文章目录
- [1. 概述](#1. 概述)
- [2. 运行流程](#2. 运行流程)
-
- [2.1 图定义](#2.1 图定义)
- [2.2 图编译](#2.2 图编译)
-
- [2.2.1 编译配置](#2.2.1 编译配置)
- [2.2.2 编译过程](#2.2.2 编译过程)
- [2.3 触发执行](#2.3 触发执行)
-
- [2.3.1 初始化状态](#2.3.1 初始化状态)
- [2.3.2 创建 Flux 响应式流](#2.3.2 创建 Flux 响应式流)
- [2.3.3 初始化图执行上下文](#2.3.3 初始化图执行上下文)
- [2.4 节点执行](#2.4 节点执行)
-
- [2.4.1 START](#2.4.1 START)
- [2.4.2 进入节点执行器](#2.4.2 进入节点执行器)
- [2.4.3 获取节点执行动作](#2.4.3 获取节点执行动作)
- [2.4.4 执行节点动作](#2.4.4 执行节点动作)
- [2.5 处理节点执行结果](#2.5 处理节点执行结果)
-
- [2.5.1 状态更新](#2.5.1 状态更新)
- [2.5.2 计算下一个节点](#2.5.2 计算下一个节点)
- [2.5.3 构建执行结果并保存检查点](#2.5.3 构建执行结果并保存检查点)
- [2.5.4 递归](#2.5.4 递归)
- [2.6 END](#2.6 END)
-
- [2.6.1 构建 NodeOutput](#2.6.1 构建 NodeOutput)
- [2.6.2 最终完成处理](#2.6.2 最终完成处理)
1. 概述
Spring AI Alibaba Graph 是一套 AI 工作流编排引擎,在之前我们已经介绍过很多基础概念:
State全局状态:整个图的唯一上下文容器 ,贯穿所有节点,本质是带字段合并策略 的线程安全MapNode执行节点: 最小执行单元,本质是输入 State → 执行业务逻辑 → 输出新 State 的异步函数Edge流转边: 控制节点怎么走,主要分三类: 固定边、条件边、循环边Graph状态图:定义期 ,只是DSL组装节点、边、起始/终止点CompiledGraph编译图:运行期,编译校验图合法性、构建调度拓扑、初始化执行器,真正可被调用执行
Graph 整体运行全流程分为五大阶段:
- 图定义(
Build阶段) - 图编译(
Compile阶段) - 传入初始状态触发执行(
Invoke/Stream) - 节点执行 + 状态更新(核心运行逻辑)
- 递归执行,直到
END
2. 运行流程
2.1 图定义
开发者通过链式 API 构建 StateGraph ,此时只是静态元数据,还不能运行。
核心步骤:
- 定义全局
State和每个字段的合并策略 - 注册所有
Node(LLM/检索/自定义) - 配置
Edge流转规则、分支、循环 - 指定
START入口、END终止节点
之前构建邮件处理工作流中的代码中, 定义节点动作:
java
/**
* 读取邮件节点
*/
public class ReadEmailNode implements NodeAction {
private static final Logger log = LoggerFactory.getLogger(ReadEmailNode.class);
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
String emailContent = state.value("email_content")
.map(v -> (String) v)
.orElseGet(() -> state.value("input")
.map(v -> (String) v)
.orElseGet(() -> state.value("content")
.map(v -> (String) v)
.orElse("")));
log.info("Processing email: {}", emailContent);
List<String> messages = new ArrayList<>();
messages.add("Processing email: " + emailContent);
return Map.of(
"messages", messages,
"email_content", emailContent
);
}
}转换为异步节点:
java
var readEmail = node_async(new ReadEmailNode());
java
/**
* Creates an asynchronous node action from a synchronous node action.
* @param syncAction the synchronous node action
* @return an asynchronous node action
*/
static AsyncNodeAction node_async(NodeAction syncAction) {
return state -> {
Context context = Context.current();
CompletableFuture<Map<String, Object>> result = new CompletableFuture<>();
try {
result.complete(syncAction.apply(state));
}
catch (Exception e) {
result.completeExceptionally(e);
}
return result;
};
}初始化状态图:
java
StateGraph workflow = new StateGraph();添加节点:
java
workflow.addNode("read_email", readEmail)添加边:
java
workflow.addEdge(START, "read_email");构建完成后的状态图对象实例:
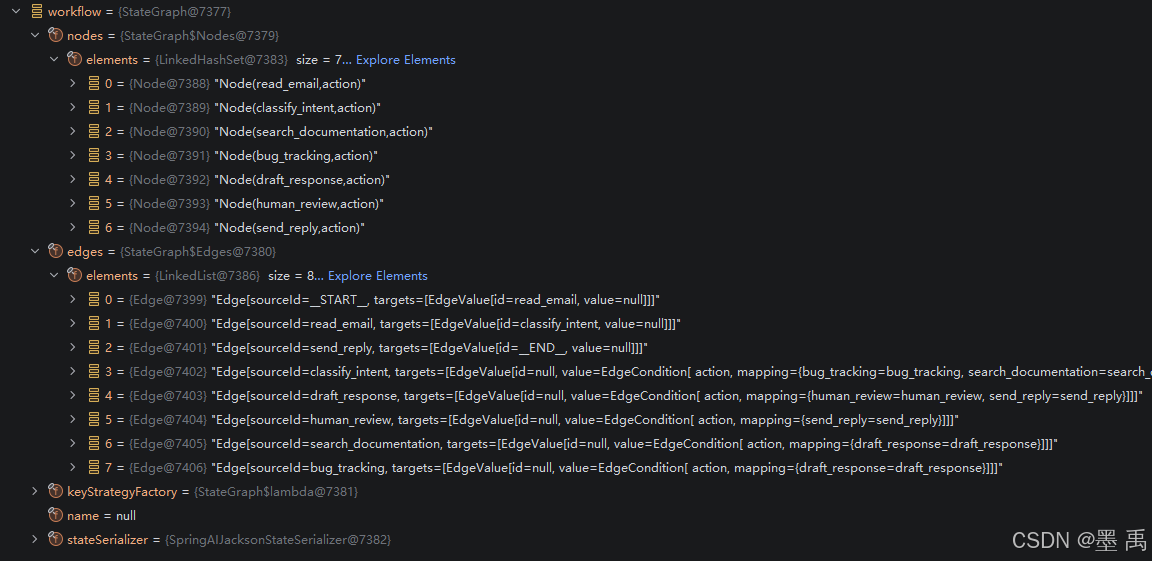
2.2 图编译
2.2.1 编译配置
编译之前可以自定义编译配置,检查点保存器:
java
SaverConfig saverConfig = SaverConfig.builder()
.register(new MemorySaver())
.build();
java
CompileConfig compileConfig = CompileConfig.builder()
.saverConfig(saverConfig)
.build();长期记忆存储:
java
CompileConfig compileConfig = CompileConfig.builder()
.saverConfig(saverConfig)
.store(new MemoryStore())
.build();2.2.2 编译过程
调用 graph.compile() 触发引擎内部处理:
- 拓扑校验:检查是否有孤岛节点、循环非法、死链
- 构建内部路由表:记录「当前节点 → 下一节点映射关系」
- 初始化异步调度器、状态管理器、异常捕获器
- 生成 CompiledGraph 可执行实例
编译只做一次,后续可重复执行多次流程。
编译方法入口:
java
import java.util.Objects;
/**
* 使用指定的配置将状态图编译为编译后的图
* @param config 编译配置对象,不能为空
* @return 编译完成后的图对象
* @throws GraphStateException 当存在与图状态相关的错误时抛出该异常
*/
public CompiledGraph compile(CompileConfig config) throws GraphStateException {
// 校验配置参数非空,为null则抛出空指针异常
Objects.requireNonNull(config, "config cannot be null");
// 校验当前状态图的合法性
validateGraph();
// 基于当前状态图和配置,创建并返回编译后的图实例
return new CompiledGraph(this, config);
}调用 CompiledGraph 构造函数完成状态图的编译、校验、节点/边处理、并行/条件节点封装:
java
/**
* 构造方法:使用指定的状态图和编译配置初始化编译后的图形对象
* @param stateGraph 原始状态图对象
* @param compileConfig 编译配置参数
* @throws GraphStateException 图状态异常(配置非法、节点不存在、边校验失败等)
*/
protected CompiledGraph(StateGraph stateGraph, CompileConfig compileConfig) throws GraphStateException {
// 1. 初始化基础配置:从编译配置中获取最大递归/迭代次数
this.maxIterations = compileConfig.recursionLimit();
// 赋值原始状态图引用
this.stateGraph = stateGraph;
// 2. 初始化键策略映射:从状态图的键策略工厂中获取策略,并转换为不可变Map
this.keyStrategyMap = stateGraph.getKeyStrategyFactory()
.apply()
.entrySet()
.stream()
.map(e -> Map.entry(e.getKey(), e.getValue()))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
// 3. 核心处理:解析状态图的节点、边和配置,生成预处理后的数据对象
this.processedData = ProcessedNodesEdgesAndConfig.process(stateGraph, compileConfig);
// 4. 合并子图定义的额外键和键策略(去重,不覆盖原有策略)
// 遍历子图处理后的键策略,仅添加当前Map中不存在的键值对
for (var entry : processedData.keyStrategyMap().entrySet()) {
if (!this.keyStrategyMap.containsKey(entry.getKey())) {
this.keyStrategyMap.put(entry.getKey(), entry.getValue());
}
}
// ====================== 合法性校验:中断节点校验 ======================
// 校验【执行前中断】的节点ID是否存在
for (String interruption : processedData.interruptsBefore()) {
if (!processedData.nodes().anyMatchById(interruption)) {
throw Errors.interruptionNodeNotExist.exception(interruption);
}
}
// 校验【执行后中断】的节点ID是否存在
for (String interruption : processedData.interruptsAfter()) {
if (!processedData.nodes().anyMatchById(interruption)) {
throw Errors.interruptionNodeNotExist.exception(interruption);
