在日常与企业级客户及前端开发者的交流中,我经常听到这样的痛点:"我们成功接入了大模型,但它总是'睁眼瞎'。用户在表格里改了数据,AI 不知道;AI 修改了单元格,UI 没有同步。聊了几轮之后,大模型的记忆和真实的电子表格完全脱节了。"
本文将为您深度解构这台状态同步引擎,看它是如何彻底破解多实例混乱,并实现自然语言与表格状态的精准对齐。
第一部分:全局状态中心的构建------打造 AI 与表格的"唯一真理之源"
1.为什么"状态同步"是前端集成 AI 的最大痛点?
SpreadJS 是一款极其强大的纯前端电子表格控件,其底层基于 Canvas 渲染引擎(拥有多达 9 层的渲染架构),这意味着你无法像操作普通 Web 页面那样通过读取 DOM 树来获取表格数据。
在 React 等现代前端框架中,组件的状态管理本就复杂。当你引入 AI 助手侧边栏(ChatPanel)后,系统就出现了两个高频变化的状态源:
- 用户在电子表格 UI 上的直接操作(修改数值、改变颜色、插入图表)。
- AI 通过大模型生成的后台操作指令。
如果采用传统的组件间传值或松散的状态管理,极易导致"多实例混乱"------内存中可能无意间实例化了多个 Workbook 对象,导致 AI 操作的表格与用户眼前看到的表格根本不是同一个。在 Harness 架构中,这就是典型的 Context Rot(上下文腐烂),大模型获取的信息由于不同步而变得充满幻觉。
2.SpreadContext 的设计逻辑与全局统筹
为了解决这个致命缺陷,我们构建了 SpreadJSContext(全局状态中心)。它直接映射了 Harness 中的"文件系统"组件,是整个 Agent 能够持久化记忆、理解当前环境的最基础原语。
SpreadContext 的核心设计逻辑是将工作簿实例(Workbook Ref)提升到 React 的全局 Context 中,使其成为全应用的"单点真实数据源(Single Source of Truth)"。
它承担了以下核心构建任务:
- 跨组件通信桥梁: 将左侧的
SpreadJSDesigner(电子表格设计器)与右侧的ChatPanel(AI 对话面板)彻底解耦。AI 在生成工具调用时,无需直接操作繁杂的底层 DOM,只需向 Context 索要当前的workbook实例快照,即可安全、高效、一致地访问同一个工作簿。 - 多层级状态隔离与映射: 在我们的架构设计图中,内存状态(React State)不仅包含
workbook ref,还严格管理着messages(对话消息)、toolResults(工具执行结果)以及activeModule(当前激活的工具模块,如图表模块、透视表模块)。这种分层设计,确保了 AI 的"对话记忆"与表格的"物理状态"始终保持映射。

第二部分:生命周期与数据流控------从初始化到脏检查的全天候追踪
在 Harness 的记忆管理模块中,Agent 不仅需要知道"现在是什么",还需要知道"刚刚发生了什么"。SpreadContext 不仅仅是一个静态的存储仓库,它还是一个精密的生命周期与数据流控中心。
1.生命周期管控与懒加载优化
企业级表格应用通常体积庞大。为了保证极速的首屏加载体验,SpreadContext 内部集成了懒加载优化 机制,动态导入 SpreadJS 的核心引擎库(如 spreadsheet.fefd9494.js)。
