基于AnimeGANv2的照片动漫化
一、作者介绍
作者:陈辛怡,西安工程大学电子信息学院,2025级研究生
研究方向:可见光与SAR图像融合
联系邮箱:321424455@qq.com
作者:李逸超,西安工程大学电子信息学院,2025级研究生 张宏伟人工智能课题组
研究方向:机器视觉与人工智能
联系邮箱:2317314922@qq.com
二、AnimeGANv2核心原理
2.1图像风格迁移概述
图像风格迁移是计算机视觉领域的核心研究方向,目标是在保留输入图像内容结构 的前提下,将图像的视觉表现形式转换为目标艺术风格。
传统风格迁移依赖 CNN 提取内容与风格特征进行图优化,速度慢、效果不稳定;基于 GAN 的端到端风格迁移凭借生成质量高、推理速度快、风格一致性强等优势,成为照片动漫化的主流技术路线。
照片动漫化属于非成对图像转换 任务,无需配对数据,可将真实人像、风景、建筑、街景等自动转为日系二次元动漫风格,广泛用于短视频特效、图像创作、虚拟形象、文创设计等场景。
2.2AnimeGANv2概述
AnimeGANv2是一种轻量级生成对抗网络,专注于将真实世界高效转换为日系动漫风格图像。它在 AnimeGAN 基础上优化了网络结构、损失函数与训练策略,在保持动漫风格高保真的同时,大幅提升推理速度与内容保留能力。
该模型广泛应用于短视频特效、图片创作、虚拟形象生成、游戏素材制作等领域,因其风格纯正、细节清晰、轻量化 而成为照片动漫化的主流方案。
2.3生成对抗基础网络
GAN 由生成器与判别器构成:生成器学习真实数据分布并生成假样本;判别器判断输入为真实样本还是生成样本。二者通过对抗训练不断优化,最终生成器可输出逼近真实分布的图像。
AnimeGANv2 基于 GAN 架构,属于无配对图像风格迁移模型 ,无需照片 --- 动漫成对数据,只需分别收集真实照片与动漫截图即可训练,大幅降低数据成本。
2.4生成器(generator)
负责将真实照片映射为动漫风格图像:
- 编码器(下采样) :通过卷积提取高层内容特征,压缩空间尺寸
- 残差块 :增强深层特征表达,避免梯度消失,保留细节
- 解码器(上采样) :逐步恢复尺寸,输出动漫化结果
使用实例归一化 提升风格一致性与训练稳定性。
2.5判别器(Discriminator)
扮演"真伪鉴别"的角色,通过深度卷积网络学习真实动漫图片的特征分布。它不断接收生成器的输出与真实动漫图,输出图像为"真动漫"的概率,以此引导生成器优化生成策略,让生成的动漫图像在细节、色彩、笔触上更接近真实的动漫作品。
2.6损失函数设计
AnimeGANv2 的总损失由四部分加权组成,是保证高质量动漫化的关键:
- 对抗损失(Adversarial Loss)
基于 WGAN-GP,确保生成图像分布与真实动漫分布一致,提升真实感。
- 内容损失(Content Loss)
使用 VGG19 网络提取图像高层语义特征,保证生成图像与输入照片内容一致,避免轮廓变形。
- 风格损失(Style Loss)
包含 Gram 矩阵风格损失与灰度风格损失,强制学习动漫的色彩、纹理、笔触特征。
- 边缘梯度损失(Gradient Loss)
保留图像边缘轮廓,使动漫线条清晰流畅,无模糊断裂。
三、数据集介绍与预处理
3.1数据集构成
AnimeGANv2 训练需要三类数据:
- 真实照片数据集(Photo)
来源:网络风景、人像、街景照片;
数量:500-700 张;
尺寸:256×256;
用途:作为风格迁移输入源。
- 动漫风格数据集(Anime)
来源:日系动漫高清截图(如《起风了》、《你的名字&与你共度时光》、《辣椒粉》);
数量:500-700 张;
尺寸:256×256;
用途:提供目标动漫风格。
- 动漫平滑数据集(Anime_Smooth)
来源:对动漫截图进行高斯模糊处理;
用途:帮助判别器区分动漫纹理与噪声,减少伪影。
3.2数据集来源
该数据集来自谷歌网,如图3.1 AnimeGANv2检索,图3.2 AnimeGANv2检索结果展示,图3.3 数据集展示。
3.1 AnimeGANv2的谷歌检索
图3.2 AnimeGANv2检索结果展示
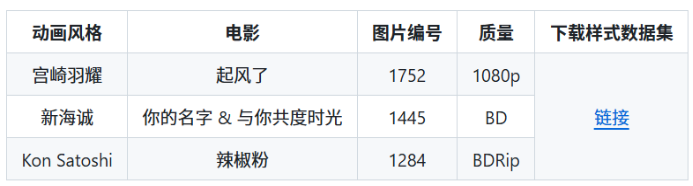
图3.3 数据集展示
3.3数据集预处理
- 尺寸统一 :将所有图像缩放到 256×256,保持训练稳定;
- 归一化 :像素值从 0,255 归一化到 -1,1,适配网络输入;
- 数据增强 :随机水平翻转、旋转、裁剪、亮度调整,提升泛化能力;
- 去重与清洗 :删除模糊、水印、低质量图像,保证训练数据纯度。
3.4数据集目录结构
AnimeGANv2/
├── dataset/
│ ├── train_photo/ 真实照片
│ ├── train_anime/ 动漫图像
│ ├── test/ 测试照片
│ └── smooth/ 动漫平滑图
├── models/ 模型权重
├── results/ 生成结果
└── main.py 主程序
四、算法流程
4.1训练流程
- 加载真实照片、动漫图像、动漫平滑图;
- 初始化生成器与判别器;
- 固定生成器,训练判别器区分三类图像;
- 固定判别器,训练生成器最小化总损失;
- 周期性保存模型权重,验证生成效果;
- 损失收敛后停止训练。
4.2推理流程
- 加载预训练模型权重;
- 读取输入照片并预处理;
- 送入生成器前向推理;
- 后处理恢复像素值范围;
- 保存动漫化输出图像。
五、代码实现
5.1环境配置
python = 7
pytorch >= 1.8
opencv-python
pillow
numpy
tqdm
matplotlib
安装命令:
pip install torch torchvision opencv-python pillow numpy tqdm matplotlib
5.2代码
1.测试代码
python
import os
import warnings
# 屏蔽 TensorFlow 警告信息
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 只显示 ERROR,忽略 INFO 和 WARNING
