【案例三】基于 LangGraph 实现的代理式 RAG(检索增强生成)系统
案例介绍
接下来我们开始讲解第三个案例。这个案例的核心,就是把我们之前用 LangChain 实现的普通 RAG 检索增强生成系统进行全面升级,改用 LangGraph 来搭建一套复杂版、智能闭环的 RAG 系统。
在正式动手编码实现之前,我们先简单回顾一下 LangChain 篇章里我们做过的基础 RAG 架构,相信大家对这套基础流程已经不陌生了。
传统 RAG 整体可以拆分为两大核心环节:离线数据存储 和 在线实时检索 。首先是离线数据存储:我们手头会有一批本地文档库或是线上知识库,第一步要做的就是把这些文档加载到程序内存中;加载完成后对长文档进行文本分割,再通过嵌入模型把分割后的文本向量化,最终持久化存入向量数据库。整个离线流程只需要执行一次,后续新增文档时再增量更新即可。
离线向量库准备好之后,就进入在线检索环节 ,这是高频反复执行的过程。用户每提一个问题,就要基于向量数据库做一次检索,有多少个问题就会触发多少次检索。在 LangChain 中,框架已经帮我们封装好了向量数据库和检索器能力,我们可以直接基于向量库创建检索器,借助检索器就能完成知识库的相似度查询。
但大家有没有发现传统 LangChain RAG 存在明显短板? 我们当时测试时,只用和文档高度相关的特定专属问题去提问,检索结果才会准确;可如果输入无关问题,比如 "你好""1+1 等于几" 这类和知识库毫无关联的内容,传统 RAG 依旧会强行去向量库检索,最终返回杂乱、不准确的无效结果。
这种面对外部无关输入、极易输出错误结果的现象,专业上叫做系统鲁棒性差。
还记得我们在 LangChain 篇章中,编写过 LCEL 链式的 RAG 系统。整个系统就是一条直线:
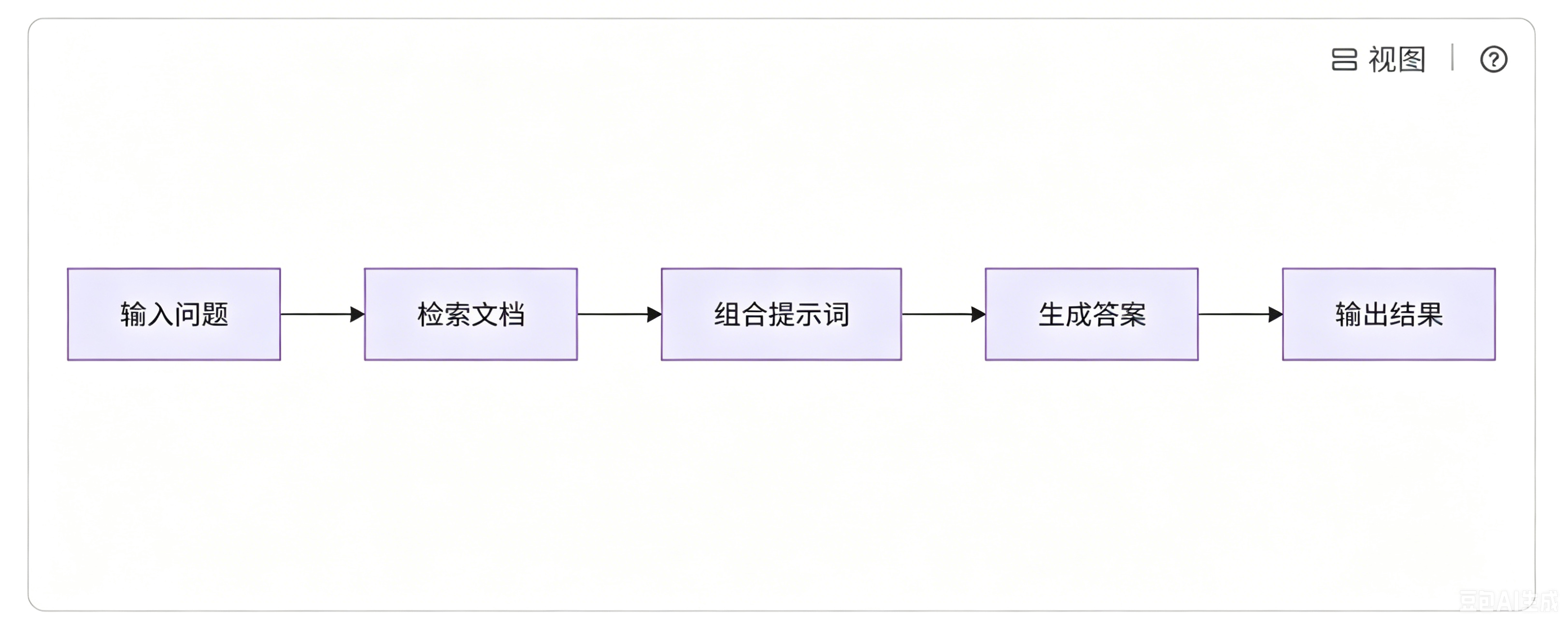
它适合初学者,因为:
- 概念少:只需要理解
Runnable,StrOutputParser等基础概念 - 逻辑简单:线性流程,易于理解和调试
- 代码直观:一眼就能看懂数据流动
- 快速上手:几分钟就能跑通整个流程
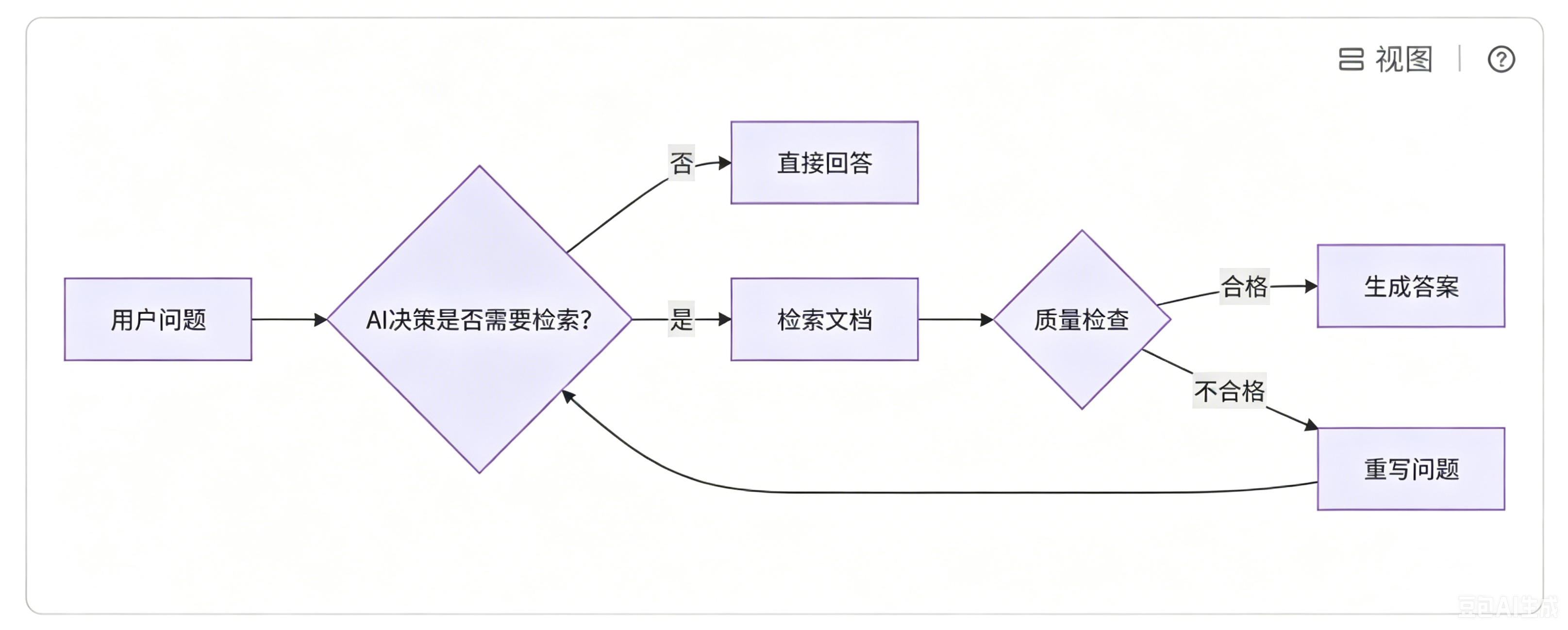
而在 LangGraph 篇章中,我们将会构建一个智能的文档问答系统(复杂版),它能够根据检索结果的质量动态调整查询策略。逻辑如下图所示:
举个例子:这里我们提供了计算机相关宣传文档,作为知识库。
bash
C++开发方向.md
Java开发方向.md
测试开发方向.md
企业介绍.md可以支持我们询问:
- "比特提供了哪些知识体系"
- "Java 开发方向的课程安排"
- "测试开发方向的主线课程有哪些"
- "C++ 开发方向的项目列表"
- "Redis 课程内容是什么"
- ......
