文章目录
前言
oncurrentHashMap 是 Java 并发容器里最常被问、也最容易被答浅的一个知识点。
很多人知道它"线程安全""性能比 Hashtable 好",也知道 JDK8 之后底层变成了"数组 + 链表 + 红黑树"。但如果继续追问:为什么要这样设计?为什么链表长度到 8 才树化?为什么容量还要达到 64?JDK7 和 JDK8 的并发控制到底差在哪里?put、扩容、计数、null 限制这些细节又分别解决了什么问题?答案往往就没那么稳了。
这篇文章会从最基础的数据结构演进讲起:先看数组和链表各自的优势与缺陷,再理解哈希表如何通过"数组 + 链表"融合查询和插入效率,最后重点分析 JDK8 中 ConcurrentHashMap 为什么引入红黑树、TreeBin、CAS、synchronized、sizeCtl、ForwardingNode 等机制。
理解 ConcurrentHashMap,不能只背结论,而要抓住它背后的核心矛盾:
如何在高并发场景下,同时保证线程安全、查询效率、写入性能和极端哈希冲突下的稳定性。
一、 数据结构进化历程
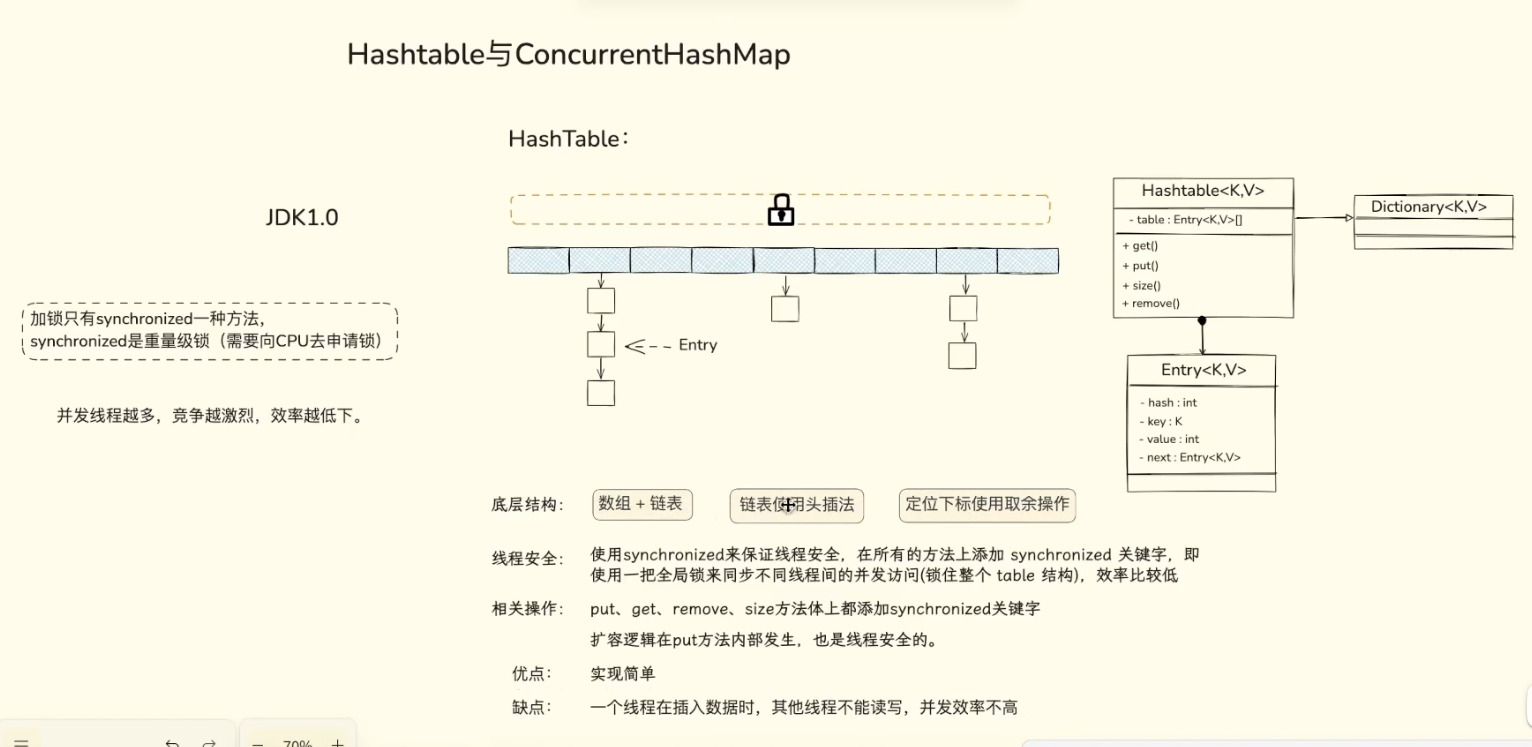
1.1 JDK1.0版本(数组+链表)
在最基础的数据结构世界里,数组和链表是两个性迥异的极端:
- 数组(Array): 内存中连续分配。优势: 拥有绝对的寻址霸权,根据下标查询的时间复杂度是绝对的