warnings.filterwarnings('ignore') # 屏蔽 Python warnings
# 屏蔽 Python 警告
warnings.filterwarnings('ignore')
# 屏蔽 TensorFlow INFO/WARNING
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 0 = all, 1 = INFO, 2 = WARNING, 3 = ERROR
# 屏蔽 TF 2.x 的兼容性警告
import logging
logging.getLogger('tensorflow').setLevel(logging.ERROR)
import tensorflow as tf
tf.get_logger().setLevel('ERROR')
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR) # 对 TF1.x 的 API 警告也屏蔽
import argparse
from tools.utils import *
import os
import warnings
# 屏蔽 TensorFlow 警告信息
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 只显示 ERROR,忽略 INFO 和 WARNING
warnings.filterwarnings('ignore') # 屏蔽 Python warnings
from tqdm import tqdm
from glob import glob
import time
import numpy as np
from net import generator
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
def parse_args():
desc = "AnimeGANv2"
parser = argparse.ArgumentParser(description=desc)
parser.add_argument('--checkpoint_dir', type=str, default='checkpoint/'+'generator_Shinkai_weight',
help='Directory name to save the checkpoints')
parser.add_argument('--test_dir', type=str, default='test_photo',
help='Directory name of test photos')
parser.add_argument('--save_dir', type=str, default='Shinkai/t',
help='what style you want to get')
parser.add_argument('--if_adjust_brightness', type=bool, default=True,
help='adjust brightness by the real photo')
"""checking arguments"""
return parser.parse_args()
def stats_graph(graph):
flops = tf.profiler.profile(graph, options=tf.profiler.ProfileOptionBuilder.float_operation())
# params = tf.profiler.profile(graph, options=tf.profiler.ProfileOptionBuilder.trainable_variables_parameter())
print('FLOPs: {}'.format(flops.total_float_ops))
def test(checkpoint_dir, style_name, test_dir, if_adjust_brightness, img_size=[256,256]):
# tf.reset_default_graph()
result_dir = 'results/'+style_name
check_folder(result_dir)
test_files = glob('{}/*.*'.format(test_dir))
test_real = tf.placeholder(tf.float32, [1, None, None, 3], name='test')
with tf.variable_scope("generator", reuse=False):
test_generated = generator.G_net(test_real).fake
saver = tf.train.Saver()
gpu_options = tf.GPUOptions(allow_growth=True)
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True, gpu_options=gpu_options)) as sess:
# tf.global_variables_initializer().run()
# load model
ckpt = tf.train.get_checkpoint_state(checkpoint_dir) # checkpoint file information
if ckpt and ckpt.model_checkpoint_path:
ckpt_name = os.path.basename(ckpt.model_checkpoint_path) # first line
saver.restore(sess, os.path.join(checkpoint_dir, ckpt_name))
print(" [*] Success to read {}".format(os.path.join(checkpoint_dir, ckpt_name)))
else:
print(" [*] Failed to find a checkpoint")
