一句话理解 BP Claw:它是 FlinkSpec 上游的 "AI 数据 BP",把产品经理的非标 PRD 自动转化为 AI Coding 可消费的高质量需求文档。在深入阅读之前,先用一张表告诉你 BP Claw 能带来什么。
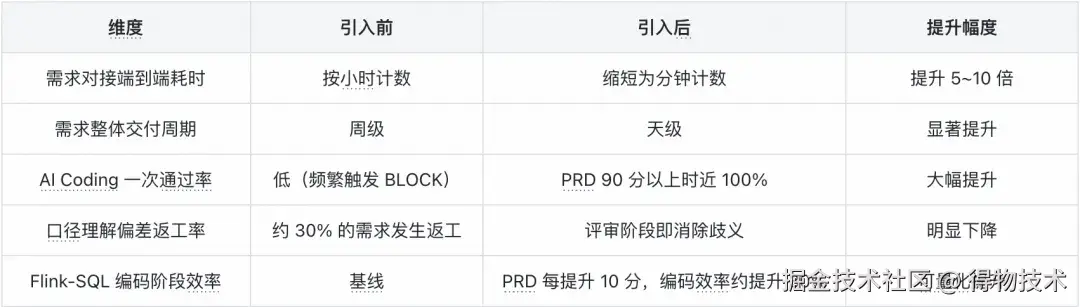
如果你的团队也在被以下问题困扰,这篇文章值得读完:AI Coding 效果不稳定,同样的框架、不同的需求,结果天差地别;需求沟通来回反复,一个指标口径要确认三四轮;PRD 质量参差不齐,开发阶段频繁踩雷、返工延期。BP Claw 的答案是:问题的根源在输入,解法在源头。
一、FlinkSpec:实时数仓的 AI 工程化底座
在深入 BP Claw 之前,我们先来看一个更大的图景 ------FlinkSpec。FlinkSpec 是实时数仓团队打造的 AI 工程化开发框架,它以 "需求驱动、制品为锚" 的理念,将一条实时数据链路的生命周期拆解为四个阶段,每个阶段都有严格的门控评估,确保交付质量。
FlinkSpec 全景架构
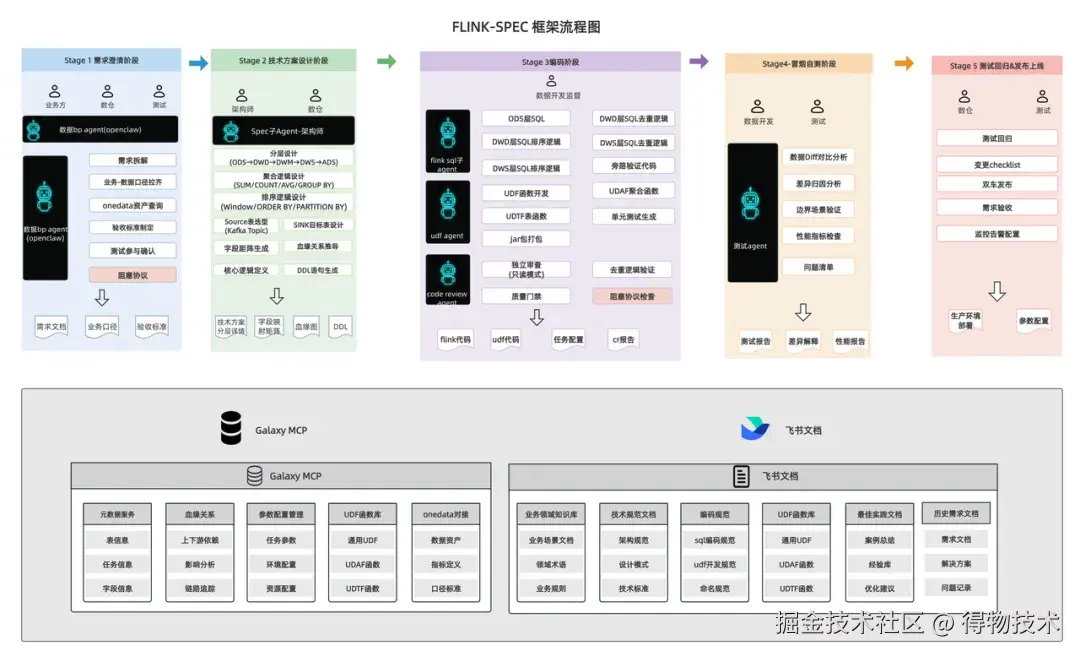
BP Claw 在 FlinkSpec 中的定位
在 FlinkSpec 的四个阶段中,需求澄清阶段是一切的起点。而需求澄清阶段的质量,取决于一个关键输入 ------PRD 文档。如果 PRD 质量不达标,后续的一切都是空中楼阁:需求定义模糊 → Intake 门控反复打回 → Define 阶段耗时翻倍;技术口径缺失 → Flink-SQL Agent 无法编码 → 频繁触发阻塞协议(BLOCK-N);验收标准不清 → Review 阶段发现问题 → 回退到 Define 重来。
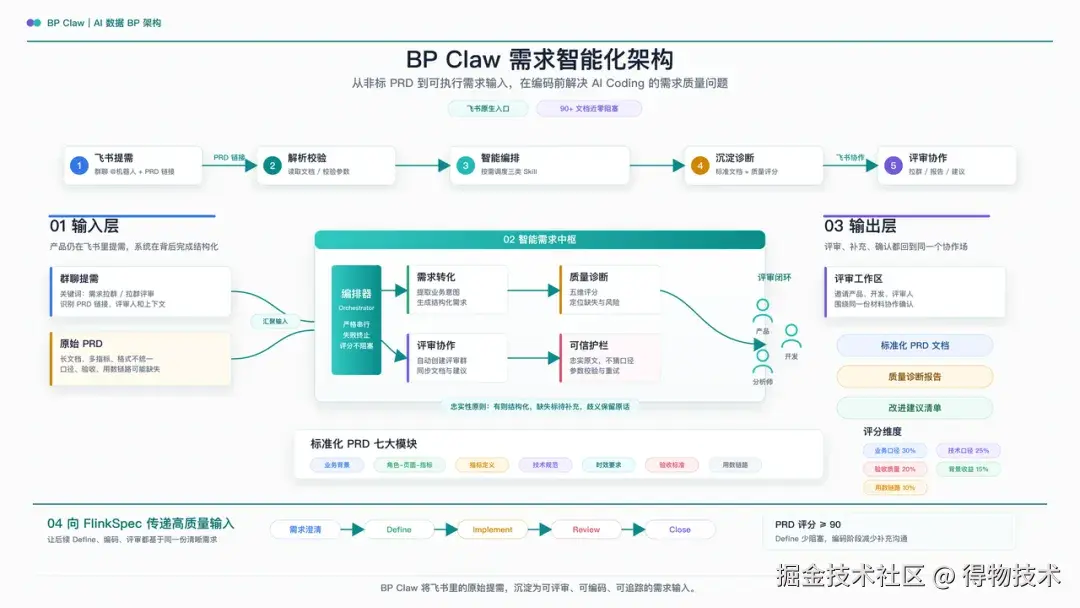
