适合准备 NLP / 大模型应用 / 算法 / 智能问答方向面试的人阅读
|------------------------------------------------------------------------------------------------------------------------------------|
| 导读 很多人一提到 NLP,第一反应就是"分词"。这其实只说对了一小部分。真正的 NLP,是一整套让机器理解、分析、检索、抽取、归类、总结并生成人类语言的技术体系。本文围绕面试高频问题展开,用通俗语言把核心概念、常见任务、业务场景和答题思路一次讲清楚。 |
如果把计算机视觉理解成"让机器看懂图片",那么自然语言处理可以理解成"让机器读懂人话"。人类说话写字看似自然,但对机器来说却非常难,因为语言里不仅有字面意思,还有语境、常识、语气、隐含意图,甚至还有反讽、双关和省略。
也正因为如此,NLP 一直都是人工智能里最接近真实业务的一条线。搜索、客服、舆情、内容审核、合同解析、会议纪要、知识库问答、翻译、写作辅助,本质上都离不开 NLP。
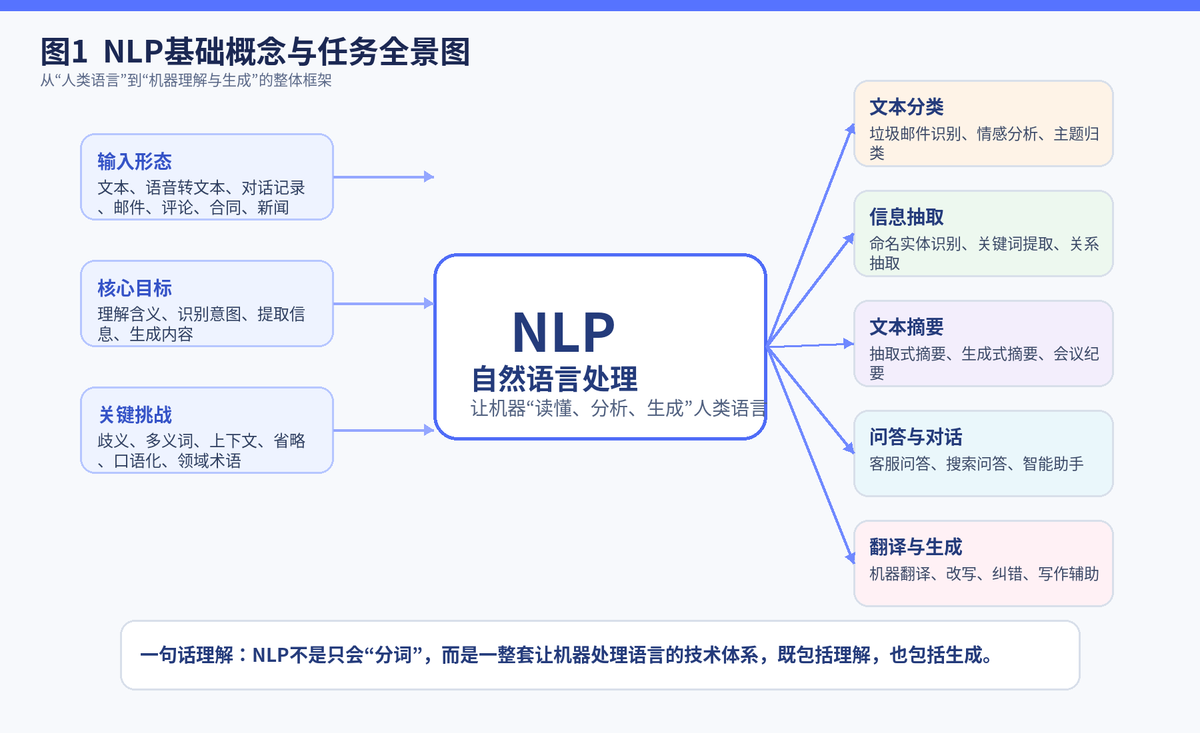
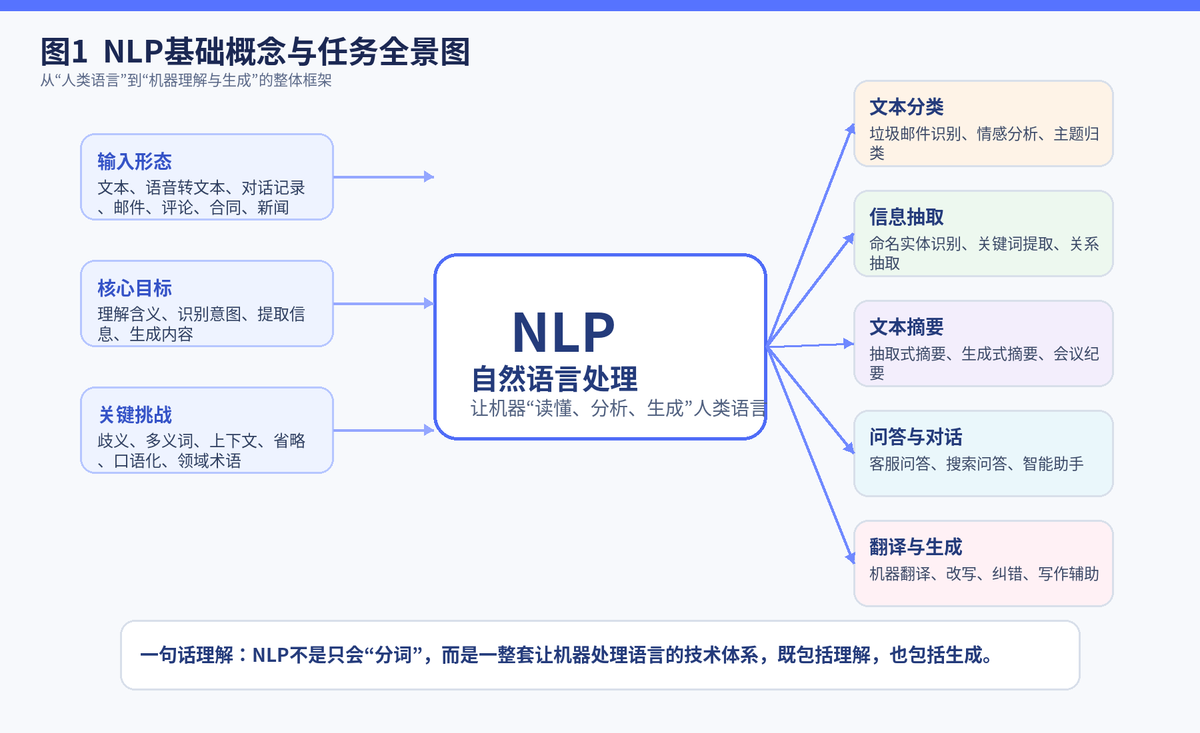
1. 面试题:什么是自然语言处理(NLP)?
