一、HTTP
虽然我们说,应用层协议是我们程序猿自己定的;但实际上,已经有大佬们定义了⼀些现成的,又非常好用的应用层协议,供我们直接参考使用;HTTP(超文本传输协议)就是其中之⼀
在互联网世界中,HTTP(HyperText Transfer Protocol,超文本传输协议)是⼀个至关重要的协议;它定义了客户端(如浏览器)与服务器之间如何通信,以交换或传输超文本(如HTML文档)
HTTP协议是客户端与服务器之间通信的基础;客户端通过 HTTP 协议向服务器发送请求,服务器收到请求后处理并返回响应;HTTP协议是⼀个无连接、无状态的协议,即每次请求都需要建立新的连接, 且服务器不会保存客户端的状态信息
二、认识URL
平时我们俗称的 "网址" 其实就是说的URL
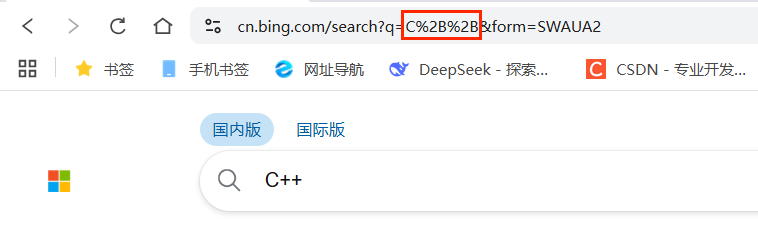
🔺urlencode 和 urldecode(了解)
像 / ?:等这样的字符,已经被 url 当做特殊意义理解了;因此这些字符不能随意出现;比如,某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义
**转义的规则如下**:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做⼀位,前⾯加 上%,编码成%XY格式,例如:
"+" 被转义成了 "%2B" urldecode就是urlencode的逆过程;

三、HTTP协议请求与响应格式
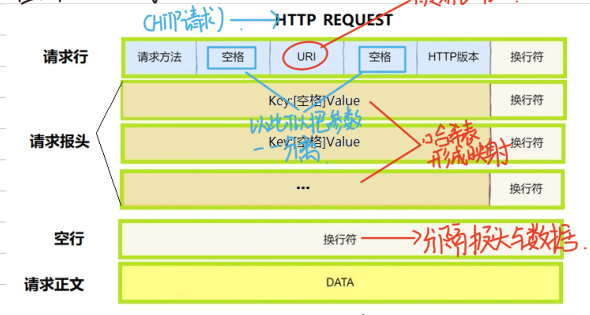
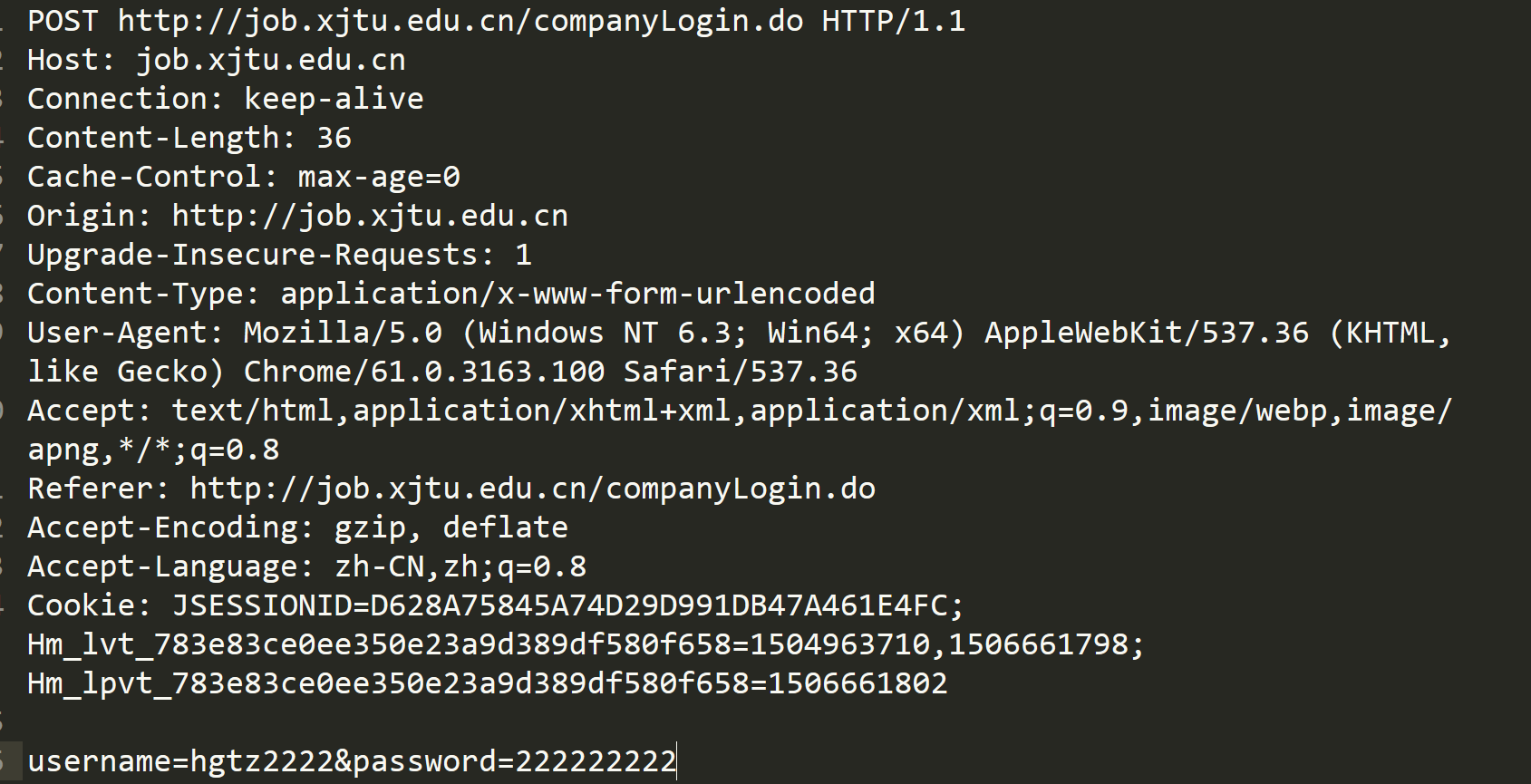
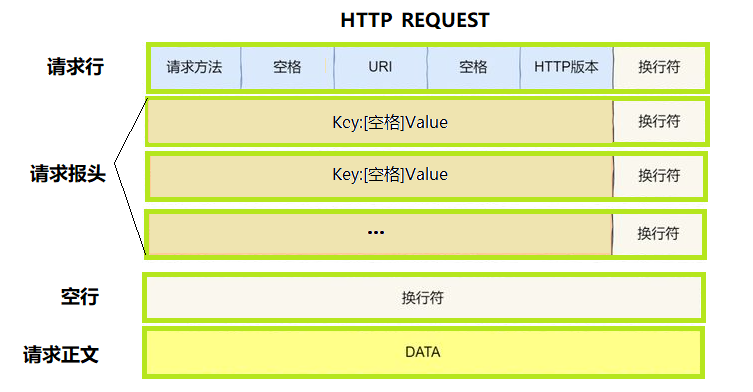
(1) HTTP请求
- 首行:方法 + url + 版本
- Header:请求的属性,冒号分割的键值对;每组属性之间使用 \r\n 分隔;遇到空行表示 Header 部分结束
- Body:空行后面的内容都是Body;Body允许为空字符串;如果Body存在,则在Header中会有⼀个 Content-Length 属性来标识Body的长度
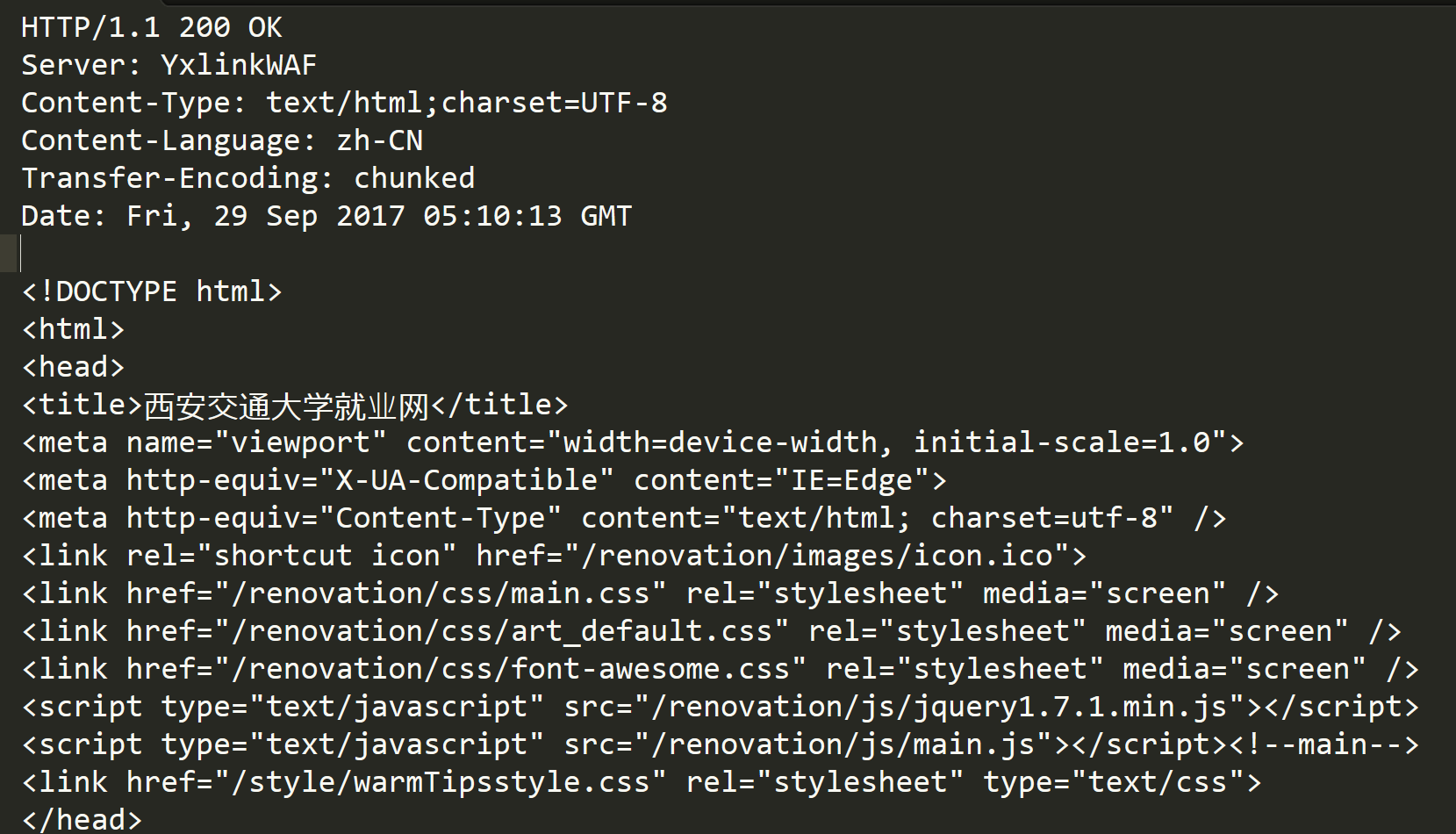
