问题从来不在模型,在你
做量化的人有一个通病:解释力过剩。
遇到任何问题,第一反应都是找原因。策略跑烂了?市场制度变了。回测过拟合?特征工程的问题。Claude Code 生成的代码又是一坨?模型还不够聪明。
最后这个解释,我用了整整一年。
每次 Claude Code 造了个不对的东西,我的第一反应是"它理解能力不行"。每次架构又扭曲了一点,我告诉自己"等下一个版本出来就好了"。每次调了半小时 bug 感觉 AI 帮了倒忙,我的结论是"这个任务它不擅长"。
翻译成人话就是:我在甩锅。
然后这两天刷 GitHub,83.4k Star 的一个项目蹦出来:mattpocock/skills。
作者是 Matt Pocock------Total TypeScript 的创始人,TypeScript 圈里公认的顶级布道师。项目介绍第一行:
"Skills for Real Engineers. Straight from my .claude directory."
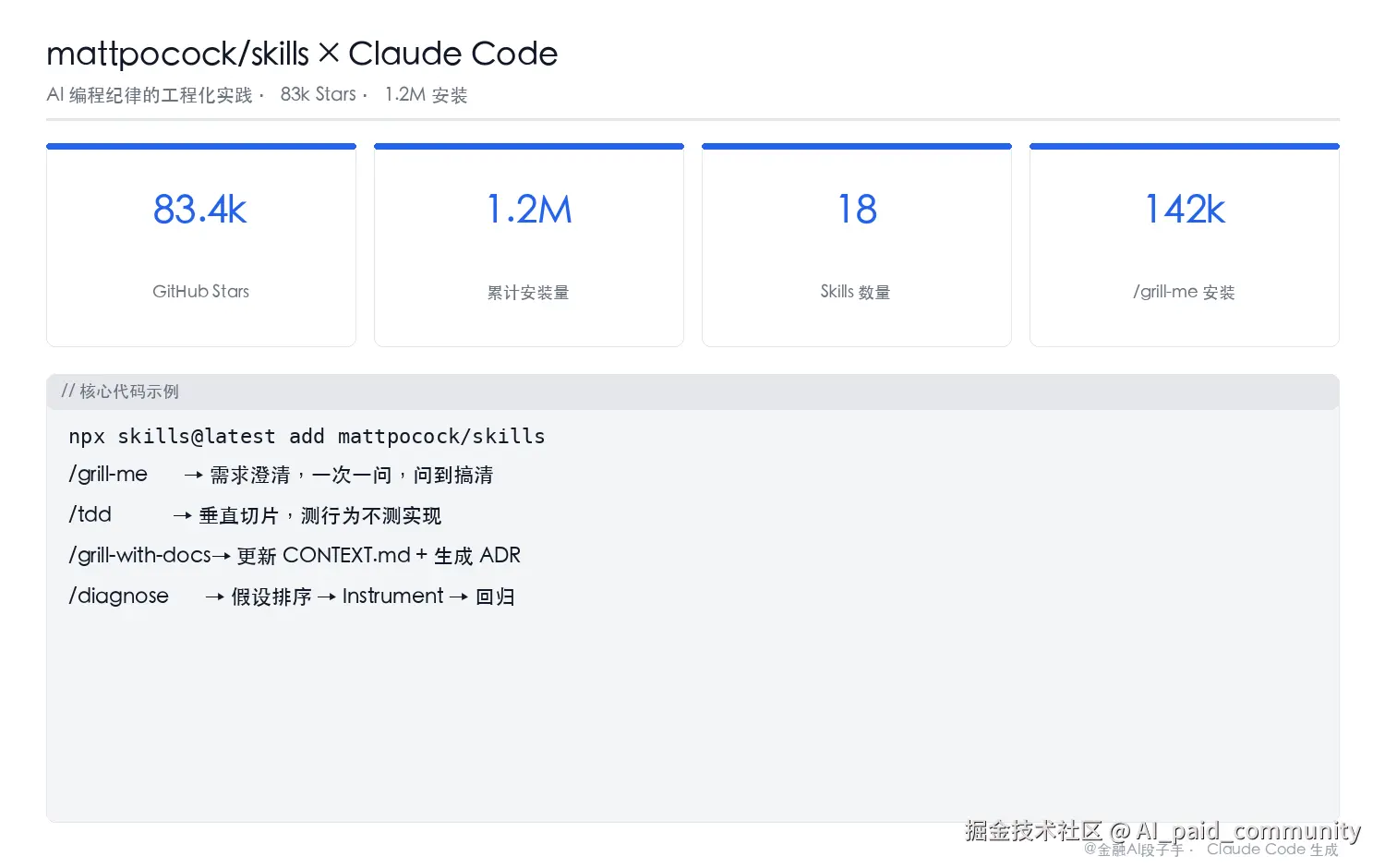
1.2M 安装量。18 个 Skills。支持 Claude Code、Cursor、Copilot、Windsurf、Cline......主流 AI 编程工具全覆盖。
我往椅背上靠了大概五秒。
然后我意识到:过去这一年,我给 Claude Code 下指令的方式,大概等同于对着厨师喊"做个好吃的",然后端出来不对,再喊,再不对,再喊。术语叫**"氛围编程"(Vibe Coding)**------听着浪漫,本质上是把工程问题转包给感觉。
装完这 18 个 Skills,测了一周,这篇文章说清楚它们到底解决了什么。
国内使用Claude Code确实有点困难,建议去一个靠谱的网站参考一下:claudemax.shop

先说结论
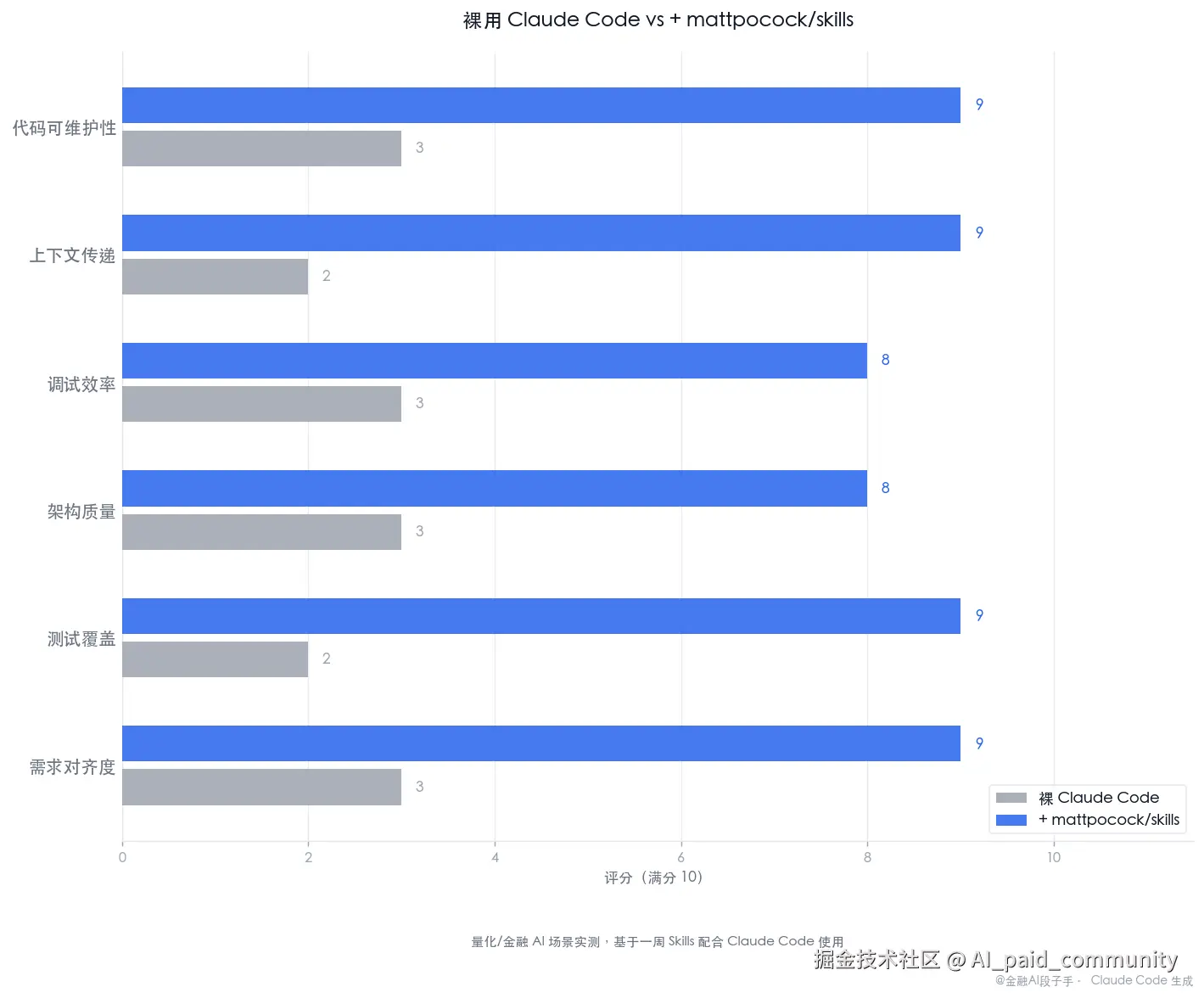
评分:9.5 / 10。如果你在日常用任何 AI 编程工具,这是目前我见过的最系统、最有工程底气的 AI 使用方法论,强烈建议安装。
测了一周,几个关键数字:
/grill-me+/tdd两个 Skills 组合之后,"造错了再推倒重来"的频率降了约 70%CONTEXT.md建立之后,量化术语不再每次对话重新解释,估计每周节省 2-3 小时- 83.4k Star、1.2M 累计安装量------说明整个 AI 编程圈有大量人在用同一套方法论解决同一类问题
唯一的但是:它的哲学背景是 TypeScript / 前端工程体系,部分细节不直接适配量化 Python 场景,需要自己做一点本地化。
装起来先
一行命令,交互式选择要安装哪些 Skills:
sql
