近端策略优化算法(Proximal Policy Optimization,简称 PPO )是目前深度强化学习(DRL)领域最主流、应用最广泛的算法之一。它由 OpenAI 在 2017 年提出,也是目前大语言模型和多模态大模型(VLM/VLA)在 RLHF(基于人类反馈的强化学习) 阶段的核心算法。
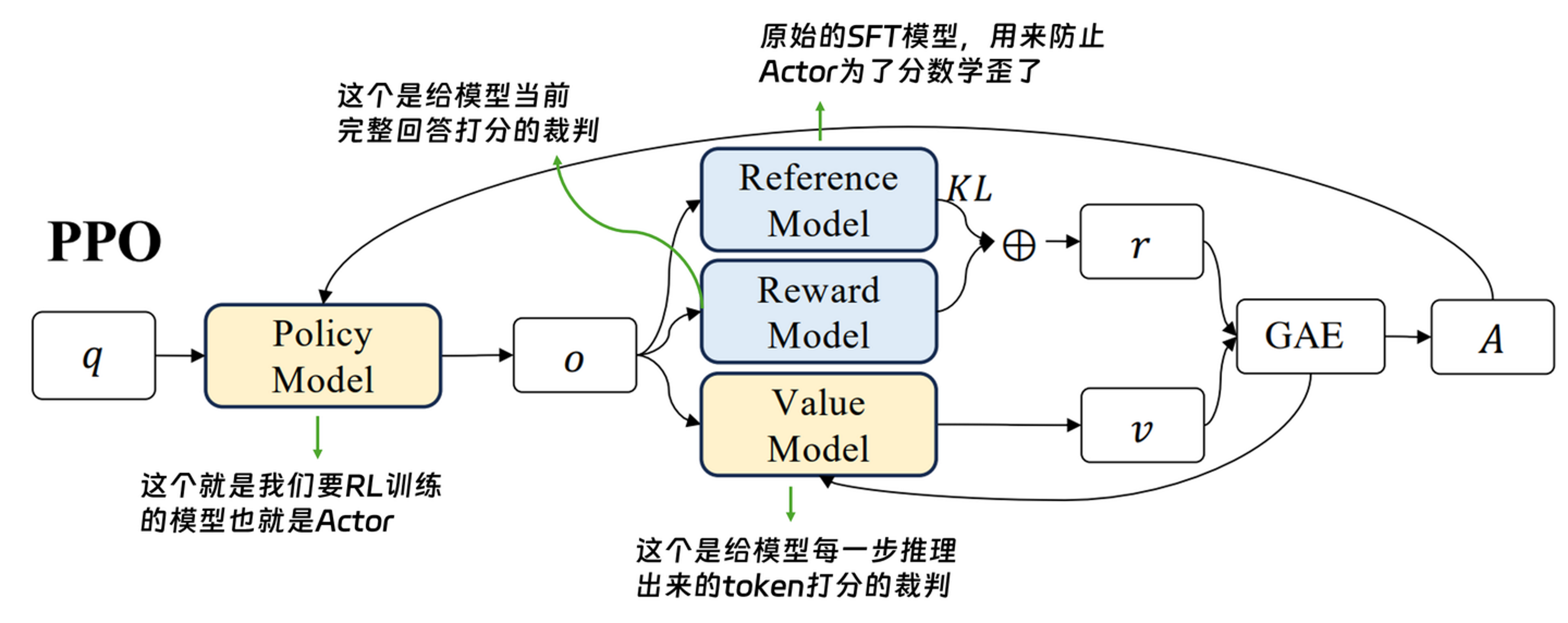
I. Actor (需更新参数):
角色:主角。这就是我们正在训练、希望它变符合我们预期的那个模型。
任务:负责根据问题生成回答。
II. Reference Model 参考模型 (冻结参数):
角色:SFT 后的原始模型副本。
任务:它不参与打分,而是作为约束。它时刻提醒 Actor:"你别为了拿高分就乱说话,要保持原本的语言能力,不要偏离太远(计算 KL 散度)。"
III. Reward Model 奖励模型 (冻结参数):
一般用什么:通常直接拿 SFT 训练好的模型(比如 Llama-3-8B-Instruct 或 Qwen3-14B-Instruct)来改。
角色:代表人类偏好的判卷人。
任务:它是个哑巴,平时不说话,只有等 Actor 把整句话写完了,它才给出一个最终分数(比如 8.0 分)。
IV. Critic 评判模型 (更新参数):
一般用什么:和 Reward Model 一样,通常也是由 Actor 同款的 Transformer 改出来的(比如 Actor 是 7B,Critic 通常也是 7B)。
维度的大不同:Critic 的独特之处在于它输出的形状,它的最终输出是Batch_Size, Seq_Len, 1,也就是 Actor 的每一个token都会有一个当下分。
一、 PPO 的设计思路
要理解 PPO 的设计思路,我们需要知道它主要是为了解决之前算法的什么痛点:
- 传统 Policy Gradient (策略梯度) 的痛点:对步长(学习率)极其敏感。步长太小,收敛极慢;步长太大,新策略可能会彻底崩溃,导致模型"学废了",且很难恢复。
- TRPO (信赖域策略优化) 的痛点:为了解决上述问题,TRPO 引入了 KL 散度来限制新旧策略的差异,确保每次更新都在一个安全的"信赖域"内。但 TRPO 需要计算复杂的二阶导数(海森矩阵),计算量极大,且代码实现极难,工程极不友好。
PPO 的核心设计思路:
"用一阶优化的简单计算,达到二阶优化(TRPO)的稳定效果。"
PPO 放弃了复杂的 KL 散度硬约束,巧妙地设计了一个截断(Clip)机制 。它的核心逻辑是:如果一个动作带来了正收益(优势大于 0),我们就增加它的出现概率,但不能增加得太离谱 ;如果带来了负收益,我们就减少它的概率,同样不能减少得太夸张。通过这种方式,保证新旧策略的更新平滑稳定。
二、 PPO 分成几个部分?
PPO 通常采用 Actor-Critic(演员-评论家) 架构,主要由以下几个核心部分组成:
- Actor (策略网络 πθ\pi_\thetaπθ):负责"表演"或"行动"。它接收当前环境的状态,输出执行各个动作的概率。在参数更新时,它的目标是最大化预期的累积奖励。
- Critic (价值网络 VϕV_\phiVϕ):负责"打分"。它评估当前状态到底有多好,预测从当前状态开始到结束能拿到的总回报。
- Advantage Estimator (优势函数估计 GAE):连接 Actor 和 Critic 的桥梁。它利用 Critic 的评分来计算"当前动作比平均水平好多少"(即优势),从而指导 Actor 的更新。
- Memory (经验回放池):由于 PPO 是同策略(On-Policy)算法,它会用当前的 Actor 去环境中采样一批数据(状态、动作、奖励等),存下来用于本次网络更新。更新完毕后,这批数据就会被丢弃。
三、 PPO 的公式建模
PPO 的核心公式本质上是一个带有"防沉迷/防崩盘"机制的收益函数。它的目标是最大化以下内容:
LCLIP(θ)=E^tmin(rt(θ)A\^t, clip(rt(θ),1−ϵ,1+ϵ)A\^t)L^{CLIP}(\theta) = \hat{\mathbb{E}}_t \left \\min(r_t(\\theta)\\hat{A}_t, \\ \\text{clip}(r_t(\\theta), 1-\\epsilon, 1+\\epsilon)\\hat{A}_t) \\rightLCLIP(θ)=E^tmin(rt(θ)A\^t, clip(rt(θ),1−ϵ,1+ϵ)A\^t)
第一眼看过去括号套括号无从下手?别急,我们像拆解积木一样,把它大卸六块:
1. 首先是 rt(θ)r_t(\theta)rt(θ)(比率 Ratio):
rt(θ)=πθ(at∣st)πθold(at∣st)=新策略生成这个词的概率旧策略生成这个词的概率r_t(\theta) = \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} = \frac{\text{新策略生成这个词的概率}}{\text{旧策略生成这个词的概率}}rt(θ)=πθold(at∣st)πθ(at∣st)=旧策略生成这个词的概率新策略生成这个词的概率
- πθ\pi_{\theta}πθ:当前正在更新参数的 Actor 模型(新策略)。
- πθold\pi_{\theta_{\text{old}}}πθold:刚采样完数据、还没更新梯度的 Actor 模型(旧策略)。注意,这和 Reference Model 无关,它就是 Actor 自己上一秒的影子。
- 大白话作用 :用来衡量参数更新后,产生当前动作的概率变成了原来的多少倍。如果 r=1.5r = 1.5r=1.5,说明新模型选这个词的概率是之前的 1.5 倍。
2. 接着是 A^t\hat{A}_tA^t(优势 Advantage):
