一、简介
Fbank(滤波器组能量特征)和MFCC(梅尔频率倒谱系数)是语音识别中最核心的声学特征提取方法,二者均通过模拟人耳非线性听觉特性处理语音信号。Fbank直接输出梅尔滤波器组的能量值,而MFCC在Fbank基础上增加对数压缩和离散余弦变换(DCT),进一步降维并去除特征相关性。现代语音识别系统中,Fbank因保留更多频谱细节更适用于深度学习模型(如CNN/RNN),而MFCC因维度低、相关性弱传统上更适合GMM-HMM系统。
原始语音 → 预加重→ 分帧加窗 → FFT → Mel 滤波器组 → 取对数 → 【FBank 特征 80 维】
↓ 继续
DCT 去相关 → 取前 N 维 → 【MFCC 特征】一张图解释fbank和MFCC的计算来源
这里不讲原理公式,只梳理下每个步骤的作用和输出维度,方便后续语音处理的理解,因为现在的语音模型基本离不开这些处理。
| 序号 | 步骤名称 | 核心原理 | 关键作用 | 适用场景 |
|---|---|---|---|---|
| 1 | 预加重 | 一阶高通滤波,补偿声门激励、口鼻辐射造成的高频衰减 | 提升高频信噪比、平衡频谱平坦度 | FBANK、MFCC 通用前置 |
| 2 | 分帧加窗 | 把非平稳语音切分为 20~30ms 短时平稳帧,帧移 10~15ms;汉明窗抑制频谱泄漏 | 保证短时平稳性、稳定时频分析、弱化帧边界突变干扰 | FBANK、MFCC 通用前置 |
| 3 | FFT 变换 | 加窗时域信号转复数频谱,舍弃相位、仅保留幅度谱 | 完成时域转频域,为人耳不敏感相位做舍弃,奠定频带分析基础 | FBANK、MFCC 通用前置 |
| 4 | Mel 滤波器组 | 20~80 个非均匀三角滤波器,低频密集、高频稀疏,线性频谱映射到 Mel 人耳感知尺度 | 贴合人耳非线性听觉特性,突出语音共振峰结构 | FBANK、MFCC 通用核心步骤 |
| 5 | 取对数 | 遵循韦伯 - 费希纳定律,对 Mel 能量做对数压缩 | 压缩能量动态范围,模拟人耳响度感知,增强弱语音成分表征 | FBANK、MFCC 通用步骤 |
| 6 | FBank 特征 (80 维) | 直接输出对数梅尔滤波器组能量,保留频带间相关性 | 完整保留频谱局部关联特征 | 深度学习:Whisper、Conformer、Wav2Vec、TTS 等 |
| 7 | DCT 去相关 | 对对数梅尔谱做离散余弦变换,解耦相关频带能量 | 去除特征相关性,集中提取声道形状低阶倒谱信息 | MFCC 专属步骤 |
| 8 | MFCC 特征 | 截取 DCT 前 12~13 维低阶系数,舍弃高阶噪声分量 | 表征声道共振峰轮廓,满足传统模型特征独立假设 | 传统模型:GMM-HMM、早期 DNN-HMM、嵌入式轻量语音算法 |
1.1 示例代码:
pip install librosa numpy
import numpy as np
import librosa
# ===================== 固定配置 =====================
target_sr = 16000 # 目标采样率 16kHz
pre_emph_coeff = 0.97 # 预加重系数
frame_ms = 25 # 帧长 25ms
hop_ms = 10 # 帧移 10ms
n_fft = 512 # FFT 点数
n_mels = 80 # FBank 80维
