****论文题目:****A novel multi-scale dense residual shrinkage GAN for data-limited rotating machinery fault diagnosis(基于多尺度密集残余收缩GAN的旋转机械故障诊断)
****期刊:****Mechanical Systems and Signal Processing(机械系统与信号处理)
****摘要:****旋转机械的故障诊断对工业安全至关重要,但实际应用面临着巨大的挑战,包括数据采集成本高、故障样本稀缺以及严重的类别不平衡,这些都严重限制了深度学习诊断模型的性能。针对有限数据条件下的故障诊断问题,提出了一种多尺度密集剩余收缩生成对抗网络(MDRSGAN)。该方法创新性地引入了一种多尺度发生器,利用多个子发生器协同工作,采用多头注意机制实现多尺度特征的动态融合,显著增强了样本分布仿真能力。同时,构建了一种基于密集块深度残余收缩网络的混合时频鉴别器,该鉴别器集成了密集连接、改进的高效信道注意机制和软阈值去噪技术,以提高对时域和频域关键特征的灵敏度。实现了样品真实性识别和故障分类的双重功能。此外,引入贝叶斯优化策略自适应调整鉴别器超参数,提高了模型训练的稳定性和效率。在CWRU和XJTU-SY轴承数据集上的大量实验表明:生成的样本与真实样本的特征分布相似度超过0.8(最大0.91);在极端小样本条件下(每类只有2个样本),故障诊断准确率分别达到94.32%和95.83%;在严重的类不平衡(100:1)下,准确率维持在96.46%和96.06%。与现有方法相比,MDRS-GAN在所有评估指标上都显示出显著的优势,为工业场景下数据有限的旋转机械故障诊断提供了有效的解决方案。
代码指南可以通过以下地址查看:
MDRS-GAN:面向有限数据的旋转机械故障诊断新方法
一、背景与问题:为什么旋转机械故障诊断这么难?
旋转机械广泛应用于现代工业传动系统,而滚动轴承是其中最关键的零部件之一。统计数据表明,约 40% 的旋转机械故障源于轴承失效,一旦发生事故,将导致严重的安全风险和经济损失。
近年来,深度学习技术(CNN、LSTM、RNN 等)已被广泛用于旋转机械故障诊断,并显著提升了诊断精度。然而,这些方法在实际工程中面临三大核心挑战:
- 数据获取成本极高:故障振动信号的采集环境复杂、成本高昂;
- 故障样本极度稀缺:小样本场景下,模型无法充分学习故障特征,诊断可靠性大幅下降;
- 严重的类别不平衡:正常状态样本数量远超故障样本(不平衡比例可高达 100:1),导致模型在训练时偏向多数类,对少数类(故障类)的识别能力薄弱,误诊和漏诊风险显著上升。
