内容回顾
1、线程池
-
ThreadPoolExecutor七个参数
-
拒绝策略
-
线程池执行流程
-
为什么不使用Executors工具类?
2、多线程高并发底层原理
1、Java内存模型
- 可见性、有序性、原子性
2、volatile关键字
3、CAS
- 如何保证原子性?
4、AQS
5、juc并行操作
今天内容
1、MySQL前置知识
Linux安装MySQL
//第一步 拉取镜像
docker pull 镜像名称:版本号
//第二步 容器启动
docker run .....
docker run -d \
-p 3309:3306 \
-v /atguigu/mysql/mysql8/conf:/etc/mysql/conf.d \
-v /atguigu/mysql/mysql8/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name atguigu-mysql8 \
--restart=always \
mysql:8.0.29MySQL字符集
-
MySQL8开始默认字符串utf8
-
utf8分为两种:uft8mb3 和 utf8mb4
-- utf8mb3只使用1~3个字节表示字符
-- utf8mb4只使用1~4个字节表示字符,可以存储表情图标
sql_mode
- 规定sql语句中一些规范
-- ONLY_FULL_GROUP_BY:要求在编写分组语句时候遵循一定规范
---- 编写分组语句时候,select后面只能出现分组字段和聚合函数
- 举例演示 分组规则
CREATE DATABASE atguigudb;
USE atguigudb;
CREATE TABLE employee(id INT, `name` VARCHAR(16),age INT,dept INT);
INSERT INTO employee VALUES(1,'zhang3',33,101);
INSERT INTO employee VALUES(2,'li4',34,101);
INSERT INTO employee VALUES(3,'wang5',34,102);
INSERT INTO employee VALUES(4,'zhao6',34,102);
INSERT INTO employee VALUES(5,'tian7',36,102);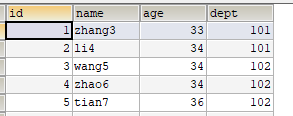
