作者:来自 Elastic Ed Savage

完全使用 Terraform 构建和管理 Elastic 异常检测作业(作业配置、数据馈送、生命周期状态以及环境晋升),并提供一个模块化、可直接克隆的示例。
使用实时问题检测和可操作的建议来简化你的 Elasticsearch 运维,从而优化性能并降低成本。 AutoOps 可用于云端和自管理部署。了解更多 AutoOps 。
手动创建的异常检测作业不会进行版本管理、不会经过审查,也无法在不同环境之间干净地进行晋升。本文展示如何将完整的 AD 生命周期(作业、数据馈送以及运行状态)作为 Terraform 代码进行管理。六个资源,一次 terraform apply,你的作业即可运行。修改一个变量即可将其从开发环境晋升到生产环境。 terraform destroy 则会按照正确顺序将其全部删除。
完整且可直接克隆的代码可在 github.com/elastic/terraform-ad-example 获取。
前提条件
-
一个 Elastic Cloud 账户,并拥有组织级 API 密钥。有关可用区域和模板,请参阅 Elastic Cloud 区域、部署模板和实例。
-
已安装 Terraform(>= 1.0.0)。异常检测( AD )作业和数据馈送资源支持需要 Elastic Stack Provider 0.14.0 或更高版本。请参阅安装 Terraform。
-
在包含 git 仓库 github.com/elastic/terraform-ad-example 克隆副本的目录中打开终端。
-
在部署完成后, Elasticsearch 集群中应存在一个适用于 AD 作业的有效索引(即包含时间戳字段)。在本示例中,索引为
filebeat-nginx-elasticco-full。
用于异常检测的 Terraform 项目结构
模块化布局意味着每个资源都有自己的模块,因此作业配置、数据馈送和状态控制器可以在团队之间独立共享和复用。
.
├── main.tf # Root: providers, variables, module calls
└── modules/
├── job/
│ ├── main.tf # AD job resource
│ ├── variables.tf # Job parameters
│ └── outputs.tf # Exports job_id
├── datafeed/
│ ├── main.tf # Datafeed resource
│ ├── variables.tf # Datafeed parameters
│ └── outputs.tf # Exports datafeed_id
├── job_state/
│ ├── main.tf # Job state resource (open / close)
│ ├── variables.tf # State parameters
│ └── outputs.tf # Exports state
└── datafeed_state/
├── main.tf # Datafeed state resource (start / stop)
├── variables.tf # State parameters
└── outputs.tf # Exports state输出( Outputs )是关键:它们允许模块进行链式连接,从而使数据馈送能够自动接收来自作业模块的 job_id,并且 Terraform 会根据这一依赖关系图推导出正确的创建和销毁顺序。
为什么要在 Terraform ML 作业中将状态与配置分离?
请注意,状态模块与配置模块是分开的。这反映了机器学习( ML )中的一种真实运维模式:你经常需要停止数据馈送(例如,为了重新索引数据),或者关闭作业(例如,在数据管道事故后重置模型),而完全不需要修改作业配置。
将它们分离意味着运维操作不会在配置资源中产生无意义的差异( diff ),从而使配置变更更加清晰和可管理。
在 Terraform 中配置 Elastic Cloud 部署
Provider 与部署
我们使用两个 Provider:
-
elastic/ec用于配置 Elastic Cloud 部署; -
elastic/elasticstack用于管理部署内部的 ML 资源。
elasticstack Provider 的连接信息直接来源于 ec_deployment 资源,因此无需硬编码任何凭据:
terraform {
required_version = ">= 1.0.0"
required_providers {
ec = {
source = "elastic/ec"
version = "~> 0.9"
}
elasticstack = {
source = "elastic/elasticstack"
version = "~> 0.14.3"
}
}
}
variable "ec_api_key" {
type = string
description = "Elastic Cloud API key (account-level)."
}
variable "ec_region" {
type = string
default = "us-east-1"
description = "Elastic Cloud region (e.g. us-east-1, gcp-us-central1)."
}
variable "deployment_template_id" {
type = string
default = "aws-cpu-optimized-faster-warm-arm"
description = "Elastic Cloud deployment template ID."
