C++ STL篇(八) ------ set 讲解
** 本篇文章将带你从零开始,一步步掌握 set的核心用法 。全程干货,坐稳发车~ ദ്ദി˶ー̀֊ー́ )✧**
文章目录
- [C++ STL篇(八) ------ set 讲解](#C++ STL篇(八) —— set 讲解)
-
- 1.序列式容器与关联式容器
-
- [1.1 序列式容器](#1.1 序列式容器)
- [1.2 关联式容器](#1.2 关联式容器)
- [2. set 系列的初步认识](#2. set 系列的初步认识)
-
- [2.1 参考资料](#2.1 参考资料)
- [2.2 set 类的声明拆解](#2.2 set 类的声明拆解)
- [2.3 构造与迭代器](#2.3 构造与迭代器)
- [2.4 增删查核心操作](#2.4 增删查核心操作)
-
- [2.4.1 插入 insert](#2.4.1 插入 insert)
- [2.4.2 查找 find 和 count](#2.4.2 查找 find 和 count)
- [2.4.3 删除 erase](#2.4.3 删除 erase)
- [2.4.4 边界查找 lower_bound 与 upper_bound](#2.4.4 边界查找 lower_bound 与 upper_bound)
- [3. 跟着代码彻底弄懂每个细节](#3. 跟着代码彻底弄懂每个细节)
-
- [3.1 insert 与迭代器遍历](#3.1 insert 与迭代器遍历)
- [3.2 find 和 erase 的正确使用](#3.2 find 和 erase 的正确使用)
- [3.3 lower_bound 与 upper_bound 实现区间操作](#3.3 lower_bound 与 upper_bound 实现区间操作)
- [4. multiset](#4. multiset)
- [5. 实战演练](#5. 实战演练)
-
- [5.1 两个数组的交集](#5.1 两个数组的交集)
- [5.2 环形链表](#5.2 环形链表)
- [6. 常见误区](#6. 常见误区)
-
- [6.1 绝不能修改元素](#6.1 绝不能修改元素)
- [6.2 迭代器失效](#6.2 迭代器失效)
- [6.3 优先使用成员函数](#6.3 优先使用成员函数)
- [6.4 为什么 set 没有下标操作?](#6.4 为什么 set 没有下标操作?)
- 结语:
1.序列式容器与关联式容器
在深入 set 之前,我们先搞清楚 STL 容器大家族里的两大派系。
1.1 序列式容器
我们已经学过的 string、vector、list、deque、array、forward_list 等,都属于序列式容器 。你可以把它们想象成一排储物柜,每个元素按照插入的顺序占据一个位置。比如你依次存入 A、B、C,那它们在内存(或逻辑上)就按照 A->B->C 的顺序排列。即使你把 A 和 B 交换一下位置,容器本身并不会因此"坏掉",依然是一个合法的序列。所以,序列式容器中元素之间的关联很松散,主要靠存储位置来组织和访问。
1.2 关联式容器
而关联式容器 则完全不一样。它的逻辑结构通常是非线性的(比如树形结构),元素之间存在着某种"紧密的关联关系"------这种关系由 关键字(key) 来维持。如果你胡乱交换两个元素的位置,这个容器的结构就会被破坏因为它不是靠位置来记忆元素的,而是靠关键字和它们之间的排序规则。
常见的关联式容器分为两大类:
- 有序关联容器 :
map/set系列,底层基于红黑树 (一种平衡二叉搜索树),元素按照键值自动排序。- 无序关联容器 :
unordered_map/unordered_set系列,底层基于哈希表,元素位置由哈希值决定,不保证顺序。
本文的主角是 set 和它的兄弟 multiset ,它们都基于红黑树实现,专门用于"关键字就是值本身"的场景(即 key 搜索模型)。而 map 则是"关键字-值"对(key/value 模型)的场景。今天我们先彻底拿下 set。
2. set 系列的初步认识
2.1 参考资料
关于 set 的官方参考可以查阅:
2.2 set 类的声明拆解
我们先来看一下 set 的类模板声明:
cpp
template <
class T, // 关键字类型
class Compare = std::less<T>, // 比较函数对象
class Alloc = std::allocator<T> // 空间配置器(内存管理)
> class set;这三个模板参数分别代表了:
T:你打算存储的元素的类型。在set里,元素的值就是它的键,因此也叫key_type和value_type,它们俩是同一回事。Compare:如何比较两个元素的大小。默认是std::less<T>,也就是用<运算符(升序)。set默认要求你的类型支持<比较。如果你想自定义排序规则,可以自己写一个仿函数(函数对象)传进来。Alloc:控制内存分配的方式,默认使用标准分配器。绝大多数情况下我们不需要动它。
关键点:
set的底层是红黑树(我们之后的文章中会对红黑树进行深入讲解),它具备以下核心特性:
- 自动排序 :元素始终按
