
最左前缀原则
最左前缀原则 联合索引 (a, b, c) 相当于创建了 (a)、(a,b)、(a,b,c) 三个索引。查询时 必须从最左列开始匹配,不能跳过中间列。 命中情况 -- 联合索引 (a, b, c) WHERE a = 1 -- ✅ 用到 a WHERE a = 1 AND b = 2 -- ✅ 用到 a, b WHERE a = 1 AND c = 3 -- ✅ 用到 a(c 没有,因为跳过了 b) WHERE b = 2 -- ❌ 最左列 a 缺失,全表扫描 WHERE a = 1 AND b > 2 AND c = 3 -- ✅ a 和 b 用到索引,c 用不到(范围查询右侧列失效) 本质原因 B+Tree 联合索引的排序规则:先按 a 排,a 相同再按 b 排,b 相同再按 c 排。跳过的列破坏了有序性,后续列无法利用索引。 实际指导
- 将等值查询的列放前面(= 条件)
- 将区分度高的列放前面
- 将范围查询(>、<、BETWEEN)的列放后面(范围后的列索引失效)
索引失效场景

3. 事务与锁
ACID 与隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ UNCOMMITTED | ✅ | ✅ | ✅ |
| READ COMMITTED | ❌ | ✅ | ✅ |
| REPEATABLE READ(默认) | ❌ | ❌ | ✅(InnoDB 通过间隙锁解决) |
| SERIALIZABLE | ❌ | ❌ | ❌ |
MVCC 实现原理
MVCC(多版本并发控制)基于 undo log 版本链 + ReadView 实现。
核心字段(每行记录隐藏列):
DB_TRX_ID:最近修改该行的事务 IDDB_ROLL_PTR:指向 undo log 的指针,用于构造旧版本
ReadView 组成(事务启动时生成):
m_ids:活跃事务 ID 列表min_trx_id:最小活跃事务 IDmax_trx_id:下一个待分配的事务 IDcreator_trx_id:当前事务 ID
可见性判断:
trx_id < min_trx_id:已提交,可见trx_id >= max_trx_id:未来事务,不可见trx_id 在 m_ids 中:活跃中(RR 下不可见,RC 下重新判断)
RC vs RR 区别:RC 每次语句都生成新 ReadView,RR 只在事务第一次查询时生成 ReadView。
当前读 vs 快照读
| 快照读(Snapshot Read) | 当前读(Current Read) | |
|---|---|---|
| 操作 | 普通 SELECT |
SELECT ... FOR UPDATE、SELECT ... LOCK IN SHARE MODE、UPDATE、DELETE、INSERT |
| 读取内容 | 历史快照(基于 MVCC) | 已提交的最新数据 |
| 加锁 | 无锁(MVCC 版本链) | 加锁(行锁/间隙锁) |
行锁、间隙锁、临键锁
行锁(Record Lock):锁定单行记录。
间隙锁(Gap Lock) :锁定两个索引之间的间隙,防止幻读(RR 级别有效)。间隙锁之间不互斥,两个事务可以同时锁同一个间隙。
临键锁(Next-Key Lock) :行锁 + 间隙锁的组合,锁定前开后闭区间 (a, b]。
sql
-- 假设数据 id = 1, 5, 10
-- 临键锁范围:(-∞, 1], (1, 5], (5, 10], (10, +∞)
SELECT * FROM t WHERE id = 5 FOR UPDATE; -- 锁 (1, 5]
-- 注意:唯一索引等值查询且命中记录,临键锁退化为行锁唯一索引等值查询退化规则:
- 命中记录 → Next-Key 退化为 Record Lock
- 未命中 → Next-Key Lock(间隙锁)
死锁分析与排查
典型死锁场景:两个事务互相等待对方持有的锁。
sql
-- 事务 A
UPDATE t SET v = 1 WHERE id = 1;
UPDATE t SET v = 2 WHERE id = 2;
-- 事务 B
UPDATE t SET v = 3 WHERE id = 2;
UPDATE t SET v = 4 WHERE id = 1;排查命令:
sql