1.1 用一句人话解释 NLP
NLP,全称 Natural Language Processing,自然语言处理。它的目标很直接:让机器能够处理人类语言。这里的"处理"不是简单识别文字,而是包括理解意思、提取关键信息、判断类别、回答问题、生成内容等一整套能力。
换句话说,NLP 干的事,就是把"人类语言"转成"机器可以计算的信息",再把"机器的结果"重新变成人能看懂的表达。
1.2 NLP 的核心不只是理解,还包括生成
很多人会把 NLP 只理解成"理解语言",其实并不完整。NLP 既包含理解,也包含生成。前者偏向 NLU,也就是 Natural Language Understanding,比如文本分类、情感分析、命名实体识别;后者偏向 NLG,也就是 Natural Language Generation,比如摘要、翻译、改写、写作辅助。
到了大模型时代,理解和生成的边界进一步被打通。一个模型既能回答问题,也能总结文章,还能提取字段、改写文本、做多轮对话。所以今天谈 NLP,已经不能只停留在传统的"分词+分类"阶段,而要从任务能力和产品落地两个角度一起看。
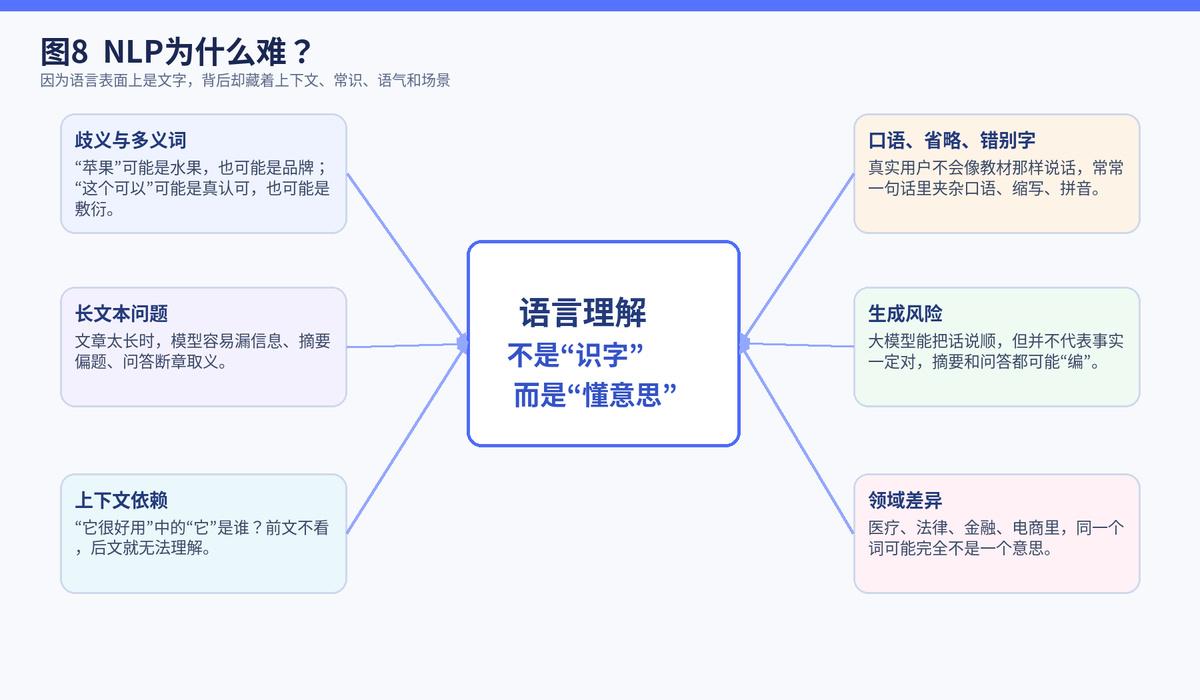
1.3 为什么 NLP 难度一直很高
因为图片中的"猫"通常就是猫,但一句话里的"这个可以啊",到底是在夸人、敷衍,还是阴阳怪气,要看上下文。语言天然带有歧义、主观性和场景依赖。
所以 NLP 最难的地方,从来不是"识别出字",而是"真正理解意思"。这也是为什么同样一句话,在电商客服、法律合同、医疗病历、社交评论里,处理方式会完全不一样。
|-----------------------------------------------------------------------------------------|
| 面试答题金句 回答"什么是 NLP"时,最稳妥的说法是:NLP 是让机器对人类语言进行理解、分析和生成的一整套技术体系,覆盖分类、抽取、摘要、翻译、问答、对话等任务。 |
