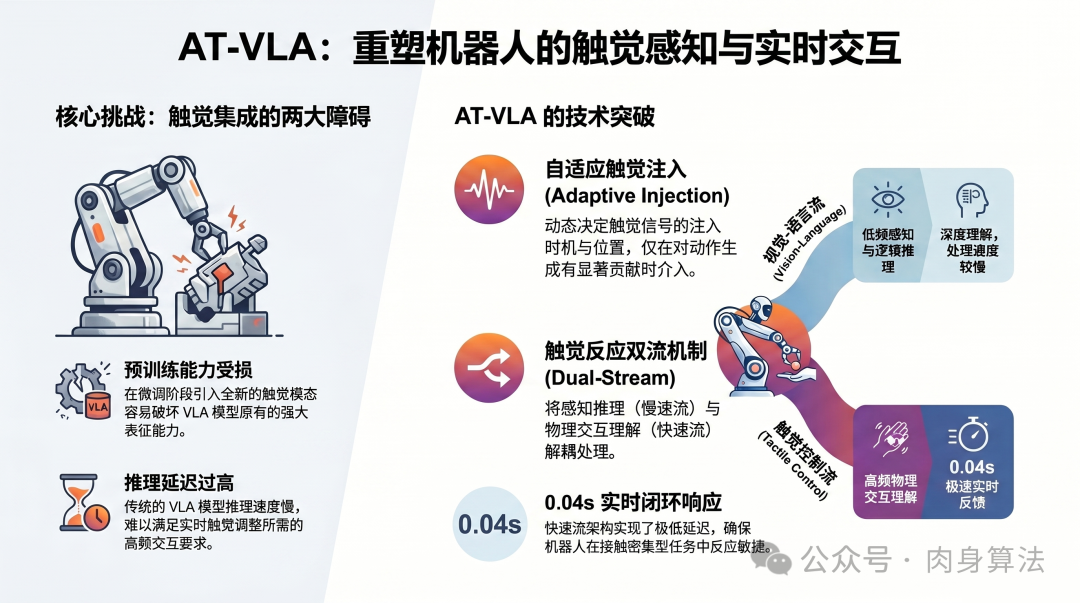
导读
让一台机器人解开背包拉链,是个意外残酷的考题。
视觉摄像头能告诉它拉链头在哪里,大语言模型能听懂"把这个包打开",可一旦拉链头开始走那条 S 形的弯路,光靠视觉的策略就会卡住------拉链卡死、被布料反向拽偏、甚至直接脱手。在 GO-1、π0.5 这些当前最强的视觉-语言-动作(VLA)通用机器人模型上,这个看似简单的任务完整成功率分别只有 20% 和 0%。
问题不在它们"看不见",而在它们"摸不着"。
来自北京大学计算机学院、PrimeBot 和 PKU Lab 的一支团队最近给出了一个非常工程化、也非常生物化的答案:与其让大脑变得更聪明,不如给机器人装一根"脊髓"。他们提出的 AT-VLA (Adaptive Tactile Vision-Language-Action)做了两件事:用一个可学习的"闸门"决定什么时候 把触觉信号塞进预训练 VLA,再用一条额外的高频"快流"专门处理触觉反馈,把闭环响应压到了 0.04 秒(40 毫秒)。
最终在 Unzip Bag、Stamp、Wipe Vase、Unscrew Lid 四个接触密集型任务上,AT-VLA 的平均成功率达到 0.50,是 GO-1 的两倍以上,是直接把触觉硬塞进 VLA(朴素方案)的近四倍。这篇文章想拆开看:他们到底解决了什么矛盾、那个"触觉闸门"是怎么训练的、为什么 0.04 秒这个数字是个分水岭,以及这套思路对未来通用机器人意味着什么。
背景:通用机器人模型的"接触盲区"
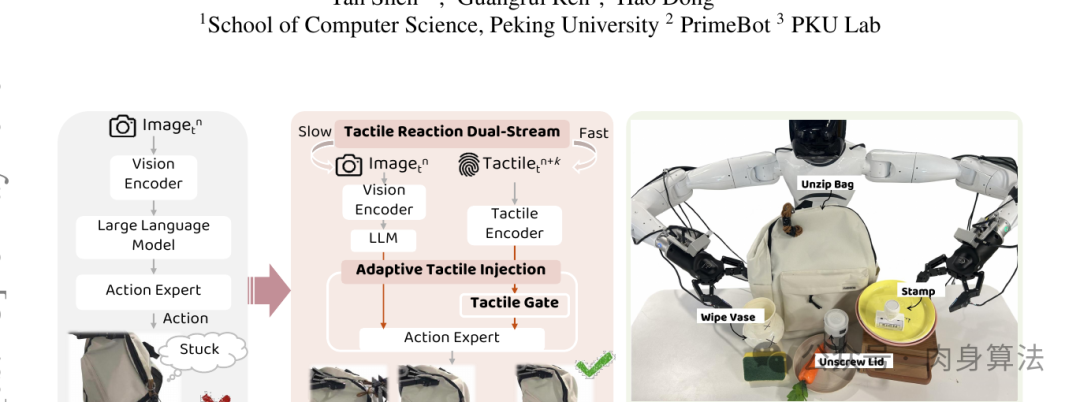
过去两年,VLA 模型几乎是机器人领域最热的方向。从 Google 的 RT-2 到 π0、π0.5、GO-1、Open X-Embodiment,再到 Gr00t、Helix 这些 humanoid 基座模型,思路都类似:拿一个预训练好的视觉-语言模型(VLM)当"大脑",再外挂一个 action expert(通常是 DiT 风格的扩散动作头),用海量遥操作数据微调它去生成动作。