}
variable "job_id" {
description = "The ID of the anomaly detection job."
type = string
default = "nginx"
}
variable "datafeed_id" {
description = "The ID of the datafeed."
type = string
default = "datafeed-nginx"
}
variable "indices" {
description = "A list of indices for the datafeed (may include wildcards)."
type = list(string)
default = ["filebeat-nginx-elasticco-full"]
}部署本身会配置 Elasticsearch(包含一个专用 ML 节点)以及 Kibana:
provider "ec" {
apikey = var.ec_api_key
}
data "ec_stack" "latest" {
version_regex = "latest"
region = var.ec_region
}
resource "ec_deployment" "demo" {
name = "ml_terraform_example"
region = var.ec_region
version = data.ec_stack.latest.version
deployment_template_id = var.deployment_template_id
elasticsearch = {
hot = {
autoscaling = {}
}
ml = {
size = "1g"
size_resource = "memory"
zone_count = 1
autoscaling = {}
}
}
kibana = {
topology = {}
}
}
provider "elasticstack" {
elasticsearch {
username = ec_deployment.demo.elasticsearch_username
password = ec_deployment.demo.elasticsearch_password
endpoints = [ec_deployment.demo.elasticsearch.https_endpoint]
}
kibana {
endpoints = [ec_deployment.demo.kibana.https_endpoint]
}
}elasticsearch 中的 ml 块至关重要;它会配置一个专用的 ML 节点。没有它,ML 作业将无法打开。
这里我们在单个可用区中分配了 1 GB 内存,这对于本示例已经足够。根据你的 AD 作业特性以及数据规模,你可能需要为 ML 节点配置不同的资源规格。
由于 elasticstack Provider 直接引用 ec_deployment.demo, Terraform 能够理解这种依赖关系:它会先配置部署,然后自动使用生成的凭据和端点。
将各个模块连接起来
module "job" {
source = "./modules/job"
job_id = var.job_id
}
module "datafeed" {
source = "./modules/datafeed"
datafeed_id = var.datafeed_id
job_id = module.job.job_id
indices = var.indices
}
module "job_state" {
source = "./modules/job_state"
job_id = module.job.job_id
state = "closed"
}
module "datafeed_state" {
source = "./modules/datafeed_state"
datafeed_id = module.datafeed.datafeed_id
state = "stopped"
depends_on = [module.job_state]
}输出引用( module.job.job_id、module.datafeed.datafeed_id )会创建一个隐式依赖关系图: Terraform 始终会先创建作业,再创建数据馈送,然后再创建其状态资源。在执行销毁时,顺序会自动反转。
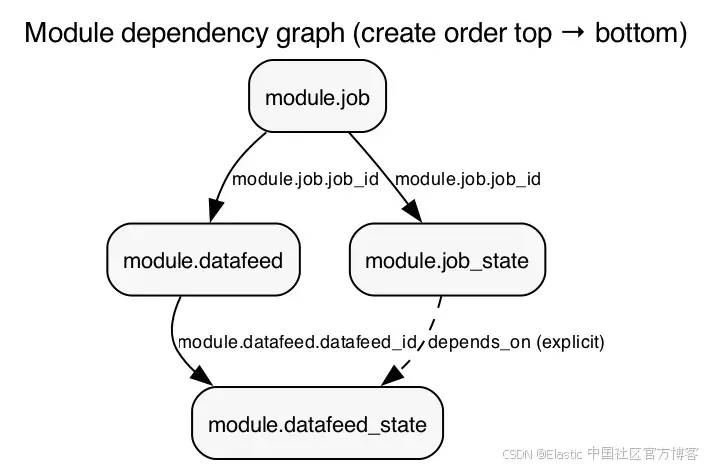
在下图中,实线箭头表示当一个模块的输出作为另一个模块的输入时所形成的隐式依赖关系图 。相对地,job_state 与 datafeed_state 之间的虚线箭头表示在根 main.tf 中定义的显式 depends_on 依赖关系。
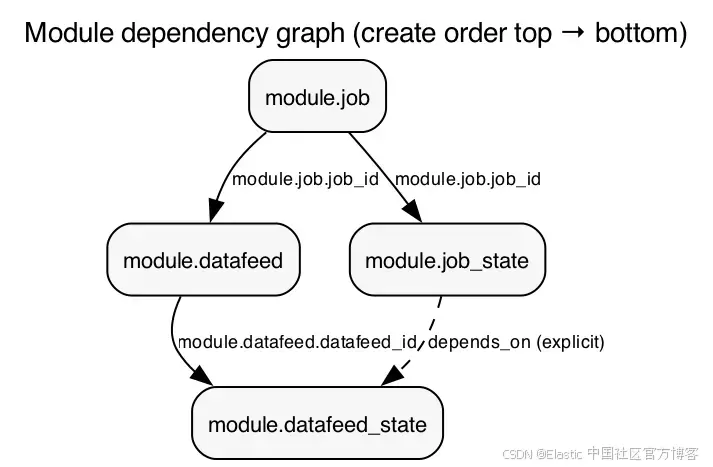
module.datafeed_state 上的显式 depends_on 值得进一步说明:数据馈送状态模块与作业状态模块之间并不存在数据流依赖,但 Elasticsearch API 要求在启动数据馈送之前,作业必须已经处于打开状态。
如果没有这个依赖关系, Terraform 会尝试并行执行两者,而这将导致操作失败。
我们首先将作业设置为 "closed",将数据馈送设置为 "stopped"。在后续步骤中,我们会打开并启动它们,以演示生命周期管理。
模块:异常检测作业
作业模块用于定义 AD 作业配置。下面是资源本身( modules/job/main.tf ):
resource "elasticstack_elasticsearch_ml_anomaly_detection_job" "nginx" {
job_id = var.job_id
description = "Anomaly detection for network traffic"
custom_settings = jsonencode(var.custom_settings)
analysis_config = {
bucket_span = "15m"
detectors = [
{
function = "count"
detector_description = "count"