2. NLP 常见任务有哪些?
2.1 从任务形态看,NLP 大致可以分成五类
第一类是分类类任务,也就是给文本打标签,比如垃圾邮件识别、情感分析、新闻主题归类、工单自动分流。
第二类是序列标注和信息抽取类任务,也就是从文本里找出实体、关键词、字段和关系,比如识别公司名、地点名、金额、合同期限。
第三类是匹配和检索类任务,比如搜索排序、问答匹配、相似问题识别、FAQ 召回。
第四类是生成类任务,比如文本摘要、机器翻译、改写、纠错、写作辅助。
第五类是问答与对话类任务,也就是让模型结合上下文或知识给出答案,并持续进行多轮交互。
2.2 面试官为什么喜欢问"常见任务"
因为这个问题最能看出一个人有没有全局观。只会说"分类、分词、摘要"说明只背了几个术语;如果能进一步讲清每类任务的输入、输出和场景,面试官通常会觉得你对 NLP 的理解是成体系的。
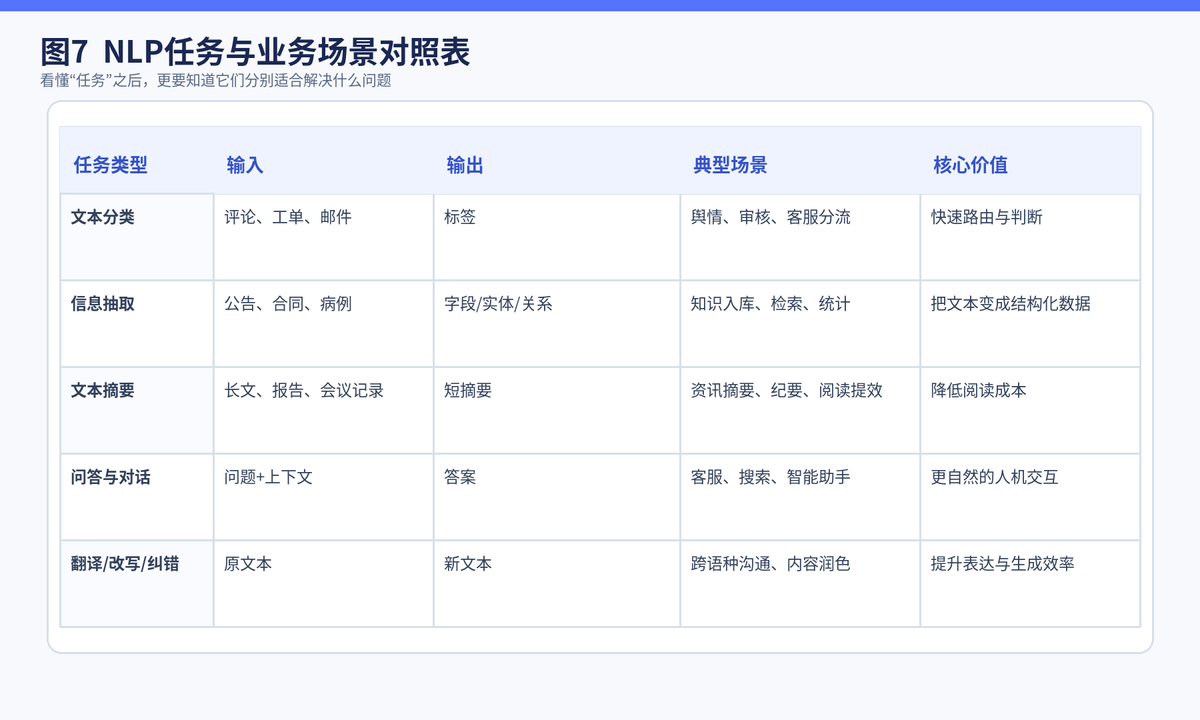
|----------|----------|----------|--------------------|
| 任务类型 | 输入 | 输出 | 典型场景 |
| 文本分类 | 一句或一段文本 | 一个或多个标签 | 垃圾邮件识别、评论情感分析、工单归类 |
| 信息抽取 | 原始长文本 | 实体、字段、关系 | 合同解析、公告抽取、知识入库 |
| 文本摘要 | 较长文本 | 更短的摘要 | 新闻摘要、会议纪要、长文压缩 |
| 问答与对话 | 问题 + 上下文 | 答案或多轮回复 | 客服机器人、知识库问答、智能助手 |
| 翻译/改写/纠错 | 原始文本 | 新文本 | 多语种内容、润色、语法修正 |
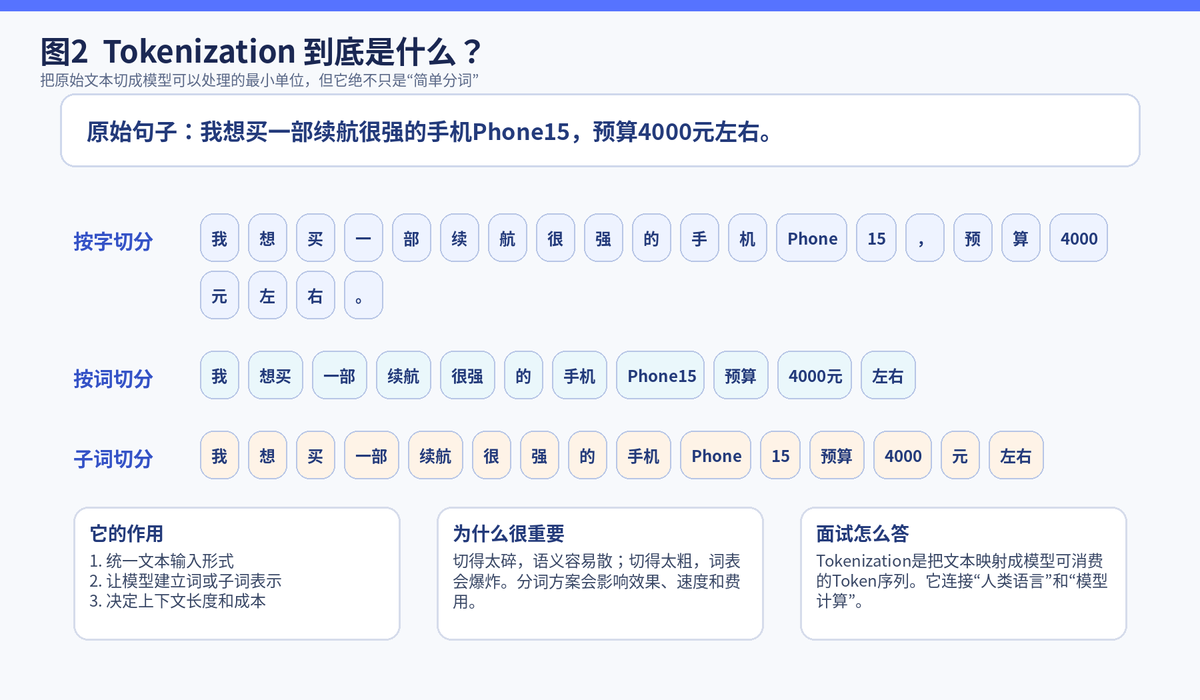
3. Tokenization 是什么?它有什么用?
3.1 Tokenization 不是简单分词
