Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

第三章 Loops and Iterators(循环和迭代器)
程序通常需要处理固定或动态长度的顺序数据。作为一种主要的命令式编程语言,Python 可以轻松地使用循环实现顺序处理。一般模式是:每次通过循环时,读取存储在变量、列表、字典等中的数据,并执行相应的状态修改或 I/O 操作。 Python 中的循环令人感觉自然,并且能够完成涉及内置数据类型、容器类型和用户定义类的最常见任务。
Python 还支持迭代器,它可以采用更函数式的方法来处理任意数据流。您可以使用迭代器,而不是直接与顺序数据的存储方式进行交互,迭代器提供了隐藏细节的通用抽象。迭代器可以使程序更高效、更容易重构,并且能够处理任意大小的数据。Python 还包含将迭代器组合在一起并使用生成器完全自定义其行为的功能(更多内容请参阅第六章 "推导式和生成器")。
Item 21:迭代参数时做好预备
当某个函数以对象列表作为参数时,通常有必要对该列表进行多次遍历。例如,假设我想要分析美国德克萨斯州境内的旅游人数。假设数据集为各城市游客数量(以百万计,每年)。我希望能够计算出每个城市在整体旅游中所占的比例。
为此,我需要一种归一化函数,它能汇总各项输入数据以确定每年游客的总体数量,然后分别将每个城市的游客人数除以总数,从而得出该城市对整个总量的贡献:
def normalize(numbers):
total = sum(numbers)
result = []
for value in numbers:
percent = 100 * value / total
result.append(percent)
return result当给定访问列表时,此函数将按预期执行:
visits = [15, 35, 80]
percentages = normalize(visits)
print(percentages)
assert sum(percentages) == 100.0
>>>
[11.538461538461538, 26.923076923076923, 61.53846153846154]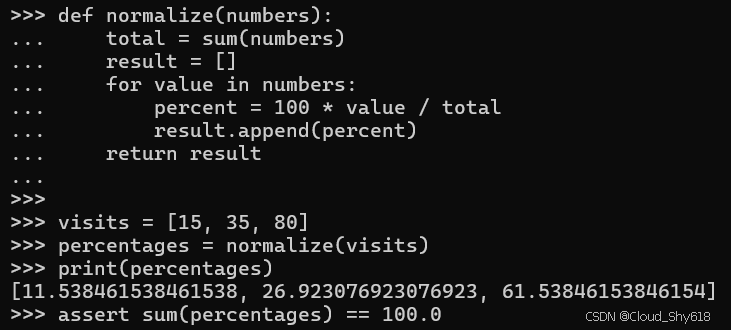
为了扩大规模,我需要从包含德克萨斯州所有城市的文件中读取数据。我定义了一个生成器来完成这项工作,因为这样我以后就可以重复使用相同的函数,当我想要计算全球范围内的旅游数据时------这是一个规模大得多、且对内存需求更高的数据集(详见 Item 43:"考虑使用生成器而非返回列表"以了解详情)
# 第一段代码来源于发布于 Github 上的 effective Python 的代码库,后续直接附上连接。
# https://github.com/bslatkin/effectivepython/blob/main/example_code/item_021.py
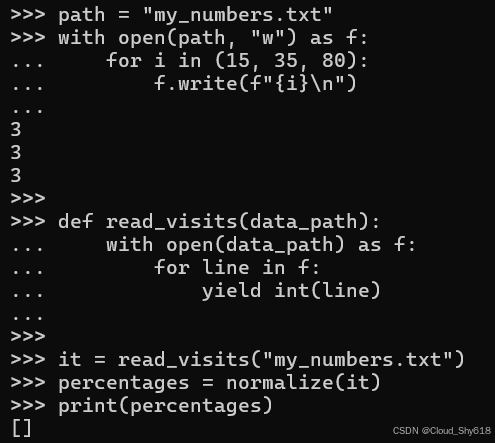
path = "my_numbers.txt"
with open(path, "w") as f:
for i in (15, 35, 80):
f.write(f"{i}\n")
def read_visits(data_path):
with open(data_path) as f:
for line in f:
yield int(line)意外的是,对 read_visits 生成器的返回值调用 normalizeon 并不会产生任何结果:
it = read_visits("my_numbers.txt")
percentages = normalize(it)
print(percentages)
>>>
[]
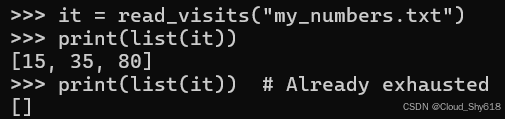
这种行为之所以会出现,是因为迭代器仅会一次性生成其结果。如果你对已引发 Stop 迭代异常的迭代器或生成器进行遍历操作,那么第二次循环时你将无法获得任何结果:
it = read_visits("my_numbers.txt")
print(list(it))
print(list(it)) # Already exhausted
>>>
[15, 35, 80]
[]
令人困惑的是,当你遍历一个已用尽的迭代器时,并不会引发异常。for 循环、列表构造器以及 Python 标准库中众多其他函数都期望在正常运行过程中能引发 Stop 迭代异常。这些函数无法区分一个没有输出的迭代器与一个曾有过输出、如今已用尽的迭代器之间的差异。
为解决这一问题,您可以显式遍历一个输入迭代器,并将其全部内容复制到一个列表中保存。之后,您可以根据需要多次遍历该数据在列表中的形式。以下是与之前相同的函数,但这次它会对输入迭代器进行防御性复制:
def normalize_copy(numbers):
numbers_copy = list(numbers) # Copy the iterator
total = sum(numbers_copy)
result = []
for value in numbers_copy:
percent = 100 * value / total
result.append(percent)
return result现在该函数在 read_visits 生成器的返回值上运行正常:
it = read_visits("my_numbers.txt")
percentages = normalize_copy(it)
print(percentages)
assert sum(percentages) == 100.0
>>>
[11.538461538461538, 26.923076923076923, 61.53846153846154]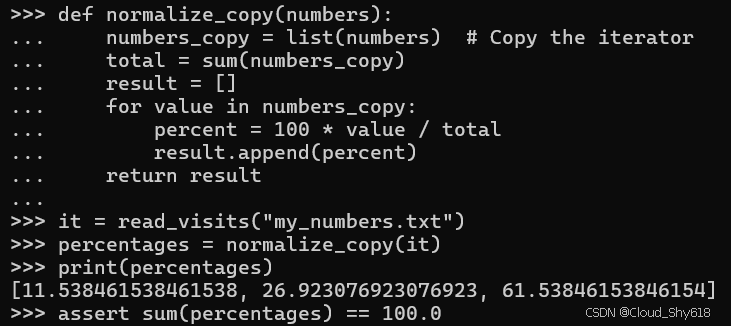
这种方法的问题在于,输入迭代器内容的副本可能极其庞大。复制迭代器可能会导致程序耗尽内存并崩溃(请参阅 Item 115:"使用 tracemalloc 理解内存使用情况与泄漏" 以了解如何进行调试)。这种潜在的扩展性问题削弱了当初我选择将 read_visits 编写为生成器的原因。解决此问题的方法之一是接受一个每次被调用时都会返回新迭代器的函数:
def normalize_func(get_iter):
total = sum(get_iter()) # New iterator
result = []
for value in get_iter(): # New iterator
percent = 100 * value / total
result.append(percent)
return result要使用 normalize_func 函数,我可以通过传递一个 lambda 表达式来实现,该表达式每次被调用时都会生成一个新的生成器迭代器:
path = "my_numbers.txt"
percentages = normalize_func(lambda: read_visits(path))
print(percentages)
assert sum(percentages) == 100.0
>>>
[11.538461538461538, 26.923076923076923, 61.53846153846154]
尽管这种做法可行,但不得不像这样传递一个 lambda 函数显得颇为笨拙。实现相同效果的一种更佳方式,是定义一个新的容器类,该类需实现迭代器协议。
Python for 循环和相关表达式使用迭代器协议来遍历容器类型的内容。当 Python 看到像 for x in foo 这样的语句时,它实际上调用 iter(foo) 来发现要循环的迭代器。 iter 内置函数依次调用 foo.__iter__ 特殊方法。 __iter__ 方法必须返回一个迭代器对象(它本身实现 __next__ 特殊方法)。 然后,for 循环重复调用迭代器对象上的 next 内置函数,直到耗尽(如引发 Stop Iteration 异常所示)。
这听起来颇为复杂,但实际操作中,你可以通过将 __iter__ 方法实现为生成器的方式,来为你的类启用所有这些功能。在此处,我定义了一个可迭代容器类,该类会读取包含旅游数据的相关文件,并使用 yield 语句逐次生成一行数据。
class ReadVisits:
def __init__(self, data_path):
self.data_path = data_path
def __iter__(self):
with open(self.data_path) as f:
for line in f:
yield int(line) 这种新型容器类型无需任何修改即可被传递至原有函数中:
visits = ReadVisits(path)
percentages = normalize(visits) # Changedprint(percentages)
assert sum(percentages) == 100.0
>>>
[11.538461538461538, 26.923076923076923, 61.53846153846154]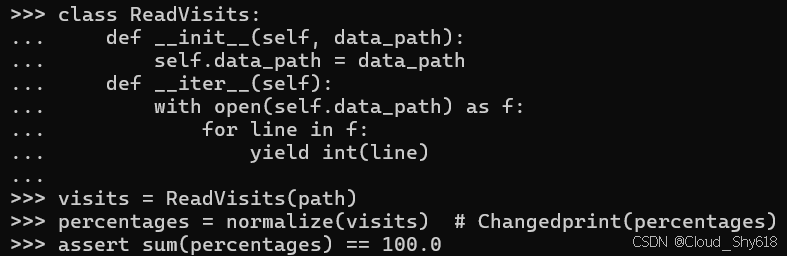
这种方法之所以可行,是因为 normalize 中的 sum 方法会调用 ReadVisits.__iter__ 来分配一个新的迭代器对象。用于对数据进行归一化的 for 循环同样会调用 __iter__ 来分配第二个迭代器对象。这些迭代器中的每一个都会独立地进行推进和遍历,从而确保每次独特的迭代都能遍历到所有输入数据值。这种方法的唯一缺点在于它会多次读取输入数据。
现在你已了解像 ReadVisits 这样的容器是如何运作的,便可以编写相应的函数和方法,以确保参数并非仅仅是迭代器。协议规定,当迭代器被传递给内置函数 iter 时,iter 会返回该迭代器本身。相比之下,当容器类型被传递给 iter 时,每次都会返回一个新的迭代器对象。因此,你可以对这种行为进行测试,并抛出 TypeError 异常,以拒绝那些无法被重复遍历的参数。
def normalize_defensive(numbers):
if iter(numbers) is numbers: # An iterator -- bad!
