1:笛卡尔积
1:什么是笛卡尔积
笛卡尔积就是两张表所有记录的所有可能组合。
举个最简单的例子:
- 表 A 有 2 条记录:苹果,香蕉
- 表 B 有 3 条记录:红色,黄色,绿色
- 它们的笛卡尔积就是 2×3=6 条记录:(苹果,红色), (苹果,黄色), (苹果,绿色),(香蕉,红色), (香蕉,黄色), (香蕉,绿色)
在 MySQL 中,当你直接查询两张表不加任何条件时,得到的就是笛卡尔积。
2:下面所有实验的基础准备表
sql
-- 创建部门表DEPT
CREATE TABLE DEPT (
DEPTNO INT PRIMARY KEY, -- 部门编号
DNAME VARCHAR(14), -- 部门名称
LOC VARCHAR(13) -- 部门位置
);
-- 创建员工表EMP
CREATE TABLE EMP (
EMPNO INT PRIMARY KEY, -- 员工编号
ENAME VARCHAR(10), -- 员工姓名
JOB VARCHAR(9), -- 工作岗位
MGR INT, -- 上级领导编号
HIREDATE DATE, -- 入职日期
SAL DECIMAL(7,2), -- 工资
COMM DECIMAL(7,2), -- 奖金
DEPTNO INT, -- 部门编号
FOREIGN KEY (DEPTNO) REFERENCES DEPT(DEPTNO)
);
-- 创建工资等级表SALGRADE
CREATE TABLE SALGRADE (
GRADE INT, -- 工资等级
LOSAL INT, -- 该等级最低工资
HISAL INT -- 该等级最高工资
);
-- 插入部门数据
INSERT INTO DEPT VALUES
(10, 'ACCOUNTING', 'NEW YORK'),
(20, 'RESEARCH', 'DALLAS'),
(30, 'SALES', 'CHICAGO'),
(40, 'OPERATIONS', 'BOSTON');
-- 插入员工数据
INSERT INTO EMP VALUES
(7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, NULL, 20),
(7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30),
(7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30),
(7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, NULL, 20),
(7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30),
(7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, NULL, 30),
(7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, NULL, 10),
(7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, NULL, 20),
(7839, 'KING', 'PRESIDENT', NULL, '1981-11-17', 5000, NULL, 10),