Compare规则保持有序,默认是升序。- 唯一性:不允许有重复的关键字,同一个值只能出现一次。
- 高效操作 :插入、删除、查找的平均时间复杂度都是 O(log N)。
- 迭代器中序遍历 :当你用迭代器遍历时,会得到一个有序序列。
通常情况下,我们只需要传第一个参数,后两个保持默认就够用了。
2.3 构造与迭代器
set 提供了多种构造方法,我们可以重点关注以下几个最常用的:
cpp
// 1. 默认构造:创建一个空 set
explicit set(const Compare& comp = Compare(),
const Alloc& alloc = Alloc());
// 2. 迭代器区间构造:用一段 [first, last) 区间内的元素初始化 set
template <class InputIterator>
set(InputIterator first, InputIterator last,
const Compare& comp = Compare(),
const Alloc& = Alloc());
// 3. 拷贝构造
set(const set& x);
// 4. 初始化列表构造(C++11)
set(std::initializer_list<value_type> il,
const Compare& comp = Compare(),
const Alloc& alloc = Alloc());例如:
cpp
set<int> s1; // 空集合
set<int> s2 = {3, 1, 4, 1, 5}; // 初始化列表,注意重复的 1 只会保留一个
set<int> s3(s2.begin(), s2.end()); // 迭代器区间构造 迭代器 是访问 set 元素的核心工具。set 提供了双向迭代器,支持正向和反向遍历。
一个极为重要的特性:
set 的迭代器不允许修改元素的值 。也就是说,无论是 iterator 还是 const_iterator,你都不能通过 *it = ... 来赋值。尝试这样做会导致编译错误。为什么?因为 set 中的元素是自动排序的,如果你偷偷改了某个键的值,整个红黑树的结构就会被破坏,导致未定义行为。所以标准库直接将迭代器指向的元素视为常量,从根本上禁止修改。
由于支持迭代器,set 自然也支持范围 for 循环,遍历起来非常方便。
2.4 增删查核心操作
下面我们来看看 set 最常用的增删查接口。这些接口和 vector、list 很像,但由于 set 的关联特性,参数和返回值会有一些不同。
2.4.1 插入 insert
cpp
// 1. 插入单个值,返回一个 pair:first 是指向插入元素(或已存在元素)的迭代器,
// second 是 bool,表示是否真的插入了新元素
pair<iterator, bool> insert(const value_type& val);
// 2. 插入初始化列表中的值(已存在的不会重复插入,也没有返回值告诉你哪些没插入)
void insert(std::initializer_list<value_type> il);
// 3. 插入一段迭代器区间
template <class InputIterator>
void insert(InputIterator first, InputIterator last); 单个插入的返回值非常有用:pair 的第一个成员是一个迭代器,指向刚插入的那个新元素 ,如果元素已经存在,就指向那个已存在的元素。第二个成员是 bool,表示是否插入成功。你可以用它来判断某个值是不是之前就已经存在。
2.4.2 查找 find 和 count
cpp
// 在 set 中查找 val,返回指向该元素的迭代器,若没找到则返回 end()
iterator find(const value_type& val);
const_iterator find(const value_type& val) const;
// 返回 val 的元素个数,由于 set 不允许重复,结果只能是 0 或 1
size_type count(const value_type& val) const; find 的复杂度是 O(log N) ,远比算法库里的通用 std::find(复杂度 O(N))高效。永远优先使用 set 自己的 find 。
count 对于 set 来说,通常用于检查某个元素是否存在:返回 1 表示存在,返回 0 表示不存在。
2.4.3 删除 erase
cpp
// 删除一个迭代器指向的元素,返回被删除元素的下一个迭代器(C++11起)
iterator erase(const_iterator position);
// 删除值为 val 的元素,返回实际删除的元素个数(0 或 1)
size_type erase(const value_type& val);
// 删除 [first, last) 区间的元素,返回 last
iterator erase(const_iterator first, const_iterator last);- 使用迭代器删除时,要确保迭代器有效,而且删除后该迭代器会失效,不能再使用。