}
}
// ====================== 重新构建编译配置 ======================
// 使用处理后的中断节点,创建更新后的编译配置对象
this.compileConfig = CompileConfig.builder(compileConfig)
.interruptsBefore(processedData.interruptsBefore())
.interruptsAfter(processedData.interruptsAfter())
.build();
// ====================== 存储节点工厂(保证线程安全) ======================
// 线程安全设计:存储节点工厂而非实例,避免多线程下的实例共享问题
for (var n : processedData.nodes().elements) {
// 获取节点对应的动作工厂
var factory = n.actionFactory();
// 校验工厂不能为空,为空则抛出异常
Objects.requireNonNull(factory, String.format("节点ID '%s' 的动作工厂不能为空!", n.id()));
// 将节点ID与工厂映射存储
nodeFactories.put(n.id(), factory);
}
// ====================== 核心逻辑:解析并处理所有边 ======================
for (var e : processedData.edges().elements) {
// 获取当前边的所有目标节点
var targets = e.targets();
// -------------------- 分支1:单目标边(最常用场景) --------------------
if (targets.size() == 1) {
var target = targets.get(0);
// 判断是否为【条件边】(目标携带条件逻辑)
if (target.value() != null) {
var edgeCondition = target.value();
// 判断是否为【多命令动作】(会返回多个节点,需要并行执行)
if (edgeCondition.isMultiCommand()) {
// ====================== 处理:多命令条件并行节点 ======================
// 创建条件并行节点,封装并行执行逻辑
var conditionalParallelNode = new ConditionalParallelNode(
e.sourceId(),
edgeCondition,
nodeFactories,
keyStrategyMap,
compileConfig);
// 将并行节点的工厂存入映射
nodeFactories.put(conditionalParallelNode.id(), conditionalParallelNode.actionFactory());
// 建立源节点到并行节点的边映射
edges.put(e.sourceId(), new EdgeValue(conditionalParallelNode.id()));
// 从条件映射中提取所有目标节点ID
var mappedNodeIds = edgeCondition.mappings().values().stream()
.collect(Collectors.toSet());
// 校验所有映射的节点都存在,不存在则抛出异常
var missingNodeIds = mappedNodeIds.stream()
.filter(nodeId -> !nodeFactories.containsKey(nodeId))
.collect(Collectors.toSet());
if (!missingNodeIds.isEmpty()) {
throw new GraphStateException("节点 '"
+ e.sourceId() + "' 的多命令条件映射引用了未知目标节点:" + missingNodeIds);
}
// 查找并行节点的最终目标节点
var parallelNodeTargets = findParallelNodeTargets(mappedNodeIds);
if (!parallelNodeTargets.isEmpty()) {
// 建立并行节点到最终目标节点的边映射
edges.put(conditionalParallelNode.id(), new EdgeValue(parallelNodeTargets.iterator().next()));
} else {
// 无目标节点,抛出非法目标异常
throw Errors.illegalMultipleTargetsOnParallelNode.exception(e.sourceId(), 0);
}
} else {
// ====================== 处理:单命令条件边(普通条件边) ======================
edges.put(e.sourceId(), target);
}
} else {
// ====================== 处理:普通单目标边(无任何条件) ======================
edges.put(e.sourceId(), target);
}
}
// -------------------- 分支2:多目标边(并行执行场景) --------------------
else {
// 定义流:获取所有存在的并行目标节点
Supplier<Stream<EdgeValue>> parallelNodeStream = () -> targets.stream()
.filter(target -> nodeFactories.containsKey(target.id()));
// 筛选并行节点对应的有效边
var parallelNodeEdges = parallelNodeStream.get()
.map(target -> new Edge(target.id()))
.filter(ee -> processedData.edges().elements.contains(ee))
.map(index -> processedData.edges().elements.indexOf(index))
.map(index -> processedData.edges().elements.get(index))
.toList();
// 提取并行节点的最终目标节点ID
var parallelNodeTargets = parallelNodeEdges.stream()
.map(ee -> ee.target().id())
.collect(Collectors.toSet());
// 校验:并行节点只能有一个最终目标,多个则抛出异常
if (parallelNodeTargets.size() > 1) {
// 检查是否存在条件边,并行节点不支持条件边
var conditionalEdges = parallelNodeEdges.stream()
.filter(ee -> ee.target().value() != null)
.toList();
if (!conditionalEdges.isEmpty()) {
throw Errors.unsupportedConditionalEdgeOnParallelNode.exception(e.sourceId(),
conditionalEdges.stream().map(Edge::sourceId).toList());
}
throw Errors.illegalMultipleTargetsOnParallelNode.exception(e.sourceId(), parallelNodeTargets);
}
// 获取有效目标列表
var targetList = parallelNodeStream.get().toList();
// 通过工厂创建并行节点的动作实例(捕获创建异常)
var actions = targetList.stream()
.map(target -> {
try {
return nodeFactories.get(target.id()).apply(compileConfig);
} catch (GraphStateException ex) {
throw new RuntimeException("创建目标节点动作失败:"
+ target.id() + ",原因:" + ex.getMessage(), ex);
}
})
.toList();
// 提取目标节点ID集合
var actionNodeIds = targetList.stream().map(EdgeValue::id).toList();
// 获取并行节点的唯一最终目标ID
var targetNodeId = parallelNodeTargets.iterator().next();
// ====================== 创建并行执行节点 ======================
var parallelNode = new ParallelNode(e.sourceId(), targetNodeId, actions, actionNodeIds, keyStrategyMap,
compileConfig);
// 存储并行节点工厂
nodeFactories.put(parallelNode.id(), parallelNode.actionFactory());
// 建立源节点 -> 并行节点 的边
edges.put(e.sourceId(), new EdgeValue(parallelNode.id()));
// 建立并行节点 -> 最终目标节点 的边
edges.put(parallelNode.id(), new EdgeValue(targetNodeId));
}
}
}编译完成后的对象实例:
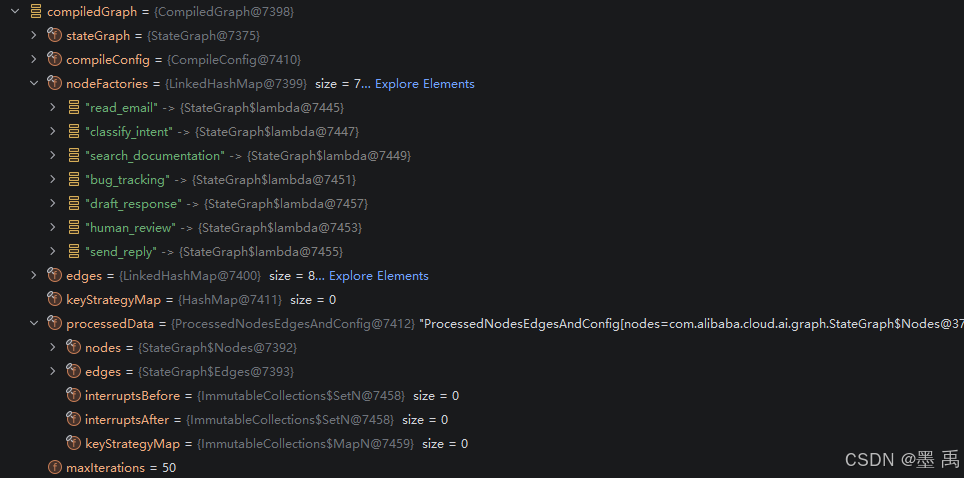
2.3 触发执行
调用 CompiledGraph 执行方法时,触发执行:
java
RunnableConfig config = RunnableConfig.builder()
.threadId(sessionId)
.build();
Map<String, Object> inputs = Map.of(
"email_content", message,
"sender_email", "user@example.com",
"email_id", UUID.randomUUID().toString()
);
Flux<NodeOutput> stream = emailAgentGraph.stream(inputs, config);初始输入参数:
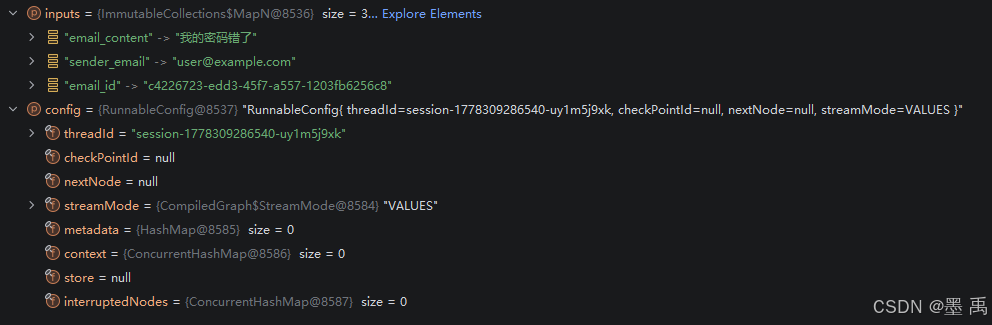
构建初始状态,然后从初始节点开始创建并返回响应式流:
java
/**
* 根据传入的输入参数,创建 NodeOutput 类型的 Flux 响应式流
* 采用基于 Project Reactor 的现代化响应式编程实现
*
* @param inputs 输入参数集合
* @param config 方法调用的配置参数
* @return 包含 NodeOutput 元素的 Flux 响应式流
*/
