核心数据结构:元组、列表与字典的实战辨析
在日常开发中,Python 的内置数据结构是我们最频繁打交道的对象。很多初学者容易混淆元组(Tuple)、列表(List)和字典(Dictionary)的使用场景,尤其是在处理复杂数据流时,选错结构往往会导致代码冗余甚至运行时错误。我们需要从"可变性"这一核心特征入手,理清它们的本质区别,并掌握一些容易被忽略的成员运算细节。
可变与不可变的边界
列表和元组在外观上非常相似,都是有序的元素序列,支持索引访问和切片操作。例如,
让我们看一个具体的例子。假设有一个字典 d = {1: '1', 'abc': 0.1, 0.4: 80} 。
当我们执行 'abc' in d 时,返回 True,因为 'abc' 确实是一个键。
但是,如果我们执行**0.1 in d**,结果却是 False。尽管 0.1 存在于字典的值集合中,但 in 运算符默认只遍历字典的键空间。
更隐蔽的陷阱:键的类型与 in 运算
python
# 示例 1:混合类型的键
mixed_dict = {1: "整数键", "1": "字符串键", (1, 2): "元组键"}
print(1 in mixed_dict) # True,检查整数键 1
print("1" in mixed_dict) # True,检查字符串键 "1"
print((1, 2) in mixed_dict) # True,检查元组键 (1, 2)
print([1, 2] in mixed_dict) # TypeError: unhashable type: 'list' (列表不可哈希,不能作为键)
# 示例 2:浮点数键的精度问题
float_key_dict = {0.1: "浮点键", 0.2: "另一个浮点键"}
print(0.1 in float_key_dict) # True,看起来没问题
print(0.3 in float_key_dict) # False,没问题
# 但注意浮点数精度问题可能导致意外
calculated_key = 0.1 + 0.2
print(calculated_key in float_key_dict) # False!因为 0.1 + 0.2 的结果是 0.30000000000000004,不等于 0.3检查值的存在性
python
# 正确检查值是否存在的方法
d = {"name": "Alice", "age": 30, "city": "Beijing"}
# 方法1:使用 .values() (O(n) 线性查找)
print("Alice" in d.values()) # True
print(30 in d.values()) # True
print("Shanghai" in d.values()) # False
# 方法2:如果需要频繁反查,构建反向映射 (O(1) 哈希查找)
reverse_dict = {v: k for k, v in d.items()} # 注意:值必须唯一,否则会覆盖
print("Alice" in reverse_dict) # True,现在变成了键查找
# 方法3:使用集合存储需要频繁查找的值
values_set = set(d.values())
print("Alice" in values_set) # True实际工程中的建议
- 设计优先:如果某个数据需要被频繁查询是否存在,尽量将其设计为字典的键。
- 类型一致:字典的键应使用不可变类型(字符串、数字、元组),避免使用列表等可变类型。
- 性能权衡 :
.values()的 O(n) 查找在小数据量下可以接受,但在循环或大数据集下应考虑构建反向索引。 - 明确语义 :写
if key in dict时,心里要清楚这是在检查键,而不是值。如果代码审查时看到if value in dict,这很可能是一个 Bug。
是一个元组,而[1, 'abc', 0.4]是一个列表。两者最大的分水岭在于可变性。
列表是可变序列,这意味着你可以在创建后随时修改其中的元素、添加新项或删除旧项。这种灵活性使得列表成为存储动态集合的首选,比如日志队列、待处理任务列表等。然而,这种可变性也带来了开销,在某些对性能敏感或需要保证数据一致性的场景下,列表并不是最优解。
相比之下,元组一旦创建,其内部元素就无法被修改、添加或删除。这种不可变性 (Immutability)赋予了元组两个关键优势:一是安全性,数据不会被意外篡改;二是性能,由于内存布局固定,元组的迭代速度通常略快于列表,且可以作为字典的键(Key)使用,而列表则不行。在实际工程中,如果你定义了一组配置常量或者坐标点 (x, y),且确定后续不会改变它们,使用元组是更符合 Pythonic 风格的做法。
