从数据结构到 Prompt 设计:前端工程师的 AI 时代进阶指南
本文从 Python 数据结构(Dict、Set)的核心原理出发,结合 JavaScript 变量提升的经典面试题,最终延伸到 Prompt 工程的设计原则,帮助前端工程师构建从底层到 AI 应用的完整知识链路。
一、字典(Dict):为什么它能 O(1) 查找?
1.1 什么是字典?
字典(Dictionary)是一种基于 键值对(Key-Value) 的数据结构,在 Python 中内置为 dict,在 JavaScript 中对应 Object 或 Map。
python
# Python dict
student = {
"张三": 95,
"李四": 88,
"王五": 72
}
# 查找时间复杂度 O(1)
print(student["张三"]) # 95
javascript
// JavaScript Map
const student = new Map();
student.set("张三", 95);
student.set("李四", 88);
console.log(student.get("张三")); // 951.2 哈希表(HashTable)原理
字典之所以能实现 O(1) 查找,核心在于 哈希算法:
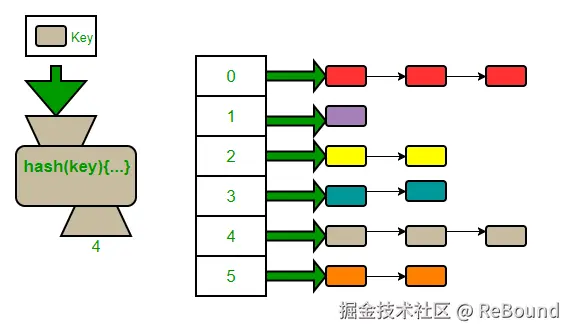
图片来源:Wikipedia - Hash Table
vbnet
Key → 哈希函数 → 索引 → 存储位置 → Value工作流程:
- 将 Key 通过哈希函数计算,得到一个用于定位的索引值
- 根据索引直接存取对应的 Value,无需遍历
这就像字典的 偏旁部首索引 或 拼音首字母索引------查"张"字,直接翻到 Z 开头的部分,而不是从第一页翻到最后一页(O(n))。
底层实现:数组 + 链表
哈希表的底层本质上是一个 数组(桶数组) ,每个槽位可能挂着一个 链表(用于处理哈希冲突):
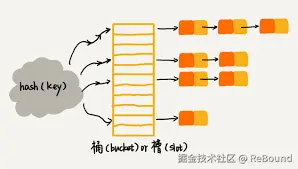
图片来源:Wikipedia - Hash Table
scss
简化示意:
Key 输入
│
▼
┌─────────┐
│ hash() │ ← 哈希函数:将任意 Key 映射为数组下标
└────┬────┘
│ index = hash(key) % array_size
▼
桶数组(Bucket Array)
┌───────┐
│ [0] ──→ NULL
│ [1] ──→ ("apple", 5) ──→ ("avocado", 8) ──→ NULL ← 链表解决冲突
│ [2] ──→ ("banana", 3) ──→ NULL
│ [3] ──→ NULL
│ [4] ──→ ("cherry", 7) ──→ ("cat", 2) ──→ NULL ← 冲突:不同 Key 同一下标
│ [5] ──→ ("date", 1) ──→ NULL
└───────┘写入流程(PUT)
scss
put("apple", 5)
"apple"
│
▼
hash("apple") = 97+112+112+108+101 = 530
│
▼
index = 530 % 8 = 2 ← 取模运算,确保落在数组范围内
│
▼
桶[2] 为空?
