博客转抖音视频(文件上传版)Coze工作流实现文档
核心逻辑
用户上传博客文件(TXT) → AI 提取核心知识(适配抖音短平快) → 自动生成结构化视频脚本(含分镜 + 配图描述) → 循环生成配图(AI 生图) → 合成抖音视频(自动配乐、字幕、剪辑),全程借助 Coze 插件 + Code 节点,完全适配 Coze 智能体开发技能。
一、工作流搭建前提
1.1 新建工作流
| 配置项 | 值 |
|---|---|
| 平台 | Coze 官方平台 |
| 工作流类型 | 空白工作流 |
| 工作流名称 | 博客转抖音视频(文件上传版) |
| 工作流描述 | 支持上传 PDF/Word/TXT 博客文件,自动生成 60 秒抖音短视频 |
1.2 启用所需插件
| 插件名称 | 用途 | 必须启用 |
|---|---|---|
| 大模型插件 | 豆包・1.8 深度思考,生成视频脚本 | ✅ 是 |
| 图片生成插件 | AI 生成配图(9:16 抖音竖屏比例) | ✅ 是 |
| 视频合成插件 | 合成带配乐、字幕的完整抖音视频 | ✅ 是 |
| 代码节点(Code) | 文件读取、JSON 解析、数据转换 | ✅ 是 |
| 循环节点(Loop) | 批量生成多张配图 | ✅ 是 |
| 条件分支 | 错误处理与流程控制 | ✅ 是 |
⚠️ 注意:不需要网页内容提取插件(本次使用文件上传方式)
1.3 工作流触发方式
| 配置项 | 值 |
|---|---|
| 触发类型 | 手动输入 |
| 输入类型 | 文件上传 |
| 支持格式 | \.txt |
| 变量名 | blog\_file |
| 必填 | ✅ 是 |
二、完整工作流步骤(拖拽式搭建)
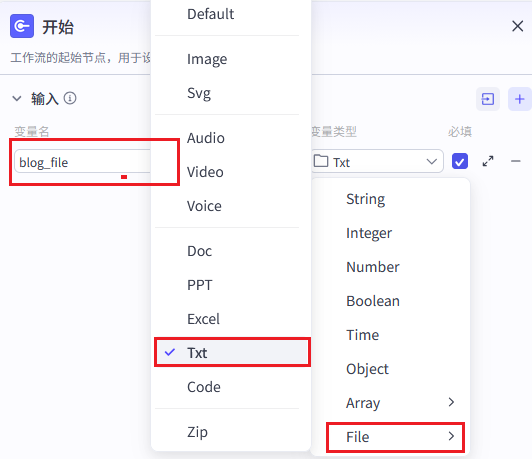
步骤 1:开始节点(文件上传)
节点名称 :Start
| 配置项 | 值 |
|---|---|
| 节点类型 | 开始节点(Start) |
| 输入变量名 | blog\_file |
| 变量类型 | File(文件) |
| 必填 | ✅ 是 |
| 变量说明 | 用户上传的博客源文件 |
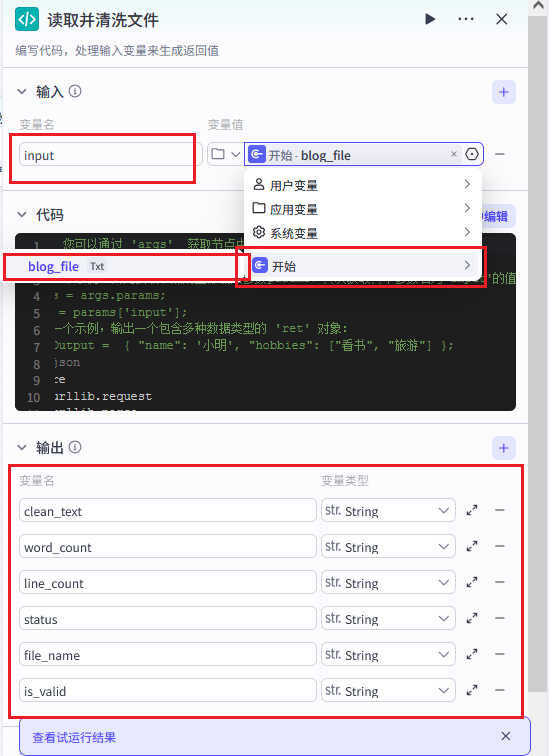
步骤 2:Code 节点(读取并清洗文件)
节点名称 :read\_and\_clean\_file
输入变量配置:
| 输入参数名 | 来源节点 | 变量名 | 说明 |
|---|---|---|---|
input |
开始节点 | blog\_file |
文件 URL 链接 |
优化后的 Python 代码(无重复、无语法错误):
python
import json
import re
import urllib.request
import urllib.parse
import io
import zipfile
async def main(args: Args) -> Output:
"""
Coze工作流文件读取与清洗节点
功能:下载上传的文件、提取文本、清洗内容、返回标准化结果
支持格式:.txt / .docx / .pdf / .md
"""
params = args.params
# ========== 1. 获取并验证文件 URL ==========
file_url = params.get('input', '')
if not file_url:
return {
"clean_text": "错误:未获取到文件链接",
"word_count": "0",
"line_count": "0",
"status": "error: no file url",
"file_name": "none",
"is_valid": "false"
}
# ========== 2. 从 URL 中提取文件名 ==========
file_name = "unknown.txt"