字典的键值对逻辑与成员运算陷阱
字典是 Python 中最强大的映射类型,通过键(Key)来唯一标识并存取值(Value)。它的语法直观:{key: value}。虽然查找某个键对应的值非常简单(如 d['abc']),但在进行成员检查时,有一个极易踩坑的细节:in 运算符在字典中仅检查键(Key),而不检查值(Value)。
让我们看一个具体的例子。假设有一个字典 d = {1: '1', 'abc': 0.1, 0.4: 80} 。
当我们执行 'abc' in d 时,返回 True,因为 'abc' 确实是一个键。
但是,如果我们执行 0.1 in d,结果却是 False。尽管 0.1 存在于字典的值集合中,但 in 运算符默认只遍历字典的键空间。
这一点在处理大规模数据校验时至关重要。如果你需要判断某个值是否存在于字典中,必须显式地检查 .values(),即 0.1 in d.values()。虽然这样写语义清晰,但需要注意的是,.values() 返回的是一个视图对象,线性查找的时间复杂度为 O(n),在大数据量下性能远不如基于哈希的键查找 O(1)。因此,在设计数据结构时,如果频繁需要根据内容反查存在性,应考虑将该内容设计为键,或者使用集合(Set)来辅助索引,而不是依赖遍历字典的值。
对于列表和元组,in 运算符的行为则符合直觉,它会线性扫描序列中的每一个元素。例如 0.4 in [1, 'abc', 0.4] 会返回 True。理解这些细微差别,能帮我们在编写条件判断逻辑时避免隐蔽的 Bug。
in 运算符在字典中的判断流程
为了更直观地理解 in 运算符在字典中的行为,以及如何正确检查值的存在性,可以参考下面的流程图:
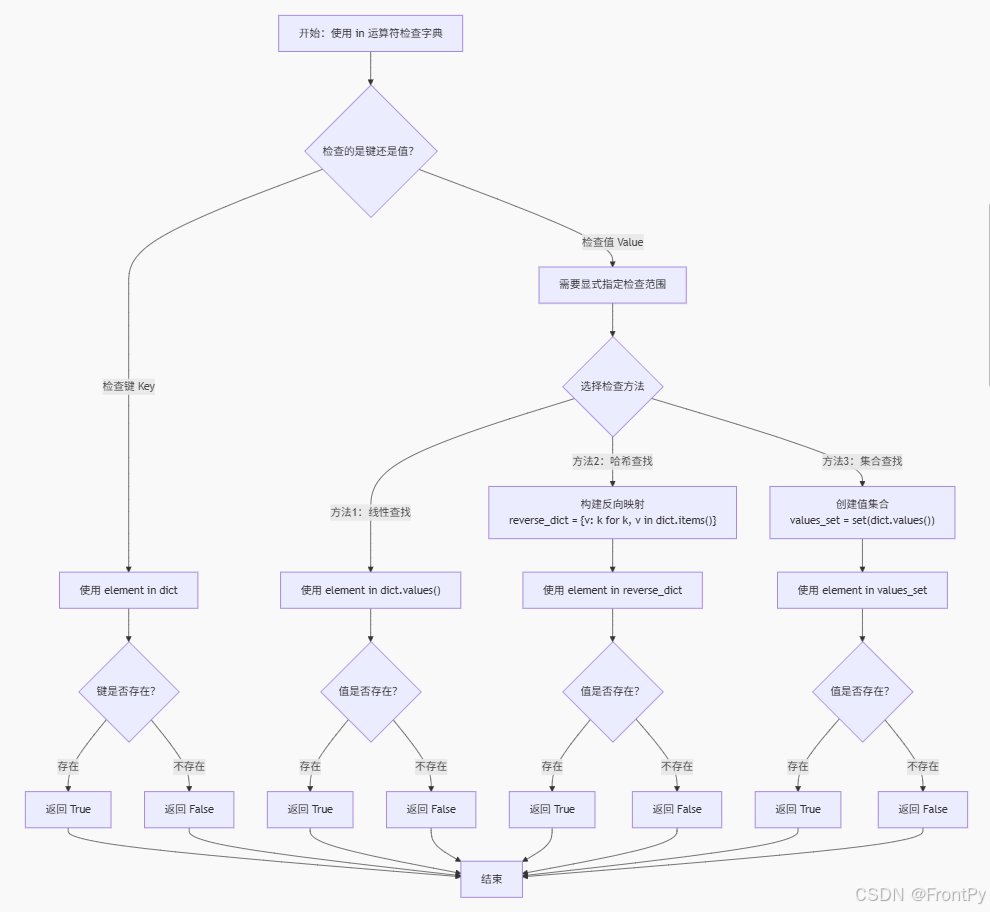
流程图解读:
-
键检查路径(左侧) :直接使用
element in dict,这是in运算符在字典中的默认行为,只检查键空间。 -
值检查路径(右侧):需要显式指定检查范围,有三种常用方法:
.values()方法:线性查找,时间复杂度 O(n),适合小数据量- 构建反向映射:将值作为键构建新字典,时间复杂度 O(1),但要求值唯一
- 转换为集合:将值转换为集合,时间复杂度 O(1),适合中等数据量
-
性能与适用场景:
- 如果频繁需要检查某个值是否存在,应优先考虑将其设计为字典的键
- 对于一次性或低频查询,使用
.values()方法即可 - 对于中等规模数据且需要多次查询,转换为集合是较好的折中方案
这个流程图清晰地展示了 Python 字典中 in 运算符的核心逻辑:默认只检查键,检查值需要额外步骤。理解这一点能帮助你在编写条件判断时避免常见的逻辑错误。
数值计算进阶:Numpy 数组转换与复数运算
当数据处理需求从简单的逻辑流转深入到数值计算领域时,原生列表的性能瓶颈便会显现。此时,引入 Numpy 库进行向量化操作是标准做法。此外,Python 原生支持的复数类型在工程信号处理、电磁场模拟等领域有着不可替代的作用,但其用法往往被常规教程所忽视。
高效的数据类型转换:List 到 Numpy Array
在处理科学计算或机器学习任务时,我们经常需要将原始的 Python 列表转换为 Numpy 数组。直接使用 numpy.asarray() 是最推荐的方式,它不仅效率高,还能智能地处理内存共享问题。
基础的转换非常简单:
python
import numpy as np
data_list = [1, 2, 3, 4]
arr = np.asarray(data_list)但这只是冰山一角。asarray 的强大之处在于其第二个参数 dtype,它允许我们在转换的同时强制指定数据类型。这在处理大规模数据时能显著节省内存并提升计算速度。例如,原始列表包含的是 Python 标准的整数对象(每个占用 28 字节左右),如果我们明确知道数据范围较小,可以将其转换为 int32 甚至 int8;如果是浮点数运算,指定为 float32 往往比默认的 float64 快一倍且省一半内存。
python
# 转换为单精度浮点型数组,适合深度学习推理等场景
float_arr = np.asarray([1, 2, 3], dtype='f')
# 输出:array([1., 2., 3.], dtype=float32)
# 转换为整型数组
int_arr = np.asarray([1.9, 2.1, 3.5], dtype='i')