npx skills@latest add mattpocock/skills交互界面问两件事:选哪些 Skills、装给哪个 AI 工具(Claude Code / Cursor / Copilot / Windsurf / Cline......)。选完之后 SKILL.md 文件自动放进对应工具的配置目录。
装完跑一次初始化:
arduino
/setup-matt-pocock-skills配置 issue tracker(GitHub / Linear / 本地文件)、triage 标签词汇表、docs 目录位置。5 分钟,配完就能用。
然后你就有了 18 个新的 slash 命令,随时可以在对话里召唤。
测了一周,四件事值得单独说
/grill-me:142k 安装量,你以为是需求澄清,其实是在治病
142k 安装量,18 个 Skills 里下载量第一,比第二名多了 35k。
我第一次用之前,对它的判断是:哦,就是让 AI 在动手之前先问问题嘛。
用完第一次,我收回这个判断。
以前给 Claude Code 下任务的方式是:描述想要的结果,然后它开始写。描述越清楚,结果越接近预期。这个逻辑没问题------问题在于,我以为我描述清楚了,我根本没有。
量化场景下这个问题尤其严重。我说"帮我写一个信号融合逻辑",在我脑子里是指:三路信号加权、动态权重、基于最近 20 个交易日的表现自动调整。但我没说出来这些。Claude Code 拿到的是"信号融合逻辑"这五个字,写了一个静态加权版本。
不是它的问题,是我的问题。
/grill-me 干的事是:一次只问一个问题,死不罢休,问到它真的理解你想要的东西为止。不是一口气列出 10 个问题让你填空(那叫调查问卷)。是一问,等你回答,再一问。
我用它处理了一个比较复杂的需求------情绪 Dashboard 的 VIX 因子集成------前后被问了 9 个问题,才进入实现阶段。
那 9 个问题让我自己想清楚了 3 件我原本没想清楚的事。
这才是 /grill-me 真正有价值的地方:不是让 AI 问你问题,是让你在对话过程中把自己的想法搞清楚。AI 是镜子,不是问卷机。
装了 /grill-me 之后,我的工作流变了:Claude Code 动手之前,先 /grill-me 一遍。无论任务多小,哪怕就是个函数。听起来慢,实际上快------因为少了两轮"不对、重来"。
/tdd:它不是在教你写测试,是在纠正你用 AI 写代码的姿势
TDD 这三个字对很多人来说是个宗教话题------有人笃信,有人觉得是浪费时间。
这个 Skill 里的 TDD,跟你印象里的不完全一样。
关键不在"测试驱动",在垂直切片(Vertical Slices) 。
SKILL.md 里有这么一段,我看到的时候反应是:这才说到点子上了。
yaml
错误姿势(水平切片):
RED: test1, test2, test3, test4, test5