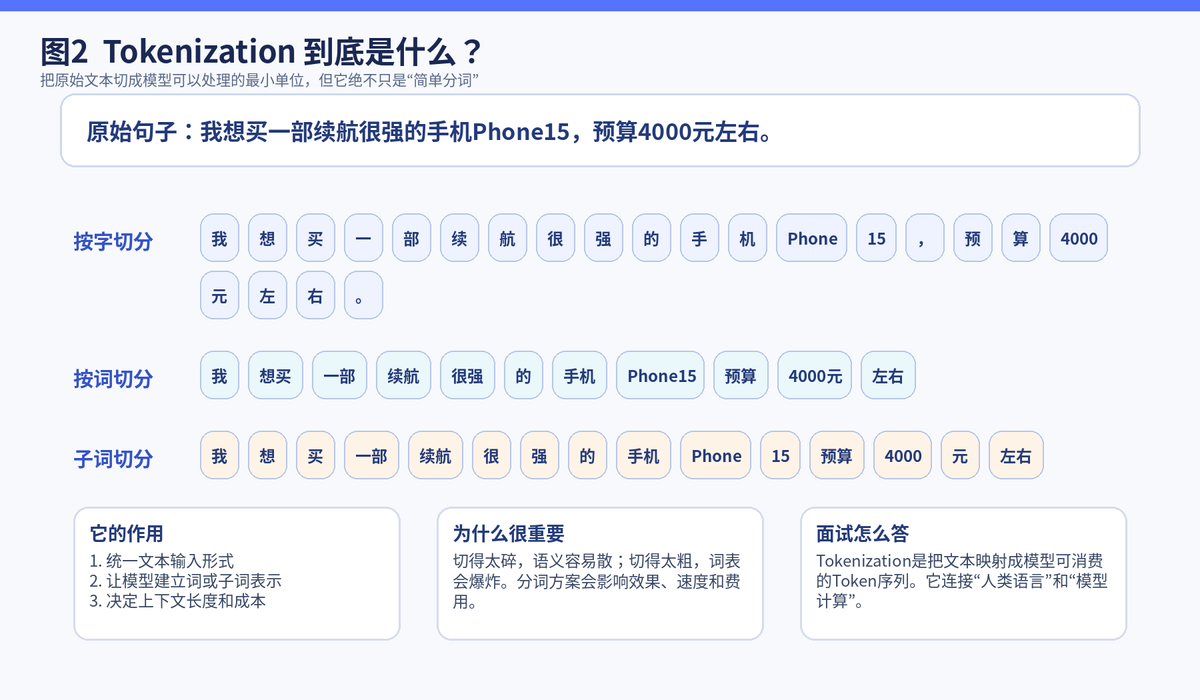
Tokenization 可以翻译成"切词"或"切分",但它和日常理解的"中文分词"并不完全一样。它的本质,是把一整段原始文本拆成模型可以处理的最小单位,也就是 Token。
对于传统 NLP 来说,这一步可能是按词切分;对于深度学习和大模型来说,这一步更可能是按子词切分,甚至会把一个英文单词拆成几个片段。目的不是为了好看,而是为了让模型既能处理常见词,也能处理生僻词和新词。
3.2 Token 为什么这么重要
因为模型不直接理解文字,它先看到的是一串 Token。文本进入模型前,要先被切成 Token,再映射成数字 ID,再变成向量表示,后面模型才能进行编码、注意力计算和生成。
所以 Tokenization 实际上是 NLP 流程里的第一道门。切分策略不合理,后面所有模型效果都会受到影响。
3.3 中文场景下为什么更值得关注
英文天然有空格,单词边界比较明显;中文没有天然空格,'研究生命起源'到底该切成'研究/生命/起源'还是'研究生/命/起源',不同切法意思可能完全不同。
这也是为什么中文 NLP 里,分词、子词和上下文理解往往会绑得更紧。很多时候不是切出来就结束了,而是切出来之后还要借助上下文进一步 disambiguation,也就是消歧。
|-----------------------------------------------------------------------------------------------------------------|
| 面试答法 Tokenization 是把原始文本转成模型可消费 Token 序列的过程,它连接"自然语言输入"和"模型计算"。传统 NLP 更强调按词切分,大模型更常用子词切分,因为这样可以兼顾词表大小和泛化能力。 |
4. 文本分类有哪些应用场景?
