在交易、行情、IoT、日志补全等典型时间序列场景中,业务需要的不是普通等值关联,而是"按业务键分组后,在时间轴上找到不晚于左侧记录的最近一条右侧记录"。ASOF JOIN 正是为这类问题设计的:它把"同键匹配"和"时间近邻"统一到一条执行路径上,天然适合做交易撮合行情补全、事件归因、快照对齐等分析任务。
Doris 在 4.0.5 和 4.1.0 版本引入的 ASOF JOIN,正是为这类场景准备的高性能能力。它不仅支持了此类语法,而是把时间序列近邻关联做成了一个能在大规模、多分布、复杂业务形态下稳定运行的分析路径。从测试结果来看,Doris 在主流场景下取得了全面的性能领先。
一、业务语义:"最近可用事实"问题
拿最典型的交易与行情补全来说,ASOF 的含义并不复杂:
SQL
SELECT t.trade_id, t.stock_id, t.trade_time, q.ask_price
FROM trade t
ASOF LEFT JOIN quote q
ON t.stock_id = q.stock_id
AND t.trade_time >= q.quote_time;它表达的是两层关系:
第一层,先按 stock_id 找到同一只股票; 第二层,在同一只股票里,找 quote_time <= trade_time 的最近一条报价。
此类需求在金融投资等行业中极其常见。这类业务的典型特征是具有海量数据,且时效性要求极高。因此对于 ASOF JOIN 来说,极致性是业务落地的刚需。
在实现中,"如何在很大的数据量下,快速找到每个 key 下最接近的条目"实际存在着多种设计可能和大量需要优化的细节。Doris 在开发过程中进行了多维度、持续的详细测试,最终迭代出了满足性能要求的实现。