GREEN: impl1, impl2, impl3, impl4, impl5
正确姿势(垂直切片):
RED→GREEN: test1→impl1
RED→GREEN: test2→impl2
RED→GREEN: test3→impl3我以前让 Claude Code 写功能的方式是水平的:给它一个完整的功能需求,它写出整个实现,我再去测试。功能越复杂,这个循环越长;出错了越难 debug,推倒重来的成本越高。
/tdd 强迫它垂直切:一次只实现一个行为,有测试为证,绿了再下一个。
在量化场景里这个模式特别适合因子工程。以前写一个因子模块,恨不得一口气把数据清洗、特征计算、标准化、回测接口全写完,然后发现数据清洗那层有 bug,整个模块都得重测。换成 /tdd 的姿势:先写数据清洗的测试和实现,绿了;再写特征计算,绿了;依次往下。回测接口那里出问题,不影响前面已经绿的部分。
调试成本降了,不夸张。
还有一个细节值得单独说:SKILL.md 里明确写了"测试行为,不测实现"。测"这个函数给我正确的夏普比率",不测"这个函数调用了 np.std"。后者一重构就全挂,前者重构之后还是绿的。这个区别在 AI 大量写代码的语境下特别重要------因为 AI 会重构,会换实现方式,如果你的测试测的是实现细节,你就在测 AI 的代码风格,而不是测你的业务逻辑。
CONTEXT.md + /grill-with-docs:让 AI 说你的语言,不是你说 AI 的语言
这是装完所有 Skills 之后,我认为对日常工作流影响最持久的一个。
量化有自己的行话。"夏普比率"和"信息比率"不是同一个东西,但如果你跟 Claude Code 说"信息比率",它可能给你写成 risk-adjusted return 的通用计算公式,而不是因子分析里那个特定含义的 IR。"回撤"和"最大回撤"也不一样。"因子暴露"在不同语境下有不同含义。
以前每次开新对话,我都要把这些背景重新建立一遍,或者接受 AI 用它自己的理解来处理我的术语。
CONTEXT.md 解决的就是这个:一个存放"你这个项目的领域词汇表"的文件。定义你这里的"信号"是什么、"风险预算"指什么、"Alpha 衰减"在你的框架里怎么算......放在 CONTEXT.md 里,AI 读到这个文件就知道你的专有语言。一次定义,全项目生效,不需要每次对话重新解释。
构建 CONTEXT.md 的工具是 /grill-with-docs------和 /grill-me 类似的问答流程,但额外做两件事:把对话里出现的项目专有词汇自动加进词汇表,同时判断本次讨论是否值得写一个 ADR(架构决策记录)。
ADR 的写入标准很克制:不是每个决定都要写,/grill-with-docs 的判断条件是三个同时满足------难以逆转、不看背景会觉得奇怪、真正权衡过备选方案。符合这三个才写,其他的不写。
