一、命令⾏参数
什么是命令行参数?
我们使用命令本质是一个可执行程序。
命令行参数的用途是为了一个可执行程序可以通过选项实现不同的子功能。
命令行参数 = 你在运行程序时,跟在程序名后面的那些 "额外信息"。
程序可以拿到这些信息,根据它们做不同的事。
指定操作对象
这是参数最常见的用法:告诉命令 "你要对哪个文件 / 目录 / 资源进行操作"。
| 命令示例 | 作用说明 |
|---|---|
ls /home |
参数 /home 告诉 ls,列出这个目录里的内容 |
rm file.txt |
参数 file.txt 告诉 rm,要删除这个文件 |
cat test.c |
参数 test.c 告诉 cat,要显示这个文件的内容 |
gcc test.c -o test |
参数 test.c 指定要编译的源文件 |
控制命令的行为(选项)
通过以 - 或 -- 开头的选项参数,可以修改命令的默认行为,实现更精细的控制。
| 命令示例 | 作用说明 |
|---|---|
ls -l |
-l 让 ls 以长格式显示文件详细信息(权限、大小、时间等) |
ls -a |
-a 让 ls 显示隐藏文件 |
grep -i "hello" file.txt |
-i 让 grep 搜索时忽略大小写 |
rm -rf dir/ |
-r 递归删除目录,-f 强制删除不提示 |
cp -r src/ dest/ |
-r 让 cp 递归复制整个目录 |
传递配置信息
很多命令支持通过参数传递配置值,比如端口号、超时时间、颜色主题等,让命令的运行更灵活。
| 命令示例 | 作用说明 |
|---|---|
ping -c 3 baidu.com |
-c 4 指定只发送 3 个数据包就停止 |
curl -m 10 https://example.com |
-m 10 指定请求超时时间为 10 秒 |
python -V |
-V 让 python 打印版本号后退出 |
提供输入数据
参数可以直接作为输入数据传递给命令,尤其是 echo、awk、脚本等文本处理工具。
| 命令示例 | 作用说明 |
|---|---|
| echo "123+456" | bc | echo 输出的表达式,通过管道传递给 bc 计算器作为输入,用于计算结果 |
./script.sh arg1 arg2 |
Shell 脚本中,arg1 和 arg2 作为脚本的输入参数,脚本内通过 $1、$2 读取 |
main函数参数
命令本身也是一个可执行程序的文件,我们既然能在这些命令后面加参数,那假设我们有自己编译的C/C++的程序,在后面带参数有什么用?
cpp
int main(int argv,char* argv[])main函数的命令行参数是实现程序不同子功能的方法,也是指令选项的实现原理。
main函数的参数默认第一个为命令行参数的个数,而后面的argv字符串数组则是根据空格分割的几个字符串
如果你写了一个 C 程序,也可以通过 main 函数的参数来获取命令行参数:
cpp
#include <stdio.h>
int main(int argc, char *argv[])
{
printf("参数个数: %d\n", argc);
for (int i = 0; i < argc; i++)
{
printf("argv[%d] = %s\n", i, argv[i]);
}
return 0;
}编译运行:
bash
gcc test.c -o test
./test hello worlk 123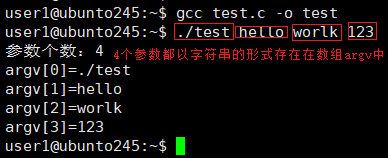
结论
无论是我们自己写的可执行程序,还是系统自带的命令(如 ls、rm、gcc),在命令行输入的参数,最终都会被传入对应程序 main 函数的 argc 和 argv 中。
- 程序通过
argc判断用户输入了多少个参数 - 程序通过
argv获取每一个参数的具体内容并支持实现选项功能 - 以空格为分隔符,用双引号包裹的内容会被视为单个参数(如
"hello world")
二、环境变量
如何理解环境变量?