当用户询问 "比特提供了哪些课程" 时,根据要求,会经历:
- 模型决定调用检索工具,搜索 "比特课程"
- 检索到相关文档后进行评估
- 如果文档相关,直接生成答案
- 如果文档不相关,重写问题后重新检索
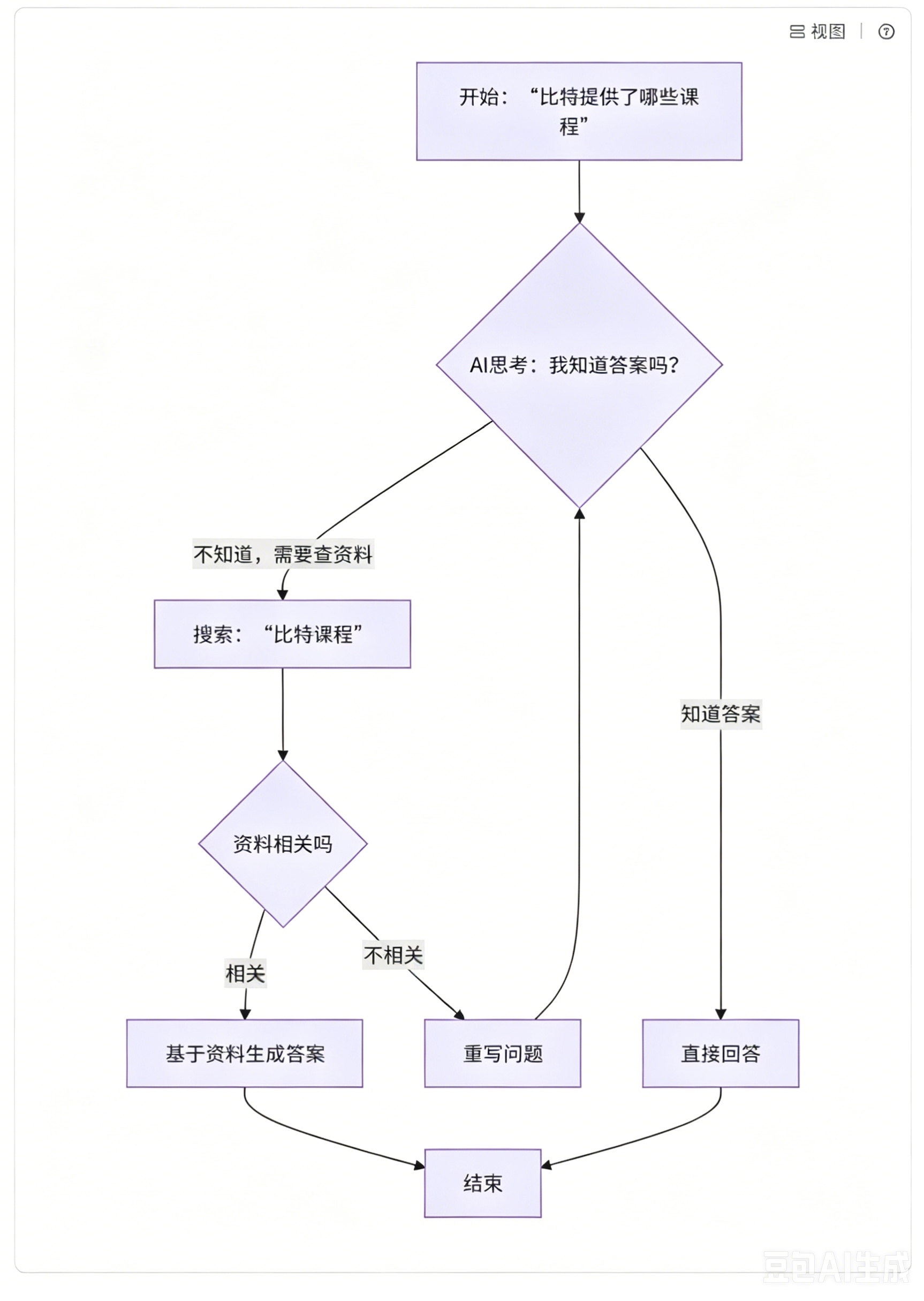
这个设计确保了即使初次检索不成功,系统也能通过重写查询来改进结果质量,比传统 RAG 系统更加鲁棒。
这里跟大家厘清两个容易混淆的概念:鲁棒性 和 稳定性。
- 稳定性:侧重系统出错之后的恢复能力,系统即便出现异常、报错,也能通过回滚、异常兜底等策略快速恢复正常运行;
- 鲁棒性 :侧重系统抵御外部干扰的能力,在杂乱输入、无关请求、异常场景下,尽量从源头避免出错,不用强行做无效检索和错误应答。
简单总结: 稳定性是出错后能快速救回来 ,鲁棒性是不容易被干扰出错,一套成熟的智能系统,这两个特性都缺一不可。
而我们这次用 LangGraph 升级 RAG,核心目标就是提升系统鲁棒性 ,把原本简单线性的链式 RAG,改造成具备智能决策、结果校验、问题重写、循环检索能力的闭环架构。
因此,相较于 LangChain 篇章中链式的 RAG:"怎么让 RAG 跑起来",该案例将学习 "怎么让 RAG 跑得更好、更智能"!