为此,研究者探索了迁移学习、元学习和数据增强三类解决思路。其中,生成对抗网络(GAN)凭借其强大的数据分布捕获能力,成为旋转机械故障诊断数据增强的重要方向。
然而,现有 GAN 方法仍存在明显局限:
- 传统单一生成器难以精确模拟复杂故障信号的分布;
- 判别器通常仅依赖时域或频域信息,对全局结构和细微特征的感知不足;
- 随着网络加深,判别器容易出现梯度消失,学习能力受限;
- 训练过程中的梯度消失和模式崩溃问题影响模型的稳定性与鲁棒性。
二、MDRS-GAN 方法总览
针对上述挑战,本文提出了 MDRS-GAN(多尺度密集残差收缩生成对抗网络),其整体框架分为三个阶段:
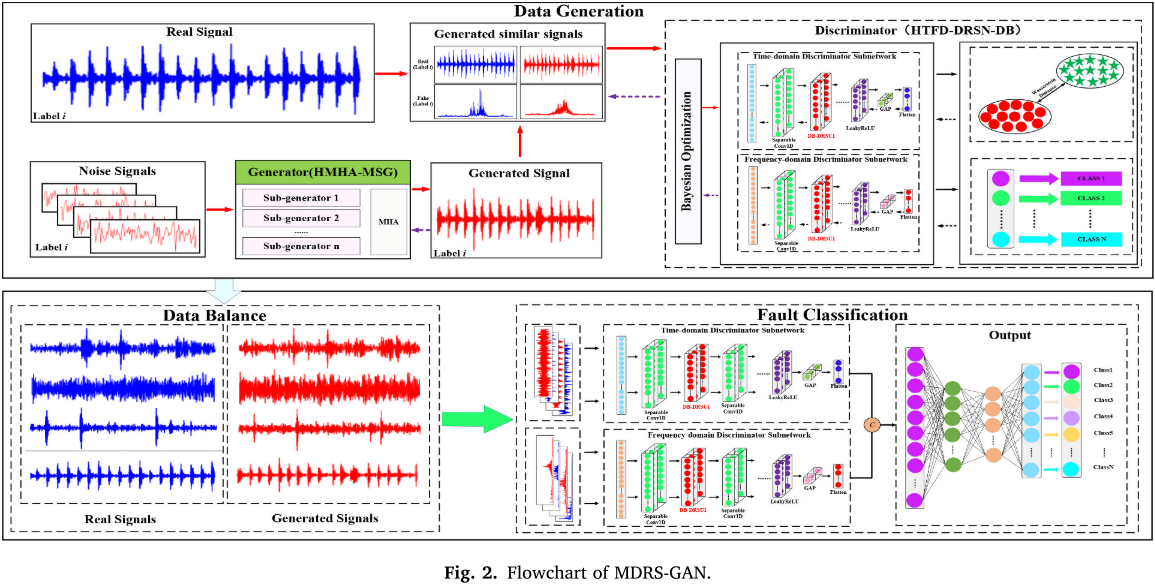
📌 【配图:Fig. 2 MDRS-GAN 整体流程图】
- 数据生成(Data Generation):利用 HMHA-MSG 生成器从少量真实样本中生成高质量的多尺度故障信号;
- 数据平衡(Data Balance):为各少数类别补充生成样本,解决类别不平衡问题;
- 故障分类(Fault Classification):利用训练好的 DB-DRSN-HTFD 判别器直接用于故障诊断。
整个方法在 ACGAN 框架基础上进行了全面创新,下面逐一介绍各核心模块。
三、核心创新一:层次多头注意力多尺度生成器(HMHA-MSG)
3.1 设计动机
传统 GAN 的单一生成器在面对复杂振动信号分布时,往往力不从心------它难以同时捕获信号的多个尺度特征,导致生成样本的多样性和真实性不足。
3.2 结构设计
HMHA-MSG 由 n 个结构相同的子生成器 并行组成(实验中设为 5 个),每个子生成器接收相同的噪声向量 和类别标签 c,独立生成输出信号
。
每个子生成器内部包含多个 AAUG 单元(自适应激活上采样单元),由以下层堆叠而成:
- 1D 反卷积层:实现信号的上采样;
- BN 层:稳定训练,防止梯度爆炸/消失;
- PReLU 激活函数:引入可学习参数,相比 ReLU 更灵活,避免"神经元死亡"问题;
- Dropout 层:防止过拟合。
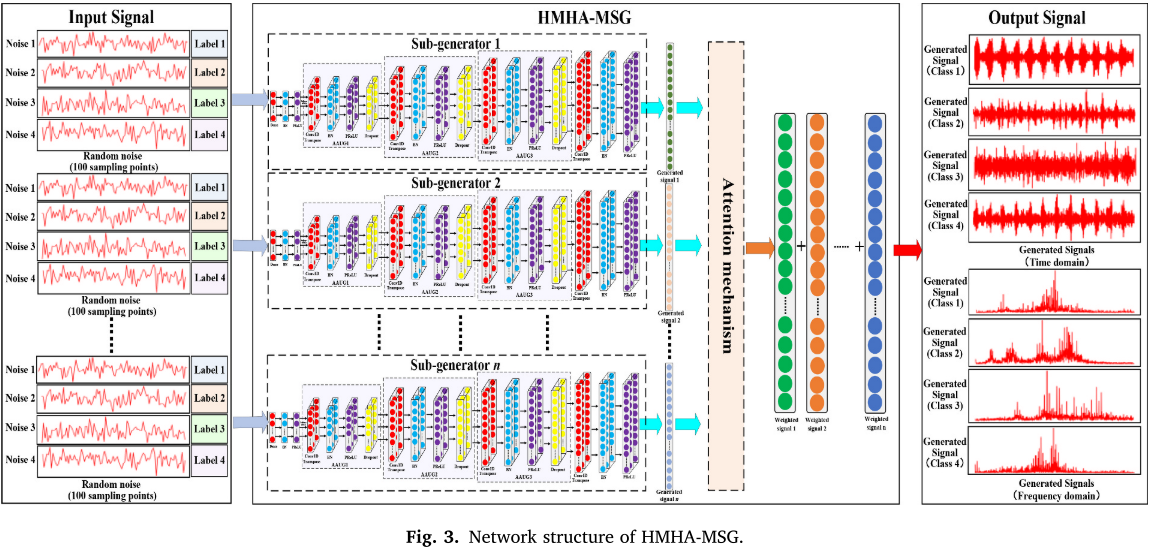
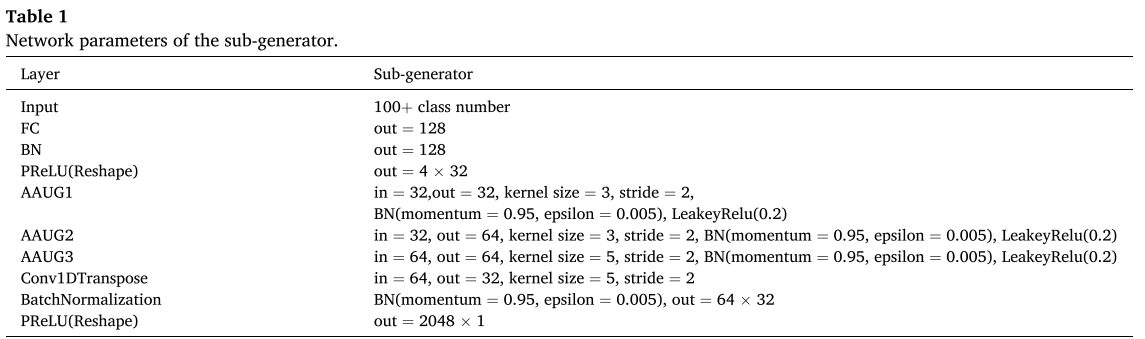
📌 【配图:Fig. 3 HMHA-MSG 网络结构图】 📌 【配表:Table 1 子生成器网络参数】
3.3 多头注意力融合机制
各子生成器生成 后,通过多头注意力机制进行动态融合:
- 将
投影为 Query(
- 各头的注意力输出累加,得到最终注意力权重
- 对每个子生成器的输出进行逐元素加权:
- 将所有加权信号累加得到最终输出:
这一机制使得模型能够动态聚焦于不同子生成器生成的关键特征区域,显著提升了样本分布的模拟能力。
四、核心创新二:混合时频判别器(DB-DRSN-HTFD)
4.1 设计动机
单一时域或频域分析无法全面反映振动信号的特征,而频率信息对轴承故障诊断尤为重要。同时,传统判别器在深层网络中容易出现梯度消失,影响学习能力。
4.2 DB-DRSU 核心模块
DB-DRSU 是判别器的基础计算单元,其创新在于将 DenseNet 的密集连接引入深度残差收缩单元(DRSU)。
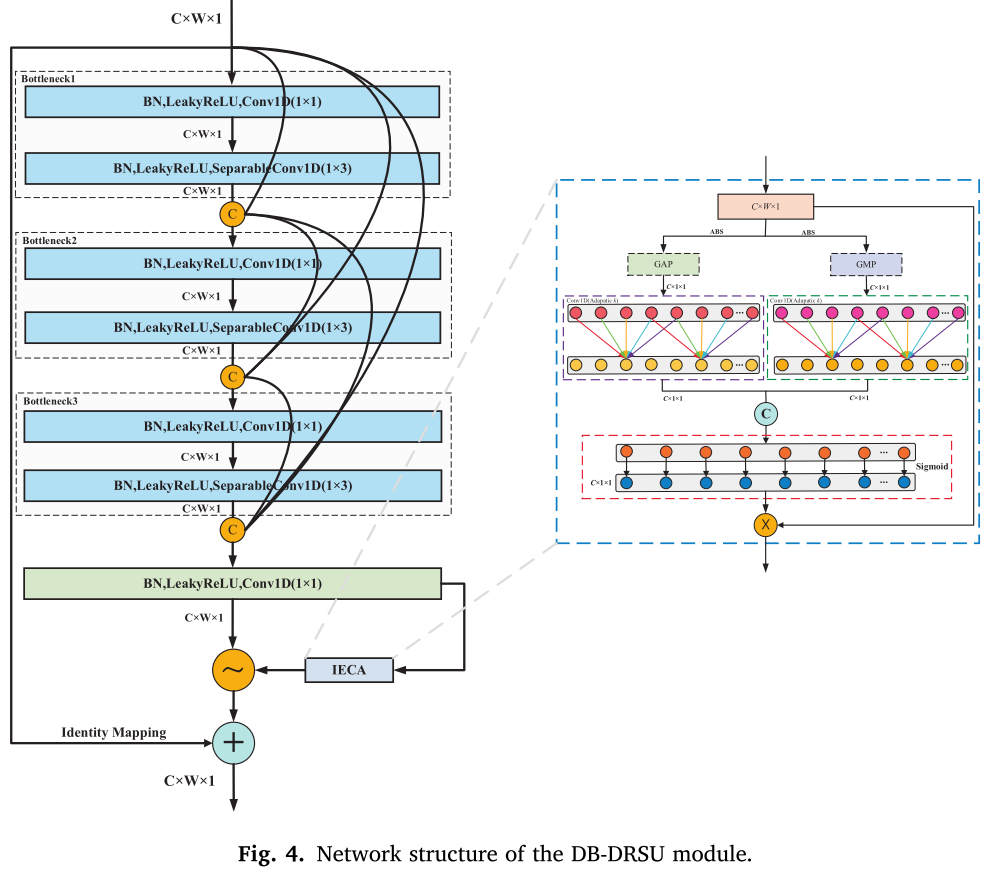
📌 【配图:Fig. 4 DB-DRSU 模块网络结构图】
其结构如下:
- 三个 Bottleneck 结构通过 Concat 密集连接,每个 Bottleneck 的输入包含所有前驱层的输出,实现浅层与深层特征的充分融合,增强多尺度特征捕获能力;
- 每个 Bottleneck 包含两个卷积单元:1×1 Conv1D (降低参数量)+ 1×3 SeparableConv1D(提取局部时序特征);
- 采用 LeakyReLU 替代 ReLU,解决"神经元死亡"问题;
- 三个 Bottleneck 拼接后,经过卷积单元与注意力机制,生成自适应阈值向量
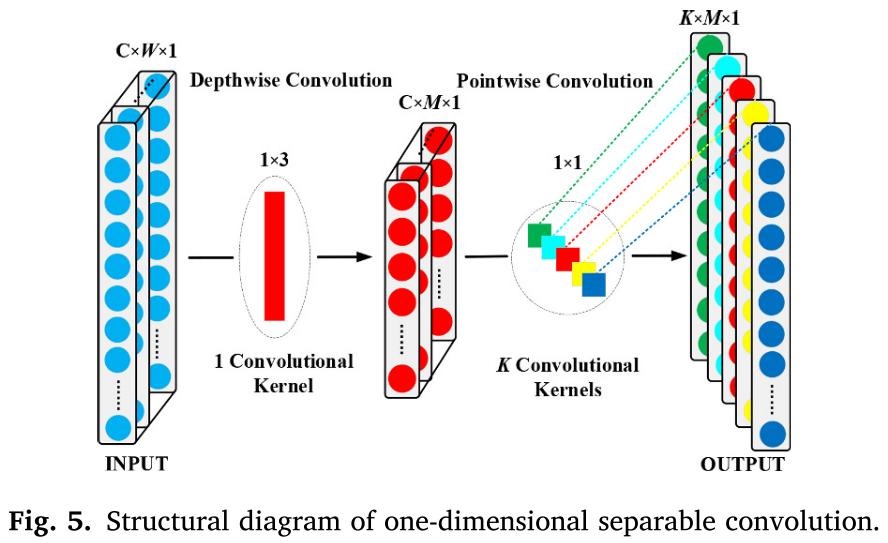
📌 【配图:Fig. 5 一维可分离卷积结构图】
4.3 改进的高效通道注意力机制(IECA)
传统 SENet 的"压缩-激励"结构存在两个关键缺陷:
- 全连接降维(
- 中间维度瓶颈导致不可逆的通道信息损失。
本文提出 IECA ,以 ECA-Net 的一维卷积替代全连接层,同时引入全局最大池化(GMP)与全局平均池化(GAP)双路径 并行处理,两路结果相加后经 Sigmoid 激活生成阈值向量 。卷积核大小 K 由通道数 C 自适应决定:
其中 ,b=3。该设计在不引入参数冗余的前提下,有效保留了关键通道信息。
4.4 混合时频判别器整体结构
DB-DRSN-HTFD 包含两个结构完全相同的并行子网络:
- 时域判别子网络(TDS):接收原始时域信号(长度 2048);
- 频域判别子网络(FDS):接收经 FFT 变换后的频域信号(长度 1024)。
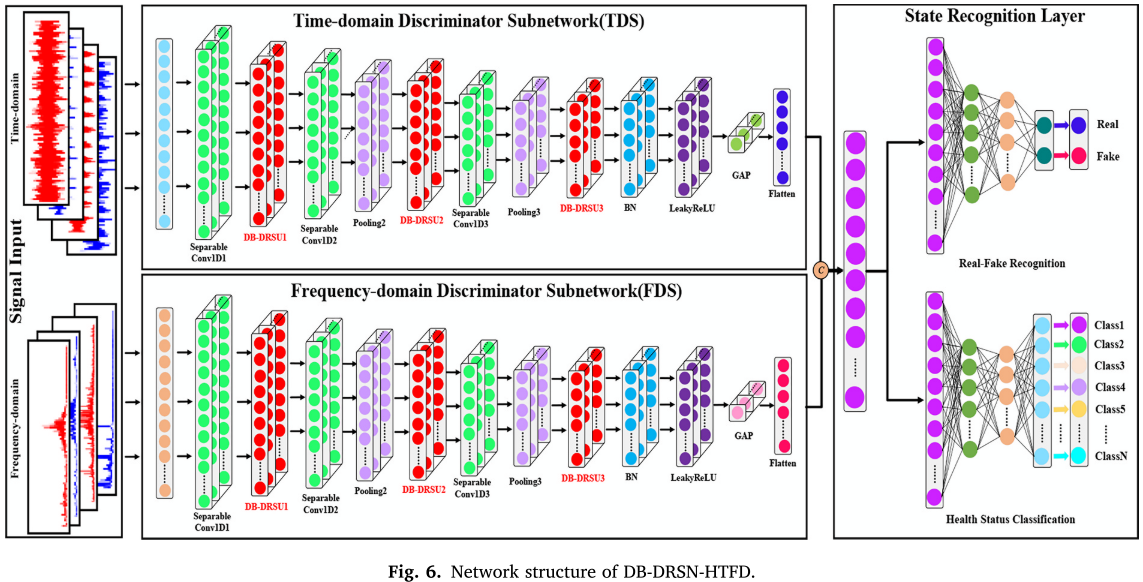
📌 【配图:Fig. 6 DB-DRSN-HTFD 网络结构图】
每个子网络均包含:1D 可分离卷积层 → 3 个 DB-DRSU 模块(由 2 个过渡层间隔)→ BN → LeakyReLU → GAP。两个子网络的特征在拼接后经全连接层输出:
- D_S(真假判别分数):通过 Sigmoid 输出;
- D_C(故障类别概率):通过 Softmax 输出。
4.5 损失函数设计
为解决 ACGAN 训练中的模式崩溃问题,本文采用 Wasserstein 距离 + 梯度惩罚(GP-WD):
梯度惩罚系数 ,确保判别器梯度范数接近 1,维持 Lipschitz 连续性。
判别器的优化目标:
生成器的优化目标:
五、核心创新三:贝叶斯超参数优化
在判别器预训练阶段,本文引入贝叶斯优化替代传统的网格搜索或随机搜索。贝叶斯优化使用概率代理模型智能引导超参数搜索,具有以下优势:
- 更稳定的参数更新,减少训练震荡;
- 高效探索超参数空间,快速定位最优组合;
- 将超参数搜索时间从 1689 秒 压缩至 983 秒(减少约 41.8%),同时提升识别效果。
六、MDRS-GAN 训练流程
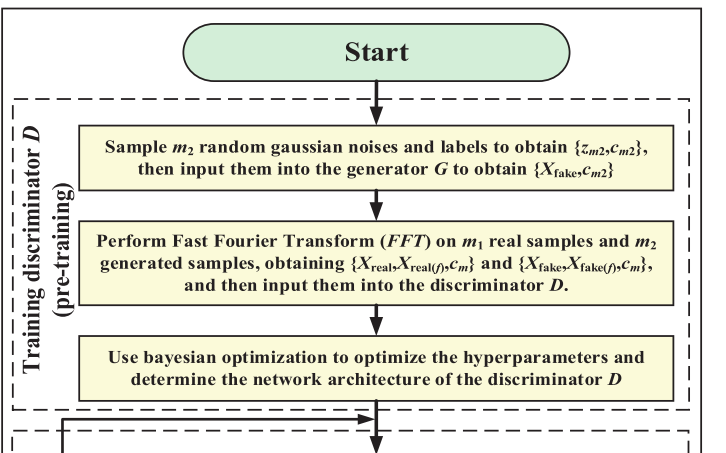
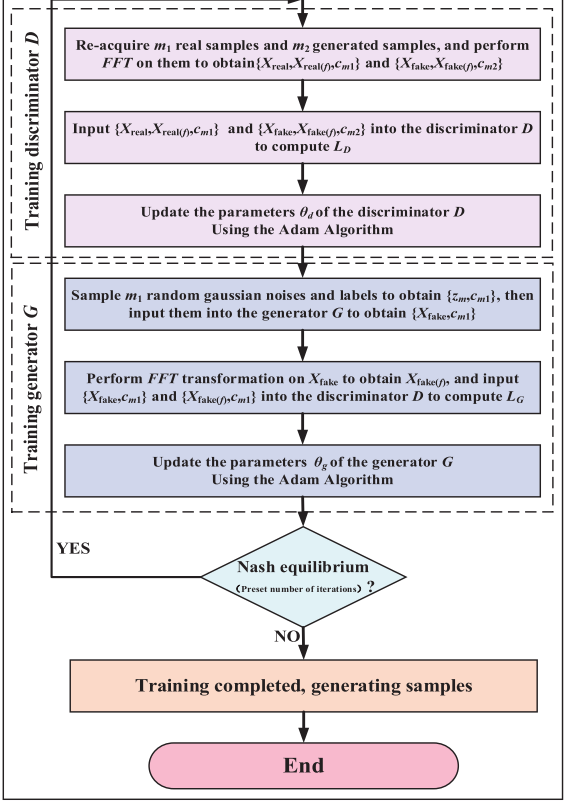
📌 【配图:Fig. 7 有限数据下的样本生成流程图】
整体训练分为三步:
Step 1 · 数据采集与预处理:对原始振动信号进行 one-hot 编码,划分训练集和测试集。
Step 2 · 有限数据样本生成:
- 固定生成器参数,通过贝叶斯优化预训练判别器;
- 确定判别器结构后,以 Adam 优化器交替更新生成器和判别器,直至达到 Nash 均衡或完成预设训练轮次(5000 epochs);
- 每批次生成
Step 3 · 基于判别器的故障诊断:训练完成后,直接以判别器作为故障诊断模型,输入时域信号和频域信号,输出健康状态分类。
七、实验验证
7.1 实验设置
所有模型基于 TensorFlow + Python 3.9 实现,硬件平台为 Intel Core i7-11800H + 32GB RAM + NVIDIA GeForce RTX 3060 GPU。
评估指标涵盖:准确率(Accuracy)、F1-Score、MCC(马修斯相关系数)、FAR(虚警率)。
对比方法包括:
- 分类方法:PCA-IPSO-SVM、Stacking 集成学习、1DCNN-GRU;
- 生成方法:SAE-GAN、MACGAN、E-DCGAN、DRHRML(元学习)、DWPCN(原型对比学习)。
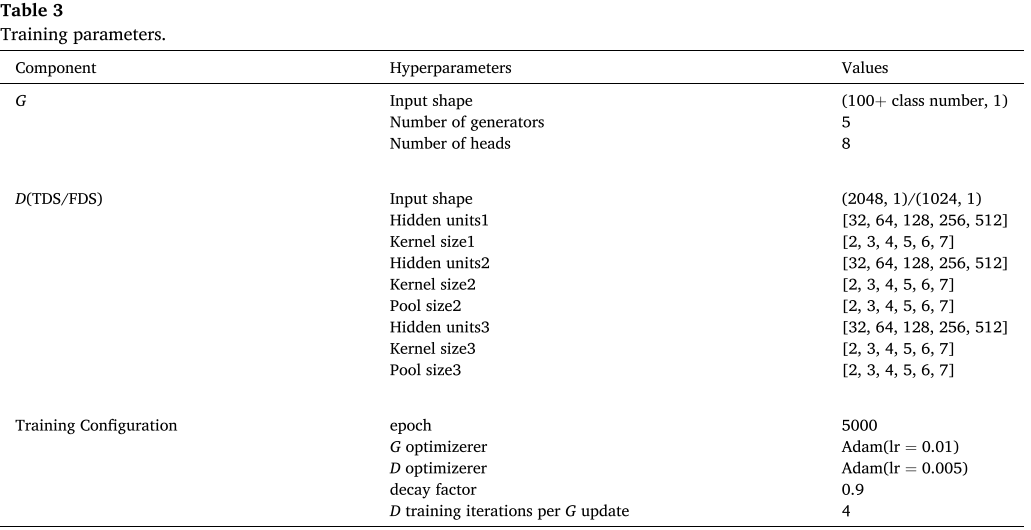
📌 【配表:Table 3 训练参数配置】
7.2 案例一:CWRU 轴承数据集
