作者:来自 Elastic Aris Papadopoulos
ES|QL 现在支持近似查询执行。只需在查询中添加一行代码,就能获得快几个数量级的结果,并内置置信区间,能够准确告诉你这些结果的可信程度。
亲自动手体验 Elasticsearch:深入探索 Elasticsearch Labs 仓库中的示例 notebooks,开始免费的云试用,或立即在你的本地机器上试用 Elastic。
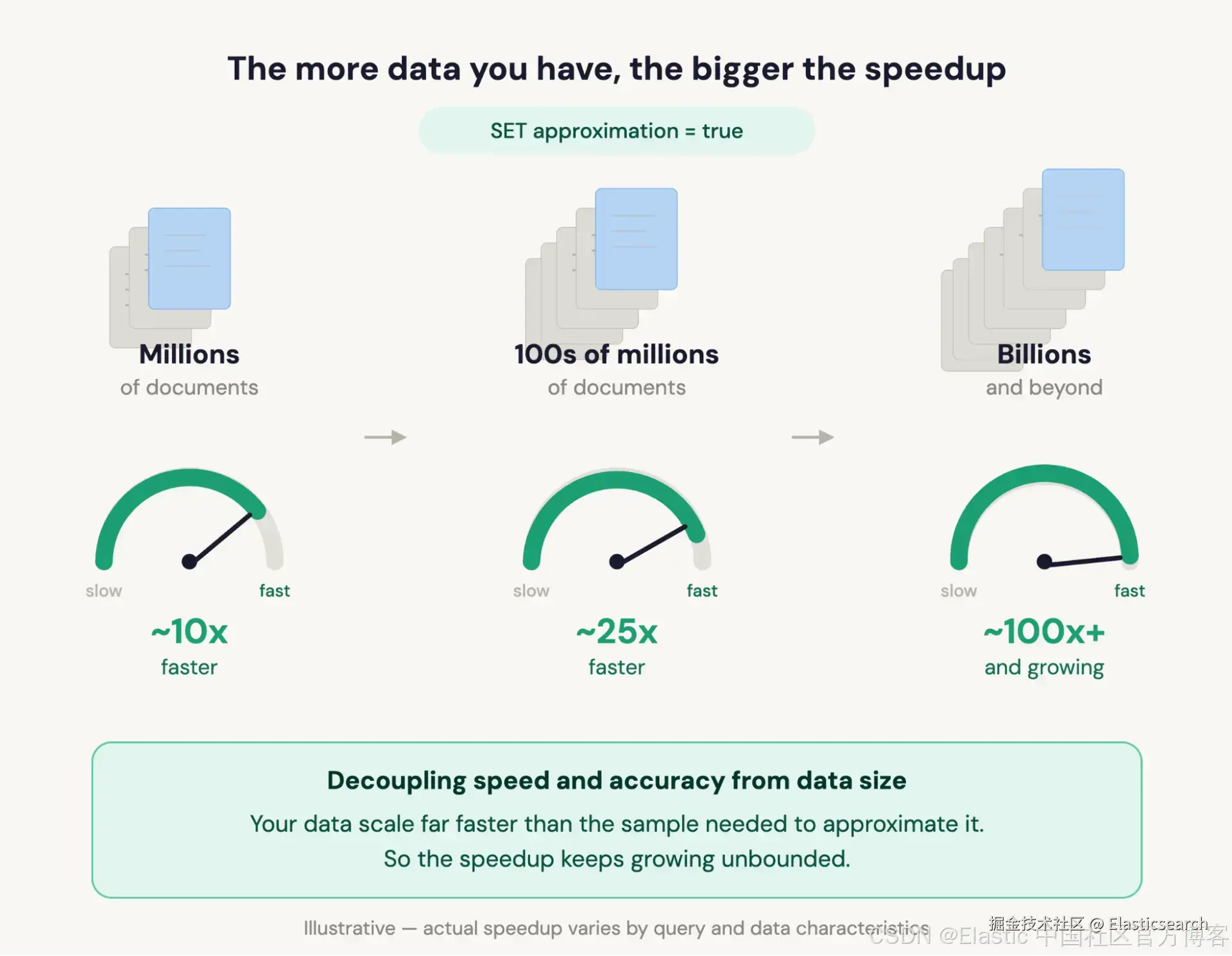
只需为任何 Elasticsearch Query Language ( ES|QL ) 查询添加一行代码,就能在数十亿文档上获得快 100 倍以上的答案。你的收益会随着数据规模增长而增长。内置的置信信号会告诉你结果何时具有正式保证,以及何时只是最佳估计。
一行代码:随数据规模扩展的速度
在数十亿文档上,分析查询会面临真实的效率与精度权衡。我们一直在努力突破这一限制。我们的原生列式支持是业内最优秀的之一。 ES|QL 本身就是一个快速、专为分析打造的引擎,并且在聚合执行方面持续变得更智能。 Elasticsearch 还持续推出稳定的效率创新,例如 Block k-dimensional ( BKD ) tree pruning,并且还有更多优化不断推出。
