文章目录
一、什么是库
库是写好的、现有的、成熟的、可以复用的代码。本质上来说,库是一种可执行代码的二进制形式,可以被操作系统载入内存执行。
为什么需要库?
现实中每个程序都要依赖很多基础的底层库,不可能每个人的代码都从零开始。比如:
输入输出功能(printf、scanf)
字符串处理(strlen、strcpy)
文件操作(fopen、fread)
网络通信(socket相关函数)
如果每个项目都要重新实现这些功能,开发效率将极其低下。库的存在让我们开发效率up。
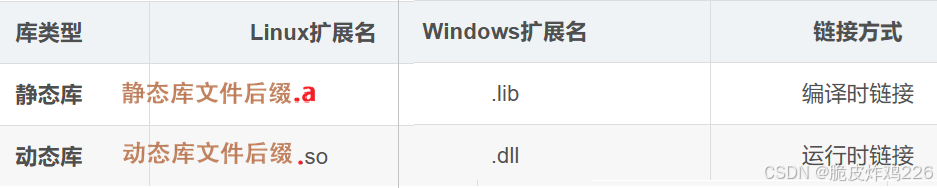
静态库
静态库是在程序编译链接的时候把库的代码链接到可执行文件中。程序运行的时候将不再需要静态库。
- 在Linux中静态库文件后缀
.a,动态库文件后缀.so;
在Windows中静态库文件后缀.lib,动态库文件后缀.dll。 - 静态库:简单来说,就是将几个
.o文件进行归档,打包
.a静态库,本质是归档文件。不需要使用者进行解包,直接用gcc/g++进行链接即可
-
ar是:Linux下的归档工具,核心作用是把多个目标文件(.o)打包成静态库文件(.a)
rc表示:replace creat,replace(替换归档文件中已有的同名文件,不存在则新增),c:create(若归档文件不存在,自动创建新文件)
例子:
ar -rc libmyc.a *.o,当前目录下所有的.o目标文件,打包创建成名为 libmyc.a 的静态库;如果库已存在,就替换里面的同名文件。(lib是前缀,.a是后缀)

-
如果链接任何非C/C++标准库(自己写的/其他外部的 ),需指明-L -l(
L去指定的目录下搜索库文件,l表示链接哪一个库)-I让编译器去指定目录寻找.h头文件

容易踩的小坑:库名不能写全:比如库文件是 libmyc.a,链接时必须写 -lmyc,
-
动静态库中,需要包含 main 函数吗?不需要
(1)库的本质定位:动态库(.so)和静态库(.a)的作用是提供可复用的函数、类或数据 ,供其他程序调用,它们本身不是可独立运行的程序 。main 函数是程序的入口点,只有可执行程序才需要它。
(2)main 函数会引发冲突:如果库中包含了 main 函数,当用户将库链接到自己的程序时,用户程序中也会有一个 main 函数,就会出现符号重定义错误(比如 multiple definition of 'main'),导致链接失败。
-
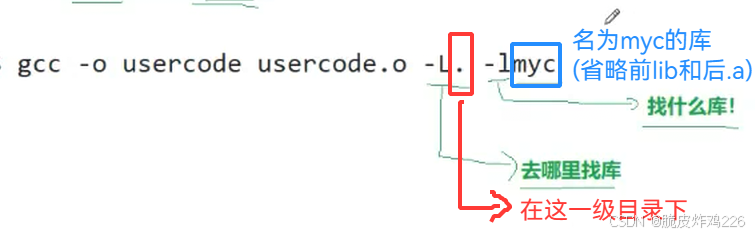
先使用
-c编译,将自己的.c源文件编译为.o目标文件,接着-o是指定生成的可执行文件名字(gcc -o usercode usercode.o),最后链接,将自己的可执行程序和.a链接就行(使用.l+库的名字)