在生命周期管控方面,SpreadContext 全权负责设计器的初始化(挂载 DOM)、卸载(销毁实例回收内存)以及事件流的建立。这意味着,哪怕 React 组件经历了多次重渲染,底层庞大的 SpreadJS 实例也能安然无恙地保持稳定,确保 AI 随时调用的引用都是最新且有效的。
2.状态持久化:打破会话隔离
传统的 AI 对话一旦刷新页面,上下文就丢失了。我们的引擎结合了本地状态(LocalStorage)策略,将 sessions(会话历史)和 autosave(自动保存的表格快照)持久化。配置开启后,即使用户不小心刷新了页面,系统也能自动恢复上一次的活跃会话,并将最新的 Workbook 快照还原,确保"记忆"不中断。
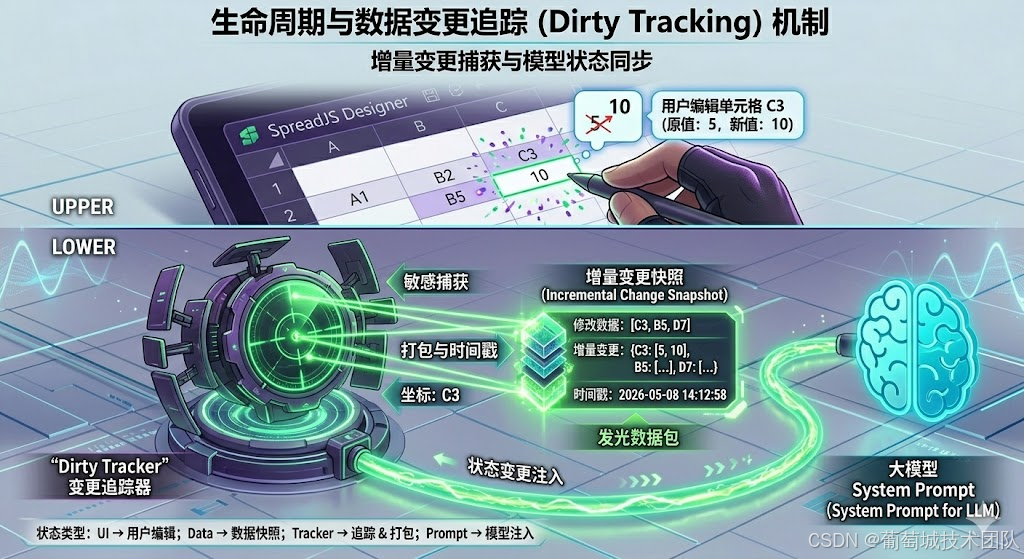
3.核心杀手锏:变更追踪(Dirty Tracking)机制
这是应对大模型上下文长度限制的终极武器。由于电子表格可能包含成千上万行数据,每次对话都把完整的表格 JSON 传给 AI 是不现实的,且会引发严重的"信息过载"。
根据项目的状态同步流程设计,我们在 SpreadContext 中引入了工作簿变更监听(Dirty Tracker)。
- 系统通过
useDirtyTrackerHook,实时监听 SpreadJS 的底层事件(如单元格内容变更、格式修改)。 - 当用户手动修改了某个区域的数据时,Tracker 会精准记录这个"修改区域(Dirty Area)"。
- 在用户下一次发起对话请求时,系统并不会发送全量数据,而是基于这些修改记录,发送
dirtyContext(增量变更记录)注入到 System Prompt 的状态快照中。
这种极其细腻的数据流控,完美契合了 Harness 对抗熵增的"上下文工程"理念,使得大模型不仅能看见表格的现在,还能精准感知表格的局部变化动态。
第三部分:调用闭环解析------底层执行管线的数据大流转
了解了状态中心的设计,接下来我们必须拆解最核心的执行闭环。大模型是如何从"动嘴"转变为"动手",并最终让 SpreadContext 实现状态闭环的?
在 Harness 架构中,这是通过"沙箱执行"让 Agent 从"生成代码"走向"执行代码",完成"写 -> 跑 -> 看 -> 修"的自我验证循环。在 SpreadJS AI Agent 中,我们打造了一条极为严密的底层执行管线。
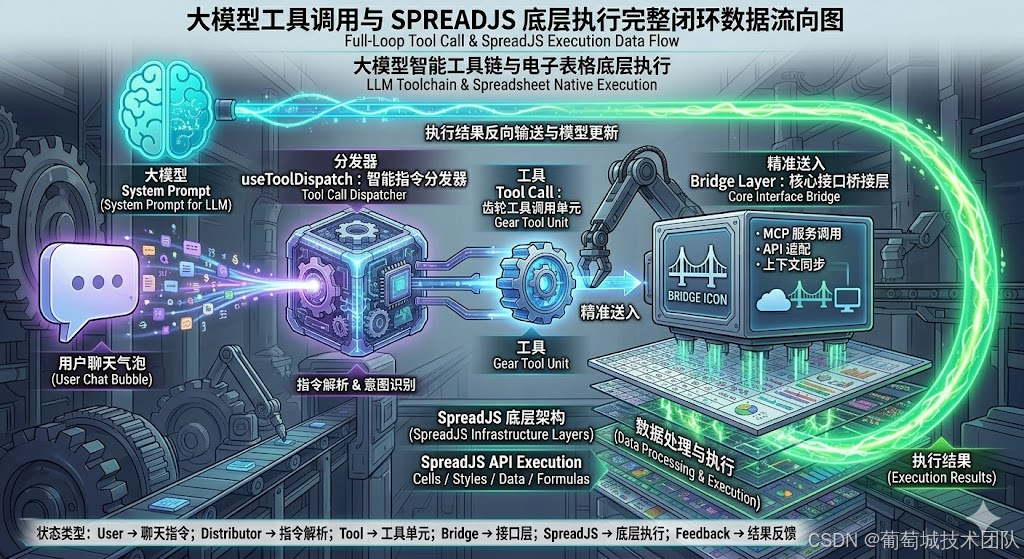
完整的调用闭环如下:
Step 1: 用户输入与上下文注入 (用户输入→LL用户输入 \rightarrow LL用户输入→LL)
当用户在 ChatPanel 输入指令(如:"将总资产标黄并加粗")后,前端 useChat 模块会拦截请求。在发送给大模型之前,通过 /api/chat 接口,系统会调用 buildSystemPrompt(ctx)。此时,大模型不仅收到了用户的文字,还接收到了由 SpreadContext 提供的当前工作簿状态描述、任务计划以及 MCP(Model Context Protocol)上下文。
Step 2: 模型决策与工具分发 (LLM生成工具调用→useToolDispatcLLM 生成工具调用 \rightarrow useToolDispatcLLM生成工具调用→useToolDispatc)
大模型经过推理,决定调用预设的工具。它会生成一段符合 JSON Schema 规范的 Tool Call 请求(例如调用 manage_format 网关工具,随后调用子工具 format_range)。 此时,前端业务逻辑层的核心 Hook------useToolDispatch 接收到这一调用指令。useToolDispatch 充当了"交通警察"的角色,它会对工具调用进行分发解析。