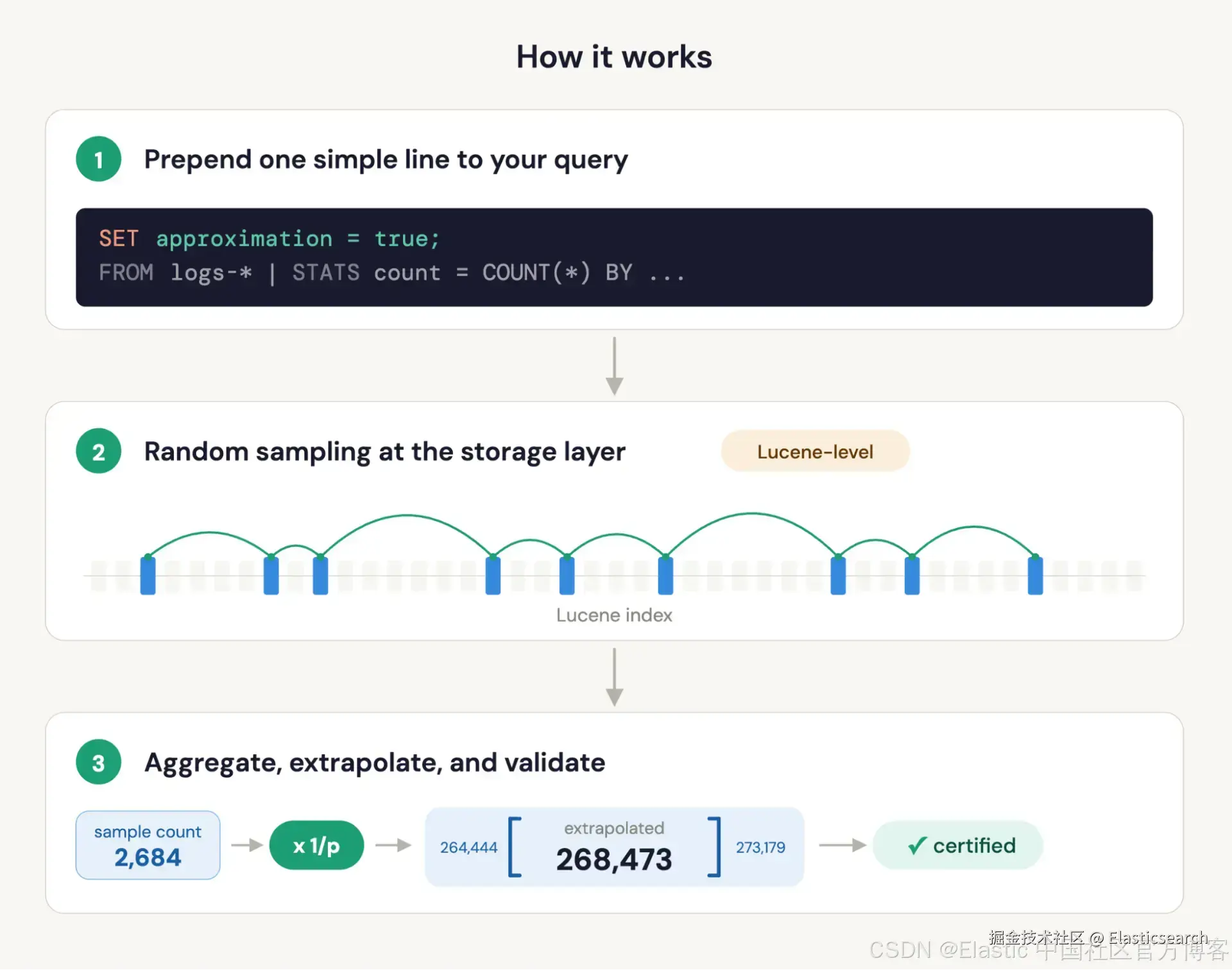
但即使拥有这一切,原生近似查询依然表现得尤为突出。从 Elasticsearch 9.4 开始, ES|QL 支持近似查询执行。你只需要为查询添加一行代码:在前面加上 SET approximation = true。现在 Elasticsearch 会自动对你的部分数据进行采样,在该样本上运行聚合,推算结果,并报告置信区间。整个过程完全透明。
less
`
1. SET approximation = true;
2. FROM logs-*
3. | STATS count = COUNT(*) BY time = BUCKET(@timestamp, 5 MINUTE)
4. | SORT time
`AI写代码你现有的查询保持不变。 SET 指令会告诉 Elasticsearch 为你处理采样、结果推算以及统计验证。无需重写查询,无需手动计算采样数学,也无需猜测采样概率。
SET approximation = true 是一个向前兼容的指令。如今,它能够加速最常使用的聚合。随着我们将支持扩展到更多能力,你现有的查询会自动受益。尚未支持近似执行的查询会继续以精确模式运行,不会报错;同时会通过 warning header 解释原因。
能快多少?