这种"视觉+语言+动作"的范式在抓取、放置、开抽屉这类非接触 或轻接触任务上效果惊人------只要看清楚、听懂指令就能搞定。但一旦任务进入"富接触"阶段,VLA 就开始露怯:
-
拉拉链要求末端持续跟随一条弯曲的力路径;
-
盖章要在压下去那一瞬精确判断"印面已经接触到桌面",再多压一毫米可能把治具撞坏;
-
拧瓶盖需要持续判断手指与盖子的摩擦力,否则一滑就空转;
-
擦曲面花瓶要让海绵贴着曲率走,否则要么悬空要么过力。
这些任务的共同点是:视觉提供不了足够信息 。摄像头看不清拉链是否卡住、看不到印章是否压实、看不到指尖是否打滑。真正能告诉策略"现在到底发生了什么"的,是接触面上的法向力、切向力、滑动信号------也就是触觉。
业界对这个"接触盲区"的常规做法是:在下游微调时给 VLA 接一个触觉编码器,把触觉 token 拼到视觉 token 后面送进 action expert。代表工作有 VTLA、RDP、TLA、TA-VLA、Omnivla 等。听起来很顺,可论文里揭示了一个反直觉的现象:
直接把触觉硬塞进 VLA,不仅没让接触任务变好,还整体掉点 9%------甚至在抓取这种本来不需要触觉的阶段也开始抓不准了。
为什么?因为 VLA 在预训练阶段几乎没见过触觉这种模态。强行把全新模态拼到 cross-attention 的 key/value 上,会扰动 query 原本指向"目标物体"的注意力分布,等于在大脑里塞了一个噪声源。
直觉实验:注意力地图告诉你哪里出了问题
<img src="images/fig3-attention.png" alt="注意力地图:直接注入触觉反而让 VLA "失焦"" title="注意力地图:直接注入触觉反而让 VLA "失焦"">
文章里有一组非常有说服力的可视化。作者拿 Open Drawer 和 Pick the Sponge 两个任务,对比"Vanilla VLA"和"Direct Incorporation(直接拼接触觉)"两种策略在 action expert 内部的注意力热力图。
-
Vanilla VLA:注意力精准落在抽屉把手或海绵本体上,是教科书般干净的视觉锚定;
-
Direct Incorporation:注意力散到了把手周围------抽屉框、海绵旁边的桌面,目标定位反而变得模糊。