- 查询每个部门年龄最大的人的姓名
# 这个语句不正确的,因为出现name字段
SELECT dept,MAX(age),`name`
FROM employee
GROUP BY dept-
上面语句执行结果不正确,因为没有满足ONLY_FULL_GROUP_BY规则,在select后面出现了name字段,name字段不是分组字段,也不是聚合函数
-
通过临时表方式编写正确语句
select maxage.dept,maxage.mage,e.name
from employee e
inner join
(select dept,max(age) as mage from employee group by dept) AS maxage
on maxage.dept= e.dept and maxage.mage=e.age2、逻辑架构
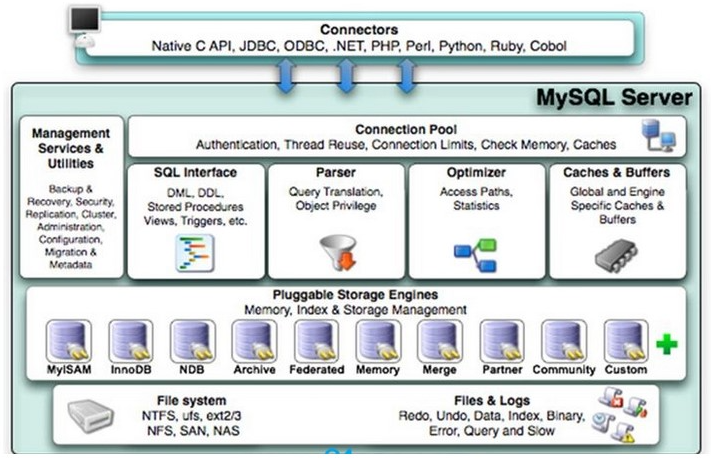
逻辑架构
-
连接mysql服务(JDBC等),使用连接池
-
检查是否具备操作权限(比如是否有权限操作数据库,或者操作某个表等等)
-
把sql语句进行分类,比如DML、DDL等,在SQL Interface有不同类型对应操作接口,把sql语句放到对应接口里面
-
把sql语句分类并且放到对应接口里面之后,首先对sql语句进行解析,使用Parser完成,解析成树形结构
-
如果当前语句是查询语句,使用优化器Optimizer对查询语句进行优化,生成执行计划
-
使用存储引擎Storage Engines按照生成执行计划,发起执行请求
-
请求存储文件系统,按照要求返回数据
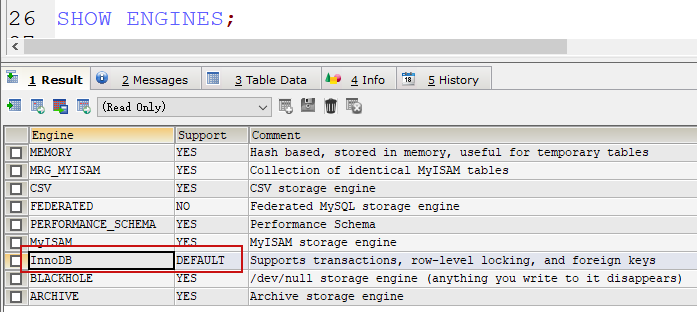
存储引擎
-
MySQL默认存储引擎 InnoDB
-
InnoDB存储引擎支持事务、使用行锁、支持外键
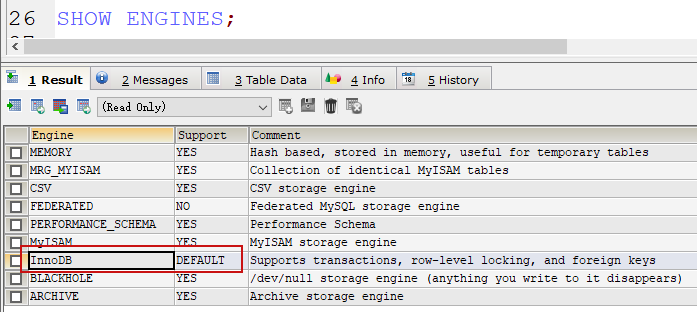
- InnoDB和MyISAM区别
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 表锁,即使操作一条记录也会锁住整个表,不适合高并发的操作 | 行锁,操作时只锁某一行,不对其它行有影响,适合高并发的操作 |
3、SQL语句编写
关联查询七种情况
-
UNION(合并并去重)