BP Claw 解决实际问题案例
问题定义
商业化广告投放链路中,一次广告曝光往往由多个商家共同参与竞价。这种一对多的流量-主体映射关系,在指标聚合时会产生一个结构性的歧义:以"商家"为维度下钻时,同一次流量事件会被多个商家各自计入,导致商家侧明细加总后,与平台侧总量不等。这不是数据质量问题,而是两套在各自语义下都正确的口径共存在同一张宽表里,却没有被显式区分:impression_cnt(平台侧)去重到流量维度,一次曝光 = 1;impression_cnt(商家侧)展开到主体维度,N 个商家参与 = N。当下游消费方使用同一个字段名、却按不同语义聚合时,CTR、CVR、ROI 等衍生指标就会系统性失真。
为什么难以在开发阶段发现
实时数仓的指标开发通常以 FlinkSQL 为载体,开发侧看到的输入是 Kafka 事件流和维度表,字段语义的边界在建模时已经隐式确定。问题在于: FlinkSQL 层面的 GROUP BY 逻辑无法自动感知上游指标应该以哪个粒度聚合。如果流量事件里同时携带了 advertiser_id 列表,不同的展开方式对应完全不同的业务语义,而这一选择在代码里只是一行 UNNEST 或一个 JOIN 的差异。常规的 Code Review 能发现 SQL 逻辑错误,却很难发现"SQL 逻辑正确、但口径选择与业务预期不符"这类问题------因为两种写法都能跑通,数据差异在没有对比基准的情况下也不会报错。
BP Claw 的介入点
BP Claw 作为需求到编码之间的中间层,其核心能力是在指标定义阶段做口径显式化,而不是在开发完成后做数据校验。
具体做法是结合 OpenViking 知识库(团队历史建模文档、字段定义、历史踩坑记录)做语义召回,识别当前需求涉及的指标是否存在多粒度歧义,并在进入 FlinkSpec 之前,将以下约束显式写入需求文档:

这套约束作为 FlinkSpec 的输入,让 AI Coding 在生成 DDL 和 INSERT 逻辑时,直接基于已经对齐的语义边界,而不是从模糊描述中自行推断。
与通用 AI Coding 的差异
通用 AI Coding 工具在给定输入后,会选择一种"看起来合理"的实现------对于多商家指标,它会倾向于展开商家维度(因为需求里写了"按商家查看"),但不会主动判断这是否会导致平台侧口径膨胀。
BP Claw 的差异在于知识来源:它使用的不是通用语言模型对业务逻辑的推断,而是团队在同类建模问题上积累的历史决策和约束条件。对于"多商家指标是否需要分口径建模"这个问题,OpenViking 里已经有过明确结论,BP Claw 将其召回并作为强约束注入当前需求,而不是重新推断一次。
BP Claw 正是为了解决这个"源头问题"而生。它站在 FlinkSpec 的上游,确保进入 Define 阶段的 PRD 文档质量足够支撑后续的 AI 自动化编码。
二、产品设计:从痛点出发的解决方案
面向谁?解决什么?
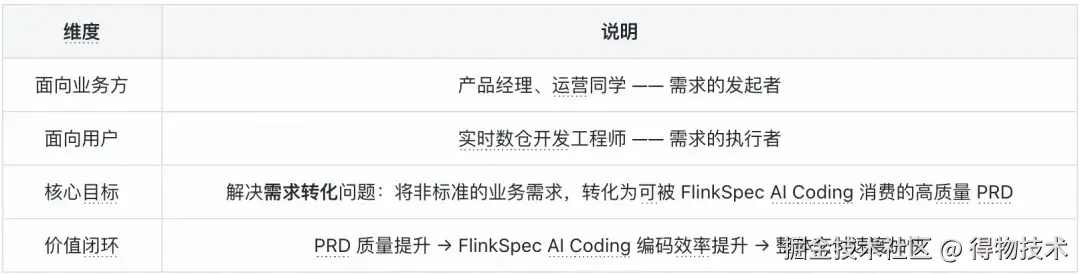
设计哲学:贴合工作流,而非改造工作流
BP Claw 的设计遵循三条核心原则,原则一 :嵌入现有场景------用户不需要打开新页面、学习新工具,直接在飞书群聊中 @ 机器人即可触发,和日常"拉群评审"的行为完全一致;原则二 :产品经理零感知提效------产品经理只需要提交原始 PRD 文档,BP Claw 自动完成规范化转换,产品经理无需关心格式,产品经理收到的是结构化、高质量的评审群,而非一堆格式要求;原则三:不硬卡点,做参照系------PRD 评分是"参照",不是"阻塞",帮助团队建立质量意识,而非制造流程摩擦,逐步提升 PRD 质量基线,而非一刀切。
三、核心能力层
对实时数仓而言,一份好的 PRD 应该是什么样的?