换句话说,多塞一个模态等于多给模型一个理由分心。这就解释了为什么 Ex1(直接融合触觉)会比 Ex0(朴素 VLA)还差。
这个观察直接催生了 AT-VLA 的设计原则:让 VLA 在不需要触觉的阶段保持"原样",只在真正接触发生时才让触觉登场。视觉负责"找到东西",触觉负责"摸清东西"------这是一种对模态的功能分工。
核心方法之一:自适应触觉注入------给 VLA 配一道"智能闸门"
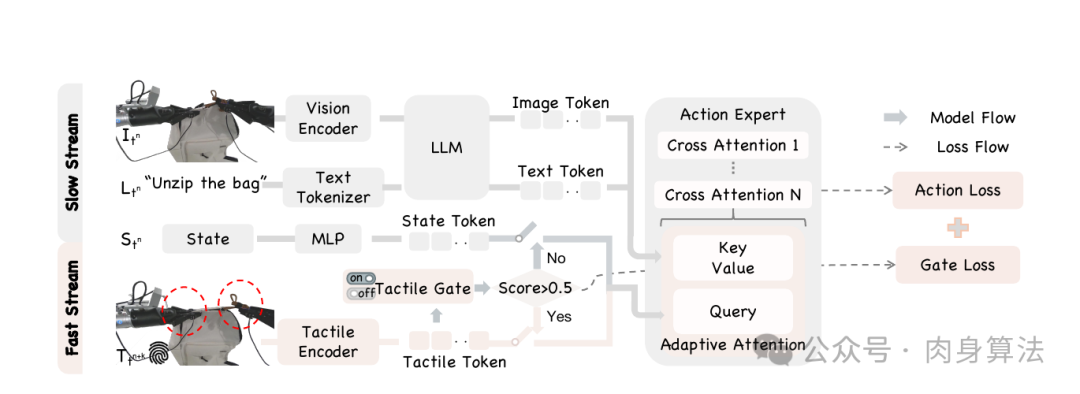
AT-VLA 的第一个核心是 Adaptive Tactile Injection。整套设计可以拆成两层:
1. Tactile Gate(触觉闸门)
闸门本身是一个轻量级 MLP 分类器:
-
输入 :触觉编码器(也是几层 MLP)输出的触觉 token
z_T; -
输出:一个 0--1 分数,表示"现在是否处于接触状态";
-
监督 :对训练片段逐帧人工标注 0/1(非接触 / 接触),用二元交叉熵
L_g监督; -
激活阈值:分数 > 0.5 视为"接触发生"。
这个闸门干两件事:一是天然地把任务切成"接近 → 抓取 → 接触富集"几个阶段;二是逼着模型学会从触觉信号中读出接触状态,而不是把触觉当作普通张量来对待。
2. Adaptive Cross Attention(自适应交叉注意力)
光有闸门还不够------还得告诉 action expert 闸门关掉的时候应该看什么、打开的时候应该看什么。AT-VLA 的做法非常优雅:
| 闸门状态 | Cross-Attention 的 Query | 行为含义 |
|---|---|---|
| 关(非接触) | 状态 token z_S(沿用 vanilla VLA) |
完全等价于原始 VLA,预训练能力 100% 保留 |
| 开(接触发生) | 触觉 token z_T |
注意力被切换到触觉,开始用接触反馈指导动作 |
Key/Value 始终是图像 token z_I 和文本 token z_L,只动 Query 这一根线。这意味着:
-
网络结构没有改------任何已有的 VLA 都可以插这套机制;