-
需要让系统知道:可执行程序依赖的库。在系统里安装/在系统能找到的路径下。在加载程序的同时,找动态库【把库拷到默认路径下,或者给默认路径建立软链接;再或者在配置文件,动态库路径】
-
静态库中:在链接时,直接把库的实现拷贝到可执行程序里,一旦执行可执行程序,不再依赖静态库。(只要编译成功,就一定能运行)
-
静态库的缺点:
(1)可执行文件体积大
(2)库更新后需要重新编译程序
(3)多个程序使用同一库会造成内存浪费
动态库
-
和静态库的原理差不多
-
先通过
.c文件生成同名的.o文件,但是需要加一个选项:fPICgcc -fPIC -c *.c
静态库打包用ar(归档),动态库直接使用gcc打包(既可以形成可执行程序,又形成动态库文件)
再通过.o文件生成动态库:gcc -shared -o libmyc.so .*o
- (动态库存在的问题)当程序运行时,需要系统去找到所依赖的库。生成可执行程序的是编译器gcc。但是,运行时系统并不知道库在哪里
但是静态库为什么不存在这样的问题呢?因为:静态库在链接时,直接将库的实现拷贝到可执行程序里。一旦形成可执行程序,就不再依赖静态库
而动态库运行时,需要可执行程序和动态库
解决办法1:有一个环境变量echo $LD_LIBARARY_PATH,OS运行程序,除了会去lib64查找,还会去该环境变量下查找动态库。所以将动态库所在路径加到该环境变量下:export LD_LIBARARY_PATH=${LD_LIBARARY_PATH}:写路径即可
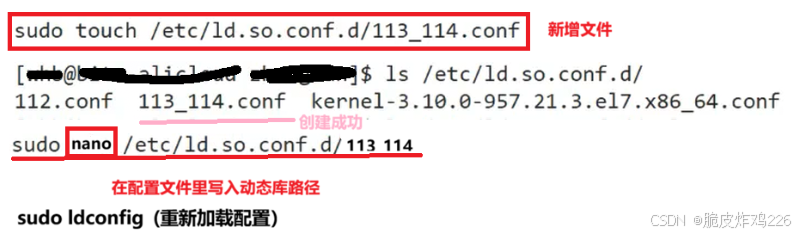
解决办法2:在系统中会存在一个/etc/ld.so.conf.d/ ,是 Linux 系统中用于分片管理动态库搜索路径的目录,里面放若干 *.conf 文本文件,每行写一个库目录路径。管理动态库(.so)搜索路径
在该目录下,新增一个任意名字的配置文件,再把自己动态库路径放进文件里【更改系统的配置文件】
- 动静态库同时存在,gcc和g++默认使用动态库 ,若动静态库同时存在,想使用静态库要写
-staic(一旦写staic就必须有对应的静态库)。如果只存在静态库,可执行程序只能静态链接 - 在Linux系统下,默认安装的大部分库,都优先安装动态库(① 省磁盘空间② 方便升级更新)
- 库(把公共方法写在一起,让别人用的),库只有一个,用库的人n个。库:应用程序=1:n
.c先是通过编译器编译生成.o目标文件,然后这些.o文件再和库通过链接形成可执行文件
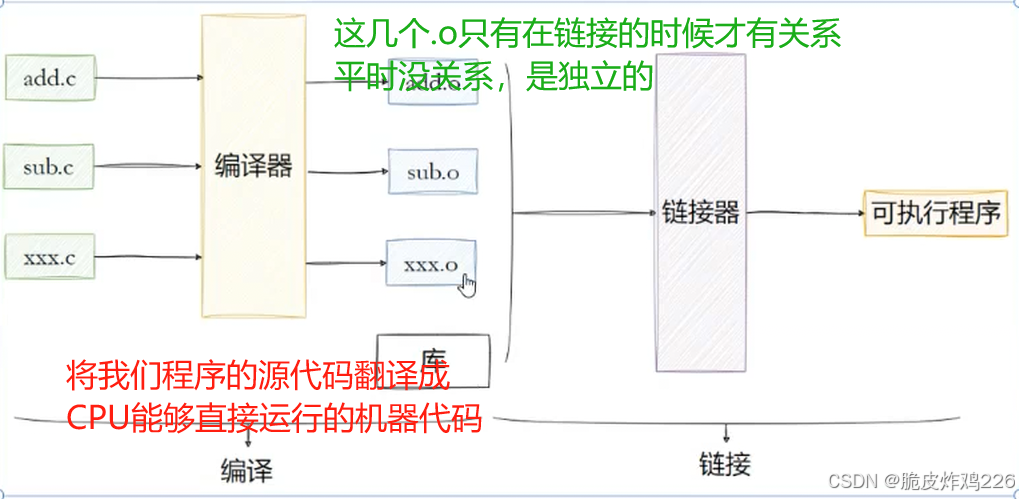
为什么要先把源代码编译成 .o 目标文件,再进行链接?