编码思路
接下来我们先拆解本次升级版 RAG 的核心业务流程,理解清楚流程和架构图之后,后续编码会非常顺畅。
整套系统依旧是用户输入问题开始、模型输出答案结束 ,但中间增加了多层智能判断逻辑,专门适配两类用户提问场景:第一类:无关性问题 (如闲聊、数学计算题等);第二类:知识库相关特定问题。
首先,用户输入任意问题后,第一步先交给大模型智能决策 :判断当前问题是否需要调用知识库检索。如果是闲聊、无关问题,无需检索向量库,模型直接给出回答即可,避免无效检索,这就从源头提升了鲁棒性;这一步的逻辑,和我们上一个案例中 "大模型判断是否需要调用搜索工具" 的思路完全一致。
如果模型判定问题和知识库相关、需要检索,就进入文档检索流程,调用提前封装好的检索器,从向量数据库中匹配相关文档。
检索出文档后,我们不再直接生成答案,而是增加检索结果质量筛查 环节:由大模型评估检索到的文档和用户问题是否匹配、信息是否充足有效。
- 若文档质量合格、信息匹配:直接基于检索文档整合信息,生成标准答案返回给用户;
- 若文档质量不合格、信息不匹配 :触发问题重写策略,让大模型基于原始问题重新优化措辞、梳理语义,生成更精准的新问题;重写后的新问题,会重新回到最开始的决策节点,再次走一遍「决策 --- 检索 --- 质检」的完整流程,直到检索出合格文档为止。
基于这套流程,我们就能梳理出 LangGraph 架构里需要设计的四大核心节点 和两条条件分支边:
- 决策节点:绑定检索工具,接收用户问题,由大模型判断是否需要调用检索工具,输出带或不带工具调用标识的消息;
- 检索工具节点:专门执行检索动作,调用检索器从向量库获取匹配文档;
- 答案生成节点:针对质检合格的检索文档,整合信息生成最终标准回答;
- 问题重写节点:针对质检不合格的检索结果,重新优化用户提问话术。
两条条件边负责流程路由:
**第一条条件边:**根据决策节点输出的消息,判断是否带有工具调用标识,无标识则直接结束流程、回复用户;有标识则进入检索节点;
第二条条件边: 检索完成后,对文档做质量校验,合格则走向答案生成节点 ,不合格则走向问题重写节点,重写后回流到决策节点形成闭环。
同时我们遵循 LangGraph 的设计思想:每个节点只做单一独立任务 ,职责拆分清晰。决策只负责判断、检索只负责查文档、重写只负责优化问题、生成只负责整合答案,不把多个逻辑塞进同一个节点。这样架构可读性更强、后续功能扩展和维护也更方便。
梳理完架构和流程,再看 LangGraph 效果图就能完全对应上:
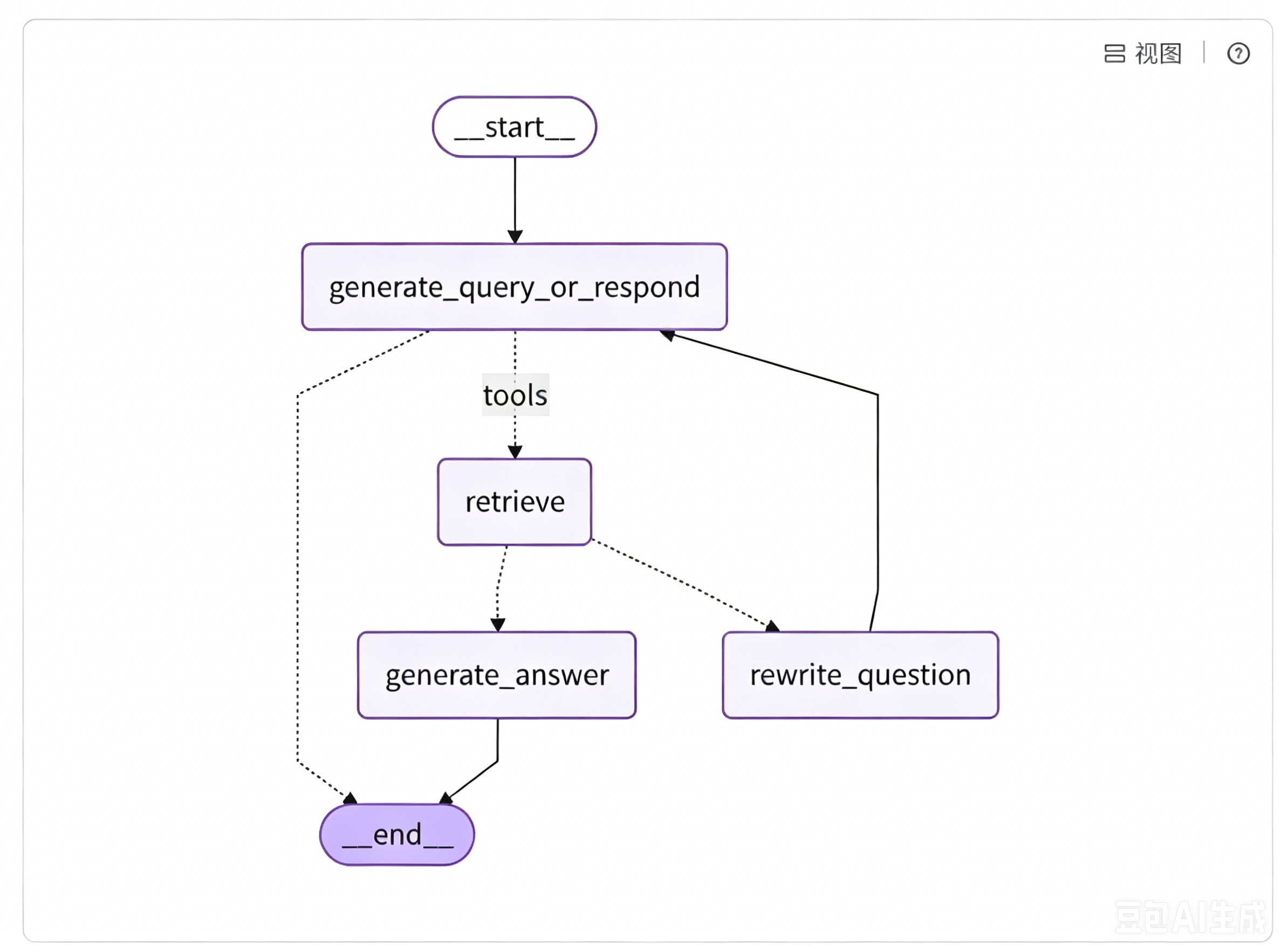
**实线是固定流转边,虚线是智能条件分支边;**从入口开始,经过决策分支分流,无关问题直接终止,相关问题进入检索,再经质检分支分流,合格生成答案、不合格重写回流,形成完整闭环。
架构流程理清后,我们接下来就进入编码环节。整体编码分为五步:
第一步:准备工作,加载本地业务文档、完成文档分割、嵌入向量化,搭建好向量知识库,这部分复用 LangChain 离线存储代码,无需大幅改动;
第二步:定义全局状态,维护流程中的对话消息上下文;
第三步:拆分并编写四大业务节点函数,每个节点实现专属逻辑;
第四步:创建图结构,添加固定边和两条条件分支边,搭建完整工作流;
第五步:编译图并运行测试,验证无关问题、相关问题、检索不合格重写等各类场景效果。
以上就是我们本次 LangGraph 复杂版 RAG 案例的完整背景、设计思路、流程拆解和编码规划,接下来我们正式开始逐行编码落地。
其实简单来说:构建一个智能文档问答系统,我们要将复杂流程分解为离散步骤,且通过共享状态连接各个节点,核心设计思路如下:
- 模块化设计:每个节点只做一件事,职责清晰
- 质量闭环:检索 → 检查 → 优化 → 再检索,确保答案质量
- 智能路由:AI 自主决定下一步行动,无需人工干预
因此,我们需要:
第一步:准备 "知识库"(数据加载与处理)
第二步:创建 "检索工具"
第三步:设计 "工作流程节点"
- 节点 1:决策节点
generate_query_or_respond - 节点 2:检索器工具节点
retrieve - 节点 3:问题优化节点
rewrite_question - 节点 4:答案生成节点
generate_answer
第四步:组装 "工作流水线"
- 条件边 1:LLM 决策是否需要进行知识库检索
- 条件边 2:检测【检索到的文档】是否与【问题】相关
代码实现
接下来我们就按照之前设计的流程,一步步落地编码实现 LangGraph 复杂版 RAG 系统。整个编码分为两大块:准备工作(搭建向量库与检索工具) 和 LangGraph 核心流程编码(状态、节点、图结构、编译运行),我们逐个模块拆解讲解。
步骤一:准备 "知识库" 并创建 "检索工具"
首先要完成基础准备 ------ 将本地 4 个相关文档(企业介绍、C++/Java/ 测试方向课程文档)转化为可检索的向量库,并封装成检索工具。这部分复用 LangChain 离线存储逻辑,我们快速过一遍核心步骤。
-
文档加载与向量化:先通过 Markdown 加载器读取本地文档,用文本分割器按设定的 chunk 大小拆分长文本,再通过嵌入模型将分割后的文本向量化,最终存入内存级向量数据库(仅用于演示,实际可替换为 Pinecone、Milvus 等持久化数据库)。
-
创建检索器与工具封装 :向量库搭建完成后,直接调用向量数据库的
as_retriever()方法生成基础检索器。但 LangGraph 中节点需要绑定「工具」而非原始检索器,因此需要将检索器封装为标准工具 ------ 这里用到 LangChain 1.x 版本新增的create_retriever_tool()方法。这里要说明一个版本差异:我们之前学的是 LangChain 0.3.x 版本,而 LangChain 1.x 为了整合 LangGraph 生态,将部分老版本能力迁移到了
langchain_community.tools等新包中,create_retriever_tool()就是迁移后的工具创建方法,作用是给检索器添加名称、描述,标准化为 LangGraph 可调用的工具。 -
工具测试验证 :封装完成后,我们可以通过
invoke()方法测试检索工具,比如查询「C++ 方向有哪些课程」「比特提供了哪些课程」,打印检索结果(仅显示前 100 字符避免冗余),验证向量库是否成功存储文档、检索工具是否正常工作。测试通过后,准备工作就完成了。
python
# 导入初始化聊天模型的函数(用于配置和创建聊天模型)
from langchain.chat_models import init_chat_model
# 导入 OpenAI 的嵌入模型(用于将文本转换为向量)
from langchain_openai import OpenAIEmbeddings
# 导入消息类型(用于定义与模型交互的消息格式)
from langchain_core.messages import HumanMessage
# 导入 Markdown 文档加载器(用于读取 Markdown 格式的文件)
from langchain_community.document_loaders import UnstructuredMarkdownLoader
# 导入文本分割器(用于将长文本切分成小块)
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 导入内存向量存储(用于存储和检索文本向量)
from langchain_core.vectorstores import InMemoryVectorStore
# 导入创建检索器工具的函数(将检索器包装成工具供 Agent 使用)
from langchain_community.tools.retriever import create_retriever_tool
# ========== 1. 初始化模型 ==========
# 初始化聊天模型(使用 GPT-4o-mini,性价比高的模型)
# - "gpt-4o-mini": OpenAI 的轻量级模型,适合大多数对话和检索任务
model = init_chat_model("gpt-4o-mini")
# 初始化 OpenAI 嵌入模型
# - model="text-embedding-3-large": OpenAI 最新的嵌入模型,生成的向量维度更高,语义理解更准确
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# ========== 2. 加载文档 ==========
# 定义需要加载的文档路径列表(比特就业课的相关介绍文档)
paths = [