在深入技术实现之前,我们先回答一个根本性问题:实时数仓对 PRD 文档的要求是什么?一份好的实时数仓 PRD,需要覆盖七大模块:
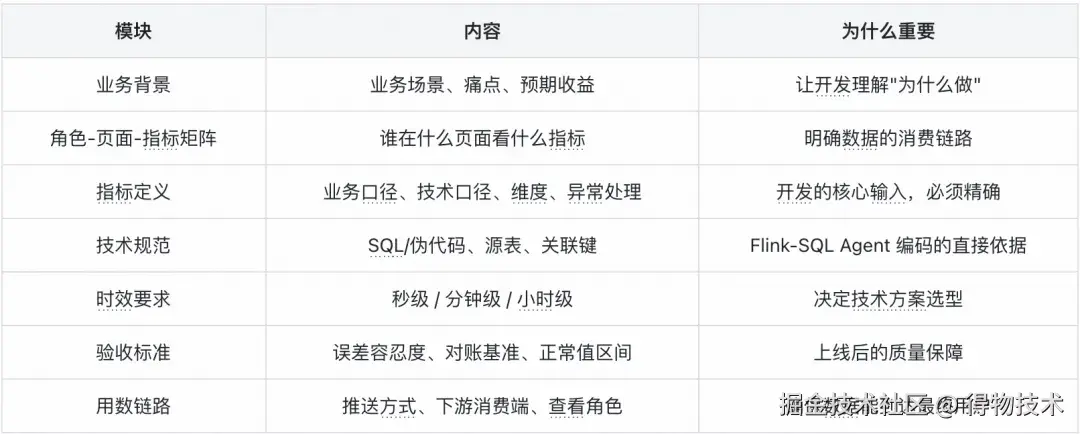
然而,产品经理提交的文档往往只覆盖了其中的 2-3 个模块,而且格式五花八门。这正是 BP Claw 要解决的核心问题 ------ 需求转化。
能力一:智能需求转化(核心能力)
这是 BP Claw 最核心、最有技术含量的能力。它做的事情,本质上是 模拟一个经验丰富的数据 BP 的工作过程。
转化过程详解
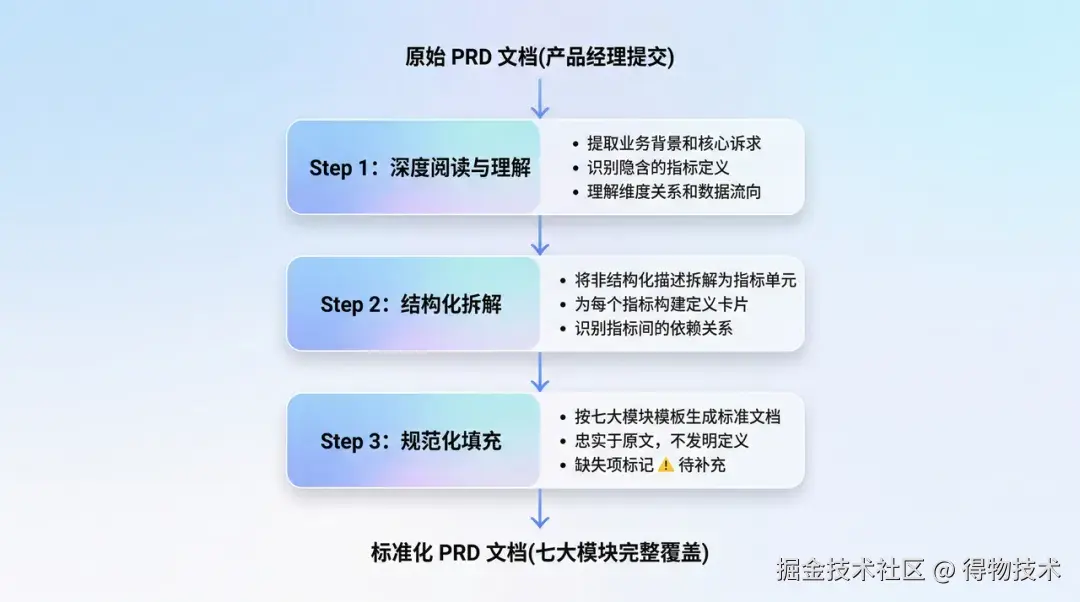
转化的技术难点
如何处理常见的业务需求类型?我们总结了实时数仓中最常见的几类需求模式:
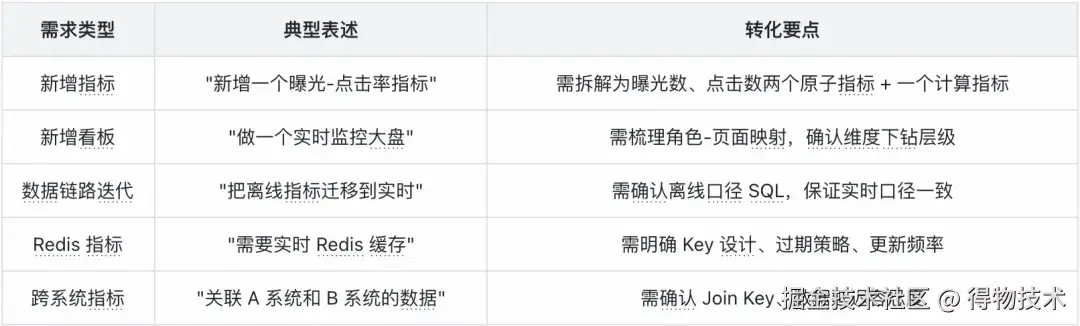
转化的核心原则:忠实于原文
原文有的信息进行结构化提取,按模板填充;原文没有的信息标记为待补充,绝不凭空捏造;原文有歧义的信息保留原始表述,同时标注歧义点;原文划删除线的标注为"本期不纳入,暂缓"。
能力二:PRD 质量评分(参照能力)
在完成需求转化后,BP Claw 会对标准化文档进行多维度质量评估,生成诊断报告。
五大评分维度
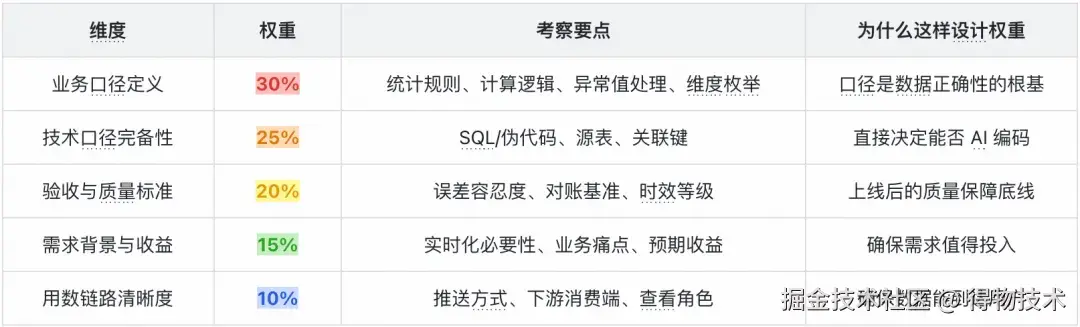
三条核心评分规则
规则一 :技术口径一票否决------如果技术口径得分 < 15 分(满分 25),即使总分 ≥ 90,也标注为不可执行。原因:没有技术口径,FlinkSpec 的 Flink-SQL Agent 完全无法启动编码。规则二 :验收标准缺失扣分------验收标准完全缺失,总分直接扣除 20 分;严重不足(≤5 分),扣除 10 分。原因:没有验收标准的需求,上线即翻车。规则三:溢出得分机制------某维度特别优秀可超出该维度满分,但总分上限仍为 100 分。原因:鼓励在关键维度上做到极致。