CWRU 数据集由凯斯西储大学提供,采样频率 12 kHz,转速 1750 rpm,包含 10 种健康状态(1 种正常 + 3 类故障 × 3 种故障尺寸),每类 1000 个样本,样本长度 2048。
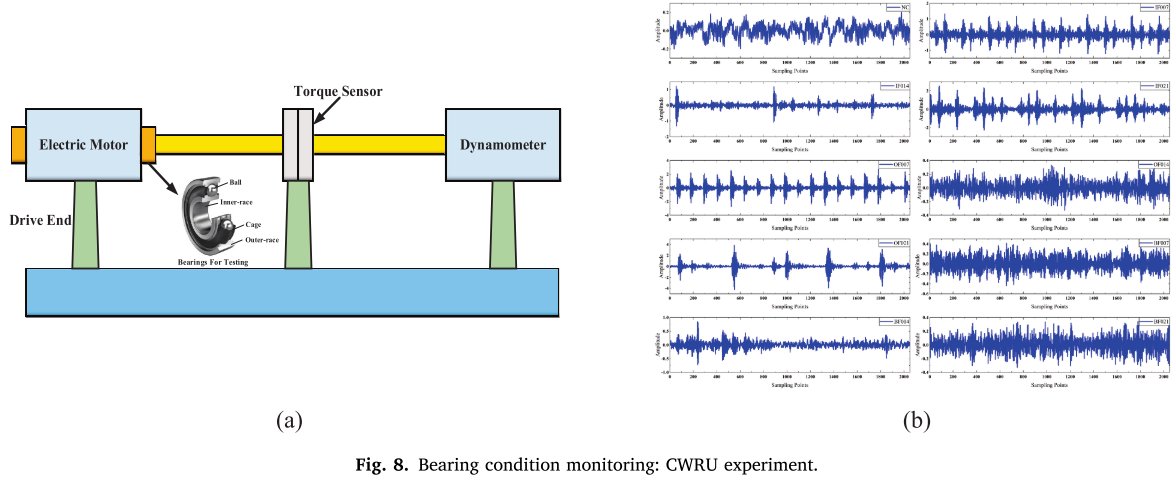
📌 【配图:Fig. 8 CWRU 实验台示意图与各健康状态时域波形】 📌 【配表:Table 4 CWRU 数据集详细描述】
(1)样本生成效果评估
使用每类 50 个真实样本训练 MDRS-GAN,训练约 300 个 epoch 后达到 Nash 均衡。
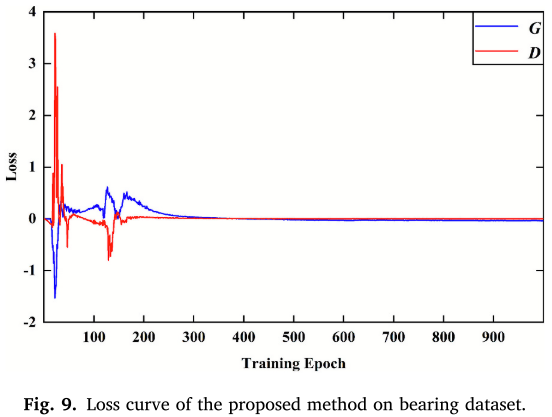
📌 【配图:Fig. 9 生成器与判别器损失曲线】
图 10 对比了四种健康状态(NC、IF007、OF007、BF007)下真实样本与生成样本的时频特性和概率分布,二者在宏观特征分布上高度一致。
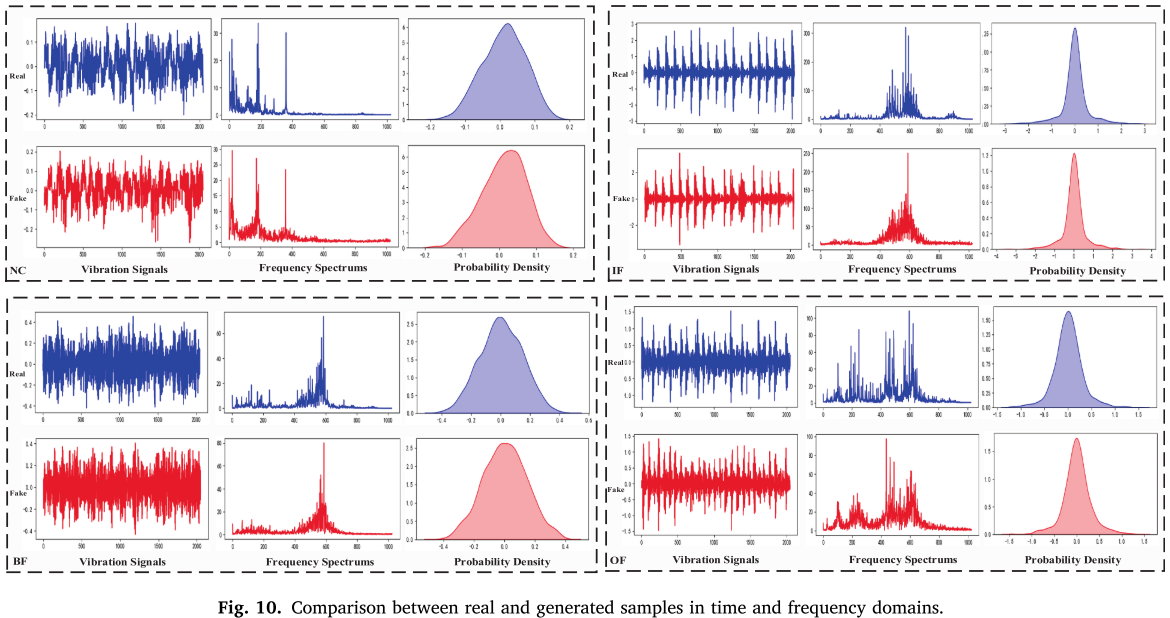
📌 【配图:Fig. 10 真实样本与生成样本时频对比图】
余弦相似度比较(图 11)显示,MDRS-GAN 在 所有健康状态下相似度均超过 0.8,最高达 0.91(IF021),显著优于 SAE-GAN(全部低于 0.8)、MACGAN 和 E-DCGAN。
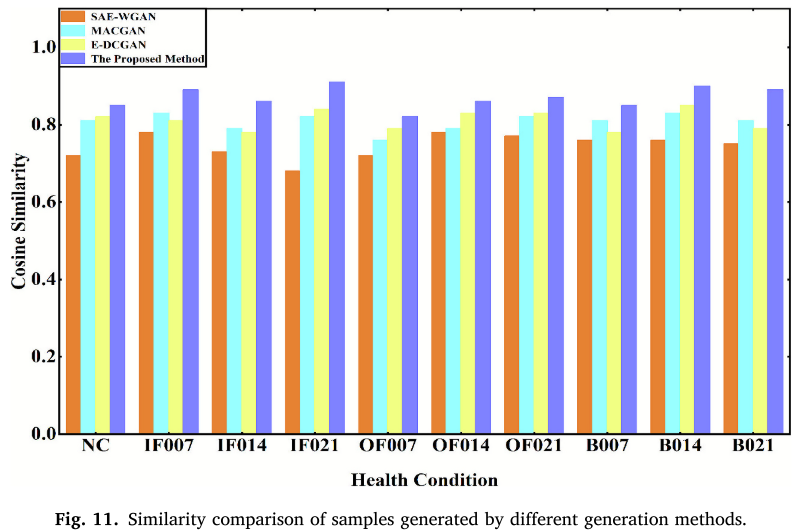
📌 【配图:Fig. 11 不同生成方法的样本相似度对比】
t-SNE 可视化(图 12)进一步验证,MDRS-GAN 生成的样本具有更优的类间可分性和类内聚集性,SAE-GAN 则存在明显的多类特征重叠。
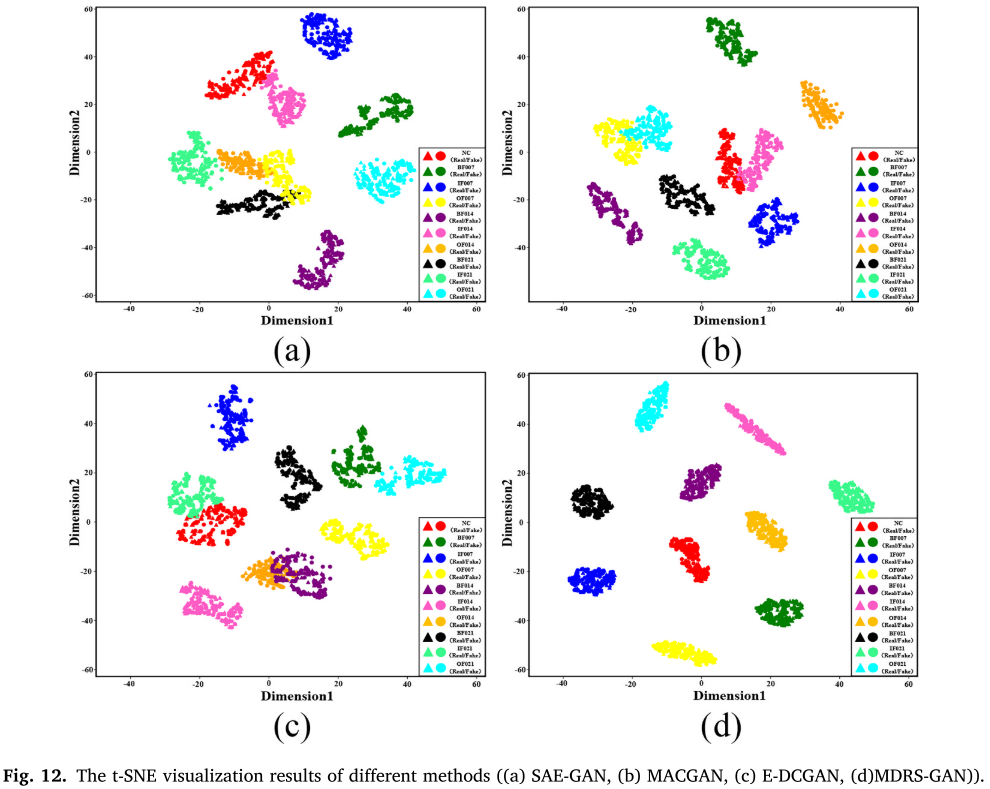
📌 【配图:Fig. 12 不同方法的 t-SNE 可视化结果(a)SAE-GAN (b) MACGAN (c) E-DCGAN (d) MDRS-GAN】
(2)小样本故障诊断
从每类提取 2、4、6、10、20、40 个真实样本,生成补充样本构建 400 个样本的训练集,600 个样本的测试集。
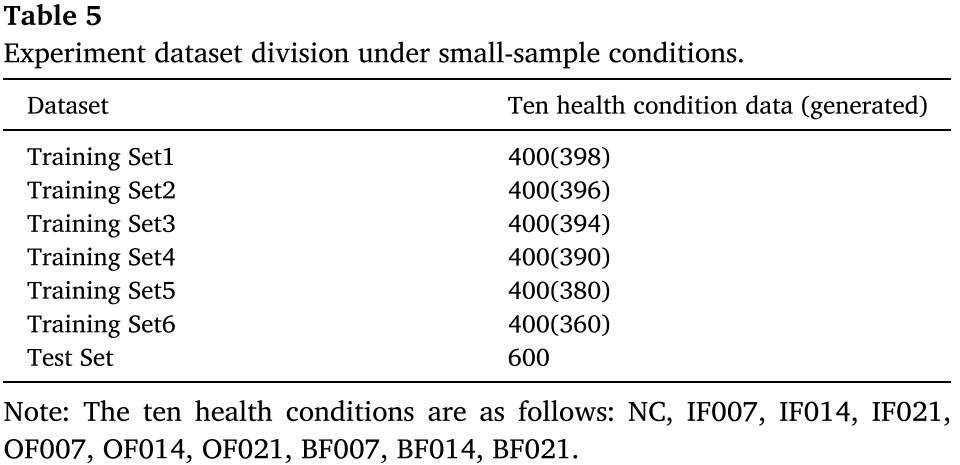
📌 【配表:Table 5 小样本实验数据集划分】
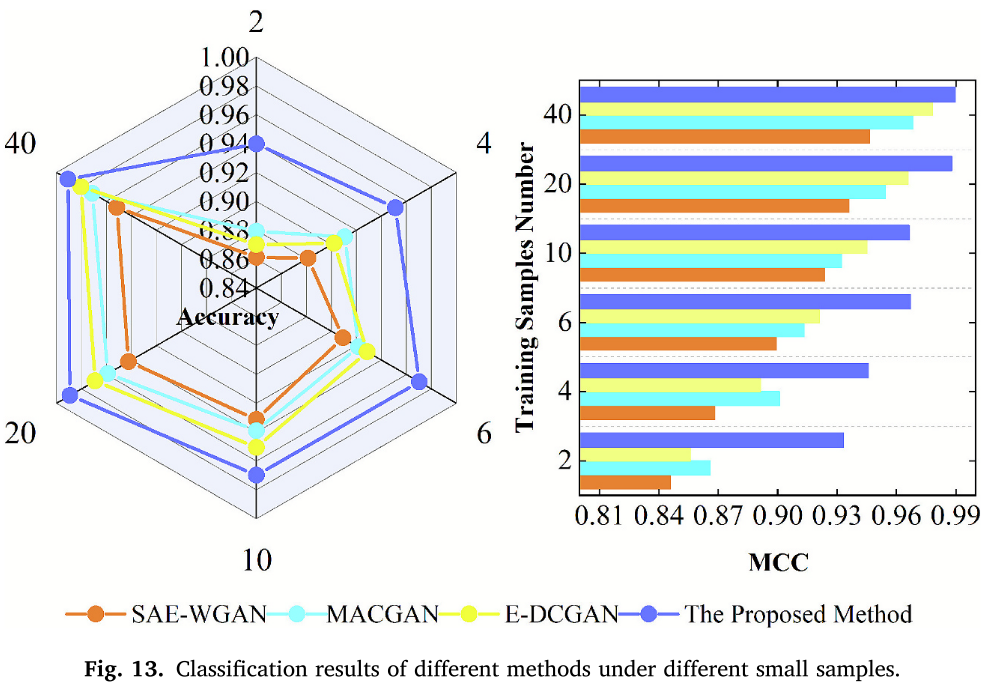
📌 【配图:Fig. 13 不同方法在不同小样本规模下的分类结果】
关键结果:
| 训练样本数/类 | MDRS-GAN 准确率 | MACGAN | E-DCGAN | SAE-GAN |
|---|---|---|---|---|
| 2 | 0.9432 | 0.8793 | 0.8701 | 0.8612 |