"../bit/企业介绍.md", # 企业介绍文档
"../bit/C++开发方向.md", # C++ 开发方向介绍
"../bit/Java开发方向.md", # Java 开发方向介绍
"../bit/测试开发方向.md", # 测试开发方向介绍
]
# 使用 UnstructuredMarkdownLoader 加载每个 Markdown 文档
# - UnstructuredMarkdownLoader: 专门用于解析 Markdown 格式的文档加载器
# - .load(): 执行加载操作,返回 Document 对象列表
docs = [UnstructuredMarkdownLoader(path).load() for path in paths]
# 将嵌套列表展平(每个 .load() 返回一个列表,需要合并成一个列表)
# - 外层列表 doc_splits 中的每个元素是 Document 对象
docs_list = [item for sublist in docs for item in sublist]
# ========== 3. 分割文档 ==========
# 创建文本分割器(使用 tiktoken 编码器)
# - tiktoken_encoder: OpenAI 的分词器,确保按 token 数分割,而不是字符数
# - encoding_name="clk100k_base": GPT-4/3.5 系列使用的编码方式
# - chunk_size=1000: 每个块最多 1000 个 token
# - chunk_overlap=50: 块与块之间重叠 50 个 token,保持上下文连贯性
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=1000,
chunk_overlap=50
)
# 执行分割:将长文档切分成多个小块
# - 每个小块是独立的 Document 对象,保留元数据(如来源文件)
doc_splits = text_splitter.split_documents(docs_list)
# ========== 4. 创建向量存储 ==========
# 使用 InMemoryVectorStore(内存向量存储)存储文档块
# - 适合数据量不大的场景(几个文档),快速且无需外部数据库
# - from_documents: 将文档列表转换为向量并存储
# - documents=doc_splits: 分割后的小块文档
# - embedding=embeddings: 使用的嵌入模型
vectorstore = InMemoryVectorStore.from_documents(
documents=doc_splits,
embedding=embeddings
)
# ========== 5. 创建检索器工具 ==========
# 从向量存储创建检索器
# - as_retriever(): 将向量存储转换为检索器接口
# - search_kwargs={"k": 2}: 每次检索返回最相关的 2 个文档块
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# 将检索器包装成 Tool(工具),供 LangChain Agent 调用
# - retriever: 检索器实例
# - "retrieve_bit": 工具的名称,Agent 通过这个名字调用工具
# - "搜索并返回有关比特就业课的信息。": 工具的描述,Agent 根据描述判断何时使用这个工具
retriever_tool = create_retriever_tool(
retriever,
"retrieve_bit",
"搜索并返回有关比特就业课的信息。",
)其中,create_retriever_tool() 用于创建一个基于文档检索的工具,参数说明:
retriever:BaseRetriever- 检索器实例,负责实际的文档检索name:str- 工具名称,传递给语言模型,需要唯一且具有描述性description:str- 工具描述,帮助语言模型理解何时使用该工具
该方法返回 Tool 对象,其继承了 BaseTool。BaseTool 是所有 LangChain 工具的基础类。执行工具时可使用 invoke() 方法,而执行参数则是检索器执行参数。
python
return Tool(
name=name,
description=description,
func=func,
coroutine=afunc,
args_schema=RetrieverInput,
response_format=response_format,
)测试:
python
# 测试
test_queries = [
"比特提供了哪些课程",
"Java开发方向的课程安排",
"测试开发方向的课程安排有哪些",
"C++开发方向的主线项目列表",
"Redis课程内容是什么"
]
for query in test_queries:
print("-" * 50)
print(f"查询: {query}\n")
result = retriever_tool.invoke({"query": query})
# 只显示前100个字符,避免输出过长
content_preview = result[:100] + "..." if len(result) > 100 else result
print(f"结果预览: {content_preview}")
print(f"结果长度: {len(result)} 字符")步骤二:设计 "工作流程节点"
接下来是核心部分 ------ 用 LangGraph 搭建闭环工作流。遵循「定义状态 → 实现节点 → 构建图结构 → 编译运行」的固定流程,每个步骤都对应我们之前设计的架构图。
由于系统是对话式场景,核心需要维护「消息上下文列表」。LangGraph 已预定义 MessagesState 类(位于 langgraph.graph 中),内置 messages 列表用于存储对话历史(HumanMessage、AIMessage、ToolMessage),无需重复定义,直接复用即可,简化编码。
每个节点只负责单一独立任务,职责拆分清晰,便于维护和扩展。我们逐个实现并测试:
根据 Graph 示意图,设计出以下四个节点:
节点 1:决策节点 generate_query_or_respond
**功能:**绑定检索工具,让大模型判断用户问题是否需要检索。
实现逻辑: 将大模型与之前封装的检索工具绑定,接收状态中的 messages 上下文,调用模型生成响应。若问题需要检索(如「测试方向主线课程有哪些」),返回带 tool_calls 标识的 AIMessage;若为无关问题(如「你好」),直接返回无工具调用的 AIMessage。
测试验证: 直接调用节点函数,传入模拟的用户消息,观察返回结果是否正确包含 / 不包含 tool_calls,确保决策逻辑生效。
该节点核心设计:
- 决定是直接回答还是检索文档
- 可以使用
model.bind_tools([retriever_tool])让模型能够调用检索工具
代码如下:
python
from langgraph.graph import MessagesState
def generate_query_or_respond(state: MessagesState):
"""调用模型以基于当前状态生成响应,或者简单地应用用户给定问题,它将决定使用检索工具检索。"""
response = model.bind_tools([retriever_tool]).invoke(state["messages"])
return {"messages": [response]}其中 MessagesState 是 LangGraph 中给我们写好只包含 messages 的 State,可以直接使用。其源码如下:
python
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]测试 generate_query_or_respond 方法返回值:
python
# 测试 generate_query_or_respond方法返回值
input_messages = {
"messages": [
{"role": "user", "content": "比特提供了哪些课程?"}
]
}
generate_query_or_respond(input_messages)["messages"][-1].pretty_print()
