MySQL 查询快,核心原因之一是索引。索引不是简单的目录,而是一种有序的数据结构。对于 InnoDB 来说,最重要的索引结构就是 B+ 树。
理解 B+ 树之前,先把 MySQL 的整体结构和存储引擎说清楚:SQL 不是直接落到磁盘文件上的,中间会经过连接层、服务层、引擎层和存储层。

MySQL 的四层结构
| 层级 | 作用 |
|---|---|
| 连接层 | 管理客户端连接、认证、权限校验 |
| 服务层 | SQL 解析、优化、执行、内置函数等 |
| 引擎层 | 负责数据存取的具体实现,比如 InnoDB |
| 存储层 | 真正的磁盘文件和数据页 |
存储引擎是基于表的,同一个库里的不同表可以使用不同引擎。日常最常见的是 InnoDB。
常见存储引擎对比
| 引擎 | 事务 | 锁粒度 | 外键 | 典型特点 |
|---|---|---|---|---|
| InnoDB | 支持 | 表锁、行锁 | 支持 | 默认引擎,兼顾可靠性和性能 |
| MyISAM | 不支持 | 表锁 | 不支持 | 早期常见,现在使用较少 |
| Memory | 不支持 | 表锁 | 不支持 | 数据主要在内存中,重启易丢失 |
InnoDB 的几个关键词很重要:事务、行级锁、外键、B+ 树索引、Buffer Pool、redo log、undo log。其中索引结构决定了查询路径,日志机制决定了事务可靠性。
索引到底是什么
索引是帮助 MySQL 高效获取数据的有序数据结构。没有索引时,数据库可能要从头到尾扫描整张表;有索引时,可以沿着索引结构快速缩小查找范围。
索引的收益主要有两个:
- 提高数据检索效率,降低磁盘 IO。
- 借助有序结构降低排序成本。