SHOW ENGINE INNODB STATUS; -- 查看 LATEST DETECTED DEADLOCK 部分预防策略:
- 固定访问顺序(如表顺序、主键顺序)
- 缩短事务时间,减少锁持有时间
- 合理设置
innodb_lock_wait_timeout
4. 日志系统
binlog、redo log、undo log
| redo log | binlog | undo log | |
|---|---|---|---|
| 所属层 | InnoDB 引擎层 | MySQL Server 层 | InnoDB 引擎层 |
| 作用 | 保证 crash-safe(物理日志) | 主从复制、PITR(逻辑日志) | 事务回滚、MVCC 版本链 |
| 记录内容 | 页的物理修改 | SQL 语句或行变更 | 行的旧版本 |
| 写入时机 | 事务执行中不断写入 | 事务提交时写入 | 事务执行中写入 |
| 存储 | 固定大小循环写 | 追加写,可设置过期 | undo tablespace |
WAL 技术(Write-Ahead Logging)
先写日志,再写磁盘。redo log 记录修改后立即返回,后续由后台线程异步刷脏页。
crash-safe 原理
- 事务提交时,
redo log写入磁盘(prepare状态) binlog写入磁盘- 两者都写入成功才标记为
commit - 崩溃恢复时,检查
redo log:redo log是commit状态:直接应用redo log是prepare且binlog完整:提交事务redo log是prepare且binlog不完整:回滚事务
两阶段提交
保证 redo log 和 binlog 一致性:
perl
1. InnoDB 写 redo log → prepare 状态
2. Server 写 binlog
3. InnoDB 将 redo log 改为 commit 状态为什么需要两阶段? 如果先写 redo log 后写 binlog,写 redo log 后 crash,恢复后主库有数据从库没有;反之从库有数据主库没有。两阶段提交保证两者一致。
5. SQL 优化
EXPLAIN 执行计划分析
关键列:
| 列 | 说明 |
|---|---|
type |
访问类型:system > const > eq_ref > ref > range > index > ALL(性能从好到差) |
key |
实际使用的索引 |
rows |
预估扫描行数 |
Extra |
额外信息,重点关注 Using filesort、Using temporary、Using index condition |
type 详解:
const:主键或唯一索引等值查询,最多返回一行eq_ref:JOIN 时被驱动表使用主键/唯一索引ref:普通索引等值查询range:索引范围查询index:扫描整个索引树ALL:全表扫描
Extra 警告信号:
Using filesort:无法利用索引排序,需要额外排序Using temporary:使用了临时表(常见于 GROUP BY、DISTINCT 无索引时)
慢查询排查
sql
-- 开启慢查询日志
SET GLOBAL slow_query_log = ON;
SET GLOBAL long_query_time = 1; -- 超过 1 秒记录
-- 分析慢查询
mysqldumpslow -s t -t 10 /path/to/slow.log优先关注:全表扫描、排序未用索引、大 offset 分页、N+1 查询。
大表优化
分库分表:
- 垂直分表:把不常用/大字段拆到副表
- 水平分表/分库:按用户 ID 等取模/范围分片
- 常用中间件:ShardingSphere、MyCat
读写分离:
- 主库写,从库读
- 解决读压力大问题,注意主从延迟
其他:
- 冷热数据分离(归档历史数据)
- 字段冗余减少 JOIN
- 用 ES 做搜索,MySQL 做事务存储
6. 存储引擎
InnoDB vs MyISAM
| InnoDB | MyISAM | |
|---|---|---|
| 事务 | ✅ | ❌ |
| 行锁 | ✅ | ❌(表锁) |
| 外键 | ✅ | ❌ |
| 聚簇索引 | ✅ | ❌ |
| 全文索引 | 5.6+ ✅ | ✅ |
| 崩溃恢复 | ✅ crash-safe | ❌ |