# 打印:
# ============================== Ai Message ==============================
# Tool Calls:
# retrieve_bit (call_hNvMsOUD3MFKEXwX1TzqahwI)
# Call ID: call_hNvMsOUD3MFKEXwX1TzqahwI
# args:
# query: 比特课程从结果看来,根据我们的输入:"比特提供了哪些课程?",LLM 决定继续检索文档,且设置好了初次的查询字符串!
节点 2:检索器工具节点 retrieve
**功能:**执行检索操作,从向量库获取相关文档。
实现逻辑: 无需手动写函数,直接使用 LangGraph 预定义的 ToolNode,将检索工具传入即可 ------ToolNode 会自动处理工具调用、结果封装,一行代码完成工具节点初始化,比案例 2 手动调用工具更简洁。
前面已经创建好了检索器工具。对于节点,可以使用 ToolNode 类来定义:
python
from langgraph.prebuilt import ToolNode
retrieve = ToolNode([retriever_tool])ToolNode 用于创建 LangGraph 工作流程中执行工具的节点。
节点 3:问题优化节点 rewrite_question
**功能:**当检索结果不合格时,优化用户原始问题,生成更精准的新问题。
实现逻辑:
① 从状态中提取原始用户问题(第 0 条 HumanMessage)、检索结果(ToolMessage);
② 构造提示词:让大模型基于原始问题和无效检索结果,推断语义意图,生成更具体的新问题(如将「比特课程」重写为「比特公司提供的就业课程有哪些?请说明各方向核心内容」);
③ **关键细节:**将大模型返回的 AIMessage(重写后的问题)转换为 HumanMessage,追加到上下文,确保后续流程能复用该新问题。
**测试验证:**模拟构造包含「原始问题 + 带工具调用的 AIMessage + 无效 ToolMessage」的状态,调用节点函数,观察是否生成符合要求的重写问题。
该节点主要负责当文档不相关时,重写问题以改进检索效果。代码如下:
python
REWRITE_PROMPT = (
"查看输入并尝试推断潜在的语义意图/含义。\n"
"这是最初的问题:\n"
"{question}\n"
"\n"
"提出一个改进后的问题:"
)
def rewrite_question(state: MessagesState):
"""重写原始用户问题"""
messages = state["messages"]
question = messages[0].content
prompt = REWRITE_PROMPT.format(question=question)
response = model.invoke([HumanMessage(content=prompt)])
return {"messages": [{"role": "user", "content": response.content}]}模拟【检索内容与原本问题不相关】的情况,测试一下:
python
from langchain_core.messages import convert_to_messages
input_messages = convert_to_messages(
[
{
"role": "user",
"content": "比特提供了哪些课程?",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "1",
"name": "retrieve_bit",
"args": {"query": "比特课程"},
}
],
},
{
"role": "tool",
"content": "你好",
"tool_call_id": "1",
},
]
)
response = rewrite_question({"messages": input_messages})
print(response["messages"][-1]["content"])
# 改进后的问题可以是:"我想了解比特所提供的课程有哪些,包括课程内容、目标和学习时长。"节点 4:答案生成节点 generate_answer
**功能:**基于合格的检索结果,生成最终标准答案。
实现逻辑:
① 提取用户原始问题(确保最终回答针对用户初始提问)和最新检索结果(最后一条 ToolMessage);
② 构造提示词:要求大模型仅用 3 句话,基于检索上下文回答问题,未知则回复「不知道」;
③ 调用大模型生成无工具调用的 AIMessage,作为最终结果追加到上下文。
该节点将基于相关文档生成最终答案,代码如下:
python
GENERATE_PROMPT = (
"你是负责回答问题的助手。\n"
"你使用以下回答的上的片段来回答问题。\n"
"如果你不知道答案,就说你不知道。\n"
"最多用三句话回答,答案要简明扼要。\n"
"Question: {question} \n"
"Context: {context} \n"
)
def generate_answer(state: MessagesState):
"""生成答案"""
# 最原始问题
question = state["messages"][0].content
# 问题的检索结果(保证参考答案)
context = state["messages"][-1].content
prompt = GENERATE_PROMPT.format(question=question, context=context)
response = model.invoke([HumanMessage(content=prompt)])
return {"messages": [response]}步骤三:组装 "工作流水线"
根据下图,开始组装 "工作流水线"。
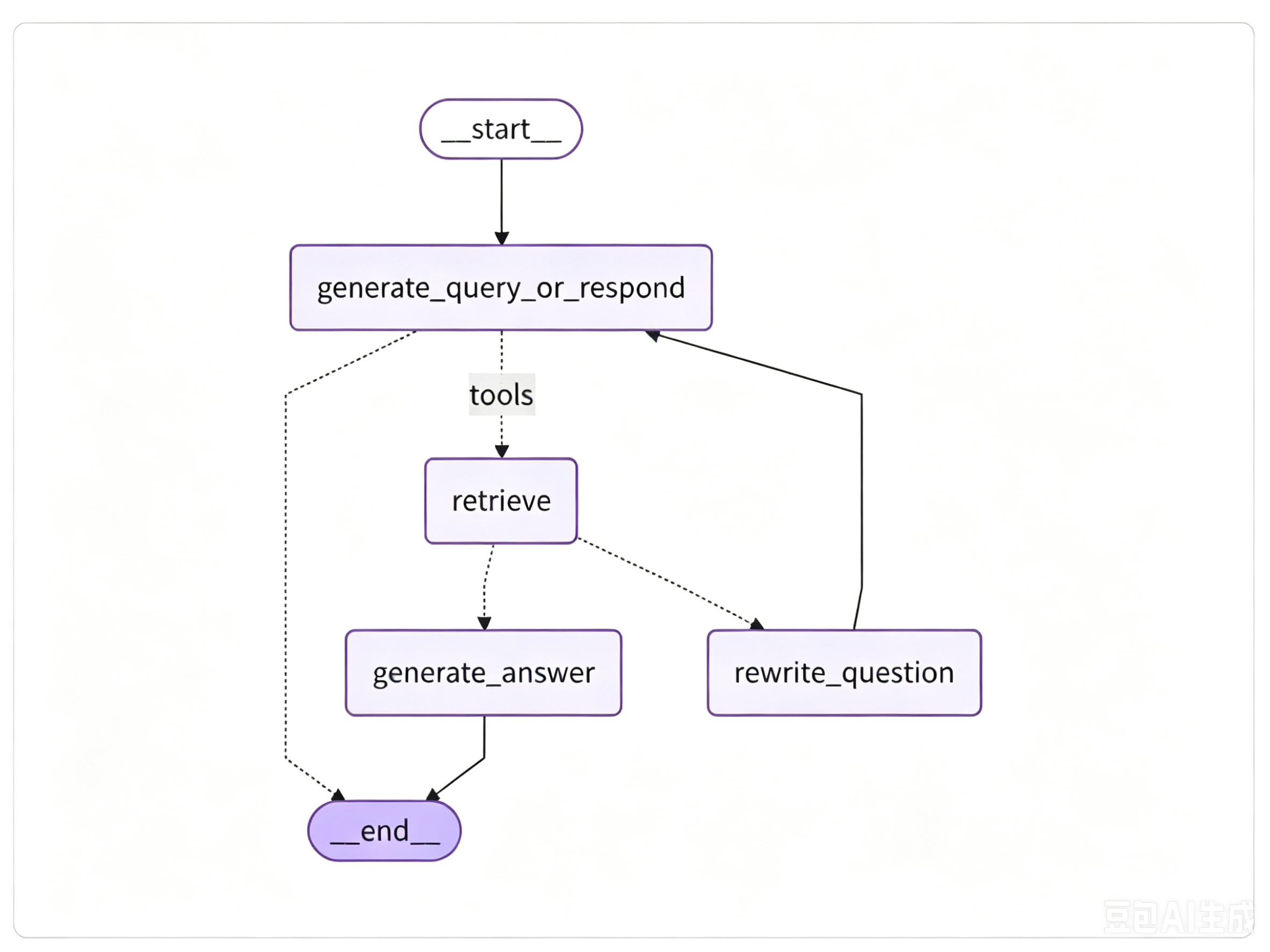
图结构直接对应我们设计的架构,包含「2 条固定边 + 2 条条件边」,用 StateGraph 类搭建:
固定边添加:
- 起始边:
START → generate_query_or_respond(用户问题先进入决策节点); - 结束边:
generate_answer → END(生成答案后流程结束); - 回流边:
rewrite_question → generate_query_or_respond(重写后的问题重新进入决策节点,形成闭环)。
添加节点与入口点
python
# 组装Graph
from langgraph.graph import StateGraph, START, END
from langgraph.prebuilt import ToolNode, tools_condition
workflow = StateGraph(MessagesState)
workflow.add_node("generate_query_or_respond", generate_query_or_respond)
workflow.add_node("retrieve", ToolNode([retriever_tool]))
workflow.add_node(rewrite_question)
workflow.add_node(generate_answer)
workflow.add_edge(START, "generate_query_or_respond")条件边添加(核心逻辑):条件边实现「智能路由」,根据前序节点结果决定下一步流向:
条件边 1:LLM 决策是否需要进行知识库检索
条件边 1(决策路由):
起始节点: generate_query_or_respond;
**判断逻辑:**使用 LangGraph 预定义的 tools_condition() 方法,自动判断最后一条 AIMessage 是否包含 tool_calls;
路由规则: 有工具调用 → 流向 retrieve 节点;无工具调用 → 流向 END(直接结束)。
第一条分支用来判断是否需要调用工具,如下图所示:
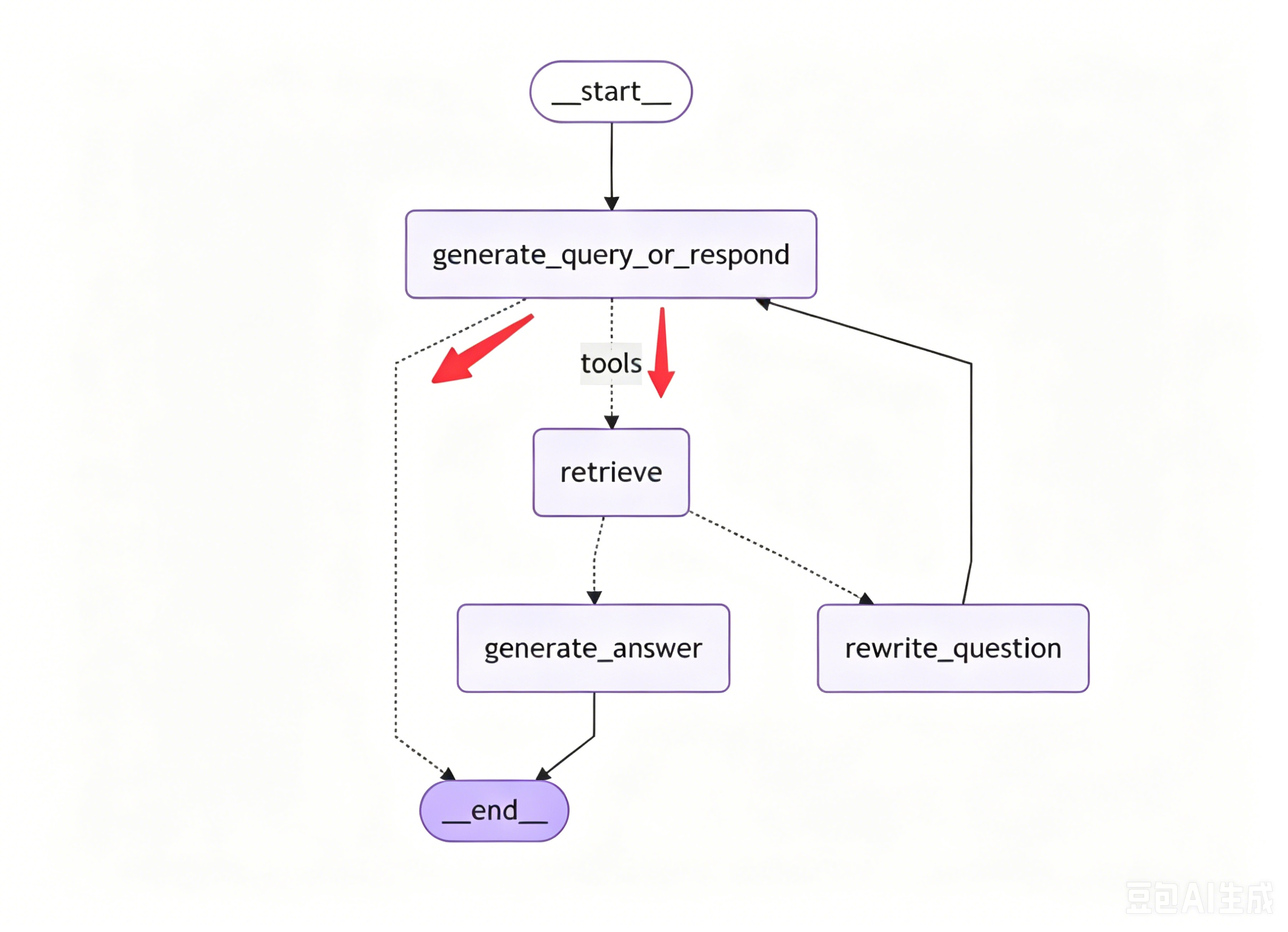
"是否需要调用工具" 的判断,可以使用 tools_condition() 方法来决定工作流的路由(等价于手动写的 should_continue 方法),规则如下:
- 如果最后一条 AI 消息包含工具调用,则路由到工具执行节点;
- 否则,请结束工作流。
该方法返回类型为 Literal["tools", "__end__"],表示:
- 当最后一条 AI 消息包含工具调用,则返回
"tools" - 否则返回
"__end__"
因此,代码如下所示:
python
workflow.add_conditional_edges(
"generate_query_or_respond",
# 评估 LLM 决策
tools_condition,
{