public Flux<NodeOutput> stream(Map<String, Object> inputs, RunnableConfig config) {
// 构建初始状态,然后从初始节点开始创建并返回响应式流
return streamFromInitialNode(stateCreate(inputs), config);
}2.3.1 初始化状态
创建全局状态对象:
- 处理输入参数空值
- 强制保证执行
ID存在:若输入参数中无执行ID,自动生成UUID作为执行ID并添加到参数中 - 使用构建器创建全局状态实例
stateCreate(inputs) 源码:
java
/**
* 创建全局状态对象
* 处理输入参数空值、自动生成执行ID,并基于图的键策略构建完整的全局状态实例
* @param inputs 输入参数集合
* @return 初始化完成的全局状态实例
*/
private OverAllState stateCreate(Map<String, Object> inputs) {
// 处理空输入参数(适配流程恢复场景),若输入为null则初始化为空Map
if (inputs == null) {
inputs = new HashMap<>();
}
// 强制保证执行ID存在:若输入参数中无执行ID,自动生成UUID作为执行ID并添加到参数中
if (!inputs.containsKey(GraphLifecycleListener.EXECUTION_ID_KEY)) {
Map<String, Object> newInputs = new HashMap<>(inputs);
newInputs.put(GraphLifecycleListener.EXECUTION_ID_KEY, UUID.randomUUID().toString());
inputs = newInputs;
}
// 使用构建器创建全局状态实例:注入键策略、输入数据、存储配置,最终构建返回
return OverAllStateBuilder.builder()
.withKeyStrategies(getKeyStrategyMap())
.withData(inputs)
.withStore(compileConfig.getStore())
.build();
}创建完成时的状态实例包含:
data:初始输入内容_graph_execution_id_:自动生成的 UUID 格式执行 ID,用来唯一标识本次图执行实例keyStrategies:状态更新规则,store:记忆存储实例
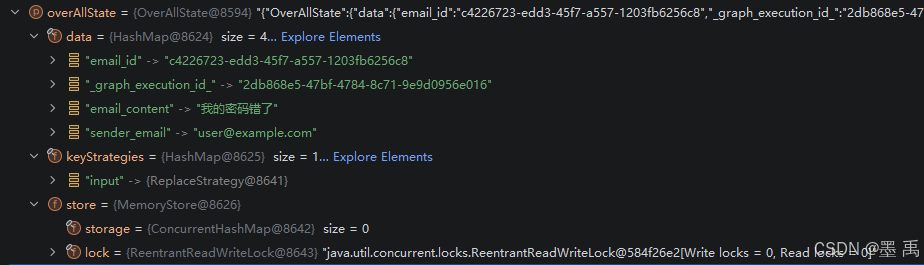
2.3.2 创建 Flux 响应式流
启动图执行器,处理执行结果并转换为标准的 NodeOutput 响应式流:
- 创建
GraphRunner、MainGraphExecutor、NodeExecutor - 执行状态图,处理执行结果流
- 异常处理
streamFromInitialNode 方法源码:
java
/**
* 从初始全局状态创建 Flux 响应式流
* @param overAllState 初始全局状态(包含输入数据、执行ID、策略等)
* @param config 运行配置参数
* @return 包含节点执行输出的 Flux 响应式流
*/
public Flux<NodeOutput> streamFromInitialNode(OverAllState overAllState, RunnableConfig config) {
// 校验运行配置不能为空,为空则抛出空指针异常
Objects.requireNonNull(config, "config cannot be null");
try {
// 创建图执行器实例,绑定当前编译图和运行配置
GraphRunner runner = new GraphRunner(this, config);
// 执行状态图,处理执行结果流,通过 flatMap 展开处理
return runner.run(overAllState).flatMap(data -> {
// 分支1:状态图执行完成
if (data.isDone()) {
// 判断执行结果是否为 NodeOutput 类型,是则返回包含结果的流
if (data.resultValue().isPresent() && data.resultValue().get() instanceof NodeOutput) {
return Flux.just((NodeOutput) data.resultValue().get());
} else {
// 无有效结果,返回空流
return Flux.empty();
}
}
// 分支2:状态图执行发生错误
if (data.isError()) {
// 获取错误输出,转换为响应式流并透传异常
return Mono.fromFuture(data.getOutput()).onErrorMap(throwable -> throwable).flux();
}
// 分支3:正常执行中,获取输出并转换为响应式流
return Mono.fromFuture(data.getOutput()).flux();
});
} catch (Exception e) {
// 捕获执行过程中的所有异常,包装为响应式错误流返回
return Flux.error(e);
}
}GraphRunner 实例对象:

GraphRunner#run 会调用 MainGraphExecutor 真正调用执行逻辑:
java
public Flux<GraphResponse<NodeOutput>> run(OverAllState initialState) {
return Flux.defer(() -> {
try {
GraphRunnerContext context = new GraphRunnerContext(initialState, config, compiledGraph);
// Delegate to the main execution handler - demonstrates polymorphism
return mainGraphExecutor.execute(context, resultValue);
}
catch (Exception e) {
return Flux.error(e);
}
});
}2.3.3 初始化图执行上下文
GraphRunnerContext 管理状态图执行过程中的所有运行时状态、节点路由、中断控制、检查点、生命周期回调,是图执行器的核心上下文载体,贯穿整个流程执行生命周期。
成员变量:
java
public class GraphRunnerContext {
/**
* 中断后标识常量:标记流程执行中断
*/
public static final String INTERRUPT_AFTER = "__INTERRUPTED__";
/** 日志对象 */
private static final Logger log = LoggerFactory.getLogger(GraphRunner.class);
/** 编译后的状态图对象 */
final CompiledGraph compiledGraph;
/** 执行迭代计数器:防止无限循环,记录当前执行步数 */
final AtomicInteger iteration = new AtomicInteger(0);
/** 全局状态对象:存储执行过程中的所有数据、状态、策略 */
OverAllState overallState;
/** 运行配置:执行时的参数、配置项 */
RunnableConfig config;
/** 当前执行的节点ID */
String currentNodeId;
/** 下一个要执行的节点ID */
String nextNodeId;
/** Token使用统计:大模型调用的token消耗信息 */
Usage tokenUsage;
/** 流程恢复的节点ID:从该节点恢复执行 */
String resumeFrom;
/** 嵌入执行返回值:子图/嵌入节点执行完成后的返回数据 */
ReturnFromEmbed returnFromEmbed;
}初始化构造方法:
java
/**
* 构造方法:初始化图执行上下文
* @param initialState 初始全局状态
* @param config 运行配置
* @param compiledGraph 编译后的状态图
* @throws Exception 初始化异常
*/
public GraphRunnerContext(OverAllState initialState, RunnableConfig config, CompiledGraph compiledGraph)
throws Exception {
this.compiledGraph = compiledGraph;
this.config = config;
// 判断是否为流程恢复执行(包含人工反馈/检查点ID)
if (config.metadata(RunnableConfig.HUMAN_FEEDBACK_METADATA_KEY).isPresent() || config.checkPointId().isPresent()) {
// 从检查点恢复执行流程
initializeFromResume(initialState, config);
} else {
// 从头开始执行流程
initializeFromStart(initialState, config);
}
}初始化好后的上下文对象实例:
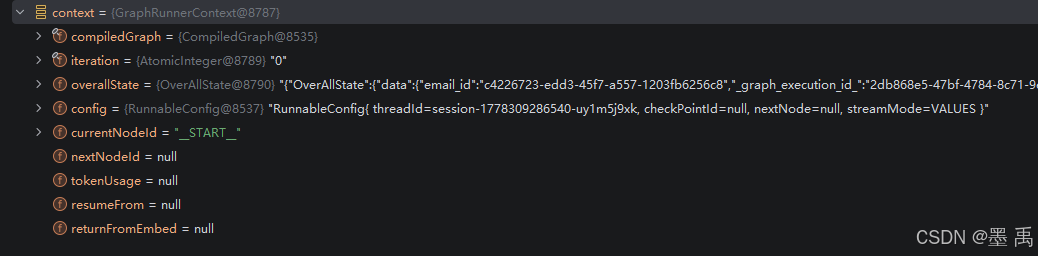
构造与初始化方法:
| 方法名称 | 核心功能说明 |
|---|---|
GraphRunnerContext(构造方法) |
初始化执行上下文,自动判别是从头启动 还是从检查点恢复流程 |
initializeFromResume |
加载检查点快照,恢复历史状态、下一节点、子图恢复配置 |
initializeFromStart |
流程首次启动,初始化全局状态、起始节点、输入参数 |
stateCreate |
复用键策略、存储配置,新建 OverAllState 全局状态实例 |
执行状态判断工具方法:
| 方法名称 | 核心功能说明 |
|---|---|
shouldStop |
判断流程是否可终止:当前节点、下一节点同时为空 |
isMaxIterationsReached |
迭代计数自增,判断是否超出最大迭代次数,防止死循环 |
isStartNode |
判断当前节点是否为流程起始节点 START |
isEndNode |
判断下一节点是否为流程结束节点 END |
shouldInterrupt |
综合前后置中断配置,判断当前是否需要触发流程中断 |
shouldInterruptBefore |
校验目标节点执行前是否配置中断规则 |
shouldInterruptAfter |
校验目标节点执行后是否配置中断规则 |
节点路由与命令解析方法:
| 方法名称 | 核心功能说明 |
|---|---|
getNodeAction |
根据节点ID从编译图获取对应的节点异步执行动作 |
getEntryPoint |
获取START入口边,解析流程第一个路由命令 |
nextNodeId(String nodeId, Map state) |
根据当前节点ID和状态,路由得到下一个节点命令 |
nextNodeId(EdgeValue route, Map state, String nodeId) |
