我统计了一下,大概是 300 行废话
情绪 Dashboard 上线之后,我加了一个功能:用卫星遥感图像做农产品的区域监测。YOLO 检测农田边界、识别作物覆盖类型,模型本身跑得挺好。
但模型之外的事情让我想骂人。
画 bounding box,要写。把检测结果格式化,要写。多帧追踪同一块农田,要写。按区域统计覆盖率,要写。输出带标注的视频,又要写。
每件事单独拿出来都不难,加在一起大概 300 行,全是"把模型输出变成可用结果"的胶水代码。
最烦的不是写,是每个项目都要重新写一遍。
这两天 GitHub Trending 日榜第一蹦出来:supervision,Roboflow 出品,副标题一句话------
"democratising computer vision"
PyPI 月下载量:1.1M。
我看到 1.1M 这个数字愣了一秒,因为这个体量意味着大概整个用 Python 做计算机视觉的圈子里,有相当比例的人在用同一个包处理同一类问题。
点进 README,第一行代码示例里,我之前花了大概 40 分钟写的 bounding box 标注逻辑,用 supervision 是三行。
我往椅背上靠了一下,回想了一下过去写的那 300 行胶水代码。
属于是把自己架空了。
这个项目目前搭配claude code使用,国内订阅确实有点困难。给大家参考一个网站:claudemax.shop
先说结论
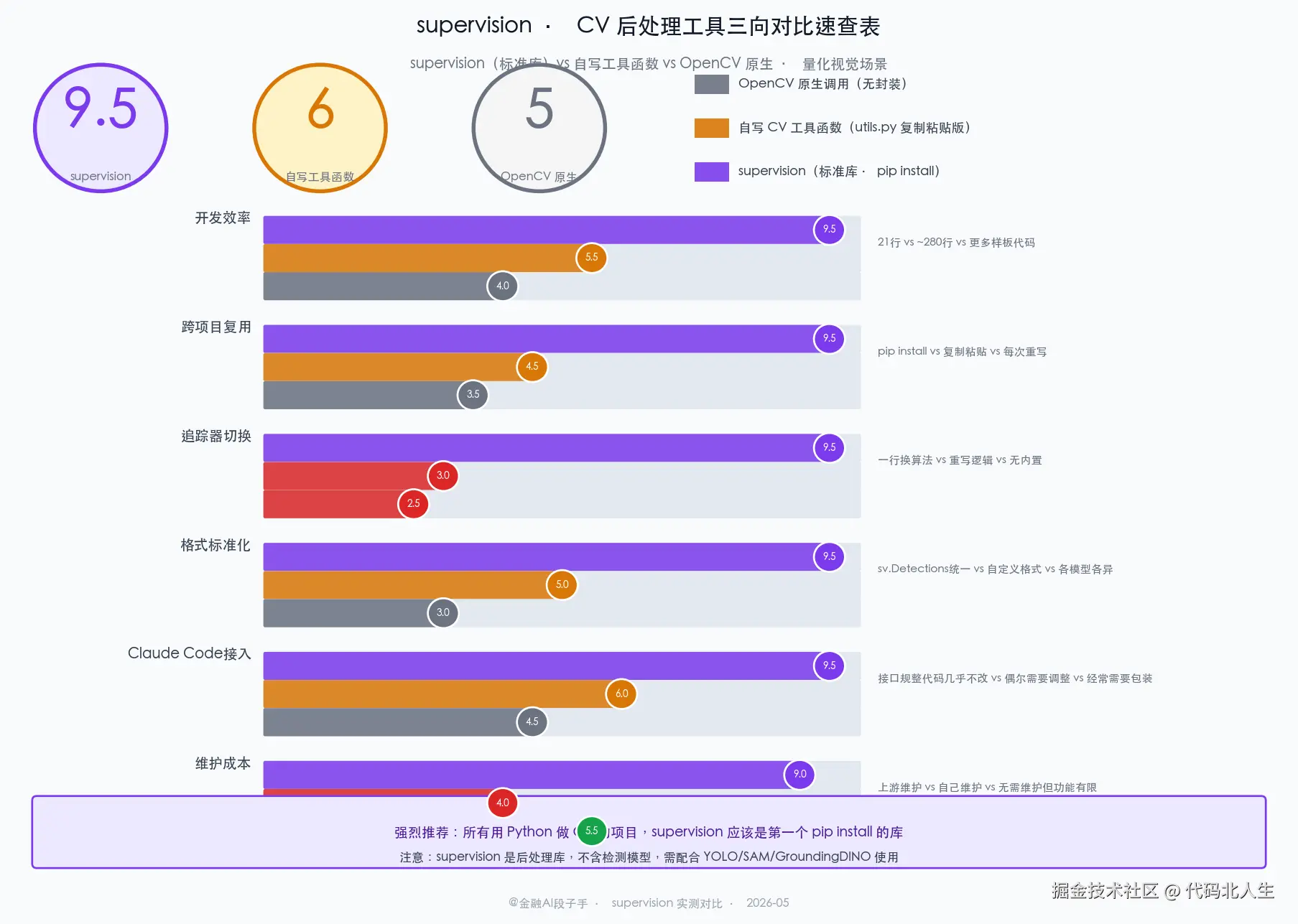
评分:9.5 / 10。用 Python 做计算机视觉的,不管什么场景,pip install supervision 这条命令应该出现在你每个项目的第一步。