A^t=(Rscore−β⋅KL(π,πref)+γV(st+1))⏟现实(实际得到的收益):RM打分 - Ref约束罚分 + 未来潜力−V(st)⏟预期:Critic 之前的预判\hat{A}t = \underbrace{ \left( R{\text{score}} - \beta \cdot \text{KL}(\pi, \pi_{\text{ref}}) + \gamma V(s_{t+1}) \right) }{\text{现实(实际得到的收益):RM打分 - Ref约束罚分 + 未来潜力}} - \underbrace{ V(s_t) }{\text{预期:Critic 之前的预判}}A^t=现实(实际得到的收益):RM打分 - Ref约束罚分 + 未来潜力 (Rscore−β⋅KL(π,πref)+γV(st+1))−预期:Critic 之前的预判 V(st)
- 这就是 Critic 和 Reward Model (RM) 联手算出来的那个数。
- 正数(+):表示这步操作比预期的好(好动作),应该鼓励,梯度推着概率往上涨。
- 负数(-):表示这步操作比预期的差(坏动作),应该惩罚,梯度压着概率往下降。
用一句话来理解这个公式的核心逻辑:
优势(Advantage) = 冰冷的现实(Reality) - 你原本的预期(Expectation)
它衡量的是:"你刚才做的这个动作,有没有带来超越预期的惊喜?"
我们把它拆成四块来对应:
1. 预期:V(st)V(s_t)V(st) (Critic 之前的预判)
想象你正在打一场游戏,目前处于状态 sts_tst(比如满血、有大招)。
这时候,你的"军师(Critic 模型)"看了一眼局势,对你说:"主公,根据目前的大好形势,我预估咱们这把最后能拿 80 分。 "
这就是 V(st)V(s_t)V(st),是你行动前的心理预期。
2. 现实之 1:RscoreR_{\text{score}}Rscore (RM打分)
现在,你大喊一声冲了上去,放了一个技能(这就是你采取的动作 ata_tat)。
系统(Reward Model)根据你这个技能打了一个即时分数:"斩杀一个小兵,真实得分 +5 分。"
3. 现实之 2:−β⋅KL(π,πref)-\beta \cdot \text{KL}(\pi, \pi_{\text{ref}})−β⋅KL(π,πref) (Ref约束罚分)
但是,大模型在生成文字时,不能为了拿高分就不择手段(比如只输出无意义的符号来骗分)。
Reference Model 就是考场纪律委员:"虽然你拿了分,但是你刚才那招动作太猥琐(语言极其不自然,偏离了正常人类说话的概率分布),我要扣你 2 分!"
4. 现实之 3:γV(st+1)\gamma V(s_{t+1})γV(st+1) (未来潜力)
你放完技能后,来到了一个新的局面 st+1s_{t+1}st+1。
军师(Critic)又跑出来看了一眼新局势:"主公,虽然刚才发生了一些事,但由于走位风骚,我们现在的新局势预估能拿 82 分! "
(公式里的 γ\gammaγ 是个折扣系数,通常是 0.99,意思是未来的分数稍微打点折扣,为了方便理解,我们假设它就是 1)
把它们拼起来算总账!