| 存储结构 | .ibd(数据+索引) |
.frm + .MYD + .MYI |
| COUNT(*) | 需扫描 | 直接返回(有缓存) |
选择建议:
- 绝大多数场景用 InnoDB(MySQL 5.5+ 默认)
- MyISAM 用于只读、全表扫描多、无事务要求的日志表
行格式与页结构
行格式:Compact(默认)、Redundant、Dynamic(8.0 默认)、Compressed
Dynamic:大字段溢出页存储,行内只存 20 字节指针Compact:变长字段列表 + NULL 位图 + 行头 + 数据
页结构(默认 16KB):
css
Page Header → Infimum + Supremum → 行记录 ← ... → Page Directory → Page Trailer- Page Directory 存放槽(slot),通过二分法快速定位行
- 一个 B+Tree 节点就是一个页
7. 主从与高可用
主从复制原理
bash
主库 binlog → 从库 relay log → 从库 SQL 线程回放三个线程:
- 主库 Binlog Dump 线程:推送 binlog 给从库
- 从库 I/O 线程:接收 binlog 写入 relay log
- 从库 SQL 线程:读取 relay log 回放 SQL
复制模式:
- 异步复制(默认):主库不等待从库确认,性能最好但可能丢数据
- 半同步复制:主库等待至少一个从库确认收到 binlog,保证不丢数据
- 组复制(MGR):Paxos 协议保证多节点强一致
主从延迟原因与解决方案
原因:
- 从库单线程 SQL 回放跟不上主库写入
- 从库配置低于主库(磁盘 IO、CPU)
- 大事务(如 DELETE 大量数据)
- 从库执行读请求消耗资源
解决方案:
- 5.6+ 开启
slave_parallel_workers(并行复制) - 从库配置不低于主库
- 拆分大事务为小批次
- 读写分离时强制读主库(或接受短暂不一致)
8. 高频场景题
分页 offset 过大优化
sql
-- 传统写法(大 offset 性能差)
SELECT * FROM t LIMIT 100000, 10;
-- 优化 1:子查询 + 覆盖索引
SELECT * FROM t
WHERE id > (SELECT id FROM t ORDER BY id LIMIT 100000, 1)
ORDER BY id LIMIT 10;
-- 优化 2:JOIN
SELECT t.* FROM t
INNER JOIN (SELECT id FROM t ORDER BY id LIMIT 100000, 10) AS tmp
ON t.id = tmp.id;
-- 优化 3:游标分页(适用于前端滚动)
SELECT * FROM t WHERE id > 100000 ORDER BY id LIMIT 10;原理:大 offset 的扫描都发生在覆盖索引上,避免回表。
大字段查询优化
- 只查需要的列,避免
SELECT * - 大字段(TEXT、BLOB)单独拆表,按需 JOIN
- 用
EXPLAIN检查是否走了覆盖索引
JOIN 与子查询优化
JOIN 优化原则:
- 小表驱动大表(被驱动表对应列建索引)
- JOIN 字段类型必须一致,避免隐式转换
- 能用 JOIN 尽量不用子查询(MySQL 5.6 之前优化较差)
子查询优化:
sql
-- 低效(相关子查询,逐行执行)
SELECT * FROM t1 WHERE id IN (SELECT id FROM t2 WHERE status = 1);
-- 改写为 JOIN
SELECT t1.* FROM t1
INNER JOIN t2 ON t1.id = t2.id
WHERE t2.status = 1;
-- 或用 EXISTS(适合小表驱动大表)
SELECT * FROM t1 WHERE EXISTS (SELECT 1 FROM t2 WHERE t2.id = t1.id AND t2.status = 1);半连接优化 :MySQL 5.6+ 会自动将 IN 子查询优化为半连接(semi-join),不一定比 JOIN 差,以 EXPLAIN 实际计划为准。
附录:高频面试题速记