• 环境变量(environmentvariables)⼀般是指在操作系统中⽤来指定操作系统运⾏环境的⼀些参数;
• 如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪 ⾥,但是照样可以链接成功,⽣成可执⾏程序,原因就是有相关环境变量帮助编译器进⾏查找;
• 环境变量通常具有某些特殊⽤途,还有在系统当中通常具有全局特性。
你可以把它理解成:系统给所有程序准备的「全局小纸条」,程序运行时可以随时读取上面的信息,比如 "程序去哪找可执行文件""默认语言是什么" 等。
查看环境变量
- echo:显⽰某个环境变量值
bash
echo $PATH # 查看命令搜索路径
echo $HOME # 查看当前用户家目录
echo $USER # 查看当前用户名
echo $LANG # 查看语言/编码
echo $PWD # 查看当前所在目录
echo $PS1 # 查看终端提示符样式-
export: 设置⼀个新的环境变量
-
env: 显⽰所有环境变量
-
unset: 清除环境变量
-
set: 显⽰本地定义的shell变量和环境变量
下面有个例子:
env命令:
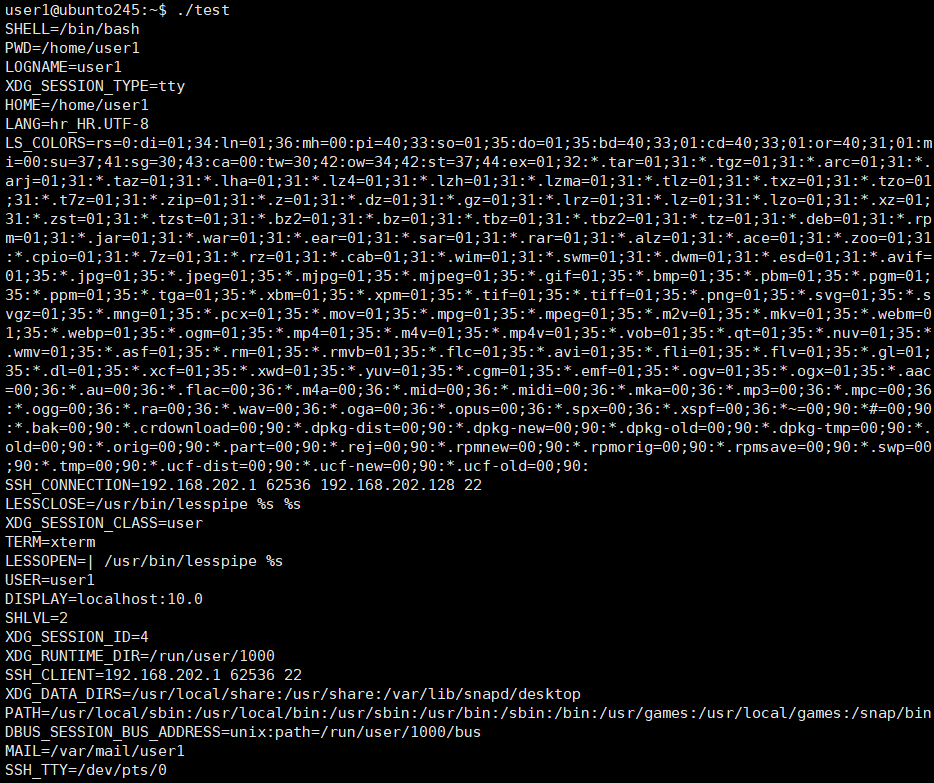
看看我们所有的环境变量:
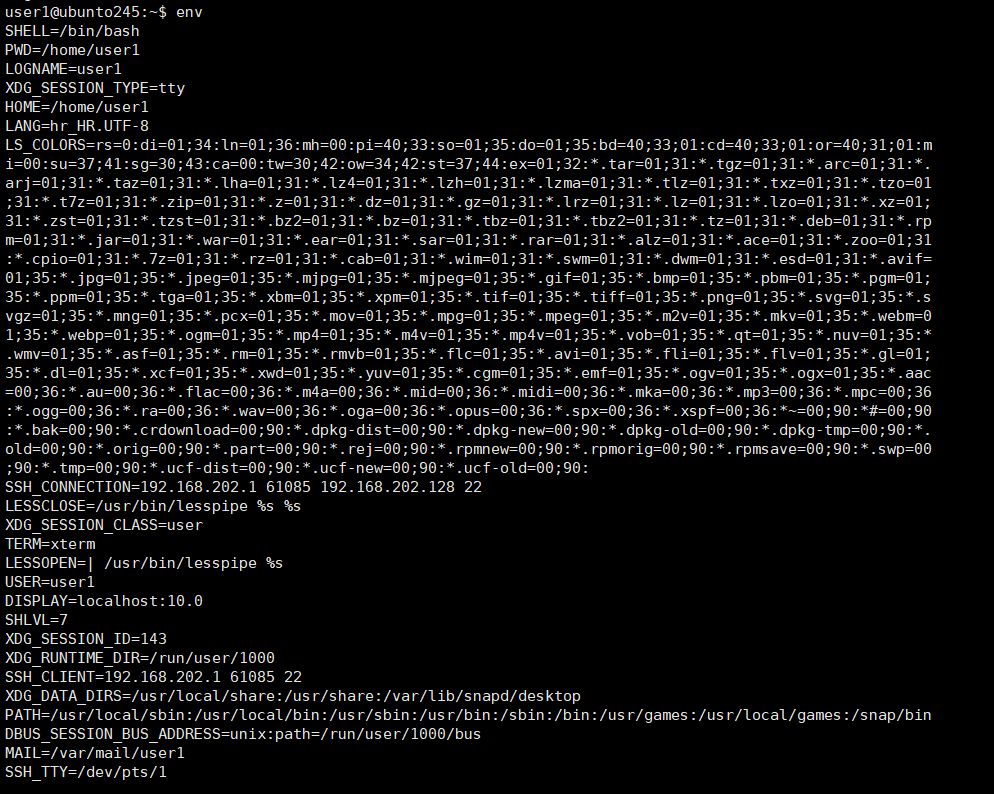
单独讲一下PATH :
PATH内部包含用':'分割的一个个的子路径,就是用来在系统中查找可通过PATH来找执行程序所对应路径,一个找不到就找下一个,直到找到为止,找不到就报错:command not found。
1.PATH=$PATH : 路径 :这种相当于+=,直接在原路径上追加路径