现在,我们来看看你刚才放的那个技能,到底是不是一个"好动作"?
第一步:结算"现实总收益"
- 实际拿到的分(5分) - 犯规扣分(2分) + 剩下的局势潜力(82分) = 85 分。
- 这就是公式左边那个长长的括号:现实情况最终值 85 分。
第二步:计算"优势(Advantage)"
- 现实你最终有了 85 分的底子。
- 但是你本来预期 就能拿 80 分(V(st)V(s_t)V(st))。
- 所以,A^t\hat{A}_tA^t = 现实 (85) - 预期 (80) = +5 分。
结论:
因为 A^t=5>0\hat{A}_t = 5 > 0A^t=5>0,这是一个正优势 !这说明你刚才那一招,不仅没拖后腿,还创造了超出预期的"意外之喜"。算法会记住这个结论,然后在更新时,努力提高以后出这一招的概率。
反之,如果现实算下来只有 70 分,减去预期的 80 分,A^t=−10\hat{A}_t = -10A^t=−10。这就说明你刚才那一步走了一手臭棋(把一把好牌打烂了),算法就会严厉惩罚,降低以后出这招的概率。
为了让你更直观地感受这四个变量是如何相互拉扯、最终决定一个动作是"惊喜"还是"惊吓"的,我为你生成了一个交互式的"优势核算计算器"。你可以自己调整预期、实际得分和扣分,看看结论怎么变。
PPO 为什么要这么算?
直接用现实得分不行吗?不行。
因为一个好学生平时能考 90 分,今天考了 80 分,对他来说是退步 (坏动作,要反思);
一个差生平时考 30 分,今天考了 50 分,对他来说是巨大进步 (好动作,要鼓励)。
减去 V(st)V(s_t)V(st)(预期基线),就是为了让模型明白:不在乎绝对分数高低,只在乎你这步操作有没有带来进步。
3. ϵ\epsilonϵ(限制范围 Epsilon):
- 通常固定设为 0.2。意思是:我最多只允许你一次性变动 20%。
4. clip 函数(强制截断):
clip(rt(θ),1−ϵ,1+ϵ)\text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)clip(rt(θ),1−ϵ,1+ϵ)
- 核心作用 :它将新旧策略的概率比率 rrr 强行锁在 0.8,1.20.8, 1.20.8,1.2 这个区间内。这意味着我们只允许模型在旧策略的基础上进行小步微调,防止模型因为一次性更新幅度过大(步子迈太大)导致训练崩溃(扯着蛋)。
- 代码解释:
python
# 在实际 PyTorch 代码中,通常直接用一句话搞定:
r_clipped = torch.clamp(r, min=0.8, max=1.2)5. min 函数(最精妙的悲观锁):
min(原始收益,截断收益)\min(\text{原始收益}, \text{截断收益})min(原始收益,截断收益)
第一项(无限制的原始收益) :rt(θ)A^tr_t(\theta)\hat{A}_trt(θ)A^t
第二项(被防沉迷系统卡住的收益) :clip(rt(θ),1−ϵ,1+ϵ)A^t\text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_tclip(rt(θ),1−ϵ,1+ϵ)A^t
为什么要用 min(第一项, 第二项) 取两者中较小的一个?因为 PPO 要建立一个"悲观界限(Pessimistic Bound)"。它的核心逻辑是:"当你朝着好的方向进化时,我限制你的速度;当你犯大错时,我毫不留情地惩罚你。"
为什么要用 min(第一项, 第二项) 取两者中较小的一个?