(7844, 'TURNER', 'SALESMAN', 7698, '1981-09-08', 1500, 0, 30),
(7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, NULL, 20),
(7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, NULL, 30),
(7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, NULL, 20),
(7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, NULL, 10);
-- 插入工资等级数据
INSERT INTO SALGRADE VALUES
(1, 700, 1200),
(2, 1201, 1400),
(3, 1401, 2000),
(4, 2001, 3000),
(5, 3001, 9999);3:看到笛卡尔积的产生
sql
-- 第一步:先看一下DEPT表有多少条记录
SELECT COUNT(*) FROM DEPT; -- 结果:4条记录
-- 第二步:看一下EMP表有多少条记录
SELECT COUNT(*) FROM EMP; -- 结果:14条记录
-- 第三步:直接查询两张表,不加任何条件(产生笛卡尔积)
-- 注意:这会返回4×14=56条记录!
SELECT * FROM EMP, DEPT;
-- 只看前10条,感受一下结果是什么样的
SELECT EMP.ename, DEPT.dname FROM EMP, DEPT LIMIT 10;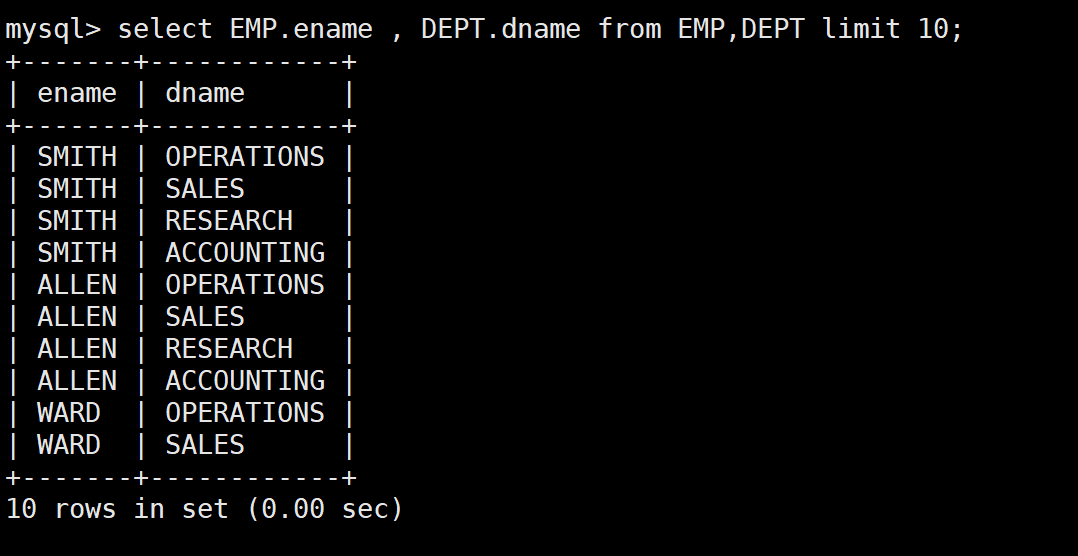
- 员工 SMITH 实际上只属于 RESEARCH 部门(20 号)
- 但笛卡尔积把 SMITH 和所有 4 个部门都组合了一遍
- 这显然是错误的、无意义的数据
- 笛卡尔积本身是数学概念,但在数据库中几乎没有直接使用价值
- 多表查询的本质就是:先产生笛卡尔积 → 再用连接条件过滤掉错误的组合
- 忘记加连接条件是初学者最常见的错误,会导致结果集爆炸式增长
2:多表查询基础(内连接的传统写法)
1:连接条件
连接条件就是用来从笛卡尔积中筛选出正确关联记录的条件。
对于员工表和部门表,正确的连接条件是:EMP.deptno = DEPT.deptno
- 意思是:只保留员工的部门编号和部门的部门编号相等的记录
- 这样就能得到每个员工真正所属的部门信息
2:正确的多表查询(关联员工和部门)
sql
-- 写法1:完整写法,指定表名.字段名
-- 原理:先产生56条笛卡尔积,再筛选出deptno相等的14条正确记录
SELECT EMP.ename, EMP.sal, DEPT.dname
FROM EMP, DEPT
WHERE EMP.deptno = DEPT.deptno;
-- 写法2:给表起别名,简化代码(推荐)
-- e是EMP的别名,d是DEPT的别名
SELECT e.ename, e.sal, d.dname
FROM EMP e, DEPT d
WHERE e.deptno = d.deptno;
-- 增加额外的筛选条件:只显示10号部门的员工