4.1 文本分类到底在分什么
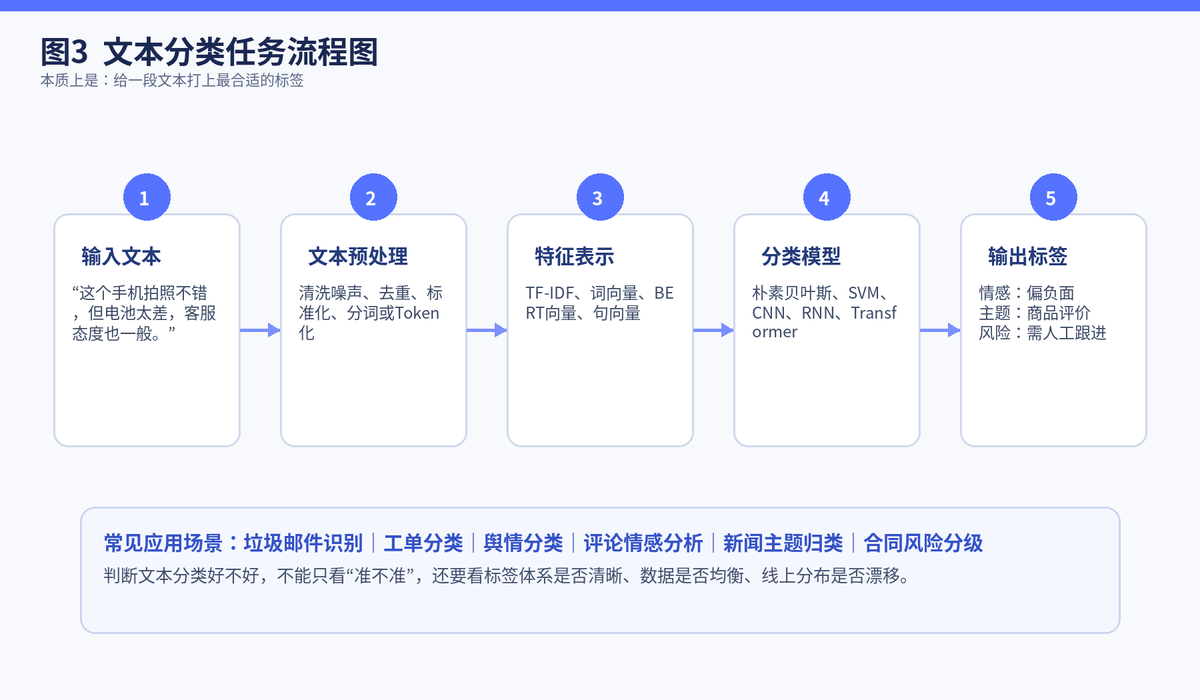
文本分类的本质,就是判断一段文本属于哪个类别。听起来很简单,但它是整个 NLP 里最实用、最常落地的一类任务。因为业务里大量问题,本质上都可以抽象成"给文本打标签"。
比如一条评论是正面还是负面,一封邮件是不是垃圾邮件,一条工单应该分给哪个部门,一篇文章属于财经还是体育,这些都属于文本分类。
4.2 文本分类的典型应用场景
在电商里,它常用来识别评论情感、分类售后问题、发现风险内容;在客服里,它可以对用户问题做意图识别和自动分流;在内容平台里,它可以做主题归类、推荐冷启动、违规内容识别;在企业办公里,它可以做邮件归档、公告归类和文档标签化。
4.3 为什么说文本分类是"业务接入最容易"的 NLP 任务
因为它的输入和输出都很清晰。输入就是文本,输出就是标签。只要标签体系定义得足够明确,样本量足够,往往很快就能做出一个可上线的版本。
但真正的难点不在模型,而在标签设计。标签过粗,价值不大;标签过细,样本不够;标签定义模糊,模型和人工都会容易混淆。
|--------|-------------------|-------------|-----------------|
| 场景 | 输入文本示例 | 输出标签 | 业务价值 |
| 评论分析 | "发货快,但包装破损。" | 情感:负面;主题:物流 | 监控用户口碑,发现问题热点 |
| 工单分流 | "账号无法登录,验证码也收不到。" | 账号问题 | 自动转交对应团队,提高处理效率 |
| 垃圾信息识别 | "低息贷款,点击领取福利。" | 垃圾营销 | 降低骚扰与风控风险 |
| 新闻归类 | "央行公布最新利率政策。" | 财经 | 提升推荐与搜索组织效率 |
5. 信息抽取为什么是企业场景中的高价值任务?
