Multi-Agent 从概念到落地:多智能体协作的底层逻辑与实战
当单个 LLM 不够用时,让多个 Agent 组队干活是自然的选择------但这支"AI 团队"该怎么管?
一、引言
2024 年以来,LLM 的能力边界被不断推高,但一个现实逐渐浮出水面:单靠一个模型解决复杂问题,天花板很明显。于是 Multi-Agent(多智能体)成为了行业热词。你打开任何一个 AI 开发者社区,满屏都是"我用 CrewAI 搭了个多 Agent 系统"、"LangGraph 多智能体编排实战"。
但热潮之下,有几个根本问题值得冷静思考:
- Multi-Agent 到底解决了什么问题?单 Agent 做不到吗?
- 多 Agent 之间怎么"配合"?有哪些经典架构模式?
- 什么情况下你不应该用 Multi-Agent?
这篇文章的目标是:帮你建立 Multi-Agent 的系统性认知,知道什么时候该用、怎么用、以及什么时候坚决不用。
读完你会获得:
- 对 Multi-Agent 核心价值的清晰理解
- 4 种主流架构模式的对比和选型指南
- 一个可直接运行的最小化 Multi-Agent 示例
- 避坑指南
二、为什么需要 Multi-Agent?
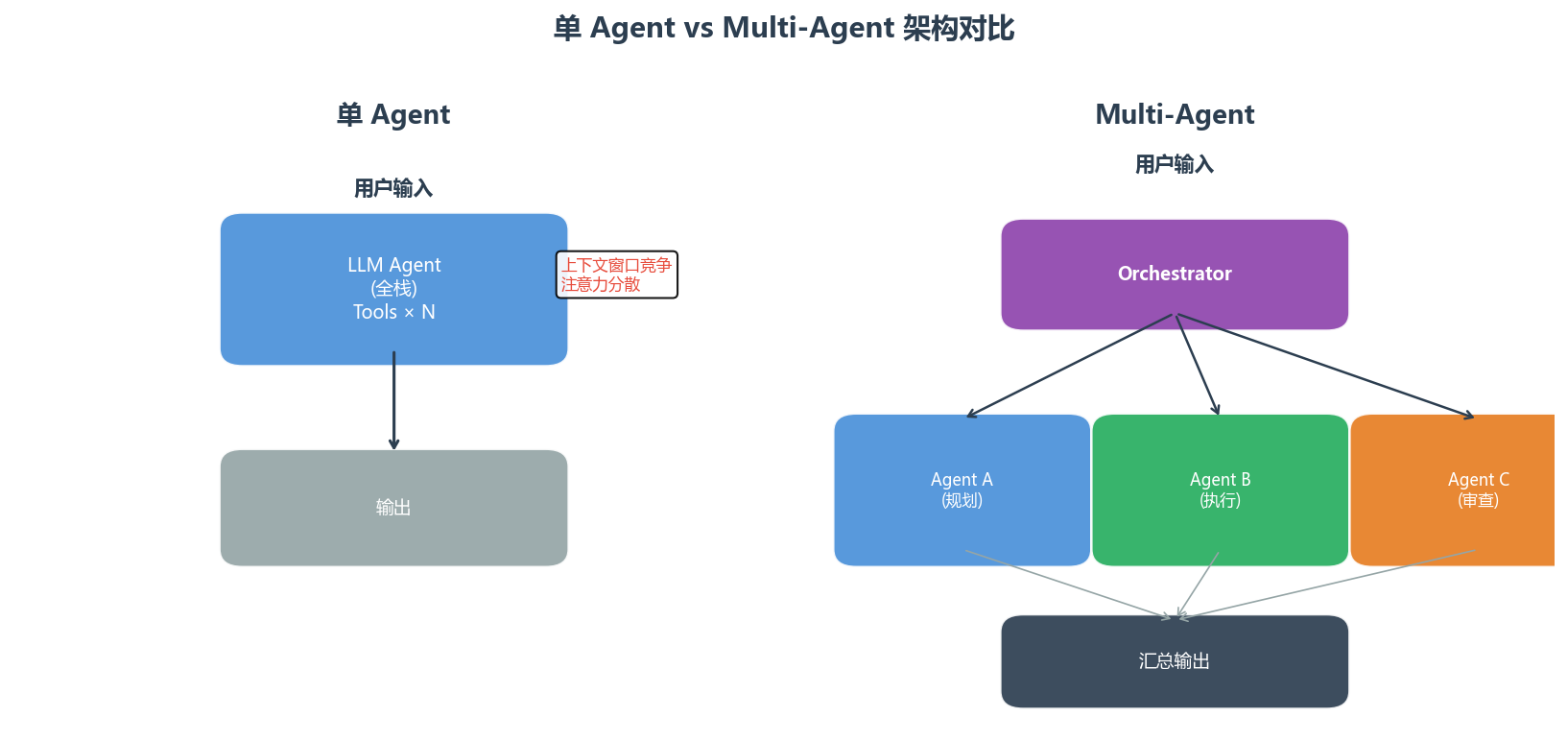
2.1 单 Agent 的天然局限
一个典型的单 Agent 系统长这样:
用户输入 → Agent(LLM + Tools)→ 输出Agent 拥有推理能力,可以调用工具,可以记忆上下文。这在很多场景下已经足够好用。但当任务复杂度达到一定程度时,问题出现了:
问题一:上下文窗口竞争。 你把所有指令、工具描述、Few-shot 示例、历史对话全塞进上下文,Agent 开始"注意力涣散"------它对长上下文中部的信息提取能力明显下降。
问题二:能力冲突。 同一个 Agent 既要写代码又要审查代码,既要做创意又要做批判------这两种思维模式在同一个提示词里互相打架。