2.PATH=路径 :直接覆盖原路径
怎么理解环境变量?
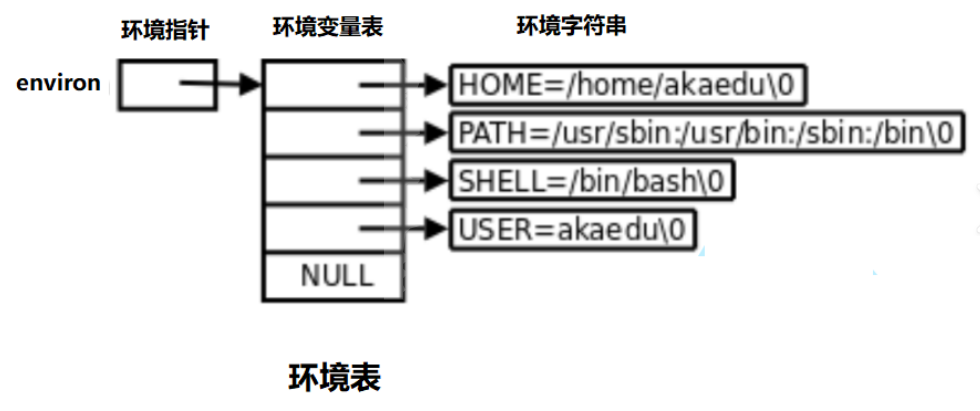
存储的角度来看,每一用户都有对应bash!每个bash里都有一张环境变量表;
而每个程序都会收到一张环境表,环境表是一个字符指针数组,每个指针指向一个以'\0'结尾的环境字符串
更多环境变量
| 变量名 | 含义 | 示例值 |
|---|---|---|
PATH |
可执行程序的搜索路径 | /usr/bin:/bin:/usr/local/bin |
HOME |
当前用户的主目录 | /home/username |
USER |
当前用户名 | username |
SHELL |
当前使用的 Shell 程序路径 | /bin/bash |
LANG |
系统语言和字符编码设置 | zh_CN.UTF-8 |
PWD |
当前工作目录 | /home/username/projects |
HOSTNAME |
当前系统的主机名称 | ubuntu245、VM-0-9-ubuntu |
HISTSIZE |
Shell 历史命令的最大保存条数 | 1000、2000 |
OLDPWD |
上一次所在的工作目录 | /home/username/olddir |
PS1 |
终端提示符样式 | \u@\h:\w\$ |
EDITOR |
默认文本编辑器 | /usr/bin/vim |
UID |
当前用户的 ID | 1000 |
LOGNAME |
当前登录用户名 | username |
TERM |
当前终端类型 | xterm-256color |
通过代码如何获取环境变量?