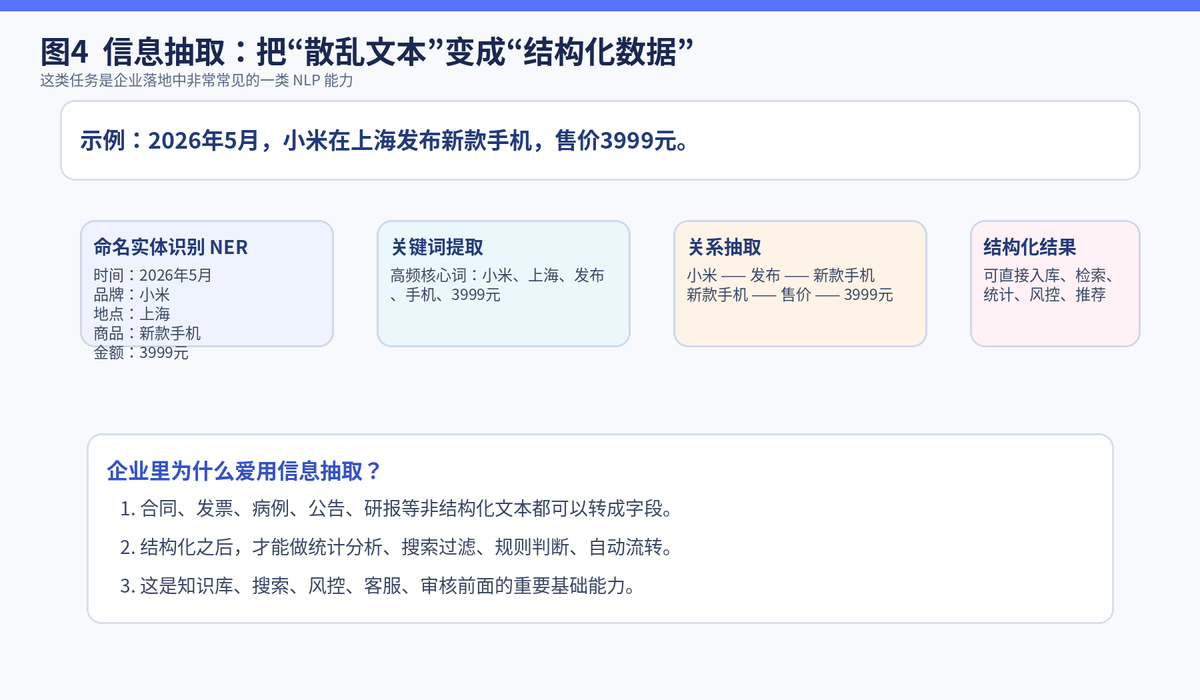
5.1 什么叫信息抽取
信息抽取的目标,是把原本散落在自然语言里的关键信息提出来,变成结构化结果。它通常包括命名实体识别、关键词提取、关系抽取、字段抽取等能力。
例如从'2026年5月,小米在上海发布新款手机,售价3999元'这句话里,可以抽出时间、品牌、地点、产品和价格。这些字段一旦抽出来,就能直接入库、过滤、统计、检索。
5.2 为什么很多系统离不开抽取
因为文本天然不利于计算。人能读懂公告、合同、病例、简历,但系统要做统计分析、流程流转、检索过滤时,更需要结构化字段。抽取本质上就是把语言变成可计算的数据。
知识库建设、RAG 前处理、合同审核、简历解析、舆情监测、风控策略,这些场景的前面,往往都有一层抽取逻辑。
6. 文本摘要有哪些应用场景?
6.1 摘要不是"把文章变短"这么简单
文本摘要看起来像压缩,其实本质上是在保留核心信息的前提下,降低阅读成本。真正好的摘要,不是简单删句子,而是用更短的篇幅保留最重要的意思。
从产品视角看,摘要最适合解决"信息太长、用户没空看完"的问题。
6.2 文本摘要的典型场景
新闻资讯场景里,用户希望一分钟抓住要点;会议纪要场景里,团队希望快速回顾讨论结论和待办事项;客服质检场景里,希望把长会话压缩成事件摘要;知识库和办公场景里,希望先给用户一段简介,再决定要不要阅读全文。
在大模型时代,摘要的重要性进一步上升。因为长文、长会话、长报告越来越多,而摘要恰好是连接"海量信息"和"有限时间"的桥梁。
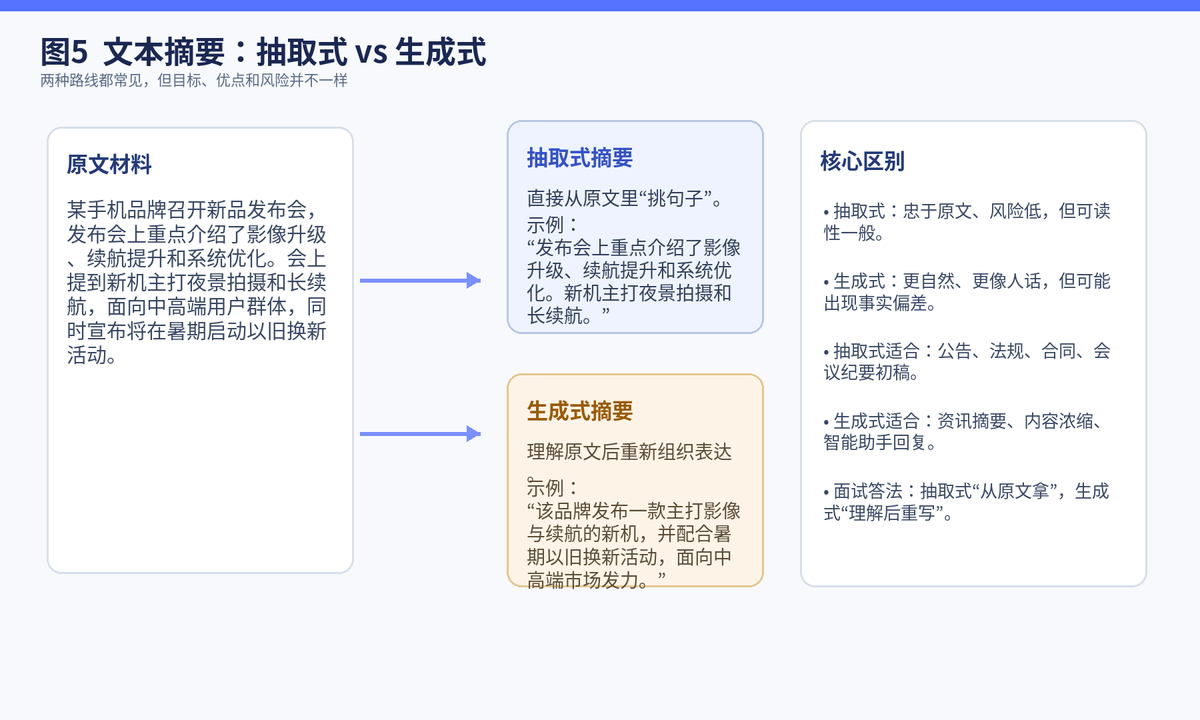
7. 抽取式摘要和生成式摘要分别存在哪些问题?
7.1 抽取式摘要的问题
抽取式摘要的优点是稳。它直接从原文中拿句子,忠于原文,不容易编造事实,适合公告、法规、合同、纪要初稿等对准确性要求高的内容。
但它的问题也很明显。第一,容易啰嗦,因为原文中的句子未必天然适合当摘要;第二,句子之间可能不连贯,读起来像拼接;第三,无法主动改写和归纳,所以在表达自然度上通常不如生成式。
7.2 生成式摘要的问题
生成式摘要的优点是更像人写的。它可以理解原文后重新组织语言,生成更自然、更顺畅的总结。
但生成式也更危险。最典型的问题就是事实漂移和幻觉:原文没说过的话,模型可能会"补"出来;原文说得很细,模型也可能理解偏了,导致重点跑偏、数字出错、结论失真。
7.3 面试时怎么比较这两类方法
最稳的说法是:抽取式摘要更像"从原文摘句子",准确但不够灵活;生成式摘要更像"理解后重写",表达自然但风险更高。前者偏保守,后者偏智能。
|----------|-----------------|----------------|