问题三:单点故障。 一个 Agent 的推理错误可能导致整个任务失败,没有"第二意见"机制。
问题四:串行瓶颈。 很多子任务本来可以并行,但单 Agent 只能一步一步来。
2.2 Multi-Agent 如何解决这些问题
Multi-Agent 的核心思想很简单:各司其职,协作共赢。
| 痛点 | Multi-Agent 方案 |
|---|---|
| 上下文竞争 | 每个 Agent 只加载相关上下文 |
| 能力冲突 | 不同 Agent 承担不同角色 |
| 单点故障 | 多个 Agent 交叉验证 |
| 串行瓶颈 | 独立子任务并行执行 |
一个不严谨但有用的类比:单 Agent 像全栈工程师一个人扛所有活,Multi-Agent 像一个有分工的团队------有写代码的、有做审查的、有写测试的。
三、四种核心架构模式
理解了"为什么"之后,来看"怎么做"。目前业界沉淀下来的 Multi-Agent 架构主要有四种模式。
3.1 Sequential(顺序流水线)
Agent A → Agent B → Agent C → 最终输出最简单的多 Agent 模式。每个 Agent 完成一个阶段,输出作为下一个的输入。
典型场景:内容生产流水线(选题 → 撰写 → 审校)、数据处理管道。
优点 :简单、可控、易于调试。缺点:缺乏反馈回路,前面环节的错误会传导到后面。
python
# Sequential Multi-Agent 最小示例
from typing import Any
class SequentialPipeline:
def __init__(self, agents: list):
self.agents = agents
def run(self, initial_input: str) -> Any:
result = initial_input
for i, agent in enumerate(self.agents):
print(f"[Agent {i+1}] {agent.name} 开始处理...")