因为 PPO 要建立一个"悲观界限(Pessimistic Bound)"。它的核心逻辑是:"当你朝着好的方向进化时,我限制你的速度;当你犯大错时,我毫不留情地惩罚你。"
我们分 4 种极端情况(假设 ϵ=0.2\epsilon = 0.2ϵ=0.2),来看看这个 min 是如何显神威的:
场景 1:动作是个好动作(A=10A = 10A=10),模型非常聪明地提高了它的概率(r=1.5r = 1.5r=1.5)
- 第一项(原始) :1.5×10=151.5 \times 10 = 151.5×10=15 分
- 第二项(截断) :因为 r=1.5r=1.5r=1.5 超过了 1.21.21.2 的上限,被 clip 强行卡在 1.21.21.2。算出来是 1.2×10=121.2 \times 10 = 121.2×10=12 分。
min的选择 :min(15, 12)= 12 分。- 大白话解释 :你做对了,想疯狂奖励自己?不行,最多只给你 1.2 倍的奖励(截断生效),防止你骄傲自大(步子迈太大扯着蛋)。
场景 2:动作是个好动作(A=10A = 10A=10),模型却愚蠢地降低了它的概率(r=0.5r = 0.5r=0.5)
- 第一项(原始) :0.5×10=50.5 \times 10 = 50.5×10=5 分
- 第二项(截断) :r=0.5r=0.5r=0.5 跌破了 0.80.80.8 的下限,被卡在 0.80.80.8。算出来是 0.8×10=80.8 \times 10 = 80.8×10=8 分。
min的选择 :min(5, 8)= 5 分。- 大白话解释 :这么好的动作你居然不去做?
min故意挑了更低的分数给你(截断不生效)。只要你反向操作,惩罚上不封顶。
场景 3:动作是个烂动作(A=−10A = -10A=−10),模型知错能改,降低了它的概率(r=0.5r = 0.5r=0.5)
- 第一项(原始) :0.5×−10=−50.5 \times -10 = -50.5×−10=−5 分
- 第二项(截断) :r=0.5r=0.5r=0.5 被卡在 0.80.80.8。算出来是 0.8×−10=−80.8 \times -10 = -80.8×−10=−8 分。
min的选择 :min(-5, -8)= -8 分。- 大白话解释 :注意了!这里选了 -8 分!因为 -8 比 -5 更小!这意味着当你的惩罚已经降到 0.8 倍时,系统就不再给你额外收益了(截断生效)。防止模型因为害怕某一个错误,把相关的好知识也连带着忘光光。
场景 4:动作是个烂动作(A=−10A = -10A=−10),模型却头铁地提高了它的概率(r=1.5r = 1.5r=1.5)
- 第一项(原始) :1.5×−10=−151.5 \times -10 = -151.5×−10=−15 分
- 第二项(截断) :r=1.5r=1.5r=1.5 被卡在 1.21.21.2。算出来是 1.2×−10=−121.2 \times -10 = -121.2×−10=−12 分。
min的选择 :min(-15, -12)= -15 分。- 大白话解释 :明明是个烂动作,你还想多干?
min毫不犹豫地选择了 -15 分的严厉惩罚(截断不生效)。错误方向上的作死,严惩不贷。
6. 大写的 E^t\hat{\mathbb{E}}_tE^t(数学期望):
在一次更新中,模型不是只生成了一个词,而是生成了一大批数据(比如一个 Batch 有 1024 个 Token)。模型会对每一个 Token 都计算出一个 min(...) 的得分。
E^t\hat{\mathbb{E}}_tE^t 的作用:
把这 1024 个词的 min(...) 得分全部加起来,除以 1024,算出一个"平均得分"。这个平均得分,就是我们要让整个神经网络去努力最大化的最终目标(Loss 的反面)。
一句话总结 PPO 的逻辑:
它就像一个严厉但稳妥的老师。你做对了,它给你奖励,但奖励有上限 (最多 20%),防止你飘了;你做错了,它直接扣分,帮你纠正错误。通过这种 clamp + min 的数学技巧,完美解决了强化学习容易"走火入魔"的稳定性问题。
四、 面试常考问题与高分回答策略
在算法和工程面试中,关于 PPO 的提问通常围绕原理对比、公式细节以及在大模型落地中的痛点。
PPO 相比于 TRPO 优势在哪里?
