注意力机制用于信号同步:从匹配滤波到可学习对齐
1. 引言:同步的本质是寻找"对齐"
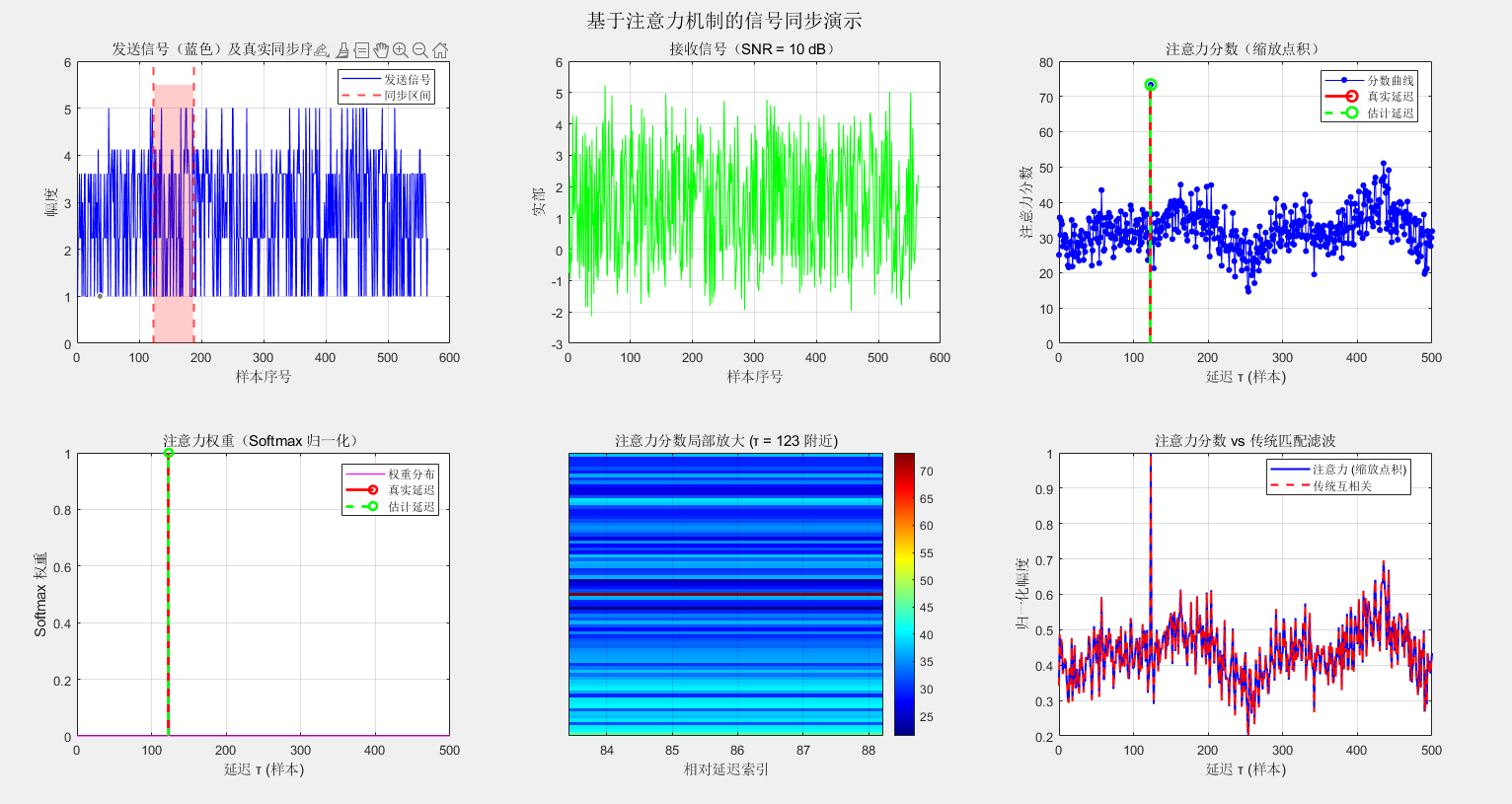
在信号处理中,同步(synchronization)是指从接收信号中确定一个已知参考信号的起始位置或延迟。经典方法------匹配滤波(matched filtering)------通过滑动相关计算峰值位置来完成这一任务。其数学本质是:
τ^=argmaxτ∣∑n=0L−1r∗(τ+n)s(n)∣ \hat{\tau} = \arg\max_{\tau} \left| \sum_{n=0}^{L-1} r^*(\tau+n) s(n) \right| τ^=argτmax n=0∑L−1r∗(τ+n)s(n)
其中 s(n)s(n)s(n)为已知同步序列(模板),r(n)r(n)r(n) 为接收信号,LLL 为序列长度。匹配滤波在加性高斯白噪声下是最优线性检测器,但它是固定的、不可学习的,并且对信道畸变、多径、频偏等非理想因素缺乏鲁棒性。
近年,注意力机制 (attention mechanism)的兴起为同步问题提供了一个统一的、可泛化的视角。本文将展示:信号同步可以自然地表述为一个序列到序列的对齐问题,而注意力机制恰是为此而生。
2. 核心思想:将同步视为"查询-键值匹配"
注意力机制的核心操作是:给定一个查询 (query)和一组键 (keys),通过计算相似度得到注意力权重,进而加权聚合对应的值(values)。在同步任务中,我们可以做如下映射:
- 查询 Q:本地已知的同步序列(长度为 (L))。
- 键 K_τ:接收信号中以延迟 (\tau) 为起点的滑动窗口片段(长度也为 (L))。
- 值 V_τ:可以是与键相同的信息,也可为其他所需内容(同步中常取键本身,用于后续解调)。
同步的目标就是找出使"查询"与"键"最匹配的那个延迟 (\tau),即:
τ^=argmaxτSim(Q,Kτ) \hat{\tau} = \arg\max_{\tau} \text{Sim}(Q, K_\tau) τ^=argτmaxSim(Q,Kτ)
其中 Sim(⋅,⋅)\text{Sim}(\cdot,\cdot)Sim(⋅,⋅) 是某种相似度度量。传统匹配滤波使用线性互相关,而注意力机制提供了更灵活、更通用的相似度计算方法。
3. 数学形式:缩放点积注意力
最常用的注意力形式是缩放点积注意力 (scaled dot-product attention)。对于单个查询向量 q∈CL\mathbf{q} \in \mathbb{C}^Lq∈CL 与一组键向量 {kτ}τ=0N−L\{\mathbf{k}\tau\}{\tau=0}^{N-L}{kτ}τ=0N−L(NNN 为接收信号长度),定义注意力分数为:
f(τ)=qHkτL f(\tau) = \frac{\mathbf{q}^\mathsf{H} \mathbf{k}_\tau}{\sqrt{L}} f(τ)=L qHkτ
其中 (⋅)H(\cdot)^\mathsf{H}(⋅)H 表示共轭转置,L\sqrt{L}L 是缩放因子(用于控制点积的方差)。若使用模值(非相干检测),则为:
f(τ)=∣qHkτ∣L f(\tau) = \frac{|\mathbf{q}^\mathsf{H} \mathbf{k}_\tau|}{\sqrt{L}} f(τ)=L ∣qHkτ∣
3.1 从硬对齐到软对齐
传统匹配滤波直接选取最大分数对应的位置,这是一种硬对齐 (hard alignment)。注意力机制则可以进一步引入 softmax 归一化,将分数转换为概率分布:
α(τ)=exp(f(τ)/T)∑τ′exp(f(τ′)/T) \alpha(\tau) = \frac{\exp\left( f(\tau) / T \right)}{\sum_{\tau'} \exp\left( f(\tau') / T \right)} α(τ)=∑τ′exp(f(τ′)/T)exp(f(τ)/T)
其中 TTT 为温度参数。此时,α(τ)\alpha(\tau)α(τ) 可解释为延迟 τ\tauτ 为真实同步位置的后验概率。软对齐允许后续模块(如信道均衡、解码)对多个可能的延迟进行加权融合,提高系统对定时误差的鲁棒性。
3.2 多头注意力:多视角联合判定
单一相似度度量可能只捕捉信号的某方面特征(如幅度、相位)。多头注意力(multi-head attention)通过多个并行的注意力头,每个头学习不同的线性投影:
q(h)=qWQ(h),kτ(h)=kτWK(h) \mathbf{q}^{(h)} = \mathbf{q} \mathbf{W}Q^{(h)},\quad \mathbf{k}\tau^{(h)} = \mathbf{k}_\tau \mathbf{W}_K^{(h)} q(h)=qWQ(h),kτ(h)=kτWK(h)
f(h)(τ)=Re(q(h)Hkτ(h))Dh f^{(h)}(\tau) = \frac{\operatorname{Re}\left( \mathbf{q}^{(h)\mathsf{H}} \mathbf{k}_\tau^{(h)} \right)}{\sqrt{D_h}} f(h)(τ)=Dh Re(q(h)Hkτ(h))
然后对所有头的分数求和或拼接:
ftotal(τ)=∑h=1Hf(h)(τ) f_{\text{total}}(\tau) = \sum_{h=1}^{H} f^{(h)}(\tau) ftotal(τ)=h=1∑Hf(h)(τ)
多头机制使得同步可以同时关注信号的时域包络、相位连续性、甚至高阶统计量,从而显著提升在复杂信道下的鲁棒性。
4. 与匹配滤波的理论联系
值得注意的是,当满足以下条件时,缩放点积注意力精确退化为匹配滤波:
- 无投影(WQ,WK\mathbf{W}_Q, \mathbf{W}_KWQ,WK 为单位阵);
- 不使用 softmax(直接取模或实部);
- 缩放因子为 1L\frac{1}{\sqrt{L}}L 1(等效于能量归一化)。
此时,f(τ)=∣qHkτ∣Lf(\tau) = \frac{|\mathbf{q}^\mathsf{H} \mathbf{k}_\tau|}{\sqrt{L}}f(τ)=L ∣qHkτ∣ 正是归一化互相关 (normalized cross-correlation)。因此,匹配滤波可以视为注意力机制的一个特例------一个单头、无学习、无软对齐的注意力同步器。