| 问题 | 一句话答案 |
|---|---|
| MySQL 默认隔离级别 | REPEATABLE READ |
| MVCC 解决了什么 | 读不阻塞写,写不阻塞读 |
| 索引为什么用 B+Tree | B+Tree 矮(3-4 层,IO 少)且叶子链式适合范围查询 |
| 什么情况不能走索引 | 函数、隐式转换、LIKE '%x'、最左缺失、OR 非索引列 |
| 分页大 offset 怎么优化 | 覆盖索引子查询 + JOIN 改写,或用游标分页 |
| Redo log 为什么是物理的 | 记录页偏移量,恢复快;binlog 是逻辑的,可跨平台 |
| 主从延迟怎么解决 | 并行复制、提高从库配置、拆分大事务 |
| 死锁怎么查 | SHOW ENGINE INNODB STATUS,固定表访问顺序 |
| 自增主键为什么好 | 页分裂少,写入顺序,B+Tree 不用频繁重平衡 |
| 为什么不要 SELECT * | 无法覆盖索引(回表)、传参多浪费内存和网络 |
Redis
基础数据结构
String
- 最基础类型,value 最大 512MB
- 底层实现:SDS(简单动态字符串),预分配冗余空间减少内存分配次数
- 常用命令:
SET/GET/INCR/DECR/MSET/MGET - 应用场景:计数器、分布式锁、Session 共享
List
- 双向链表,插入删除 O(1),索引访问 O(n)
- 底层实现:quicklist(3.2+,由多个 ziplist 节点组成的链表)
- 常用命令:
LPUSH/RPUSH/LPOP/RPOP/LRANGE - 应用场景:消息队列、最新消息列表、时间线
Hash
- 键值对集合,适合存对象
- 底层实现:ziplist (数据量小)或 dict(哈希表)
- 常用命令:
HSET/HGET/HDEL/HGETALL - 应用场景:用户信息、商品详情、购物车
Set
- 无序不可重复集合,支持交并差运算
- 底层实现:intset (整数集合,全是整数且少时)或 dict
- 常用命令:
SADD/SMEMBERS/SINTER/SUNION/SDIFF - 应用场景:共同好友、标签系统、每日签到
ZSet(有序集合)
- 每个元素有 score 按分值排序,不重复
- 底层实现:ziplist (元素少时)或 skiplist + dict
- 常用命令:
ZADD/ZRANGE/ZREVRANGE/ZRANK/ZSCORE - 应用场景:排行榜、延时队列、优先队列
为什么 ZSet 用跳表而不是 B+Tree?
- 跳表实现简单,范围查询也够快
- 内存占用比 B+Tree 少(B+Tree 每个节点是一个页,有内部碎片)
高级数据结构
HyperLogLog
- 用于基数统计(去重计数),标准误差约 0.81%
- 占用固定 12KB 内存,可统计 2^64 个元素
- 命令:
PFADD/PFCOUNT/PFMERGE - 场景:UV 统计、独立访客数
Bitmap
- 基于 String 的位操作,一个 bit 表示一个状态
- 8 位 = 1 字节,10 亿位只占约 120MB
- 命令:
SETBIT/GETBIT/BITCOUNT/BITOP - 场景:签到记录、活跃用户统计、布隆过滤器底层
Geo
- 存储经纬度坐标,支持附近的人查询
- 底层用 ZSet 实现,score 为 geohash 编码
- 命令:
GEOADD/GEORADIUS/GEODIST
持久化机制
RDB
- 触发方式 :
SAVE(同步,会阻塞) /BGSAVE(fork 子进程异步写) - 文件:dump.rdb,二进制快照
- 优点:文件紧凑,恢复快,适合备份和灾备
- 缺点:可能丢数据(两次快照间的数据),fork 子进程有内存开销
bgsave 流程:
- fork 子进程,父进程继续处理请求
- 子进程写临时 RDB 文件,利用**写时复制(COW)**保证数据一致性
- 写完后原子替换旧 RDB 文件
AOF
- 以日志形式记录每条写命令,追加写
- 刷盘策略 :
always:每条命令都 fsync,最安全最慢everysec(默认):每秒 fsync,最多丢 1 秒数据no:由操作系统决定刷盘
- 重写机制(AOF rewrite):将内存数据转化为写命令,生成新的 AOF 文件替换旧文件