raise TypeError("Must supply a container")
total = sum(numbers)
result = []
for value in numbers:
percent = 100 * value / total
result.append(percent)
return result此外,collections.abc 内置模块定义了一个名为 Iterator 的类,该类可用于进行 isinstance 测试,以识别潜在的问题(参见 Item 57:"为自定义容器类型继承自 collections.abc 类")
from collections.abc import Iterator
def normalize_defensive(numbers):
if isinstance(numbers, Iterator): # Another way to check
raise TypeError("Must supply a container")
total = sum(numbers)
result = []
for value in numbers:
percent =100 * value / total
result.append(percent)
return result采用预备一个容器的方法非常理想,尤其是当你不想复制完整的输入迭代器------就像上面提到的 normalize_copy 函数那样------但同时也需要多次遍历输入数据时。在此处,我展示了 normalize_defensive 函数如何能够接受一个列表、一个 ReadVisit 对象,或者理论上任何遵循迭代器协议的数据容器:
visits_list = [15, 35, 80]
list_percentages = normalize_defensive(visits_list)
visits_obj = ReadVisits(path)
obj_percentages = normalize_defensive(visits_obj)
assert list_percentages == obj_percentages
assert sum(percentages) == 100.0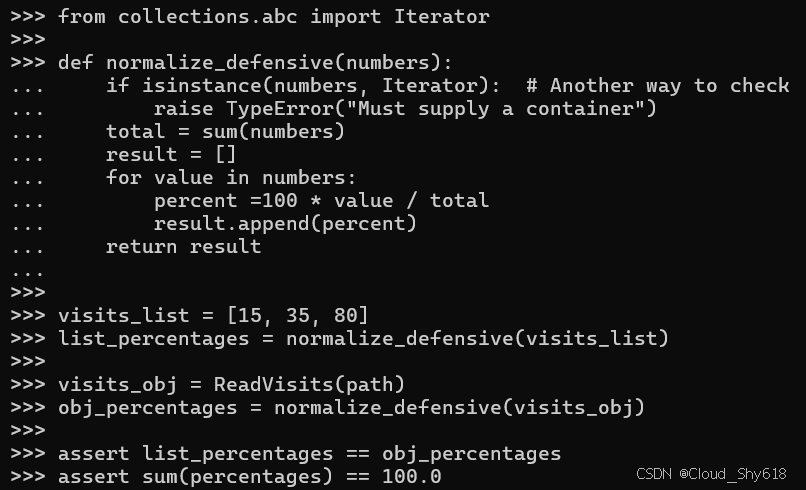
normalize_defensive 函数如果接收到的是迭代器而非容器时,会抛出一个异常:
visits = [15, 35, 80]
it = iter(visits)
normalize_defensive(it)
>>>
Traceback ...
TypeError: Must supply a container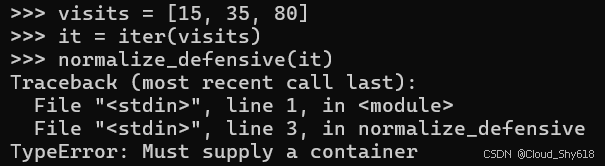
检查是否遵循迭代器协议这一方法同样适用于异步迭代器(有关示例,请参阅 Item 76:"学会如何将线程式 I/O 移植到 asyncio 中")。
注意:
- 请注意多次迭代输入参数的函数和方法。 如果这些参数是迭代器,您可能会看到奇怪的行为和缺失值。
- Python 的迭代器协议定义了容器和迭代器如何与 iter 和 next 内置函数、for 循环和相关表达式交互。
- 您可以通过将
__iter__方法实现为生成器来轻松定义自己的可迭代容器类型。 - 如果调用 iter 生成的值与您传入的值相同,您可以检测到该值是迭代器(而不是容器)。或者,您可以将 isinstance 内置函数与 collections.abc 迭代器类一起使用。
Item 22:迭代容器时切勿修改容器;使用副本或缓存代替
Python 中存在许多由令人意外的迭代行为引起的陷阱(有关另一种常见情况,请参阅 Item 21:"迭代参数时做好预备")。例如,如果在迭代字典时向字典中添加新项目,Python 将引发运行时异常:
search_key = "red"
my_dict = {"red": 1, "blue": 2, "green": 3}
for key in my_dict:
if key == "blue":
my_dict["yellow"] = 4 # Causes error
>>>
Traceback ...