SELECT e.ename, e.sal, d.dname
FROM EMP e, DEPT d
WHERE e.deptno = d.deptno -- 连接条件(必须写)
AND d.deptno = 10; -- 额外筛选条件(可选)
-- 关联三张表:显示员工姓名、工资、部门名称和工资等级
SELECT e.ename, e.sal, d.dname, s.grade
FROM EMP e, DEPT d, SALGRADE s
WHERE e.deptno = d.deptno -- 员工和部门的连接条件
AND e.sal BETWEEN s.losal AND s.hisal; -- 员工和工资等级的连接条件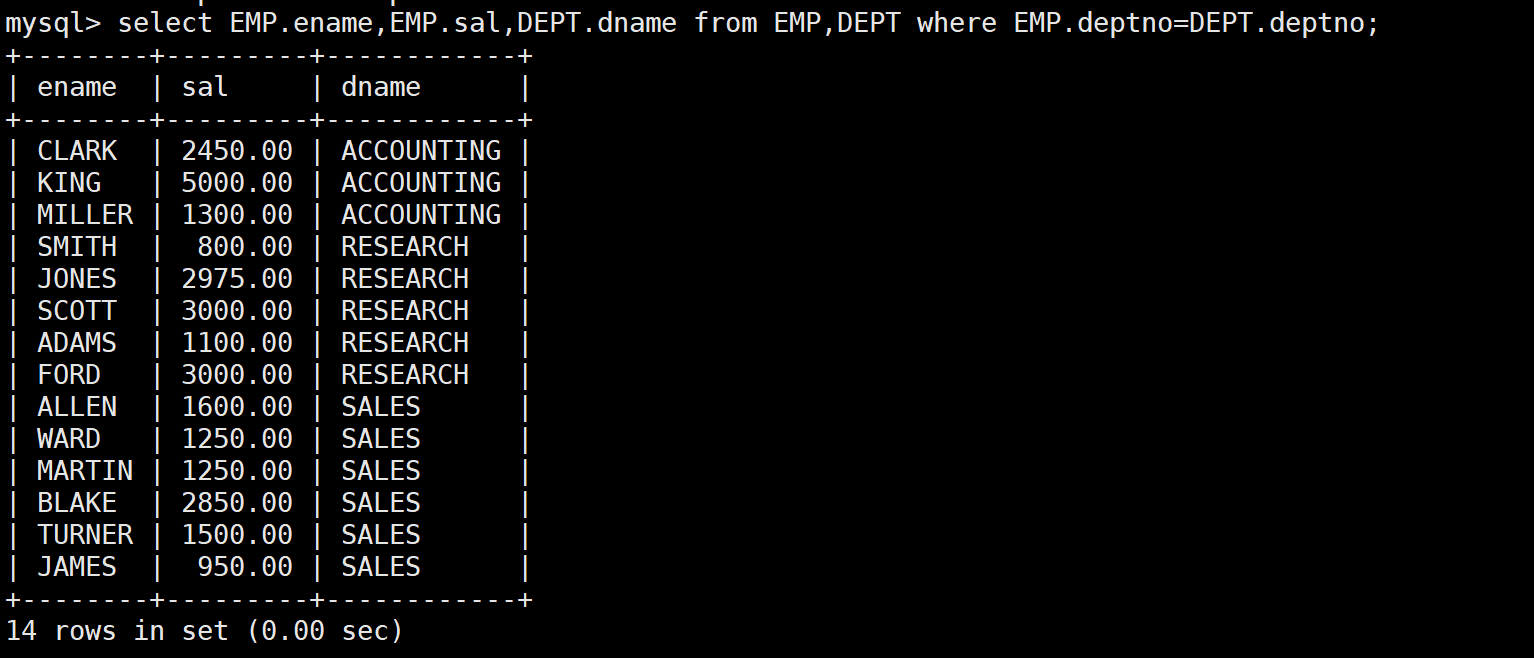
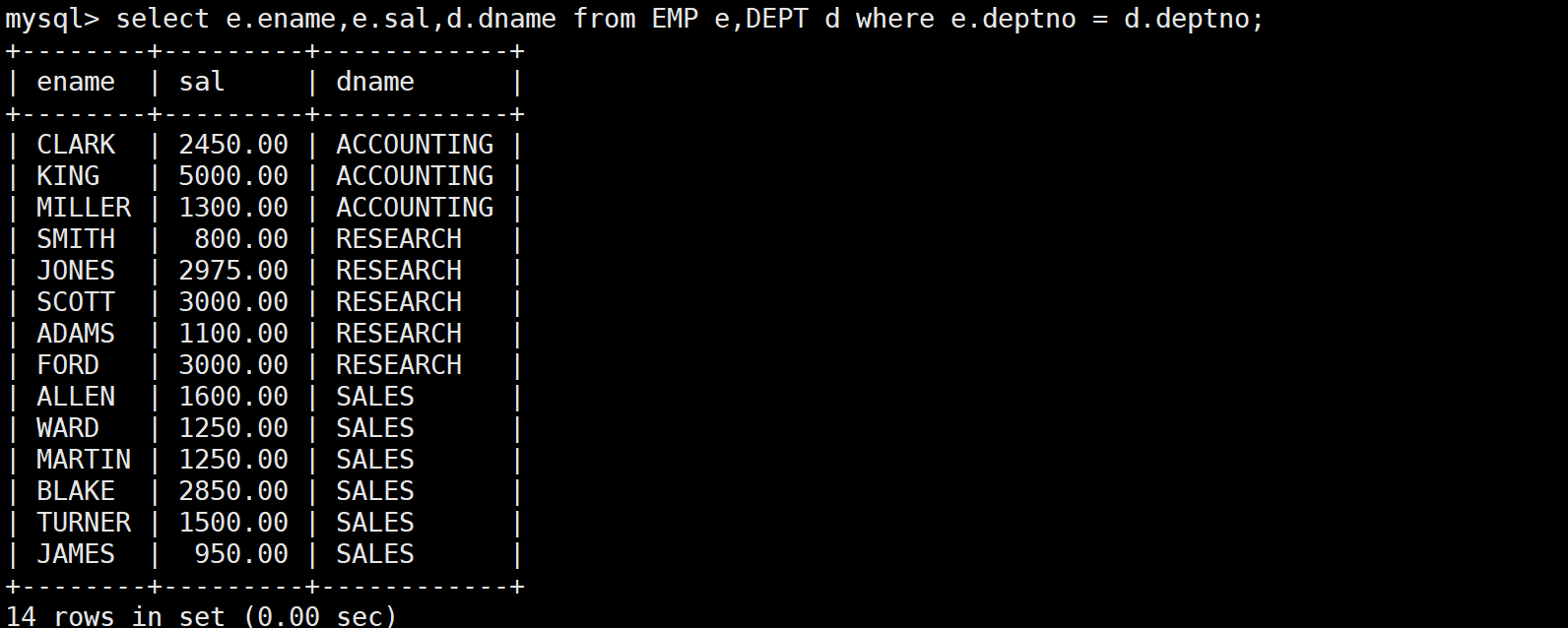

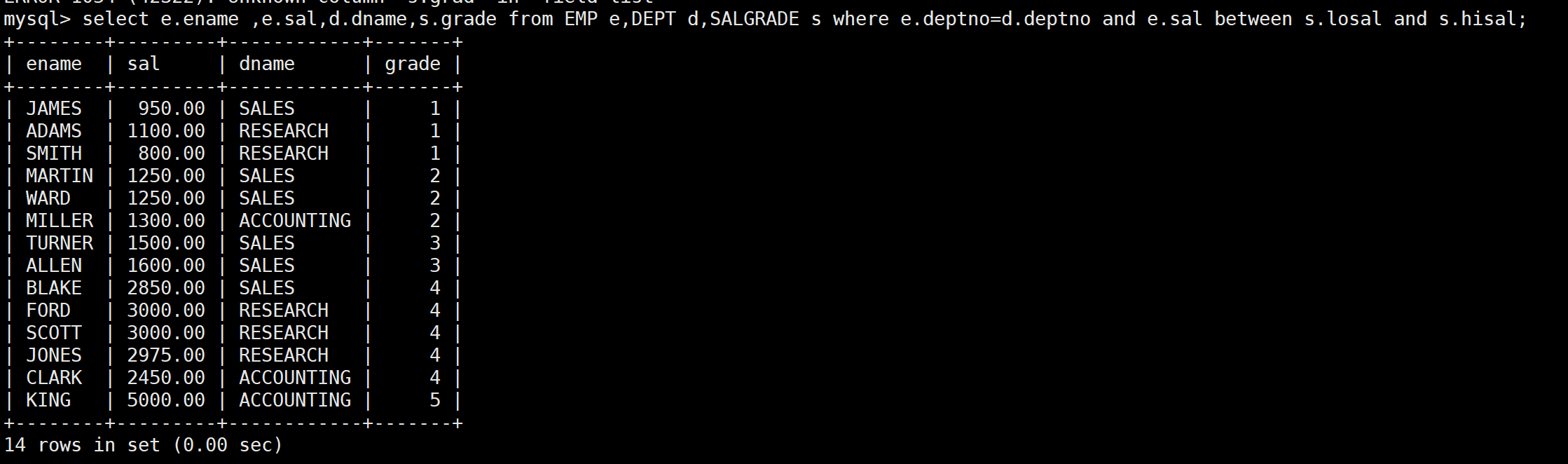
- 第一个查询返回 14 条记录,正好是员工表的记录数
- 每个员工都只和自己真正所属的部门关联
- 关联三张表时,需要写两个连接条件(N 张表需要 N-1 个连接条件)
3:常见错误
sql
-- 错误1:忘记写连接条件(产生56条笛卡尔积)
SELECT e.ename, d.dname FROM EMP e, DEPT d;
-- 错误2:连接条件写错(比如写成e.deptno = d.loc)
SELECT e.ename, d.dname FROM EMP e, DEPT d WHERE e.deptno = d.loc;
-- 错误3:字段名冲突,没有指定表名
-- 错误原因:deptno字段在两张表中都存在,MySQL不知道用哪个
SELECT ename, sal, deptno, dname FROM EMP e, DEPT d WHERE e.deptno = d.deptno;
-- 正确写法:指定表名
SELECT e.ename, e.sal, e.deptno, d.dname FROM EMP e, DEPT d WHERE e.deptno = d.deptno;3:自连接查询(同一张表自己连自己)
1:自连接
自连接就是把同一张表当作两张不同的表来进行连接查询。
使用场景 :当表内的数据存在层级关系 或父子关系时
- 员工表:员工和领导(都是员工,领导的 empno 是员工的 mgr)
- 分类表:商品分类和子分类
- 地区表:省份和城市
2:查询员工的上级领导
sql
-- 先看一下员工表的结构,理解mgr字段的含义
-- mgr是员工的上级领导的员工编号(empno)
SELECT empno, ename, mgr FROM EMP;
-- 需求:查询员工FORD的上级领导的编号和姓名
-- 方法一:使用子查询(分步思考)
-- 第一步:先查FORD的mgr是多少
SELECT mgr FROM EMP WHERE ename = 'FORD'; -- 结果:7566
-- 第二步:再查empno=7566的员工是谁
SELECT empno, ename FROM EMP WHERE empno = 7566; -- 结果:JONES
-- 合并成一个子查询
SELECT empno, ename
FROM EMP
WHERE empno = (SELECT mgr FROM EMP WHERE ename = 'FORD');