- 按值删除会返回删掉了几个,对于
set来说就是 0 或 1(set 中的值不重复)。
2.4.4 边界查找 lower_bound 与 upper_bound
这两个函数在处理区间问题时特别有用:
cpp
// 返回第一个 >= val 的位置的迭代器
iterator lower_bound(const value_type& val);
const_iterator lower_bound(const value_type& val) const;
// 返回第一个 > val 的位置的迭代器
iterator upper_bound(const value_type& val);
const_iterator upper_bound(const value_type& val) const;lower_bound 和 upper_bound 加起来可以精确划定一个范围:[lower_bound(a), upper_bound(b)) 包含所有满足 a ≤ x ≤ b 的元素。你可以利用这个区间进行批量删除或遍历。
3. 跟着代码彻底弄懂每个细节
下面我们结合具体的代码,一块一块地分析。
3.1 insert 与迭代器遍历
cpp
#include <iostream>
#include <set>
using namespace std;
int main()
{
// set<int> s; // 默认升序(从小到大)
set<int, greater<int>> s; // 传入 greater<int>,改为降序(从大到小)
s.insert(4);
s.insert(8);
s.insert(4); // 重复的 4,不会插入成功
s.insert(2);
s.insert(9);
auto it = s.begin();
while (it != s.end())
{
// 编译报错!不能给常量赋值
// *it = 1;
cout << *it << " ";
++it;
}
cout << endl;
// 插入初始化列表中的值,已经存在的值(如 8)插入失败,4 也不会再出现
s.insert({6, 8, 7, 1, 5});
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
// 存放字符串的 set,默认按照字符串的字典序(ASCII码)排序
set<string> strset({"sort", "insert", "add"});
for (auto& e : strset)
{
cout << e << " ";
}
cout << endl;
return 0;
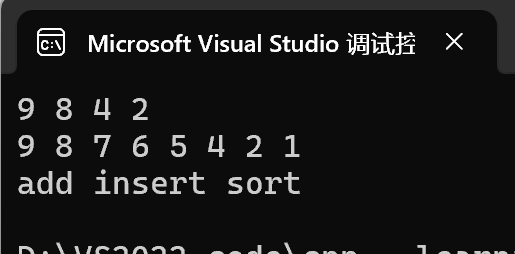
}
解析:
- 降序排列 :
set<int, greater<int>> s;通过第二个模板参数把比较器换成了greater<int>。原本用less<int>,比较规则是"小于",换成greater后,比较规则变成了"大于",所以中序遍历结果是降序。输出时你会看到从大到小排列。 - 重复插入 :
s.insert(4);执行两次,第二次插入时4已经存在,操作会失败。set里仍然只有一个4。 - 不能修改元素 :如果写
*it = 1;,编译器会直接报错,因为set的迭代器指向的是常量。这保护了底层的结构不被破坏。 - 初始化列表插入 :
s.insert({6,8,7,1,5});会把列表中的每个元素尝试插入。对于已经存在的元素(比如之前就有的8和4),会直接跳过。最终容器里是所有出现过的唯一值,并按降序排列。 - 字符串 set :
set<string>默认按照字典序比较,所以输出顺序是"add","insert","sort"(因为 'a' < 'i' < 's')。
3.2 find 和 erase 的正确使用
cpp
int main()
{
set<int> s = {3, 9, 2, 6, 8, 1, 4, 7};
for (auto e : s)
{
cout << e << " "; // 输出:1 2 3 4 6 7 8 9 (自动升序)
}
cout << endl;
// 删除最小的元素(s.begin() 指向最小)
s.erase(s.begin());
for (auto e : s)
{
cout << e << " "; // 2 3 4 6 7 8 9
}
cout << endl;
// 方法1:直接按值删除 x
int x;
cin >> x;
int num = s.erase(x);
if (num == 0)
cout << x << "不存在!" << endl;
else
cout << x << "删除成功!" << endl;
// 方法2:先用 find 找到迭代器,再删除
cin >> x;
auto pos = s.find(x);
if (pos != s.end())
{
s.erase(pos); // 删除后 pos 失效
cout << x << "删除成功!" << endl;
// cout << *pos; // 不能使用失效的迭代器!!