-
预训练特征没有被破坏------非接触时模型行为与原始模型完全一致;
-
接触时刻动态切换------触觉成为新的"问句",问视觉-语言上下文"在我现在感受到的力下,下一步该怎么走"。
整体训练目标是
L = L_a + λ₁ · L_g (λ₁ = 0.01)
L_a 是原本的动作损失,L_g 是闸门的二元交叉熵。λ₁ = 0.01 是一个很小的权重------保证闸门"够用",不喧宾夺主。
核心方法之二:触觉反应双流------把 0.04 秒"挤"出来
解决了"何时塞"和"塞到哪"的问题后,还有最后一个坎:速度。
VLA 推理慢是出了名的------基座 VLM(这里是 IntelVL-2B + GO-1 上的 DiT action expert)一次前向少则 100ms,多则上百毫秒。可触觉信号本质上是高频的:拉链卡顿是毫秒级事件,海绵打滑只在几十毫秒内可逆。等大模型"想完",事件已经过去了。
AT-VLA 的回答是给系统装一条额外的"快流"------把感知-决策做频率解耦:
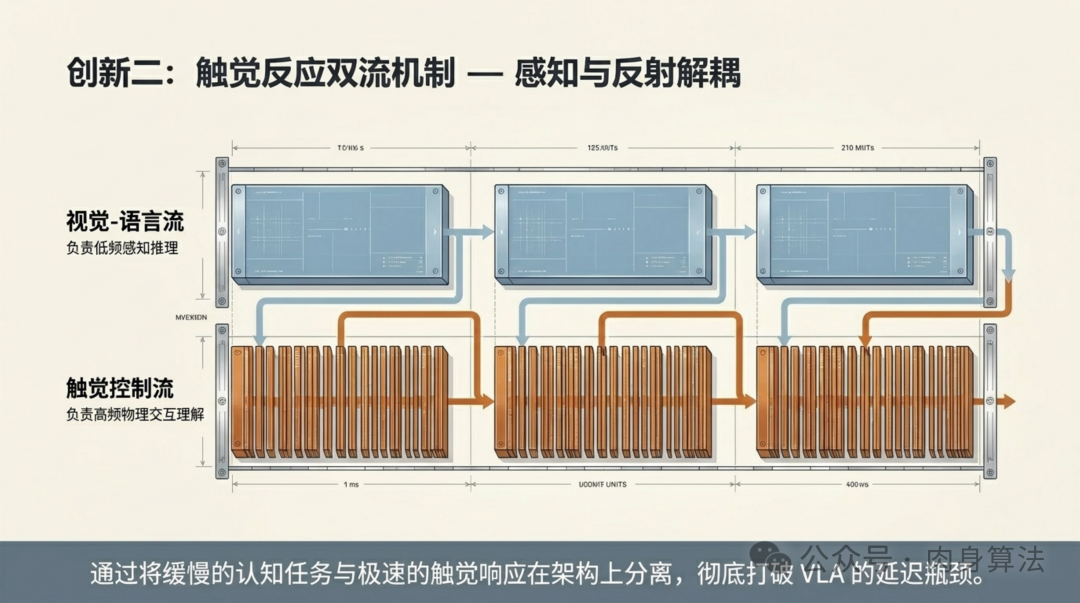
| 数据流 | 内容 | 频率 | 角色 |
|---|---|---|---|
| Slow Stream(慢流) | Image + Language → VLM 推理 | 低频 | 负责长程规划、场景理解、目标定位 |
| Fast Stream(快流) | Tactile feedback → 直接喂入 action expert | 高频 | 负责瞬时接触反应、动作微调 |
具体到时序:当闸门开启时,慢流每推理一次,快流连续推理 3 次 ------也就是 3:1 的快慢频率比。这是参照前作 Fast-in-Slow、MLA 的设计经验定下的比例,既不会因为快流太快而和慢流脱钩,也保证了响应足够灵敏。
借助上一节定义的动作 chunking(slow stream 一次产生未来 H 步的潜在条件),快流的每次推理可以"提前"参考 slow stream 在时间 t_n 的输出,作为接下来 t_n 到 t_{n+H} 区间的语义先验。训练时这个比例 h:1 在 1 < h < H 范围内随机采样,让模型学会在任意比例下都能工作。