main函数的第三个参数
main函数的第三个参数为环境变量表,程序执行时系统会自动传入
cpp
#include <stdio.h>
int main(int argc, char *argv[], char *envp[])
{
int i = 0;
// 打印所有环境变量
while (envp[i] != NULL) {
printf("envp[%d] = %s\n", i, envp[i]);
i++;
}
return 0;
}结果:
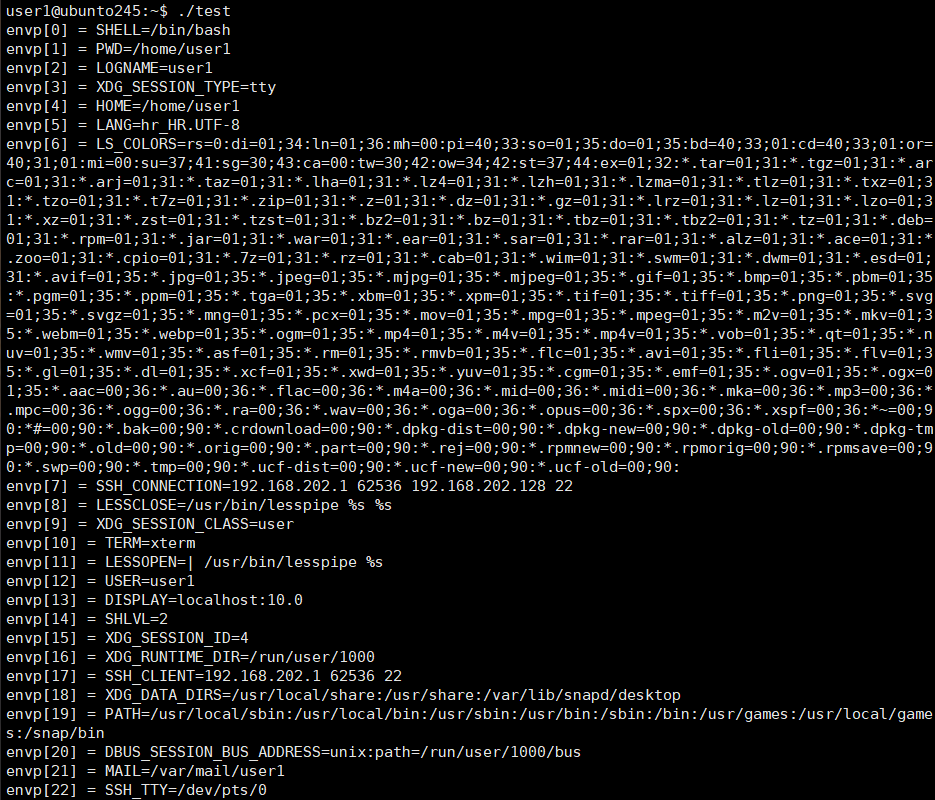
1.main 第三个参数 envp 是环境变量数组
2.里面包含系统所有环境变量
3.数量不固定,一般几十个
4.以 NULL 结尾
父进程的的(bash)环境变量可被子进程继承。
通过第三⽅变量environ获取
libc中定义的全局变量environ指向环境变量表,environ没有包含在任何头文件中,所以在使用时要用extern声明。
cpp
#include <stdio.h>
extern char **environ;
int main()
{
for(int i = 0;environ[i];i++)
{
printf("%s\n",environ[i]);
}
}结果:
使用getenv函数
getenv:通过系统调用来获取指定环境变量的内容
cpp
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("%s\n",getenv("PATH"));
}结果:

理解环境变量的特性
1.环境变量具有全局特性;
2.本地变量不会被子进程继承,只在bash内部被使用;
3.我们的环境变量是在bash里面的;
4.export为内建命令built-in command,不需要创建子进程,而是让bash亲自执行。
三、程序地址空间
我们在学C语⾔的时候,应该都见过这样的空间布局图
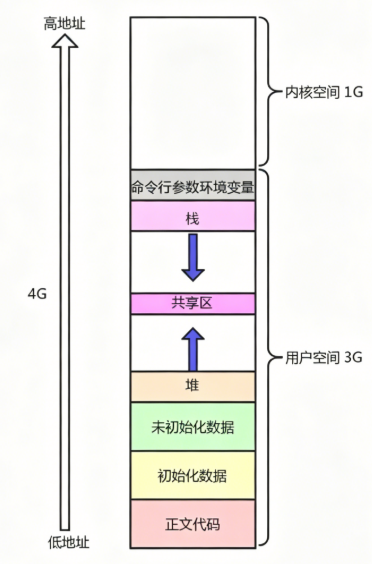
程序地址空间不是内存!是虚拟地址!