在 ClickBench 基准测试中,表现良好的分析查询在启用置信区间后,平均运行速度提升了 23 倍。单个查询最高可达到约 100 倍。如果禁用置信区间计算,收益最高的查询速度可接近约 300 倍。
你得到的内容
响应会包含你原始的聚合值,并自动缩放以表示完整数据集;在1%样本上的计数返回的是估算后的总数,而不是样本计数。列名和类型都会被保留(向后兼容)。此外,每个近似值还会额外附带两列:
- 置信区间:在配置的置信水平下(默认90%)用于界定真实值的范围。例如,一个计数值为268,473,区间为264,444--273,179,意味着你可以有90%的信心认为真实计数落在该范围内。
- 认证标志:一个布尔值,用于表示该值的置信区间是否满足正式的统计保证。当认证标志为真时,数据分布允许我们直接信赖这些结果。当为假时,近似结果通常依然比较接近,但我们无法提供同等级别的正式保证,这通常是因为数据分布可能高度倾斜,或某个分组中的文档数量过少。你可以把它理解为"统计上已证明"和"最佳估计"之间的区别。

这是一个刻意的设计选择:不关心置信度元数据的使用方,可以选择完全不计算这些信息(见"需要时的细粒度控制"),或者直接忽略额外列,并像以前一样使用结果。
而关心这些信息的使用方(例如程序化读取结果的 AI agent),则可以无需第二次查询就获得所有需要的数据。
ES|QL 近似查询的使用场景:它的重要性体现在哪里
AI agent 和 agentic 工作流
近似查询不仅让 agent 查询更快,还让一种 "先扫描再增强" 的分析模式在大规模数据上首次变得可行。agent 可以在亚秒级时间内扫描数十亿文档,识别候选结果,然后再进一步精确分析,这一切都可以在同一个推理循环中完成。certified 标志将近似结果转化为一个决策信号:当为 true 时可以直接信任结果继续执行;当为 false 且该步骤需要严格保证时,则升级为精确查询。随着 ES|QL 成为 Elastic 中 agentic analytics 的基础,近似计算就是让大规模调查成为可能的速度层。
大规模数据集上的仪表盘和图表
随着数据量增长,覆盖数周或数月数据的仪表盘会变得越来越慢。启用 SET approximation = true 后,同样的仪表盘加载速度会更快。未来 Kibana 将会透明注入该设置,用户甚至不会意识到这一过程;他们只会看到更快的图表。
ES|QL 中的大规模日志模式分析
CATEGORIZE、GROK 以及基于正则的复杂条件是 ES|QL 中计算成本最高的部分,因为它们需要对每条文档进行非平凡计算。在启用近似执行后,这类大规模模式分析和探索工作流可以在超大索引上变得可行。
探索性分析与假设验证
在探索数据以形成假设时,例如 "本周哪些服务的错误率最高?",通常并不需要精确计数,而需要趋势、相对规模和异常点。近似模式可以提供交互级速度的结果,而置信区间则告诉你何时需要切回精确模式以得到最终答案。
ES|QL 近似查询如何工作(不涉及数学)
这种加速来自真实工程实现,而不是查询优化器的技巧。采样发生在 Lucene 层:Elasticsearch 只读取样本中的文档,因此 I/O 和计算开销与采样比例成正比下降。聚合在样本上执行,然后自动缩放以表示完整数据集。
置信区间通过对样本进行多次子分区的 bootstrap 过程计算得出:这是统计上严格的方法,而不是启发式或猜测。这也是 certified 标志的依据:当方法假设成立时,这些区间具有正式统计保证。
一句话:巨幅收益、外推计算、置信信号。
需要细粒度控制时
默认配置是开箱即用的良好选择,但你也可以进行调优:
ini
`
1. SET approximation = {"rows": 500000, "confidence_level": 0.95};
2. FROM logs-*
3. | STATS count = COUNT(*), avg_duration = AVG(duration) BY service.name
`AI写代码- rows:采样多少文档(默认:未分组查询 100,000;分组查询 1,000,000)。rows 越多,精度越高,但运行时间也越长。
- confidence_level:置信区间的置信水平。默认值为 0.9。可以将其设得更高,以提高结果落在置信区间内的概率。