├── 是 → 直接存入 ("apple", 5)
└── 否 → 遍历链表,找到 Key 相同则覆盖,否则追加到链表尾部查找流程(GET)
scss
get("apple")
"apple"
│
▼
hash("apple") = 530
│
▼
index = 530 % 8 = 2 ← O(1) 直接定位到桶[2]
│
▼
桶[2] ──→ ("apple", 5) ← 遍历链表,Key 匹配,返回 Value=5
时间复杂度:O(1 + α),α = 元素数/桶数(负载因子),通常 α 很小 ≈ O(1)哈希冲突(Collision)
当两个不同的 Key 经过哈希运算得到 相同的索引,就发生了冲突:
erlang
hash("cherry") % 8 = 4
hash("cat") % 8 = 4 ← 冲突!同一个桶
桶[4] 的链表:
("cherry", 7) ──→ ("cat", 2) ──→ NULL
解决方式:链地址法(Chaining)------ 用链表将冲突的元素串起来另一种解决方式:开放寻址法(Open Addressing)
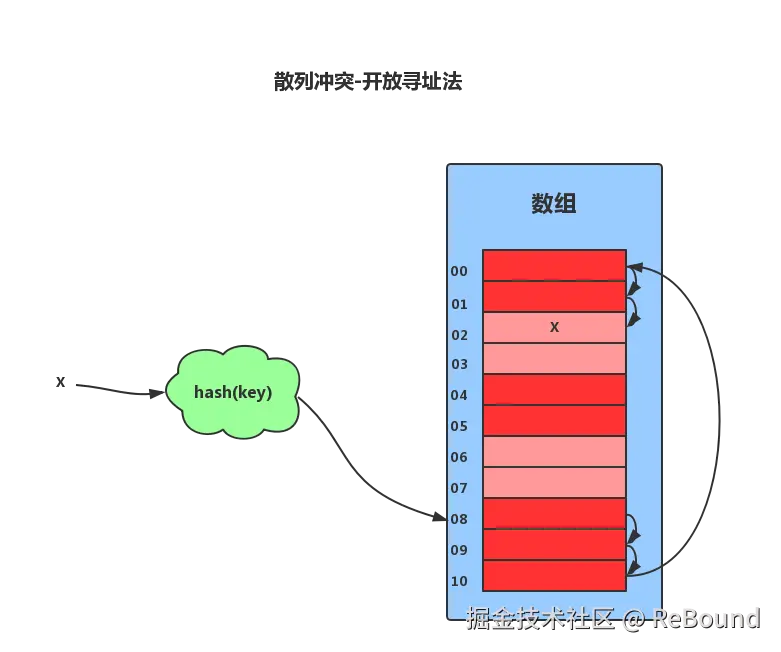
图片来源:Wikipedia - Hash Table
与链地址法不同,开放寻址法 不使用链表,冲突时直接在数组中寻找下一个空位:
scss
hash("cherry") % 8 = 4 → 存入桶[4]
hash("cat") % 8 = 4 → 桶[4] 已占用 → 线性探测桶[5] → 存入桶[5]
[4] → ("cherry", 7)
[5] → ("cat", 2) ← 不用链表,直接存在数组中| 方案 | 优点 | 缺点 |
|---|---|---|
| 链地址法 | 实现简单,负载因子可 >1 | 链表遍历开销 |
| 开放寻址法 | 缓存友好,无额外指针 | 负载因子必须 <1,探测成本高 |
负载因子与扩容(Resize)
ini
负载因子 α = 已存储元素数 / 桶数组长度
α = 6 / 8 = 0.75 ──→ 超过阈值(通常 0.75),触发扩容!
扩容过程:
┌────────────────┐ ┌────────────────────────────┐
│ 旧数组(长度 8) │ ──→ │ 新数组(长度 16) │
│ 6 个元素 │ │ 所有元素重新哈希并分配到新位置 │
└────────────────┘ └────────────────────────────┘
扩容后,每个桶的链表更短 → 查找更快
但扩容本身需要 O(n) 的时间重新哈希所有元素完整的哈希表操作复杂度
| 操作 | 平均 | 最坏(所有 Key 冲突) |
|---|---|---|
| 查找 | O(1) | O(n) |
| 插入 | O(1) | O(n) |
| 删除 | O(1) | O(n) |
最坏情况极少发生,良好的哈希函数 + 合理的负载因子控制,能保证实际性能趋近 O(1)。
1.3 Dict vs List:空间换时间
| 特性 | Dict(字典) | List(列表) |
|---|---|---|
| 查找速度 | O(1),极快 | O(n),随元素增加变慢 |
| 插入速度 | O(1),极快 | 尾部追加 O(1),任意位置插入 O(n) |
| 内存占用 | 大,需要额外空间做哈希 | 小,连续存储 |
| 适用场景 | 高频查找、去重 | 顺序访问、遍历 |
结论 :Dict 是典型的 空间换时间 策略。在需要高速查找的场景(如缓存、索引),优先选择 Dict。
1.4 Dict 的 Key 可以重复吗?
不能。 Key 是唯一的,Value 可以重复。
python
# Python --- 重复 Key,后面的覆盖前面的
d = {"a": 1, "b": 2, "a": 3}
print(d) # {'a': 3, 'b': 2}
javascript
// JavaScript Object --- 同理
const obj = { a: 1, b: 2, a: 3 };
console.log(obj); // { a: 3, b: 2 }
// JavaScript Map
const map = new Map();
map.set("a", 1);
map.set("a", 3);
console.log(map.get("a")); // 3为什么不能重复?回到哈希表的写入流程
erlang
put("a", 1) → hash("a") = 97 → 桶[1] 为空 → 存入 ("a", 1)
put("a", 3) → hash("a") = 97 → 桶[1] 已有 ("a", 1)
→ 遍历链表,发现 Key 相同("a" == "a")
→ 覆盖 Value:("a", 1) → ("a", 3)Key 相同的判定标准:hash 值相同 + 实际值相等 。哈希表遇到重复 Key 时的行为是 覆盖旧值,而非追加。
Dict vs Set vs List 对比
| 容器 | Key 能重复? | Value 能重复? |
|---|---|---|
| Dict / Map | ❌ 覆盖 | ✅ 可以 |
| Set | ❌ 跳过 | ---(没有 Value) |
| List / Array | ---(没有 Key) | ✅ 可以 |
一句话总结:哈希表的 Key 天然唯一,Dict 和 Set 是同一个机制的两种表现------Dict 存 Key-Value 对,Set 只存 Key。
二、为什么 Dict 的 Key 必须是不可变的?
2.1 Unhashable Type 问题
你可能遇到过这个错误:
python
# 运行时抛出 TypeError: unhashable type: 'list'
my_dict = {[1, 2, 3]: "value"}原因:列表(List)是可变对象,内容可以随时修改。
如果允许列表作为 Key:
- 第一次哈希
[1, 2, 3]→ 索引 5 - 修改列表为
[1, 2, 3, 4]→ 哈希结果变成索引 8 - 再次查找时,去索引 8 找,但数据存在索引 5 → 数据丢失!
2.2 可变 vs 不可变对象
| 类型 | Python | JavaScript | 可否作为 Dict Key |
|---|---|---|---|
| 字符串 | str(不可变) |
string(原始类型) |
✅ |
| 数字 | int/float |
number(原始类型) |
✅ |
| 元组 | tuple(不可变) |
--- | ✅ |
| 列表 | list(可变) |
Array(可变) |
❌ |
| 字典 | dict(可变) |
Object(可变) |
❌ |
关键理解 :字符串是不可变对象。
"abc".replace("a", "A")并没有改变"abc"本身,而是返回了一个新的字符串"Abc"。变量s可以被重新赋值,但原始字符串对象永远不会改变。
python
s = "abc"
s_new = s.replace("a", "A")
print(s) # "abc" --- 原对象不变
print(s_new) # "Abc" --- 新对象三、Set:没有 Value 的 Dict
3.1 Set 的特性
Set(集合)和 Dict 类似,也是一组 Key 的集合,但 不存储 Value 。由于 Key 不能重复,Set 天然具有 去重 功能。
python
# Python Set
s = {1, 2, 2, 3, 3, 3}
print(s) # {1, 2, 3} 自动去重
javascript
// JavaScript Set
const s = new Set([1, 2, 2, 3, 3, 3]);
console.log([...s]); // [1, 2, 3]3.2 为什么 Set 的 Key 是唯一的?和 Hash 有什么关系?
Set 的去重能力 完全依赖哈希机制 。本质上,Set 就是一个 只存 Key、不存 Value 的哈希表。
插入流程:如何判断"重复"?
bash
s.add("apple")
"apple"
│
▼
hash("apple") = 530 ← 第一步:计算哈希值
│
▼
index = 530 % 8 = 2 ← 第二步:定位到桶[2]
│
▼
桶[2] 已有元素?