RuntimeError: dictionary changed size during iteration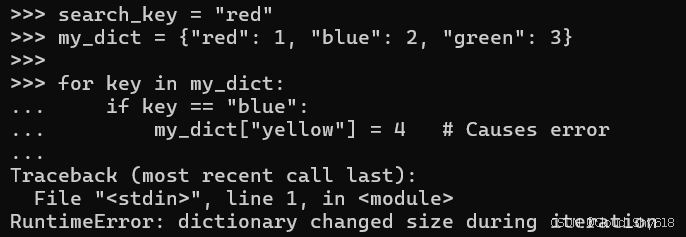
如果您在迭代字典时从字典中删除某个项目,则会出现类似的错误:
for key in my_dict:
if key == "blue":
del my_dict["green"] # Causes error
>>>
Traceback ...
RuntimeError: dictionary changed size during iteration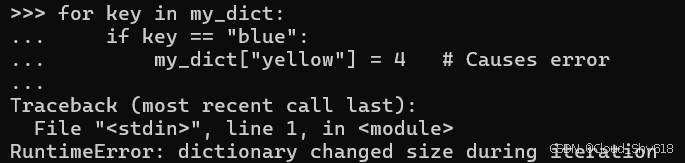
如果您不从字典中添加或删除键,而只更改它们的关联值,则不会发生错误,这与上面的行为惊人地不一致:
for key in my_dict:
if key == "blue":
my_dict["green"] = 4 # Okay
print(my_dict)
>>>
{'red': 1, 'blue': 2, 'green': 4}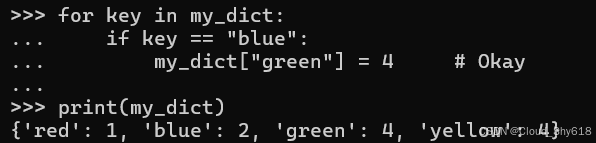
集合的工作方式与字典类似,如果您在迭代期间通过添加或删除项目来更改其大小,则会在运行时遇到异常:
my_set = {"red", "blue", "green"}
for color in my_set:
if color == "blue":
my_set.add("yellow") # Causes error
>>>
Traceback ...
RuntimeError: Set changed size during iteration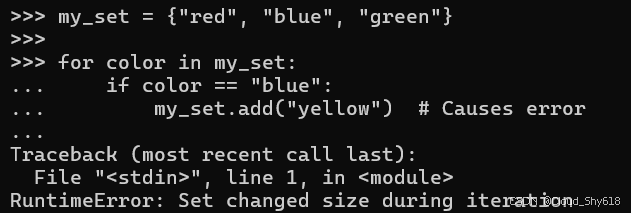
然而,set 的行为似乎也不一致,因为尝试添加集合中已存在的项目在迭代它时不会导致任何问题。允许重新添加,因为集合的大小没有改变:
my_set = {"red", "blue", "green"}
for color in my_set:
if color == "blue":
my_set.add("green") # Okay
print(my_set)
>>>
{'green', 'blue', 'red'}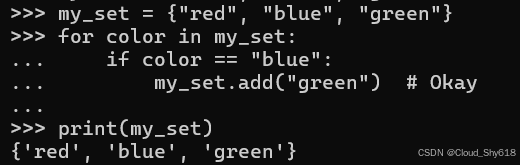
与字典非常相似,而且令人意外的是,列表可以在迭代期间覆盖任何现有索引,而不会出现任何问题:
my_list = [1, 2, 3]
for number in my_list:
print(number)
if number == 2:
my_list[0] = -1 # Okay
print(my_list)
>>>
1
2
3
[-1, 2, 3]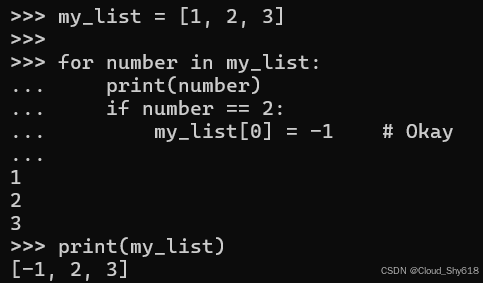
但是,如果您尝试在当前迭代器位置之前将元素插入列表中,您的代码将陷入无限循环:
my_list = [1, 2, 3]
for number in my_list:
print(number)
if number == 2:
my_list.insert(0, 4) # Causes error
>>>
1
2
2
2
2
2
...