Step 3: 工具路由与 Bridge 层处理 (获取workbook→Bridge层处获取 workbook \rightarrow Bridge 层处获取workbook→Bridge层处)
在分发阶段,系统会判断该工具是需要服务端执行(如 web_search、execute_code)还是客户端执行(如各种 SpreadJS 表格原生操作)。 对于前端表格操作,useToolDispatch 会从 SpreadContext 中安全地提取当前的 workbook 实例引用。接着,将工具的参数(args)和实例一并交给 SpreadJS 桥接层(Bridge Layer)。 Bridge 层是极其关键的隔离层,它包含了对数据读写(Data)、工作表管理(Sheet)、格式设置(Format)和对象处理(Object)的封装。
Step 4: 触达物理层与安全护栏 (执行SpreadAP执行 Spread AP执行SpreadAP)
Bridge 层接收到指令后,将其精确转化为 SpreadJS 底层的原生 API 操作(例如调用 sheet.getRange().backColor("yellow").fontWeight("bold"))。 值得一提的是,在这个执行步骤中,系统融入了极强的安全约束(对应 Harness 的安全审计与人工确认)。如果是诸如清空数据等"破坏性操作(WRITE 操作)",系统可以通过挂载"人工确认(AskForPermission)"节点暂停执行,等待用户点击同意后才实际触发表格 API 的调用。
Step 5: 结果格式化与状态回传 (结果返回LL结果返回 LL结果返回LL)
API 执行完毕后,无论成功还是因为参数错误引发了异常,Bridge 层都会捕获返回值或错误信息,并将其格式化为标准的 ToolResult。 这个 ToolResult 会被沿着原路返回给大模型。LLM 观察执行结果后,验证操作是否符合预期(对应 Harness 的"看和修"环节)。如果成功,大模型会生成最终的自然语言回复并展示在 ChatPanel 中;如果失败,它将根据错误日志进行二次推理重试。
至此,一个从自然语言意图到表格物理状态改变,再到大模型记忆更新的宏大闭环完美落幕。
总结
通过深入剖析 SpreadJS AI Agent 的状态与记忆管理模块,我们可以清晰地看到,它是如何完美践行 Harness 核心架构思想的。
SpreadContext 同步引擎 绝不仅仅是一个简单的状态存储器,它是打通大语言模型"虚拟认知"与复杂电子表格"物理现实"的高速公路。它通过全局单一的工作簿引用解决了多实例灾难;通过精细的生命周期管理与 Dirty Tracking 变更追踪,赋予了大模型对抗上下文信息腐烂的能力;更通过严密的 useToolDispatch 到 Bridge 层的调用闭环,保障了从自然语言到代码执行的安全与一致。
在下一篇文章中,我们将进一步探索这套架构中的"杀手锏"------渐进式 API 披露(ModuleTracker)与多 Agent 协同流转,看葡萄城是如何通过状态机机制,在面对成百上千个复杂的 SpreadJS API 时,彻底消灭大模型的"认知过载"与"调用幻觉"。敬请期待!
https://gitee.com/GrapeCity/spreadjs-ai-agent