将源代码先编译为.o文件,再统一链接,主要是为了支持增量编译:当项目中只有某一个.c文件被修改时,不需要重新编译所有代码,只需要重新编译这个被修改的文件生成新的.o,其他未修改的文件对应的.o可以继续使用,最后再将所有.o重新链接成可执行文件。这样能大幅节省编译时间,以最小成本完成重新构建。
-
(动静态库,.o文件,可执行程序)都是ELF格式,以一定的格式放入到二进制文件中

OS加载程序时,它会根据你在ELF内部的program header table表,根据上面的说明,把指定的数据节合并为大的segment
-
代码在
.text节中。数据在.data节中。 -
ELF形成可执行程序
(1)将多份 C/C++ 源代码,翻译成为目标.o文件,.o文件(是ELF格式) + 动静态库(也是ELF格式)进行合并
(2)动静态库是.o文件的合并,.o文件+动静态库合并,就是将多份 .o 文件中相同属性的section进行合并
可执行程序是将相同属性的内容放在一个节(ELF的格式)
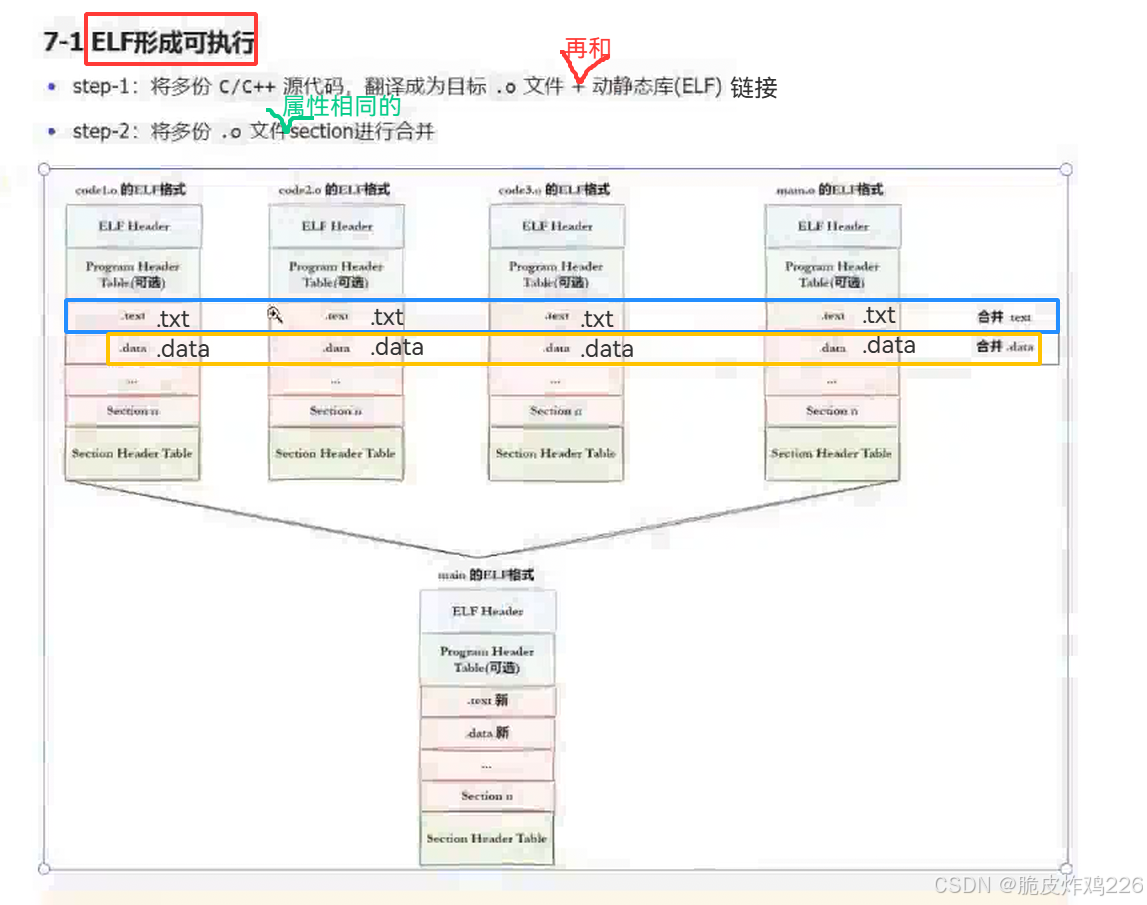
通过上图,可以将链接简单的看作合并。将相同属性,相同功能,相同权限的集合,合并成更大的数据集
静态库的方法就是将(即将用到的方法的txt和数据节)合并,并拷贝到可执行程序里。本质上,合并ELF就是二进制文件的合并
readelf中,-l选项是:读取可执行程序合并之后的段segment(运行时内存布局)。-S选项是编译阶段的「节(Section)」