result = agent.process(result)
return result
# 使用示例
pipeline = SequentialPipeline([
PlannerAgent(), # 规划选题
WriterAgent(), # 撰写初稿
ReviewerAgent(), # 审校润色
])
article = pipeline.run("写一篇关于 Python 协程的文章")3.2 Hierarchical(层级调度)
Orchestrator(调度者)
/ | \
Agent A Agent B Agent C由一个"领导"Agent 负责任务分解、分配和结果汇总。这是目前最主流的模式,CrewAI、AutoGen 都采用类似架构。
典型场景:复杂项目的端到端执行、需要动态调整任务分配的场晙。
优点 :灵活、适应性强。缺点:调度者本身成为瓶颈,调度逻辑复杂时容易出错。
python
# Hierarchical 模式示例
class Orchestrator:
def __init__(self, specialists: dict):
self.specialists = specialists # {"code": CoderAgent, "review": ReviewerAgent}
def delegate(self, task: str) -> dict:
# LLM 分析任务,决定分配给哪些 Agent
plan = self.plan_tasks(task)
results = {}
for subtask in plan:
agent = self.specialists[subtask["role"]]
results[subtask["id"]] = agent.execute(subtask)
return self.aggregate(results)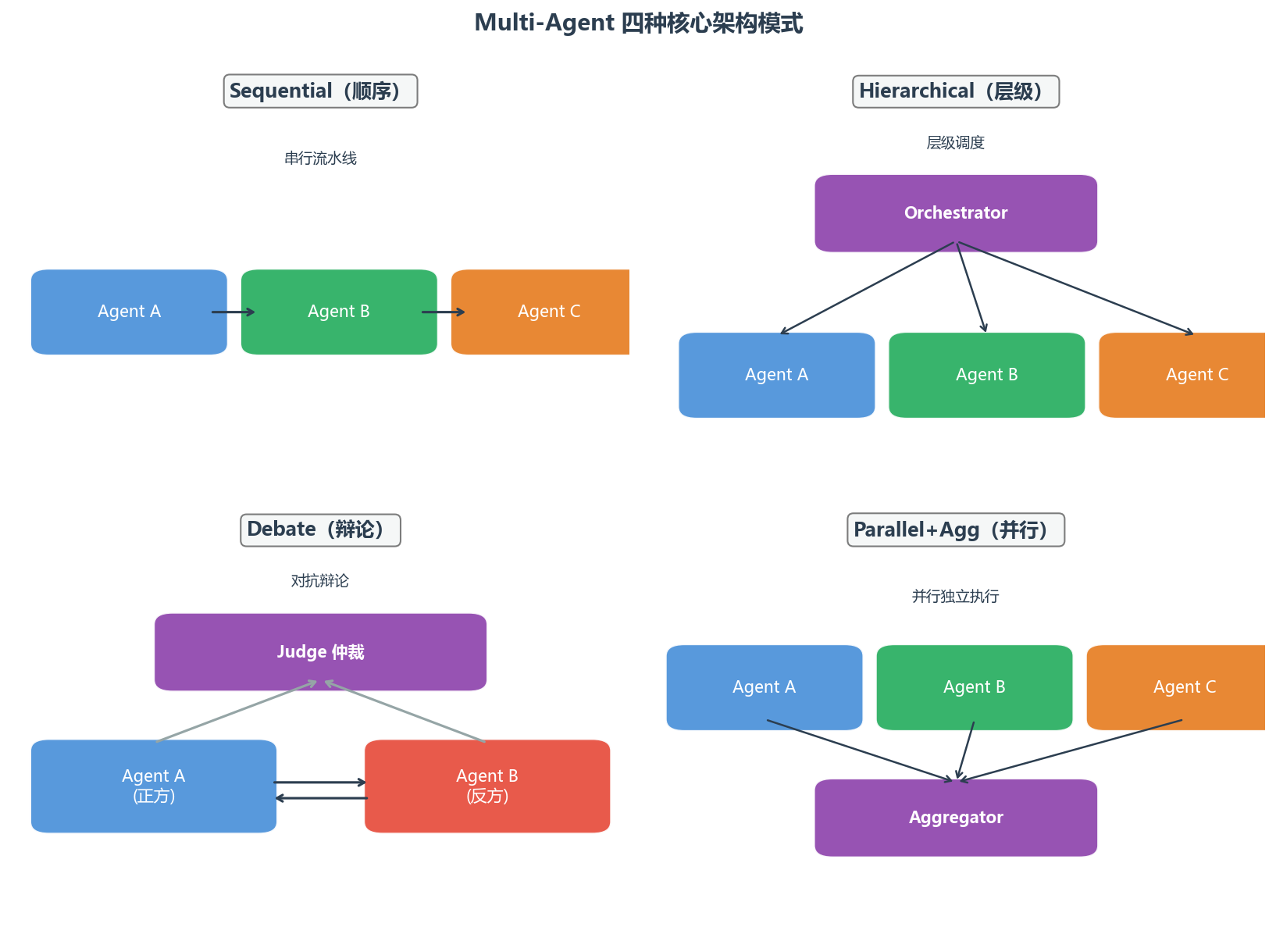
3.3 Debate(辩论/对抗)
Agent A(立场1) ⇄ Agent B(立场2)
↓
Judge Agent(仲裁)两个或多个 Agent 持不同立场进行辩论,由仲裁者综合各方观点做最终判断。
典型场景:代码审查、安全审计、事实核查、策略评估。
优点 :能发现单一视角的盲区,减少幻觉。缺点:计算成本翻倍,辩论轮次难以控制。
python
# Debate 模式概念示例
class DebateOrchestrator:
def run_debate(self, question: str, rounds: int = 3) -> str:
pro_agent = Agent(role="支持方")
con_agent = Agent(role="反对方")
judge = Agent(role="仲裁者")
pro_arg = pro_agent.argue(question, stance="pro")
con_arg = con_agent.argue(question, stance="con")
for _ in range(rounds):
pro_arg = pro_agent.rebut(con_arg)
con_arg = con_agent.rebut(pro_arg)
return judge.verdict(pro_arg, con_arg)3.4 Parallel + Aggregation(并行聚合)
Input
/ | \
Agent A Agent B Agent C (并行执行)
\ | /
Aggregator(汇总)
↓
Output多个 Agent 同时处理同一任务的不同方面,或各自独立处理同一任务后投票/汇总。
典型场景:多路召回、多维评估、投票机制。
优点 :速度快、结果更鲁棒。缺点:协调成本高,冗余计算。
3.5 四种模式对比
| 模式 | 复杂度 | 延迟 | 可靠性 | 适用场景 |
|---|---|---|---|---|
| Sequential | ★☆☆☆☆ | 高(串行) | 中 | 流水线任务 |
| Hierarchical | ★★★★☆ | 中 | 高 | 复杂项目 |
| Debate | ★★★☆☆ | 高(多轮) | 很高 | 需要高确定性的判断 |
| Parallel+Agg | ★★☆☆☆ | 低 | 高 | 独立子任务 |
四、什么时候你不该用 Multi-Agent
这不是一个推销帖。以下情况,单 Agent 反而更优:
1. 任务本身足够简单。 如果你的任务一个 system prompt + 2 个工具就能搞定,引入多 Agent 纯属过度设计。多一个 Agent 就多一份延迟、多一份出错概率。
2. 延迟敏感的场景。 Multi-Agent 意味着多轮 LLM 调用,端到端延迟可能是单 Agent 的 3-5 倍。如果你的用户等不起,慎重。
3. 调试和可观测性跟不上。 多 Agent 系统的调试难度指数级上升。当出问题时,你需要追踪是哪个 Agent 的哪一步出了问题------如果没有完善的日志和 Tracing,这会是一场噩梦。