C\C++指针用到的地址,全部都是虚拟地址!
虚拟地址空间
先来段代码感受⼀下
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if (id < 0)
{
perror("fork");
return 0;
}
else if (id == 0)
{ // child
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
else
{ // parent
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}结果:
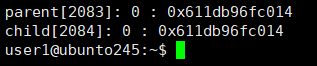
我们发现,输出出来的变量值和地址是⼀模⼀样的,很好理解呀,因为⼦进程按照⽗进程为模版,⽗ ⼦并没有对变量进⾏进⾏任何修改,也验证了之前我们所说的子进程继承父进程的一切信息。可是将代码稍加改动:
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if (id < 0)
{
perror("fork");
return 0;
}
else if (id == 0)
{ // child,⼦进程肯定先跑完,也就是⼦进程先修改,完成之后,⽗进程再读取
g_val = 100;
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
else
{ // parent
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}结果:
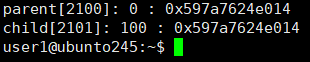
我们发现,⽗⼦进程,输出地址是⼀致的,但是变量内容不⼀样!能得出如下结论:
• 变量内容不⼀样,所以⽗⼦进程输出的变量绝对不是同⼀个变量
• 但地址值是⼀样的,说明,该地址绝对不是物理地址!
• 在Linux地址下,这种地址叫做 虚拟地址
• 我们在⽤C/C++语⾔所看到的地址,全部都是虚拟地址!物理地址,⽤⼾⼀概看不到,由OS统⼀ 管理
OS必须负责将 虚拟地址转化成 物理地址。
虚拟地址空间的工作原理
虚拟地址:每个进程看到的地址(例如 0x100000)都是虚拟的,进程以为自己在独享整个内存空间。
物理地址:内存芯片上的真实地址。
MMU(内存管理单元):CPU 中的硬件组件,负责将虚拟地址实时转换为物理地址。
页表:操作系统为每个进程维护一张映射表,记录了虚拟页到物理页框的对应关系。
每个进程都有一个页表,这个页表可以当作一个哈希表,保存着虚拟地址向着物理地址的映射表。
当进程要访问虚拟地址时,系统会顺着页表找到其物理地址,然后在物理地址上进行访问,而一开始,子进程确实继承了父进程的页表,其映射关系是完全一样的。
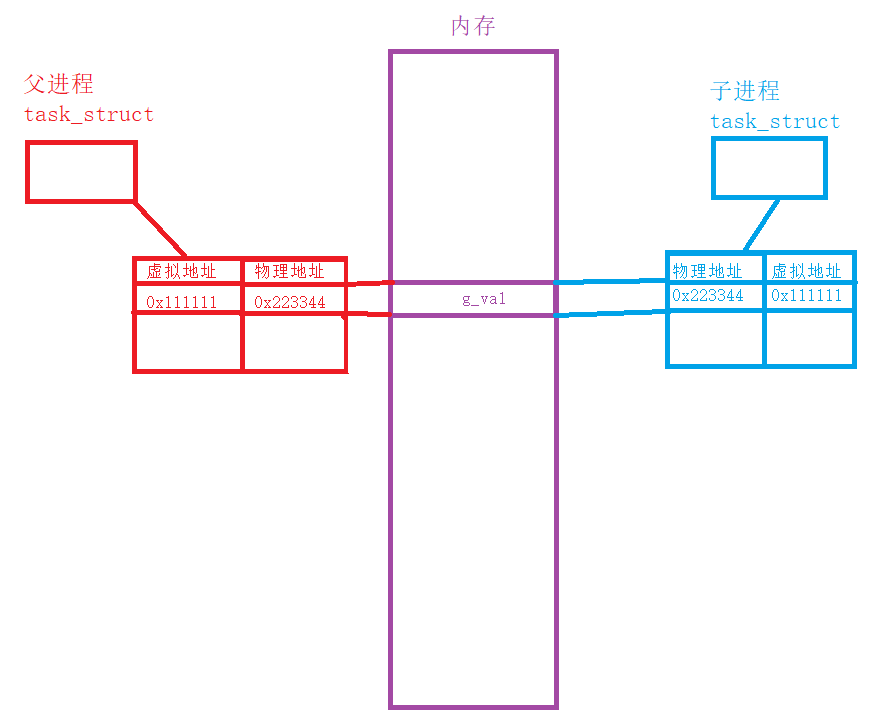
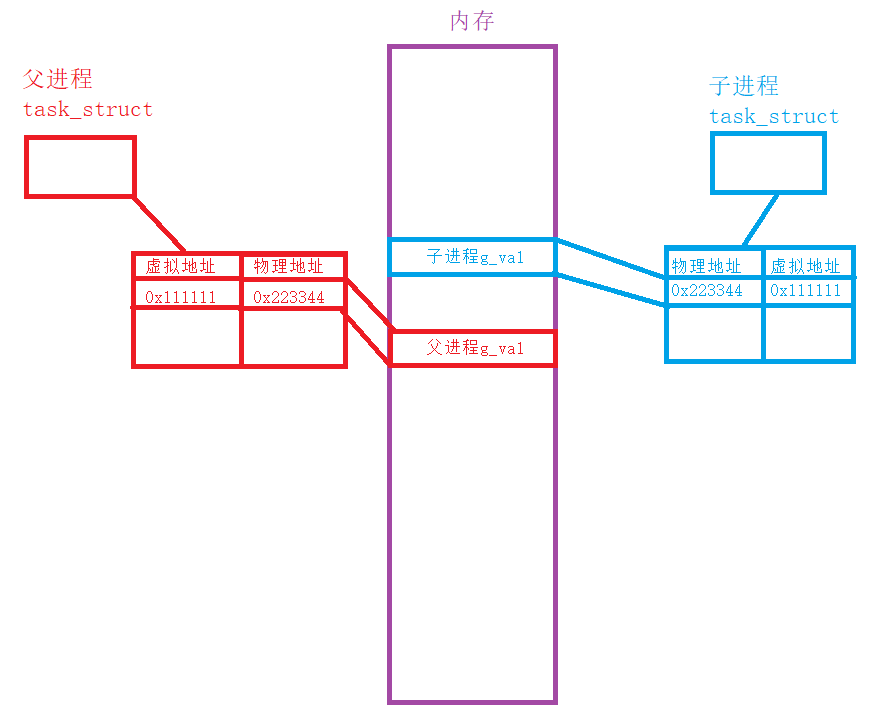
当子进程或者父进程要进行对变量的修改时,对应变量的虚拟地址不变,但是物理地址会发生改变 ,使得两个进程访问的变量实际上并不一样,这就是写时拷贝
更具体一点,每个task_struct都有一个mm_struct结构体,正是表示进程地址空间的结构体,这个mm_struct再根据页表查询物理地址
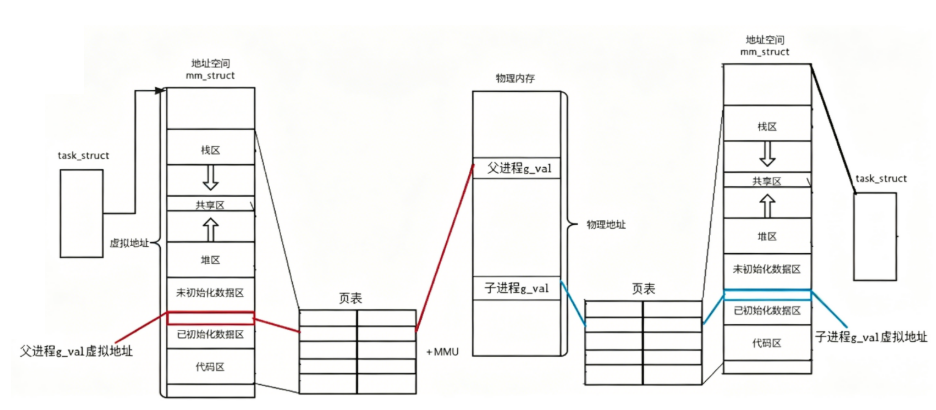 上面的图就足矣说明问题,同一个变量,地址相同,其实是虚拟地址相同,内容不同其实是被映
上面的图就足矣说明问题,同一个变量,地址相同,其实是虚拟地址相同,内容不同其实是被映
射到了不同的物理地址!