| 40 | 0.9908 | --- | --- | --- |
MCC 指标从 0.933(n=2)提升至 0.9896(n=40),验证了方法的持续优越性。
(3)不平衡数据故障诊断
设置 6 种不平衡比例(100:1 至 1:1),对比各方法在原始数据和平衡后数据上的表现。
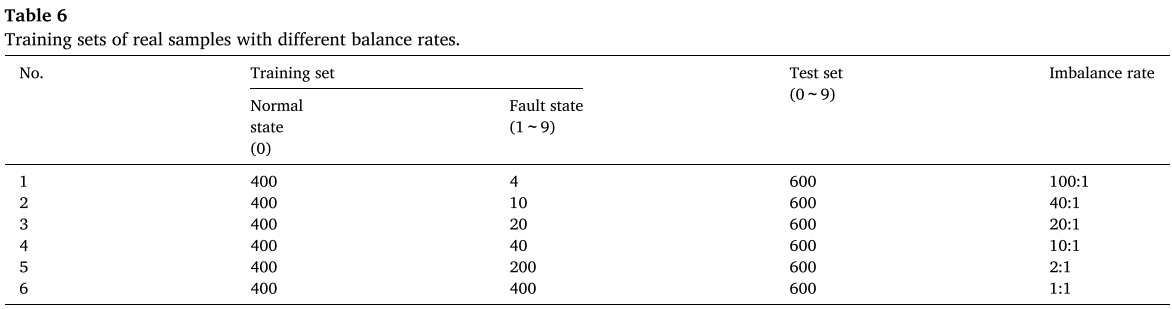
📌 【配表:Table 6 不同不平衡率训练集设置】
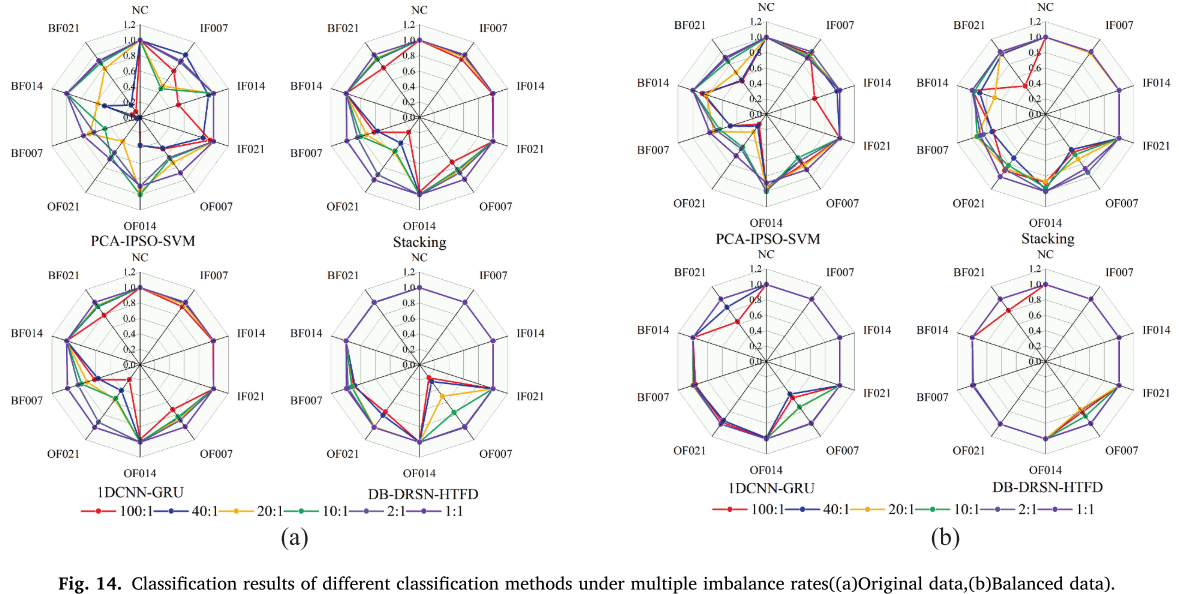
📌 【配图:Fig. 14 不同分类方法在多种不平衡率下的分类结果(a)原始数据 (b) 平衡后数据】
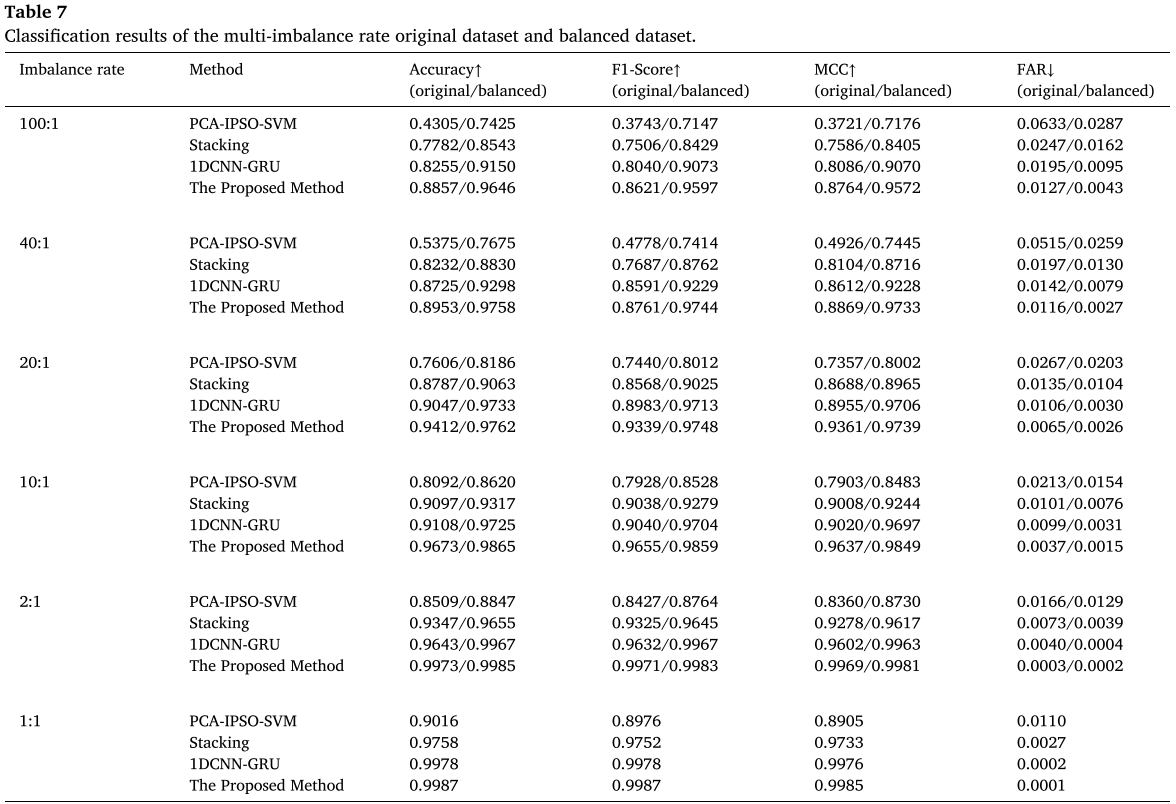
📌 【配表:Table 7 多不平衡率原始与平衡数据集的分类结果汇总】
关键结果(100:1 极端不平衡,平衡后):
| 方法 | Accuracy | F1-Score | MCC | FAR |
|---|---|---|---|---|
| PCA-IPSO-SVM | 0.7425 | 0.7147 | 0.7176 | 0.0287 |
| Stacking | 0.8543 | 0.8429 | 0.8405 | 0.0162 |
| 1DCNN-GRU | 0.9150 | 0.9073 | 0.9070 | 0.0095 |
| MDRS-GAN(本文) | 0.9646 | 0.9597 | 0.9572 | 0.0043 |
与其他方法的全面对比(图 15)表明,在 100:1 极端不平衡条件下,MDRS-GAN 达到 96.46% 准确率,相比 MACGAN 提升 3.96 个百分点,相比 SAE-WGAN 提升 6.58 个百分点,相比元学习方法 DRHRML 提升 4.34 个百分点,且标准差(0.0189)显著低于其他方法,稳定性最优。
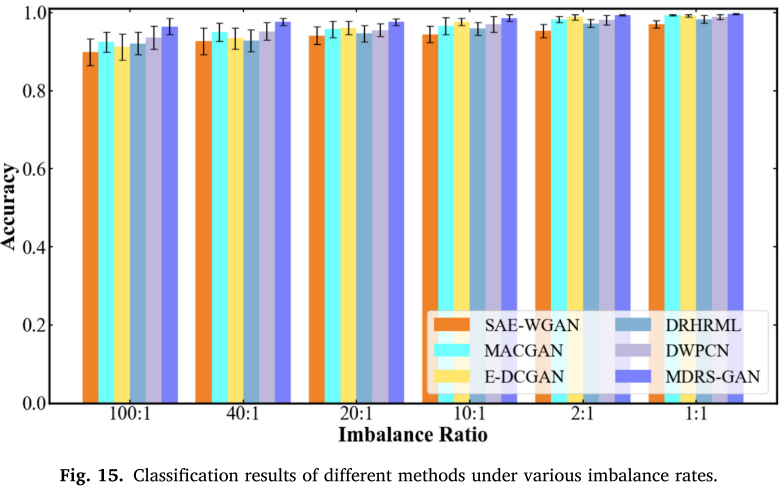
📌 【配图:Fig. 15 不同方法在各不平衡率下的分类结果对比】
7.3 案例二:XJTU-SY 轴承数据集
XJTU-SY 为滚动轴承加速寿命测试数据集,采样频率 25.6 kHz,包含 4 种健康状态(NC、IF、OF、CF),每类 1000 个样本。
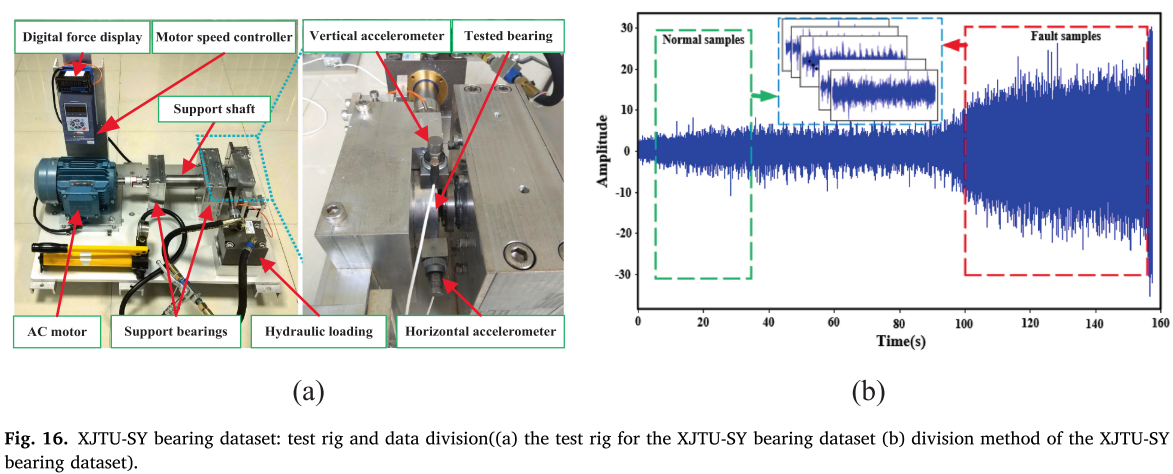

📌 【配图:Fig. 16 XJTU-SY 实验台与数据划分方法】 📌 【配表:Table 8 XJTU-SY 数据集详细描述】