最终效果:0.04 秒内完成一次完整的闭环响应------感知 → 决策 → 执行 → 再感知。这个数字大致对应人类脊髓反射弧的时延量级(30--50ms),论文用一个非常贴切的隐喻形容这套设计:
我们不需要让大脑变得更大,而是要给机器人装一根"脊髓"。
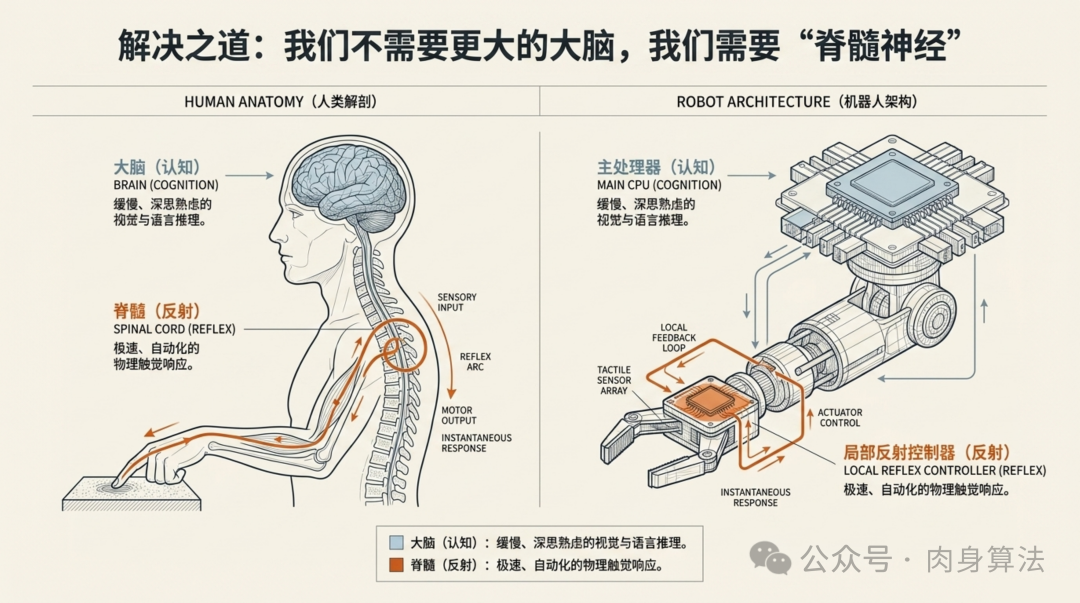
把高频物理交互和低频认知推理在架构上彻底分开------这才是真正的灵感来源。
实验:在四个"拉链级"任务上的硬碰硬对比
实验在 AgiBot Genie1 双 7-DoF 机械臂平台上进行,配 Xense Robotics 的触觉夹爪,VR 头显遥操作收集 30--50 段示教。任务分两组:
-
接触密集型:Unzip Bag(解拉链)、Stamp(盖章)、Wipe Vase(擦花瓶)、Unscrew Lid(拧瓶盖);
-
非接触型对照:Pick and Place、Open Drawer。
基线选了四个最强的对照:GO-1(同数据集预训练,AT-VLA 的 vanilla 版本)、π0.5(SOTA VLA)、VTLA(基于 Qwen2-VL + ViT 处理 visual-tactile image)、RDP(Diffusion Policy + 2D marker PCA)。每个子任务跑 15 次试验。
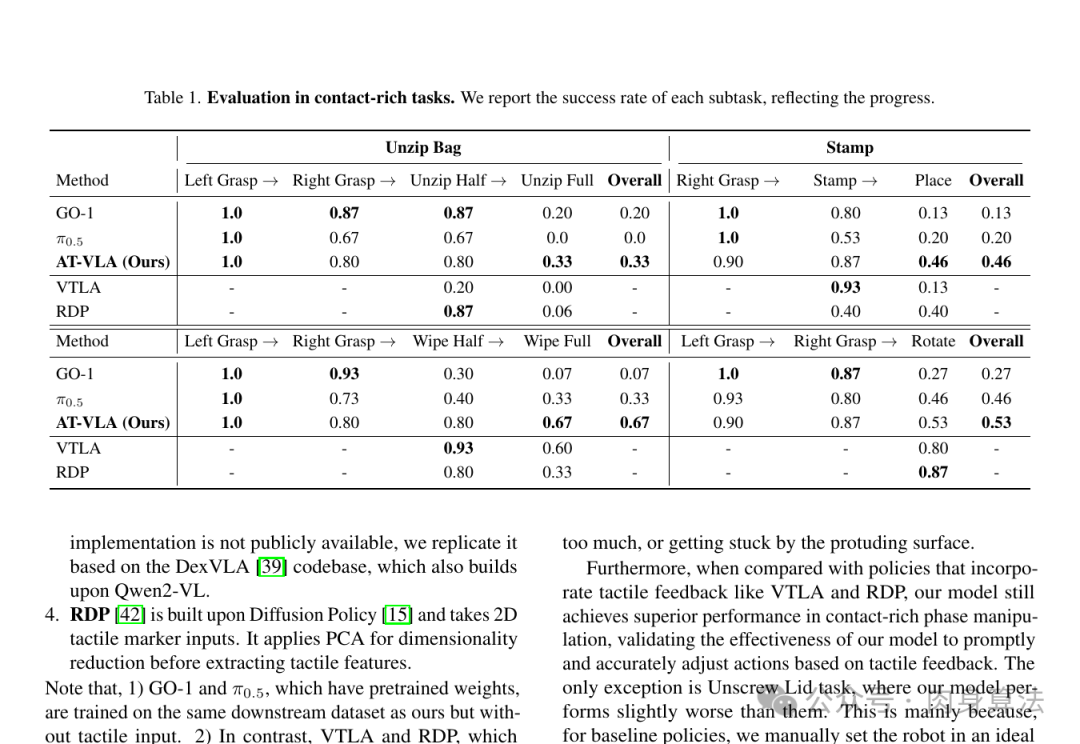
关键结果(Table 1)
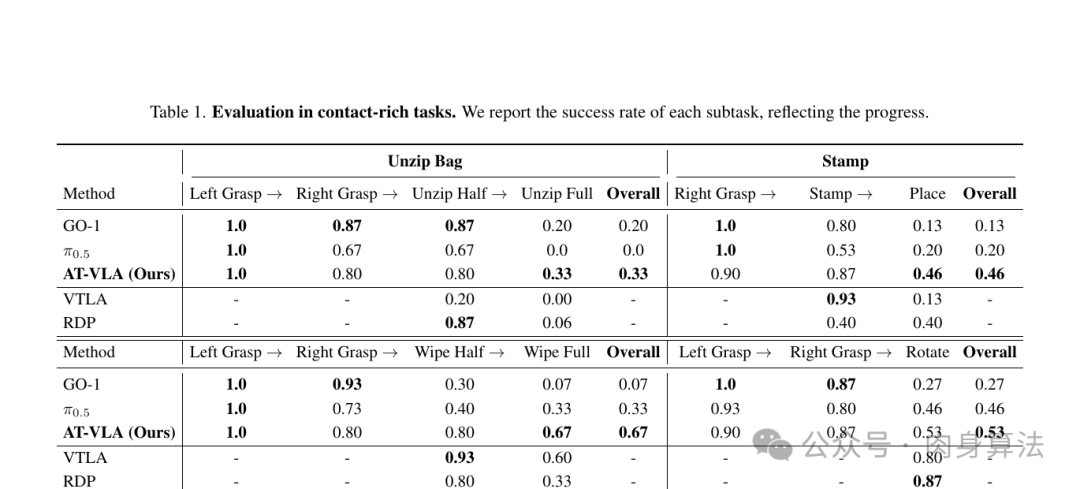
| 任务 | GO-1 | π0.5 | AT-VLA | VTLA | RDP |
|---|---|---|---|---|---|
| Unzip Bag (Overall) | 0.20 | 0.00 | 0.33 | 0.00 | 0.06 |
| Stamp (Overall) | 0.13 | 0.20 | 0.46 | 0.13 | 0.40 |
| Wipe Vase (Overall) | 0.07 | 0.33 | 0.67 | 0.60 | 0.33 |