-- 方法二:使用自连接(推荐,性能更好)
-- 给同一张表起两个不同的别名:
-- worker:代表普通员工表
-- leader:代表领导表
SELECT leader.empno, leader.ename
FROM EMP worker, EMP leader
WHERE worker.mgr = leader.empno -- 连接条件:员工的mgr = 领导的empno
AND worker.ename = 'FORD'; -- 筛选条件:找FORD的领导
-- 拓展:查询所有员工的姓名和他们领导的姓名
-- 注意:KING没有领导,所以不会出现在结果中
SELECT worker.ename AS '员工姓名', leader.ename AS '领导姓名'
FROM EMP worker, EMP leader
WHERE worker.mgr = leader.empno;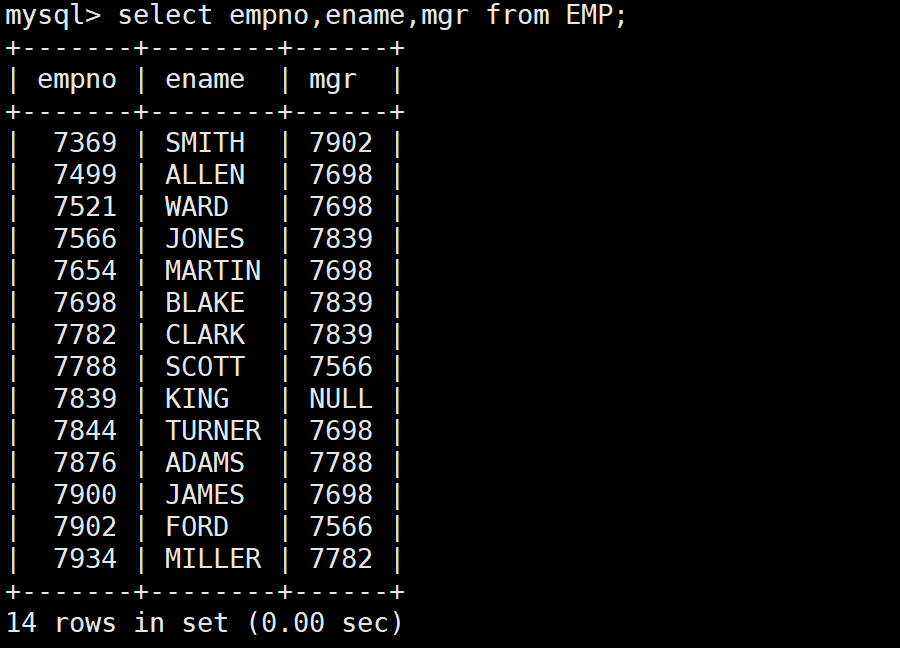
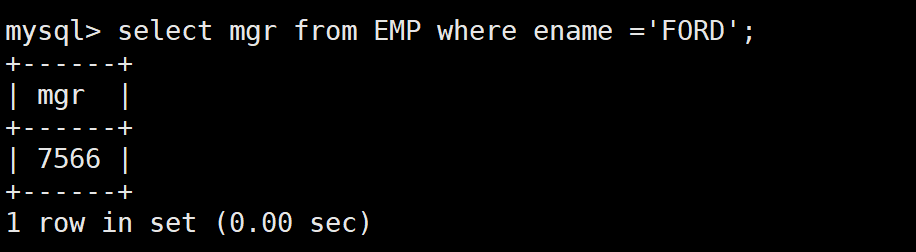
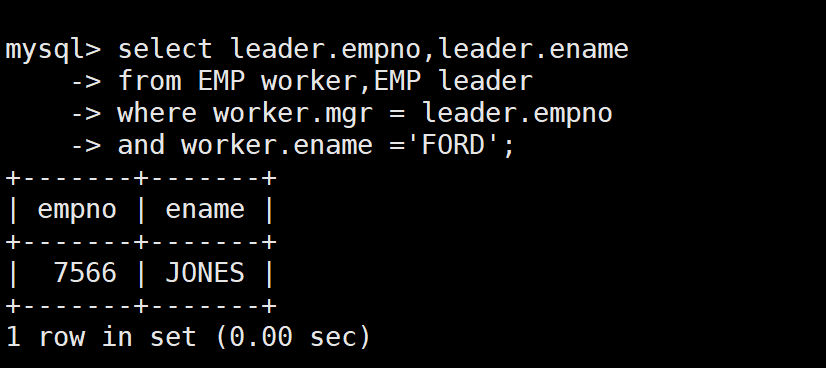
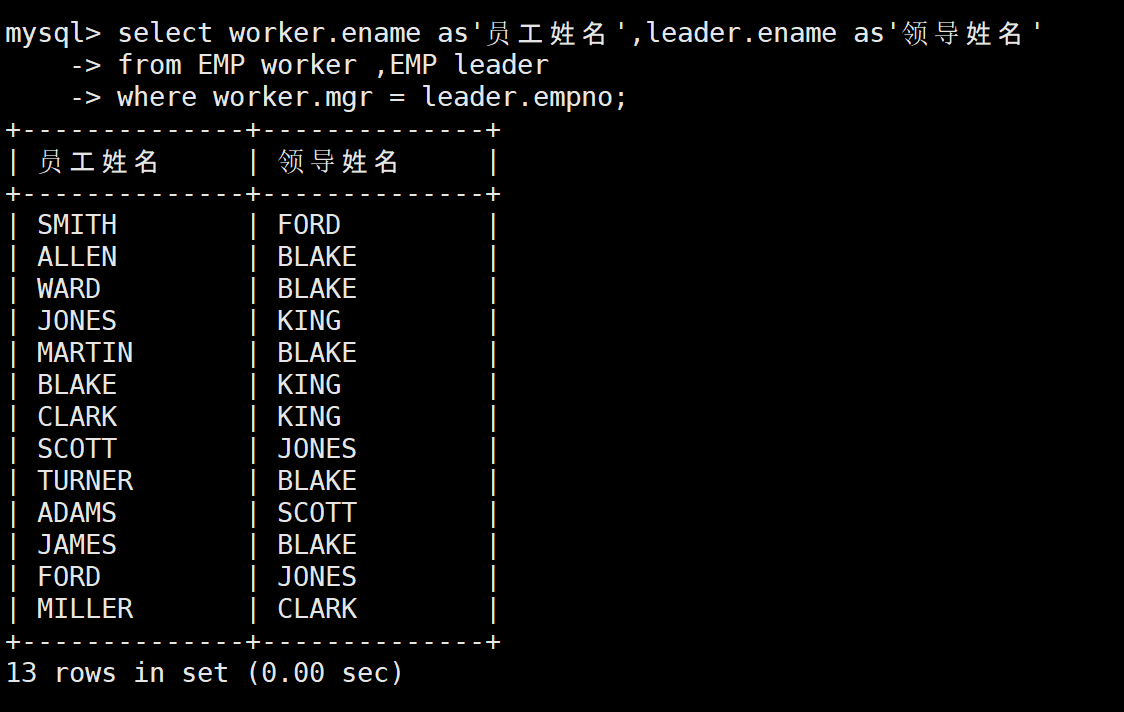
- 两种方法都能得到正确结果:FORD 的领导是 JONES(编号 7566)
- 自连接的性能通常比子查询好,特别是当数据量较大时
- 自连接的关键是给表起两个有意义的别名,把一张表当成两张表用
4:子查询(嵌套查询)、
1:子查询
子查询就是嵌入在其他 SQL 语句中的 SELECT 语句,也叫嵌套查询。
子查询可以出现在:
- WHERE 子句中(最常用)
- FROM 子句中(当作临时表)
- SELECT 子句中(较少用)
根据返回结果的不同,子查询分为:
- 单行子查询:返回一行一列数据
- 多行子查询:返回多行一列数据
- 多列子查询:返回一行或多行多列数据
2:单行子查询
sql
-- 单行子查询:子查询只返回一行一列数据
-- 可以使用单行比较运算符:=、>、<、>=、<=、<>
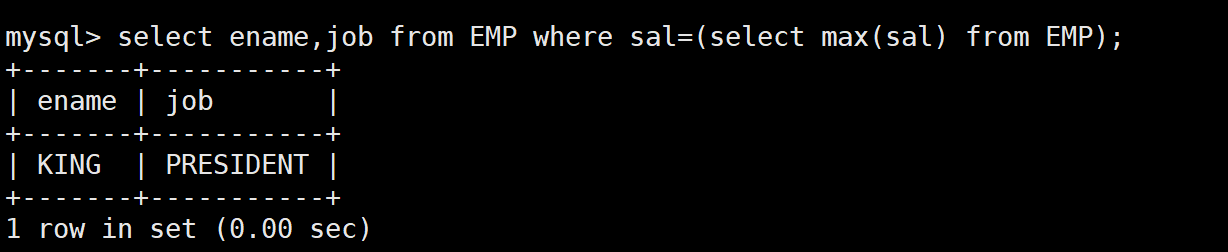
-- 需求1:显示工资最高的员工的名字和工作岗位
-- 第一步:先查最高工资是多少
SELECT MAX(sal) FROM EMP; -- 结果:5000
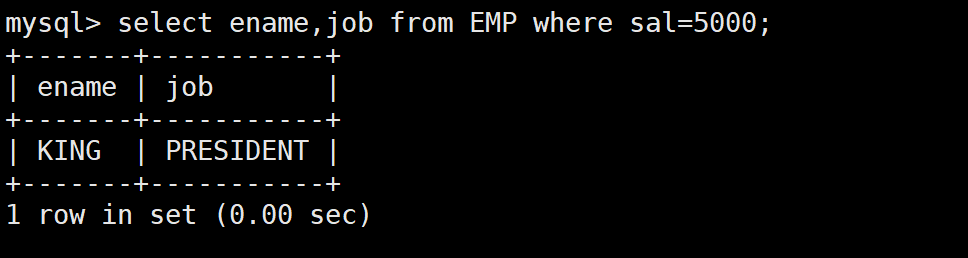
-- 第二步:再查工资等于5000的员工
SELECT ename, job FROM EMP WHERE sal = 5000;
-- 合并成子查询
SELECT ename, job FROM EMP WHERE sal = (SELECT MAX(sal) FROM EMP);
-- 需求2:显示工资高于平均工资的员工信息
SELECT ename, sal FROM EMP
WHERE sal > (SELECT AVG(sal) FROM EMP);
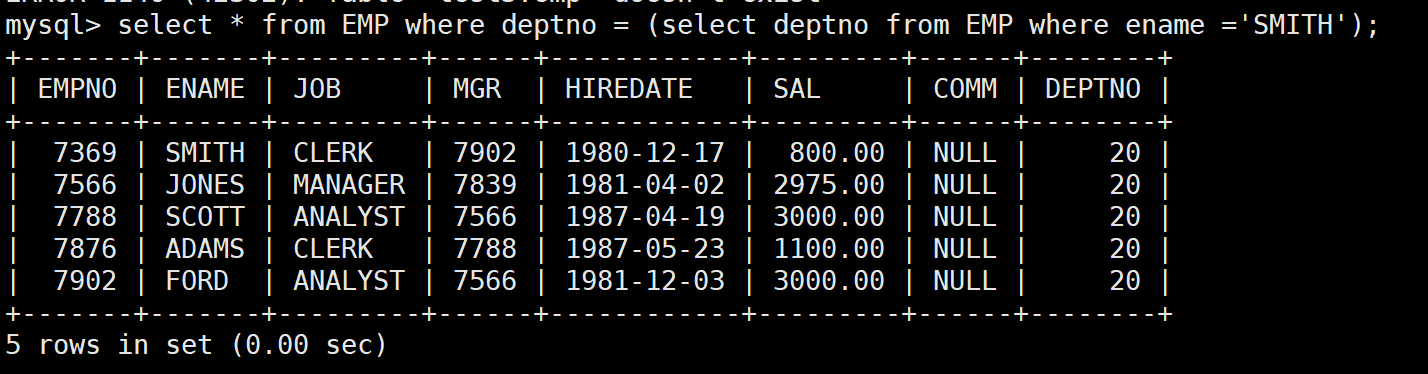
-- 需求3:显示和SMITH同一部门的员工
SELECT * FROM EMP
WHERE deptno = (SELECT deptno FROM EMP WHERE ename = 'SMITH');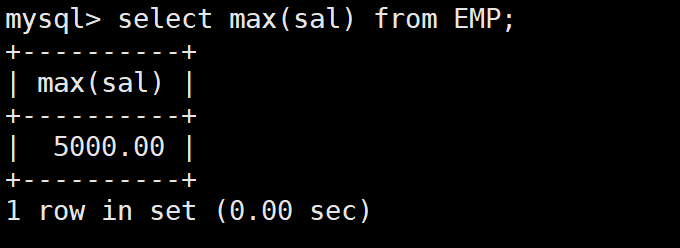