生成样本的时频对比(图 17)和 t-SNE 可视化(图 18)均表明,MDRS-GAN 生成样本与真实样本高度相似,类间区分能力强。
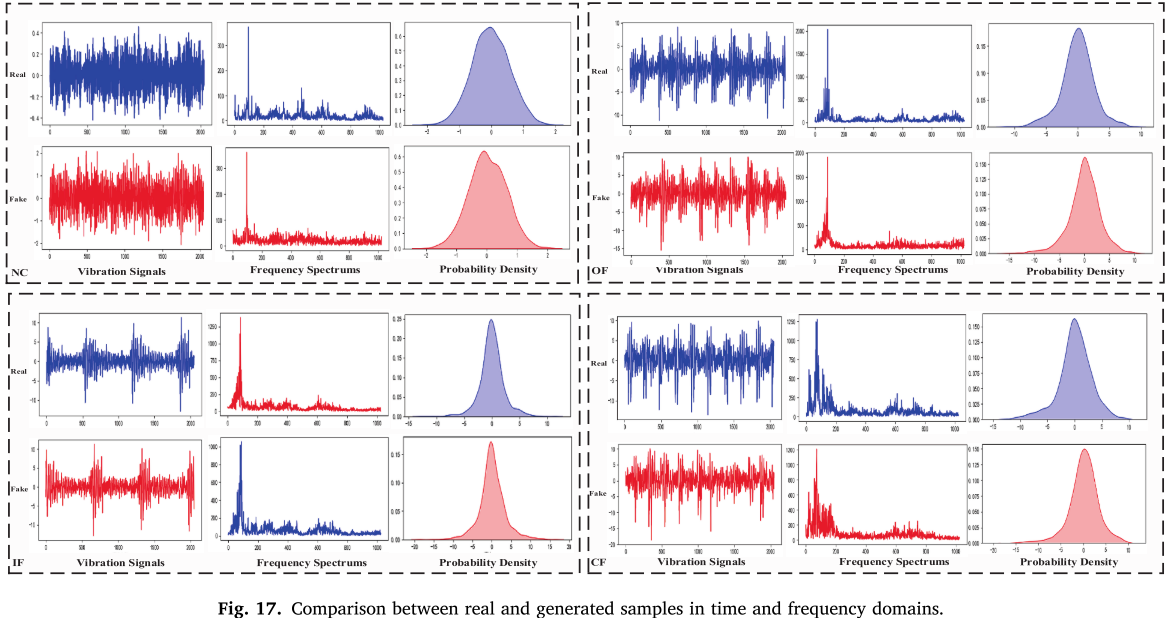
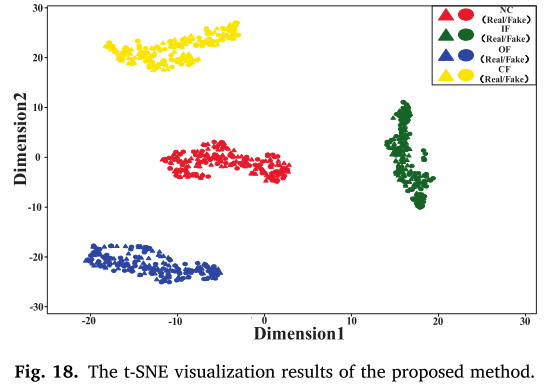
📌 【配图:Fig. 17 XJTU-SY 数据集真实样本与生成样本时频对比】 📌 【配图:Fig. 18 XJTU-SY 数据集 t-SNE 可视化结果】
小样本实验(图 19)与 CWRU 结论一致,MDRS-GAN 在所有样本规模下均保持领先优势。
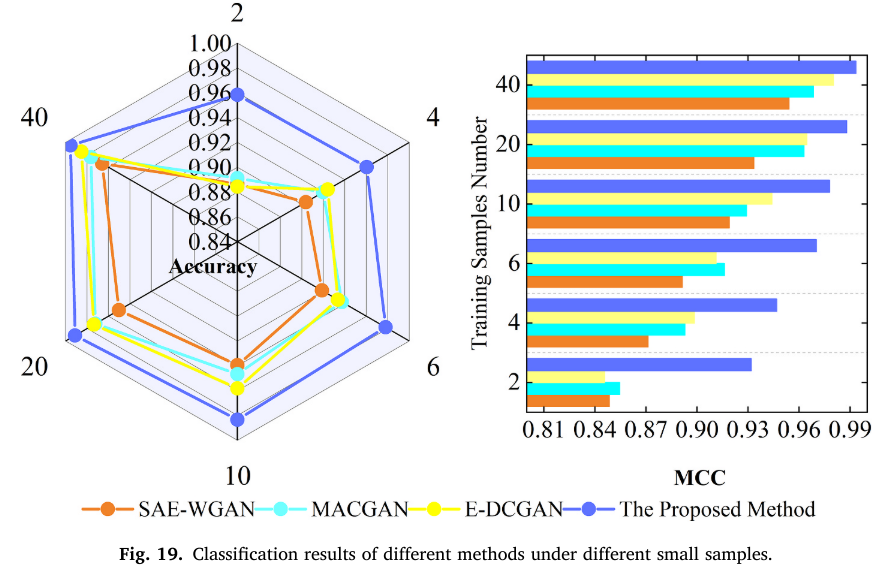
📌 【配图:Fig. 19 XJTU-SY 数据集不同小样本规模下的分类结果】
在 100:1 极端不平衡条件下,MDRS-GAN 平衡后准确率达 96.06% ,MCC 从原始的 0.8082 提升至 0.9479 ,FAR 从 0.0510 降至 0.0132。
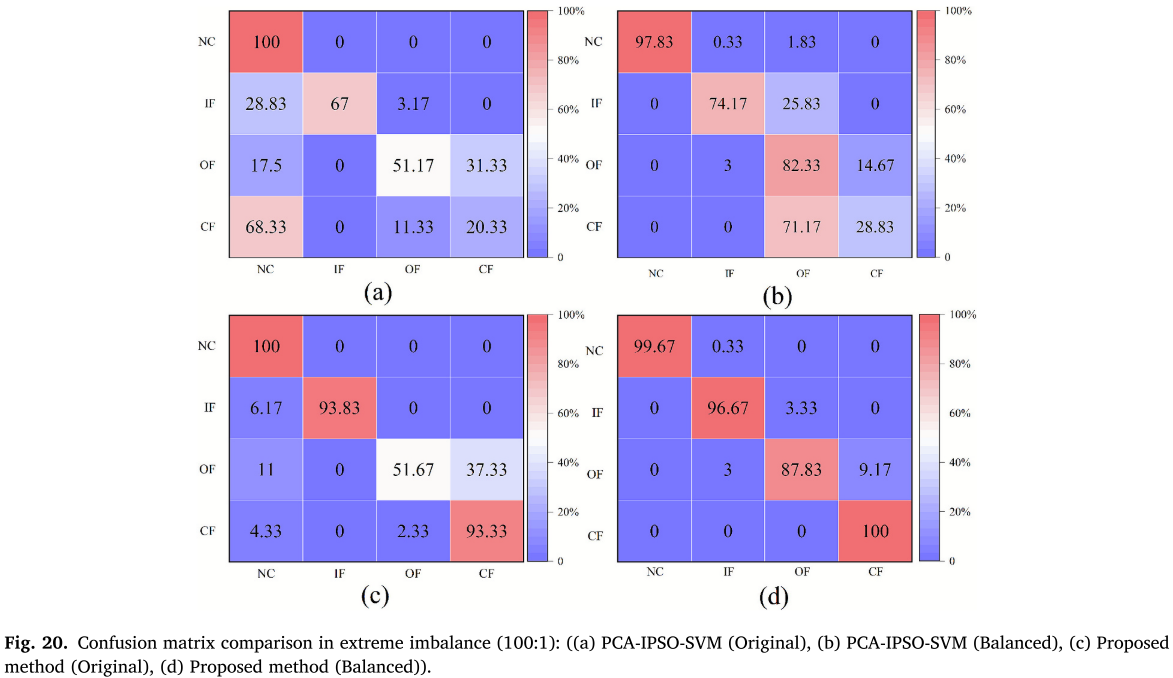
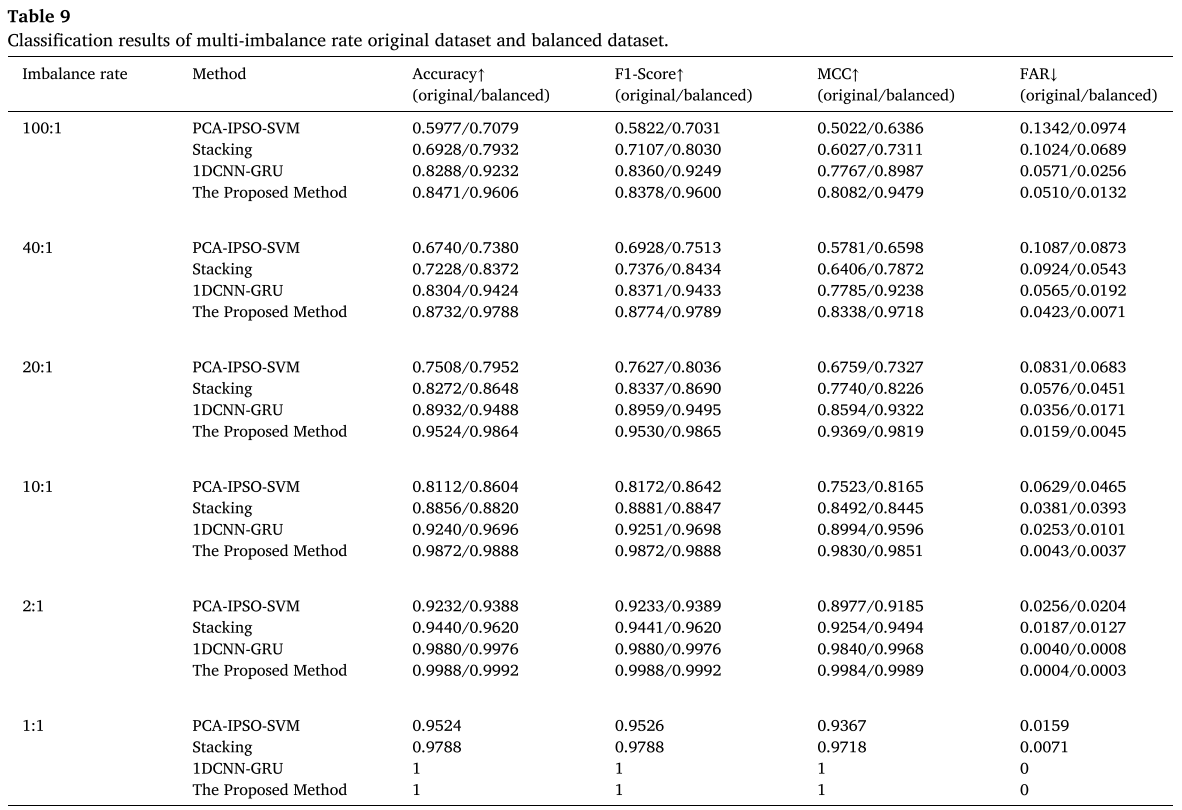
📌 【配图:Fig. 20 极端不平衡(100:1)条件下的混淆矩阵对比】 📌 【配表:Table 9 XJTU-SY 多不平衡率原始与平衡数据集的分类结果汇总】
在 100:1 场景下,MDRS-GAN 达到 96.06%,超过 E-DCGAN(94.23%)1.83 个百分点、DWPCN(93.87%)2.19 个百分点、MACGAN(91.23%)4.83 个百分点。
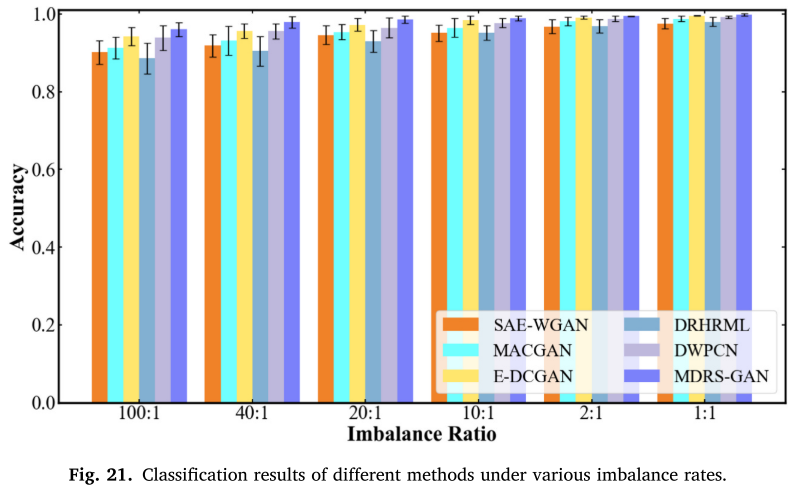
📌 【配图:Fig. 21 XJTU-SY 数据集不同方法在各不平衡率下的分类结果对比】
7.4 消融实验
在 CWRU 数据集上,对 7 个关键组件分别进行移除/替换,评估其对生成质量、小样本分类(n=2)、极端不平衡分类(100:1)和训练时间的影响。
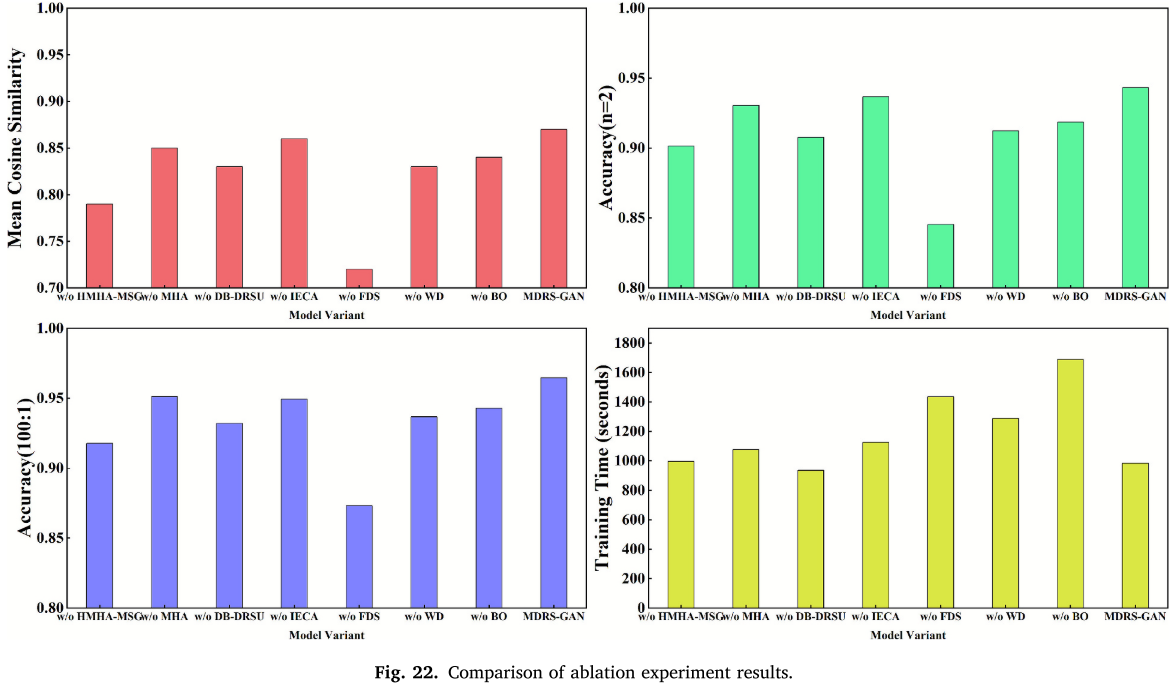
📌 【配图:Fig. 22 消融实验结果对比图】
主要发现:
| 消融项 | 余弦相似度变化 | 小样本准确率变化 | 不平衡准确率变化 | 训练时间变化 |
|---|---|---|---|---|
| 去除 FDS(w/o FDS) | 0.87 → 0.72(↓最大) | ↓ 9.78% | ↓ 9.14% | ↑ 45.98% |
| 去除 HMHA-MSG | 0.87 → 0.79 | ↓ 明显 | ↓ 明显 | --- |