},
{
function = "mean"
field_name = "nginx.access.body_sent.bytes"
detector_description = "mean(\"nginx.access.body_sent.bytes\")"
}
]
influencers = ["nginx.access.geoip.city_name", "nginx.access.user_agent.build"]
model_prune_window = "30d"
}
analysis_limits = {
model_memory_limit = var.analysis_limits.model_memory_limit
categorization_examples_limit = var.analysis_limits.categorization_examples_limit
}
data_description = {
time_field = "@timestamp"
time_format = "epoch_ms"
}
model_snapshot_retention_days = var.model_snapshot_retention_days
daily_model_snapshot_retention_after_days = var.daily_model_snapshot_retention_after_days
}关于模块复用,有几点值得注意:
-
Elasticsearch 作业 API 会在一个名为 custom_settings 的 JSON 对象中存储任意元数据。在这个模块中,该对象就是你传入的 Terraform 变量
custom_settings:资源会设置custom_settings = jsonencode(var.custom_settings),因此集群接收到的是该 map 的 JSON 编码结果。因此,variables.tf中定义的默认值实际上就是默认元数据(created_by = "terraform"和department = "ITOps"),除非调用方在使用模块时覆盖custom_settings(例如,在导入一个 Terraform 之外创建的遗留作业时,用于记录归属信息)。 -
同样的模式也适用于其他可调参数:
analysis_limits、model_snapshot_retention_days和daily_model_snapshot_retention_after_days都是带默认值的变量,因此模块可以开箱即用,同时团队也可以在调用时进行覆盖(例如,为高基数作业提高model_memory_limit)。
| 变量 | 默认值 | 用途** |
|---|---|---|
| custom_settings | created_by = "terraform" | 任意作业元数据;可覆盖以记录所有权 |
| analysis_limits.model_memory_limit | (见 variables.tf) | 用于高基数作业的性能调优 |
| model_snapshot_retention_days | (见 variables.tf) | 模型快照的保留周期 |
完整的变量定义和输出都在 GitHub 仓库中。
模块:数据馈送
数据馈送模块将索引模式连接到 AD 作业,并且是服务团队进行参数化配置的主要入口点。(modules/datafeed/main.tf):
resource "elasticstack_elasticsearch_ml_datafeed" "this" {
datafeed_id = var.datafeed_id
job_id = var.job_id
query = jsonencode({
bool = {
must = [{ match_all = {} }]
}
})
indices = var.indices
}indices 变量是最关键的参数化入口点;每个服务团队在调用该模块时都会传入各自的索引模式。
模块:作业状态与数据馈送状态
作业状态和数据馈送状态由独立的模块进行管理,因此运维操作(停止数据馈送、关闭作业)不需要执行配置计划(config plan)即可完成。
# modules/job_state/main.tf
resource "elasticstack_elasticsearch_ml_job_state" "this" {
job_id = var.job_id
state = var.state # "opened" or "closed"
job_timeout = var.job_timeout # default: "30s"
}
# modules/datafeed_state/main.tf
resource "elasticstack_elasticsearch_ml_datafeed_state" "this" {
datafeed_id = var.datafeed_id
state = var.state # "started" or "stopped"
force = var.force # default: false
datafeed_timeout = var.datafeed_timeout # default: "60s"
}如何运行并应用 anomaly detection Terraform 配置
设置你的 API key 并初始化
export TF_VAR_ec_api_key="your-elastic-cloud-api-key-here"
terraform init该仓库还包含一个用于管理密钥的 elastic-env.sh 辅助脚本。详情请参阅 README。
执行 plan 并创建资源
terraform planplan 会显示将要创建的全部六个资源:
-
Elastic Cloud 部署。
-
AD 作业。
-
数据馈送。
-
两个状态资源。
-
用于批量写入的作用域 API key。
请仔细查看输出;这正是 Terraform 最强大的能力之一。下面是关键部分:
Plan: 6 to add, 0 to change, 0 to destroy.确认无误后,执行 apply:
terraform apply
ec_deployment.demo: Creating...