| Unscrew Lid (Overall) | 0.27 | 0.46 | 0.53 | 0.80 | 0.87 |
几个值得品的细节:
-
抓取阶段几乎追平 GO-1。Left Grasp 全员 1.0,Right Grasp AT-VLA 是 0.80,和原 GO-1(0.87)差不多------这就是"自适应注入"在起作用:非接触阶段模型行为基本没动。
-
接触阶段拉开差距 。Unzip Full:GO-1 0.20,π0.5 0.00,AT-VLA 0.33;Wipe Full:GO-1 0.07,π0.5 0.33,AT-VLA 0.67。差距全在那"卡住的一瞬间"。
-
Unscrew Lid 输给 VTLA / RDP ------但作者诚实地点了原因:VTLA 和 RDP 这两个基线没有预训练能力,作者只在富接触子任务上训练它们,并人为把机器人手动放到理想抓握位置;而 AT-VLA 要从零完整跑完整个任务,偶尔会因为抓握不够稳而滑脱。这其实更说明 AT-VLA 的"全栈通用"价值。
模态无关鲁棒性:训练有触觉,推理可以没触觉
| Method | Pick Place | Open Drawer | Stamp | AVG |
|---|---|---|---|---|
| GO-1 | 1.00 | 0.93 | 0.13 | 0.68 |
| π0.5 | 1.00 | 0.93 | 0.20 | 0.70 |
| AT-VLA w/o. | 1.00 | 0.93 | 0.20 | 0.70 |
| AT-VLA w/. | 1.00 | 0.93 | 0.46 | 0.79 |
这张表很有意思:AT-VLA 训练时用了触觉,但推理时拔掉触觉传感器 ,它仍然能跑非接触任务,性能和原版 GO-1 持平。这意味着------AT-VLA 不是"必须有触觉才能用"的封闭系统,而是个模态无关的鲁棒模型。当传感器掉线、被遮挡、或在新硬件上没装触觉时,它至少不会崩。
更妙的是,在 Stamp(一个轻接触任务)上,AT-VLA w/o(推理时无触觉)甚至比 vanilla GO-1 略好------作者推测:训练时有触觉让模型隐式地学到了更丰富的接触动力学和跨模态关联,视觉特征也跟着变聪明了。