O(1)。劣势: 增删元素时需要大面积挪动数据,极其低效。 - 链表(Linked List): 内存中分散存储,通过指针相连。优势: 增删元素只需改变指针指向,时间复杂度
O(1)。劣势: 查找数据只能从头节点顺藤摸瓜,时间复杂度高达O(n)。
痛点: 在高并发、大数据的业务场景中,我们既想要数组的"秒查",又想要链表的"秒插",这能做到吗?
1.2 JDK1.5版本(哈希表)
为了融合两者的优点,哈希表(Hash Table) 诞生了。它采用了拉链法(Separate Chaining) ,这也是 JDK7 及之前版本 HashMap 和 ConcurrentHashMap 的底层基石。
- 结构解析: 主体是一个数组。当你插入一个 Key 时,通过哈希函数计算出一个哈希值,然后对数组长度取模,定位到具体的数组下标(也就是哈希桶
Bucket)。 - 解决冲突: 如果两个不同的 Key 算出了相同的下标(哈希冲突),怎么办?就把它们串成一个链表,挂在这个数组节点下面。
- 比喻: 数组就像是酒店的各个楼层,哈希函数是电梯。你瞬间到达指定楼层(O(1)),如果这层住了多个人(冲突),你再挨个敲门寻找(遍历链表)。
随着数据量激增,或者遇到恶意攻击(如 Hash DoS 攻击,故意构造大量哈希值相同的 Key),哈希表的脆弱一面暴露无遗。