AOF 重写流程:
- fork 子进程,基于当前内存数据生成新 AOF
- 父进程将新写入的命令缓存到 AOF 重写缓冲区
- 子进程写完通知父进程,父进程将缓冲区追加到新 AOF 尾部
- 原子替换旧 AOF
RDB vs AOF 选择:
- 接受丢几分钟数据:RDB
- 最多丢 1 秒数据:AOF everysec
- 生产建议:同时开启,Redis 重启时优先用 AOF 恢复(数据更完整)
过期淘汰策略
过期删除策略
| 策略 | 说明 | 缺点 |
|---|---|---|
| 定时删除 | 创建过期 key 时设定时器 | 大量定时器占用 CPU |
| 惰性删除 | 访问时检查是否过期,过期则删 | 过期的 key 不及时删,浪费内存 |
| 定期删除(Redis 使用) | 每秒随机抽查一批 key 删除过期 key | CPU 与内存的折中 |
Redis 实际方案:定期删除 + 惰性删除 结合。
内存淘汰策略
当内存达到 maxmemory 上限时触发:
| 策略 | 说明 |
|---|---|
noeviction(默认) |
不淘汰,写操作直接报错 |
allkeys-lru |
对所有 key 使用 LRU 淘汰 |
volatile-lru |
对设置过期时间的 key 使用 LRU 淘汰 |
allkeys-random |
对所有 key 随机淘汰 |
volatile-random |
对设置过期时间的 key 随机淘汰 |
volatile-ttl |
淘汰 TTL 最小的 key |
allkeys-lfu(4.0+) |
对所有 key 使用 LFU 淘汰 |
volatile-lfu(4.0+) |
对设置过期时间的 key 使用 LFU 淘汰 |
LRU vs LFU:
- LRU:淘汰最近最少访问的(可能把偶发大量访问的 key 误杀)
- LFU:淘汰访问频率最低的(更精确)
Redis 的近似 LRU :不是全量 LRU,而是随机采样(maxmemory-samples 控制,默认 5)淘汰。性能高,效果接近理论 LRU。
主从与集群
主从复制
复制流程:
- 从库向主库发送
PSYNC命令 - 主库执行
BGSAVE生成 RDB 全量同步给从库 - 同时主库将后续写命令缓存到 replication buffer
- 从库加载 RDB + 接收并执行增量命令
增量复制 :断线重连后,从库发送 PSYNC <runid> <offset>,主库从 repl_backlog_buffer 中找缺失数据,有则增量同步,无则全量同步。
主从延迟原因:
- 主库写入过快,从库单线程回放跟不上
- 网络延迟大
- 从库执行读请求消耗 CPU
解决 :repl-backlog-size 调大、保证网络质量、读写分离架构中接受短暂不一致。
哨兵模式
- 监控主从状态,自动故障转移
- 哨兵节点通过 Gossip 协议通信
- 客观下线需要多数哨兵(quorum)确认
- 领导者选举使用 Raft 算法
故障转移流程:
- 哨兵检测到主库主观下线
- 达到 quorum 后判定客观下线
- 哨兵选举 leader 执行故障转移
- 选择一个从库晋升为主库
- 通知其他从库复制新主库
- 原主库恢复后降级为从库
Cluster 集群
- 去中心化架构,16384 个 hash slot
- 每个节点负责一部分 slot,通过 CRC16(key) % 16384 确定
- 节点间通过 Gossip 协议通信
- 支持在线扩容缩容(slot 迁移)
集群限制:
- 不支持多 key 操作(除非 key 在同一个 slot)
- 事务/Lua 脚本只支持同 slot 的 key
- 批量操作只能针对同 slot 的 key
缓存问题
缓存穿透
现象:查询一个不存在的数据,每次都越过缓存直接查 DB。
解决方案:
- 缓存空值:查询 DB 为空时也缓存(设置短过期时间)
- 布隆过滤器:请求前先判断 key 是否存在,不存在直接拦截
- 参数校验:不合法的 key 直接拒绝
缓存击穿
现象:一个热点 key 过期,大量并发请求同时打到 DB。
解决方案:
- 互斥锁:缓存失效时,第一个请求获取锁去查 DB,其他请求等待
- 逻辑过期:缓存永不过期,设置逻辑过期时间,异步刷新
- 热点 key 不过期:结合定时任务主动刷新
缓存雪崩