总结:虚拟内存空间是一个结构体变量,不是内存,上面全是区域划分的起始地址和结束地址,有一个页表把上面的虚拟地址的映射关系全部构建好,这样我们就能访问它了。
虚拟地址空间与程序地址空间
1. 虚拟地址
核心定义
虚拟地址是CPU 和进程视角下的地址,它不是内存条上真实存在的物理地址。
- 所有程序(进程)在运行时,代码里写的、CPU 执行的,全都是虚拟地址。
- 这些地址会由操作系统 + 硬件 MMU(内存管理单元) 自动、实时地翻译成真实的物理内存地址。
最直观的例子
你同时运行两个一模一样的 a.out 程序:
- 进程 A 的
main函数地址是0x400520 - 进程 B 的
main函数地址也是0x400520
但它们在物理内存中,绝对是两个完全不同的位置。这就是虚拟地址的魔力:不同进程可以使用相同的虚拟地址,互不冲突。
2. 进程地址空间
核心定义
操作系统给每个进程画了一个独立、私有、连续的虚拟地址 "大饼",这就是进程地址空间。
- 32 位系统:每个进程固定拥有 0 ~ 4GB 的虚拟地址空间
- 64 位系统:每个进程拥有 0 ~ 2^48 B(约 256TB)的虚拟地址空间
标准布局(Linux)
每个进程的地址空间内部,都按照固定规则划分成不同区域,对应你写的 C 程序的不同部分:
| 区域 | 作用 | 对应你的 C 代码 |
|---|---|---|
| 代码段(.text) | 存放程序的二进制指令,只读 | main()、printf() 等函数的代码 |
| 数据段(.data) | 存放已初始化的全局变量和静态变量 | int a=10;(全局) |
| BSS 段(.bss) | 存放未初始化的全局变量和静态变量,自动清零 | int b;(全局) |
| 堆(Heap) | 动态分配的内存,从低地址向高地址增长 | malloc()、new 分配的内存 |
| 共享库区 | 存放动态链接库(如 libc.so)的代码和数据 |
printf() 实际的实现代码 |
| 栈(Stack) | 存放函数调用的栈帧、局部变量、参数,从高地址向低地址增长 | 函数内的 int c;、函数参数 |
| 内核区 | 操作系统内核的代码和数据,所有进程共享,用户态不能直接访问 | 系统调用的实现 |
关键特点
- 独立性:每个进程的地址空间完全独立,进程 A 看不到进程 B 的地址空间内容。
- 虚拟性:它只是一个地址范围,不是实际占用的物理内存。你有 4GB 地址空间,不代表你用了 4GB 物理内存,用多少才分配多少。
- 统一性:所有进程的地址空间布局完全一样,编译器不用关心物理内存的位置,直接按固定地址生成代码即可。
总结
操作系统为每个进程创建了一个独立的虚拟地址空间,进程在这个空间里使用虚拟地址运行,由硬件和系统负责把虚拟地址翻译成真实的物理地址,从而实现了进程隔离、内存复用和统一编程。
虚拟内存管理
描述linux下进程的地址空间的所有的信息的结构体是 个mm_struct结构,在每个进程的 mm_struct (内存描述符)。每个进程只有⼀ task_struct 结构中,有⼀个指向该进程的mm_struct结构体指 针。
cpp
struct task_struct
{
/*...*/
struct mm_struct *mm;//对于普通的⽤⼾进程来说该字段指向他的虚拟地址空间的
//⽤⼾空间部分,对于内核线程来说这部分为NULL。
struct mm_struct *active_mm;// 该字段是内核线程使⽤的。当该进程是内核线程时,
//它的mm字段为NULL,表⽰没有内存地址空间,可也并不是真正的没有,
//这是因为所有进程关于内核的映射都是⼀样的,内核线程可以使⽤任意进程的地址空间。
/*...*/
}可以说, mm_struct 结构是对整个⽤⼾空间的描述。每⼀个进程都会有⾃⼰独⽴的 mm_struct , 这样每⼀个进程都会有⾃⼰独⽴的地址空间才能互不⼲扰。先来看看由task_struct到mm_strcut,进程的地址空间的分布情况:
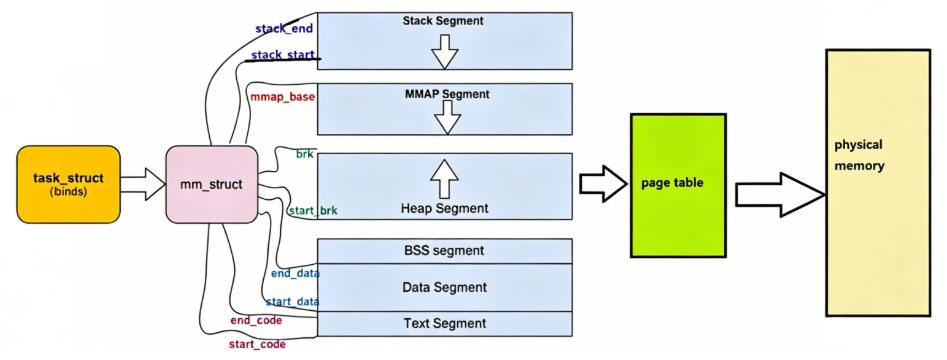
定位 mm_struct ⽂件所在位置和task_struct 的所在路径是⼀样的,不过他们所在⽂件是不⼀样的, mm_struct 所在的⽂件是 mm_types.h
下面是一部分内核代码:
cpp
struct mm_struct
{
/*...*/
struct vm_area_struct *mmap; /*指向虚拟区间(VMA)链表*/
struct rb_root mm_rb; /*red_black*/
unsigned long task_size; /*具有该结构体的进程的虚拟地址空间的⼤⼩*/
/*...*/
//代码段、数据段、堆栈段、参数段及环境段的起始和结束地址。
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
/*...*/
}那既然每一个进程都会有自己独立的mm_struct,那么操作系统如何管理?