(2) HTTP响应
- 首行:版本号 + 状态码 + 状态码解释
- Header:请求的属性,冒号分割的键值对;每组属性之间使用 \r\n 分隔;遇到空行表示Header部分结束
- Body:空行后面的内容都是Body;Body允许为空字符串;如果Body存在,则在Header中会有⼀个 Content-Length属性来标识Body的长度;如果服务器返回了⼀个html页面,那么html页面内容就是在body中
- HTTPS的正文都是加密的
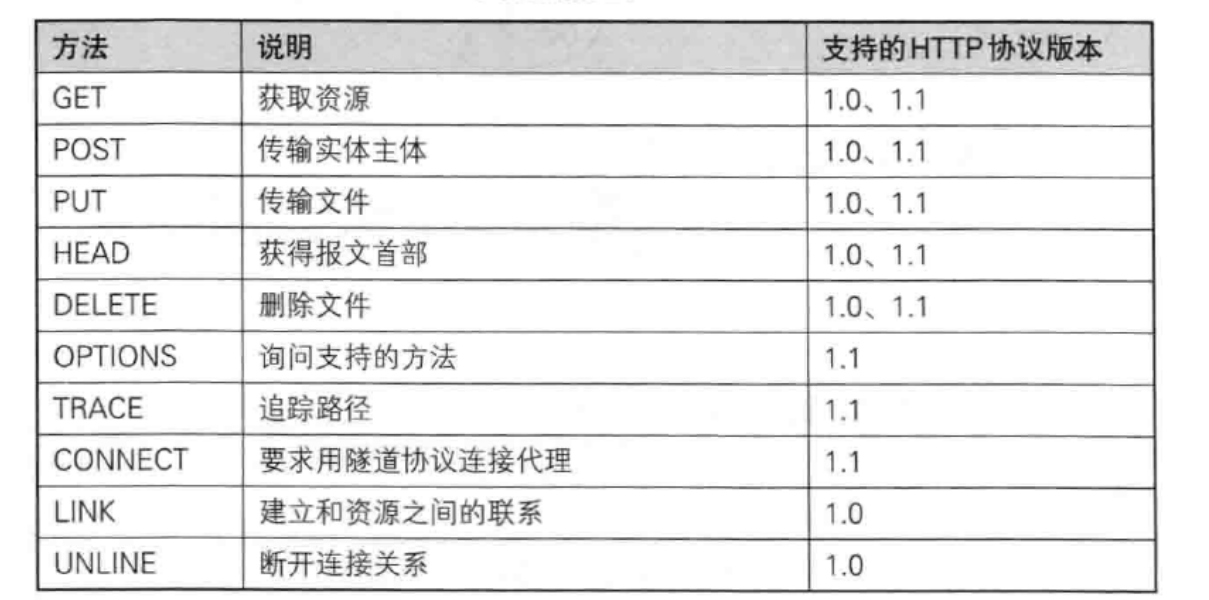
(3) HTTP的方法
- 其中最常用的就是GET方法和POST方法
(4) HTTP常用的方法
- GET方法(重点)
用途:用于请求URL指定的资源
示例:GET /index.html HTTP/1.1
特性:指定资源经服务器端解析后返回响应内容
cppstd::string GetFileContentHelper(const std::string& path) { // ⼀份简单的读取⼆进制⽂件的代码 std::ifstream in(path, std::ios::binary); if (!in.is_open()) return ""; in.seekg(0, in.end); int filesize = in.tellg(); in.seekg(0, in.beg); std::string content; content.resize(filesize); in.read((char*)content.c_str(), filesize); // std::vector<char> content(filesize); // in.read(content.data(), filesize); in.close(); return content; }
- POST方法(重点)
用途:用于传输实体的主体,通常用于提交表单数据
示例: POST /submit.cgi HTTP/1.1
特性:可以发送大量的数据给服务器,并且数据包含在请求体中
- PUT方法(不常用)
用途:用于传输文件,将请求报文主体中的文件保存到请求URL指定的位置