-
UNION ALL(合并,没有去重)
练习
# 需求1:查询各个门派对应的掌门人
#华山 岳不群
#丐帮 洪七公
#峨眉 灭绝师太
select d.deptName,e.name,e.age
from t_dept d
left join t_emp e on d.CEO=e.id
# 需求2:查询所有掌门人的平均年龄
select avg(e.age)
from t_dept d
inner join t_emp e on d.CEO=e.id
# **需求3:查询所有人物对应的掌门名称
#风清扬 岳不群
#岳不群 岳不群
#令狐冲 岳不群
#洪七公 洪七公
select de.name,e.name
from t_emp e
inner join
(select e.name,d.CEO from t_emp e
inner join t_dept d on e.deptId=d.id) as de
on de.CEO=e.id
##
SELECT emp.name, ceo.name AS ceoname
FROM t_emp emp
LEFT JOIN t_dept dept ON emp.deptid = dept.id
LEFT JOIN t_emp ceo ON dept.ceo = ceo.id;4、MySQL索引(★)
什么是索引
- 索引(Index)是帮助MySQL高效获取数据的数据结构。
- 索引优点和缺点
-- 优点:减低IO次数,提高效率
-- 缺点:占用空间,维护成本高
- 索引分类
-
从功能逻辑上划分,索引主要有 4 种,分别是
普通索引、唯一索引、主键索引。 -
按照作用字段个数划分,索引可以分为
单列索引和联合索引。 -
按照物理实现方式划分 ,索引可以分为 2 种,分别是
聚簇索引和非聚簇索引。
MySQL索引树结构
二叉树
- 每个节点
最多只能有两个子节点的一种形式称为二叉树。二叉树的子节点分为左节点和右节点
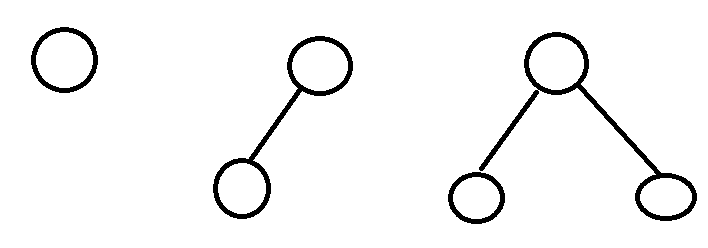
二叉搜索树BST
- 要求左子节点的值比当前节点的值小,右子节点的值比当前节点的值大。
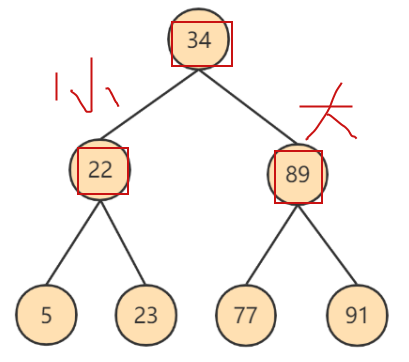
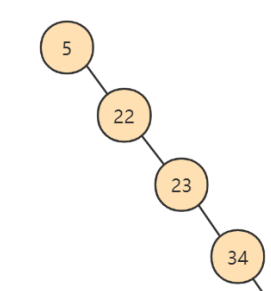
- 二叉搜索树有缺陷:
-- 如果只有左节点,或者只有右接口,再查询没有优势