常见错误
sql
-- 错误:单行子查询返回了多行数据
-- 错误原因:如果有多个员工叫SMITH,子查询会返回多行
-- 此时不能使用=,应该使用IN
SELECT * FROM EMP WHERE deptno = (SELECT deptno FROM EMP WHERE ename = 'SMITH');3:多行子查询
- 掌握多行子查询的语法
- 学会使用 IN、ALL、ANY 三个关键字
sql
-- 多行子查询:子查询返回多行一列数据
-- 必须使用多行比较运算符:IN、ALL、ANY
-- 1. IN关键字:判断值是否在子查询的结果集中
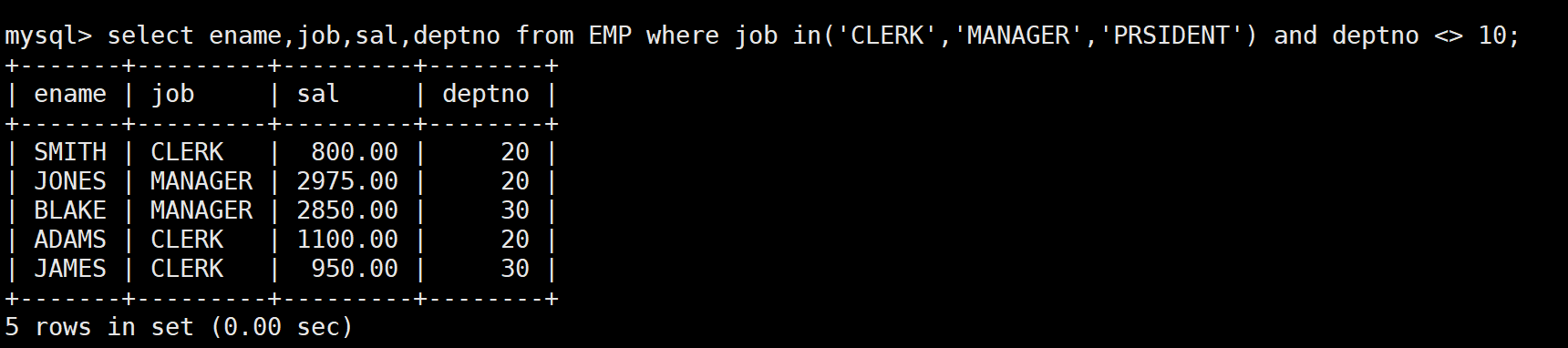
-- 需求:查询和10号部门的工作岗位相同的雇员,不包含10号部门自己
-- 第一步:先查10号部门有哪些岗位
SELECT DISTINCT job FROM EMP WHERE deptno = 10; -- 结果:CLERK、MANAGER、PRESIDENT
-- 第二步:再查其他部门中岗位在这个集合中的员工
SELECT ename, job, sal, deptno
FROM EMP
WHERE job IN ('CLERK', 'MANAGER', 'PRESIDENT')
AND deptno <> 10;
-- 合并成子查询
SELECT ename, job, sal, deptno
FROM EMP
WHERE job IN (SELECT DISTINCT job FROM EMP WHERE deptno = 10)
AND deptno <> 10;
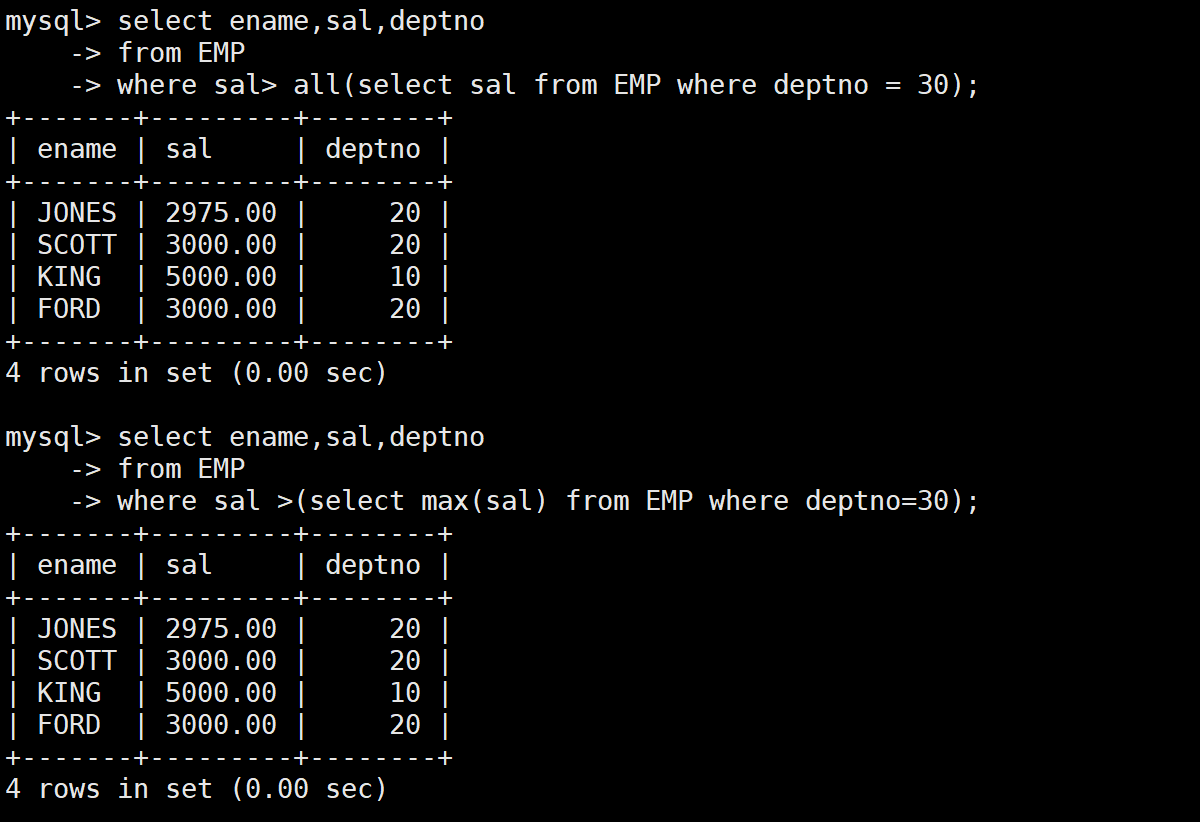
-- 2. ALL关键字:和子查询结果集中的所有值比较
-- 需求:显示工资比部门30的所有员工的工资都高的员工
-- 部门30的最高工资是2850,所以只要工资>2850就满足条件
SELECT ename, sal, deptno
FROM EMP
WHERE sal > ALL(SELECT sal FROM EMP WHERE deptno = 30);
-- 等价于:
SELECT ename, sal, deptno
FROM EMP
WHERE sal > (SELECT MAX(sal) FROM EMP WHERE deptno = 30);
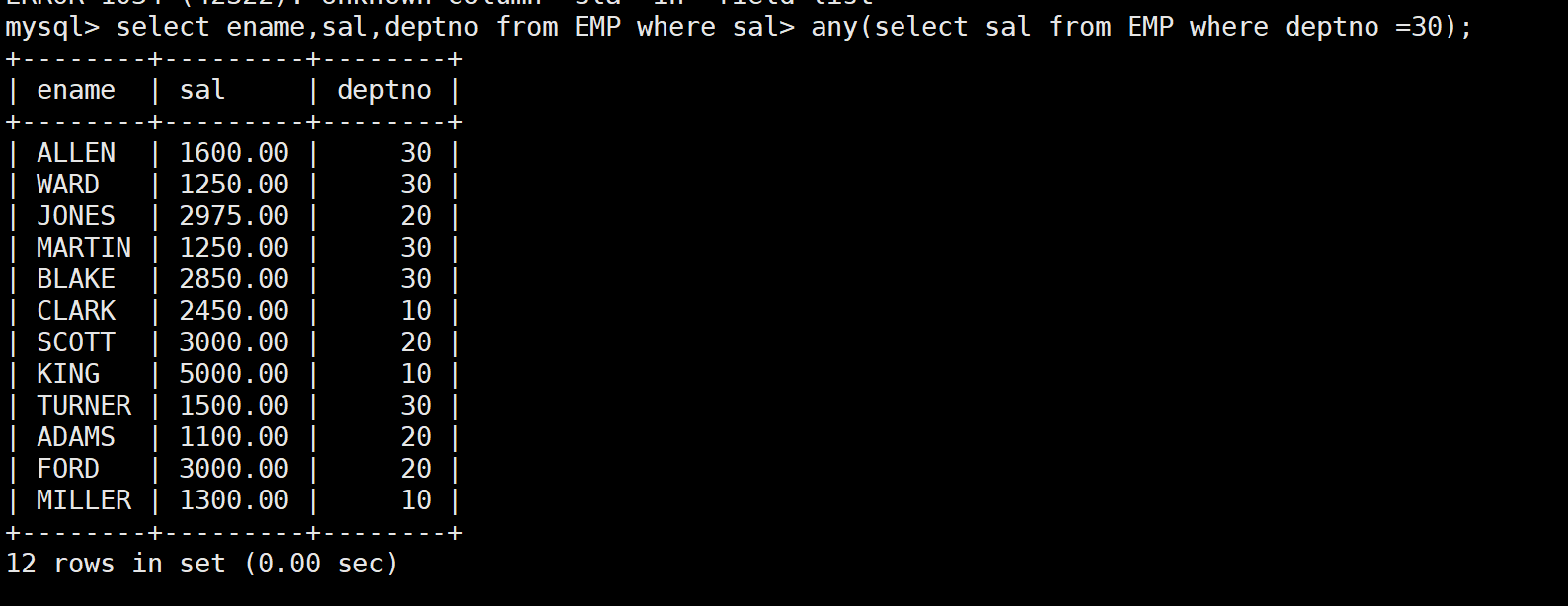
-- 3. ANY关键字:和子查询结果集中的任意一个值比较
-- 需求:显示工资比部门30的任意员工的工资高的员工
-- 部门30的最低工资是950,所以只要工资>950就满足条件
SELECT ename, sal, deptno
FROM EMP
WHERE sal > ANY(SELECT sal FROM EMP WHERE deptno = 30);
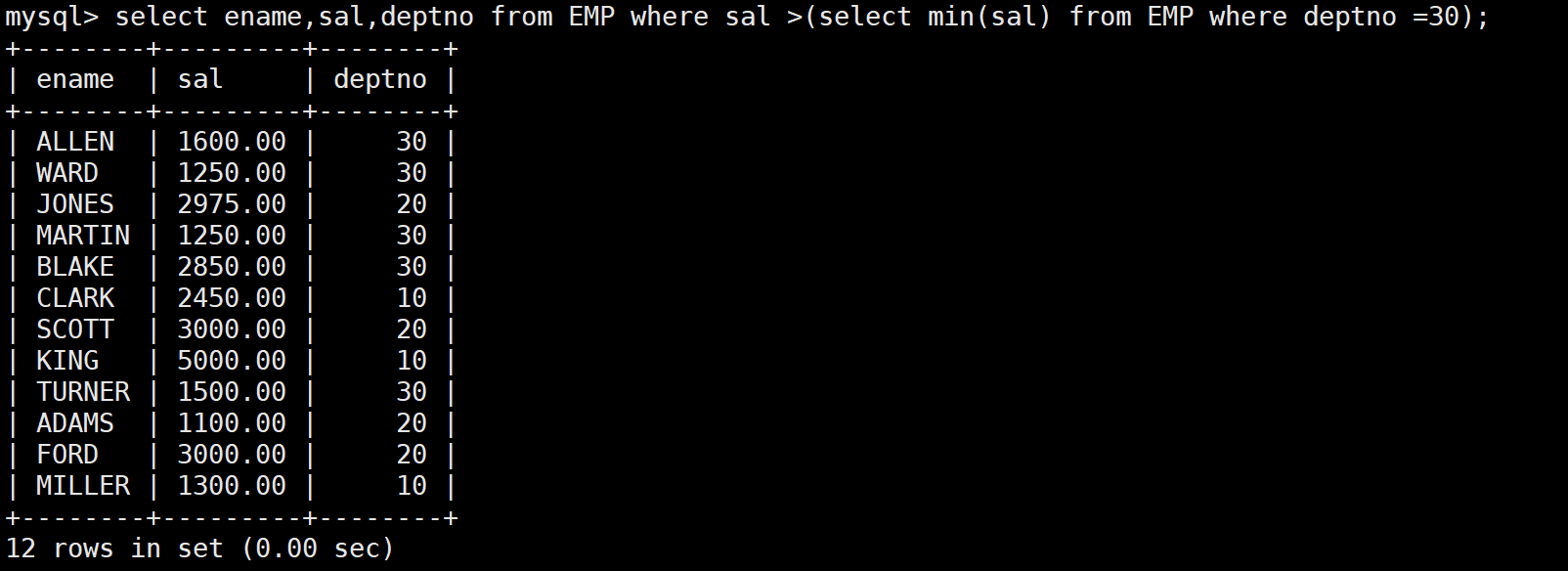
-- 等价于:
SELECT ename, sal, deptno
FROM EMP
WHERE sal > (SELECT MIN(sal) FROM EMP WHERE deptno = 30);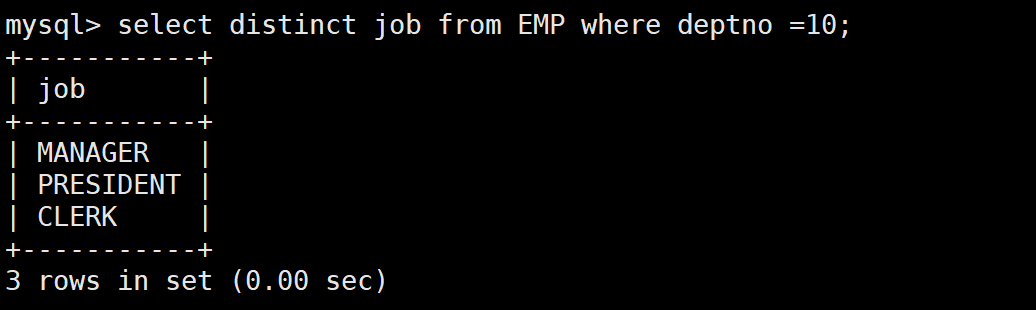