示例:PUT /example.html HTTP/1.1
特性:不太常用,但在某些情况下,如RESTful API中,用于更新资源
- HEAD方法
用途:与GET方法类似,但不返回报文主体部分,仅返回响应头
示例:HEAD /index.html HTTP/1.1
示例:HEAD /index.html HTTP/1.1
cpp// curl -i 显⽰ $ curl -i www.baidu.com HTTP/1.1 200 OK Accept-Ranges: bytes Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform Connection: keep-alive Content-Length: 2381 Content-Type: text/html Date: Sun, 16 Jun 2024 08:38:04 GMT Etag: "588604dc-94d" Last-Modified: Mon, 23 Jan 2017 13:27:56 GMT Pragma: no-cache Server: bfe/1.0.8.18 Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/ <!DOCTYPE html> ... // 使⽤head⽅法,只会返回响应头 $ curl --head www.baidu.com HTTP/1.1 200 OK Accept-Ranges: bytes Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform Connection: keep-alive Content-Length: 277 Content-Type: text/html Date: Sun, 16 Jun 2024 08:43:38 GMT Etag: "575e1f71-115" Last-Modified: Mon, 13 Jun 2016 02:50:25 GMT Pragma: no-cache Server: bfe/1.0.8.18
- DELETE方法(不常用)
用途:用于删除文件,是PUT的相反方法
