GRU (Gated Recurrent Unit,门控循环单元) 是一种改进的循环神经网络(RNN),旨在解决传统 RNN 的梯度消失问题,并简化 LSTM 的复杂结构。

简单译文:我们在我们的实验中选择GRU是因为它的实验效果与LSTM相似,但是更易于计算。
核心思想总结
GRU 通过两个门实现:
- 更新门 :平衡历史记忆 与当前新信息的取舍
- 重置门 :控制计算新状态时是否忽略/重用历史
- 结构简化 :合并 LSTM 的遗忘/输入门、去掉细胞状态,效率更高、参数更少,在多数任务上性能接近 LSTM。
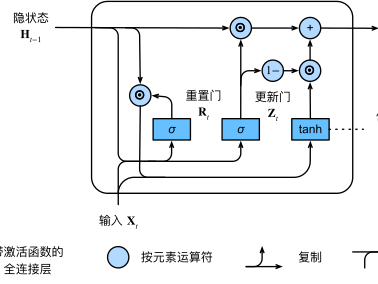
核心结构:两个门控机制
GRU 的核心是通过重置门 (Reset Gate)和更新门 (Update Gate)来控制信息的流动与保留,没有 LSTM 的细胞状态(Cell State) ,仅用隐藏状态(Hidden State) 兼顾记忆与输出。
前向计算过程
设:
- x t x_t xt:当前时刻输入
- h t − 1 h_{t-1} ht−1:前一时刻隐藏状态(历史记忆)
- h t h_t ht:当前时刻隐藏状态(输出)
- σ \sigma σ: Sigmoid 激活函数(输出 0 , 1 0, 1 0,1) 表示门的开闭 1:开 0:闭
- tanh \tanh tanh:双曲正切激活函数(输出 − 1 , 1 -1, 1 −1,1)
重置门 (Reset Gate, r t r_t rt)
作用 :控制计算新候选状态 时,依赖多少历史信息 。
r t → 1 r_t \to 1 rt→1:充分利用历史 ,结合新信息计算
r t → 0 r_t \to 0 rt→0:忽略历史,仅基于当前输入重新计算
- 公式:
r t = σ ( W x r x t + b x r + W h r h t − 1 + b h r ) \Huge r_t = \sigma\left( W_{xr} x_t+ b_{xr} + W_{hr} h_{t-1} + b_{hr} \right) rt=σ(Wxrxt+bxr+Whrht−1+bhr)
候选隐藏状态 (Candidate Hidden State, h ~ t \tilde{h}_t h~t)
作用 :结合当前输入 x t x_t xt和重置门 r t r_t rt加权后的旧隐藏状态= r t ⊙ ( W h h h t − 1 + b h h ) r_t \odot ( W_{hh} h_{t-1} + b_{hh}) rt⊙(Whhht−1+bhh),生成新的候选状态:
⊙ \odot ⊙ 为按元素相乘(Hadamard 积)。
- 公式:
h ~ t = tanh ( W x h x t + b x h + r t ⊙ ( W h h h t − 1 + b h h ) ) \Large \tilde{h}t = \tanh \left( W{xh} x_t + b_{xh}+ r_t \odot \left( W_{hh} h_{t-1} + b_{hh} \right) \right) h~t=tanh(Wxhxt+bxh+rt⊙(Whhht−1+bhh))
更新门 (Update Gate, z t z_t zt)
作用 :控制历史信息 ( h t − 1 h_{t-1} ht−1)有多少保留到当前,新信息 ( x t x_t xt)有多少写入。
z t → 1 z_t \to 1 zt→1:完全保留历史 ,忽略新输入
z t → 0 z_t \to 0 zt→0:完全遗忘历史,用新信息覆盖
- 公式:
z t = σ ( W x z x t + b x z + W h z h t − 1 + b h z ) \Huge z_t = \sigma\left( W_{xz} x_t+ b_{xz} + W_{hz} h_{t-1} + b_{hz} \right) zt=σ(Wxzxt+bxz+Whzht−1+bhz)
最终隐藏状态 (Current Hidden State, h t h_t ht)
作用 :结合更新门 z t z_t zt,最终输出当前状态。
( 1 − z t ) ⊙ h ~ t (1-z_t) \odot \tilde{h}t (1−zt)⊙h~t:保留部分旧信息
z t ⊙ h t − 1 z_t \odot h{t-1} zt⊙ht−1:加入部分新信息
本质:线性插值平衡新旧信息
- 公式:
h t = ( 1 − z t ) ⊙ h ~ t + z t ⊙ h t − 1 \Huge h_t = (1 - z_t) \odot\tilde{h}t + z_t \odot h{t-1} ht=(1−zt)⊙h~t+zt⊙ht−1
GRU 与 LSTM 核心区别
| 特性 | GRU | LSTM |
|---|---|---|
| 门控数量 | 2个(更新、重置) | 3个(遗忘、输入、输出) |
| 状态单元 | 仅隐藏状态 h t h_t ht | 细胞状态 C t C_t Ct + 隐藏状态 h t h_t ht |
| 参数规模 | 少(约 LSTM 的 2/3) | 多 |
| 计算速度 | 快(训练/推理快约 30--40%) | 慢 |
| 记忆能力 | 较强(适合 < 500 步序列) | 强(适合 > 1000 步长序列) |
| 适用场景 | 资源受限、实时性高、短序列 | 高精度、长依赖、复杂任务 |
手写GRU模型代码
import torch
import torch.nn as nn
# 导入包
# 保证可复现,随机数一致
torch.manual_seed(42)
model = nn.GRU(input_size=10,hidden_size=20,num_layers=1)
# 和自定义的模型 x 输入一样,w,b
class MyGRU(nn.Module):
def __init__(self,input_size,hidden_size,num_layers=1):
super(MyGRU,self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# x的w 和 b (3*hidden_size,input_size)=(60,10)
self.w_ih = model.weight_ih_l0
self.b_ih = model.bias_ih_l0
# h的w 和 b (3*hidden_size,hidden_size)=(60,20)
self.w_hh = model.weight_hh_l0
self.b_hh = model.bias_hh_l0
def forward(self,x,h0):
# 取一层 上一刻状态
h_t_1 = h0[0]
# 保存所有的隐藏的输出
h_all = []
for i in range(x.shape[0]):
# 输入和隐藏层相乘,第一批的单词
x_t = x[i]
# x的线性映射
ih = x_t@self.w_ih.T +self.b_ih
# h的线性映射
hh = h_t_1@self.w_hh.T +self.b_hh
# 拆出来3个门的输入 重置门,更新门,候选隐藏层
ih_r,ih_z,ih_n = ih.chunk(3,dim=1)
hh_r,hh_z,hh_n = hh.chunk(3,dim=1)
# 重置门,获取值
r_t = torch.sigmoid(ih_r + hh_r)
# 候选隐藏层,获取值
n_t = torch.tanh(ih_n + r_t*hh_n)
# 更新门,获取值
z_t = torch.sigmoid(ih_z + hh_z)
# 获取最终的隐藏层
h_t = (1-z_t)*n_t + z_t*h_t_1
h_all.append(h_t)
# 当成下一刻的输入
h_t_1 = h_t
# 将h_all 变成张量
h_all = torch.stack(h_all,dim=0)
# 多一维,一层的隐藏层维数
h_final = h_t.unsqueeze(0)
return h_all,h_final
# x 3句话,5个单词,10维,没有写bath_first
x = torch.randn(5,3,10)
# 1 = 层数*方向 3句话 20隐藏层维度
h0 = torch.zeros(1,3,20)
# 输入x和h0
h_all,h_final = model(x,h0)
mygru = MyGRU(input_size=10,hidden_size=20)
my_all,my_final = mygru(x,h0)
print(h_all.shape)
print(my_all.shape)
# print(h_final)
# print(my_final)
# 2个数差距是多少
# print(h_all-my_all)
# print(torch.abs(h_all-my_all))
# 求总差距,越接近0 越好
print( torch.sum(torch.abs(h_all-my_all)) )