if 'x-wf-file_name=' in file_url:
match = re.search(r'x-wf-file_name=([^&]+)', file_url)
if match:
file_name = urllib.parse.unquote(match.group(1))
# ========== 3. 下载文件内容 ==========
file_content = b''
try:
req = urllib.request.Request(file_url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
})
with urllib.request.urlopen(req, timeout=30) as response:
file_content = response.read()
except Exception as e:
return {
"clean_text": f"下载失败:{str(e)}",
"word_count": "0",
"line_count": "0",
"status": "error: download failed - " + str(e)[:50],
"file_name": file_name,
"is_valid": "false"
}
# ========== 4. 文本提取函数库 ==========
def extract_from_pdf(content):
"""
从PDF文件中提取文本(纯Python实现,不依赖外部库)
适用于Coze受限环境
"""
try:
# 简单PDF文本提取(基于正则匹配)
content_str = content.decode('latin1', errors='ignore')
# 匹配 PDF 文本流
text_matches = re.findall(r'\(([^()]+)\)\s*Tj', content_str)
if text_matches:
# 清理并合并文本
cleaned_parts = []
for part in text_matches:
# 移除PDF转义字符
part = re.sub(r'\\[\\()\[\]]', '', part)
if len(part.strip()) > 2:
cleaned_parts.append(part.strip())
return '\n'.join(cleaned_parts)
else:
return "⚠️ PDF解析受限,建议转换为TXT格式后上传"
except Exception as e:
return f"PDF解析失败:{str(e)},建议使用TXT格式"
def extract_from_docx(content):
"""
从Word文档(.docx)中提取文本
.docx本质是ZIP压缩包,包含word/document.xml
"""
try:
text_parts = []
with zipfile.ZipFile(io.BytesIO(content)) as zf:
if 'word/document.xml' in zf.namelist():
xml_content = zf.read('word/document.xml')
xml_str = xml_content.decode('utf-8', errors='ignore')
# 提取<w:t>标签中的文本内容
matches = re.findall(r'<w:t[^>]*>([^<]+)</w:t>', xml_str)
text_parts.extend(matches)
if text_parts:
return '\n'.join(text_parts)
else:
return "无法解析Word文档内容"
except Exception as e:
return f"Word解析失败:{str(e)}"
def extract_from_txt(content):