示例: DELETE /example.html HTTP/1.1
特性:按请求URL删除指定的资源
- OPTIONS方法
用途:用于查询针对请求URL指定的资源支持的方法
示例:OPTIONS * HTTP/1.1
特性:返回允许的方法,如GET、POST等
(5) HTTP的状态码
📍 最常见的状态码,比如200(OK),404(Not Found),403(Forbidden),302(Redirect,重定向),504(Bad Gateway)
以下是仅包含重定向相关状态码的表格:
- 关于重定向的验证,以301为代表
HTTP状态码301(永久重定向)和302(临时重定向)都依赖Location选项;以下是关于两者依赖 Location 选项的详细说明:
🔺 HTTP状态码301(永久重定向)
- 当服务器返回HTTP 301状态码时,表⽰请求的资源已经被永久移动到新的位置
- 在这种情况下,服务器会在响应中添加⼀个Location头部,⽤于指定资源的新位置。这个Location 头部包含了新的URL地址,浏览器会⾃动重定向到该地址
- 例如,在HTTP响应中,可能会看到类似于以下的头部信息:
cppHTTP/1.1 301 Moved Permanently\r\n Location: https://www.new-url.com\r\n🔺 HTTP状态码302(临时重定向)
- 当服务器返回HTTP 302状态码时,表⽰请求的资源临时被移动到新的位置
- 同样地,服务器也会在响应中添加⼀个Location头部来指定资源的新位置;浏览器会暂时使⽤新的 URL进⾏后续的请求,但不会缓存这个重定向
- 例如,在HTTP响应中,可能会看到类似于以下的头部信息:
cppHTTP/1.1 302 Found\r\n Location: https://www.new-url.com\r\n📍 总结:⽆论是HTTP 301还是HTTP 302重定向,都需要依赖Location选项来指定资源的新位置;这个 Location选项是⼀个标准的HTTP响应头部,⽤于告诉浏览器应该将请求重定向到哪个新的URL地址

四、HTTP常见Header
- Content-Type:数据类型(text/html等)
- Content-Length:Body的长度