核心路由逻辑:支持普通边、条件边、多命令并行节点路由解析 |
检查点持久化相关方法:
| 方法名称 | 核心功能说明 |
|---|---|
addCheckpoint |
构建执行快照,保存当前节点、状态、下一节点,持久化检查点 |
输出结果构建相关方法:
| 方法名称 | 核心功能说明 |
|---|---|
buildOutput(String nodeId, Optional<Checkpoint>) |
根据流模式/检查点,构建普通输出或状态快照输出 |
buildStreamingOutput(Message,...) |
构建带聊天消息、原始数据的流式输出对象 |
buildStreamingOutput(Object,...) |
构建仅含原始数据的流式输出对象 |
buildNodeOutput(String nodeId) |
构建标准节点输出,封装节点ID、状态、Token用量 |
buildNodeOutput(String nodeId, Map, boolean) |
自动解析消息列表,适配普通/流式场景组装输出 |
状态更新与克隆管理方法:
| 方法名称 | 核心功能说明 |
|---|---|
cloneState |
深度克隆状态数据,避免原全局状态被篡改污染 |
mergeIntoCurrentState |
将节点增量更新数据合并到全局状态 |
findTokenUsageInDeltaState |
分离Token统计与业务状态,单独存储用量、过滤普通状态数据 |
生命周期监听回调方法:
| 方法名称 | 核心功能说明 |
|---|---|
doListeners |
统一触发生命周期监听器:开始、结束、节点前置、节点后置、异常回调 |
工具 & 状态存取辅助方法:
| 方法名称 | 核心功能说明 |
|---|---|
| 各类 get/set 方法 | 读写当前节点、下一节点、全局状态、运行配置、恢复节点等属性 |
getResumeFromAndReset |
获取恢复节点标识并立即置空,一次性消费 |
getReturnFromEmbedAndReset |
获取嵌入子图返回值并置空 |
setReturnFromEmbedWithValue |
设置嵌入执行的返回结果 |
ReturnFromEmbed 内部记录类 |
封装嵌入返回值,提供泛型类型安全转换 |
2.4 节点执行
初始化好图执行上下文后,进入到 MainGraphExecutor 执行方法,该方法是 AI 状态图的执行大脑,负责判断当前该执行什么逻辑、处理各种特殊场景、管控流程生命周期,并最终返回标准化的执行结果。
完整执行步骤(按代码顺序):
-
校验流程终止条件(最高优先级):
- 判断条件:流程执行完成 / 达到最大迭代次数(防止死循环)
- 处理动作:调用完成处理方法,结束整个流程
-
处理嵌入/子图的返回结果:
- 判断条件:存在子图/嵌入节点的返回值
- 处理动作 :
- 解析返回值中是否包含中断信息
- 有中断 → 返回中断响应
- 无中断 → 构建节点结果、保存检查点,返回完成响应
-
处理节点中断恢复:
- 判断条件:当前节点处于中断状态
- 处理动作:标记节点为已恢复,返回当前执行状态
-
处理流程起始节点:
- 判断条件 :当前节点为
START(流程刚启动) - 处理动作:执行起始节点的初始化逻辑
- 判断条件 :当前节点为
-
处理流程结束节点:
- 判断条件 :下一个节点为
END(流程即将结束) - 处理动作:执行收尾逻辑,封装最终结果
- 判断条件 :下一个节点为
-
处理检查点断点恢复:
- 判断条件:从历史检查点恢复执行
- 处理动作:重新路由下一个执行节点,恢复执行上下文
-
处理流程主动中断:
- 判断条件:满足配置的中断规则(节点执行前/后中断)
- 处理动作:构建中断元数据,暂停流程执行
-
执行普通节点业务逻辑:
- 判断条件:以上所有特殊场景都不满足
- 处理动作:调用节点执行器,运行节点的核心业务逻辑
-
全局异常捕获(兜底):
- 触发条件:执行过程中任意步骤抛出异常
- 处理动作 :
- 触发生命周期异常监听器
- 打印错误日志
- 返回标准化的错误响应流
方法源码:
java
/**
* 执行方法的具体实现
* 体现多态性:为状态图的主执行流程提供专属实现
* @param context 图执行上下文(存储所有运行时状态)
* @param resultValue 存储执行结果的原子引用(保证线程安全)
* @return 包含节点输出的GraphResponse响应式流
*/
@Override
public Flux<GraphResponse<NodeOutput>> execute(GraphRunnerContext context, AtomicReference<Object> resultValue) {
try {
// ====================== 1. 终止条件判断 ======================
// 判断是否需要停止执行:流程完成 或 达到最大迭代次数(防止死循环)
if (context.shouldStop() || context.isMaxIterationsReached()) {
return handleCompletion(context, resultValue);
}
// ====================== 2. 处理嵌入执行返回值 ======================
// 获取并重置子图/嵌入节点的返回值
final var returnFromEmbed = context.getReturnFromEmbedAndReset();
if (returnFromEmbed.isPresent()) {
// 解析返回值中的中断元数据
var interruption = returnFromEmbed.get().value(new TypeRef<InterruptionMetadata>() {
});
// 存在中断元数据:直接返回中断完成响应
if (interruption.isPresent()) {
return Flux.just(GraphResponse.done(interruption.get()));
}
// 无中断:构建节点输出并保存检查点,返回执行完成响应
return Flux.just(GraphResponse.done(context.buildNodeOutputAndAddCheckpoint(Map.of())));
}
// ====================== 3. 处理节点中断恢复 ======================
// 当前节点存在,且配置为中断状态:标记节点已恢复
if (context.getCurrentNodeId() != null && context.getConfig().isInterrupted(context.getCurrentNodeId())) {
context.getConfig().withNodeResumed(context.getCurrentNodeId());
return Flux.just(GraphResponse.done(context.getCurrentStateData()));
}
// ====================== 4. 处理起始节点 ======================
if (context.isStartNode()) {
return handleStartNode(context);
}
// ====================== 5. 处理结束节点 ======================
if (context.isEndNode()) {
return handleEndNode(context, resultValue);
}
// ====================== 6. 处理流程恢复(从检查点恢复) ======================
final var resumeFrom = context.getResumeFromAndReset();
if (resumeFrom.isPresent()) {
// 校验边中断配置,路由下一个执行节点
if (context.getCompiledGraph().compileConfig.interruptBeforeEdge()
&& java.util.Objects.equals(context.getNextNodeId(), INTERRUPT_AFTER)) {
var nextNodeCommand = context.nextNodeId(resumeFrom.get(), context.getCurrentStateData());
context.setNextNodeId(nextNodeCommand.gotoNode());
context.setCurrentNodeId(null);
}
}
// ====================== 7. 处理流程中断 ======================
if (context.shouldInterrupt()) {
try {
// 构建中断元数据,包含当前节点和状态
InterruptionMetadata metadata = InterruptionMetadata
.builder(context.getCurrentNodeId(), context.cloneState(context.getCurrentStateData()))
.build();
return Flux.just(GraphResponse.done(metadata));
}
catch (Exception e) {
// 中断处理异常:返回错误响应
return Flux.just(GraphResponse.error(e));
}
}
// ====================== 8. 执行普通节点逻辑 ======================
// 所有前置校验通过,执行节点的具体业务逻辑
return nodeExecutor.execute(context, resultValue);
}
catch (Exception e) {
// ====================== 全局异常捕获 ======================
// 执行生命周期异常监听器
context.doListeners(ERROR, e);
// 打印错误日志
LoggerFactory.getLogger(com.alibaba.cloud.ai.graph.GraphRunner.class)
.error("Error during graph execution", e);
// 返回异常响应式流
return Flux.just(GraphResponse.error(e));
}
}2.4.1 START
首先会进入 START 分支:
java
if (context.isStartNode()) {
return handleStartNode(context);
}handleStartNode 方法处理步骤如下:
- 触发启动监听器:执行流程启动的生命周期回调,通知所有监听器流程开始。
- 解析流程入口 :从上下文获取
START节点的路由规则,得到第一个要执行的业务节点。 - 设置下一节点 :将解析出的首个业务节点,设置为上下文的下一个执行节点。
- 保存检查点:持久化起始节点的执行快照,支持后续断点恢复执行。
- 构建执行结果:生成起始节点的标准输出对象,包含节点信息和状态数据。
- 切换当前节点 :将下一个节点更新为当前执行节点,完成节点切换。