- 回答要点 :TRPO 使用 KL 散度作为硬约束,在优化时需要计算 Fisher 信息矩阵(海森矩阵近似),并使用共轭梯度法,计算复杂度为 O(N2)O(N^2)O(N2)(NNN 为参数量)。这在深度学习时代尤其对于参数量巨大的模型是不可接受的。PPO 将 KL 散度约束替换为 Clip 操作,将二阶优化问题简化为一阶优化问题,可以直接用 Adam 等优化器求解,不仅极大地降低了计算开销,而且代码实现简单,稳定性反而更好。
详细解释一下 PPO 公式中的 Clip 机制是怎么起作用的?
- 回答要点 :需要分 A^t>0\hat{A}_t > 0A^t>0 和 A^t<0\hat{A}_t < 0A^t<0 两种情况向面试官解释。
- 当 A^t>0\hat{A}_t > 0A^t>0 时 (动作好,需要鼓励):我们希望 rt(θ)r_t(\theta)rt(θ) 变大。但因为 clip\text{clip}clip 的存在,当 rt(θ)r_t(\theta)rt(θ) 超过 1+ϵ1+\epsilon1+ϵ 时,目标函数值就不再增加,梯度变为 0。这就防止了策略网络过度自信,单步更新步子迈得太大。
- 当 A^t<0\hat{A}_t < 0A^t<0 时 (动作差,需要惩罚):我们希望 rt(θ)r_t(\theta)rt(θ) 变小。当 rt(θ)r_t(\theta)rt(θ) 减小到 1−ϵ1-\epsilon1−ϵ 以下时,目标函数值同样被截断截平,停止更新。防止好不容易学到的策略因为一次糟糕的探索被彻底破坏。
(结合大模型趋势)在 VLM/VLA 或大语言模型的 RLHF 阶段,PPO 是怎么应用的?在工程上有什么痛点?
- 回答要点:
- 应用:在 RLHF 中,PPO 用于将模型的输出与人类偏好对齐。此时 Actor 网络就是被训练的大模型(生成文本或决策动作),Critic 网络预测当前回答的累积奖励,Reward Model 提供单步环境奖励,还有一个 Reference Model(冻结的初始模型)用于计算 KL 惩罚,防止模型输出为了迎合高分而变得不说人话(过度优化)。
- 痛点 :显存压力极大。在训练时,GPU 中需要同时存放 4 个大模型(Actor、Critic、Reward Model、Reference Model),对工程架构要求极高(需要深度的 DeepSpeed / Megatron 并行优化)。为了缓解显存压力,工业界现在也会探索 DPO(Direct Preference Optimization)等无需 RL 也能对齐的算法作为平替,但 PPO 的上限和探索能力依然更强。
PPO 解决了什么问题?为什么不用 Policy Gradient 或 TRPO?
普通策略梯度(REINFORCE)步长极难控制,过大策略崩溃,过小收敛缓慢,且每批数据只能用一次,样本效率低。TRPO 虽然通过 KL 散度约束解决了稳定性问题,但需要计算 Fisher 信息矩阵和二阶导数,需要共轭梯度法进行约束优化,实现极为复杂,难以规模化应用。PPO 用截断概率比率替代了 KL 约束,转化为无约束优化,普通 Adam 就能求解,实现简单,允许多轮复用数据,效果与 TRPO 相当甚至更好。
PPO 和 TRPO 的核心区别是什么?