- 灾难再现: 当大量的元素全部堆积在同一个哈希桶时,这个桶下面的链表会变得无限长。
- 性能崩塌: 此时,哈希表的查询效率从神坛跌落,由
O(1)极速退化成了单链表的O(n)。如果你去查一个在链表末尾的元素,每一次查询都要经历漫长的遍历,系统甚至会被直接拖垮。
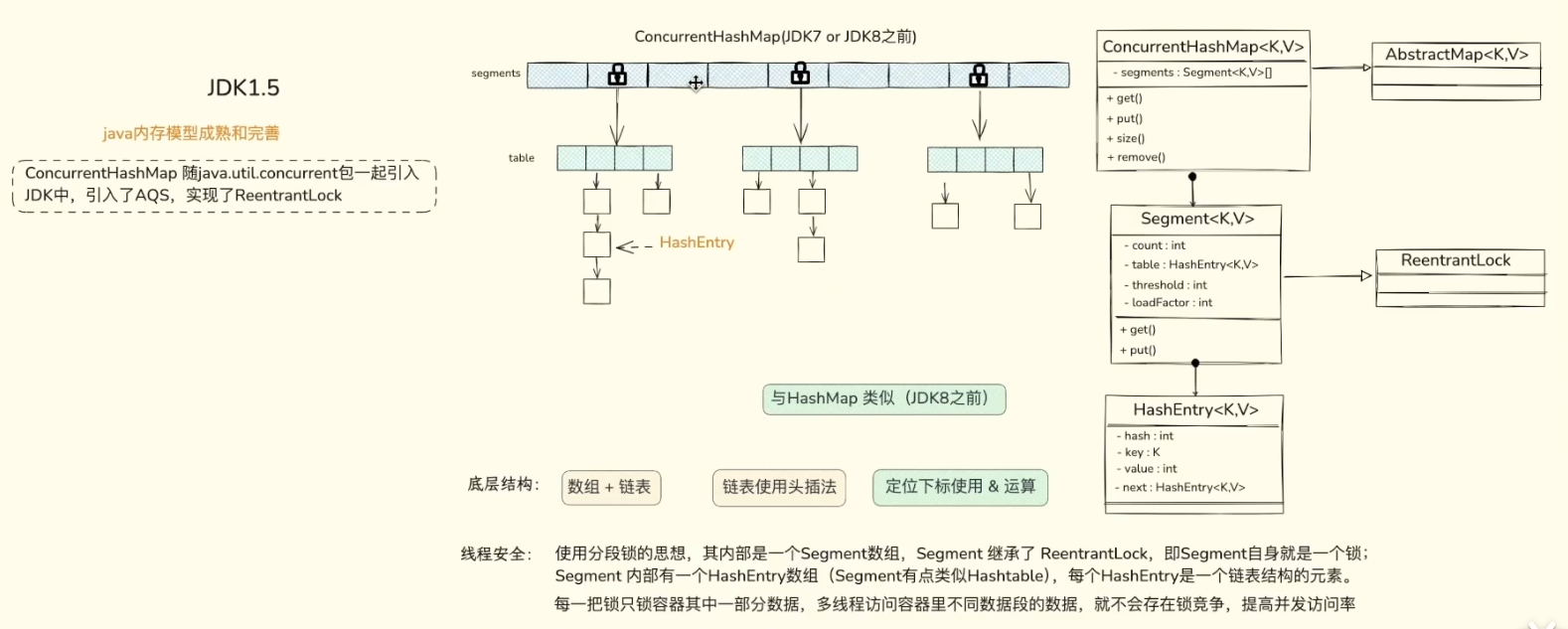

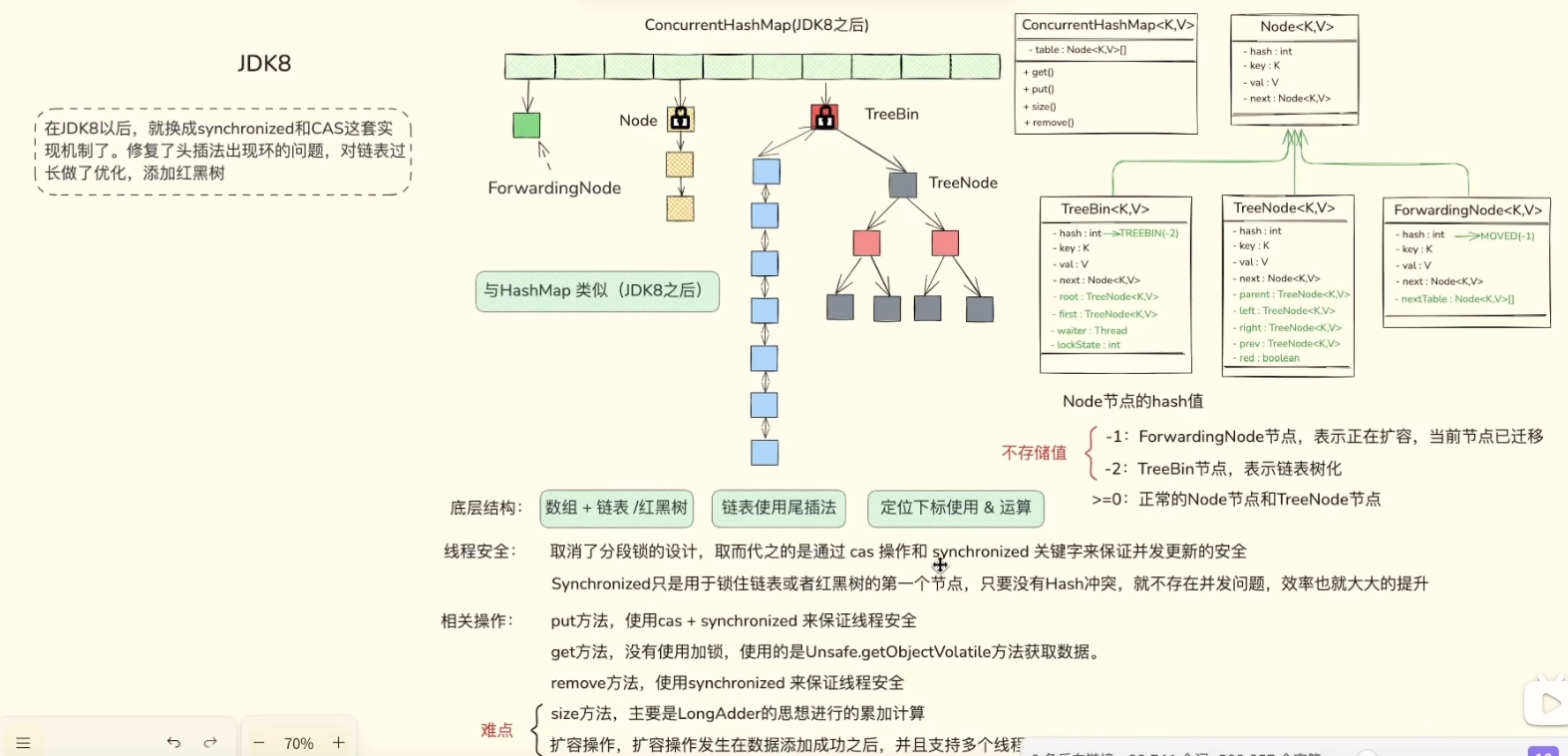
1.3 JDK8版本(红黑树)
为了彻底封死链表过长导致的性能退化,JDK8 对 ConcurrentHashMap 和 HashMap 的数据结构进行了史诗级大换血,进化成了数组 + 链表 + 红黑树的终极形态。
当发生哈希冲突时,元素依然先追加到链表上,但加入了严苛的"变异机制":
- 树化触发(Treeify): 当某一个哈希桶的链表长度达到 8 ,并且整个数组的总容量达到 64 时,这条慵懒的单向链表就会瞬间变身为一棵结构严密的红黑树(Red-Black Tree)。
- 退化触发(Untreeify): 当进行扩容或删除节点操作后,如果树中的节点数降到 6,红黑树又会退化回普通链表(利用 6 和 8 之间的差值,防止在 7 这个临界点发生频繁的"树化-退化"抖动)。
为什么是红黑树? 红黑树是一种自平衡的二叉查找树。
- 它的最大威力在于:无论数据怎么插入,它都能通过自身的左旋、右旋和变色,保持树的相对平衡。