n_mfcc = 13 # MFCC 取前13维
# 计算帧长/帧移的采样点数
frame_len = int(target_sr * frame_ms / 1000)
hop_len = int(target_sr * hop_ms / 1000)
# ===================== 0. 加载语音 + 重采样到 16kHz =====================
wav_path = "test.wav" # 你的音频路径
sig, original_sr = librosa.load(wav_path, sr=None) # 不自动重采样
# 重采样到 16kHz(不管输入是 8k/32k/44k/48k,全部转 16k)
sig_resample = librosa.resample(sig, orig_sr=original_sr, target_sr=target_sr)
print(f"原始采样率: {original_sr} Hz → 重采样到 {target_sr} Hz")
print(f"0.重采样后信号 shape: {sig_resample.shape}")
# ===================== 1. 预加重 =====================
def pre_emphasis(signal, alpha=0.97):
return np.append(signal[0], signal[1:] - alpha * signal[:-1])
sig_pre = pre_emphasis(sig_resample, pre_emph_coeff)
print("1.预加重后 shape:", sig_pre.shape)
# ===================== 2. 分帧 + 汉明窗 =====================
def framing_and_window(signal, frame_len, hop_len):
num_frames = int(np.ceil((len(signal) - frame_len) / hop_len))
frames = np.zeros((num_frames, frame_len))
for i in range(num_frames):
start = i * hop_len
end = start + frame_len
frames[i] = signal[start:end]
ham_win = np.hamming(frame_len)
frames_win = frames * ham_win
return frames_win
frames_win = framing_and_window(sig_pre, frame_len, hop_len)
print("2.分帧加窗后 shape (帧数, 每帧点数):", frames_win.shape)
# ===================== 3. FFT → 幅度/功率谱 =====================
def stft_pow_spec(frames, n_fft):
fft_res = np.fft.fft(frames, n=n_fft)
mag_spec = np.abs(fft_res)
pow_spec = (mag_spec ** 2) / n_fft