4. 成本预算有限。 每个 Agent 每次调用都在烧 Token。一个 3-Agent 系统做一轮协作,成本轻松翻 3 倍以上。
简单的决策原则:先试单 Agent,确认它真的不够用了,再考虑 Multi-Agent。
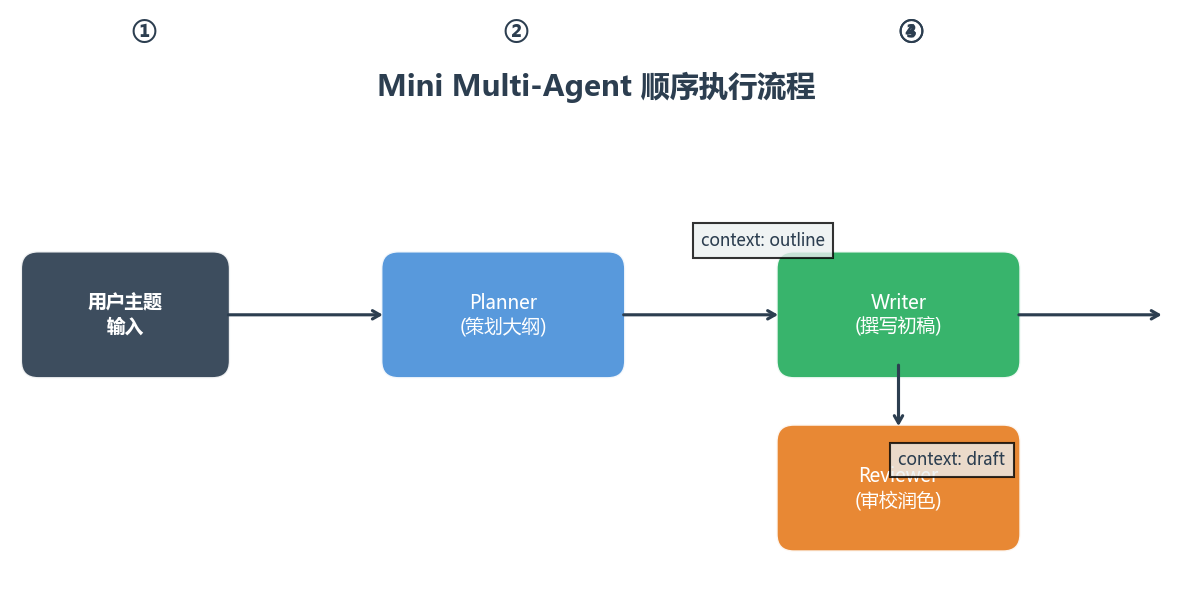
五、实战:搭建一个最小化 Multi-Agent 系统
下面我们不用任何框架(不用 CrewAI、不用 AutoGen),用最基础的 Python + OpenAI API 搭建一个最小化 Multi-Agent 系统,帮你理解底层原理。
5.1 项目结构
mini-multi-agent/
├── main.py # 入口和编排
├── agents.py # Agent 基类和具体 Agent
└── requirements.txt # openai5.2 Agent 基类
python
# agents.py
from openai import OpenAI
class BaseAgent:
def __init__(self, name: str, role: str, system_prompt: str):
self.name = name
self.role = role
self.system_prompt = system_prompt
self.client = OpenAI()
self.history = []
def think(self, task: str, context: str = "") -> str:
messages = [
{"role": "system", "content": self.system_prompt},
]
if context:
messages.append({"role": "user", "content": f"上下文:\n{context}"})
messages.append({"role": "user", "content": task})
response = self.client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0.7,
)
result = response.choices[0].message.content
self.history.append({"task": task, "result": result})
print(f"[{self.name}] 完成: {result[:80]}...")