├── 无 → 直接存入 "apple"
└── 有 → 遍历链表,逐个比较:
① 先比 hash 值 → hash 不同,肯定不是同一个元素
② hash 相同 → 再调用 __eq__() 比较实际值
③ 如果相等 → 判定为重复,跳过插入
④ 如果不等 → 哈希冲突,追加到链表尾部关键点:"重复"的判断标准是 hash(x) == hash(y) and x == y,两步缺一不可。
Python 中的 __hash__ 和 __eq__
python
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __hash__(self):
# 哈希值由 name 和 age 共同决定
return hash((self.name, self.age))
def __eq__(self, other):
# 两个 Student 相等 ⟺ name 和 age 都相同
return self.name == other.name and self.age == other.age
s = set()
s.add(Student("张三", 20))
s.add(Student("张三", 20)) # 不会重复,因为 hash 和 eq 都相等
s.add(Student("李四", 20)) # 不同元素,hash 不同
print(len(s)) # 2注意 :如果你自定义类但没有重写
__hash__和__eq__,Python 默认使用对象的内存地址作为哈希值,每个对象都是"唯一的":
python
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
s = set()
s.add(Point(1, 2))
s.add(Point(1, 2)) # 不同对象,内存地址不同 → hash 不同 → 被视为不同元素!
print(len(s)) # 2,不是 1!为什么可变对象不能放入 Set?
和 Dict 的 Key 同理------可变对象的哈希值不稳定:
python
s = set()
s.add([1, 2, 3]) # ❌ TypeError: unhashable type: 'list'
# 假设可以放入:
# 1. add([1,2,3]) → hash([1,2,3]) → 存入桶 5
# 2. 修改列表为 [1,2,3,4] → hash 变了 → 去桶 8 找
# 3. 找不到 → 数据丢失,去重机制彻底失效Set 的三个核心操作复杂度
| 操作 | 原理 | 时间复杂度 |
|---|---|---|
add(x) |
hash → 定位 → 判重 → 插入 | O(1) |
remove(x) |
hash → 定位 → 遍历匹配 → 删除 | O(1) |
x in s |
hash → 定位 → 遍历匹配 | O(1) |
总结 :Set 的"唯一性"不是靠遍历比较实现的(那样是 O(n)),而是靠 哈希值的快速定位 + 相等性判断 实现的 O(1) 去重。这就是为什么 Set 和 Dict 一样,元素必须是 可哈希的(hashable)------不可哈希就无法计算索引,整个机制就崩了。
3.3 Set 的应用场景
- 数组去重 :
[...new Set(arr)] - 成员检测 :
value in s(Python)/set.has(value)(JavaScript)--- O(1) - 集合运算:交集、并集、差集
javascript
// 数组去重 --- 最优雅的写法
const arr = [1, 2, 2, 3, 3, 3];
const unique = [...new Set(arr)];
console.log(unique); // [1, 2, 3]四、JavaScript 变量提升:经典面试题解析
4.1 函数提升 vs 变量提升
JavaScript 中存在 变量提升(Hoisting) 机制,但函数和变量的提升优先级不同:
函数声明优先于变量声明
看这道经典面试题:
javascript
showName();
var showName = function() {
console.log(2);
}
function showName() {
console.log(1);
}
showName();输出是什么?
解析过程(等价于):
javascript
// 1. 函数声明提升到顶部
function showName() {
console.log(1);
}
// 2. 变量声明提升(但赋值不提升)
var showName; // 此时 showName 已经是函数,var 不会覆盖
showName(); // 输出 1 --- 调用的是函数声明
showName = function() {
console.log(2); // 赋值操作,覆盖了函数
}
showName(); // 输出 2 --- 调用的是函数表达式答案 :先输出 1,再输出 2。
4.2 同名函数的覆盖规则
javascript
function showName() {
console.log("极客时间");
}
showName(); // ?