但索引不是免费的。每次写入、更新、删除数据时,索引结构也需要维护,所以索引越多,写入成本越高。
为什么不用普通二叉树
二叉搜索树在理想情况下查询效率不错,但它有一个大问题:如果数据插入顺序接近有序,树可能退化成链表。
text
1
\
2
\
3
\
4这种情况下,查询复杂度接近全表扫描。红黑树通过旋转和变色保持平衡,可以避免严重退化,但它仍然不适合作为数据库磁盘索引的主结构。
原因是:红黑树每个节点存储的数据太少,树高相对较高。数据库查询通常涉及磁盘 IO,树越高,磁盘访问次数越多。
B 树解决了什么
B 树是一种多路平衡查找树。一个节点可以存多个 key,也可以有多个子节点。相比二叉树,它可以显著降低树高。
如果一个节点能容纳更多 key,一次磁盘 IO 就能加载更多索引信息,下一步查找范围也能缩得更小。
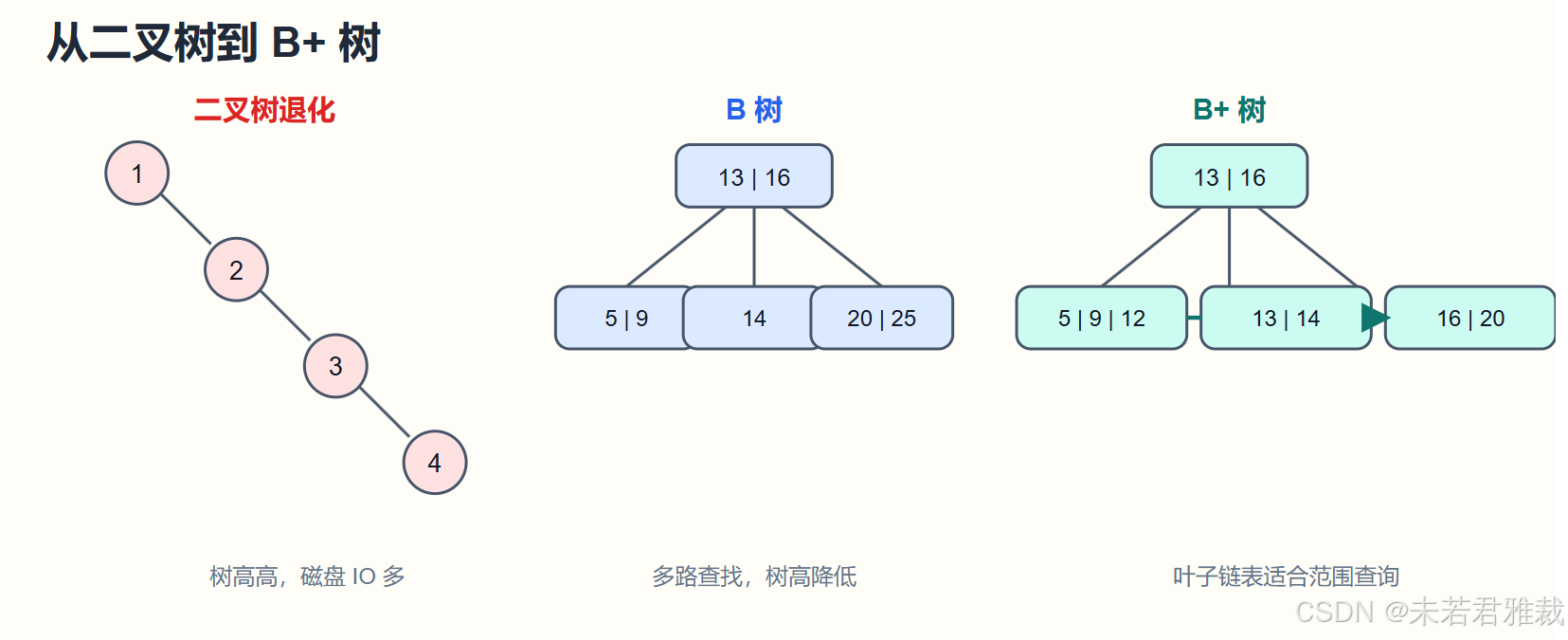
为什么 InnoDB 更适合 B+ 树
B+ 树是在 B 树基础上的优化,更适合外存索引。它和 B 树有几个关键区别:
| 对比项 | B 树 | B+ 树 |
|---|---|---|
| 数据存放 | 非叶子节点和叶子节点都可能存数据 | 数据集中在叶子节点 |
| 非叶子节点 | 存 key 和数据 | 主要存 key 和指针 |
| 范围查询 | 需要中序遍历 | 叶子节点链表天然适合范围扫描 |
| 查询稳定性 | 命中位置不同,路径可能不同 | 通常都走到叶子节点,路径更稳定 |
B+ 树有三个适合数据库的优势:
- 磁盘 IO 成本更低:非叶子节点不存整行数据,可以放更多 key,树更矮。
- 查询效率更稳定:数据集中在叶子节点,查找路径更一致。