用了两周,几个关键数字:
- 替代掉我自己维护的 CV 工具函数:约 280 行胶水代码 → 21 行 supervision 调用
- 多目标追踪接入:从"查文档 + 调 ByteTrack 参数"到"换一行 tracker 初始化代码"
- 与 Claude Code 的配合:supervision 输出的数据结构标准化程度很高,Claude Code 生成的接入代码几乎不需要修改
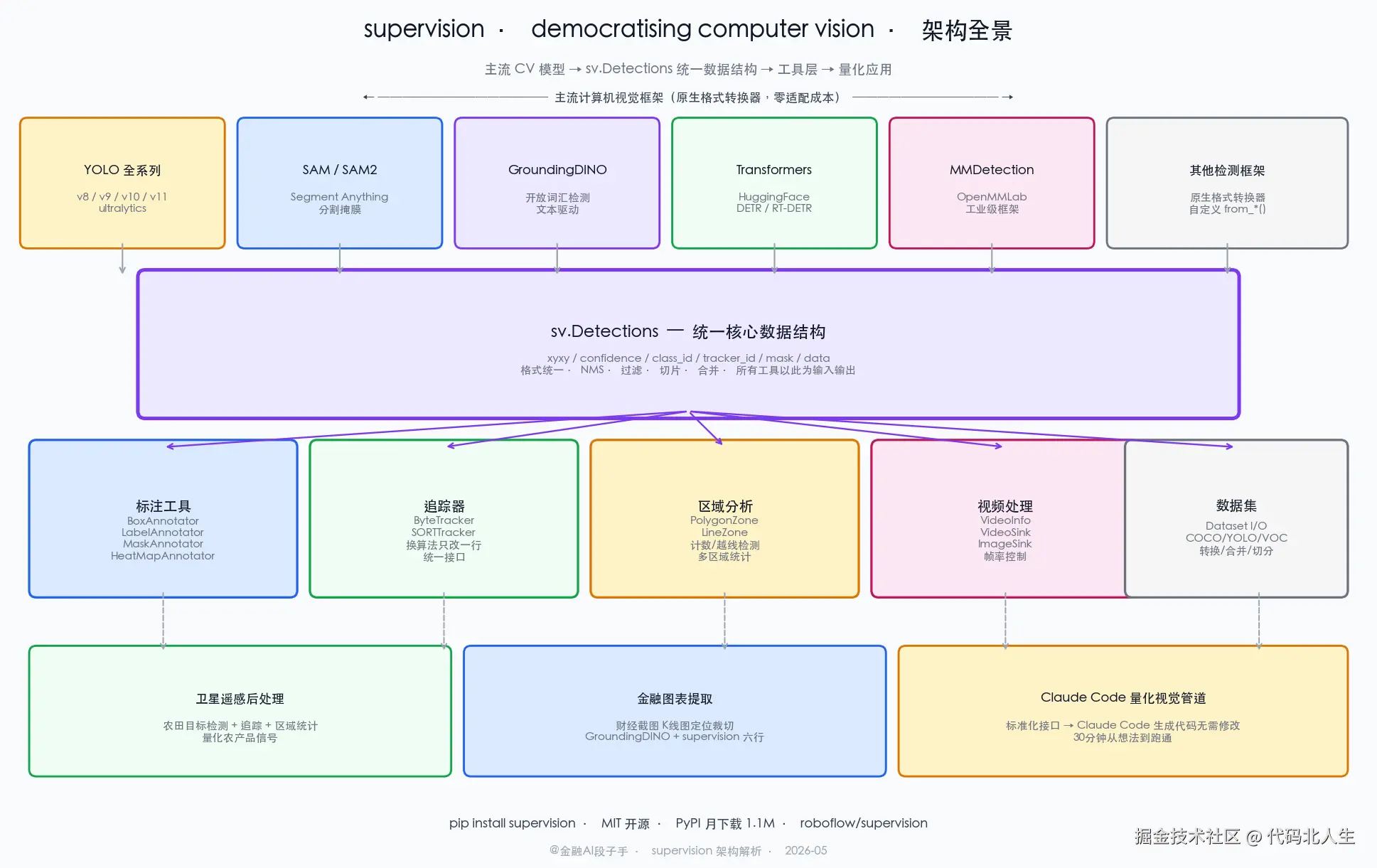
唯一的但是:它是后处理工具库,不包含模型本身。你还是得自己搞 YOLO / SAM / GroundingDINO,supervision 负责"模型输出之后的所有事情"。
先跑起来
pip install supervision装完,用三行代码画出你人生中第一个用 supervision 的 bounding box:
ini
import supervision as sv
detections = sv.Detections(xyxy=boxes, confidence=scores, class_id=class_ids)
annotator = sv.BoxAnnotator()
frame = annotator.annotate(scene=frame, detections=detections)就这样。模型跑完,把结果塞进 sv.Detections,剩下的交给 supervision。
支持 YOLO 全系列、SAM、GroundingDINO、Transformers、MMDetection......主流检测框架的输出格式 supervision 基本都有原生转换器,不需要手写格式转换代码。