# 输出:array([1, 2, 3]),注意这里发生了截断这种显式的类型控制在涉及底层 C 扩展调用或与二进制文件交互时尤为重要。相比于先创建列表再逐个转换元素,asarray 能在底层一次性完成内存分配和数据拷贝,避免了中间临时对象的产生,是高性能数据处理流水线的基石。
被遗忘的复数:表示、提取与共轭
Python 是少数几种在语法层面原生支持复数(Complex Number)的主流编程语言之一。复数在电气工程的交流电路分析、量子力学波函数描述以及数字信号处理的傅里叶变换中是基础单元。然而,许多开发者直到遇到相关需求时,才发现自己对其语法一无所知。
1. 复数的字面量表示
在 Python 中,复数的虚部后缀必须是 j 或 J(数学中常用 i,但在 Python 中 i 只是一个普通变量名)。实部和虚部都是浮点数。
python
c1 = 3 + 4j
c2 = complex(3, 4) # 也可以使用 complex() 构造函数值得注意的是,如果虚部为 1,不能省略数字直接写 +j,必须写成 1j。例如 3 + 1j 是合法的,而 3 + j 会抛出 NameError,除非你预先定义了 j = 1j。
2. 实部与虚部的提取
获取复数的实部和虚部非常直观,直接访问 .real 和 .imag 属性即可。这两个属性返回的都是浮点数。
python
z = 3 + 4j
real_part = z.real # 3.0
imag_part = z.imag # 4.0在进行信号解调或坐标转换时,这种直接属性访问的方式比调用函数更加高效且可读性强。
3. 共轭复数与模长计算
共轭复数(Conjugate)是将虚部符号取反的操作,即 a + bi 变为 a - bi。在 Python 中,所有复数对象都内置了 .conjugate() 方法。
python
z = 3 + 4j
z_conj = z.conjugate()
# 结果为 (3-4j)这个方法在计算复数的模长平方(z * z.conjugate())或者进行分母有理化时非常有用。
除了共轭,另一个高频操作是求复数的模(Magnitude),即复平面上点到原点的距离,计算公式为 a2+b2a2+b2。Python 内置的 abs() 函数可以直接作用于复数,无需导入 math 模块。
python
magnitude = abs(z)
# 结果为 5.0,因为 sqrt(3^2 + 4^2) = 5这种内置支持使得复数运算代码极其简洁。例如,在计算两个信号的相位差或功率时,我们可以直接链式调用:
python
signal = 10 + 5j
power = abs(signal) ** 2 # 计算功率,等于 signal * signal.conjugate()
normalized = signal / abs(signal) # 归一化,得到单位复数综合应用场景
将上述知识点结合起来,我们可以构建一个小型的数据处理片段。假设我们需要处理一批传感器读数,其中包含复数形式的阻抗数据。我们首先用列表收集数据,然后利用 Numpy 进行批量类型转换以优化存储,最后利用复数特性计算模长和共轭。
python
import numpy as np
# 模拟原始传感器数据 (列表)
raw_impedance = [3+4j, 1+1j, 5-12j, 0.5+0.5j]
# 虽然 numpy 对复数数组支持良好,但在某些特定硬件接口可能需要分离实虚部
# 这里演示如何快速提取实部并转为 float32 数组以节省空间
real_parts = np.asarray([z.real for z in raw_impedance], dtype='f')
# 直接对复数列表进行向量化操作通常更优雅
impedance_array = np.array(raw_impedance)
# 批量计算模长
magnitudes = np.abs(impedance_array)
# 批量获取共轭
conjugates = np.conjugate(impedance_array)
print(f"原始数据:{raw_impedance}")
print(f"模长集合:{magnitudes}")
print(f"共轭集合:{conjugates}")这段代码展示了从基础数据结构到高级数值计算的平滑过渡。理解列表与元组的取舍,掌握字典 in 运算的真实行为,熟练运用 Numpy 的类型控制,以及不畏惧复数运算,这些技能点共同构成了一个 Python 开发者扎实的基本功。在面对复杂的工程问题时,正是这些看似细碎的语法特性,决定了代码的健壮性与执行效率。