当然是先描述,再组织
- 当虚拟区间较少时采取单链表,由mmap指针指向这个链表;
- 当虚拟区间多时采取红黑树进行管理,由mm_rb指向这棵树。
linux内核使⽤ vm_area_struct 结构来表⽰⼀个独⽴的虚拟内存区域(VMA),由于每个不同质的虚 拟内存区域功能和内部机制都不同,因此⼀个进程使⽤多个vm_area_struct结构来分别表⽰不同类型 的虚拟内存区域。上⾯提到的两种组织⽅式使⽤的就是vm_area_struct结构来连接各个VMA,⽅便进 程快速访问。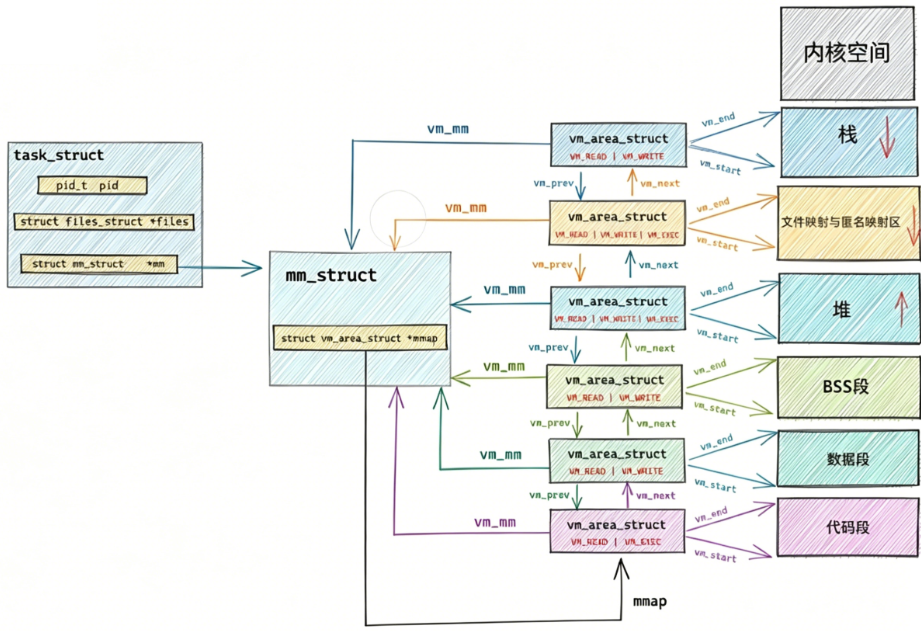
为什么要有虚拟地址空间?
- 隔离程序:每个程序都以为自己独占整块内存,互不干扰,一个崩了不影响其他。
- 内存复用 :物理内存不够时,用磁盘当临时内存,把暂时不用的数据换出去,用更少物理内存跑更多程序。
- 地址统一 :每个程序都从固定虚拟地址开始写代码,不用管物理内存实际在哪,编译链接更简单。
- 安全保护:硬件配合虚拟地址,程序不能随便乱访问别人的内存地址,防止越权篡改。
通俗一点:
1.将地址从"无序"变"有序"。
2.地址转换的过程中,也可以对你的地址和操作进行合法判定,进而保护内存(页表里的权限位,规定有没有权限对访问区的读和写)。
3.让进程管理和内存管理进行一定程度的解耦合。