它把什么问题解决了
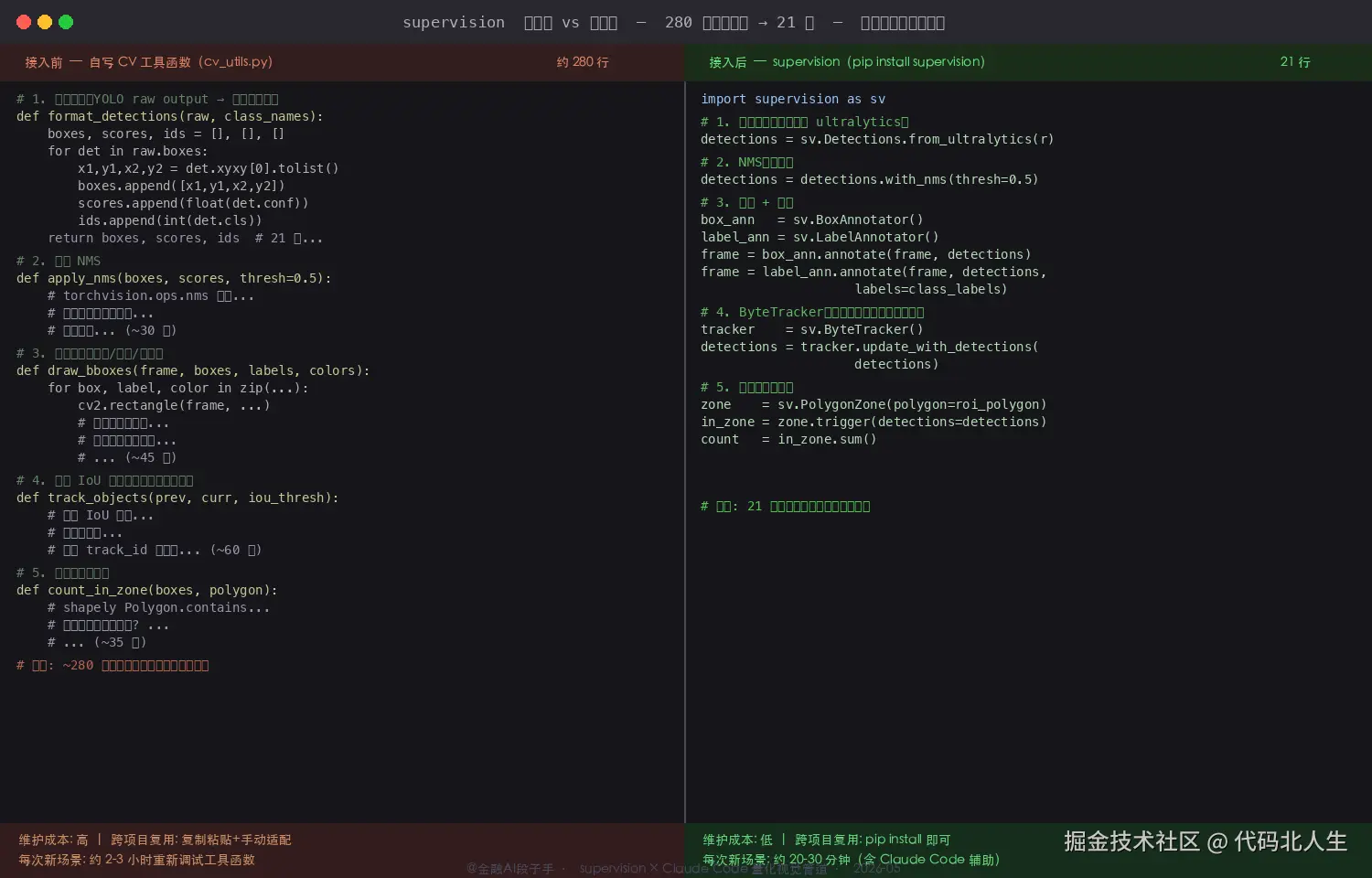
300 行胶水代码,压缩成 21 行
这不是夸张,我做了实际统计。
之前我的卫星遥感后处理模块里,有这些自己手写的工具函数:
draw_bboxes(frame, boxes, labels, colors)--- 画框,处理颜色映射,处理标签位置溢出apply_nms(boxes, scores, iou_threshold)--- 手动实现 NMS,因为不同模型输出格式不同format_detections(raw_output, class_names)--- 把 YOLO 输出格式化成自己的数据结构track_objects(detections_history, current)--- 手撸的 IoU 追踪,逻辑很脆count_in_zone(detections, polygon_zone)--- 按多边形区域统计检测数量
全部加起来,约 280 行。每次新项目就把这个文件复制过去,然后发现新场景里有些地方对不上,再改。改了这个项目的,下个项目又是旧版本。
换成 supervision 之后,这五件事的代码量:
ini
import supervision as sv
# 1. 格式转换(从 ultralytics 输出直接转)
detections = sv.Detections.from_ultralytics(result)
# 2. NMS(一行)
detections = detections.with_nms(threshold=0.5)
# 3. 画框 + 标签
box_ann = sv.BoxAnnotator()
label_ann = sv.LabelAnnotator()
frame = box_ann.annotate(frame, detections)
frame = label_ann.annotate(frame, detections, labels=[...])
# 4. 追踪(换一行就换算法)
tracker = sv.ByteTracker()
detections = tracker.update_with_detections(detections)
# 5. 区域统计
zone = sv.PolygonZone(polygon=roi_polygon)
in_zone = zone.trigger(detections=detections)21 行,包括注释。原来 280 行。
这个压缩比是因为 supervision 把这些模式封装得非常标准------sv.Detections 是整个库的核心数据结构,所有工具都围绕它转,格式一致,没有阻抗。
多目标追踪:换算法只改一行
这是让我实际感受到"工程质量"的功能。
卫星遥感场景里,我需要追踪农田里的移动农机------不同时间点的卫星过境,把同一台农机的检测框关联起来,估算作业进度。
之前的方案是手撸 IoU 追踪,简单但脆,遮挡一下就追丢。改成 ByteTracker 之前,我花了大概半天时间搭环境、理解参数、调 track_thresh / match_thresh / frame_rate......