- 这样一来,即使发生最极端的哈希冲突,在同一个桶里堆积了成千上万的数据,红黑树也能将最坏情况下的查询时间复杂度死死钉在
O(log n)(例如,100万条数据,最多只需查询 20 次左右),彻底杜绝了性能雪崩。
并发控制视角的升华: 在 JDK8 的 ConcurrentHashMap 源码中,当链表转为红黑树后,桶的头节点会被替换为一个特殊的包装类 TreeBin。此时,如果其他线程来修改数据,锁住的就是这个 TreeBin 节点。这不仅保证了读写的极高效率,还在红黑树复杂的平衡调整(左旋右旋)过程中,完美地维护了并发安全性。
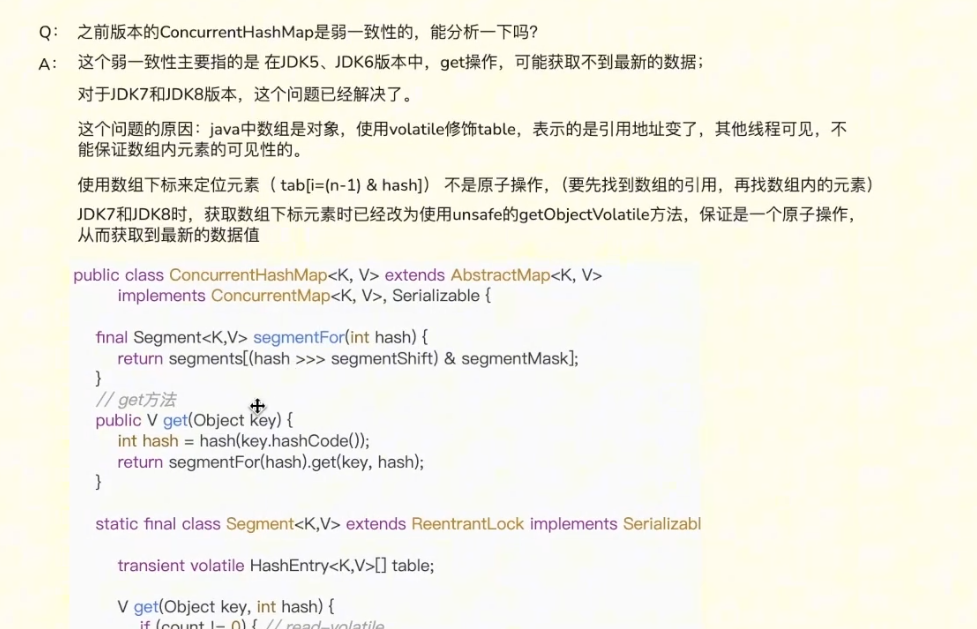
二、 常见面试问题








总结
ConcurrentHashMap 的底层演进,本质上是一条围绕"并发安全"和"性能稳定性"不断优化的路线。
最开始,数组和链表分别代表了两种极端:数组查询快,但增删成本高;链表增删灵活,但查询效率低。哈希表通过数组定位桶位、链表解决冲突,把两者的优势结合起来,让大多数情况下的查询和插入都接近 O(1)。
但哈希表并不是没有缺点:当大量 key 落到同一个桶中,链表会越来越长,查询复杂度会从 O(1) 退化到 O(n)。这也是 JDK8 引入红黑树的重要原因:当链表达到树化条件后,将桶内结构转换为红黑树,把极端冲突下的查询复杂度控制在 O(log n),避免性能雪崩。
从并发控制角度看,ConcurrentHashMap 的变化同样关键:
JDK7 主要依赖 Segment + ReentrantLock,通过分段锁降低锁竞争;JDK8 则取消 Segment,改为 Node 数组 + CAS + synchronized + TreeBin 的组合,只在必要时锁住桶头节点,粒度更细,结构也更灵活。
面试中常见的问题,比如 put 流程、扩容协助、ForwardingNode、sizeCtl、baseCount + CounterCell、为什么 key/value 不能为 null、为什么复合操作仍可能不安全,本质上都可以回到同一条主线:
ConcurrentHashMap 不是简单地给 HashMap 加锁,而是在数据结构、锁粒度、扩容协作、计数机制和异常语义上做了一整套面向高并发的工程设计。
所以,学习 ConcurrentHashMap 最重要的不是死记 API,而是理解它如何一步步解决这些问题:
- 哈希冲突如何处理?
- 链表过长如何避免性能退化?
- 多线程写入时如何减少锁竞争?
- 扩容时如何让多个线程协作迁移?
- 计数时如何降低热点竞争?
- 为什么不能允许 null 带来语义歧义?
把这些问题串起来,ConcurrentHashMap 的底层结构和面试题就不再是零散知识点,而是一套完整的并发容器设计思路。