return pow_spec[:, :n_fft//2 + 1] # 取前半频段
pow_spec = stft_pow_spec(frames_win, n_fft)
print("3.FFT功率谱 shape (帧数, 频点):", pow_spec.shape)
# ===================== 4. Mel 滤波器组 =====================
mel_filter = librosa.filters.mel(sr=target_sr, n_fft=n_fft, n_mels=n_mels)
mel_energy = np.dot(pow_spec, mel_filter.T)
print("4.Mel滤波后 shape (帧数, mel维):", mel_energy.shape)
# ===================== 5. 取对数 =====================
log_mel = np.log(mel_energy + 1e-8)
print("5.对数Mel后 shape:", log_mel.shape)
# ===================== 6. FBank 80维 完成 =====================
fbank = log_mel
print("6.最终FBank特征 shape (帧数, 80维):", fbank.shape)
# ===================== 7. DCT 去相关 =====================
dct_feat = librosa.feature.dct(log_mel.T, n_mfcc=n_mfcc).T
print("7.DCT变换后 shape:", dct_feat.shape)
# ===================== 8. MFCC 13维 完成 =====================
mfcc = dct_feat
print("8.最终MFCC特征 shape (帧数, 13维):", mfcc.shape)二、原始语音信息
我们这里使用采样率:16hz,16bit 单声道 PCM。
这里以1秒的语音,1秒的语音数据大概32000byte。
公式如下:
字节率 (Byte/s) = 采样率 × 位深 ÷ 8 × 声道数然后1ms大概32byte 具体如下:
16000×16÷8×1=32000 Byte/秒 = 32 Byte/毫秒
由于是16bit,那么存储为int16 ,大概数组为 1秒为 数组 int16【1600】

这里输出int16【16000】
三、预加重
通过一阶高通滤波补偿声门激励和口鼻辐射导致的高频衰减,提升高频信噪比并平衡频谱平坦度。
语音产生时声带辐射导致高频能量自然衰减,而人耳对高频变化更敏感,此步骤可平衡频谱平坦度,提升信噪比(SNR),并减少后续FFT的数值计算误差。
效果:高频共振峰(如元音谐波)能量显著增强,对区分音素至关重要
公式:
y[n]=x[n]-a·x[n-1]a通常取0.95~0.97,这里取0.97

这里把int16 转换为float32 ,这里需要精度处理,所以用float存储
这里把int16【16000】 转换为 float32 【16000】
1ms为float32【16】
输出:float32 【16000】
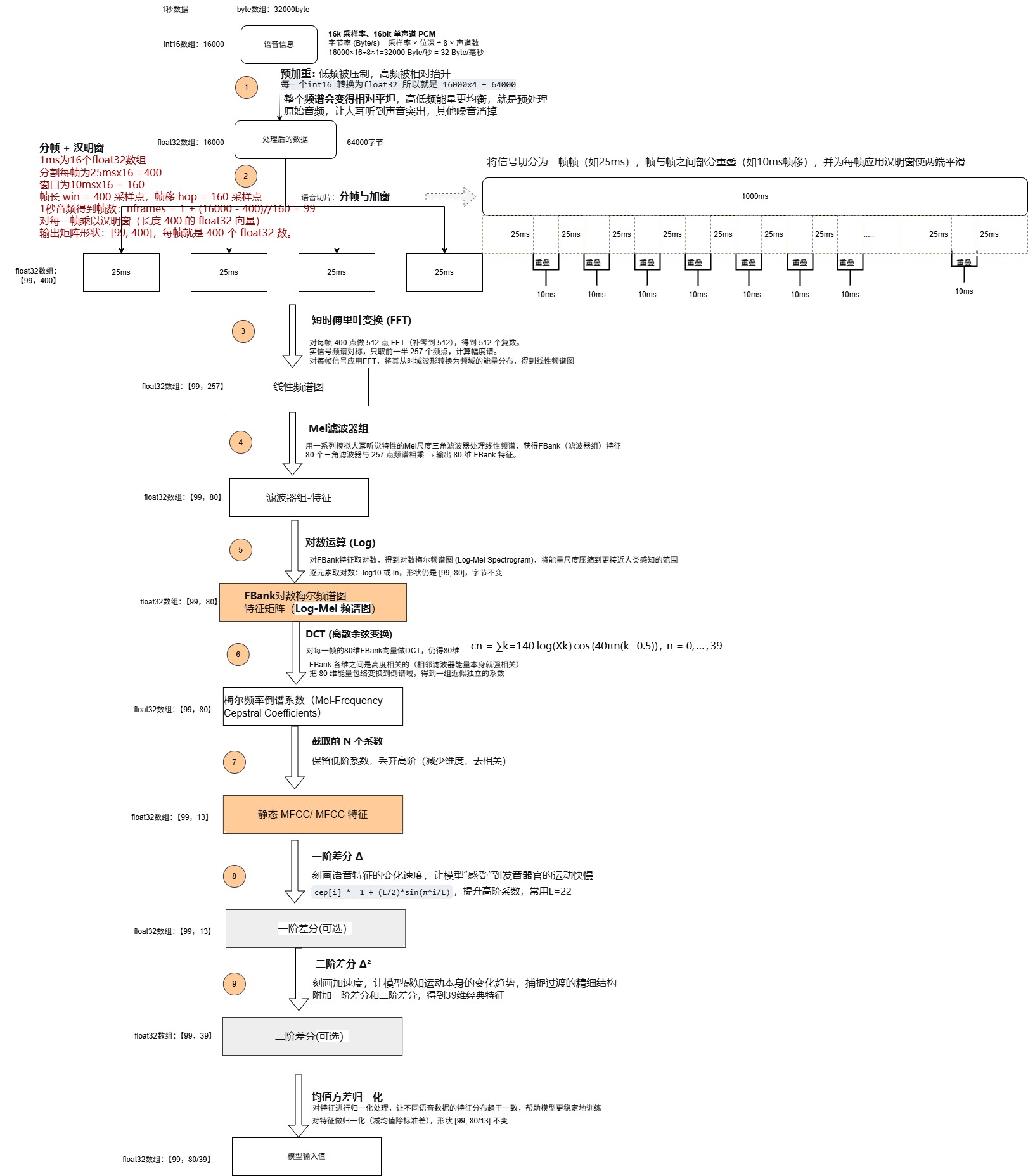