function showName() {
console.log("极客邦");
}
showName(); // ?规则 :如果定义了两个同名函数,最后一个生效。
💡 常见误区 :很多人以为"变量提升优先于函数",实际上恰恰相反------函数声明优先于变量声明 。这也是为什么上面的
var showName不会覆盖已提升的函数声明。
javascript
// 等价于
function showName() {
console.log("极客邦"); // 后定义的覆盖前面的
}
showName(); // "极客邦"
showName(); // "极客邦"4.3 面试要点总结
| 声明方式 | 提升行为 | 初始值 |
|---|---|---|
function foo() {} |
函数声明整体提升 | 函数本身 |
var foo = function() {} |
仅 var foo 提升 |
undefined |
let/const foo |
暂时性死区(TDZ) | 报错 ReferenceError |
五、Prompt 工程:让 AI 听懂你的话
掌握了数据结构和语言特性,我们来看更上层的应用------如何写好 Prompt,让大模型输出符合预期的结果。
5.1 核心原则一:清晰、具体的指令
❌ 模糊的 Prompt:
帮我写个函数✅ 清晰的 Prompt:
markdown
请用 JavaScript 编写一个函数,功能如下:
1. 函数名:debounce
2. 参数:一个回调函数 fn,延迟时间 delay(毫秒)
3. 功能:在 delay 毫秒内如果重复调用,只执行最后一次
4. 返回值:返回防抖后的函数
5. 请添加中文注释说明核心逻辑要点:
- 提供完整的上下文环境
- 明确输入输出要求
- 指定编程语言和风格
- 说明边界条件
5.2 核心原则二:引导逐步推理(Chain of Thought)
不要一次性要求模型给出最终答案,而是引导它分步思考:
❌ 一次性要求:
这段代码有什么 bug?直接告诉我答案✅ 引导逐步推理:
markdown
请分析以下代码,按以下步骤进行:
1. 首先,逐行阅读代码,理解其意图
2. 然后,检查变量声明和作用域
3. 接着,验证异步逻辑是否正确
4. 最后,总结发现的问题并给出修复方案
代码如下:
[代码内容]5.3 Prompt 模板封装
在实际项目中,我们可以将 Prompt 封装为函数:
python
from openai import OpenAI
client = OpenAI() # 自动读取环境变量 OPENAI_API_KEY
def get_response(prompt, model="gpt-4", temperature=0.7, max_tokens=2000):
"""
封装 LLM API 调用
参数:
- prompt: 提示词
- model: 模型名称
- temperature: 控制随机性(0-1,越低越确定)
- max_tokens: 最大输出长度
"""
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature,
max_tokens=max_tokens
)
return response.choices[0].message.content
# 使用多行字符串模板 --- 变量提前定义
requirement = "实现一个防抖函数"
tech_stack = "JavaScript ES6+"
code_style = "简洁、有注释"
prompt = f"""
你是一位资深前端工程师,请根据以下需求编写代码:
需求:{requirement}
技术栈:{tech_stack}
代码风格:{code_style}
请确保:
1. 代码有完整的注释
2. 处理边界情况
3. 遵循最佳实践
"""
result = get_response(prompt)参数说明:
temperature:控制输出的随机性。0 表示完全确定(适合代码生成),1 表示更随机(适合创意写作)max_tokens:限制输出长度,避免模型"话痨"
六、知识图谱:这些知识点如何串联?
python
数据结构基础
├── Dict(哈希表) → O(1) 查找原理 → Key 唯一性(覆盖机制)
│ ├── Key 必须不可变 → 可变 vs 不可变对象
│ └── Set(无 Value 的 Dict) → hash 去重机制 → hashable 约束
│
├── 内存与性能 → 空间换时间策略
│
└── JavaScript 语言特性
├── 变量提升 → 函数优先于变量
└── 作用域 → 执行上下文
↓ 向上抽象
Prompt 工程
├── 清晰指令 → 结构化输入
├── 逐步推理 → Chain of Thought
└── API 封装 → 参数调优(temperature、max_tokens)七、总结
| 知识点 | 核心要点 | 应用场景 |
|---|---|---|
| Dict / HashTable | 哈希函数 → 索引 → O(1) 查找,Key 唯一(覆盖机制) | 缓存、索引、高频查找 |
| 不可变对象 | Key 必须 hashable,不可变才能保证哈希值稳定 | Dict Key、Set 元素 |
| Set | 无 Value 的 Dict,靠 hash 实现 O(1) 去重 | 数组去重、集合运算、成员检测 |
| 变量提升 | 函数声明 > 变量声明 > 赋值 | 面试题、代码调试 |
| Prompt 设计 | 清晰指令 + 逐步推理 + 参数调优 | AI 应用开发 |
从底层数据结构到上层 AI 应用,这些知识点构成了前端工程师的 完整技术栈。理解原理,才能在面试和实际开发中游刃有余。
💡 思考题 :为什么 JavaScript 的
Object的 key 只能是字符串(或 Symbol),而Map的 key 可以是任意类型?这和 Python 的 hashable 有什么关系?欢迎在评论区讨论!
如果觉得有帮助,别忘了点赞 👍 收藏 ⭐ 关注,后续会持续分享前端 + AI 的技术干货!