| 对比维度 | 抽取式摘要 | 生成式摘要 |
| 信息来源 | 直接来自原文 | 基于原文理解后重写 |
| 优点 | 忠于原文,事实风险低 | 表达自然,可压缩能力更强 |
| 问题 | 拼接感强,连贯性一般,可能啰嗦 | 可能幻觉、遗漏、数字偏差 |
| 适合场景 | 法规、公告、合同、纪要初稿 | 资讯摘要、智能助手、阅读提效 |
8. 除了分类和摘要,面试里还常被问到哪些 NLP 任务?
8.1 情感分析
情感分析本质上也是文本分类,只不过标签通常是正面、负面、中性,或者更细的情绪类型。它常用于评论分析、用户反馈、舆情监测。
8.2 命名实体识别(NER)
NER 的目标是从文本里找出人名、地名、机构名、金额、时间等实体。它是抽取类任务里的基础能力,也是知识图谱、知识库建设、文档解析的重要前置步骤。
8.3 机器翻译
机器翻译是把一种语言转成另一种语言。它看似成熟,但真实业务里仍然很考验领域术语、上下文一致性、语气保持和专有名词翻译。
8.4 问答与对话
问答任务关注的是"给定问题,如何返回答案";对话任务则更进一步,要求模型记住上下文、理解用户连续意图、保持角色和风格一致。今天很多知识库助手、客服机器人、办公助手,都是问答与对话任务的产品化形态。
8.5 改写、纠错与生成
改写关注的是不改变原意的情况下换一种说法;纠错关注的是语法、错别字、表达问题;生成则包括写标题、写摘要、写邮件、写回复。这些任务在大模型时代几乎被合并成了一类"生成增强能力"。
9. 一个 NLP 任务通常是怎么落地成产品的?
很多人面试时一聊 NLP 就只说模型,实际上企业最关心的,是你能不能把任务做成稳定可用的系统。真正的落地流程,通常包括业务定义、数据收集、清洗标注、建模训练、评估验证、部署上线和持续优化。
先有业务,后有模型。业务问题没定义清楚,哪怕模型再先进,最后也很难交付。比如你说要做"智能摘要",那到底是做公告摘要、会议纪要、会话摘要还是长文压缩?摘要长度怎么定?哪些信息必须保留?这些都属于任务定义。
接下来才是数据和建模。数据质量决定上限,模型决定起点,持续优化决定最终效果。线上问题回流、错误样本分析、标签修正、Prompt 调整、模型替换,往往比第一次建模更重要。

|------------------------------------------------------------------------------------------------------|
| 落地视角的高分表达 面试里讲 NLP,不要只说"用了什么模型",而要补上"这个任务为什么成立、输入输出是什么、数据怎么来、效果怎么评估、上线后怎么迭代"。这会让回答一下子从概念层升级到项目层。 |
10. 面试官最爱追问的 6 个问题,应该怎么答?