| 关键字 | 含义 | 等价于 |
|---|---|---|
| IN | 等于结果集中的任意一个 | = ANY |
| ALL | 大于结果集中的所有值 | > MAX() |
| ALL | 小于结果集中的所有值 | < MIN() |
| ANY | 大于结果集中的任意一个 | > MIN() |
| ANY | 小于结果集中的任意一个 | < MAX() |
4:多列子查询
- 理解多列子查询的概念
- 掌握多列子查询的语法
sql
-- 多列子查询:子查询返回多个列的数据
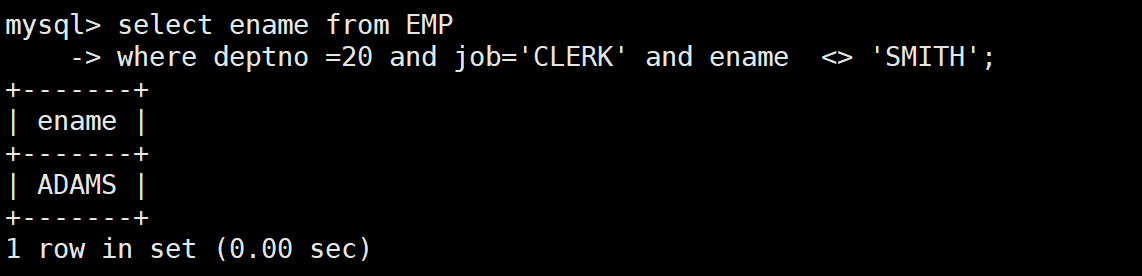
-- 需求:查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
-- 第一步:先查SMITH的部门和岗位
SELECT deptno, job FROM EMP WHERE ename = 'SMITH'; -- 结果:(20, 'CLERK')
-- 第二步:再查部门=20且岗位='CLERK'的员工
SELECT ename FROM EMP
WHERE deptno = 20 AND job = 'CLERK' AND ename <> 'SMITH';
-- 合并成多列子查询(更简洁)
SELECT ename FROM EMP
WHERE (deptno, job) = (SELECT deptno, job FROM EMP WHERE ename = 'SMITH')
AND ename <> 'SMITH';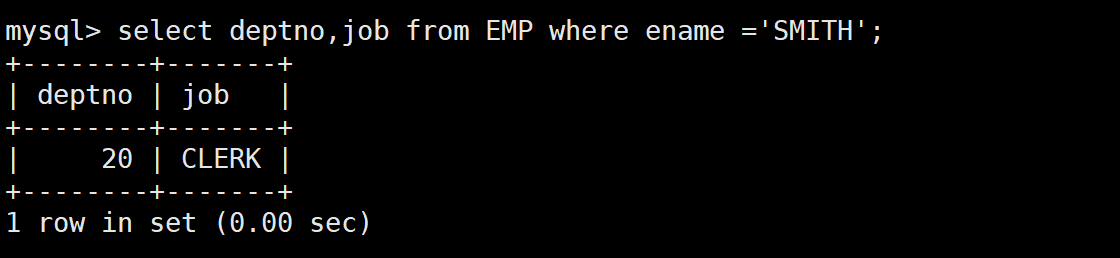

5:在from字句中使用子查询
- 掌握将子查询当作临时表使用的技巧
- 解决需要先统计再查询的复杂问题
sql
-- 在FROM子句中使用子查询:把子查询的结果当作一张临时表
-- 这是非常强大的技巧,能解决很多复杂问题
-- 需求1:显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
-- 分析:
-- 1. 首先需要统计每个部门的平均工资
-- 2. 然后把这个统计结果当作临时表,和员工表关联
-- 3. 最后筛选出工资高于部门平均工资的员工
-- 第一步:统计每个部门的平均工资
SELECT AVG(sal) AS avg_sal, deptno FROM EMP GROUP BY deptno;
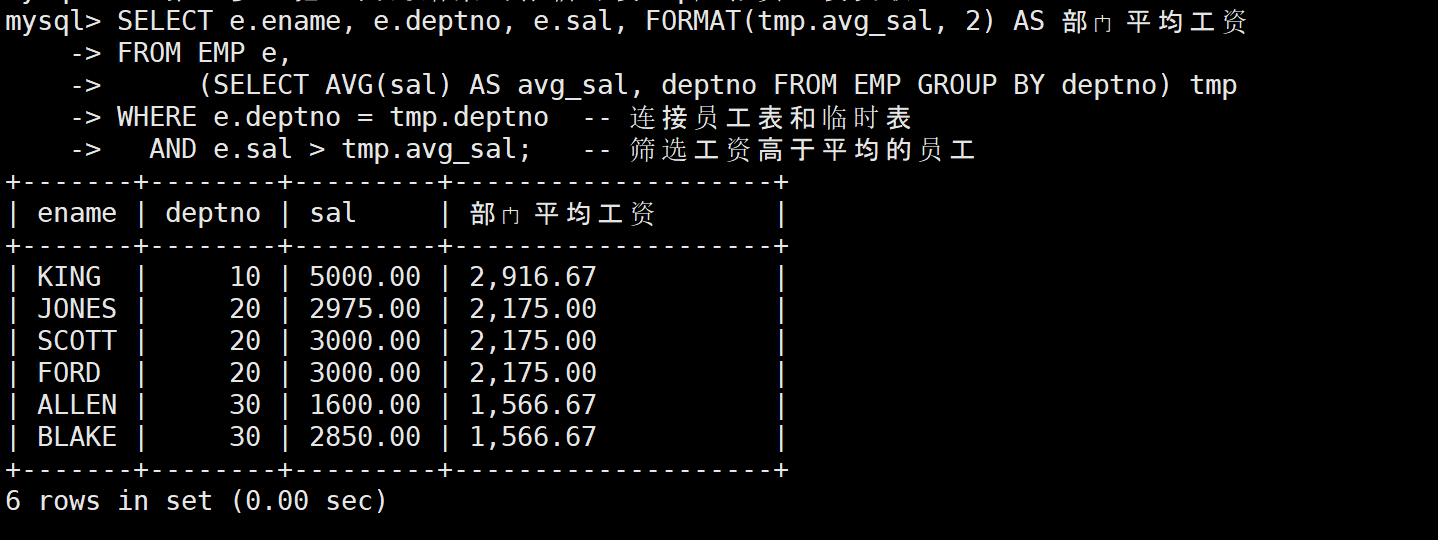
-- 第二步:把上面的结果当作临时表tmp,和员工表关联
SELECT e.ename, e.deptno, e.sal, FORMAT(tmp.avg_sal, 2) AS 部门平均工资
FROM EMP e,
(SELECT AVG(sal) AS avg_sal, deptno FROM EMP GROUP BY deptno) tmp
WHERE e.deptno = tmp.deptno -- 连接员工表和临时表
AND e.sal > tmp.avg_sal; -- 筛选工资高于平均的员工
-- 需求2:查找每个部门工资最高的人的姓名、工资、部门、最高工资
SELECT e.ename, e.sal, e.deptno, tmp.max_sal
FROM EMP e,