- 跳过置信区间以获得最大速度:将 confidence_level 设置为 null,Elasticsearch 只返回点估计值,在近似执行的基础上还能再获得 2--5 倍速度提升。这也是最高收益查询接近 300x 的原因。
下一步
SET approximation = true 是一个向前兼容的指令。随着我们增加对 FORK、JOIN、链式 STATS 以及更多聚合能力的支持,你现有的查询会自动受益。
未来还将与 Kibana 更紧密集成,使 dashboard 和 Discover 可以自动启用近似模式,并改进对高度偏斜分组字段的处理。
此外,我们也会让近似查询原生可供 agent 使用,使其可以作为分析工具和推理循环的一部分选择高速执行。
开始使用
近似查询已在 Elasticsearch 9.4 中作为 Enterprise 订阅层级的技术预览提供。只需在查询前添加 SET approximation = true; 即可体验差异。更多配置选项请参考 ES|QL SET 命令文档。
常见问题
什么是 Elasticsearch 中的近似查询执行?
近似查询执行是一种模式,Elasticsearch 会对数据进行采样,在样本上执行聚合,然后将结果外推为完整数据集的估计值。返回结果包含估计值以及置信区间,用于表示可信范围。通过在 ES|QL 查询前添加一个 SET 指令即可启用,无需改写查询。
如何在不降低数据保留的情况下加速 ES|QL 聚合?
只需在查询中添加 SET approximation = true。近似执行是在查询时采样,而不是在索引时采样。数据仍然完整保留、完整可查询。你可以随时移除该指令以获得精确结果,底层数据不会发生任何变化。
近似查询能快多少?
在 ClickBench 基准测试中,适合采样的聚合型 ES|QL 查询通常可获得 10--40 倍平均加速,单个查询可达到 100 倍以上。若关闭置信区间计算(SET approximation = {"confidence_level": null}),可在此基础上再获得 2--5 倍提升,因此最高收益可接近 300x。随着数据规模增长,加速优势会进一步扩大。
近似查询的准确性如何?可以信任吗?
每个近似结果都会返回两个信号:置信区间(在设定置信水平下界定真实值范围)以及 certified 布尔标志。当 certified 为 true 时,说明统计假设成立,结果具有正式保证。当为 false 时,结果通常仍然接近,但分布不满足严格假设。精度取决于数据分布与查询形态,而非文档总数。
速度提升取决于什么?
主要有五个因素:
- 数据规模:越大收益越高,因为精确查询随 N 线性增长,而采样查询不随 N 增长。
- 查询形态:大规模 STATS(尤其 MEDIAN、PERCENTILE)收益最大;本身就很轻的查询收益较小。
- 分组基数与分布:均匀分布的 BY 字段收益更稳定;长尾或高度稀疏分组会削弱收益。
- 置信区间计算:计算 interval 会带来额外开销,设为 null 可再获得 2--5 倍加速。
- 采样大小:默认值(无分组 100k,分组 1M)在大多数场景下表现良好;增大提升精度,减小提升速度。
可以用于日志分析和模式识别吗?
可以。CATEGORIZE、GROK 和正则匹配是 ES|QL 中最耗算力的操作之一。启用近似执行后,这些操作只在采样数据上运行,使超大规模日志分析和探索变得可行。
是否需要重写查询?
不需要。只需在现有 ES|QL 查询前加上 SET approximation = true。表达式、列名和返回结构保持不变,只是额外增加两列(置信区间与 certified 标志)。
支持哪些聚合?
COUNT、SUM、AVG、WEIGHTED_AVG、MEDIAN、PERCENTILE(不含极值)、MEDIAN_ABSOLUTE_DEVIATION、STD_DEV(在高偏态分布下有一定限制)等,后续还会扩展。
同一查询结果会完全一致吗?
不会。由于每次查询都会重新采样,同一查询的结果会有轻微差异,但变化通常远小于置信区间本身。如果需要完全一致性,应使用精确查询;用于 dashboard 时,这种波动通常低于可视化误差。