在 100 余条回归测试,以及大量随机生成的 Join 测试保障正确性的基础之上,我们通过详细分析典型业务场景,总结了六大类不同的典型场景,设计了一套 ASOF JOIN 的客观性能测试标准。通过这组 Benchmark,我们将 Doris 与知名数据库产品 ClickHouse、Duckdb 进行了性能对比。以下是完整测试设计、环境配置与性能结论:
二、测试设计:系统验证 ASOF JOIN 的核心能力边界
测试设计中,我们不仅从数据量角度完成覆盖,而是把 ASOF JOIN 的关键影响因子挨个拆开验证。整个测试矩阵覆盖了六大类典型场景:
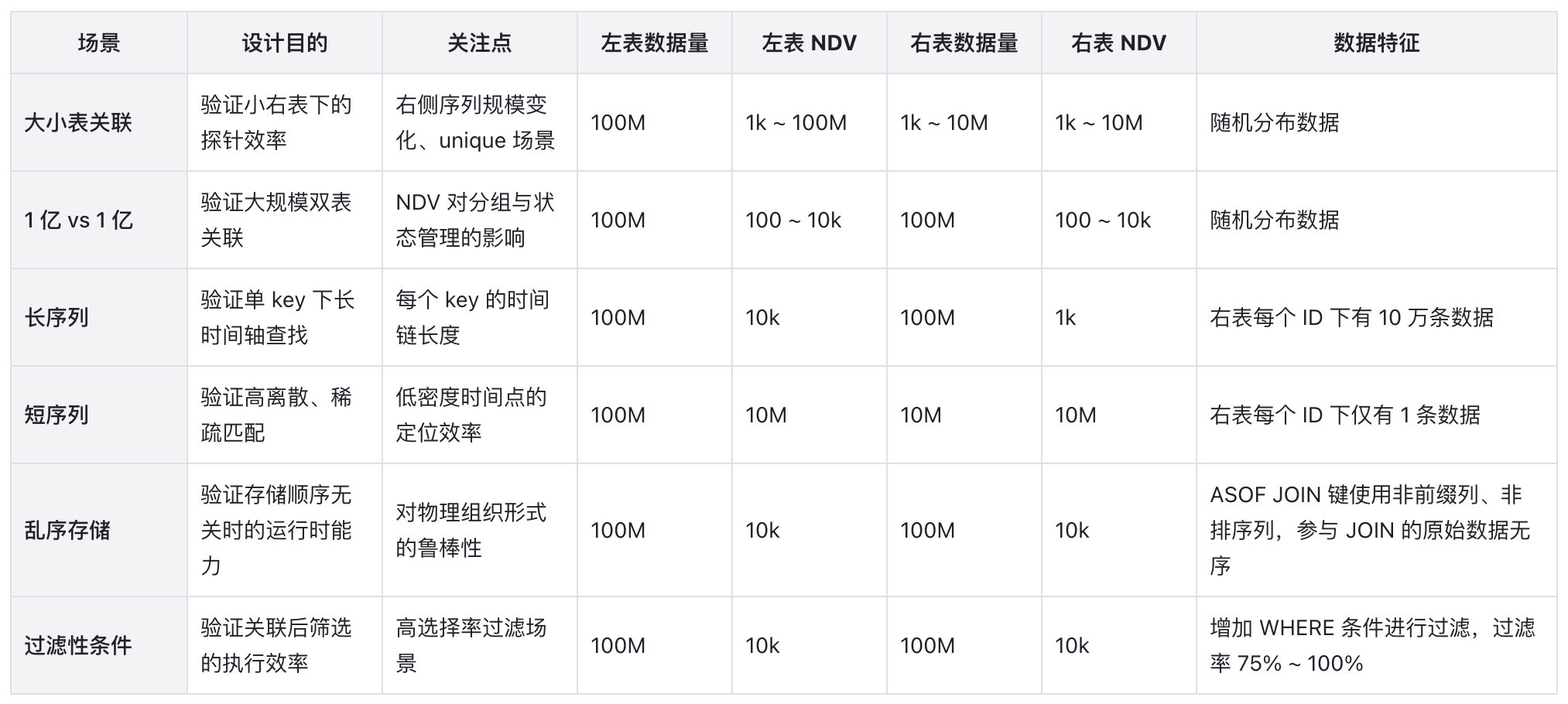
为了规避不同 DB 中数据扫描的影响,我们在被测的各个产品中使用了相同的表结构的和测试数据。并且在测试完成后验证了 case 的主要开销均为 ASOF JOIN 本身。
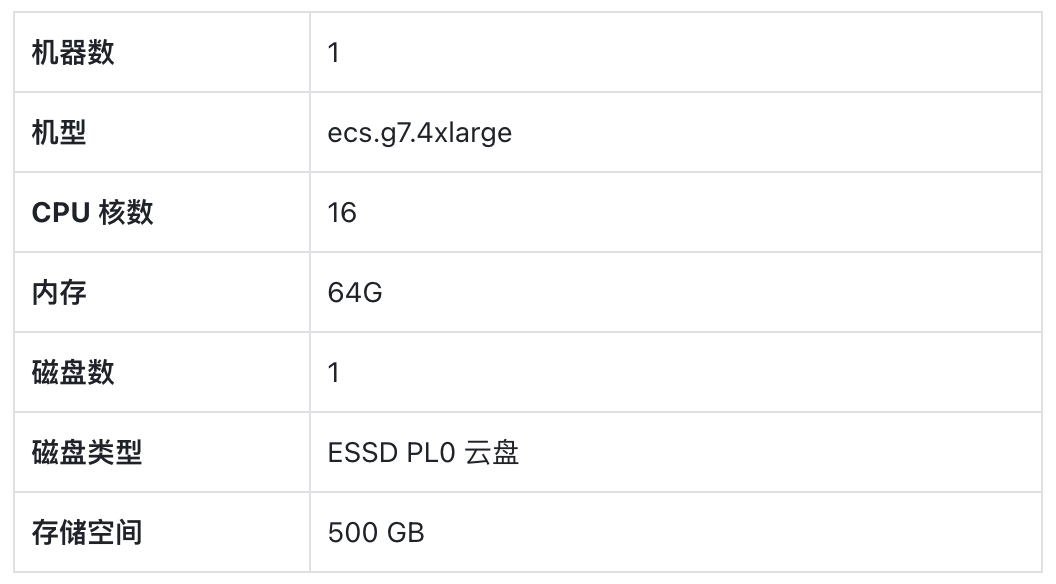
在实际测试中,由于存在单机数据库作为测试对象,我们对所有被测产品在相同集群配置下进行部署,Doris FE 与 BE 部署在同一机器内。以下为具体环境:
在相同的硬件环境下,各产品受测版本和参数调整如下:

由于 Apache Doris 的默认并发数与其他两款产品不同,在测试时我们手动调整它们到相同的并发,如上表。
实际测试中,我们在单并发下顺序重复测试所有 SQL,对每一个 SQL 在一次冷查过后进行三次热查,取热查中的最快成绩作为结果。最终结果如下:
三、性能结果:Doris 跨场景稳定领先
这次测试覆盖了大小表之间 JOIN、1 亿行对 1 亿行、不同 NDV、长序列、短序列、乱序、过滤等多种典型场景,基本覆盖了生产中可能遇到的各种情况。结果非常一致:Doris 在绝大多数主流用例中,都表现出了明显的性能优势。
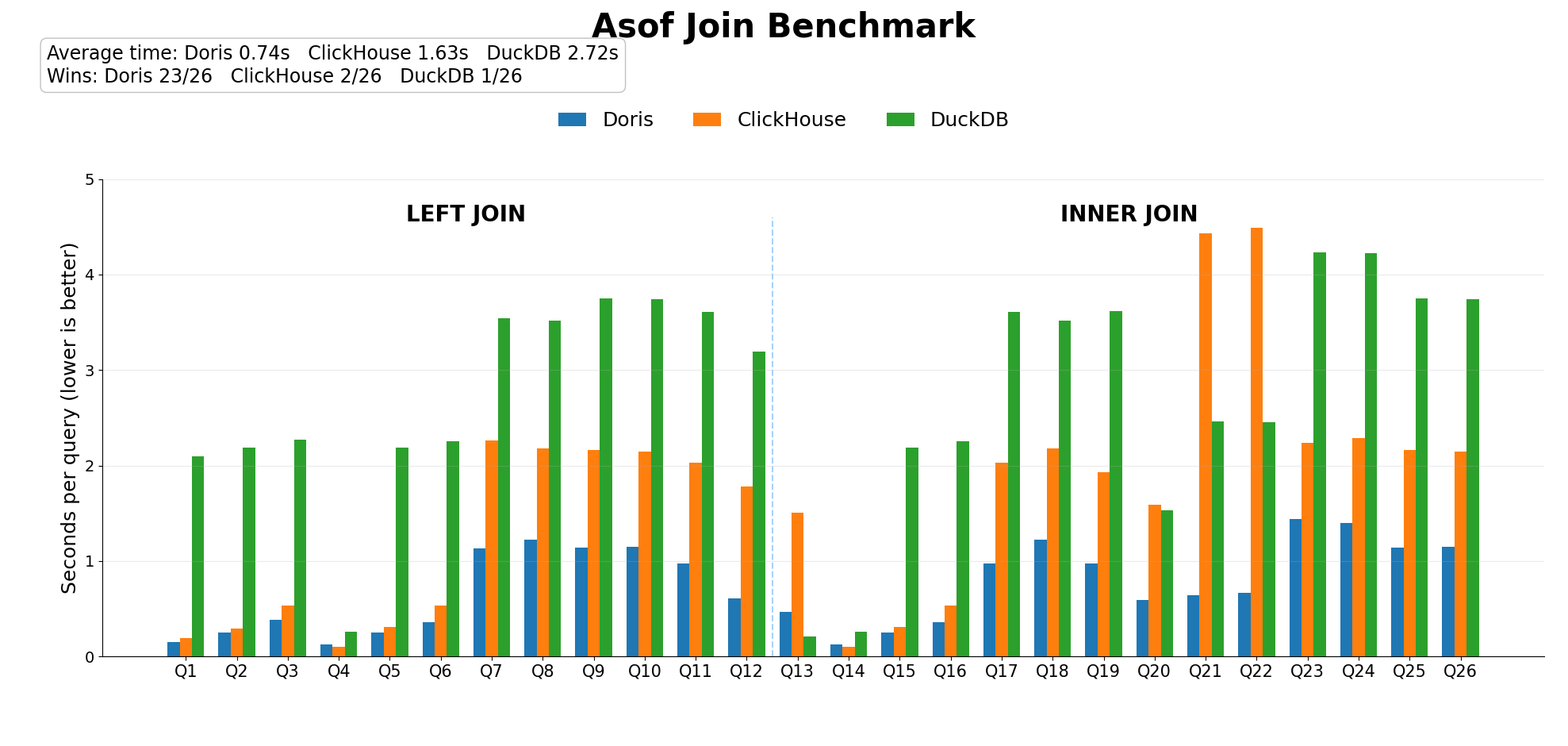
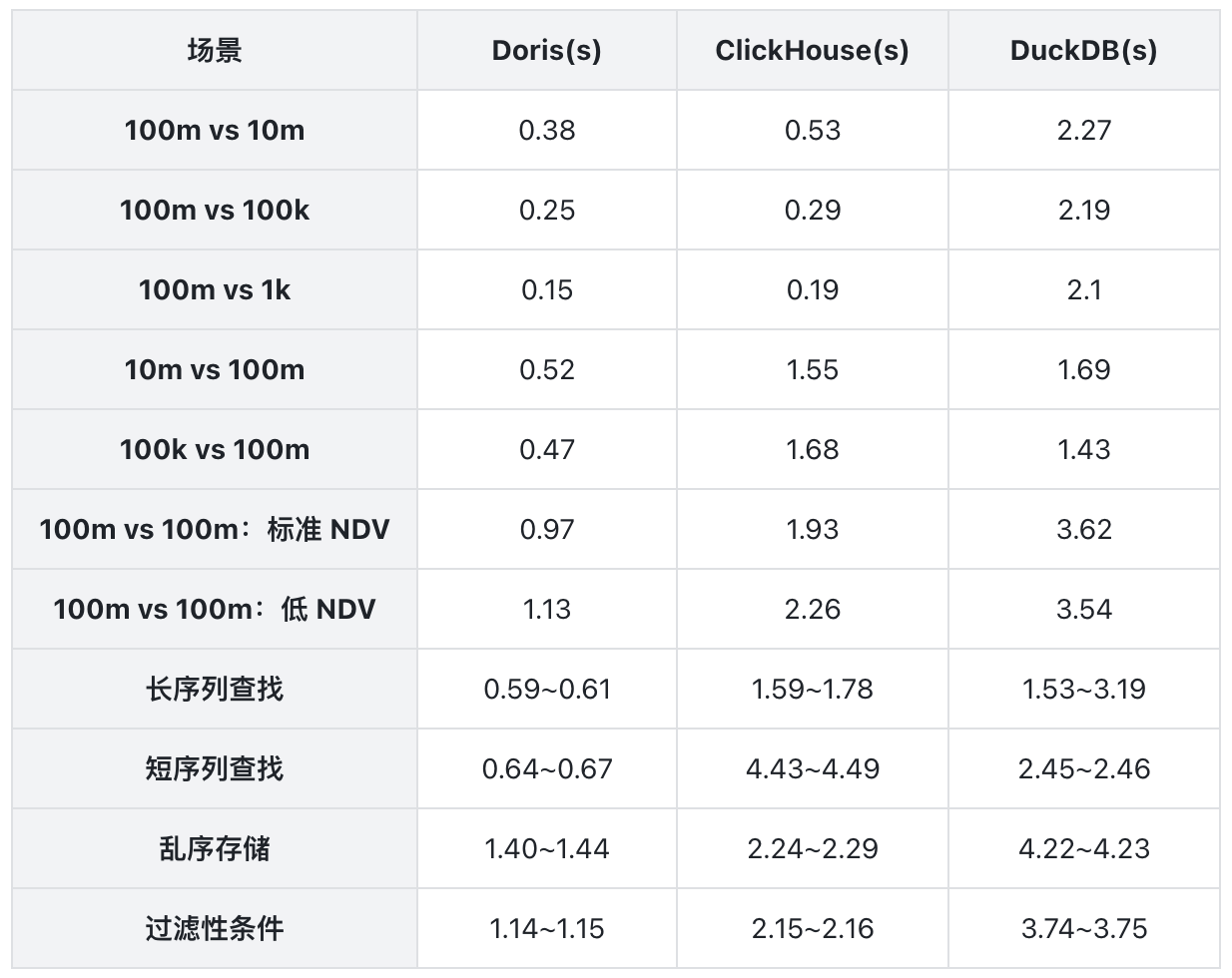
从数据上来看,Doris 在所有主流场景下都比 ClickHouse 更快,且在不少场景下优势接近 2 倍 ;相较 DuckDB,优势则更明显,很多场景能拉开到 3 倍以上。
可以说,Doris 的 ASOF JOIN 不是"某类数据碰巧跑得好",而是对时间序列近邻关联这件事本身不仅展现了卓越的性能,更显示了极高的稳定性。这与我们在实际客户场景中得到的结论相符。
接下来我们详细分析这些结果:
第一批结果:大小表 JOIN,最常见的业务形态下的领先
在很多真实业务里,左表往往是高频事实流,右表则是相对更小的参考序列。这是真实业务中 ASOF JOIN 最经典的使用方式,三组结果很能说明问题:
- 100m vs 10m:Doris 0.38s,ClickHouse 0.53s,DuckDB 2.27s
- 100m vs 100k:Doris 0.25s,ClickHouse 0.29s,DuckDB 2.19s
- 100m vs 1k:Doris 0.15s,ClickHouse 0.19s,DuckDB 2.10s
随着右表继续变小,Doris 的下降趋势非常自然,固有开销非常轻。这意味着 Doris 对高频探针、窄范围近邻查找的处理很成熟,能把典型业务里最常见的查询压到很低的延迟区间。
