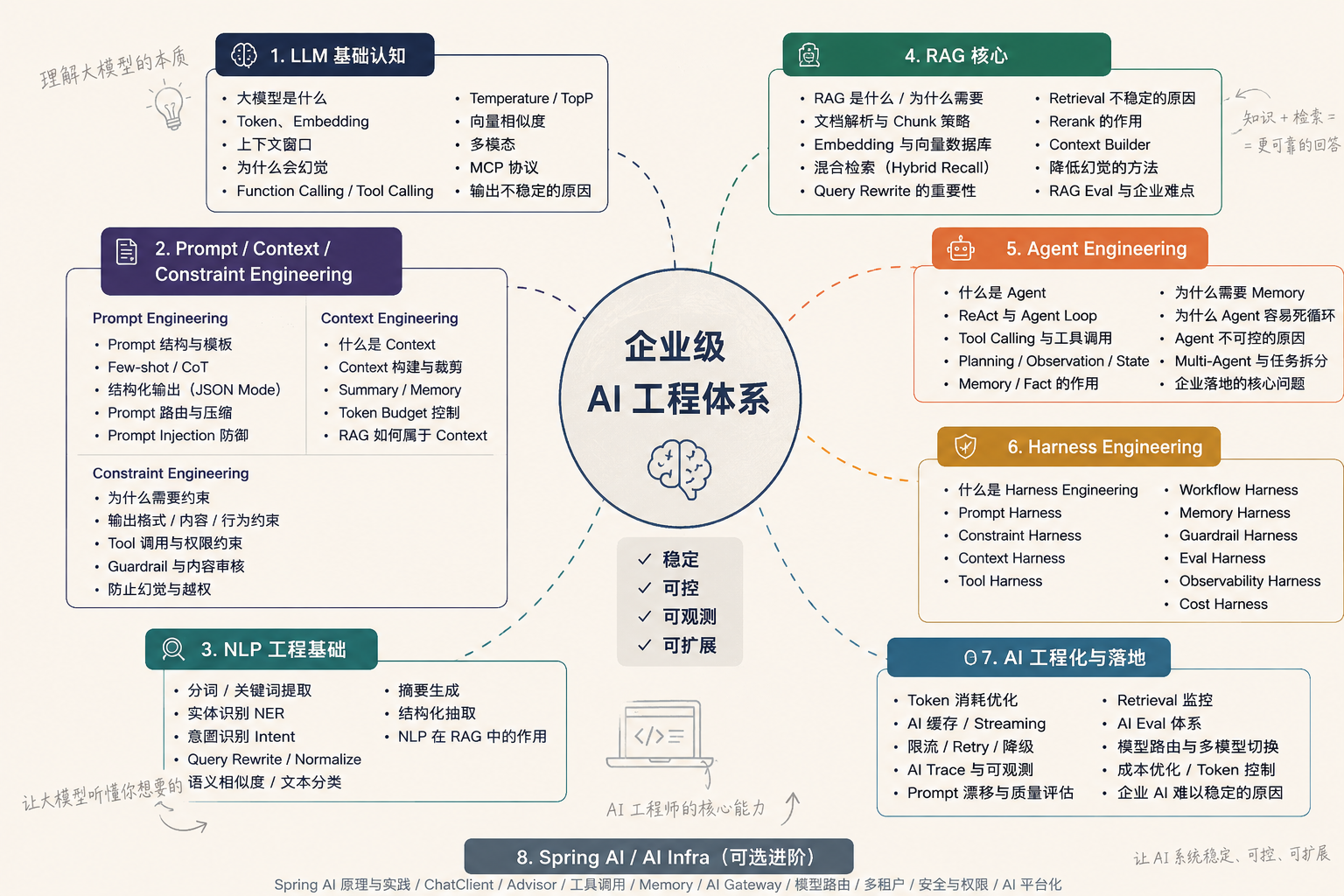
第一阶段:LLM 基础认知
1. 什么是 LLM?