四、分帧和加窗
将非平稳语音切分为20--30ms短时平稳片段 (帧移10--15ms),并用汉明窗抑制帧边界频谱泄漏,确保时频分析稳定性。
分帧:
- 作用 :将非平稳语音信号切分为短时平稳的帧 (通常20~30ms,帧移10ms)。因语音在短时间内可视为平稳信号,短时分析能有效捕捉动态声学特性。
- 关键参数:以16kHz采样率为例,25ms帧长对应400个采样点,10ms帧移确保相邻帧重叠50%,避免信息丢失。
加窗:
- 作用 :对每帧施加汉明窗(Hamming Window)等平滑窗函数 ,抑制分帧导致的频谱泄漏。窗函数使帧边界平滑过渡,减少FFT后的旁瓣干扰。
- 关键效果:矩形窗旁瓣高易引发频谱混叠,汉明窗主瓣较宽但旁瓣显著降低,更适合语音频谱分析。
1ms为16个float32数组
分割每帧为25msx16 =400
窗口为10msx16 = 160
帧长 win = 400 采样点,帧移 hop = 160 采样点
1秒音频得到帧数:nframes = 1 + (16000 - 400)//160 = 99
对每一帧乘以汉明窗/汉宁窗(长度 400 的 float32 向量)
输出矩阵形状:99, 400,每帧就是 400 个 float32 数。
这里输出:float32 【99,400】
五、短时傅里叶变换(FFT)
将加窗后时域信号转换为复数频谱 ,仅保留幅度谱(因人耳对相位不敏感),为后续频带分析提供基础。
它把一帧帧摸不着头脑的波形,变成一张张看得清"嗓音成分"的频谱图
- 作用 :对加窗后的帧进行FFT转换至频域 ,得到线性频率的功率谱( ∣X(k)∣2∣X(k)∣2 )。将时域信号映射为可分析的频谱能量分布。
- 关键效果:保留幅度信息而舍弃相位(语音识别对相位不敏感),为后续非线性频率映射奠定基础。
FFT 的作用是将"时间-幅度"的波形帧变换为"频率-能量"的频谱,让隐藏在波形里的频率成分显形,为后续模拟人耳听觉的 Mel 滤波提供标准线性频谱,是整个语音特征提取中"从听感波形到可见纹理"的关键一步。

对每帧 400 点做 512 点 FFT(补零到 512),得到 512 个复数。
实信号频谱对称,只取前一半 257 个频点,计算幅度谱。
对每帧信号应用FFT,将其从时域波形转换为频域的能量分布,得到线性频谱图
输出为float32 【99,257】
六、Mel滤波器组
通过20--80个非均匀三角滤波器 (低频密、高频疏),将线性频谱映射至符合人耳非线性感知的Mel尺度,突出共振峰结构。
梅尔滤波器组 是语音特征提取中连接"线性频谱"与"人耳听觉"的关键桥梁。它把 FFT 输出的精细线性频谱(成百上千个频点)压缩、变形为更符合人类听觉感知的梅尔频谱,最终得到 FBank 特征。
它就是一组按照人耳听觉非线性尺度排列的三角带通滤波器,它能将线性的 Hz 频谱"揉"成低频分辨率高、高频分辨率低的梅尔频谱,模拟人耳对音高的感知特性。

用一系列模拟人耳听觉特性的Mel尺度三角滤波器处理线性频谱,获得FBank(滤波器组)特征
80 个三角滤波器与 257 点频谱相乘 → 输出 80 维 FBank 特征。
输出float32 【99,80】
七、对数运算 (Log)-》Fbank
对数运算在 FBank 特征提取中,是连接"物理能量"与"人耳响度感知"的最后一步转换。它不只是简单的数学压缩,更是为了让特征符合听觉规律,并为后续的模型处理创造更好的数值条件。