在交易补行情、订单补状态、事件补维表快照这类场景中,系统最怕的就是"每一行都要去右表深挖一遍"。Doris 的结果说明,它在这种主流模式下足够高效。对于业务侧来说,这意味着:
- 交互式分析更容易保持低延迟;
- 高频补全类查询更适合直接在线跑;
- ASOF JOIN 不再是一个只能离线慢慢算的重功能。
第二批结果:1 亿行对 1 亿行,大数据场景下的领先
前一类结果证明的是"常见业务形态下好用",那 1 亿行对 1 亿行的结果则说明:Doris 的 ASOF JOIN 能够真正能扛住大规模数据压力。
这一批测试区分了两种场景:
标准 NDV 场景
- 数据量 1 亿 vs 1 亿,两表 NDV = 10000:Doris 0.97s,ClickHouse 1.93s,DuckDB 3.62s
这是一个非常强的结果。在大规模双表关联中,Doris 能把查询控制在 1 秒以内,而对比系统明显更慢。这说明 Doris 的 ASOF JOIN 实现在规模上来之后,依然有很好的适应性。
低 NDV 场景
- 数据量 1 亿 vs 1 亿,两表 NDV = 100:Doris 1.13s,ClickHouse 2.26s,DuckDB 3.54s
低 NDV 往往意味着更大的分组压力、更集中的状态压力、更容易出现执行波动。Doris 在这里仍然保持稳定,说明它在面对"分组少、每组重"的情况下,性能更显卓越。
这对于生产环境非常重要,因为真实数据从来不是理想分布。一个能在 NDV 变化下依然稳定的系统,才可以考虑进入核心链路。