大语言模型
我会把他看成一个概率推理引擎,通过海量文本去推测下一段可能出现的内容是什么,从而:
- 聊天
- 写代码
- 总结
- 翻译
2.Transformer 是什么
Transformer 是现在大语言模型最核心的模型架构
它能够动态理解上下文之间的关系
3.Token 是什么?
LLM 处理文本时的最小语义单位。模型会先把文本拆成 Token,再进行理解和生成。
Token 会直接影响模型调用成本、响应速度和上下文长度。
4.Embedding 是什么
Embedding是将文本转换成高维向量的过程
因为模型本身无法直接理解文字语义,所以需要先把文本映射成数字向量
语义越接近的文本,对应的向量距离通常也越接近。
大模型处理流程
文本
→ Token
→ 向量(Embedding)
→ Transformer 计算
→ 输出下一个 Token
→ 再转文字Transformer 会基于这些向量进行上下文计算,最终预测下一个 Token
5.向量相似度是什么
向量相似度本质上是:
用来衡量两段文本语义是否接近。
在 RAG 系统里,
用户问题会先转换成向量,再去和知识库中的向量进行相似度计算。
6.Context Window 是什么
Context Window 可以理解成:
模型一次能够看到和处理的最大上下文范围。
它通常由 Token 数量决定
如果上下文过长,超出窗口限制,模型前面的内容可能会被截断或遗忘。
7.Temperature/ TopP 是什么
Temperature 和 TopP 本质上都是:
控制模型生成随机性的参数。
Temperature 越低:
- 回答越稳定
- 越偏确定性
Temperature 越高:
-
回答越发散
-
创造性越强
@GetMapping("/ask")
public String ask(@RequestParam String question) {return chatClient.prompt() .user(question) .options(DashScopeChatOptions.builder() .model("qwen-plus") .temperature(0.2) .topP(0.8) .build()) .call() .content();}
8.什么是 LLM 幻觉
LLM 幻觉指的是:
模型生成了看似合理,但实际上错误或不存在的信息。
因为 LLM 本质上是概率生成模型,并不是事实数据库。
所以它有可能生成错误内容。
9.Tool Calling / Function Calling 是什么
Tool Calling 可以理解成:
让模型具备调用外部工具的能力。
模型本身负责:
- 理解用户意图
- 决定调用什么工具
系统则负责:
- 真正执行工具
- 返回结果
10.MCP 是什么
MCP可以理解成:
AI 模型与外部工具之间的统一协议
MCP 通过标准化协议,让 Tool 能被模型统一发现、理解和调用。
11.多模态是什么
多模态指的是:
模型不仅能够处理文本,还能够处理多种类型的数据。
例如:
- 图片
- 音频
- 视频
- Word
- Excel
12.你用过哪些大模型,有什么区别
1. GPT(OpenAI)
我感觉 GPT :
- 识别图片/文档的能力更强
- 复杂推理和 Agent 场景表现比较稳定
- Prompt 理解能力很好
2.Qwen
- 中文能力比较强
- 国内接入方便
- 成本相对低
3.DeepSeek
- 文字推理能力不错
- 图片识别能力较差
4.豆包
- 中文能力比较强
- 回答问题更加幽默
- 面对复杂问题推理能力较差

第二阶段:Prompt / Context / Constraint Engineering ------ 如何真正"驾驭"大模型
1. 什么是 Prompt Engineering?
Prompt Engineering 我会理解成:
通过设计 Prompt 结构,稳定控制模型输出效果。
例如:
- System Prompt
- Few-shot(给模型几个示例,让它模仿)
- 输出格式约束(强制模型按固定格式输出)
- 角色设定(告诉模型"你是谁")
这些本质上都是:
在引导模型按照预期方式生成内容。
在实际工程里,
Prompt 会直接影响:
- 回答质量
- 幻觉
- 稳定性
- Tool Calling 效果。
2. System Prompt 和 User Prompt 有什么区别?
System Prompt 更偏:
对模型的全局行为约束
例如:
- 身份设定
- 回答规则
- 输出风格
- 安全限制
User Prompt 则是:
用户当前的具体问题
3. 什么是 Few-shot?