- 递归执行后续流程 :返回起始节点的输出结果,递归调用主执行方法,继续执行后续的业务节点。
- 异常兜底:捕获所有启动异常,返回标准化的错误响应。
方法源码:
java
/**
* 处理起始节点(START)的执行逻辑
* 流程启动的核心方法:触发监听器、解析入口节点、保存检查点、递归执行后续流程
* @param context 图执行上下文
* @return 包含起始节点处理结果的 GraphResponse 响应式流
*/
private Flux<GraphResponse<NodeOutput>> handleStartNode(GraphRunnerContext context) {
try {
// 1. 触发生命周期监听器:流程启动事件
context.doListeners(START, null);
// 2. 获取流程入口命令:解析START节点的路由,得到第一个要执行的节点
Command nextCommand = context.getEntryPoint();
// 3. 设置下一个执行节点ID
context.setNextNodeId(nextCommand.gotoNode());
// 4. 为起始节点添加执行检查点(持久化当前执行状态)
Optional<Checkpoint> cp = context.addCheckpoint(START, context.getNextNodeId());
// 5. 构建起始节点的执行输出结果
NodeOutput output = context.buildOutput(START, cp);
// 6. 将下一个节点设置为当前执行节点
context.setCurrentNodeId(context.getNextNodeId());
// 7. 返回输出结果,并递归调用执行方法,继续执行后续节点逻辑
return Flux.just(GraphResponse.of(output))
.concatWith(Flux.defer(() -> execute(context, new AtomicReference<>())));
}
catch (Exception e) {
// 异常捕获:返回错误响应
return Flux.just(GraphResponse.error(e));
}
}此时始化图执行上下文中的内容变化成:
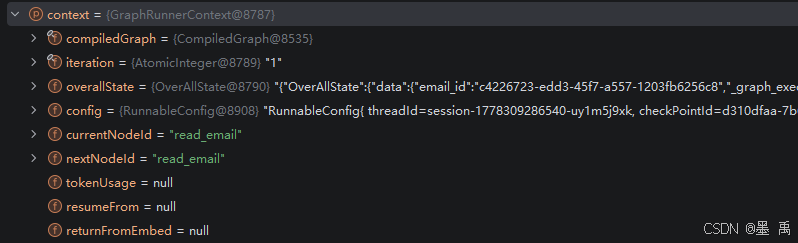
2.4.2 进入节点执行器
接着递归进入到 MainGraphExecutor#execute 方法,上下文中当前节点是 read_email,进入到 NodeExecutor :
java
return nodeExecutor.execute(context, resultValue);该方法是状态图中单个节点的执行引擎,负责节点的加载、校验、执行、中断处理与结果回调,步骤如下:
- 切换执行节点 :将上下文的下一个节点 设置为当前节点,完成节点执行的切换。
- 加载节点执行动作 : 根据节点
ID,从编译图中获取对应的业务执行逻辑。 - 节点合法性校验:若节点动作不存在,直接返回节点未找到的异常响应。
- 处理可中断节点:针对支持中断的节点,合并人工反馈的状态更新数据,执行节点中断逻辑,若触发中断则直接返回中断结果
- 触发节点前置监听器:执行节点执行前的生命周期回调。
- 异步执行节点业务逻辑:调用节点动作,异步执行业务代码,获取状态更新结果。
- 处理执行结果:转换异步执行结果,交给后续方法处理状态合并、路由下一个节点。
- 双层异常兜底:分别捕获异步执行异常、同步流程异常,统一返回标准化错误响应。
完整代码:
java
/**
* 执行单个节点并处理执行结果
* 核心职责:加载节点动作、执行节点逻辑、处理中断/回调/结果,是节点执行的最小单元
* @param context 图执行上下文
* @param resultValue 存储执行结果的原子引用(保证线程安全)
* @return 包含节点执行结果的 GraphResponse 响应式流
*/
private Flux<GraphResponse<NodeOutput>> executeNode(GraphRunnerContext context,
AtomicReference<Object> resultValue) {
try {
// 1. 将下一个执行节点设置为当前节点,完成节点切换
context.setCurrentNodeId(context.getNextNodeId());
String currentNodeId = context.getCurrentNodeId();
// 2. 获取当前节点对应的执行动作
AsyncNodeActionWithConfig action = context.getNodeAction(currentNodeId);
// 3. 节点动作不存在:返回节点不存在异常
if (action == null) {
return Flux.just(GraphResponse.error(RunnableErrors.missingNode.exception(currentNodeId)));
}
// 4. 处理【可中断节点】的特殊逻辑
if (action instanceof InterruptableAction) {
// 合并人工反馈的状态更新数据到当前全局状态
context.getConfig().metadata(RunnableConfig.STATE_UPDATE_METADATA_KEY).ifPresent(updateFromFeedback -> {
if (updateFromFeedback instanceof Map<?, ?>) {
context.mergeIntoCurrentState((Map<String, Object>) updateFromFeedback);
} else {
throw new RuntimeException("状态更新数据格式非法!");
}
});
// 执行节点中断逻辑,获取中断元数据
Optional<InterruptionMetadata> interruptMetadata = ((InterruptableAction) action)
.interrupt(currentNodeId, context.cloneState(context.getCurrentStateData()), context.getConfig());
// 存在中断信息:标记结果并返回中断完成响应
if (interruptMetadata.isPresent()) {
resultValue.set(interruptMetadata.get());
return Flux.just(GraphResponse.done(interruptMetadata.get()));
}
}
// 5. 触发生命周期监听器:节点执行前回调
context.doListeners(NODE_BEFORE, null);
// 6. 异步执行节点动作,返回执行结果Future
CompletableFuture<Map<String, Object>> future = action.apply(context.getOverallState(),
context.getConfig());
// 7. 转换异步结果,处理节点执行完成后的逻辑
return Mono.fromFuture(future)
.flatMapMany(updateState -> handleActionResult(context, updateState, resultValue))
// 异常处理:执行异常监听器,返回错误响应
.onErrorResume(error -> {
context.doListeners(ERROR, new Exception(error));
return Flux.just(GraphResponse.error(error));
});
}
catch (Exception e) {
// 全局异常兜底:返回错误响应
return Flux.just(GraphResponse.error(e));
}
}2.4.3 获取节点执行动作
根据当前节点名称获取节点执行动作:
java
public AsyncNodeActionWithConfig getNodeAction(String nodeId) {
return compiledGraph.getNodeAction(nodeId);
}最终是在 CompiledGraph 通过 ActionFactory 获取节点执行动作对象:
java
/**
* 为 ReactiveNodeGenerator 提供节点的访问能力
* 注:声明为 public 用于外部生成器访问,实际设计为包级私有使用场景
*/
public AsyncNodeActionWithConfig getNodeAction(String nodeId) {
// 从节点工厂映射中,根据节点ID获取对应的动作工厂
Node.ActionFactory factory = nodeFactories.get(nodeId);
try {
// 工厂存在:使用编译配置创建并返回节点动作;工厂不存在:返回null
return factory != null ? factory.apply(compileConfig) : null;
} catch (GraphStateException e) {
// 捕获节点动作创建异常,包装为运行时异常抛出
throw new RuntimeException(
"创建节点动作失败,节点ID:" + nodeId + ",异常原因:" + e.getMessage(), e);
}
}CompiledGraph 中的 nodeFactories 数据:
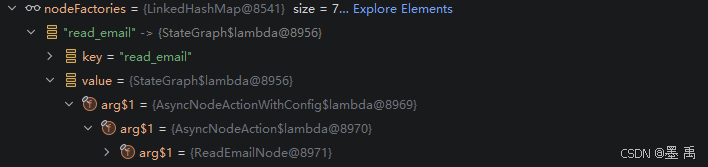
2.4.4 执行节点动作
调用获取到的节点动作实例:
java
CompletableFuture<Map<String, Object>> future = action.apply(context.getOverallState(),
context.getConfig());进入到自定义的节点动作类,执行业务逻辑处理,返回处理后的数据:
java
public class ReadEmailNode implements NodeAction {
private static final Logger log = LoggerFactory.getLogger(ReadEmailNode.class);
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
String emailContent = state.value("email_content")
.map(v -> (String) v)
.orElseGet(() -> state.value("input")
.map(v -> (String) v)
.orElseGet(() -> state.value("content")
.map(v -> (String) v)
.orElse("")));
log.info("Processing email: {}", emailContent);
List<String> messages = new ArrayList<>();
messages.add("Processing email: " + emailContent);
return Map.of(
"messages", messages,
"email_content", emailContent
);
}
}2.5 处理节点执行结果