- 范围查询更方便:叶子节点之间有链表,区间扫描非常自然。
InnoDB 中的数据页
InnoDB 管理磁盘的基本单位是页,默认大小是 16KB。B+ 树的节点可以理解为一个个数据页,查询时从根节点开始,逐层定位到叶子节点。
一次普通等值查询,可以按这条路径理解:
否
是
聚簇索引
二级索引
SQL 条件进入优化器
选择可用索引
读取 B+ 树根节点
根据 key 定位下一层页
是否到达叶子节点
是聚簇索引还是二级索引
叶子节点直接拿到整行数据
叶子节点拿到主键值
必要时回到主键索引取整行
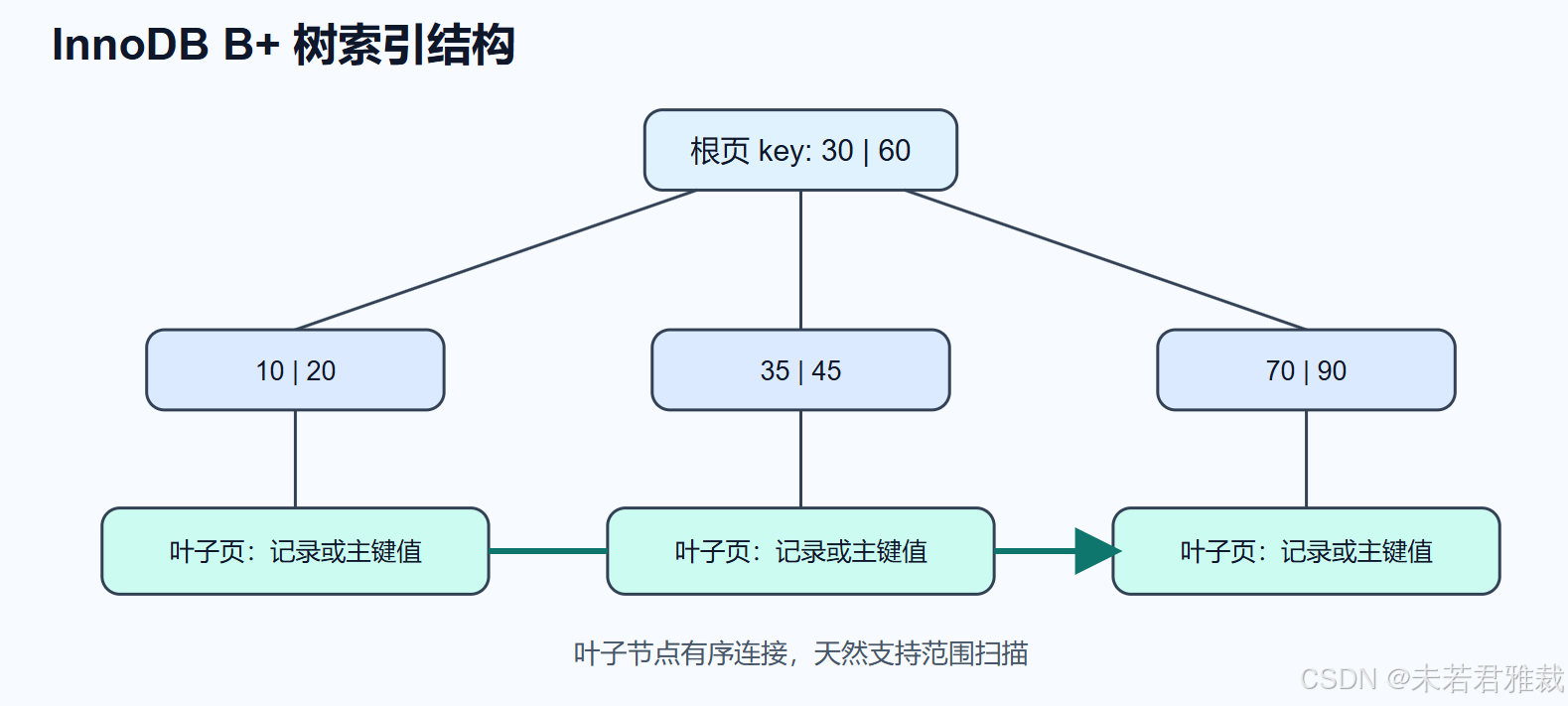
一次等值查询大致是:
- 从根页开始比较 key。
- 找到下一层页指针。
- 继续向下定位。
- 到叶子节点找到目标记录或主键值。
对于高度较低的 B+ 树,即使数据量很大,也只需要少量磁盘 IO 就能定位记录。
范围查询时,B+ 树的叶子链表会继续发挥作用:
定位范围起点
叶子节点 1
叶子节点 2
叶子节点 3
直到超过范围终点
面试回答模板
可以这样回答:
MySQL 的 InnoDB 默认使用 B+ 树实现索引。相比二叉树和红黑树,B+ 树是多路查找树,树高更低,更适合磁盘 IO。相比 B 树,B+ 树把数据集中放在叶子节点,非叶子节点能存更多 key,因此路径更短;同时叶子节点之间通过链表连接,范围查询和排序扫描效率更高。所以 InnoDB 选择 B+ 树,是为了降低磁盘读写成本、提升查询稳定性,并更好支持范围查询。
小结
索引不是抽象概念,它背后就是数据结构和磁盘 IO 的取舍。InnoDB 使用 B+ 树,是因为它能用更矮的树、更稳定的查询路径和更友好的范围扫描能力,支撑大数据量下的高效查询。