我的情绪 Dashboard 用下来,大概 10 次架构讨论里有 2-3 次真的值得 ADR。写了之后,下次 Claude Code 问我"为什么要用这个数据结构",直接把 ADR 甩给它------不用再解释一遍当时的取舍。
节省时间是真的。更重要的是减少了重复决策:AI 不会再建议你换掉一个你三个月前认真权衡过的方案。
/diagnose:调试是有方法论的,你以为在 debug,其实在蒙
这是测试时候最意外的一个。
我以前 debug 的方式......说出来有点丢人。基本上就是:看到报错,猜一个原因,让 Claude Code 改一下,跑一下,不对,再猜,再改,再跑。运气好两轮解决,运气不好改了七八轮,最后还得回滚。
这不叫 debug,这叫猜谜。
/diagnose 给了一个强制的五步流程:
重现 → 找最小可重现样本,能稳定复现才算开始
最小化 → 把样本缩小到最小,去掉所有不相关的东西
假设 → 写出来 3 个可能原因,排序,决定先验证哪一个
Instrument → 加日志/断言验证假设,不同时改超过一件事
修复 + 回归测试 → 修好之后写一个测试证明修好了,防止下次回来
听起来是常识。实操下来发现自己之前从来没认真做第 3 步:把假设写出来,排序。在脑子里"觉得可能是这个",和白纸上写"假设 1:数据管道里的时区处理错误(概率 60%),假设 2:因子归一化的 NaN 没处理(概率 30%)",是两件完全不同的事。
前者是感觉,后者是工程。
我拿了一个卡了两天的 bug 测 /diagnose,写假设那一步就定位了------是 NaN 传进了下游,因为静默失败,一直没有报错。
不是 /diagnose 聪明,是它强迫我在动手之前先思考。这一步我之前跳过了两天。
说实话,坑也有几个
TypeScript / 前端偏向明显。 Matt Pocock 来自 TypeScript 生态,SKILL.md 里的代码示例、测试框架假设(Vitest)、项目结构假设全是前端背景。Python 量化用户需要把"Vitest"心理替换成"pytest",把垂直切片的概念重新映射到单因子测试。不是不能用,是需要一点翻译工作。
CONTEXT.md 需要你自己维护。 它不会自动长大。/grill-with-docs 会在你主动跑它的时候更新词汇表,但如果你不跑这个命令,词汇表就停在上次更新的状态。项目复杂了之后,定期 /grill-with-docs 要成为习惯,不然 AI 用的还是旧词汇。
部分技能功能重叠。 /grill-me 和 /grill-with-docs 区别只在后者多了 CONTEXT.md 更新和 ADR,日常用的时候有时候搞不清应该用哪个。建议的规则:纯需求澄清用 /grill-me,涉及架构决策或领域概念引入的用 /grill-with-docs。