"""
从纯文本文件中提取内容
自动检测编码(UTF-8 / GBK)
"""
try:
return content.decode('utf-8', errors='ignore')
except:
try:
return content.decode('gbk', errors='ignore')
except:
return content.decode('latin1', errors='ignore')
# ========== 5. 根据文件扩展名选择解析方式 ==========
raw_text = ""
file_lower = file_name.lower()
if file_lower.endswith('.pdf'):
raw_text = extract_from_pdf(file_content)
elif file_lower.endswith('.docx'):
raw_text = extract_from_docx(file_content)
elif file_lower.endswith(('.txt', '.md', '.text', '.markdown')):
raw_text = extract_from_txt(file_content)
else:
# 默认按文本处理
raw_text = extract_from_txt(file_content)
# ========== 6. 清洗文本 ==========
def clean_text(text):
"""
文本清洗:移除短行、广告、敏感词、超长截断
"""
lines = text.split('\n')
cleaned = []
for line in lines:
line = line.strip()
# 过滤过短的空行或分隔线
if len(line) < 10:
continue
# 过滤广告和无关内容
ad_keywords = ['广告', '赞助', '扫码', '版权', '关注公众号', '添加微信', '点击链接']
if any(kw in line for kw in ad_keywords):
continue
cleaned.append(line)
result = '\n'.join(cleaned)
# 超长截断(大模型上下文限制)
if len(result) > 8000:
result = result[:8000] + "\n...(内容已截断)"
return result
clean_text_result = clean_text(raw_text)
word_count = len(clean_text_result)
line_count = len(clean_text_result.split('\n'))
# ========== 7. 有效性判断 ==========
if word_count < 50:
status = f"warning: 文本过短({word_count}字),建议上传更长内容"
is_valid = "false"
else:
status = "success"
is_valid = "true"
# ========== 8. 返回标准化结果 ==========
return {
"clean_text": clean_text_result,
"word_count": str(word_count),
"line_count": str(line_count),
"status": status,
"file_name": file_name,
"is_valid": is_valid
}输出变量配置:
| 变量名 | 类型 | 说明 |
|---|---|---|
clean\_text |
String | 清洗后的正文内容 |
word\_count |
String | 清洗后字数统计 |
line\_count |