第三批结果:长序列、短序列、乱序、过滤......真实业务压力下的领先
很多性能宣传的"小窍门",就是只看"整齐表"上的结果,忽略真实业务中最难的部分。在这个 ASOF JOIN 的 Benchmark 中,我们专门考察了这些特殊情况下的性能表现:
长序列:时间链很长,但 Doris 仍然稳定
长序列场景下,右表每个 key 对应很长的时间轴,查询本身更接近真实的金融和监控业务。结果显示 Doris 维持在 0.59s~0.61s,而对比系统明显更慢。
这个结果说明 Doris 的能力不是"只适合短时间窗口",而是对长时间轴近邻查找同样成熟。
短序列:高离散、高稀疏,Doris 依旧快
短序列场景尤其能看出系统在稀疏分布下的表现。Doris 在 0.64s~0.67s,ClickHouse 在 4.43s~4.49s,DuckDB 在 2.45s 左右。
这类场景在实际业务里很常见,比如:
- 设备ID很多,但每个ID有效记录很少;
- 用户维度很散,每个实体只存在少量历史点;
- 大量单点式补全、稀疏式匹配。
Doris 在这里的表现说明,它不只是能处理"密集时间轴",也能很好地处理"稀疏时间轴"。
乱序存储:不是理想数据,照样能跑稳
乱序场景通常更接近真实落库状态。Doris 在乱序右表上仍然保持 1.40s~1.44s 的稳定结果,明显优于对比系统。这个结果的业务意义很强:它表明 Doris 的 ASOF JOIN 不依赖完美有序的数据输入,工程上更容易落地。
过滤条件:不只是连得上,还能连后筛得快
在加上过滤条件后,Doris 仍然维持在 1.14s~1.15s,说明它在"先过滤,再关联"的复合执行场景里也很稳。