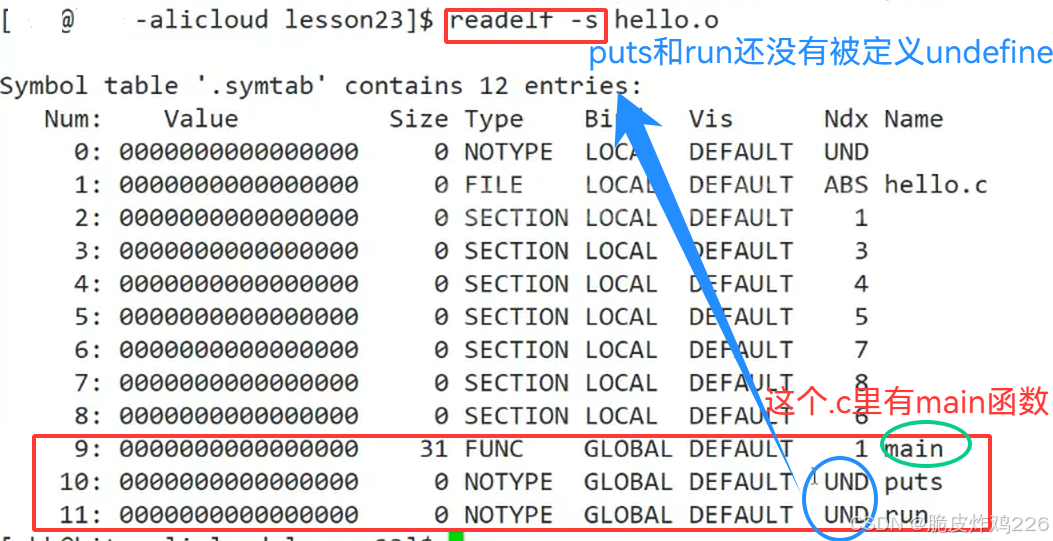
readelf -s可以查看ELF文件的符号表
size 文件名:读取一个ELF 文件的 三大数据集大小
text 代码段大小
data 已初始化数据大小
bss 未初始化数据大小
-
ELF 文件 的两个视角:Section给编译链接用,Segment给内核加载运行用
编译链接阶段 :编译器 / 链接器看Section(节)
运行加载阶段 :系统内核看Segment(段),将多个 Section 打包合并成一个 Segment


-
问题:如何读取刚刚合并的segment呢?
readelf -l ./a.out-l 就是看 Program Header 程序头表
能清晰看到:哪些 Section 被合并进同一个 Segment
这是链接完成后、准备给操作系统加载运行的整体内存布局
-
文件 IO、磁盘、内存交互的基本单位:4KB(一页)
Linux 磁盘与内存 IO 交互基本单位:4KB(一页)
内存被 OS 划分为一个个 4KB 的页框,磁盘文件按 4KB 整块载入内存。
OS把内存也看成大数组,每一个元素的空间是4KB,磁盘文件它的4KB内容就可以承装到内存划分好的4KB空间里,它们两个交互时,以4KB大小交互
静态链接(现成可执行程序)
链接 = 把多个 .o 拼在一起 + 把没填的函数地址全部修正(从 UND 变成真实地址)
链接前(.o 文件阶段):多个 .o 互相完全独立、谁也不认识谁。
A.o要调用这个函数,但不知道它在哪,地址全部是:00000000,等链接来填!