Fbank: 直接输出对数梅尔滤波器组能量 ,保留完整的频带相关性,适用于深度学习模型(如RNN/Transformer),因其能显式建模频谱局部模式。
人耳对声音响度的感知不是线性的,而是近似对数关系:
-
声强(物理能量)需要增加到原来的 10 倍,我们听起来才感觉响了大约 2 倍(一个"贝尔"的差异)。
-
这意味着,物理上巨大的能量差异(比如 1000 倍),在人耳感知中只是几个"档位"的变化。
梅尔滤波器组输出的每个值 S[m] 是该频带的物理能量(或功率),单位是线性尺度。直接使用它们有两个问题:
-
不符合听觉特性:模型应该去模仿人耳听到的"响度关系",而不是物理能量本身。
-
数值动态范围巨大:从安静帧(能量接近 0)到响亮元音(能量可达 10⁶~10⁷),跨度可达多个数量级。如果不压缩,后续处理(如神经网络)会面临严重的梯度问题,特征中的弱能量细节会被大能量完全淹没。
取对数后:
-
能量比变成差值:比如两倍能量变成长数上的
log(2)的差距,符合了"响度感知"。 -
动态范围被强烈压缩:1000 倍的差异压缩成
log(1000) ≈ 7个单位。安静帧的微弱信息(比如辅音的高频能量)得以在数值上与响亮元音共存,不会被"压碎"。
对数运算把物理能量按照人耳感知的对数规律进行压缩,让特征的数值范围变得可控,同时让不同响度级别的声音信息公平地呈现在特征中,使模型能同时"看到"嘹亮元音和微弱辅音。

这里这步就取到了Fbank
输出:float32 【99,80】
八、DCT (离散余弦变换)
对对数梅尔谱执行离散余弦变换(DCT) ,将相关频带能量解耦为去相关的倒谱系数,集中表征声道形状的低阶信息。
离散余弦变换(DCT) 是 MFCC 提取过程中最关键的一步,它把"符合人耳感知"的 FBank 特征,进一步加工成"符合传统模型需求"的紧凑倒谱表示。
梅尔滤波器组输出的 80 维 FBank 虽然很好地模拟了听觉频率尺度,但它有一个"缺点":相邻滤波器之间有很高的相关性。
-
因为三角滤波器相互交叠,相邻频带的能量往往是联动的,这导致 FBank 向量各维之间高度相关。
-
传统的 高斯混合模型(GMM) 假设特征向量的各维独立(对角协方差),直接使用 FBank 会违反这个假设,导致建模困难。
-
即使神经网络没有独立性假设,高度相关的特征也会增加冗余,降低训练效率。
DCT 的作用就是对这种相关特征进行正交变换,把能量集中到少数几个系数上,实现:
-
去相关:变换后系数近似统计独立。
-
能量压缩:大部分信号信息集中在低阶系数,高阶系数接近于零。
-
降维:截取前 13~20 个系数,丢弃高阶系数,大幅压缩特征维度。
这就像把一团乱麻的相关信息,梳理成少数几根承载主要信息的"主成分"。
Ck=∑m=079Em⋅cos(80πk(m+0.5)),k=0,1,...,79
DCT 是 MFCC 的灵魂步骤,它将高度相关的对数梅尔谱变换到倒谱域,实现去相关和能量压缩,用低阶系数概括声道形状,用高阶系数承载激励细节。截取低阶倒谱后,就得到紧凑且独立的特征向量,完美适配传统 GMM‑HMM 声学模型的对角协方差假设,也成为语音识别史上最重要的特征设计之一。

输出数组:float32【99,80】
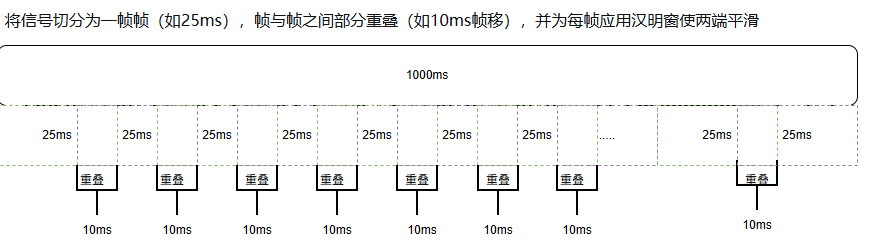
九、截取前 N 个系数->MFCC
"截取前 N 个系数" 是 MFCC 特征从"全信息倒谱"到"紧凑声学表示"的决定性裁剪。它凭借一个简单的截断操作,完成降维、去噪、提取音色三合一的功能。