这种视角下,匹配滤波不再是孤立的方法,而是位于通用注意力框架的一个固定点。通过引入可学习投影、多头和 softmax,我们自然地获得了超越匹配滤波的能力。
5. 注意力同步的优势
5.1 可学习性
传统的同步序列必须事先设计且固定不变。在注意力框架中,查询 q\mathbf{q}q 和键 kτ\mathbf{k}_\taukτ 可以通过可训练的投影矩阵WQ,WK\mathbf{W}_Q, \mathbf{W}_KWQ,WK 进行端到端优化。这意味着同步器可以自动适应信道特性(如多径时延分布、频偏范围),甚至联合优化数据检测和信道估计。
5.2 软决策与不确定性表达
通过 softmax 输出概率分布,注意力同步提供了定时误差的置信度 。在多径信道中,多个峰值可能对应不同路径;软权重可以自然地实现 RAKE 接收机式的能量合并,而不必硬选择一个路径。
5.3 多模态特征提取
多头注意力允许从原始信号中同时提取多种特征(例如实部/虚部、幅度/相位、差分相位等),每个头学习各自最优的相似性度量。这相当于特征级联,传统匹配滤波无法做到。
5.4 无缝集成到神经网络接收机
现代深度学习通信接收机(如基于 Transformer 的解调器)中,同步可以作为网络的第一层,通过反向传播与后续均衡、解码模块联合训练。注意力同步的梯度可以流经整个网络,实现全局优化。
6. 推广到更一般的同步问题
本文以时域延迟估计为例,但注意力同步的思想可以推广到:
- 载波频偏同步:将查询设计为频移版本的序列,键为接收信号,注意力分数最大值对应的频偏即为估计值。
- 帧起始检测:与延迟同步同理,但序列更长,可引入分段注意力降低复杂度。
- 多用户同步:每个用户有自己的查询,使用多头或交叉注意力区分不同用户。
- 联合定时-频偏估计:二维注意力(延迟 × 频偏)可通过计算二维分数矩阵实现。
在所有这些场景中,核心公式始终是:
θ^=argmaxθ∣q(θ)Hk∣L或θ^=argmaxθ∑hRe(q(h)(θ)Hk(h))Dh \hat{\theta} = \arg\max_{\theta} \frac{\left| \mathbf{q}(\theta)^\mathsf{H} \mathbf{k} \right|}{\sqrt{L}} \quad \text{或} \quad \hat{\theta} = \arg\max_{\theta} \sum_h \frac{\operatorname{Re}\left( \mathbf{q}^{(h)}(\theta)^\mathsf{H} \mathbf{k}^{(h)} \right)}{\sqrt{D_h}} θ^=argθmaxL q(θ)Hk 或θ^=argθmaxh∑Dh Re(q(h)(θ)Hk(h))
其中 θ\thetaθ代表待估计的同步参数(延迟、频偏、相偏等)。
7. 结论
注意力机制为信号同步提供了一个统一且强大的数学框架。它将传统匹配滤波吸收为一种特例,同时开放了可学习、软决策、多头特征提取等全新能力。在未来的通信、雷达、声呐等系统中,基于注意力的同步方法有望替代经典相关器,成为智能接收机的基础组件。
思想的演进:从"匹配一个固定模板"到"学习如何对齐",注意力同步代表了信号处理与深度学习融合的一个典范。它的美在于:公式几乎未变,但意义已经升华。