ec_deployment.demo: Creation complete after 1m54s
elasticstack_elasticsearch_security_api_key.bulk_ingest: Creating...
module.job.elasticstack_elasticsearch_ml_anomaly_detection_job.nginx: Creation complete after 0s
elasticstack_elasticsearch_security_api_key.bulk_ingest: Creation complete after 0s
module.job_state.elasticstack_..._job_state.this: Creation complete after 0s
module.datafeed.elasticstack_..._datafeed.this: Creation complete after 0s
module.datafeed_state.elasticstack_..._datafeed_state.this: Creation complete after 0s
Apply complete! Resources: 6 added, 0 changed, 0 destroyed.注意创建顺序:
-
deployment 首先创建(约 ~2 minutes)。
-
然后 API key。
-
然后 AD job。
-
然后 datafeed 和 job state 并行创建。
-
最后是 datafeed state。
Terraform 自动从依赖关系图中推导出这一顺序:
此时,你可以在 Kibana 的 ML UI 中确认该作业已经存在;nginx 作业会以 closed 状态显示。
加载示例数据
最初的 terraform apply 还会创建一个用于批量写入(bulk ingestion)的受限 Elasticsearch API key。我们可以使用它来加载一些测试数据。
该 GitHub 仓库中包含一个文件(sample_data.ndjson),里面有少量示例文档,这些文档匹配该作业期望的字段(@timestamp、nginx.access.body_sent.bytes),以及 influencer 字段:nginx.access.geoip.city_name 和 nginx.access.user_agent.build。
可以通过 Elasticsearch _bulk API 将其加载到部署中:
ES_URL=$(terraform output -raw elasticsearch_https_endpoint)
ES_API_KEY=$(terraform output -raw elasticsearch_api_key 2>/dev/null)
curl -s -XPOST "${ES_URL}/_bulk" \
-H "Authorization: ApiKey ${ES_API_KEY}" \
-H "Content-Type: application/x-ndjson" \
--data-binary @sample_data.ndjson在实际使用中,你需要更多的数据(跨越数周或数月的数百到数千条文档),才能让异常检测模型学习到有意义的基线;这个示例数据仅用于验证整个 pipeline 是否端到端正常工作。
打开作业
修改 job_state 模块调用中的 state 参数(定义在顶层 main.tf 文件中):
module "job_state" {
source = "./modules/job_state"
job_id = module.job.job_id
state = "opened" # was "closed"
}
terraform applyTerraform 只会更新作业状态资源;作业配置和数据馈送不会被修改:
Apply complete! Resources: 0 added, 1 changed, 0 destroyed.启动数据馈送
同样地,更新数据馈送状态:
module "datafeed_state" {
source = "./modules/datafeed_state"
datafeed_id = module.datafeed.datafeed_id
state = "started" # was "stopped"
depends_on = [module.job_state]
}
terraform apply此时数据馈送已经在运行。由于我们没有指定开始或结束时间,它会处理索引中所有可用的数据,并会持续实时轮询新的数据。
清理(Cleaning up)
当你完成后,只需一个命令即可按正确的逆序销毁所有资源:
-
先销毁 datafeed state。
-
然后是 job state。
-
再是 datafeed。
-
然后是 job。
-
接着是 API key。
-
最后是 deployment:
terraform destroy
Destroy complete! Resources: 6 destroyed.