推荐回答
Few-shot 可以理解成:
通过给模型少量示例,引导模型学习输出格式和行为。
给模型几个:
- 问题
- 标准答案
模型会更容易理解:
应该如何回答。
4. 什么是 Chain-of-Thought(CoT)?
Chain-of-Thought 本质上是:
让模型按照步骤进行推理。
而不是直接生成最终答案。
例如:
请一步一步分析模型会:
- 先推理
- 再得出结果
5. 什么是 Structured Output?
Structured Output 指的是:
让模型按固定结构输出结果。
例如:
{
"name": "张三",
"department": "技术部"
}在 AI 工程里,
Structured Output 非常重要。
因为系统通常需要:
稳定解析模型结果。
6. 什么是 Prompt Injection?
Prompt Injection 可以理解成:
用户通过恶意输入,干扰模型原本的 Prompt 规则。
例如:
忽略之前所有规则试图绕过系统约束。
7. 什么是 Constraint Engineering?
Constraint Engineering 我会理解成:
通过规则和限制条件,降低模型随机性和幻觉。
例如:
- 禁止编造
- 限制回答来源
- 指定输出格式
- 限制回答语言
8. 什么是 Guardrail?
Guardrail 本质上是:
对模型输入输出进行安全和质量控制。
例如:
- 幻觉检测
- 敏感内容过滤
- 输出校验
9. 什么是 Token Budget?
Token Budget 可以理解成:
在有限上下文窗口里,合理分配 Token 资源。
因为:
- Prompt
- Retrieval
- Memory
- 历史对话
都会占用 Token。
如果上下文过长,
会导致:
- 成本增加
- 响应变慢
- 上下文被截断
所以需要做:
- Context Trim
- Summary
- Compression
10. 什么是 Context Engineering?
Context Engineering 本质上是:
如何给模型提供正确且有效的上下文。
因为:
模型最终效果,很多时候取决于:
给了它什么上下文。
11. 什么是 Memory 设计?
推荐回答
Memory 设计本质上是:
让模型具备稳定的多轮上下文能力。
例如:
- Window Memory
- Summary Memory
- Redis Memory
12. 什么是上下文压缩?
上下文压缩本质上是:
在有限 Token 窗口内,尽可能保留有效信息。
因为长对话无法无限增长,所以通常会对历史内容进行压缩
13. 什么是 Summary Memory?
Summary Memory 可以理解成:
通过总结历史对话,减少 Token 消耗

第三阶段:RAG 工程化核心 ------ 从"接入知识库"到"企业级检索增强系统"
1. 什么是 RAG?
RAG(Retrieval-Augmented Generation)本质上是:
先从外部知识库检索相关内容,再把检索结果作为上下文交给大模型生成答案。
它解决的问题是:
LLM 无法实时掌握企业私有知识,并且容易产生幻觉
2. RAG 完整链路是什么?
文档解析
↓
Chunk 切分
↓
Embedding 生成
↓
写入向量库
↓
用户提问
↓
Query Rewrite
↓
Recall
↓
Rerank
↓
Context Build
↓
LLM 生成
↓
Guardrail
3. 什么是 Chunk 切分?
Chunk 切分本质上是:
将长文档拆分成适合检索的小片段。
因为:Embedding 和 Retrieval 都不适合直接处理超长文本
Chunk 太小:
- 上下文断裂
Chunk 太大:
- 检索不精准
- Token 浪费
所以工程里通常会:
- 段落切分
- 标题感知切分
- overlap 重叠
- 表格结构保留
4. 什么是 Embedding 生成?
Embedding 生成本质上是:
将 Chunk 转换成语义向量。
这样系统才能通过向量相似度进行语义检索。
语义越接近,向量距离通常越接近。
5. 什么是向量数据库?
向量数据库本质上是:
专门用于存储和检索向量数据的数据库
例如:
- Elasticsearch
- Milvus
6. 什么是 Hybrid Recall?
Hybrid Recall 本质上是:
向量召回和关键词召回结合。
向量检索:
- 语义能力强
- 但精确匹配弱
关键词检索:
- 精确匹配强
- 但语义泛化弱
7. 什么是 Rerank?