"tools": "retrieve", # 将条件输出转换为图中的节点
"__end__": END,
},
)条件边 2:检测【检索到的文档】是否与【问题】相关
条件边 2(结果质检路由):
起始节点: retrieve;
判断逻辑: 自定义 grade_documents 方法,让大模型评估检索结果与用户最新问题的相关性(结构化输出「yes/no」);
路由规则: 相关(yes)→ 流向 generate_answer;不相关(no)→ 流向 rewrite_question。
该条件边核心在于:
评估检索到的文档与问题的相关性
可以使用【结构化输出】模型返回二元评分
yes:表示检索到的文档与问题相关no:表示检索到的文档与问题不相关
返回下一步路由决策:"generate_answer" 或 "rewrite_question"
代码如下:
python
# 对文档进行评估
from pydantic import BaseModel, Field
from typing import Literal
GRADE_PROMPT = (
"你是一个评分员,评估检索到的文档与用户问题的相关性。\n "
"以下是检索到的文档: {context} \n\n"
"以下是用户的问题: {question} \n\n"
"如果文档包含与用户问题相关的关键字或语义,则将其评为相关。\n"
"给出一个二元分数"yes"或"no",以表明该文档是否与问题相关。"
)
class GradeDocuments(BaseModel):
"""使用二进制评分进行相关性检查"""
score: str = Field(
description="相关性评分: 如果相关则为"yes",如果不相关则为"no""
)
def grade_documents(state: MessagesState) -> Literal["generate_answer", "rewrite_question"]:
"""确定检索到的文档是否与问题相关"""
question = state["messages"][0].content
context = state["messages"][-1].content
prompt = GRADE_PROMPT.format(question=question, context=context)
response = model.with_structured_output(GradeDocuments).invoke(
[{"role": "user", "content": prompt}]
)
score = response.score
if score == "yes":
return "generate_answer"
else:
return "rewrite_question"
workflow.add_conditional_edges(
"retrieve",
# 评估代理决策
grade_documents,
["generate_answer", "rewrite_question"],
)添加结束点并编译
编译图 :调用 workflow.compile() 生成可执行的图实例,LangGraph 会自动校验节点和边的合法性。
python
workflow.add_edge("generate_answer", END)
workflow.add_edge("rewrite_question", "generate_query_or_respond")
graph = workflow.compile()运行 RAG
python
# 运行 RAG
for chunk in graph.stream(
{
"messages": [HumanMessage(content="C++开发方向的项目列表")]
}
):
for node, update in chunk.items():
print(f"由节点 {node} 更新消息:")
if node != "rewrite_question":
update["messages"][-1].pretty_print()
print("\n\n")结果如下:
python
由节点 generate_query_or_respond 更新消息:
================================== Ai Message ==================================
Tool Calls:
retrieve_bit (call_kHhk5pvL33lGheckV1VwMKKt)
Call ID: call_kHhk5pvL33lGheckV1VwMKKt
Args:
query: C++开发方向的项目列表
由节点 retrieve 更新消息:
================================== Tool Message ==================================
Name: retrieve_bit
...(检索结果较长,省略显示)
由节点 generate_answer 更新消息:
================================== Ai Message ==================================
C++开发方向的项目包括多个层次的挑战项目、标准项目和极简项目。挑战项目如微服务的即时通讯系统和视频点播系统,涵盖复杂功能和技术组件;标准项目如仿QQ音乐的播放器客户端等,适合快速掌握;极简项目则如贪吃蛇游戏,适合基础薄弱的同学,总共有15个不同规格的项目可供选择。完整代码:
python
# ============================================================
# 导入模块(按类型分组)
# ============================================================
# ---------- 标准库 ----------
import os
# ---------- 第三方库 ----------
from dotenv import load_dotenv
# ---------- LangChain 嵌入模型 ----------
# 本地 HuggingFace 嵌入模型(免费,无需 API key)
from langchain_community.embeddings import HuggingFaceEmbeddings
# OpenAI 风格的嵌入模型(用于 OpenRouter)
from langchain_openai import OpenAIEmbeddings
# ---------- LangChain 聊天模型 ----------
from langchain_openai import ChatOpenAI
# ---------- LangChain 核心消息 ----------
from langchain_core.messages import HumanMessage, convert_to_messages
# ---------- LangChain 工具 ----------
from langchain_core.tools import create_retriever_tool
# ---------- 文档处理 ----------
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.vectorstores import InMemoryVectorStore
# ---------- LangGraph 图构建 ----------
from langgraph.graph import StateGraph, START, END
from langgraph.graph import MessagesState
from langgraph.prebuilt import ToolNode, tools_condition
# ---------- Pydantic 数据验证 ----------
from pydantic import BaseModel, Field
from typing import Literal
# ============================================================
# 环境配置
# ============================================================
# 加载 .env 文件中的环境变量(API key 等)
load_dotenv()