return
# stats_graph(tf.get_default_graph())
begin = time.time()
for sample_file in tqdm(test_files) :
# print('Processing image: ' + sample_file)
sample_image = np.asarray(load_test_data(sample_file, img_size))
image_path = os.path.join(result_dir,'{0}'.format(os.path.basename(sample_file)))
fake_img = sess.run(test_generated, feed_dict = {test_real : sample_image})
if if_adjust_brightness:
save_images(fake_img, image_path, sample_file)
else:
save_images(fake_img, image_path, None)
end = time.time()
print(f'test-time: {end-begin} s')
print(f'one image test time : {(end-begin)/len(test_files)} s')
if __name__ == '__main__':
arg = parse_args()
print(arg.checkpoint_dir)
test(arg.checkpoint_dir, arg.save_dir, arg.test_dir, arg.if_adjust_brightness)
2.训练代码
from AnimeGANv2 import AnimeGANv2
import argparse
from tools.utils import *
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
"""parsing and configuration"""
def parse_args():
desc = "AnimeGANv2"
parser = argparse.ArgumentParser(description=desc)
parser.add_argument('--dataset', type=str, default='Hayao', help='dataset_name')
parser.add_argument('--epoch', type=int, default=101, help='The number of epochs to run')
parser.add_argument('--init_epoch', type=int, default=10, help='The number of epochs for weight initialization')
parser.add_argument('--batch_size', type=int, default=12, help='The size of batch size') # if light : batch_size = 20
parser.add_argument('--save_freq', type=int, default=1, help='The number of ckpt_save_freq')
parser.add_argument('--init_lr', type=float, default=2e-4, help='The learning rate')
parser.add_argument('--g_lr', type=float, default=2e-5, help='The learning rate')
parser.add_argument('--d_lr', type=float, default=4e-5, help='The learning rate')
parser.add_argument('--ld', type=float, default=10.0, help='The gradient penalty lambda')
parser.add_argument('--g_adv_weight', type=float, default=300.0, help='Weight about GAN')
parser.add_argument('--d_adv_weight', type=float, default=300.0, help='Weight about GAN')
parser.add_argument('--con_weight', type=float, default=1.5, help='Weight about VGG19')# 1.5 for Hayao, 2.0 for Paprika, 1.2 for Shinkai
# ------ the follow weight used in AnimeGAN
parser.add_argument('--sty_weight', type=float, default=2.5, help='Weight about style')# 2.5 for Hayao, 0.6 for Paprika, 2.0 for Shinkai
parser.add_argument('--color_weight', type=float, default=10., help='Weight about color') # 15. for Hayao, 50. for Paprika, 10. for Shinkai
parser.add_argument('--tv_weight', type=float, default=1., help='Weight about tv')# 1. for Hayao, 0.1 for Paprika, 1. for Shinkai