- Host:客户端告知服务器,所请求的资源是在哪个主机的哪个端口上
- User-Agent:声明用户的操作系统和浏览器版本信息
- Referer:当前页面是从哪个页面跳转过来的
- Location:搭配3xx状态码使用,告诉客户端接下来要去哪里访问
- Cookie:用于在客户端存储少量信息;通常⽤于实现会话(session)的功能
关于connection报头
HTTP中的 Connection 字段是HTTP报文头的⼀部分,它主要用于控制和管理客户端与服务器之间的连接状态
📍 核心作用
- 管理持久连接: Connection 字段还用于管理持久连接(也称为长连接);持久连接允许客户端和服务器在请求 / 响应完成后不立即关闭TCP连接,以便在同⼀个连接上发送多个请求和接收多个响应
- 持久连接 (长连接)
- HTTP / 1.1:在HTTP / 1.1协议中,默认使用持久连接;当客户端和服务器都不明确指定关闭连接时,连接将保持打开状态,以便后续的请求和响应可以复用同⼀个连接
- HTTP/1.0:在HTTP/1.0协议中,默认连接是非持久的;如果希望在HTTP / 1.0上实现持久连接,需要在请求头中显式设置 Connection: keep-alive
- 语法格式
- Connection: keep-alive :表示希望保持连接以复用TCP连接
- Connection: close :表示请求/响应完成后,应该关闭TCP连接
五、补充
- Cookie
- 网站存在你浏览器里的文本数据,一般4KB;
- 作用:记住你的登录状态;保存个性化设置;用户追踪 + 推荐;
- Cookie本质可以是一个文件,也可以存在内存中;如若存在内存中,关闭浏览器后,Cookie就不存在了(不常用)
- 现在,常使用Cookie与Session配合使用来维持长会话功能;当我们向服务器发起请求,提交我们的个人信息;那么服务器应答时,会返回一个session id(唯一的数字),并且把我们的信息以文件形式保存,作为key与sid进行映射,session+cookie=会话管理
- 如果服务器发现客户端登陆状态异常,就会把sid失效掉;所以主动权在于服务端,就是看server对异常情况的处理能力