10.1 NLP 和大模型是什么关系?
可以说:大模型不是脱离 NLP 的新东西,而是 NLP 能力的一次大升级。以前很多任务要单独建模,现在一个大模型就能覆盖分类、摘要、问答、改写、抽取等多类任务。
10.2 Tokenization 为什么关键?
可以说:它是文本进入模型前的第一道处理步骤,决定了模型如何看待文本,也会影响成本、长度和效果。
10.3 文本分类和信息抽取有什么区别?
可以说:分类是给整段文本打标签,抽取是从文本里找字段和关系。一个偏整体判断,一个偏细粒度提取。
10.4 抽取式摘要和生成式摘要怎么选?
可以说:如果准确性优先,先选抽取式;如果可读性和压缩能力优先,再考虑生成式。真实业务里也常把两者结合起来。
10.5 如何判断一个 NLP 任务做得好不好?
可以说:不仅要看离线指标,还要看线上价值。分类不能只看准确率,还要看误杀和漏判;摘要不能只看像不像,还要看事实是否稳定;问答不能只看回答流畅,还要看是否可靠。
10.6 回答"常见任务"时,怎样显得更专业?
不要只背名词。最好的方式是"任务名称 + 输入输出 + 应用场景 + 核心难点"一起讲。只要这样回答,面试官通常会觉得你不是背题,而是真的理解。
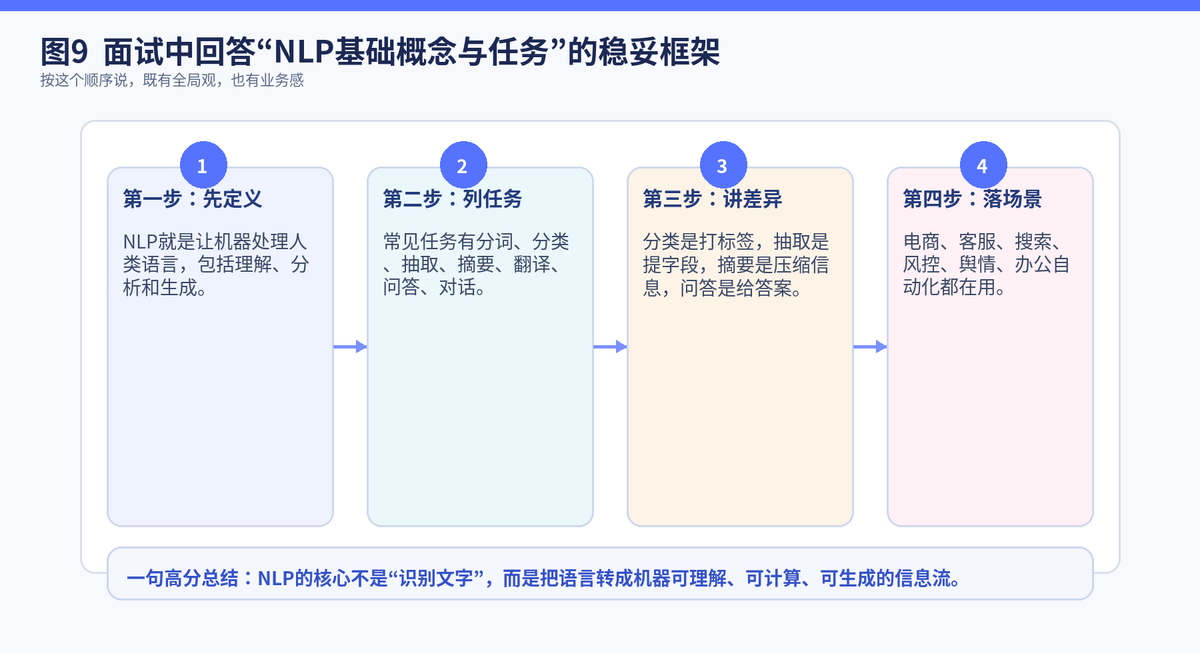
11. 一段可以直接复用的面试回答模板
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 参考回答 NLP,也就是自然语言处理,本质上是让机器理解、分析和生成人类语言的技术体系。常见任务包括 Tokenization、文本分类、信息抽取、文本摘要、机器翻译、问答与对话等。分类是给文本打标签,抽取是从文本里提字段,摘要是把长文本压缩成更短的核心信息,问答则是根据问题和上下文返回答案。实际业务里,电商、客服、搜索、知识库、风控和办公自动化都大量使用 NLP。到了大模型时代,很多原本分散的 NLP 任务开始被统一到一个更强的模型能力框架里。 |
12. 总结:学 NLP,真正要抓住的不是名词,而是任务本质
回头看一遍就会发现,NLP 的学习主线其实很清楚:先理解它是什么,再理解它解决哪些问题,然后再理解每类任务的输入、输出、场景和难点。
真正拉开差距的,不是你能背出多少术语,而是你能不能把"任务本质"说透。面试官并不怕你不用很高深的数学公式,反而更在意你是不是能把复杂问题讲成简单清楚的话。
只要你把这篇文章里的几个核心点记住------NLP 是理解与生成的结合,Tokenization 是入口,分类是打标签,抽取是结构化,摘要是信息压缩,问答是语言交互------那么"基础概念与任务"这一题,基本就能答得既完整又稳。
附录:一眼看懂全文脉络