如何使用 Terraform 将异常检测作业从开发环境晋升到生产环境?
在这种模块化结构下,将作业从 dev 晋升到 production 不再是手动迁移,而只是一次变量修改。平台团队会先在 dev 集群中验证该作业,然后只需更新一个变量:
# terraform.tfvars (or a workspace-specific file)
ec_region = "us-west-2" # production region
indices = ["filebeat-nginx-prod-*"]相同的 Terraform 配置、相同的模块、相同的审查流程,只是参数不同。
在实际操作中,你会为不同环境使用独立的 Terraform workspaces 或 .tfvars 文件,并将其接入 CI/CD pipeline(持续集成与持续交付)流程。
如何将已有的异常检测作业导入 Terraform?
如果你已经有通过 UI 或 API 创建并运行的 AD 作业,provider 支持将它们导入 Terraform state:
terraform import module.job.elasticstack_elasticsearch_ml_anomaly_detection_job.nginx <deployment_id>/nginx该内容让你可以在不重新创建资源的情况下,逐步将旧有的作业纳入 Terraform 管理。
接下来
未来版本的 Elasticsearch Terraform provider 将增加对 ML calendars 和 filters 资源的支持。在此期间,这种模块化模式可以扩展,用于与 AD 作业一起管理其他 Elasticsearch 资源。
为了体验完整能力,请升级到 9.3(或更高版本)或开始 Elastic Security 免费试用。如果你同时在管理检测规则,可以参考使用 Terraform 管理 Elastic Security 检测规则。
资源
常见问题
如何使用 Terraform 管理 Elastic 异常检测作业?
使用 Elastic Stack Terraform provider(0.14.0 或更高版本),其中包含异常检测作业(elasticstack_elasticsearch_ml_anomaly_detection_job)、数据馈送以及其运行状态的原生资源。一次 terraform apply 会按正确依赖顺序创建作业、数据馈送及所有状态资源。
为什么要在 Terraform 中将异常检测作业状态与配置分离?
作业状态(open/closed)和数据馈送状态(started/stopped)在日常运维中会频繁变化(例如重新索引、模型重置、pipeline 事故),但不会改变配置本身。将它们拆分成独立模块可以避免这些操作在配置资源中产生 diff,也不需要完整 config plan。
如何将已有 Elastic 异常检测作业导入 Terraform 而不重新创建?
可以。Elastic Stack Terraform provider 支持使用 terraform import 导入已有 AD 作业。运行 terraform import module.job.elasticstack_elasticsearch_ml_anomaly_detection_job.nginx <deployment_id>/nginx,即可将 Kibana UI 或 Elasticsearch API 创建的作业纳入 Terraform 管理,而无需删除重建。
如何使用 Terraform 将异常检测作业从 dev 晋升到 production?
在模块化 Terraform 结构中,环境晋升只是变量变化。更新 .tfvars 文件或 workspace 变量中的 ec_region 和 indices,然后在生产集群上执行 terraform apply。相同的经过审查的配置在不同环境中运行:无需手动迁移,也无需 UI 操作。
Terraform 管理 Elastic anomaly detection 时需要多大的 ML 节点?
示例在单个可用区中分配 1 GB 内存,适用于低基数 AD 作业。更高基数或更大数据集需要在 Elasticsearch 资源的 ml block 中增加 size,同时 job module 中的 model_memory_limit 是主要调优参数。
为什么 Elasticsearch Terraform provider 需要在 datafeed state 和 job state 之间显式 depends_on?
Elasticsearch API 要求在启动 datafeed 之前 job 必须处于 open 状态。由于两个 state module 之间没有数据流依赖,否则 Terraform 可能并行执行并失败。root main.tf 中的 depends_on = [module.job_state] 强制执行正确顺序。
Elastic Cloud Terraform provider 和 Elastic Stack Terraform provider 有什么区别?
elastic/ec 用于配置 Elastic Cloud 基础设施(deployment、节点拓扑、region)。elastic/elasticstack 用于管理运行中的 Elasticsearch 集群资源(ML jobs、datafeeds、security API keys、index settings)。典型方案会同时使用两者:ec 创建部署,elasticstack 配置集群,并自动传递凭据。
这篇内容对你有多大帮助?
原文:Elastic anomaly detection in Terraform: a modular example - Elasticsearch Labs