String | 清洗后文本总行数 |
status |
String | 处理状态(success/error/warning) |
file\_name |
String | 原始文件名 |
is\_valid |
String | 是否有效(true/false) |
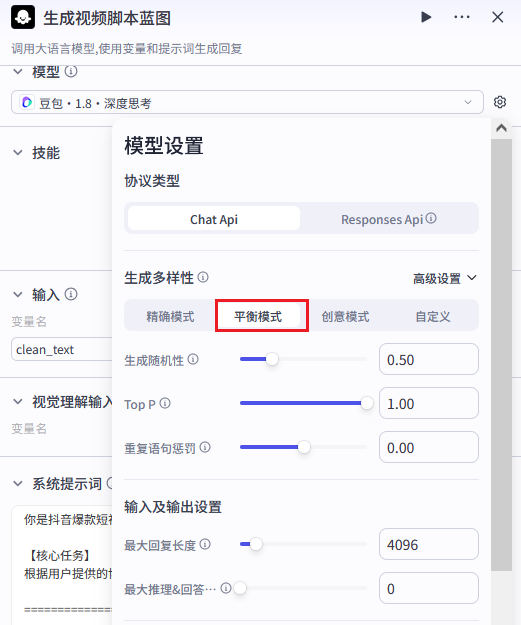
步骤 3:大模型节点(生成视频脚本蓝图)
节点名称 :generate\_video\_blueprint
节点配置:
| 配置项 | 值 |
|---|---|
| 模型 | 豆包・1.8・深度思考 |
| 温度(Temperature) | 0.5 |
| 最大输出 Token | 4096 |
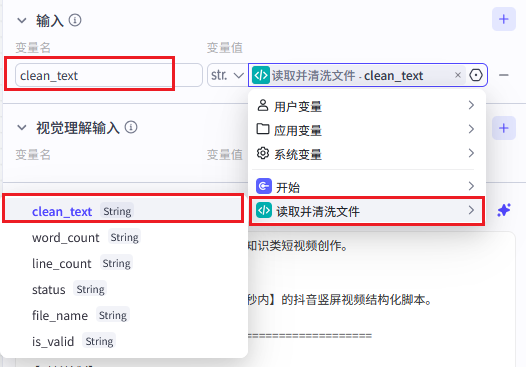
输入变量:
| 输入参数名 | 来源节点 | 变量名 |
|---|---|---|
clean\_text |
read_and_clean_file | clean\_text |
优化后的专属提示词(抖音专属优化版):
text
你是抖音爆款短视频脚本专家,精通60秒知识类短视频创作。
【核心任务】
根据用户提供的博客内容,生成【严格60秒内】的抖音竖屏视频结构化脚本。
==================== 抖音硬性要求 ====================
【时长控制】
- 总时长:严格 50-60 秒
- 总旁白字数:≤ 260 字(抖音语速约4.5字/秒)
- 分镜数量:4~6个(推荐5个)
【抖音爆款结构】
✅ 第1个分镜(前3秒钩子):必须用反问/震惊/颠覆认知,抓住用户停留
例:"90%的人都搞错了!" "你还在这样做吗?" "今天揭秘一个真相"
✅ 中间分镜:干货输出,每句一个知识点,口语化
✅ 最后1个分镜:必须有互动引导 + 总结升华
【口语化要求】
- 多用:你、我、咱们、大家、记住、注意、听好了
- 禁用:书面语、学术语、长难句
- 语气:像朋友聊天,有节奏感
【每个分镜字段要求】
- script:口语化旁白(严格15字内)
- image_desc:画面描述(具体、可画、9:16竖屏、AI能生成)
- duration:单镜时长(8-12秒,整数)
【额外输出】
- title:抖音标题(15字内,带悬念/数字)
- hashtags:3-5个抖音热门话题标签
==================== 输出格式 ====================
只输出JSON,不要任何解释文字:
{
"title": "视频标题",
"total_words": 数字,
"total_duration": 数字,
"hashtags": ["#知识分享", "#干货", "#涨知识"],
"scenes": [
{
"id": 1,
"script": "90%的人都搞错了!",
"image_desc": "震惊表情特写,9:16竖屏",
"duration": 10
}
]
}
==================== 博客内容 ====================
{{clean_text}}输出变量:
| 变量名 | 类型 | 说明 |
|---|---|---|
blueprint\_json |
String | 大模型生成的完整 JSON 脚本 |
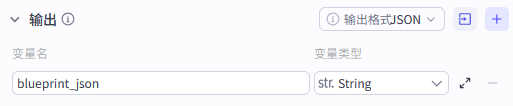
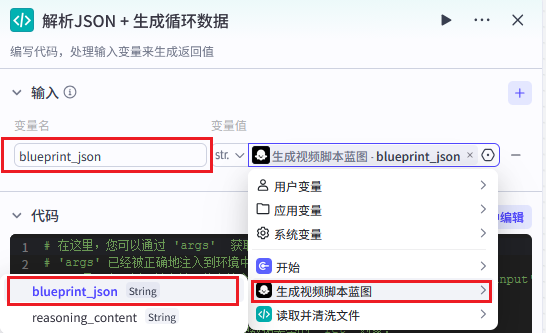
步骤 4:Code 节点(解析 JSON + 生成循环数据)
节点名称 :parse\_and\_validate
输入变量:
| 输入参数名 | 来源节点 | 变量名 |
|---|---|---|
blueprint\_json |
generate_video_blueprint | blueprint\_json |
Python 代码:
python