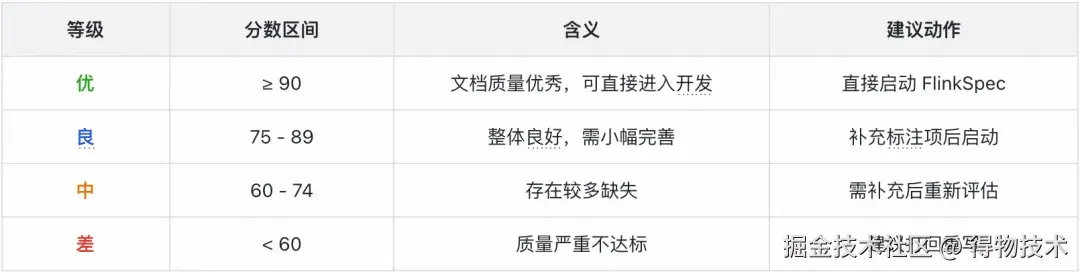
需要强调的是:PRD 评分不是硬卡点,不是流程阻塞。它是一面镜子,帮助团队看到当前 PRD 的质量水位,逐步建立质量意识。
能力三:自动拉群(工作流融合能力)
自动拉群看似简单,但它承载着一个重要的产品设计意图------降低落地阻碍。为什么做自动拉群?如果 BP Claw 只能生成文档,用户还需要手动拉群、手动 @ 人、手动转发文档,那使用体验就是割裂的。自动拉群让整个流程变成了"一步触发、全程自动":用户只需要在飞书群里 @ 机器人、@ 评审人,附上文档链接。BP Claw 自动完成:读取文档 → 生成标准化文档 → 质量评估 → 创建评审群 → 邀请成员 → 发送文档和诊断报告。评审人在新群里直接看到结构化的文档和质量报告,开始评审。这就是"贴合现有工作流"的具体体现------用户的行为没有变,但背后的效率翻了20倍。
四、技术难点与解决方案
省 Token 的技巧
在 AI 应用中,Token 消耗直接关系到成本和响应速度。BP Claw 在这方面做了多项优化。
技巧一:分段生成策略
对于包含 10 个以上指标的大文档,我们不会一次性生成完整文档(这会导致上下文溢出),而是采用分段生成:先创建文档骨架(业务背景 + 角色-页面-指标矩阵),逐个追加指标定义模块,每追加 5 个指标发送一次进度反馈,最后追加验收标准和用数链路。本质是把"一次大事务"拆成"多次小提交",即使中途失败也保留了已写入内容,不需要从头来。同时每段写入后向群聊发送进度消息(已生成 5/12 个指标),让用户有等待感知,不会误以为机器人卡死。收益:避免单次 API 调用超时,同时减少重复上下文传递的 Token 消耗。
技巧二:分层调用架构
BP Claw 采用编排者(动态调度,按需组合 Skill,职责清晰)模式,将核心逻辑拆分到三个独立 Skill 中:
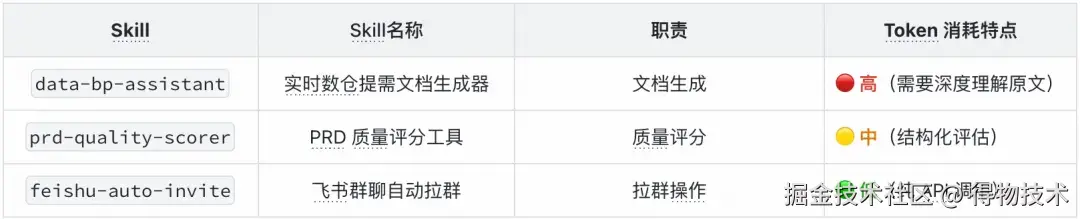