现象:大量 key 同时过期,或 Redis 宕机,所有请求落到 DB。
解决方案:
- 过期时间加随机值 :
SETEX key TTL + random(300)防止同时过期 - 多级缓存:本地缓存 + Redis 缓存
- 降级限流:DB 打爆时返回默认值或缓存旧值
- Redis 高可用:主从 + 哨兵 / Cluster
底层与进阶
IO 多路复用
- Redis 基于 Reactor 模式 的 IO 多路复用
- 根据系统选择最优实现:
epoll(Linux)/kqueue(macOS)/select/poll - 将 socket 的读写事件注册到事件循环,单线程处理
- 非阻塞 IO,避免线程上下文切换开销
Redis 线程模型
- 主线程:处理命令请求、IO 多路复用事件循环
- 后台线程 :
- 写 AOF 文件(fsync)
- 关闭文件描述符
- 异步释放大 key 内存(unlink)
- lazy free
- 6.0+ 多线程 IO :IO 读写使用多线程,命令执行仍是单线程
- 多线程 IO 默认关闭,需配置
io-threads
- 多线程 IO 默认关闭,需配置
为什么 Redis 单线程还快:
- 纯内存操作
- IO 多路复用(非阻塞 IO)
- 单线程避免锁竞争和上下文切换
- 数据结构高效
事务与 Lua
事务:
MULTI/EXEC/DISCARD/WATCH- 注意:Redis 事务不支持回滚(语法错误全部不执行,运行时错误不影响其他命令)
WATCH提供乐观锁(CAS 机制)
Lua 脚本:
- 原子执行,整个脚本作为一个整体
- 脚本出错全部回滚
- 减少网络开销(多个命令一次发)
- 保证原子性,替代事务多数场景
分布式锁
lua
-- 加锁(SET NX + EX 原子操作)
SET lock_key unique_value NX PX 30000
-- 解锁(Lua 脚本保证原子性)
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end要点:
SET NX PX必须原子执行,防止死锁- value 用唯一标识(UUID),防止误释放别人的锁
- 解锁用 Lua 脚本保证原子性(GET + DEL)
- 更完善的方案:RedLock(多节点锁,但存在争议)
高频场景题
大 key 处理
定义:单个 key 的 value 很大(String > 10MB / 集合元素 > 1 万)
危害:
- 阻塞 Redis(读写大 key 慢)
- 阻塞网络(传输大 key)
- 集群中数据倾斜
发现:
bash
redis-cli --bigkeys # 扫描大 key
DEBUG OBJECT key_name # 查看编码和序列化长度
MEMORY USAGE key_name # 查看内存占用处理:
- 拆分为多个小 key(如 Hash 按 field 拆分)
- 使用
UNLINK异步删除(非阻塞) - 压缩序列化(如使用 MessagePack 替代 JSON)
- 冷热分离:大 value 放对象存储,Redis 存 URL
热 key 处理
定义:某个 key 的 QPS 极高,打满单节点 CPU/网络
发现:
redis-cli --hotkeys(4.0+)MONITOR命令抽样分析- 客户端记录访问频率
处理:
- 本地缓存:客户端缓存热 key 数据,减少 Redis 请求
- 副本:热 key 扩容多个从库分担读压力
- 拆分:热 key + N 后缀,打散到多个节点
延时队列
方案一:ZSet 实现
lua
-- 生产者:添加任务,score 为执行时间戳
ZADD delay_queue <timestamp> <task_id>
-- 消费者:轮询获取到期任务
ZRANGEBYSCORE delay_queue 0 <now_timestamp> WITHSCORES
ZREM delay_queue <task_id> -- 取出后删除方案二:Redis 键空间通知
- 配置
notify-keyspace-events Ex - key 过期时自动通知,实现延时队列
- 缺点:消息可能丢失(过期删除不可靠)
方案三:Redisson 延迟队列
- 基于 Redis 的 RDelayedQueue
- 内部使用 ZSet + List,到期后放入 List 消费