消融实验:每一个零件都拆开看一遍

Table 3 把组件拆得很细,平均成功率(AVG)这一列特别能说明问题:
| 配置 | Tactile Gate | Adaptive Cross-Attn | Direct Incorp | Reaction Dual-Stream | AVG |
|---|---|---|---|---|---|
| Ex0 (Vanilla VLA) | - | - | - | - | 0.22 |
| Ex1 (Direct Incorp) | - | - | ✓ | - | 0.13 |
| Ex2 (+Gate +AdaCA) | ✓ | ✓ | - | - | 0.39 |
| Ex3 (Ours) | ✓ | ✓ | - | ✓ | 0.50 |
读这张表可以读出三件事:
-
Ex0 → Ex1:0.22 降到 0.13 。直接拼接触觉让模型变差了 41%。这印证了开头的注意力图:硬塞模态会扰动预训练表征。
-
Ex1 → Ex2:0.13 飙到 0.39 。加上 Tactile Gate + Adaptive Cross-Attention 后,成功率直接翻了三倍------证明"什么时候让触觉进来"远比"是否让它进来"更重要。比 vanilla VLA(0.22)也有 +17% 的提升。
-
Ex2 → Ex3:0.39 升到 0.50 。再加上 Reaction Dual-Stream 高频流,又涨 +11%。在 Unzip Bag 这种"延迟一帧就卡住"的任务里,这 11% 几乎全来自实时性。
不同触觉格式的对比
文章还测了三种触觉编码格式:
-
Force 6D (3D 切向力 + 3D 法向力,6 维):AVG 0.50(最优)
-
Marker 2D(N×2 标记点位移):AVG 0.32
-
V-T Image(视觉-触觉融合图):AVG 0.40
作者的解释:高维触觉输入(如 V-T image)会引入过多 token,反而扰动预训练表征。低维但信息密度高的力向量是更聪明的选择。这也是另一种"少即是多"。
讨论:AT-VLA 真正的贡献是什么?