(SELECT MAX(sal) AS max_sal, deptno FROM EMP GROUP BY deptno) tmp
WHERE e.deptno = tmp.deptno
AND e.sal = tmp.max_sal;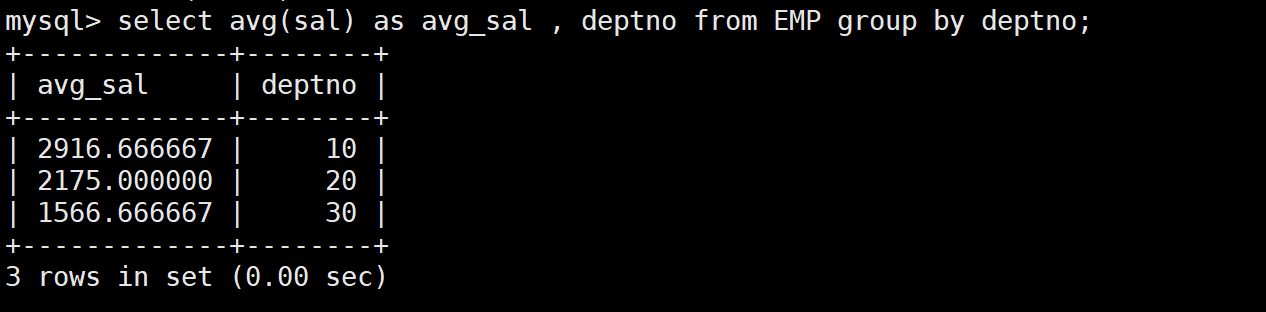
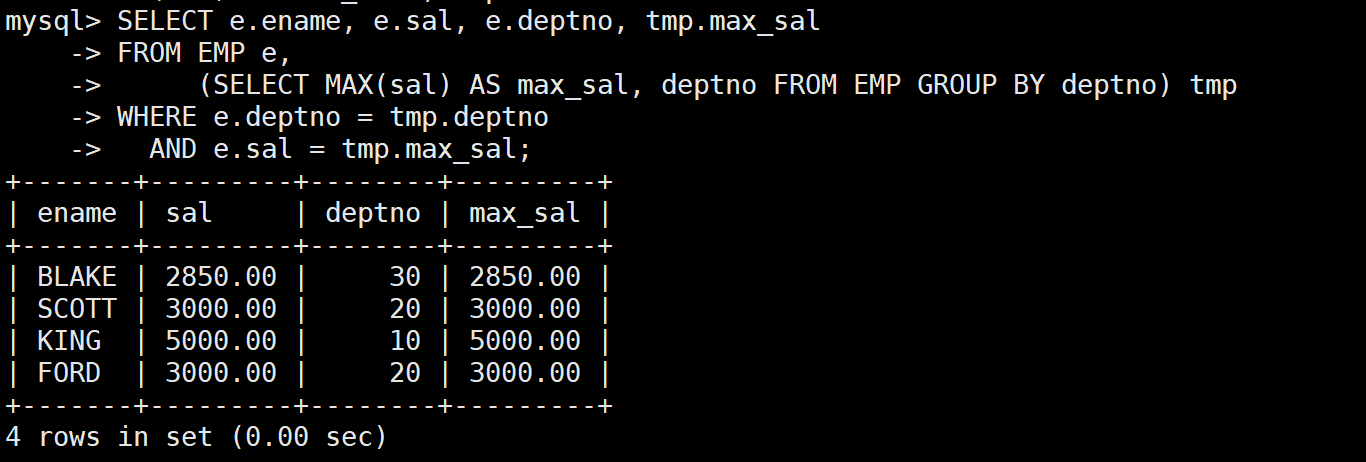
- 子查询必须给一个别名(上面的 tmp)
- 子查询中的字段也要给别名,方便外面引用
- 这种方法可以把复杂问题分解成多个简单步骤
5:合并查询
1:合并查询
合并查询就是把多个 SELECT 语句的结果集合并成一个结果集。
使用场景:
- 当需要从多个表中查询相似结构的数据时
- 当一个复杂查询可以拆分成多个简单查询时
2:UNION和UNION ALL的区别
- 掌握合并查询的语法
- 理解 UNION 和 UNION ALL 的区别
- 知道什么时候用哪个
sql
-- 合并查询的要求:
-- 1. 多个SELECT语句的列数必须相同
-- 2. 对应列的数据类型必须兼容
-- 需求:将工资大于2500或职位是MANAGER的人找出来
-- 方法一:用OR条件(简单情况)
SELECT ename, sal, job FROM EMP WHERE sal > 2500 OR job = 'MANAGER';
-- 方法二:用UNION(自动去重)
-- 先查工资大于2500的员工
SELECT ename, sal, job FROM EMP WHERE sal > 2500
UNION
-- 再查职位是MANAGER的员工
SELECT ename, sal, job FROM EMP WHERE job = 'MANAGER';
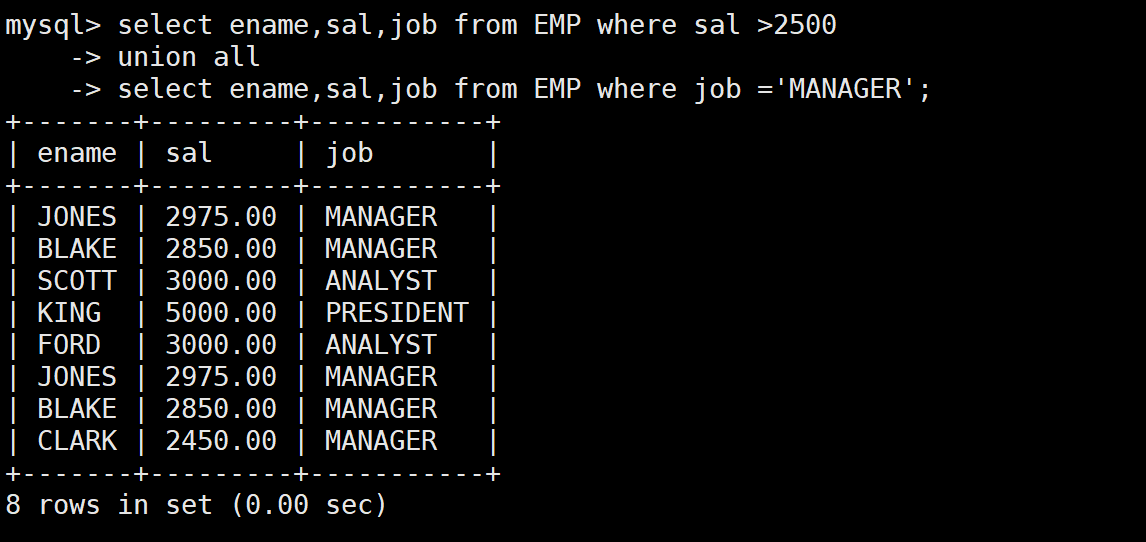
-- 方法三:用UNION ALL(不去重)
SELECT ename, sal, job FROM EMP WHERE sal > 2500
UNION ALL
SELECT ename, sal, job FROM EMP WHERE job = 'MANAGER';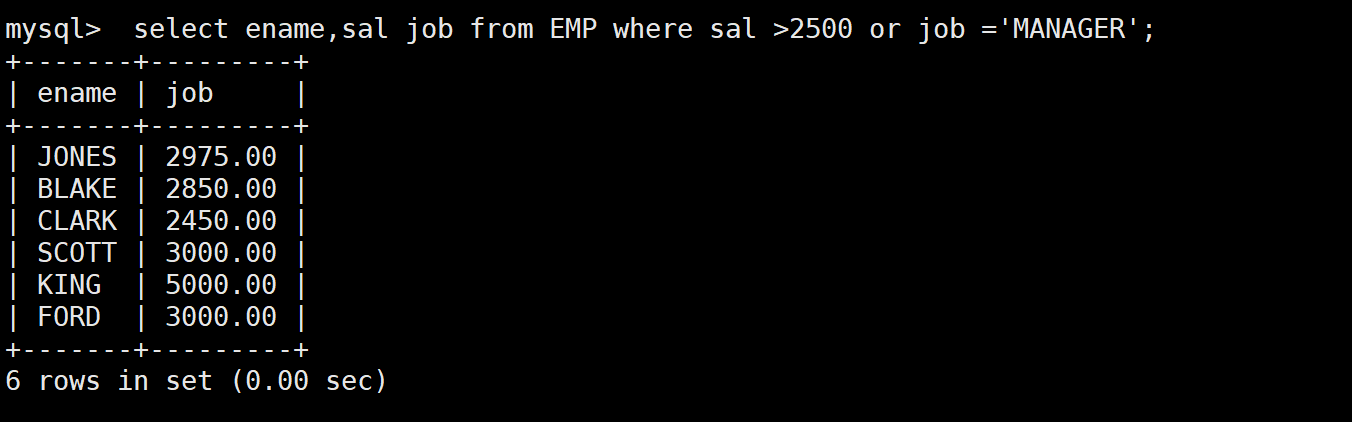
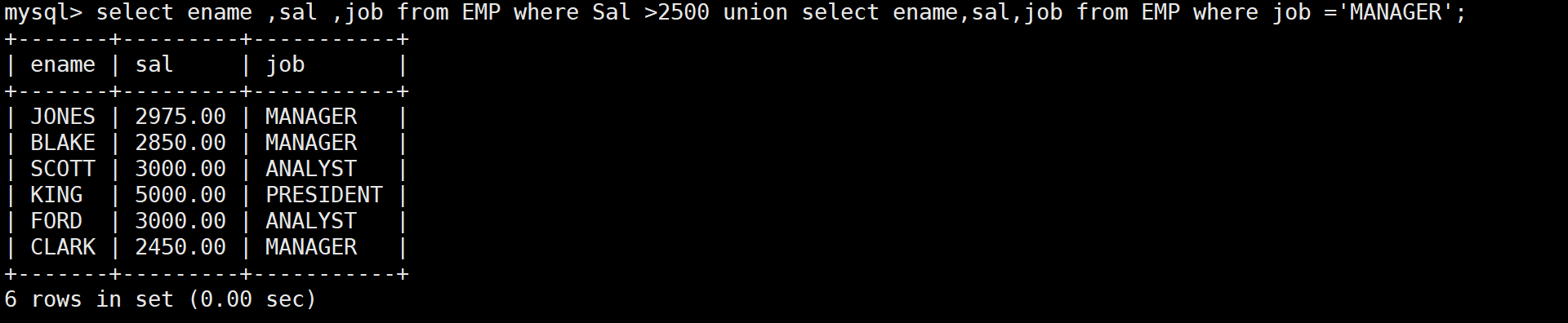
- UNION 结果:6 条记录(JONES 和 BLAKE 既是 MANAGER,工资又大于 2500,只出现一次)
- UNION ALL 结果:8 条记录(JONES 和 BLAKE 出现了两次)
- UNION :自动去掉结果集中的重复行,会对结果进行排序,性能较差
- UNION ALL :不去掉重复行,直接合并,性能好很多
- 最佳实践:如果确定两个结果集没有重复数据,优先使用 UNION ALL
6:内外连接详解(标准 JOIN 语法)
我们之前学的多表查询是传统写法(用逗号分隔表,WHERE 写连接条件),这其实是内连接的一种写法。
SQL 标准提供了更清晰、更强大的 JOIN 语法:
INNER JOIN:内连接(和传统写法等价)LEFT JOIN:左外连接RIGHT JOIN:右外连接
标准 JOIN 语法的优点:
- 连接条件和筛选条件分离,可读性更好
- 支持外连接(传统写法不支持)
- 是 SQL 标准,兼容性更好