然而,在当前迭代器位置之后附加到列表并不是问题------基于索引的迭代器还没有达到那么远------这又是令人意外的不一致行为:
my_list = [1, 2, 3]
y_list = [1, 2, 3]
for number in my_list:
print(number)
if number == 2:
my_list.append(4) # Okay this time
print(my_list)
>>>
1
2
3
4
[1, 2, 3, 4]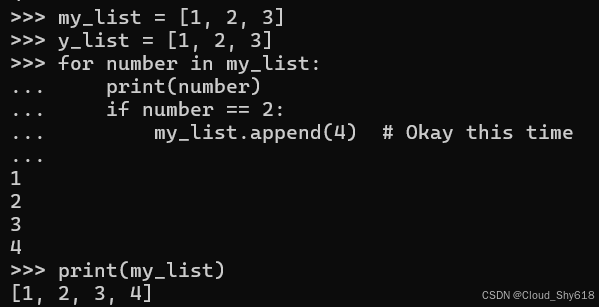
查看上面的每个示例,很难猜测代码是否在所有情况下都有效。在修改点根据算法输入而变化的情况下,在迭代期间修改容器尤其容易出错。在某些情况下它会起作用,而在其他情况下则会出现错误。因此,我的建议是在迭代容器时永远不要修改容器。
如果由于算法的性质,您仍然需要在迭代期间进行修改,则只需复制要迭代的容器并将修改应用于原始容器(请参阅 Item 30:"知道函数参数可以改变")。例如,使用字典我可以复制键:
my_dict = {"red": 1, "blue": 2, "green": 3}
keys_copy = list(my_dict.keys()) # Copy
for key in keys_copy: # Iterate over copy
if key == "blue":
my_dict["green"] = 4 # Modify original dict
print(my_dict)
>>>
{'red': 1, 'blue': 2, 'green': 4}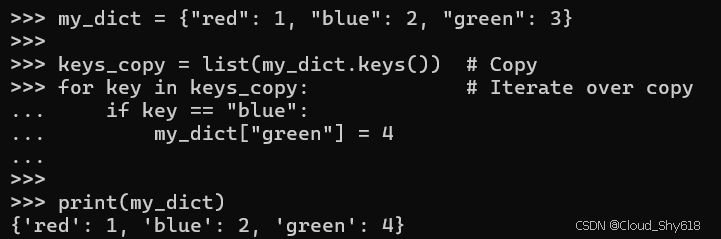
对于列表,我可以复制整个容器:
my_list = [1, 2, 3]
list_copy = list(my_list) # Copy
for number in list_copy: # Iterate over copy
print(number)
if number == 2:
my_list.insert(0, 4) # Inserts in original list
print(my_list)
>>>
1
2
3
[4, 1, 2, 3]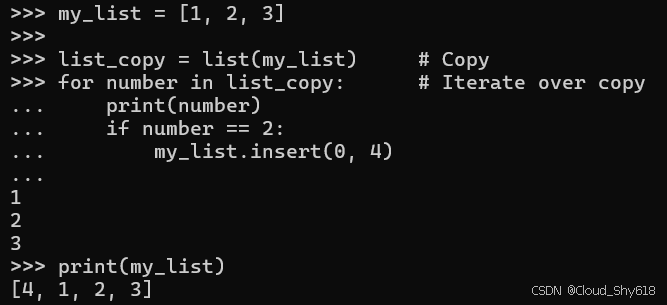
同样的方法也适用于集合:
my_set = {"red", "blue", "green"}
set_copy = set(my_set) # Copy
for color in set_copy: # Iterate over copy
if color == "blue":
my_set.add("yellow") # Add to original set
print(my_set)
>>>
{'yellow', 'green', 'blue', 'red'}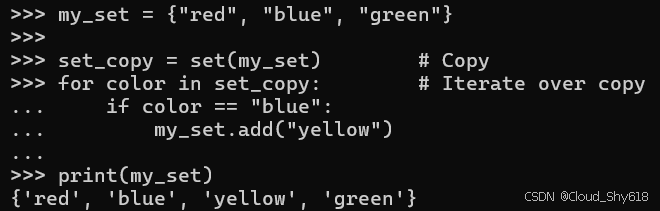
注意:集合里颜色的位置顺序不一样是正常的。