return result5.3 定义三个具体 Agent
python
# agents.py (续)
PLANNER_PROMPT = """你是一个技术内容策划专家。
你的职责是:根据用户给出的主题,产出一份结构清晰的文章大纲。
输出格式:Markdown 格式的大纲,包含引言、核心内容(3-4 个小节)、总结。"""
WRITER_PROMPT = """你是一个技术文章写手。
你的职责是:根据策划给出的大纲,撰写一篇完整的技术文章。
要求:
- 中文撰写,语言自然流畅
- 技术内容准确
- 代码示例完整可运行
- 每段不超过 5 句话"""
REVIEWER_PROMPT = """你是一个技术编辑。
你的职责是:审校写手完成的文章,检查以下方面:
1. 技术准确性
2. 语言流畅度
3. 中英文空格规范
4. 代码块语言标注
输出:修改后的完整文章,并在开头列出你的改动摘要。"""
class PlannerAgent(BaseAgent):
def __init__(self):
super().__init__("Planner", "策划", PLANNER_PROMPT)
class WriterAgent(BaseAgent):
def __init__(self):
super().__init__("Writer", "写手", WRITER_PROMPT)
class ReviewerAgent(BaseAgent):
def __init__(self):
super().__init__("Reviewer", "编辑", REVIEWER_PROMPT)5.4 编排器
python
# main.py
from agents import PlannerAgent, WriterAgent, ReviewerAgent
class MultiAgentOrchestrator:
def __init__(self):
self.planner = PlannerAgent()
self.writer = WriterAgent()
self.reviewer = ReviewerAgent()
def run(self, topic: str) -> dict:
print(f"开始处理主题: {topic}\n")
# 阶段 1: 策划生成大纲
print("=" * 40)
outline = self.planner.think(f"为以下主题生成大纲:{topic}")
# 阶段 2: 写手撰写初稿
print("=" * 40)
draft = self.writer.think(
task=f"根据大纲撰写完整文章",
context=outline,
)
# 阶段 3: 编辑审校
print("=" * 40)
final = self.reviewer.think(
task=f"审校并优化以下文章",
context=draft,
)
return {
"outline": outline,
"draft": draft,
"final": final,
}
if __name__ == "__main__":
orchestrator = MultiAgentOrchestrator()
result = orchestrator.run("Python 异步编程最佳实践")
print("\n" + "=" * 40)
print("最终文章:\n")
print(result["final"])5.5 运行结果解读
这个最小化示例展示了 Multi-Agent 的核心机制:
- 角色分离:三个 Agent 各司其职,system prompt 定义了各自的"人设"
- 上下文传递:前一个 Agent 的输出作为后一个 Agent 的 context 传入
- 顺序编排:采用 Sequential 模式,但你可以轻松改为其他模式
六、主流框架速览
| 框架 | 模式 | 特点 | 适合 |
|---|---|---|---|
| CrewAI | Hierarchical | 角色化设计,上手快 | 快速原型 |
| AutoGen | Hierarchical + Group Chat | 微软出品,对话式 | 多轮对话 |
| LangGraph | 灵活图编排 | 状态图驱动,最灵活 | 复杂工作流 |
| OpenAI Swarm | 轻量 Handoff | 极简,实验性 | 学习/实验 |
七、注意事项与踩坑点
7.1 上下文膨胀
每个 Agent 的输出都在累积。如果不加控制,传到第 3、4 个 Agent 时上下文可能已经数千 Token。对策:对中间结果做压缩摘要,或只传递关键字段而不是全文。
7.2 Agent 之间"客套"
多 Agent 之间的输出如果包含太多"好的,我来处理"这种对话式废话,会让下游 Agent 的输入变得嘈杂。对策:在 system prompt 中明确要求"只输出结果内容,不要寒暄"。
7.3 无限循环
在 Debate 或 Hierarchical 模式中,如果没有设置终止条件,Agent 可能无限讨论下去。对策:设置最大轮次(max_rounds)或让 Orchestrator 判断何时收敛。
7.4 "集体幻觉"
多个 Agent 可能互相强化错误信息------A 犯了个错,B 引用 A 的输出当事实,C 再引用 B 的,形成"谣言链"。对策:关键环节引入外部工具验证(如搜索、数据库查询),不要纯靠 Agent 间口口相传。
八、总结
- Multi-Agent 不是银弹:它解决的是单 Agent 在复杂任务中的上下文竞争、能力冲突和单点故障问题,但也引入了更多延迟和复杂度。
- 四种模式选型:Sequential 适合流水线,Hierarchical 最灵活通用,Debate 适合需要高确定性的判断,Parallel+Agg 适合可并行的子任务。
- 先做减法:在引入 Multi-Agent 之前,先问自己------单 Agent + 更好的提示工程能不能搞定?
- 控制复杂度:Agent 数量每增加一个,调试难度指数上升。从最简单的 2-Agent 起步。
多 Agent 的本质不是"让 AI 更像人一样协作",而是"将复杂问题分解到可管理的子问题"------这和软件工程的模块化思想一脉相承。