结果处理完成后,进入到执行完成后的逻辑:
java
// 7. 转换异步结果,处理节点执行完成后的逻辑
return Mono.fromFuture(future)
.flatMapMany(updateState -> handleActionResult(context, updateState, resultValue))
// 异常处理:执行异常监听器,返回错误响应
.onErrorResume(error -> {
context.doListeners(ERROR, new Exception(error));
return Flux.just(GraphResponse.error(error));
});handleActionResult 方法是节点执行结果的核心处理器,承接节点业务逻辑的输出,完成状态、路由、中断、流的全流程处理,核心处理步骤说明:
- 嵌套流处理 :优先处理子图/嵌入执行的
Flux、并行流、兼容流,实现图的嵌套/并行执行。 - 执行后中断校验:针对可中断节点,执行中断钩子逻辑,触发中断则直接返回中断结果。
- 状态合并:将节点执行后的增量状态更新,合并到全局状态中。
- 下一个节点路由:根据配置判断是否中断,或正常计算下一个执行节点。
- 结果持久化:构建节点输出,保存执行检查点。
- 生命周期回调:触发节点执行完成的监听器。
- 递归驱动流程 :返回当前节点结果,递归调用主执行器,驱动状态图继续执行下一个节点。
- 全局异常捕获:捕获所有异常,返回标准化错误响应。
完整源码:
java
/**
* 处理节点动作的执行结果,返回标准化响应
* 核心:处理嵌入流、并行流、执行后中断、状态合并、节点路由,递归驱动下一轮执行
* @param context 图执行上下文
* @param updateState 节点执行后返回的状态更新数据
* @param resultValue 存储执行结果的原子引用
* @return 包含处理结果的 GraphResponse 响应式流
*/
private Flux<GraphResponse<NodeOutput>> handleActionResult(GraphRunnerContext context,
Map<String, Object> updateState, AtomicReference<Object> resultValue) {
try {
// ====================== 1. 处理嵌入的 Flux 流(子图/嵌套执行) ======================
Optional<Flux<GraphResponse<NodeOutput>>> embedFlux = getEmbedFlux(context, updateState);
if (embedFlux.isPresent()) {
return handleEmbeddedFlux(mainGraphExecutor, context, embedFlux.get(), updateState, resultValue);
}
// ====================== 2. 处理并行图 Flux 流(ParallelNode 返回) ======================
Optional<ParallelGraphFlux> embedParallelGraphFlux = getEmbedParallelGraphFlux(updateState);
if (embedParallelGraphFlux.isPresent()) {
return handleParallelGraphFlux(context, embedParallelGraphFlux.get(), updateState, resultValue);
}
// ====================== 3. 处理兼容版 GraphFlux 流(向下兼容) ======================
Optional<GraphFlux<?>> embedGraphFlux = getEmbedGraphFlux(updateState,context);
if (embedGraphFlux.isPresent()) {
return handleGraphFlux(context, embedGraphFlux.get(), updateState, resultValue);
}
// ====================== 4. 处理【可中断节点】的执行后中断逻辑 ======================
String currentNodeId = context.getCurrentNodeId();
AsyncNodeActionWithConfig action = context.getNodeAction(currentNodeId);
if (action instanceof InterruptableAction) {
// 执行节点执行后的中断钩子,获取中断元数据
Optional<InterruptionMetadata> interruptMetadata = ((InterruptableAction) action)
.interruptAfter(currentNodeId, context.cloneState(context.getCurrentStateData()),
updateState, context.getConfig());
// 触发中断:合并状态、路由节点、保存检查点、返回中断结果
if (interruptMetadata.isPresent()) {
// 先合并状态,保证恢复时状态正确
context.mergeIntoCurrentState(updateState);
// 计算下一个执行节点
Command nextCommand = context.nextNodeId(currentNodeId, context.getCurrentStateData());
context.setNextNodeId(nextCommand.gotoNode());
// 构建输出并保存检查点
context.buildNodeOutputAndAddCheckpoint(updateState);
// 触发节点执行后监听器
context.doListeners(NODE_AFTER, null);
// 设置结果并返回中断完成响应
resultValue.set(interruptMetadata.get());
return Flux.just(GraphResponse.done(interruptMetadata.get()));
}
}
// ====================== 5. 合并节点状态更新到全局状态 ======================
context.mergeIntoCurrentState(updateState);
// ====================== 6. 路由下一个执行节点 ======================
// 判断是否配置边中断:设置中断标识
if (context.getCompiledGraph().compileConfig.interruptBeforeEdge()
&& context.getCompiledGraph().compileConfig.interruptsAfter()
.contains(context.getCurrentNodeId())) {
context.setNextNodeId(INTERRUPT_AFTER);
}
else {
// 正常路由:根据当前节点和状态计算下一个节点
Command nextCommand = context.nextNodeId(context.getCurrentNodeId(), context.getCurrentStateData());
context.setNextNodeId(nextCommand.gotoNode());
}
// ====================== 7. 构建执行结果并保存检查点 ======================
NodeOutput output = context.buildNodeOutputAndAddCheckpoint(updateState);
// ====================== 8. 触发节点执行后监听器 ======================
context.doListeners(NODE_AFTER, null);
// ====================== 9. 返回结果,并递归执行下一轮主流程 ======================
return Flux.just(GraphResponse.of(output))
.concatWith(Flux.defer(() -> mainGraphExecutor.execute(context, resultValue)));
}
catch (Exception e) {
// 异常兜底:返回错误响应
return Flux.just(GraphResponse.error(e));
}
}2.5.1 状态更新
这里直接进入到合并节点状态更新到全局状态:
java
// ====================== 5. 合并节点状态更新到全局状态 ======================
context.mergeIntoCurrentState(updateState);mergeIntoCurrentState 对外提供的状态合并入口,负责将节点执行后的更新数据,合并到全局状态中:
java
/**
* 合并状态更新数据到全局状态
* 会自动过滤Token用量统计信息,仅将业务数据更新到全局状态中
* @param updateState 节点执行后返回的状态更新数据
*/
public void mergeIntoCurrentState(Map<String, Object> updateState) {
// 过滤状态数据:分离Token用量统计,保留纯业务数据
Map<String, Object> filteredState = findTokenUsageInDeltaState(updateState);
// 将过滤后的业务数据更新到全局状态对象
this.overallState.updateState(filteredState);
}findTokenUsageInDeltaState 临时解决方案:
- 从状态数据中提取
_TOKEN_USAGE_字段(AI大模型Token消耗),单独存储; - 避免统计数据污染业务状态,仅返回纯业务数据用于合并。
java
/**
* 临时修复方案:从状态更新数据中分离Token用量统计信息
* 专门配合 AgentLlmNode 非流式节点使用,将Token统计数据单独存储
* FIXME: 临时实现,后续需要统一状态更新与Token用量的处理逻辑
* @param updateState 原始的状态更新数据
* @return 过滤掉Token统计后的纯业务状态数据
*/
private Map<String, Object> findTokenUsageInDeltaState(Map<String, Object> updateState) {
Map<String, Object> filteredState = new HashMap<>();
// 遍历状态数据,分离Token用量和业务数据
for (Map.Entry<String, Object> entry : updateState.entrySet()) {
Object value = entry.getValue();