- 服务器怎么保证自己的网页文件被你找到?(域名=IP)
答:首先通过 IP+Port 找到全网内唯一的进程,然后通过文件路径找到我们需要的资源(我们平常使用的连接会经过加密,不容易直接找出文件路径)
- URI:统一资源标识符,标识某一资源唯一性
- URL:是一种特殊的URI,是属于URI的
- HTTP底层与浏览器,用的都是TCP socket,用的都是 IP+Port 的进程间通信机制
- 和TCP一样,需要将报头与数据序列化与反序列化
- HTTP答复
- 状态码:返回服务器处理的结果
- 状态码描述:数字对人类不友好,所以会返回一些字符串,例如"Not Found"
- 无论是成功还是失败,如果网络没有问题,服务器没有挂掉,都得应答
- 一个网页,不一定只是一个文件!可能会有一个网页+多种资源构成;首页中一张网页,可能会和很多资源联系,需要把首页资源全都通过HTTP获取(这个过程需要非常多次请求)
- 图片,视频,音频,css,js------都叫做静态资源(只需要获取,无需跳转服务)
- 资源不一定全都存在于服务器,为减轻服务器启动压力,有的资源会保存到外部图床,这样服务器只用去请求外部资源即可
- 动态站点------>站点支持和用户进行交互------>登录,注册,支付查找
- 如何理解浏览器给HTTPserver提交参数的过程?
答:前端网页中有表单,用户填写表单,浏览器自动提取表单里的内容构建带参的HTTP request
- GET方法可以常用来进行获取静态资源,同时也可以用来向目标服务器传递参数(通过URI方式进行传递参数)
- POST可以用来向目标服务器传参,传参的方式是通过正文部分传参
- 相同点:都不安全
- 不同点:只是POST会更加私密一点,GET会在连接中回显
- 如何理解一个HTTP request中的URI的?
- Linux web根目录下存在的一个文件路径(静态资源访问)
- 我们可以把他当作一个字符串,用来请求http server中所对应的服务,字符串也往往以路径形式体现,只不过,这个路径不能在web根目录下存在
📍 这个路径不能在web根目录下存在(分两种情况)
- 返回静态资源时,需要对应的物理文件
- 调用后端接口时,不能对应物理文件,而是跟后端程序的暗号,把请求传给后端程序来处理