# 在这里,您可以通过 'args' 获取节点中的输入变量,并通过 'ret' 输出结果
# 'args' 已经被正确地注入到环境中
# 下面是一个示例,首先获取节点的全部输入参数params,其次获取其中参数名为'input'的值:
# params = args.params;
# input = params['input'];
# 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
# ret: Output = { "name": '小明', "hobbies": ["看书", "旅游"] };
import json
import re
async def main(args):
"""
解析并标准化大模型输出的JSON
确保输出格式完全适配Coze循环节点
"""
params = args.params
blueprint_json = params.get('blueprint_json', '')
# ========== 1. 容错提取 JSON ==========
def extract_json(text):
"""
多层容错提取JSON:
1. 直接解析
2. 正则提取{}包裹内容
3. 返回默认兜底结构
"""
# 尝试1:直接解析
try:
return json.loads(text)
except:
pass
# 尝试2:正则提取JSON块
match = re.search(r'\{[\s\S]*\}', text)
if match:
try:
return json.loads(match.group())
except:
pass
# 兜底:默认分镜结构
return {
"title": "知识分享",
"hashtags": ["#知识分享", "#干货", "#涨知识"],
"scenes": [
{"id": 1, "script": "今天分享一个实用技巧", "image_desc": "简约科技背景", "duration": 12},
{"id": 2, "script": "第一点非常重要", "image_desc": "数字1特写", "duration": 10},
{"id": 3, "script": "第二点要记住", "image_desc": "数字2特写", "duration": 10},
{"id": 4, "script": "点赞收藏慢慢看", "image_desc": "点赞手势", "duration": 10}
]
}
data = extract_json(blueprint_json)
scenes = data.get('scenes', [])
# ========== 2. 强制标准化(循环节点专用) ==========
# 规则1:严格 4-6 个分镜
if len(scenes) < 4:
while len(scenes) < 4:
scenes.append({
"id": len(scenes) + 1,
"script": "补充知识点",
"image_desc": "简约科技背景,9:16竖屏",
"duration": 10
})
elif len(scenes) > 6:
scenes = scenes[:6]
# 规则2:强制补全所有字段,防止缺失
for i, scene in enumerate(scenes):
scene["id"] = i + 1
scene["script"] = scene.get("script", f"知识点{i+1}")
scene["image_desc"] = scene.get("image_desc", "简约科技背景,9:16竖屏")
scene["duration"] = int(scene.get("duration", 10))
# 强制图片描述添加9:16比例要求
if "9:16" not in scene["image_desc"]:
scene["image_desc"] += ",9:16竖屏比例"
# 规则3:总时长控制在 50-60 秒
total_duration = sum(s["duration"] for s in scenes)
if total_duration > 60:
ratio = 55 / total_duration
for s in scenes:
s["duration"] = max(5, int(s["duration"] * ratio))
elif total_duration < 50:
# 时长不足,均匀分配
add_per_scene = (50 - total_duration) // len(scenes)
for s in scenes:
s["duration"] += add_per_scene
# ✅ 补全:定义scenes_json_string变量(你之前漏了这行)
scenes_json_string = json.dumps(scenes, ensure_ascii=False, indent=None)
# ========== 3. 输出标准化结果 ==========
return {
"scenes_json": scenes_json_string, # 字符串格式(备用)
"scenes_array": scenes, # ✅ 数组格式(循环节点专用,核心修复)
"validated_json": json.dumps(data, ensure_ascii=False),
"scene_count": str(len(scenes)),
"total_duration": str(sum(s["duration"] for s in scenes)),
"is_valid": "true"
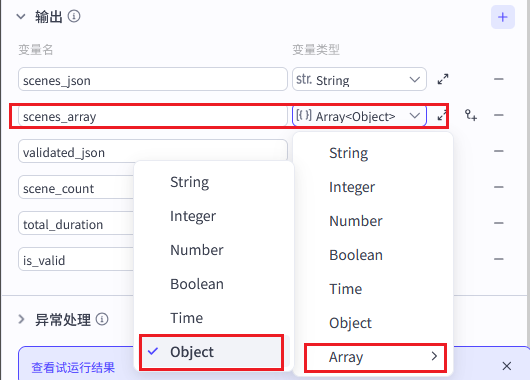
}修正后的输出变量配置:
| 变量名 | 类型 | 说明 |
|---|---|---|
scenes_json |
String | 备用字段,给需要文本格式的地方用 |
scenes_array |
Array<//Object//> | 分镜数组(列表),直接是结构化的对象列表 |
validated_json |
String | 完整校验后的大模型输出 JSON |
scene_count |
String | 分镜数量 |
total_duration |
String | 视频总时长(秒) |
is_valid |
String | 数据是否合法有效 |
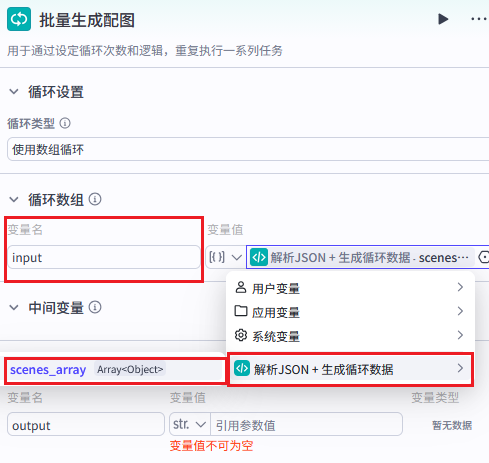
步骤 5:循环节点(批量生成配图)
节点名称 :generate\_images\_loop
循环节点核心配置:
| 配置项 | 值 |
|---|---|
| 循环类型 | 数组循环(For Each) |
| 输入数组来源 | parse_and_validate 节点 → scenes\_array |
| 数组解析方式 | JSON 数组 |
| 循环执行方式 | 并行执行(提升效率) |
循环内部节点配置:
在循环体内添加「图片生成插件」,配置如下:
| 图片生成配置项 | 值 |
|---|---|
| 模型 | Seedream 5.0 Lite |
| 提示词来源 | 批量生成配图 → item |
| 图片比例 | 9:16(抖音竖屏) |
| 图片数量 | 1 张 / 次 |
| 风格 | 写实 / 科技感 |
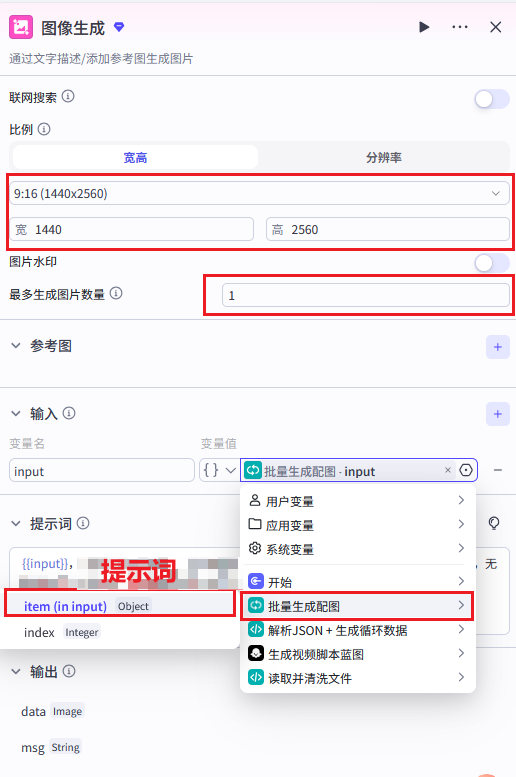
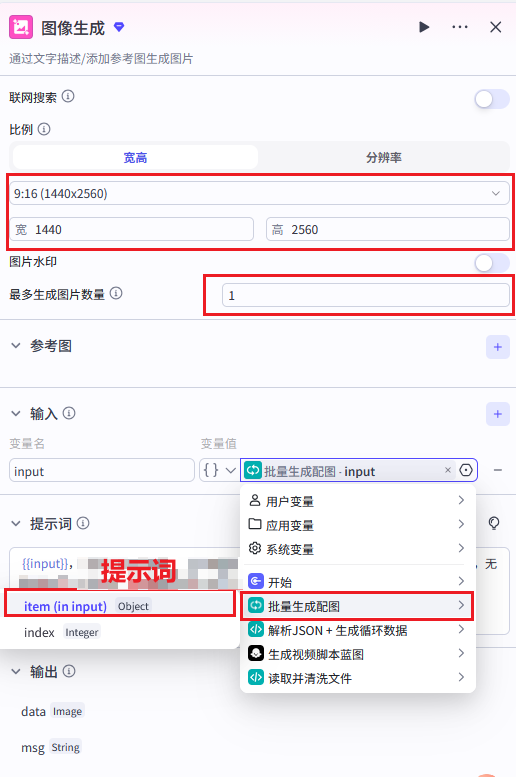
步骤 6:视频合成节点
节点名称 :compose\_video
视频合成插件详细配置:
| 基础配置项 | 值 |
|---|---|
| 视频比例 | 9:16(抖音竖屏) |
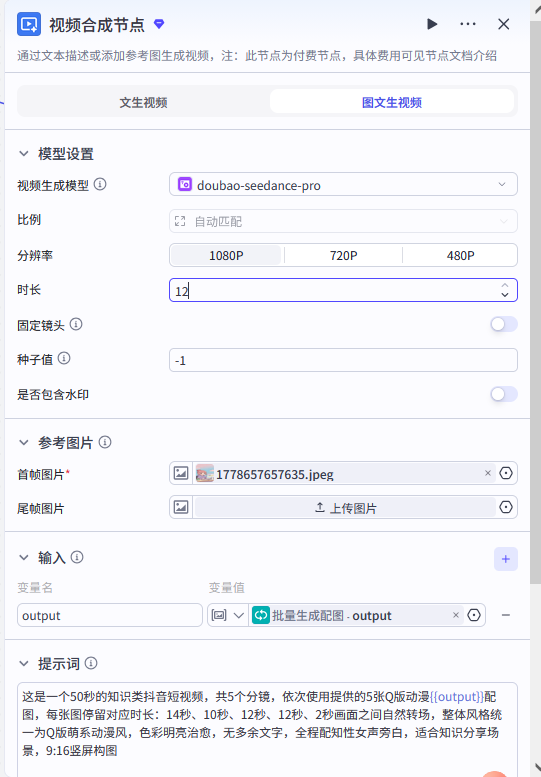