每个 Skill 独立运行、独立管理上下文,避免了将所有逻辑放在同一个上下文中导致的 Token 膨胀。
技巧三:模板化 Prompt 设计
标准化文档的七大模块,每个模块都有严格定义的模板结构。通过模板约束 AI 的输出格式,避免了冗余输出:明确指定输出字段,不多不少;使用 Markdown 表格约束结构;通过 Few-Shot 示例引导输出风格。
稳定性保障:如何避免幻觉?
这是 BP Claw 最重要的技术挑战。AI 生成的文档如果出现"幻觉"(编造不存在的业务口径),后果比不生成还严重。
策略一:严格的忠实性约束
在 Skill 的核心 Prompt 中,我们设置了多层约束:
核心规则:忠实于源材料原文有的 → 结构化提取原文没有的 → 标记 ⚠️ 待补充绝不凭空发明业务定义绝不猜测技术口径策略二:标记机制取代猜测
当 AI 遇到无法确定的信息时,不允许"猜测后继续",而是必须:明确标记为待补充;说明缺失的具体内容;给出建议补充的方向。这样做的好处是:用户看到的文档中,每一条确定的信息都是可信的。
策略三:质量评分的交叉验证
prd-quality-scorer 作为独立的评分 Skill,会对生成的文档进行"第二遍"审查。如果文档中存在明显的逻辑矛盾或不合理之处,评分报告中会直接指出。
策略四:参数校验与重试机制
arduino
• 调用飞书 API 前,强制校验所有必填参数• 文档生成失败 → 最多重试 3 次(间隔 2s → 5s → 10s 指数退避)• 3 次均失败 → 终止流程,发送明确的错误消息• 绝不降级生成"简化版"文档(不完整不如不生成)打磨 Skill 的技巧与难点
难点一:如何让 AI 理解"实时数仓"的领域语义?普通的 LLM 并不理解"去重视图""Lookup Join""sink.properties.columns"这些领域概念。我们通过以下方式解决:领域知识注入(在 Skill 定义中嵌入实时数仓的核心概念解释);模板驱动(通过模板结构限定输出范围,减少 AI 的"自由发挥空间");Few-Shot 示例(提供真实的标准化 PRD 样例作为参考)。