链接时,链接器做了 3 件大事:① 合并所有 section② 确定每个函数 / 变量的最终地址(链接器给所有函数排好顺序,分配最终内存地址)③ 修正所有callq跳转地址
把之前UND 未定义符号,00000000 空地址,全部替换成真实有效的函数地址(这就叫:重定位)
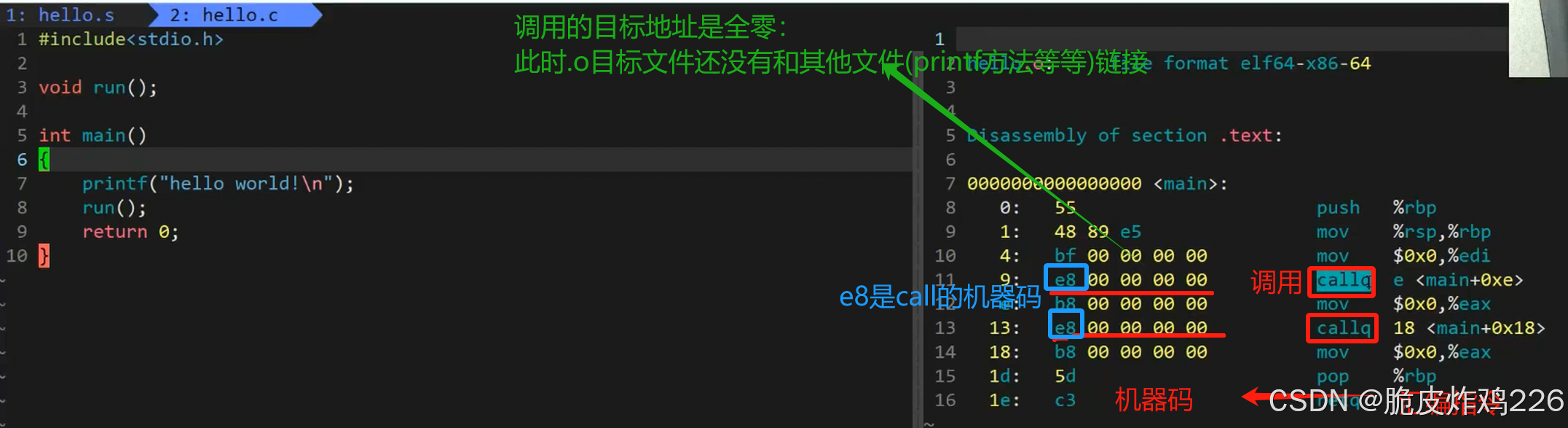
我们可以看到这里的call指令,它们分别对应之前调用的printf和run函数,但是你会发现他们的跳转地
址都被设成了0。那这是为什么呢?
在编译code.c文件时,编译器完全不知道fun函数和printf函数的存在,不知道这两个函数的地址;编译器就只好将这两个函数的地址设置成0。(所以,当我们调用一个没有实现的函数时,是不会编译报错的)
链接的本质 就是编译之后的所有目标文件 连同用到的一些静态库运行时库组合,形成一个独立的可执行文件。
当所有模块组合在一起之后,链接器就会根据我们的.o文件或者静态库中的重定位表找到那些被重定位的函数,从而修改它们的地址。
我们链接的过程中就会涉及到对目标文件.o的地址修正(地址重定位);所以.o目标文件也被称为可重定位目标文件。
gcc -o main.exe *.o是将两个.o文件链接,链接之后的可执行程序名字是main.exe
readelf -s hello.o:读取hello.o文件的section表
readelf -s main.exe:读取链接之后的 文件的section表
函数声明不用加extern,变量需要(声明,定义会分不清)
objdump -d将目标文件(.o)的代码段进行反汇编查看
ELF可执行文件加载到内存
-
可执行程序用线性地址编址(Linux 里:虚拟地址 = 线性地址,可执行 ELF 里写的地址,全是虚拟地址,不是物理内存地址)
-
虚拟地址不仅管操作系统,还管编译器、链接器(编译器编译、链接器排布代码数据时,直接按虚拟地址规划位置)
-
指令也是数据,会占内存
-
CPU 只认虚拟地址,不管物理地址
CPU 眼里:整个程序地址空间从(0 ~ 全F)线性排布,只访问虚拟地址,完全感知不到真实物理内存在哪。程序在磁盘上的地址布局、运行时虚拟地址布局 视角一致。
-
虚拟地址空间如何形成的?
由 ELF 文件里每个 Section 的属性 + 虚拟地址 拼接构成链接器给每个 Section 分配好虚拟起始地址、权限、大小,拼起来就是整个程序的虚拟地址空间布局。
-
ELF程序是如何转换成进程的?
(1)找到 ELF 文件(路径 + 文件名)
(2)内核读取 ELF 的 Program Header/Segment
(3)按 4KB 内存页 把 Segment 映射到进程虚拟地址空间
(4)建立页表、分配虚拟内存
(5)调度执行 → ELF 文件就变成了一个运行中的进程
-
一个可执行程序没有加载到内存的话,也有地址(编译链接完成后,可执行文件内部已经写好了虚拟地址就算没运行、没加载到内存,地址布局早已固定在 ELF 里)
-
编译后没有变量名、函数名,只剩地址
总结:Linux 下所有可执行程序,从头到尾都在用「虚拟地址(线性地址)」布局;
编译链接时就把代码、数据按虚拟地址排好写进 ELF 文件;
程序没运行也自带虚拟地址,运行时系统直接把 ELF 的段映射到进程虚拟地址空间,变成进程;CPU 只认虚拟地址,完全不管物理内存。