# ---------------------------------------------
parser.add_argument('--training_rate', type=int, default=1, help='training rate about G & D')
parser.add_argument('--gan_type', type=str, default='lsgan', help='[gan / lsgan / wgan-gp / wgan-lp / dragan / hinge')
parser.add_argument('--img_size', type=list, default=[256,256], help='The size of image: H and W')
parser.add_argument('--img_ch', type=int, default=3, help='The size of image channel')
parser.add_argument('--ch', type=int, default=64, help='base channel number per layer')
parser.add_argument('--n_dis', type=int, default=3, help='The number of discriminator layer')
parser.add_argument('--sn', type=str2bool, default=True, help='using spectral norm')
parser.add_argument('--checkpoint_dir', type=str, default='checkpoint',
help='Directory name to save the checkpoints')
parser.add_argument('--log_dir', type=str, default='logs',
help='Directory name to save training logs')
parser.add_argument('--sample_dir', type=str, default='samples',
help='Directory name to save the samples on training')
return check_args(parser.parse_args())
"""checking arguments"""
def check_args(args):
# --checkpoint_dir
check_folder(args.checkpoint_dir)
# --log_dir
check_folder(args.log_dir)
# --sample_dir
check_folder(args.sample_dir)
# --epoch
try:
assert args.epoch >= 1
except:
print('number of epochs must be larger than or equal to one')
# --batch_size
try:
assert args.batch_size >= 1
except:
print('batch size must be larger than or equal to one')
return args
"""main"""
def main():
# parse arguments
args = parse_args()
if args is None:
exit()
# open session
gpu_options = tf.GPUOptions(allow_growth=True)
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True,inter_op_parallelism_threads=8,
intra_op_parallelism_threads=8,gpu_options=gpu_options)) as sess:
gan = AnimeGANv2(sess, args)
# build graph
gan.build_model()
# show network architecture
show_all_variables()
gan.train()
print(" [*] Training finished!")
if __name__ == '__main__':
main()六、问题与分析
6.1 pytorch环境适配问题
- 问题:由于电脑问题pytorch环境搭建不上,如图6.1。
图6.1 pytorch环境搭建问题图
- 解决方法:
(1)询问AI,按AI给出的方案去搭建环境,由于电脑问题,搭建还是未能搭建出来。
(2)寻找懂pytorch的同学帮忙搭建。
6.2 python版本问题
问题:要求python 7版本的环境依赖问题,如图6.2。
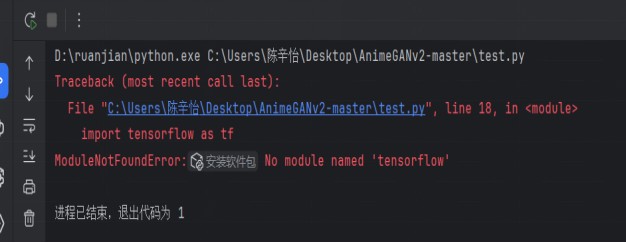
图6.2 测试错误图
解决方法:寻找师兄帮忙解决。
6.3 生成图像模糊或出现伪影
现象与原因:画面整体发虚、有马赛克或色彩断层;通常是输入原图分辨率过低、光线不足,或预处理时的降噪操作过度丢失了纹理细节。如图6.3为原图,图6.4为生成模糊或有伪影的图片。图6.5是解决之后所输出的高清动漫图。



图6.3 原图 图6.4出现伪影/模糊 图6.5高清动漫图
解决方案:确保输入照片清晰且光照均匀;尝试更换不同的预训练模型(如Realistic Vision);生成后可通过Photoshop等工具进行轻微的"高反差保留"锐化处理。如图6.5是解决之后所输出的高清动漫图。
6.4 风格差异不显著与原图差异小
现象与原因:生成图只是简单的滤镜效果,缺乏艺术感,如图6.6为原图,图6.7为生成图;原因是选择的模型风格与输入内容的属性不匹配。



6.6原图 6.6 生成简单滤镜效果图 6.7高清动漫图
解决方案:"对症下药"选择模型:风景照用新海诚(Shinkai)或宫崎骏风格模型,人像用face_paint或二次元动漫模型,建筑用赛博朋克风格模型,如图6.7。