// 识别专用的Token用量字段,单独保存,不合并到业务状态
if (value instanceof Usage && entry.getKey().equals("_TOKEN_USAGE_")) {
this.tokenUsage = (Usage) value;
} else {
// 普通业务数据,加入过滤集合
filteredState.put(entry.getKey(), value);
}
}
return filteredState;
}最终调用的是 OverAllState 中全局状态合并方法,所有节点执行后的状态更新都通过该方法实现:
- 策略优先:读取字段专属的
KeyStrategy(更新规则),无配置则使用默认覆盖策略; - 支持删除:识别
MARK_FOR_REMOVAL标记,直接删除指定状态字段; - 智能合并:根据策略(覆盖 / 追加 / 累加等)合并新旧状态值;
- 全局生效:将合并后的结果写入全局状态,返回最新数据。
java
/**
* 状态Map更新方法
* 核心:根据配置的键策略将局部增量状态合并到全局状态,支持覆盖、追加、删除等多种更新规则
* @param partialState 增量局部状态(节点执行后需要更新的状态数据)
* @return 合并完成后的全局状态数据
*/
public Map<String, Object> updateState(Map<String, Object> partialState) {
// 获取全局状态的键策略映射(定义每个字段的更新规则)
Map<String, KeyStrategy> keyStrategies = keyStrategies();
// 遍历增量状态的所有键,逐个执行状态更新
partialState.keySet().forEach(key -> {
// 获取当前字段对应的键策略
KeyStrategy strategy = keyStrategies != null ? keyStrategies.get(key) : null;
// 无专属策略时,使用默认的覆盖策略(REPLACE)
if (strategy == null) {
strategy = KeyStrategy.REPLACE;
}
// 处理状态删除:若值为删除标记,直接从全局状态中移除该字段
if (partialState.get(key) == MARK_FOR_REMOVAL) {
this.data.remove(key);
} else {
// 应用键策略,合并旧值与新值,更新到全局状态
this.data.put(key, strategy.apply(value(key, null), partialState.get(key)));
}
});
// 返回最终更新完成的全局状态
return data();
}2.5.2 计算下一个节点
handleActionResult 中会计算下一个节点,并设置到执行上下文中:
java
Command nextCommand = context.nextNodeId(context.getCurrentNodeId(), context.getCurrentStateData());
context.setNextNodeId(nextCommand.gotoNode());会先从 CompiledGraph 中获取节点连接的边名称:
java
public Command nextNodeId(String nodeId, Map<String, Object> state) throws Exception {
return nextNodeId(compiledGraph.getEdge(nodeId), state, nodeId);
}
nextNodeId 按优先级处理 3 种跳转规则:
- 固定路由 → 直接跳转到配置的节点
- 多命令并行路由 → 跳转到动态生成的并行节点
- 单命令条件路由 → 执行条件逻辑→映射目标节点→合并状态→跳转
- 所有配置无效 → 抛出执行异常
java
/**
* 【核心路由方法】根据边配置计算下一个执行节点
* 处理三种路由场景:固定节点路由、单命令条件路由、多命令并行条件路由
* @param route 节点边配置(定义节点跳转规则)
* @param state 当前状态数据
* @param nodeId 当前执行的节点ID
* @return 执行命令(包含下一个节点ID + 状态数据)
* @throws Exception 边配置缺失、节点映射错误、执行异常
*/
private Command nextNodeId(EdgeValue route, Map<String, Object> state,
String nodeId) throws Exception {
// 1. 合法性校验:边配置不能为空,为空则抛出缺失边异常
if (route == null) {
throw RunnableErrors.missingEdge.exception(nodeId);
}
// 2. 固定路由场景:边直接配置了目标节点ID,直接返回命令
if (route.id() != null) {
return new Command(route.id(), state);
}
// 3. 条件路由场景:边配置了动态条件逻辑
if (route.value() != null) {
var edgeCondition = route.value();
// 判断是否为多命令并行执行逻辑
if (edgeCondition.isMultiCommand()) {
// 多命令场景:路由到动态创建的条件并行节点
// 该并行节点在CompiledGraph中动态生成,负责处理并行逻辑
String conditionalParallelNodeId = ParallelNode.formatNodeId(nodeId);
// 返回指向并行节点的执行命令
return new Command(conditionalParallelNodeId, state);
} else {
// 单命令场景:执行单条件路由逻辑
var singleAction = edgeCondition.singleAction();
// 执行条件动作,获取路由命令
var command = singleAction.apply(this.overallState, config).get();
// 从条件映射中获取最终的目标节点ID
var newRoute = command.gotoNode();
String result = route.value().mappings().get(newRoute);
// 校验目标节点是否存在,不存在则抛出映射异常
if (result == null) {
throw RunnableErrors.missingNodeInEdgeMapping.exception(nodeId, newRoute);
}
// 合并条件执行产生的状态更新到全局状态
this.mergeIntoCurrentState(command.update());
// 返回最终目标节点的执行命令
return new Command(result, state);
}
}
// 4. 兜底异常:边配置非法,无有效路由规则
throw RunnableErrors.executionError.exception(format("节点 [%s] 的边配置无效!", nodeId));
}因为读取邮件是一个固定边,直接返回 Command 命令对象。
2.5.3 构建执行结果并保存检查点
接着进入到:
java
// ====================== 7. 构建执行结果并保存检查点 ======================
NodeOutput output = context.buildNodeOutputAndAddCheckpoint(updateState);buildNodeOutputAndAddCheckpoint 先保存检查点,再构建节点输出:
java
/**
* FIXME 临时方案
* 以下为重复冗余方法,需要重构为统一的流式输出方式,为终端用户提供标准化输出
*/
public NodeOutput buildNodeOutputAndAddCheckpoint(Map<String, Object> updateStates) throws Exception {
// 添加当前执行节点的检查点
Optional<Checkpoint> cp = addCheckpoint(currentNodeId, nextNodeId);
// 构建并返回节点执行输出结果
return buildOutput(currentNodeId, updateStates, cp, false);
}addCheckpoint方法执行克隆状态、持久化执行快照,支持流程断点恢复,强制新增不覆盖:
java
/**
* 添加执行检查点(持久化执行快照)
* 保存当前节点、状态数据、下一个节点信息,支持流程断点恢复
* @param nodeId 当前执行节点ID
* @param nextNodeId 下一个执行节点ID
* @return 封装后的检查点对象(未配置持久化器则返回空)
* @throws Exception 检查点持久化异常
*/
public Optional<Checkpoint> addCheckpoint(String nodeId, String nextNodeId) throws Exception {
// 判断是否配置了检查点持久化器
if (compiledGraph.compileConfig.checkpointSaver().isPresent()) {
// 构建检查点对象:存储节点ID、克隆后的状态、下一个节点ID
var cp = Checkpoint.builder().nodeId(nodeId).state(cloneState(overallState.data())).nextNodeId(nextNodeId)
.build();
// 强制清空检查点ID,确保新增检查点(而非覆盖原有检查点)
RunnableConfig appendConfig = RunnableConfig.builder(config).checkPointId(null).build();
// 持久化检查点,并更新运行配置
this.config = compiledGraph.compileConfig.checkpointSaver().get().put(appendConfig, cp);
return Optional.of(cp);
}
// 未配置持久化器,返回空
return Optional.empty();
}buildOutput 输出统一入口,区分快照模式/普通模式,适配不同的流输出需求:
java
/**
* 构建节点执行输出(统一入口)
* 根据流模式判断返回状态快照 或 标准节点输出
* @param nodeId 节点ID
* @param updateStates 状态更新数据
* @param checkpoint 执行检查点
* @param streaming 是否为流式输出
* @return 节点输出对象
* @throws Exception 构建异常
*/
public NodeOutput buildOutput(String nodeId, Map<String, Object> updateStates, Optional<Checkpoint> checkpoint, boolean streaming)
throws Exception {
// 快照模式:存在检查点且配置为快照流模式,返回状态快照