# ============================================================
# 1. 初始化模型
# ============================================================
# ---------- 聊天模型 ----------
# 使用 OpenRouter 聚合 API,自动选择可用的免费模型
# - base_url: OpenRouter 的 API 端点
# - api_key: 从环境变量获取
# - model: "openrouter/free" 表示自动选择免费模型
# - temperature: 0 表示确定性输出(每次结果相同)
model = ChatOpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.environ["OPENROUTER_API_KEY"],
model="openrouter/free",
temperature=0,
)
# ---------- 嵌入模型 ----------
# 使用本地 HuggingFace 模型,无需 API key
# - model_name: 轻量级句子嵌入模型(384维)
# - device: 'cpu' 使用 CPU 运行
# - normalize_embeddings: 归一化向量,便于余弦相似度计算
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
# 备选方案:使用 OpenRouter 的云端嵌入模型(需要测试兼容性)
# embeddings = OpenAIEmbeddings(
# base_url="https://openrouter.ai/api/v1",
# api_key=os.environ["OPENROUTER_API_KEY"],
# model="nvidia/llama-nemotron-embed-vl-1b-v2:free"
# )
# ============================================================
# 2. 加载和分割文档
# ============================================================
# 定义需要加载的 Markdown 文件路径
paths = [
"./Linux/线程的同步与互斥 [ 上 ].md",
"./Linux/线程的同步与互斥 [ 中 ].md",
"./Linux/线程的同步与互斥 [ 下 ].md",
]
# 加载每个文档(.load() 返回列表)
docs = [UnstructuredMarkdownLoader(path).load() for path in paths]
# 展平二维列表:将多个列表合并成一个
# 原结构:[[doc1], [doc2], [doc3]] → 新结构:[doc1, doc2, doc3]
docs_list = [item for sublist in docs for item in sublist]
# 创建文本分割器(使用 tiktoken 编码器,按 token 数分割)
# - encoding_name="cl100k_base": GPT-4/3.5 使用的编码方式
# - chunk_size=1000: 每个块最多 1000 个 token
# - chunk_overlap=50: 块之间重叠 50 个 token,保持上下文连贯
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=1000,
chunk_overlap=50
)
# 执行分割,将长文档切成小块
doc_splits = text_splitter.split_documents(docs_list)
# ============================================================
# 3. 创建向量存储和检索工具
# ============================================================
# 创建内存向量存储
# - 将文档块转换为向量并存储
# - 适合小规模数据,无需外部数据库
vectorstore = InMemoryVectorStore.from_documents(
documents=doc_splits,
embedding=embeddings
)
# 创建检索器
# - search_kwargs={"k": 2}: 每次检索返回最相关的 2 个文档块
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# 将检索器包装成 LangChain 工具
# - retriever: 检索器实例
# - "retrieve_bit": 工具名称(Agent 通过此名称调用)
# - "搜索返回相关的线程同步与互斥的知识": 工具描述(帮助 LLM 决定何时使用)
retriever_tool = create_retriever_tool(
retriever,
"retrieve_bit",
"搜索返回相关的线程同步与互斥的知识",
)
# ============================================================
# 4. 定义 LangGraph 工作流的各个节点函数
# ============================================================
def generate_query_or_respond(state: MessagesState):
"""
节点1: 生成查询或响应
作用:
- 调用 LLM 决定是否需要检索
- 如果 LLM 决定使用工具,会返回 tool_calls
- 如果 LLM 认为可以直接回答,则直接返回响应
参数:
state: 包含消息列表的状态对象
返回:
更新后的消息(可能包含 tool_calls)
"""
# 将检索工具绑定到模型,让模型知道可以调用这个工具
# .invoke(state["messages"]) 调用模型并传入历史消息
response = model.bind_tools([retriever_tool]).invoke(state["messages"])
return {"messages": [response]}
def rewrite_question(state: MessagesState):
"""
节点3: 重写问题
作用:
- 当检索到的文档不相关时触发
- 根据原始问题推断语义意图,生成改进后的问题
- 用于下一轮检索
参数:
state: 包含消息列表的状态对象
返回:
重写后的问题(作为用户消息)
"""
# 获取原始问题(第一条消息的内容)
messages = state["messages"]
question = messages[0].content
# 构建提示词,要求 LLM 重写问题
prompt = REWRITE_PROMPT.format(question=question)
# 调用模型生成改进后的问题
response = model.invoke([HumanMessage(content=prompt)])
# 返回重写后的问题(作为用户消息)
return {"messages": [{"role": "user", "content": response.content}]}
def grade_documents(state: MessagesState) -> Literal["generate_answer", "rewrite_question"]:
"""
决策点: 评估文档相关性
作用:
- 判断检索到的文档是否与用户问题相关
- 相关 → 进入生成答案节点
- 不相关 → 进入重写问题节点(重新检索)
参数:
state: 包含消息列表的状态对象
返回:
下一个节点的名称
"""
# 原始问题(第一条消息)
question = state["messages"][0].content
# 检索到的文档内容(最后一条消息)
context = state["messages"][-1].content
# 构建评估提示词
prompt = GRADE_PROMPT.format(question=question, context=context)
# 使用结构化输出,强制模型返回 GradeDocuments 格式
response = model.with_structured_output(GradeDocuments).invoke(
[{"role": "user", "content": prompt}]
)
# 根据评分决定下一步
score = response.score
if score == "yes":
return "generate_answer" # 文档相关,生成答案
else:
return "rewrite_question" # 文档不相关,重写问题重新检索
def generate_answer(state: MessagesState):
"""
节点4: 生成最终答案
作用:
- 使用检索到的文档作为上下文
- 调用 LLM 生成准确、简明的答案
参数:
state: 包含消息列表的状态对象
返回:
生成的答案(作为助手消息)
"""