这点对用户很重要,因为真实分析查询通常不会只做一次 JOIN,还会接着做筛选、聚合、统计。一个好的 ASOF JOIN 实现需要在更复杂的筛选中表现依然良好。
四、综合分析
综合来看,这套测试围绕着 ASOF JOIN 的核心业务难点形成了完整的覆盖:
- 数据量有大有小,验证不同规模组合;
- 有高 NDV 也有低 NDV,验证分组压力;
- 有长序列也有短序列,验证时间轴长度差异;
- 有乱序,也有过滤,验证真实业务复杂度;
- 有 LEFT JOIN,也有 INNER JOIN,验证常见语义路径。
可以相信,这套测试下的胜者,可以在追求高性能的真实业务中作为主要功能来使用,完全满足在实际业务中的需求。在初步的金融行业用户实际落地测试中,Doris 的 ASOF JOIN 完全满足了用户需求,给用户的分析任务带来了直接的价值。
五、结论:ASOF JOIN------Doris 在真实业务负载中可靠的能力
ASOF JOIN 是时间序列分析里非常关键的一类能力,但真正能把它做好、做稳、做快,并不容易。
Doris 这次给出的结果表明,它已经不是"支持一个新语义"这么简单,而是把这类时间近邻关联做成了一个成熟的高性能路径------性能领先不只在少数场景,而是覆盖了真实业务可能遇到的一切;优势不止在理想的"实验室数据"上成立,而是在大规模、复杂分布、真实形态下更加突出。
在 Apache Doris 4.0.5/4.1.0 中,ASOF JOIN 功能已经完整提供。您可以随时在官网下载部署 4.0/4.1 最新版本,跟随官网文档试用,体验 Apache Doris 的极致性能!使用当中遇到任何问题,欢迎到官方论坛进行反馈。