| 去除 DB-DRSU | --- | ↓ 4.56% | ↓ 4.25% | --- |
| SENet 替换 IECA | --- | ↓ 一定 | ↓ 一定 | --- |
| 传统 ACGAN 损失替换 GP-WD | --- | ↓ 一定 | ↓ 一定 | ↑ 305 s |
| 网格搜索替换贝叶斯优化 | --- | ↓ 一定 | ↓ 一定 | ↑ 706 s |
FDS 分支是贡献最大的单一模块,其移除导致生成器与判别器能力失衡,严重阻碍 Nash 均衡的达成。
7.5 噪声鲁棒性验证
在 5 种不同信噪比(−5 dB、−2 dB、2 dB、5 dB、无噪声)下对比 IECA 与 SENet 的性能,验证软阈值去噪机制的有效性。
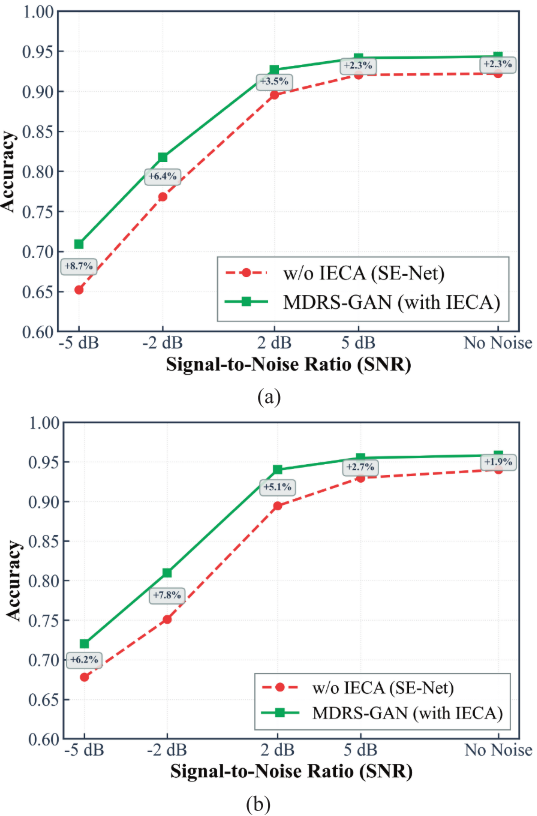
📌 【配图:Fig. 23 不同噪声环境下自适应软阈值模块性能对比(a)小样本(b)极端不平衡】
结论:IECA 在强噪声环境下(−5 dB)的性能提升最为显著,小样本场景提升 8.7% ,不平衡场景提升 6.3%,验证了软阈值去噪机制在嘈杂工业环境中的实用价值。
7.6 模型复杂度与效率分析
本文提出综合性能指数(CPI),综合衡量诊断精度与计算成本的权衡:
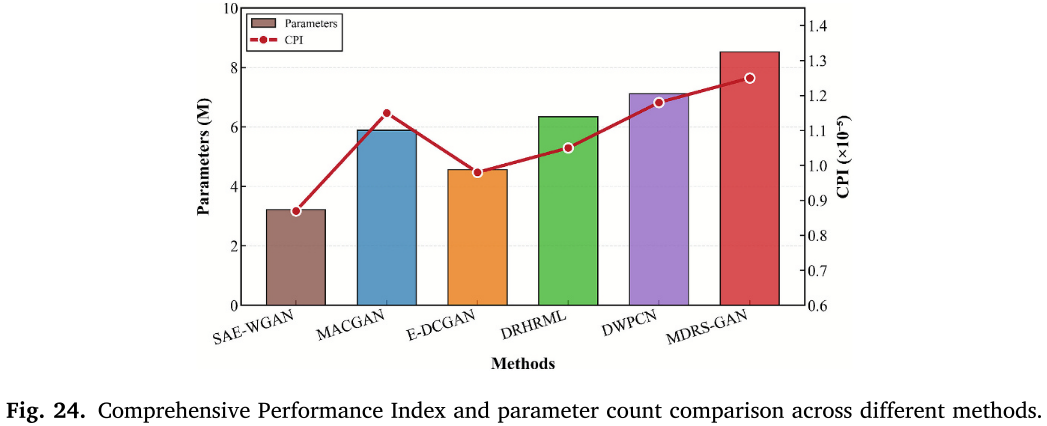
📌 【配图:Fig. 24 不同方法的综合性能指数与参数量对比】
尽管 MDRS-GAN 参数量最大,但其 CPI 值最高,说明其架构创新带来的诊断性能提升远超额外的计算开销,在工业实际应用中具有最优的效率-性能平衡。
八、结论与展望
本文提出的 MDRS-GAN 在旋转机械有限数据故障诊断领域取得了显著成果,核心结论如下:
- 生成质量 :生成样本与真实样本的余弦相似度全部超过 0.8,最高达 0.91;
- 小样本诊断 :仅 2 个样本/类时,CWRU 和 XJTU-SY 数据集的准确率分别达到 94.32% 和 95.83%;
- 极端不平衡诊断 :100:1 不平衡率下,两数据集准确率分别达到 96.46% 和 96.06%;
- 稳定性:MDRS-GAN 的平均标准差(CWRU: 0.0149,XJTU-SY: 0.0223)在所有对比方法中最低;
- 效率:贝叶斯优化将训练时间从 1689 s 压缩至 983 s,GP-WD 损失将训练时间从 1288 s 缩短至 983 s。
未来研究方向包括:
- 开发更广义的数据合成技术,适应更多设备类型和故障模式;
- 融合迁移学习与元学习策略,进一步提升跨域泛化能力;
- 在真实工业环境中(航空发动机、电力系统、医疗设备、工业物联网)验证模型的实用性。