# 原始问题(第一条消息)
question = state["messages"][0].content
# 检索到的文档内容(最后一条消息,作为上下文)
context = state["messages"][-1].content
# 构建生成答案的提示词
prompt = GENERATE_PROMPT.format(question=question, context=context)
# 调用模型生成答案
response = model.invoke([HumanMessage(content=prompt)])
return {"messages": [response]}
# ============================================================
# 5. 定义提示词模板
# ============================================================
# 重写问题的提示词模板
# - 要求 LLM 分析原始问题的语义意图
# - 生成更精确、更利于检索的问题
REWRITE_PROMPT = (
"查看输入并尝试推断潜在的语义意图/含义。\n"
"这是最初的问题:\n"
"{question}\n"
"\n"
"提出一个改进后的问题:"
)
# 评估文档相关性的提示词模板
# - 要求 LLM 判断文档是否与问题相关
# - 输出二元评分:"yes" 或 "no"
GRADE_PROMPT = (
"你是一个评分员,评估检索到的文档与用户问题的相关性。\n "
"以下是检索到的文档: {context} \n\n"
"以下是用户的问题: {question} \n\n"
"如果文档包含与用户问题相关的关键字或语义,则将其评为相关。\n"
"给出一个二元分数"yes"或"no",以表明该文档是否与问题相关。"
)
# 生成答案的提示词模板
# - 使用检索到的上下文回答问题
# - 要求回答简明扼要(三句话以内)
# - 不知道就说不知道(避免幻觉)
GENERATE_PROMPT = (
"你是负责回答问题的助手。\n"
"你使用以下回答的上的片段来回答问题。\n"
"如果你不知道答案,就说你不知道。\n"
"最多用三句话回答,答案要简明扼要。\n"
"Question: {question} \n"
"Context: {context} \n"
)
# ============================================================
# 6. 定义 Pydantic 数据模型(用于结构化输出)
# ============================================================
class GradeDocuments(BaseModel):
"""
文档相关性评分的数据模型
用于强制 LLM 输出结构化的 JSON,便于程序解析
"""
score: str = Field(
description="相关性评分: 如果相关则为"yes",如果不相关则为"no""
)
# ============================================================
# 7. 构建 LangGraph 工作流图
# ============================================================
# 创建状态图,使用预定义的 MessagesState
# MessagesState 包含 messages 字段,存储对话历史
workflow = StateGraph(MessagesState)
# ---------- 添加节点 ----------
# 节点1: 查询生成/响应决策
workflow.add_node("generate_query_or_respond", generate_query_or_respond)
# 节点2: 检索工具节点(执行文档检索)
workflow.add_node("retrieve", ToolNode([retriever_tool]))
# 节点3: 重写问题
workflow.add_node("rewrite_question", rewrite_question)
# 节点4: 生成答案
workflow.add_node("generate_answer", generate_answer)
# ---------- 添加边(定义执行顺序)----------
# 从 START 开始,进入 generate_query_or_respond
workflow.add_edge(START, "generate_query_or_respond")
# 条件边1: 根据 generate_query_or_respond 的决策分支
# - tools_condition: 检查是否调用了工具
# - 如果调用了工具 → 进入 "retrieve"
# - 如果没有调用工具 → 结束(END)
workflow.add_conditional_edges(
"generate_query_or_respond",
tools_condition, # 决策函数
{
"tools": "retrieve", # 有 tool_calls 时
"__end__": END, # 无 tool_calls 时
},
)
# 条件边2: 评估检索到的文档是否相关
# - 相关 → generate_answer
# - 不相关 → rewrite_question
workflow.add_conditional_edges(
"retrieve",
grade_documents, # 决策函数
["generate_answer", "rewrite_question"],
)
# 生成答案后结束
workflow.add_edge("generate_answer", END)
# 重写问题后回到 generate_query_or_respond(重新开始流程)
workflow.add_edge("rewrite_question", "generate_query_or_respond")
# ---------- 编译图 ----------
# 将图编译成可执行的应用
graph = workflow.compile()
# ============================================================
# 8. 运行测试
# ============================================================
if __name__ == "__main__":
# 运行 RAG 工作流
# 输入问题,流式输出每个节点的执行结果
for chunk in graph.stream(
{
"messages": [HumanMessage(content="线程同步的相关系统调用")]
}
):
for node, update in chunk.items():
print(f"由节点 {node} 更新消息:")
# rewrite_question 节点返回的是字典格式,不是消息对象
if node != "rewrite_question":
update["messages"][-1].pretty_print()
print("\n\n")
# ┌─────────────────────────────┐
# │ START │
# └─────────────┬───────────────┘
# ↓
# ┌─────────────────────────────┐
# │ generate_query_or_respond │
# │ (LLM 决定是否需要检索) │
# └─────────────┬───────────────┘
# ↓
# tools_condition 判断
# │
# ┌─────────────┴─────────────┐
# ↓ ↓
# [调用了工具] [没有调用工具]
# ↓ ↓
# ┌─────────────────┐ ┌─────────┐
# │ retrieve │ │ END │
# │ (执行文档检索) │ └─────────┘
# └────────┬────────┘
# ↓
# grade_documents 判断
# │
# ┌─────────┴─────────┐
# ↓ ↓
# [相关: yes] [不相关: no]
# ↓ ↓
# ┌─────────────────┐ ┌─────────────────────┐
# │ generate_answer │ │ rewrite_question │
# │ (生成最终答案) │ │ (重写问题) │
# └────────┬────────┘ └──────────┬──────────┘
# ↓ ↓
# ┌───┐ (返回 generate_query_or_respond)
# │END│ (重新开始流程)
# └───┘