难点二:如何处理超长文档?有些 PRD 文档超过 10000 字符、包含 15+ 指标,直接处理会导致 API 超时(默认 60 秒不够用)、Token 超限、输出截断。解决方案:显式设置 timeoutSeconds=1200(20 分钟);采用分段生成策略,每次只处理 3-5 个指标;实时进度反馈,让用户知道系统仍在工作。
难点三:如何协调多个 Skill 的执行顺序?BP Claw 作为"指挥家/编排者",需要严格控制 4 个步骤的执行顺序和依赖关系:
vbscript
规则:严格串行,前序成功才执行后续STEP 1 成功 → STEP 2STEP 2 成功 → STEP 3STEP 3 成功或失败 → STEP 4(评分失败不阻塞)STEP 4 成功 → 完成任一关键步骤失败 → 立即终止,通知用户为什么 STEP 3 失败不阻塞?因为质量评分是"参照"而非"卡点"。即使评分失败,标准化文档和评审群依然有价值。
五、与 FlinkSpec 的联动:全链路赋能
BP Claw → FlinkSpec 的价值传递
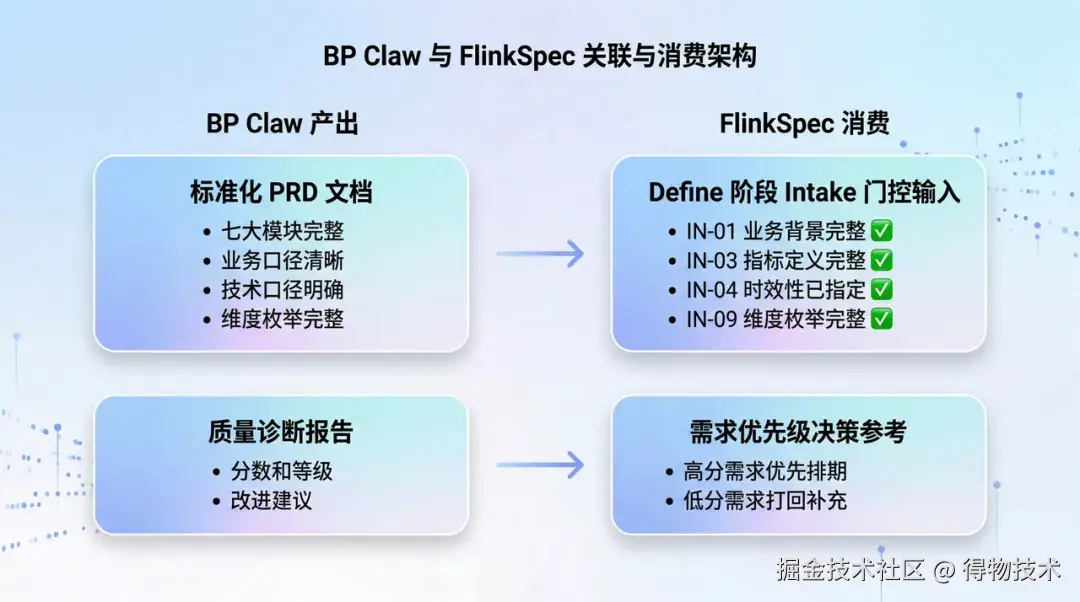
体验效果:PRD 质量提升对 AI Coding 的赋能
场景一 :技术口径完整的 PRD------BP Claw 评分 ≥ 90 分,FlinkSpec Define 阶段一次通过,无 BLOCK,Flink-SQL Agent 直接编码无需人工干预,整体交付周期为天级 ⏱️。场景二 :技术口径缺失的 PRD------BP Claw 评分 < 60 分,触发技术口径一票否决,FlinkSpec Define 阶段频繁触发阻塞协议,Flink-SQL Agent 无法编码需反复沟通,整体交付周期为周级。结论: BP Claw 每提升 10 分的 PRD 质量,FlinkSpec 的编码阶段效率约提升 30%。
六、落地运营:产品 + 运营 = 真正的落地