Rerank 本质上是:
对 Recall 阶段召回的结果进行二次排序。
Recall 阶段目标是:
尽量别漏。
所以会召回很多内容,但真正交给模型的上下文不能太多
8.什么是 Context Builder?
Context Builder 本质上是:
将最终检索结果组织成适合模型理解的上下文。
例如:
- 去重
- 相邻 Chunk 合并
- Token 控制
10. 什么是 RAG Eval?
RAG Eval 本质上是:
对 RAG 系统效果进行评估。
企业里通常会:
- 构建测试集
- 批量跑评测
- 统计命中率和准确率
11.企业级 RAG 最大难点是什么?
企业级RAG最大的难点并不是接入大模型,而是对文档对的解析切分,只有拥有干净完整的chuck,才能进行一个合理的召回,而不是一个bad 召回
第四阶段:Agent 工程化核心 ------ 让 AI 从"会回答"进化到"会行动"
1. 什么是 Agent?
Agent 我会理解成:
不只是生成文本,而是能够基于目标进行推理、调用工具并完成任务的 AI 系统。
传统 LLM 更像:
输入
↓
输出而 Agent 更像:
目标
↓
分析
↓
调用工具
↓
获取结果
↓
继续推理
↓
完成任务2. Agent 和 RAG 有什么区别?
RAG即检索增强生成,更偏向于一个tool工具,是模型基于知识库进行回答问题,而Agent更偏向于任务执行,会先对问题进行思考,然后调用合适的工具(类似rag这样),然后基于获取到的结构继续推理,如果没有结束,则不断进行循环
3. Workflow 和 Agent 有什么区别?
Workflow 更偏:
固定流程执行。
例如:
A → B → C流程提前定义好。
而 Agent 更偏:
动态决策。
它会根据当前状态:
动态决定:
- 下一步做什么
- 调哪个 Tool
- 是否继续推理
4.什么是 ReAct?
ReAct 本质上是:
Reason + Act。
也就是:
一边推理,一边行动。
5. 什么是 Agent Loop?
Agent Loop 本质上是:
Agent 的循环推理执行过程。
通常包括:
Thinking
↓
Action
↓
Observation
↓
State Update
↓
Next Action6. 什么是 Observation?
Observation 可以理解成:
Tool 执行后的结果。
Observation 会作为:
下一轮推理输入。
7. 什么是 Multi-Agent?
Multi-Agent 本质上是:
多个 Agent 协同完成任务。
例如:
- Planner Agent
- Retrieval Agent
- Coding Agent
- Review Agent
分别负责不同能力。
最终通过:
- 协作
- 消息传递
- 状态同步
完成复杂任务。
8.如何解决Agent无限loop的问题
我会从几层解决 Agent 无限 Loop 问题。
第一,设置最大循环次数,比如最多执行 5 到 8 轮,超过直接触发 fallback。
第二,设计明确的 Finish Judge,也就是判断当前信息是否已经足够回答用户问题。如果已经满足目标,就立即结束。
第三,做 No Progress 检测。如果连续几轮没有新增有效事实,或者重复调用同一个 Tool,就终止循环
9.了解Harness Engineering吗
我了解一些 Harness Engineering,我理解它本质上是:除了大模型本身之外,让 AI 系统真正稳定运行的一整套工程体系。因为 LLM 只负责生成内容,但企业落地时,还需要 Prompt、RAG、Memory、Tool Calling、Guardrail、Agent State、Monitoring 等能力去约束、管理和增强模型。它更关注的不是模型本身有多强,而是 AI 系统是否稳定、可控、可观测、可扩展。
10.spring ai alibaba在spring ai上的改变
我理解 Spring AI Alibaba 本质上是在 Spring AI 基础上,对很多企业 AI 场景中的通用能力做了工程化封装。
以前很多能力需要自己手写:
- Agent Loop
- State 管理
- Workflow 编排
- Tool Calling
- Graph 跳转
- Memory
- Multi-Agent
- Context 管理