}
else {
cout << x << "不存在" << endl;
}
// 算法库的 find(不推荐用于 set)
auto pos1 = std::find(s.begin(), s.end(), x); // O(N)
auto pos2 = s.find(x); // O(logN)
// 利用 count 快速判断元素是否存在
cin >> x;
if (s.count(x))
cout << x << "存在!" << endl;
else
cout << x << "不存在!" << endl;
return 0;
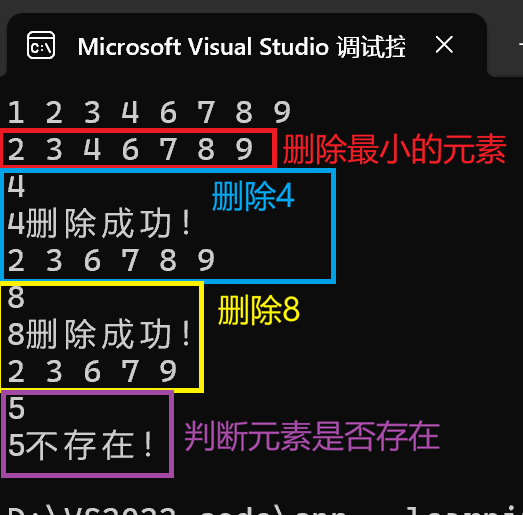
}
核心要点:
- 删除 begin() :
s.erase(s.begin())会移除当前最小的元素。注意删除后,原来的s.begin()迭代器失效了,但s本身依然有效,下一次调用begin()会指向新的最小元素。 - 按值删除
erase(x):返回 0 或 1,可以直接用来判断该值是否存在于集合中。这是一种既判断又删除的简洁写法。 - 先 find 后 erase :
pos = s.find(x)如果成功,pos就是一个有效的迭代器。传给erase(pos)后,pos 立即失效 ,不能再解引用或递增。代码中注释掉的那行cout << *pos;一旦执行,行为是未定义的,可能导致崩溃或读取垃圾数据。 - 效率差异 :
std::find(s.begin(), s.end(), x)在set上执行时是暴力遍历,复杂度 O(N);而s.find(x)利用红黑树,复杂度 O(log N)。在数据量大时,两者差距惊人,一定要用成员函数find。 count判段是否存在 :s.count(x)要么是 0 要么是 1,非常适合做条件判断,比find略简洁一些,但如果你还需要拿到迭代器做进一步操作,find更好。
3.3 lower_bound 与 upper_bound 实现区间操作
cpp
int main()
{
set<int> myset;
for (int i = 1; i < 10; i++) {
myset.insert(i * 10); // 10 20 30 40 50 60 70 80 90
}
for (auto e : myset) {
cout << e << " "; // 10 20 30 40 50 60 70 80 90
}
cout << endl;
// 想要获取在 [30, 50] 范围内的所有元素
auto itlow = myset.lower_bound(30); // 返回第一个 >=30 的位置,即 30
auto itup = myset.upper_bound(50); // 返回第一个 >50 的位置,即 60
// 演示更宽泛的范围 [25, 55]
itlow = myset.lower_bound(25); // >=25,实际指向 30
itup = myset.upper_bound(55); // >55,实际指向 60
// 删除 [itlow, itup) 区间内的所有元素
myset.erase(itlow, itup);
for (auto e : myset) {
cout << e << " "; // 输出 10 20 60 70 80 90
}
cout << endl;
return 0;
}这段代码展示了如何删除一个闭区间内的所有元素。
- 初始集合包含 10 的倍数:10, 20, 30, 40, 50, 60, 70, 80, 90。
lower_bound(25)找到第一个 ≥ 25 的元素。由于 20 < 25,下一个是 30,所以返回指向 30 的迭代器。upper_bound(55)找到第一个 > 55 的元素。55 之后第一个是 60,所以返回指向 60 的迭代器。- 区间