1:内连接(INNER JOIN)
sql
-- 标准内连接语法:
-- SELECT 字段 FROM 表1 INNER JOIN 表2 ON 连接条件 WHERE 筛选条件;
-- 需求:显示SMITH的名字和部门名称
-- 传统写法
SELECT e.ename, d.dname
FROM EMP e, DEPT d
WHERE e.deptno = d.deptno AND e.ename = 'SMITH';
-- 标准内连接写法(推荐)
SELECT e.ename, d.dname
FROM EMP e
INNER JOIN DEPT d ON e.deptno = d.deptno -- 连接条件写在ON后面
WHERE e.ename = 'SMITH'; -- 筛选条件写在WHERE后面
-- 关联三张表的标准写法
SELECT e.ename, e.sal, d.dname, s.grade
FROM EMP e
INNER JOIN DEPT d ON e.deptno = d.deptno
INNER JOIN SALGRADE s ON e.sal BETWEEN s.losal AND s.hisal;


- 传统写法:连接条件和筛选条件都写在 WHERE 后面,容易混淆
- 标准写法:连接条件写在 ON 后面,筛选条件写在 WHERE 后面,逻辑更清晰
2:左外连接
左外连接:左边的表完全显示,右边的表只显示匹配的记录,匹配不到显示 NULL
sql
-- 先创建两张简单的测试表,方便理解
CREATE TABLE stu (id INT, name VARCHAR(30)); -- 学生表
INSERT INTO stu VALUES(1, 'jack'), (2, 'tom'), (3, 'kity'), (4, 'nono');
CREATE TABLE exam (id INT, grade INT); -- 成绩表
INSERT INTO exam VALUES(1, 56), (2, 76), (11, 8);
-- 先看一下内连接的结果
SELECT * FROM stu
INNER JOIN exam ON stu.id = exam.id;
-- 结果:只有jack和tom有成绩,kity和nono没有成绩,所以不显示
-- 左外连接:左边的stu表完全显示
SELECT * FROM stu
LEFT JOIN exam ON stu.id = exam.id;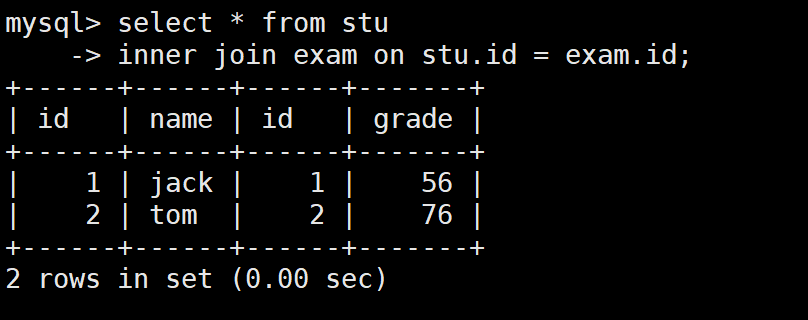
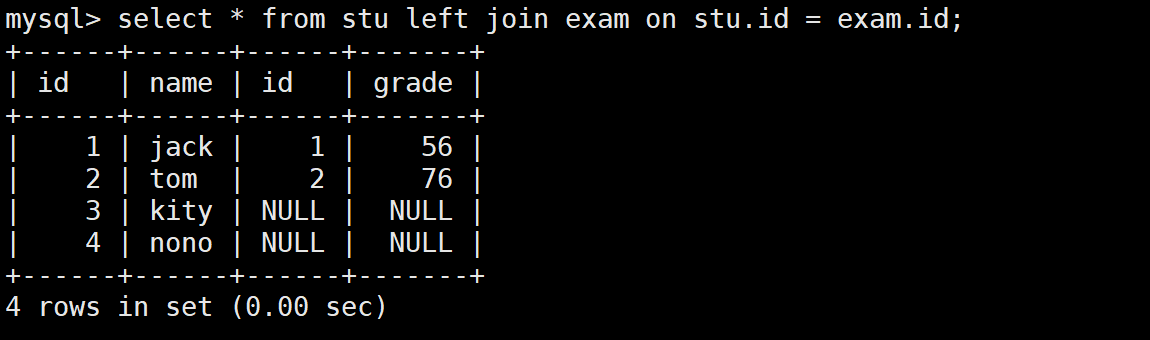
- 内连接只返回两张表都匹配的记录
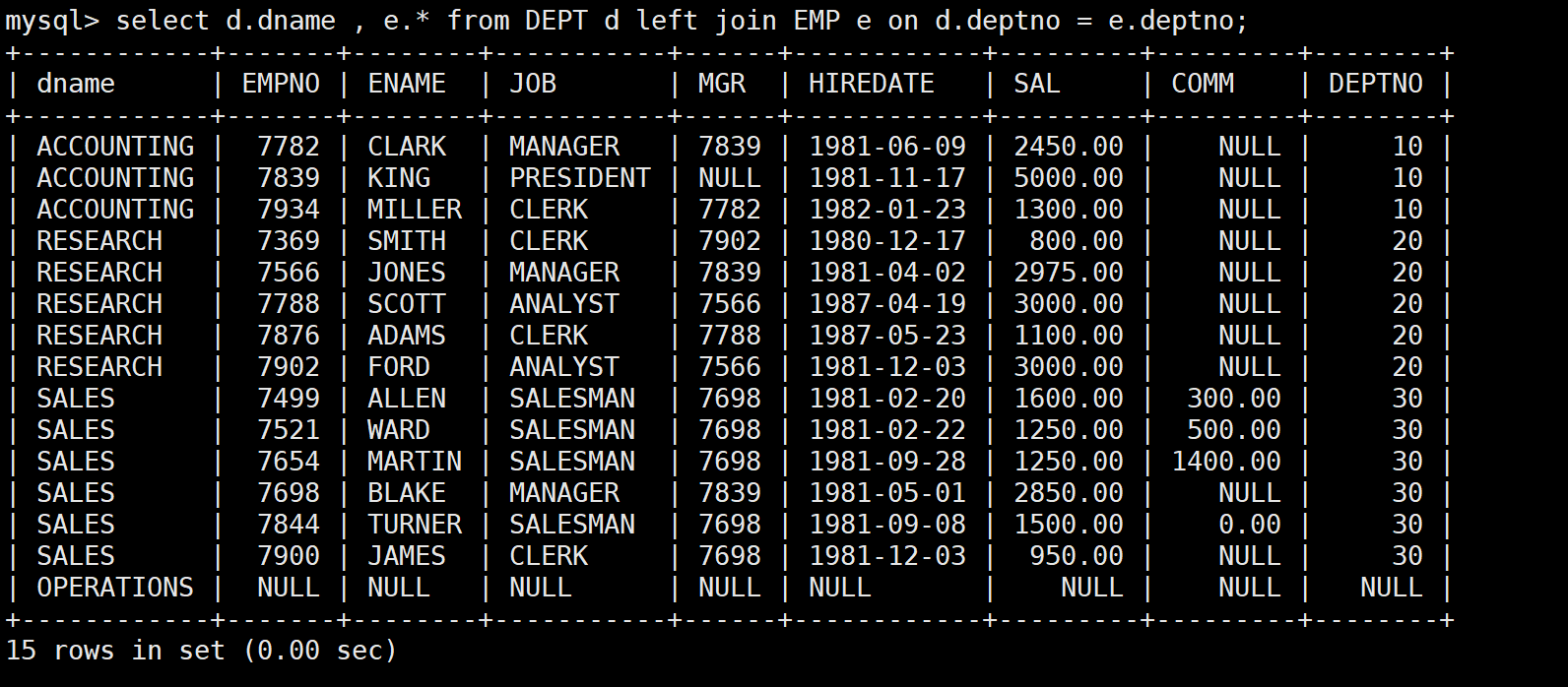
- 左外连接返回左表的所有记录,即使右表没有匹配
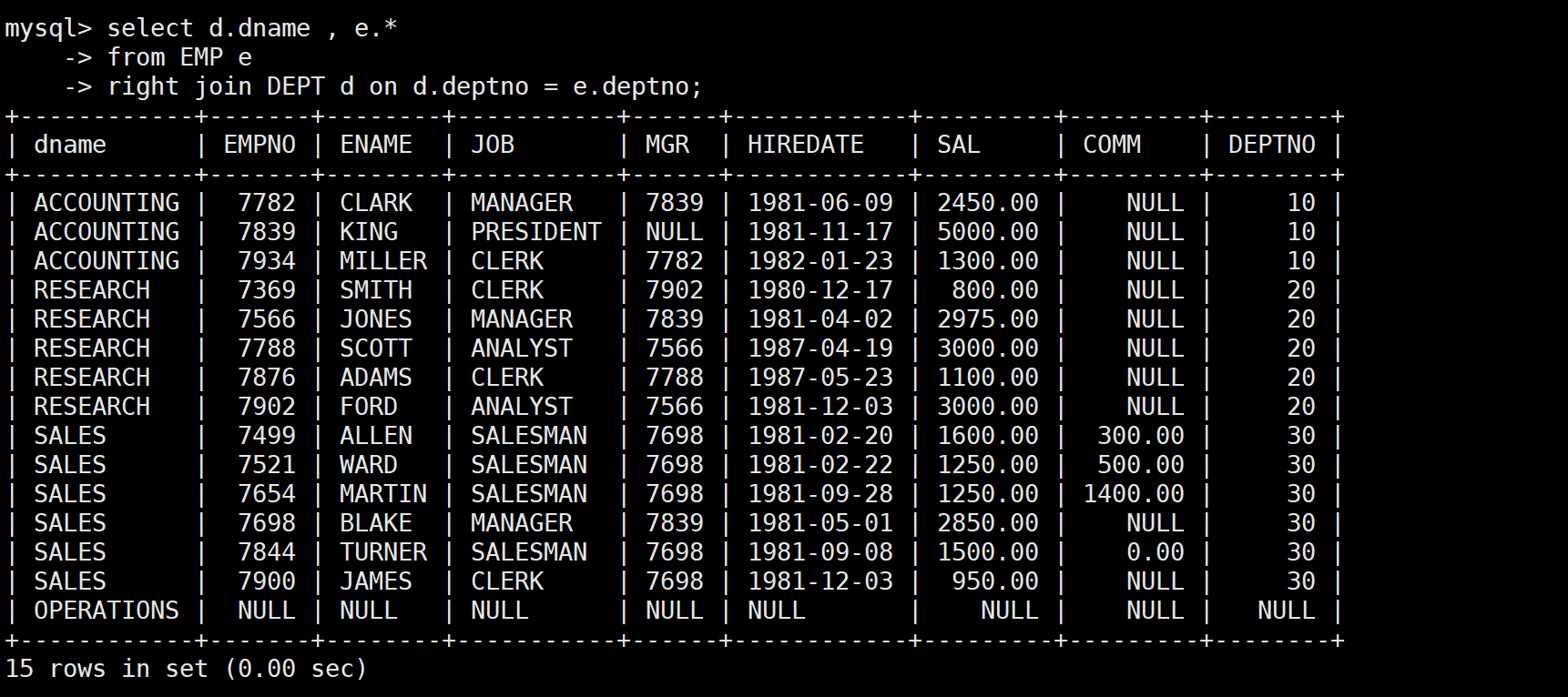
3:左外连接和右外连接的转换
sql
-- 左外连接
SELECT d.dname, e.*
FROM DEPT d
LEFT JOIN EMP e ON d.deptno = e.deptno;
-- 等价的右外连接(交换表的位置)
SELECT d.dname, e.*
FROM EMP e
RIGHT JOIN DEPT d ON d.deptno = e.deptno;