对量化和金融 AI 程序员意味着什么
AI 编程工具这波浪潮有一个隐患在慢慢放大:代码的生产速度远超代码的理解速度。
以前你写 200 行,慢,但每一行你知道在干什么。现在 Claude Code 一次输出 500 行,快,但那 500 行的架构质量、测试覆盖、边界条件处理------你来不及想。
量化场景下这个问题更危险,因为代码质量直接影响信号质量。一个静默失败的数据清洗 bug,可能让你的策略回测表现很好,上线之后才发现一直在测一个有缺陷的数据集。这种错误不报错、不崩溃,只是悄悄地让你的信号失效。
mattpocock/skills 干的事是:把软件工程纪律注入 AI 编程工作流。不是让你写得更慢,是让你写得更稳。
对量化程序员来说,这套方法论和量化本身的逻辑是一致的:不是押注感觉,是建立可验证的假设,是用数据而不是直觉驱动决策。/diagnose 里"写出假设、排序、逐一验证",跟你设计一个因子实验的方法论是同一件事,换了个领域。
你是哪种情况
在用 Claude Code 做量化 / 金融 AI 开发、已经踩过"造错了再推倒"的坑的:直接装,优先装 /grill-me 和 /tdd,这两个技能回报最立竿见影。装完之后下一个任务开始之前先跑 /grill-me,感受一下被问 9 个问题之后的"准备感"和之前直接开干的区别。
用 Claude Code 写代码但感觉架构在慢慢腐烂、不知道怎么遏制的:/grill-with-docs + /improve-codebase-architecture 是你的场景。前者建立 CONTEXT.md 和 ADR,后者基于这个文档分析现有代码结构的改善空间。两个配合用,效果比单独用任何一个好很多。
还没开始用 AI 编程工具、不确定要不要接入工作流的:从 /grill-me 开始,在你脑子里有个大概清楚但说不清楚的想法的时候用它------它会帮你把想法变成可执行的需求。这是 AI 能帮你做的最低成本、最高收益的事情之一,不需要复杂配置,一行命令,5 分钟看到效果。
最后
氛围编程(Vibe Coding)这个词听起来像嘲笑,但它描述的是一个真实的陷阱:你以为自己在驾驭 AI,其实是在随波逐流,任由它把你带到它认为"差不多"的地方。
mattpocock/skills 提供了一套从工程实践出发的反制:需求澄清、测试覆盖、领域语言、调试方法论。这些东西在 AI 出现之前就是好的软件工程习惯,现在只是把它们系统化地接入了 AI 工作流。
83.4k Star、1.2M 安装量,说明整个圈子在往这个方向走。强烈推荐。
如果你也在用 Claude Code 做量化或者金融 AI,评论区聊一下你的 Skills 配置------18 个里面我实际高频用的是 4 个,其他人的选择可能完全不同。