if (checkpoint.isPresent() && config.streamMode() == CompiledGraph.StreamMode.SNAPSHOTS) {
return StateSnapshot.of(getKeyStrategyMap(), checkpoint.get(), config,
compiledGraph.stateGraph.getStateSerializer().stateFactory());
}
// 普通模式:构建标准节点输出
return buildNodeOutput(nodeId, updateStates, streaming);
}最终调用 buildNodeOutput 输出构建底层方法,自动提取AI 对话消息、封装状态/Token用量,生成标准化流式输出:
java
/**
* 构建标准节点输出
* 自动提取消息数据,区分流式/普通输出,封装状态、Token用量、节点信息
* @param nodeId 节点ID
* @param updateStates 状态更新数据
* @param streaming 是否为流式输出
* @return 流式节点输出对象
* @throws Exception 构建异常
*/
public NodeOutput buildNodeOutput(String nodeId, Map<String, Object> updateStates, boolean streaming) throws Exception {
Message message = null;
// 校验状态更新数据非空
if (updateStates != null && !updateStates.isEmpty()) {
// 获取消息数据
Object messagesObj = updateStates.get("messages");
// 场景1:消息为列表,取最后一条消息
if (messagesObj instanceof List<?> messagesList && !messagesList.isEmpty()) {
Object lastElement = messagesList.get(messagesList.size() - 1);
if (lastElement instanceof Message) {
message = (Message) lastElement;
}
}
// 场景2:消息为单个Message对象
else if (messagesObj instanceof Message singleMessage) {
message = singleMessage;
}
}
// 根据流式标识生成输出类型
OutputType outputType = OutputType.from(streaming, nodeId);
// 存在消息:返回带消息的流式输出
if (message != null) {
return new StreamingOutput<>(message, nodeId, (String) config.metadata("_AGENT_").orElse(""),
cloneState(this.overallState.data()), tokenUsage, outputType);
}
// 无消息:返回基础节点输出
else {
return new StreamingOutput<>(nodeId, (String) config.metadata("_AGENT_").orElse(""),
cloneState(this.overallState.data()), tokenUsage, outputType);
}
}2.5.4 递归
在当前节点 执行 NodeExecutor#handleActionResult 的最后,会调用 MainGraphExecutor#execute 递归执行下一轮:
java
// ====================== 9. 返回结果,并递归执行下一轮主流程 ======================
return Flux.just(GraphResponse.of(output))
.concatWith(Flux.defer(() -> mainGraphExecutor.execute(context, resultValue)));2.6 END
在 MainGraphExecutor#execute 中如果直行道结束节点,会调用 handleEndNode 完成流程收尾、结果存储、响应返回:
java
if (context.isEndNode()) {
return handleEndNode(context, resultValue);
}处理流程【结束节点】的逻辑:
- 触发流程结束的监听器(回调)
- 构建结束节点的输出结果
- 返回标准响应 + 执行流程完成收尾逻辑
- 全局捕获异常,统一返回错误响应
java
/**
* Handles the end node execution.
* 处理流程【结束节点】的执行
* @param context 流程运行上下文(存储流程状态、节点、配置等)
* @param resultValue 原子引用,用于线程安全地存储最终执行结果
* @return Flux<GraphResponse<NodeOutput>> 响应式流,返回结束节点处理结果
*/
private Flux<GraphResponse<NodeOutput>> handleEndNode(GraphRunnerContext context,
AtomicReference<Object> resultValue) {
try {
// 1. 触发流程结束事件的所有监听器(回调函数)
context.doListeners(END, null);
// 2. 基于上下文构建【结束节点】的输出对象
NodeOutput output = context.buildNodeOutput(END);
// 3. 响应式返回:先返回成功响应,再执行流程完成逻辑
return Flux.just(GraphResponse.of(output))
.concatWith( // 串联执行:第一个流完成后,执行第二个流
Flux.defer(() -> handleCompletion(context, resultValue))
);
}
catch (Exception e) {
// 4. 全局异常捕获:任何错误都包装成错误响应返回
return Flux.just(GraphResponse.error(e));
}
}2.6.1 构建 NodeOutput
buildNodeOutput 方法中会返回统一的 NodeOutput 结果:
java
// Normal NodeOutput builders for nodes with normal message output.
// 注释:为【普通消息输出类型的节点】提供标准 NodeOutput 构建器
public NodeOutput buildNodeOutput(String nodeId) throws Exception {
// 构建并返回标准的节点输出对象
return NodeOutput.of(
nodeId, // 1. 当前节点ID(如 END、开始节点、业务节点)
(String) config.metadata("_AGENT_").orElse(""), // 2. 执行代理(Agent)标识
cloneState(this.overallState.data()), // 3. 深度克隆的流程全局状态
this.tokenUsage // 4. 当前节点执行消耗的Token(AI/大模型场景)
);
}2.6.2 最终完成处理
handleCompletion 是流程引擎真正执行结束收尾的核心方法,只有两个分支,决定了流程结束后返回什么:
- 释放线程(
releaseThread = true) && 检查点保存器不为空时:生成一个Tag并返回,包含了检查点所有信息,同时释放该执行线程的所有checkpoint资源 - 普通正常结束(返回流程最终状态):返回
OverallState.data
java
/**
* 可被子类使用的受保护方法,通过提供对公共功能的受控访问来演示封装特性。
* @param context 流程运行上下文
* @param resultValue 用于存储最终结果的原子引用
* @return 包含完成处理结果的 GraphResponse 响应式流
*/
protected Flux<GraphResponse<NodeOutput>> handleCompletion(GraphRunnerContext context,
AtomicReference<Object> resultValue) {
// Flux.defer():延迟执行 ------ 直到被订阅时才运行里面的逻辑
return Flux.defer(() -> {
try {
// ====================== 核心分支:两种完成结果 ======================
// 条件1:是否开启释放线程
// 条件2:是否配置了检查点保存器(AI流程持久化)
if (context.getCompiledGraph().compileConfig.releaseThread()
&& context.getCompiledGraph().compileConfig.checkpointSaver().isPresent()) {
// 获取 Checkpoint 保存器 → 执行释放
BaseCheckpointSaver.Tag tag = context
.getCompiledGraph().compileConfig.checkpointSaver().get()
.release(context.getConfig());
// 原子引用存储:Checkpoint 标签
resultValue.set(tag);
} else {
// ============= 场景 B:普通正常结束(返回流程最终状态)=============
// 把流程全局状态数据复制一份,存入结果引用
resultValue.set(new HashMap<>(context.getOverallState().data()));
}
// 返回:流程执行完成(携带最终结果)
return Flux.just(GraphResponse.done(resultValue.get()));
} catch (Exception e) {
// 任何异常 → 返回错误响应(不崩溃)
return Flux.just(GraphResponse.error(e));
}
});
}releaseThread 控制图执行完成后是否释放/清理该执行线程的所有 checkpoint 资源。两种流程结束模式对比表:
| 对比维度 | releaseThread = false(默认模式) | releaseThread = true(释放线程模式) |
|---|---|---|
| 执行完成后 | 保留所有 checkpoints | 调用 release() 清理检查点 |
| 最终返回值 | HashMap(state.data()) 流程快照 |
Tag(threadId, checkpoints) 唯一标记 |
| 内存占用 | 流程上下文持续占用 | 执行完毕立即释放内存 |
| 支持恢复/时光回溯 | ✅ 支持中断恢复、历史回放、调试 | ❌ 不支持恢复与回放 |
| 适用场景 | 长流程、需中断恢复、调试、历史轨迹回放 | 一次性短流程、生命周期短、无需恢复 |