核心区别在于如何约束策略更新幅度。TRPO 使用硬约束:
maxθLCPI(θ)s.t.EtKL\[πθold(⋅∣st)∥πθ(⋅∣st)]≤δ \max_\theta L^{CPI}(\theta) \quad \text{s.t.} \quad \mathbb{E}_t\leftKL\\left\[\\pi_{\\theta_{old}}(\\cdot \\mid s_t) \\\| \\pi_\\theta(\\cdot \\mid s_t)\\right\right] \leq \delta θmaxLCPI(θ)s.t.EtKL\[πθold(⋅∣st)∥πθ(⋅∣st)]≤δ
这需要二阶优化(共轭梯度法 + 线搜索),计算 Fisher 信息矩阵,代码实现复杂。PPO 将约束"软化"进目标函数本身,通过截断或 KL Penalty 的方式,转化为无约束问题,用标准 SGD/Adam 即可求解,代码量减少数倍,且超参数更鲁棒。
GAE 中 λ\lambdaλ 参数的作用是什么?
λ\lambdaλ 控制偏差-方差权衡。λ=0\lambda=0λ=0 时 GAE 退化为单步 TD 残差 δt\delta_tδt,偏差较大(因为 VVV 本身存在估计误差),但方差小。λ=1\lambda=1λ=1 时 GAE 退化为完整 Monte Carlo 回报减去基线,理论上无偏,但方差极大,训练不稳定。实践中取 λ=0.95\lambda=0.95λ=0.95 左右,在低偏差和低方差之间找到较好的平衡点,是 PPO 能稳定训练的重要因素之一。
PPO 为什么可以对同一批数据进行多轮更新?有什么风险?
PPO 通过引入概率比率 rt(θ)r_t(\theta)rt(θ),用重要性采样校正了新旧策略之间的分布偏差,因此理论上可以对同一批数据进行多轮更新。风险在于:随着每轮更新,新旧策略差距会越来越大,重要性采样的方差增大,优势估计逐渐失效。Clip 机制正是用来限制这个漂移的,当 rt(θ)r_t(\theta)rt(θ) 超出 1−ϵ,1+ϵ1-\\epsilon, 1+\\epsilon1−ϵ,1+ϵ,梯度会被截断,阻止策略跑得太远。实践中需要合理设置 epoch 数(通常 3~10),并在训练时监控新旧策略的 KL 散度是否过大,如果 KL 散度显著超过 ϵ\epsilonϵ 可以提前终止 epoch。
PPO 在 RLHF 中是如何应用的?
在 RLHF(基于人类反馈的强化学习,如 InstructGPT、ChatGPT)中,PPO 被用于使语言模型的输出符合人类偏好。流程上先训练奖励模型(Reward Model)对语言模型的回答打分,然后以语言模型为 Actor,用 PPO 最大化奖励分数。为防止语言模型过度优化奖励模型(reward hacking)并偏离原始 SFT 模型,会加入 KL 散度惩罚:
rtotal(s,a)=rϕ(s,a)−β⋅KLπθ(⋅∣s)∥πref(⋅∣s) r_{total}(s, a) = r_\phi(s, a) - \beta \cdot KL\left\\pi_\\theta(\\cdot \\mid s) \\\| \\pi_{ref}(\\cdot \\mid s)\\right rtotal(s,a)=rϕ(s,a)−β⋅KLπθ(⋅∣s)∥πref(⋅∣s)
- rϕ(s,a)r_\phi(s, a)rϕ(s,a):奖励模型对当前回答的打分
- πref\pi_{ref}πref:SFT 阶段得到的参考模型(冻结参数)
- β\betaβ:KL 惩罚系数,控制语言模型偏离参考模型的程度
PPO 的优缺点和适用场景?
PPO 的优点是实现简单、超参数鲁棒(对 ϵ\epsilonϵ、λ\lambdaλ、学习率不敏感)、在连续控制(MuJoCo)、离散动作(Atari)和 RLHF 等场景均有出色表现,是目前工业界使用最广泛的策略优化算法之一。主要局限在于:本质上仍是 on-policy 算法,样本效率不如 SAC、TD3 等 off-policy 方法;在奖励极稀疏的场景效果有限;超参数组合较多(ϵ\epsilonϵ、λ\lambdaλ、c1c_1c1、c2c_2c2、epoch 数),需要一定调参经验。对于需要大量与真实环境交互的场景,可以考虑结合 off-policy 方法或使用模型预测来提高样本效率。