经过 DCT 后,每一帧语音得到一个 80 维的向量 [C₀, C₁, C₂, ..., C₇₉],这些系数按阶数从低到高排列。截取前 N 个系数(通常 N=13)就是:
保留 C₀ 到 C₁₂(共 13 个系数)
丢弃 C₁₃ 到 C₇₉(其余 67 个系数)
此时得到的 [帧数, 13] 矩阵,就是 静态 MFCC 特征。
"截取前 N 个系数"是在倒谱域做了一次分离:保留承载音色的低阶共振峰包络,丢弃混入噪声和激励细节的高阶成分,得到维度低、信息密、抗噪性好的静态 MFCC 特征,为传统语音识别模型提供了一组精心设计的、近乎最优的声学表示。
输出 float32 【99,13】
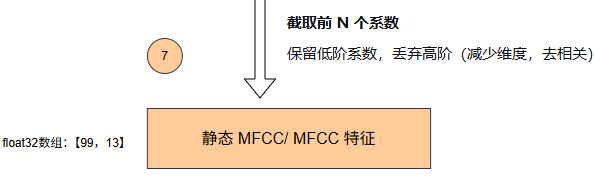
十、【可选】 动态特征**(Δ 和 Δ²)**
动态特征(Δ 和 Δ²) 是传统语音识别中为静态 MFCC 注入"时间生命"的关键操作。它们把一帧帧孤立的声道快照,变成携带发音动作速度 与加速度的完整动态描述,让模型能"听"出语音是如何从"b"滑到"a"的
静态 MFCC 描述的是某一瞬间声道截面的形状,如同给你的发音器官拍了一张张快照。但语音的本质是动态的过渡过程:
-
辅音 /b/ 和 /p/ 在成阻阶段的静态频谱几乎一样,区别全在于除阻后声带开始振动的时机和速度。
-
元音 /i/ 到 /a/ 的滑动,核心信息隐藏在共振峰如何随时间移动的轨迹里。
只给模型看静态照片,它无法区分这些动态音素。Δ 和 Δ² 给模型装上了一双"眼睛",让它看到画面之间的运动和运动的变化。
其他好处:
-
抗噪:整体幅度偏移(如距离远近)对差分影响较小,动态特征对信道、背景噪声有一定鲁棒性。
-
提供时序上下文:每一帧的 Δ 融合了前后 MM 帧的信息,变相扩展了模型的视野,弥补早期 HMM 条件独立性假设的不足。
动态特征 Δ 和 Δ² 将静态的 MFCC 照片连成了一段动画:Δ 给出发音动作的速度,Δ² 给出加速度,三者结合让模型不仅能识别"是什么",还能捕捉"怎么变",从而大幅提升对辅音、过渡音和协同发音的区分能力,是传统语音识别系统能够成功的核心工程设计之一。
后续就是可以给模型进行训练了,具体看什么模型,看选择的是MFCC还是 FBank
十一、代表模型和使用的特征类型
| 特征类型 | 代表模型 | 维度(每帧) | 现状 |
|---|---|---|---|
| MFCC + 差分 | GMM‑HMM、早期 DNN | 39 | 淘汰 |
| FBANK(Log‑Mel) | Whisper、Wav2Vec、Conformer、Tacotron | 40/80 | 主流 |
| 原始波形 | WaveNet、ECAPA‑TDNN、SpeechLM | 1(时域) | 上升 |
| 离散 Speech Tokens | HuBERT、SpeechLM、AudioPaLM | 1(token ID) | 大模型专用 |
| PLP | 传统 ASR | 13/39 | 小众 |
- 做现代 ASR/TTS :优先用 80 维 FBANK,不用 MFCC、不用手工差分。
- 做传统 / 嵌入式 :用 39 维 MFCC + 差分。
- 做语音大模型 / 声纹 :可用原始波形 或离散 tokens。
简言之:MFCC已退出主流研究视野,Fbank是当前深度学习语音模型的基石