在《Semi-Supervised Classification with Graph Convolutional Networks》中,使用两层图卷积网络(GCN)对具有对称邻接矩阵 A(二进制或加权)的图进行半监督节点分类。
首先在预处理阶段计算 A^=D~−1/2A~D~−1/2\hat{A} = \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2}A^=D~−1/2A~D~−1/2。
随后,前向模型的形式如下:
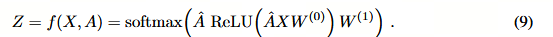
A. 权重矩阵与网络结构
文本中提到了两个权重矩阵:
- W(0)∈RC×HW^{(0)} \in \mathbb{R}^{C \times H}W(0)∈RC×H :这是输入层到隐藏层 的权重矩阵。
- CCC 通常代表输入特征的维度(例如,节点的特征数)。
- HHH 代表隐藏层中的特征映射(feature maps)数量,也就是隐藏层的神经元数量。
- 含义:这个矩阵负责将原始输入数据转换为隐藏层能够处理的高阶特征。
- W(1)∈RH×FW^{(1)} \in \mathbb{R}^{H \times F}W(1)∈RH×F :这是隐藏层到输出层 的权重矩阵。
- FFF 代表输出类别的数量(例如,如果是分类猫、狗、鸟,则 F=3F=3F=3)。
- 含义这个矩阵负责将隐藏层学到的特征映射到最终的预测结果上。
在传统 CV(如 CNN)中,卷积核(相当于 AAA)才是需要学习的参数;但在图卷积(GCN)中,结构矩阵 AAA 却是固定的输入。
造成这种反直觉现象的原因,是因为图像(Image)和图(Graph)的空间几何结构不同。我们可以从以下三个维度来彻底理清两者的本质区别:
1. 卷积核参数的"寄生"对象不同
- 图像卷积 (CNN):图像具有网格规则性(Grid Structure)。每个像素周围的邻居结构永远是一样的(如 3×33 \times 33×3 的九宫格)。
- 因为结构是固定的、平凡的,我们不需要把"结构"当成输入。
- 我们学习的是九宫格里每个相对位置的权重(上、下、左、右的权重)。这 9 个数字就是可学习的参数。
- 图卷积 (GCN):图具有非欧几里得不规则性(Non-Euclidean Structure)。每个节点的邻居数量、连接方式都是千差万别的(节点 A 有 2 个邻居,节点 B 有 1000 个邻居)。
- 因为拓扑结构太复杂,我们必须把"谁和谁连、怎么连"作为输入数据(即 AAA)显式地喂给模型。
- 既然 AAA 已经决定了信息的流动通道,那我们学习的 Θ\ThetaΘ,则是针对特征通道(Channel)的变换矩阵。
2. 两种卷积的等价对应关系
为了让你更直观地理解,我们可以把图像卷积写成矩阵形式。实际上,图像卷积可以看作是图卷积的一种特例:
| 概念 | 传统图像卷积 (CNN) | 图卷积 (GCN) |
|---|---|---|
| 空间拓扑 | 隐含在像素网格中(规则九宫格) | 显式写在邻接矩阵 AAA 中(不规则网络) |
| 参数角色 | 卷积核 WWW 是参数(决定空间哪个位置更重要) | 映射矩阵 Θ\ThetaΘ 是参数(决定特征哪个通道更重要) |
| 参数更新 | 更新卷积核,使其学会识别特定空间模式(如边缘、纹理) | 更新特征权重,使其学会如何将邻居聚合过来的信息转化为有用的高阶特征 |
3. GCN 为什么要这样设计?(参数共享的无奈)
如果像你所想,把图的邻接矩阵 AAA 里面的每个元素都变成可学习的参数,会发生什么?
- 如果图有 NNN 个节点, AAA 的大小就是 N×NN \times NN×N。
- 这意味着参数量将高达 O(N2)\mathcal{O}(N^2)O(N2)。当图有 100 万个节点时,参数量多到根本无法训练。
- 更致命的是,这样的参数无法泛化。如果你训练好了一个模型,突然加入了一个新节点,或者要把模型用到另一个全新的图上,由于 AAA 的尺寸变了,原本学到的参数直接报废。
而通过将参数放在 Θ\ThetaΘ(大小为 C,FC, FC,F,仅与输入/输出特征维度有关,与节点数 NNN 无关)中,GCN 完美实现了参数共享:无论图有多大、节点怎么增加,所有节点和边在聚合信息时,使用的都是同一套 Θ\ThetaΘ。
GCN 学习特征通道的变换规律
- CNN 的卷积:在固定的空间网格上,学习空间的加权模式。
- GCN 的图卷积:在输入的复杂拓扑结构(AAA)上,学习特征通道的变换规律(Θ\ThetaΘ)。
4 CV卷积是 输出=AX+b\text{输出} =AX+b输出=AX+b,GCN是输出=A^XΘ\text{输出} = \hat{A} X \Theta输出=A^XΘ
AX+bAX+bAX+b 与 XΘX\ThetaXΘ 并不冲突,它们是正交的
AX+bAX+bAX+b 属于空间聚合(Aggregation),而 XΘX\ThetaXΘ 属于特征变换(Transformation)。
在完整的 GCN 公式中,这两者是同时存在的:
输出=A^XΘ\text{输出} = \hat{A} X \Theta输出=A^XΘ
- 其中 A^=D~−1/2A~D~−1/2\hat{A} = \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2}A^=D~−1/2A~D~−1/2,维度是 N,NN, NN,N(表示节点间的邻接关系)。
- 计算顺序(结合律):A^XΘ=(A^X)Θ=A^(XΘ)\hat{A} X \Theta = (\hat{A} X) \Theta = \hat{A} (X \Theta)A^XΘ=(A^X)Θ=A^(XΘ)。
无论是先做空间聚合再做特征变换,还是先做特征变换再做空间聚合,数学结果完全一致:
- A^(XΘ)\hat{A} (X \Theta)A^(XΘ):先把每个节点的 CCC 维特征通过 Θ\ThetaΘ 映射到 FFF 维,再让邻居节点之间进行加权求和(AAA 的作用)。
- (A^X)Θ(\hat{A} X) \Theta(A^X)Θ:先让邻居节点之间对 CCC 维特征进行加权求和,再将聚合后的结果通过 Θ\ThetaΘ 映射到 FFF 维。
AXAXAX 负责处理节点与节点之间的信息流动(横向聚合),而 XΘX\ThetaXΘ 负责处理通道与通道之间的特征变换(纵向投影)。它们分工明确,互不干扰。