supervision 里,ByteTracker 是一行初始化:
ini
tracker = sv.ByteTracker(
track_activation_threshold=0.25,
lost_track_buffer=30,
minimum_matching_threshold=0.8
)更关键的是:如果我想换成 SORT 或者其他追踪器,只改这一行。追踪器接口是统一的,tracker.update_with_detections(detections) 这个调用不变。
这才是库设计层面真正有价值的地方------不是给你一个算法,是给你一套可替换的算法接口。换算法成本接近零,你可以真正做实验而不是做迁移。
接进金融图表处理管道:意外的好用
这个场景我没预料到,但测了一下效果不错,值得单独说。
情绪 Dashboard 有一个需求:自动提取财经新闻截图里的 K 线图位置,裁出来喂给 Kronos 分析。以前这步是手动的,或者用 OpenCV 写了一堆边缘检测 + 轮廓提取的代码,很脆。
换成 supervision + GroundingDINO 的方案:
ini
# GroundingDINO 检测"K-line chart"区域
result = grounding_dino.predict("K-line chart", image)
detections = sv.Detections.from_groundingdino(result)
# 按置信度过滤 + 裁图
detections = detections[detections.confidence > 0.6]
charts = [sv.crop_image(image, box) for box in detections.xyxy]六行,把 K 线图从任意财经截图里裁出来,准确率比我之前的 OpenCV 方案高不少。
Claude Code 帮我把这个接进了 Dashboard 的图像处理管道,前后花了大概 20 分钟。supervision 的数据结构标准,Claude Code 生成的接入代码几乎不需要改------这个配合比我预期的顺。
1.1M 月下载背后的设计哲学
这个数字值得认真看一下。
PyPI 上月下载量过百万的 Python 包不多。能到这个量级,要么是基础设施(requests、numpy),要么是解决了一个极高频的真实痛点。
supervision 属于后者。
它瞄准的是"每个做 CV 的人都在写、但没有一个人想再写的那些代码"。画框、格式转换、追踪、区域统计、视频处理......这些东西不复杂,但零散、重复、难以维护。没有 supervision 之前,每个人都有一个自己的 utils.py,代码质量参差不齐,跨项目没法复用。
supervision 做的事是定义标准 ------sv.Detections 是什么,各种标注器怎么接口,追踪器怎么接口------然后用这个标准把整个 CV 后处理生态连起来。
1.1M/月的下载量告诉你:整个 CV 圈子接受了这个标准。
这件事 Roboflow 做对了。
说实话,也有几个坑
它不包含模型,只做后处理。 这既是设计选择,也是使用门槛------你得先搞定检测模型(YOLO 安装、权重下载、推理环境),supervision 才有发挥的空间。对纯 Python 背景、没接触过 CV 模型的人,上手顺序不能搞反。
视频处理 API 变化较快。 v0.28.0 里视频相关的部分跟几个版本前有 breaking changes,如果你在网上找到一年以前的教程,代码很可能直接跑不起来。建议认准官方文档,不要依赖第三方博客代码。
GPU 依赖通过模型传导,不能省。 supervision 本身是纯 Python,对 GPU 没有要求,但你接的检测模型通常需要 CUDA。如果是 CPU-only 的部署环境,检测速度会是瓶颈,supervision 这层不是瓶颈所在。
标注样式自定义有时需要查文档。 LabelAnnotator 的字体、颜色、位置选项比较多,想做非默认样式需要查 API 文档,不是很直觉。不算大问题,但第一次用的时候会花一点时间。
对量化和金融 AI 程序员意味着什么
计算机视觉进量化这件事,在往前走。
卫星遥感信号、财经新闻截图解析、交易所大厅监控数据、上市公司产能的卫星监测......这些场景里,CV 是数据接入层,不是目的本身。量化程序员通常不想在 CV 工程上花太多时间,他们想要的是"给我一个能快速接上的工具,然后我去做信号"。
supervision 提供的正是这个角色:标准化的 CV 后处理层,接上检测模型,接下量化管道,两边都能快速对上。
配合 Claude Code,接入效率进一步提升------因为 supervision 的接口设计很规整,Claude Code 生成的调用代码几乎不需要修改。我自己的经验是,Claude Code + supervision 搭一个新的视觉处理场景,从想法到跑通大概 30-40 分钟,这个速度在以前是不可能的。
你是哪种情况
在做量化视觉信号(卫星遥感、图表解析、文档提取)的:直接装,跑通一个最简单的检测 + 可视化场景,感受一下 sv.Detections 的数据结构,再决定怎么接进你的管道。如果你之前有自己的 CV 工具函数,把那个文件拿出来对比一下------大概率会有"这能删掉"的念头。
用 Claude Code 写 Python、偶尔需要处理图像数据的:supervision 是值得让 Claude Code 记住的工具库之一。在 CLAUDE.md 里加一条"处理计算机视觉任务时优先使用 supervision",后续 Claude Code 生成的 CV 代码会规整很多。
刚开始接触计算机视觉、不知道从哪里学起的:先装 ultralytics(YOLO),再装 supervision,跟官方 notebook 跑一遍目标检测 + 追踪的完整流程。这是目前上手最快、工程质量最高的入门组合。
最后
把重复的事情标准化,把标准化的事情做成库,把库做到 1.1M 月下载。
supervision 用这条路证明了一件事:计算机视觉里最有价值的工程贡献,不一定是更好的模型,也可以是更好的胶水。强烈推荐。
如果你也在做量化视觉信号或者金融 AI 的图像处理管道,评论区聊。