[itlow, itup)包含了 30, 40, 50。erase(itlow, itup)会删除这三个元素,剩下 10, 20, 60, 70, 80, 90。
小技巧: 如果你想获取包含边界
[a, b]的所有元素,就用lower_bound(a)和upper_bound(b),然后作用于erase或遍历。
4. multiset
multiset 与 set 的用法几乎一模一样,唯一的本质区别就是:multiset 允许存在多个相同的关键字 ,也就是允许值冗余。这一差异导致了 insert、find、count 和 erase 的行为有所不同。
cpp
int main()
{
// multiset 只排序,不去重
multiset<int> s = {3, 9, 2, 6, 8, 1, 4, 7, 2, 6, 4, 4};
auto it = s.begin();
while (it != s.end())
{
cout << *it << " "; // 输出:1 2 2 3 4 4 4 6 6 7 8 9
++it;
}
cout << endl;
// find 查找 x:如果有多个,返回中序遍历的第一个 x
int x;
cin >> x;
auto pos = s.find(x);
while (pos != s.end() && *pos == x)
{
cout << *pos << " ";
++pos;
}
cout << endl;
// count 返回 x 的实际个数
cout << s.count(x) << endl;
// erase 按值删除:会把所有的 x 都删掉
// 如果你只想删一个,需要用迭代器删除
pos = s.find(x);
while (pos != s.end() && *pos == x)
{
pos = s.erase(pos); // erase 返回下一个迭代器,所以可以安全地继续
}
cout << endl;
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
return 0;
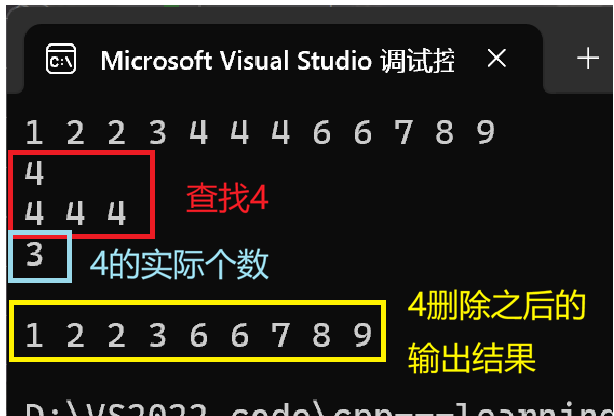
}
对比 set 逐一理解:
- 构造和插入 :
multiset<int>可以接收重复值,构造后它会自动排序,但不会去重。输出中4出现了 3 次,2和6各出现 2 次。 - find 的行为 :
s.find(x)在有多个匹配时,返回的是中序遍历遇到的第一个x。然后我们可以在循环里依次向后遍历,直到遇到的值不再是x,这样就访问了所有等于x的元素。 - count 的含义不同了 :在
multiset里,count(x)返回的是实际存在多少个x,可能大于 1。 - erase 按值删除十分危险 :
s.erase(x)会删除所有等于 x 的元素 !如果你只想删除其中一个,必须通过迭代器s.erase(pos)来精确删除某个位置。代码中使用了一个循环,每次erase(pos)返回被删除元素的下一个位置,将其赋给pos可以安全地继续向后清理所有x。
简单总结:
| 特性 | set | multiset |
|---|---|---|
| 是否允许重复元素 | 否 | 是 |
insert 返回值 |
pair<iterator, bool> |
仅 iterator(总成功) |
find |
返回唯一元素或 end() | 返回中序第一个 |
count |
0 或 1 | 实际个数 |
erase(val) |
删除该值(0 或 1 个) | 删除所有该值 |
5. 实战演练
5.1 两个数组的交集
传送门:两个数组的交集