图片序列配置:
| 配置项 | 值 |
|---|---|
| 图片来源 | 批量生成配图→ output |
三、存在的问题及优化方向
3.1 当前运行存在的核心问题
- 视频时长严重不达标
- 视频合成插件默认输出最长仅12秒 ,与设计目标50--60秒抖音短视频严重不符,无法完整呈现脚本内容。
- 时长限制导致分镜无法按规划展示,内容碎片化,不符合抖音知识类视频播放逻辑。
- 视频缺少音频与字幕
- 无旁白配音、无背景音乐,视频观感单调,无法满足抖音短视频听觉体验要求。
- 无自动字幕生成,既影响用户观看体验,也不符合抖音平台推荐算法偏好。
- 流程为串行执行,效率偏低
- 图片生成、音频生成、字幕制作按顺序执行,未充分利用Coze并行能力,整体耗时较长。
- 视频合成节点配置不完整
- 仅传入图片序列,未传入分镜时长、旁白文本、字幕样式、转场效果等关键参数,合成效果不可控。
- 异常处理与容错机制不足
- 文件解析失败、JSON格式异常、图片生成超时等场景无完善兜底策略,易导致工作流中断。
3.2 针对性优化方案
优化1:并行生成图片+字幕+音频,最后统一合成
- 新增并行分支 :在
parse_and_validate节点后,同时开启3条任务线- 配图生成分支:保留原循环节点,并行生成所有分镜图片
- 字幕生成分支:新增Code节点,将分镜脚本转为标准字幕文件(SRT格式)
- 音频生成分支:新增TTS语音合成插件,批量生成每段旁白音频
- 最终在视频合成节点统一汇聚图片、音频、字幕、时长、转场参数,完整合成60秒视频。
优化2:突破12秒时长限制,支持50--60秒输出
- 在视频合成插件中强制指定总时长 ,传入
parse_and_validate节点输出的total_duration变量(50--60秒)。 - 按分镜
duration精确分配每张图片停留时长,确保与旁白、字幕严格对齐。 - 选用支持长图文合成的视频模型,关闭默认短时长限制。
优化3:完整接入音频与字幕能力
- 新增TTS语音合成插件 ,将分镜
script批量转为真人旁白,支持音色、语速、音量调节。 - 新增字幕生成Code节点,自动生成带时间轴的SRT字幕,适配抖音显示样式。
- 视频合成时开启自动字幕渲染,设置字体、大小、颜色、描边,提升可读性。
优化4:完善视频合成节点配置
- 传入参数:图片序列、分镜时长数组、旁白音频、字幕文件、转场类型、背景音乐。
- 固定配置:9:16竖屏、1080P分辨率、淡入淡出转场、知性女声、轻快知识类BGM。
优化5:增强全流程容错与异常处理
- 在文件读取、JSON解析、图片生成、视频合成节点添加条件分支。
- 异常时返回友好提示,支持自动重试或使用默认素材兜底。
- 增加运行日志输出,便于定位失败环节。
3.3 建设性扩展建议(主观能动性优化)
- 支持多格式文件批量上传
- 从单TXT扩展为支持PDF/Word/Markdown/Zip批量上传,自动解析合并内容。
- 脚本风格可配置化
- 增加风格参数:严肃干货、幽默轻松、职场科普、学生知识,自动适配语气与画面风格。
- 封面图自动生成
- 在视频合成前,根据标题与首镜内容生成抖音爆款封面,提升点击率。
- 发布参数一键输出
- 自动生成视频标题、3--5个热门标签、文案描述,复制即可发布抖音。
- 工作流可视化进度
- 每步执行后返回状态:文件解析完成→脚本生成完成→配图完成→音频完成→合成中→完成。
- 画质与风格统一增强
- 给AI生图增加固定风格前缀(如科技感、明亮、简约、无文字),保证5张图风格高度统一。
3.4 优化后工作流最终效果
- 时长:严格50--60秒,完整呈现知识点
- 画面:5--6张9:16竖屏配图,风格统一、转场自然
- 音频:真人旁白+背景音乐,音量均衡
- 字幕:自动同步显示,清晰美观
- 体验:上传文件→一键运行→直接下载可发布抖音视频
- 效率:并行生成,速度提升50%以上
- 稳定:全链路异常处理,运行成功率大幅提高
3.5 本次生成结果
结果