一个好的产品工具,如果没有运营手段的配合,是无法真正落地的。BP Claw 在落地过程中,我们采用了产品能力 + 运营能力双轮驱动的策略。
运营手段一:成熟度评分体系
我们建立了 域级 PRD 成熟度评分 机制,通过持续追踪各业务域的 PRD 质量水位,推动整体提升:
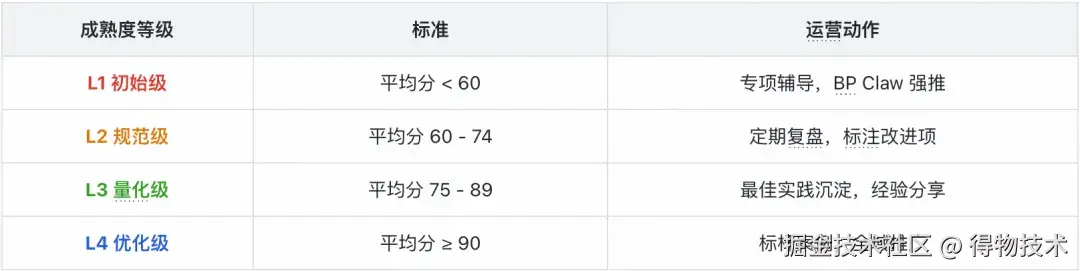
运营手段二:质量趋势追踪
通过持续收集每次 PRD 评分数据,建立质量趋势看板:按业务域维度追踪质量变化;识别高频缺失项,定向改进;月度质量复盘,表彰优秀案例。
运营手段三:最佳实践沉淀
将高分 PRD 案例沉淀为模板,形成可复用的知识资产:优秀案例库(≥ 90 分的 PRD 自动入库);改进指南(针对常见扣分项提供标准化的补充模板);新人培训(通过 BP Claw 评分报告快速上手 PRD 编写规范)。
七、快速上手
使用方法
只需一步:在飞书群聊中发送一条消息:
swift
@商业化MOSS @评审人1 @评审人2 @评审人N.... 需求拉群 飞书PRD文档链接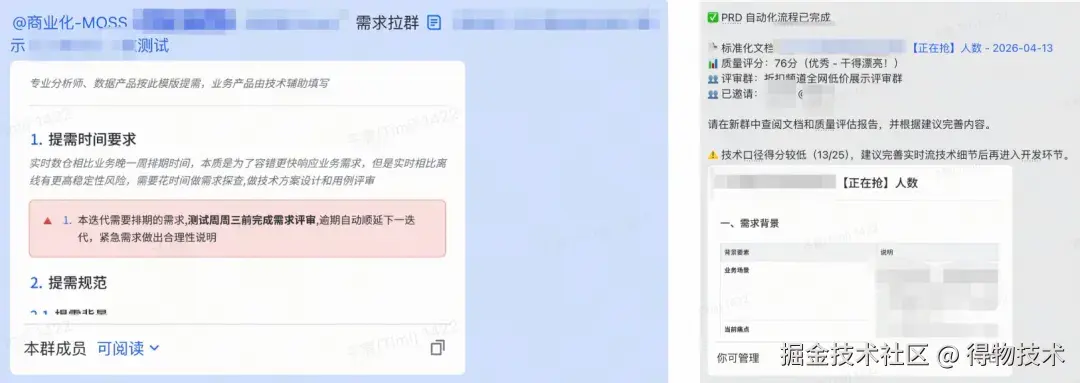
然后等待 1-5 分钟,你将在新的评审群中看到:标准化 PRD 文档、质量诊断报告、改进建议清单。
注意事项

八、展望后续
本文为 FlinkSpec 系列之开篇,亦是这场工程化变革的序章。BP Claw 所立之处,不过链路之源。FlinkSpec 所图,乃以 AI 之力,将实时数仓从需求落地至验收上线的全程工序,熔铸为一套精密自洽、生生不息的智能工程体系。宏图未竟,后续系列将逐章揭幕,敬请期待!
往期回顾
1.基于 Harness + SDD + 多仓管理模式的 AI 全栈开发实践|得物技术
2.通用 AI Agent 驱动网关路由安全审计实践|得物技术
5.立正请站好:一个组件复用 Skill 的工程化实践|得物技术
文 /子宸
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。