思路拆解:
- 利用set完成 去重+排序
- 迭代器遍历两个有序集合,找交集
两个迭代器都从头开始遍历两个有序集合;
如果迭代器指向的值不相等:指向的值比较小的那个迭代器向后移动(有序序列越往右数越大,更小的数永远不可能匹配对面后方更大的数,直接舍弃、迭代器后移即可。)
如果相等:说明这是交集元素,加入结果集,然后两个迭代器都向后移动(因为集合里没有重复元素,这个数不会再出现了)。
代码示列
cpp
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
set<int> s1(nums1.begin(),nums1.end());
set<int> s2(nums2.begin(),nums2.end());
vector<int> v;
auto it1 = s1.begin();
auto it2 = s2.begin();
while(it1 != s1.end() && it2 != s2.end())
{
if(*it1 < *it2)
{
++it1;
}
else if(*it1 > *it2)
{
++it2;
}
else{
v.push_back(*it1);
++it1;
++it2;
}
}
return v;
}
};这里再补充一个小问题:如果要找差集怎么办?
- 迭代器指向的值更小的就是差集,加入结果集,然后让值更小的迭代器向后移动。
- 如果两个迭代器相等 ,说明这个元素在两个集合里都存在,不属于差集,两个迭代器同时往后走。
- 其中一个走到尾部了,另一个没走完的值也是属于差集
5.2 环形链表
传送门:环形链表
思路拆解:
利用 set 存储已经访问过的节点指针,遍历链表时,第一次遇到重复访问的节点,就是环的入口。
- 创建一个集合,用来存储已经访问过的节点指针
- 遍历链表,直到节点为空(无环)或找到重复节点(有环)。
- 遍历结束没找到重复节点,说明链表无环,返回 nullptr
代码示例:
cpp
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
set<ListNode*> s;//用来存储已经访问过的节点
ListNode* cur = head;
while(cur)
{
//count 可以判断节点是否存在
if(!s.count(cur))
{
s.insert(cur);
cur = cur->next;
}
else //找到了重复的节点
return cur;
}
return nullptr;
}
};6. 常见误区
6.1 绝不能修改元素
*it = new_value 在 set 中是行不通的。如果你需要修改一个元素,只能先 erase 旧值,再 insert 新值。
6.2 迭代器失效
set 的插入操作不会使任何已有的迭代器失效;删除操作只会使指向被删除元素的迭代器失效,其它迭代器依然有效。这与 vector 有很大不同。代码中删除后继续使用 pos 是个常见的坑,务必重新赋值或提前备份。
6.3 优先使用成员函数
set 的成员函数 find、lower_bound 等是专为树结构优化的,复杂度 O(log N)。不要图方便去用 <algorithm> 里全局的 std::find,那会变成线性遍历。
6.4 为什么 set 没有下标操作?
set 不是序列容器,元素的位置由排序规则决定,而不是线性索引。如果你需要"第 k 个元素",只能通过迭代器 + 循环,但那样做效率较低,通常说明 set 可能不是最适合你的结构。可以考虑在特定场景下使用 vector 并保持排序,或结合其它数据结构。
结语:
今天的内容到这里就结束了,希望你能有所收获~
干货整理到手抖,觉得有用的话,赏个三连回回血?__(:ᗤ」ㄥ)_ _