我读完通篇有三点想多说几句。
第一,它把"模态融合"从工程黑魔法变成了一个可设计的开关问题。
过去做多模态融合,几乎所有工作都默认"信息越多越好,拼接就完事"。但 AT-VLA 用最直接的数据告诉你:当新模态在预训练阶段缺席时,硬融合可能让性能腰斩。它给出的解法不是"再去预训练一遍",而是用一个 5 万参数级别的 MLP 闸门 + 一行 query 切换代码,零成本地让大模型"知道什么时候该听触觉、什么时候不该听"。这套思路完全可以推广到力觉、嗅觉、温度、深度------任何在 VLM 预训练中罕见的新模态。
第二,它在工程上把"双系统"做对了。
近一两年 Helix(Figure AI)、Gr00t N1(NVIDIA)、Fast-in-Slow 都在搞类似的快慢双系统,但大多数把"快流"放在视觉或点云上。AT-VLA 第一个明确把触觉作为快流------这是非常对路的选择,因为视觉的物理意义是"长程感知",而触觉的物理意义就是"瞬时反应",让它各得其所。3:1 的快慢比也比 Helix 公开的 200Hz/8Hz(25:1)更保守、更接近"动作 chunking 时间窗"的自然节奏。
第三,0.04 秒是个分水岭,但不是终点。
40ms 大致对应人类脊髓反射的下限,但人在做精细操作时还有更快的肌梭、高尔基腱反射回路(10--20ms)。如果未来要做缝合手术、装配纳米器件这种任务,触觉控制流可能还需要更快------可能要直接绕开 action expert,做嵌入式的 reflex layer。AT-VLA 没解决这个终极问题,但它把"反应速度可设计"这件事建立成了一个明确维度。
几个公开的局限也值得想想:
-
闸门是用人工标注 0/1 监督的------对新任务每段示教都得手工标注接触帧,扩展性堪忧。下一步如果能用力阈值或视觉接触检测来自动伪标签,会好很多。
-
触觉编码器只是几层 MLP,没用大规模触觉预训练(虽然消融里 Sparsh 这种预训练 tactile encoder 在 V-T image 模式下表现并不更好)。如果未来出现强大的 tactile foundation model,AT-VLA 的上限还能再抬一截。
-
实验任务还是四个比较"经典"的接触任务,对真正高动态的事件------比如挡球、抓取掉落物------还没验证。
总结
-
问题:VLA 模型在富接触任务上失效------硬加触觉会破坏预训练表征,模型推理太慢又赶不上高频触觉信号。
-
思路 :用一个轻量"触觉闸门" + 自适应 cross-attention,动态决定何时让触觉登场;再用 3:1 的快慢双流,把闭环响应压到 0.04 秒。
-
数据:四个接触密集型任务平均成功率 0.50,是 vanilla GO-1 的 2.27 倍,是直接融合方案的 3.85 倍;推理时拔掉触觉传感器仍能跑非接触任务。
-
启示:通用机器人不必走"全靠一个大模型"的死路。把"反应速度"和"模态注入时机"作为独立的可设计维度,是更工程化、也更生物化的路径。
-
延伸:自适应注入的范式可推广到力觉、嗅觉、温度等任何缺席于 VLM 预训练的新模态;下一站可能是更快的反射层和自监督的闸门标注。
本文基于 AT-VLA: Adaptive Tactile Injection for Enhanced Feedback Reaction in Vision-Language-Action Models1 解读。项目主页:https://sites.google.com/view/at-vla。\[2\]
引用链接
1AT-VLA: Adaptive Tactile Injection for Enhanced Feedback Reaction in Vision-Language-Action Models: https://arxiv.org/abs/2605.07308
2https://sites.google.com/view/at-vla。: https://sites.google.com/view/at-vla。