平衡二叉树(AVL)
-
它是一棵空树或它的左右两个子树的高度差的绝对值不超过1
-
并且左右两个子树都是一棵平衡二叉树。
-
最终目的减少io次
-
每个节点经过一次io,树的高度越高io次数越多,只需要降低树高度,io次数也就减少了
-
在平衡二叉树基础之上降低树高度,提高效率,减少io次数
-
平衡二叉树 变成 多叉树
B树
-
B树,Balance Tree,平衡树,B树就是典型的多叉树,它的高度远小于平衡二叉树的高度。
-
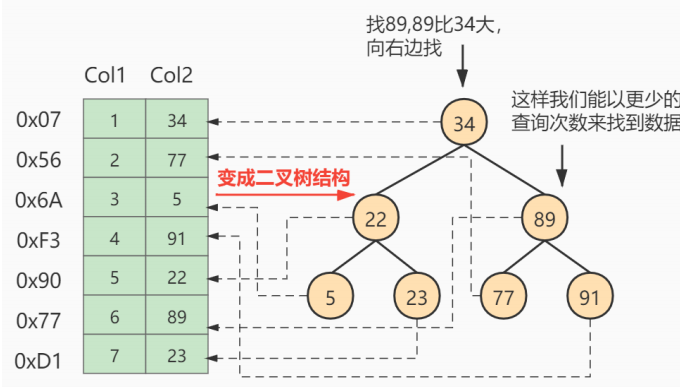
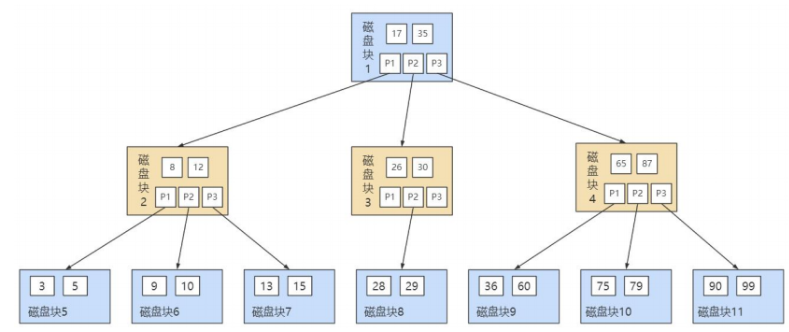
看图总结1:
B树结构中包含很多磁盘块(节点),每个磁盘块默认大小16kb
每个磁盘块(节点)包含多个(主键)索引值和指向下一个节点指针
满足二叉搜索树规则
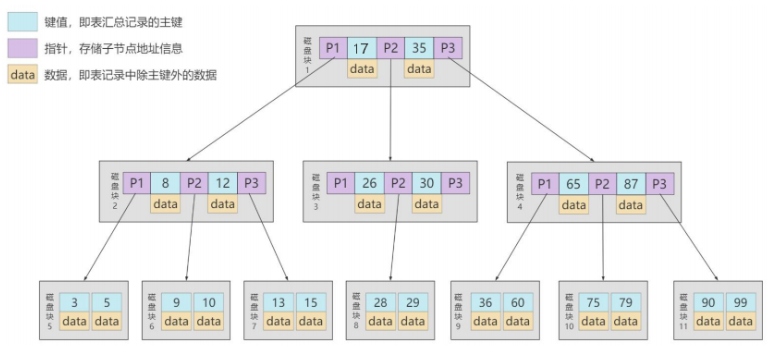
- 看图总结2
B树结构中包含很多磁盘块(节点),每个磁盘块默认大小16kb
每个磁盘块包含多个主键值,指向下一个节点指针和主键以外其他数据
非叶子节点和叶子节点包含多个主键值和主键以外其他数据
B+树
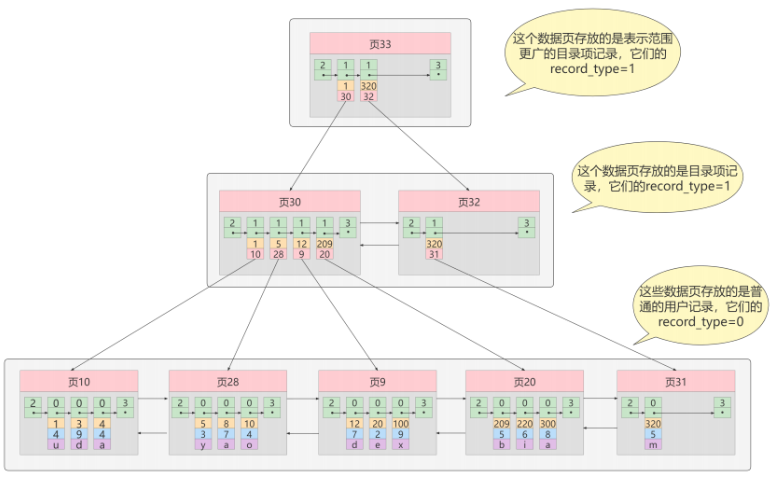
B+ 树和 B 树的差异:
-
B+树中非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中
-
而B树中, 非叶子节点既保存索引,也保存数据记录 。
-
B+树中所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大小从小到大顺序链接。
-
B+树中非叶子节点的关键字也会同时存在于子节点中,并且是在子节点中所有关键字的最小值。
聚簇索引
- 对主键创建索引,根据主键进行查询,就是聚簇索引
非聚簇索引
-
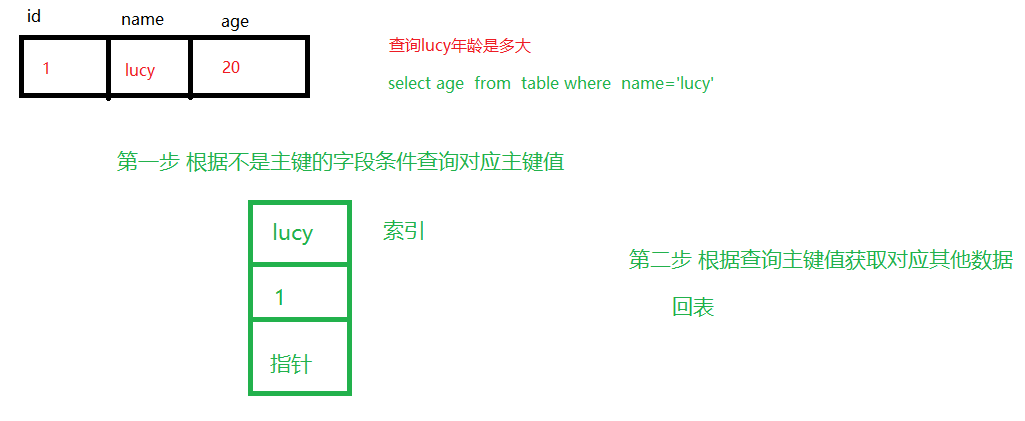
对不是主键的字段创建索引,把不是主键字段作为条件进行查询,使用非聚簇索引
-
非聚簇索引查询过程:
第一步 根据不是主键的字段条件查询对应主键值
第二步 根据查询主键值获取对应其他数据(回表)
覆盖索引
如果能通过读取索引就可以得到想要的数据,那就不需要读取用户记录,或者不用再做回表操作了。
通俗:查询字段就是索引字段