对于一些非常大的容器,复制可能太慢(请参阅 Item 92:"优化前的配置文件" 以验证您的假设)。处理性能不佳的一种方法是将修改暂存在单独的容器中,然后在迭代后将更改合并到主数据结构中。例如,这里我修改了一个单独的字典,然后使用 update 方法将更改带入原始字典中:
my_dict = {"red": 1, "blue": 2, "green": 3}
modifications = {}
for key in my_dict:
if key == "blue":
modifications["green"] = 4 # Add to staging
my_dict.update(modifications) # Merge modifications
print(my_dict)
>>>
{'red': 1, 'blue': 2, 'green': 4}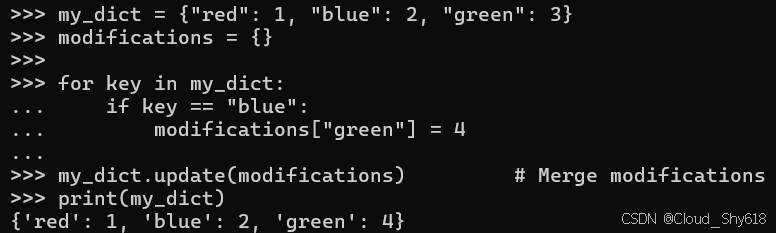
暂存修改的问题 在于,它们在迭代期间不会立即在原始容器中可见。如果循环中的逻辑依赖于立即可见 的修改,则代码将无法按预期工作。例如,这里程序员的意图可能是使 "yellow" 出现在结果字典中,但它不会出现在那里,因为修改在迭代期间不可见:
my_dict = {"red": 1, "blue": 2, "green": 3}
modifications = {}
for key in my_dict:
if key == "blue":
modifications["green"] = 4
value = my_dict[key]
if value == 4: # This condition is never true
modifications["yellow"] = 5
my_dict.update(modifications) # Merge modifications
print(my_dict)
>>>
{'red': 1, 'blue': 2, 'green': 4}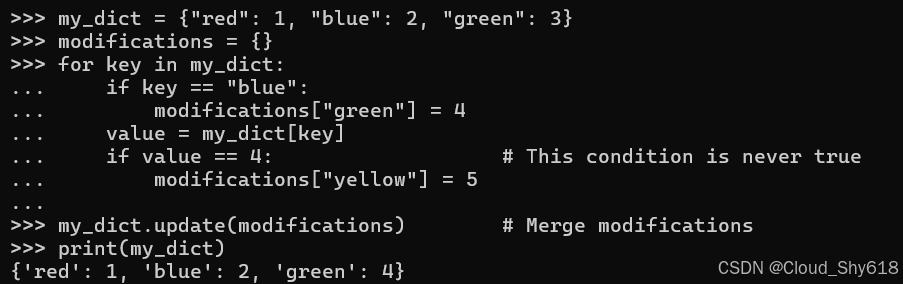
可以通过在迭代期间查看原始容器 (my_dict) 和修改容器 (modifications) 中的最新值来修复此代码,本质上将临时字典视为中间缓存:
my_dict = {"red": 1, "blue": 2, "green": 3}
modifications = {}
for key in my_dict:
if key == "blue":
modifications["green"] = 4
value = my_dict[key]
other_value = modifications.get(key) # Check cache
if value == 4 or other_value == 4:
modifications["yellow"] = 5
my_dict.update(modifications) # Merge modifications
print(my_dict)
>>>
{'red': 1, 'blue': 2, 'green': 4, 'yellow': 5}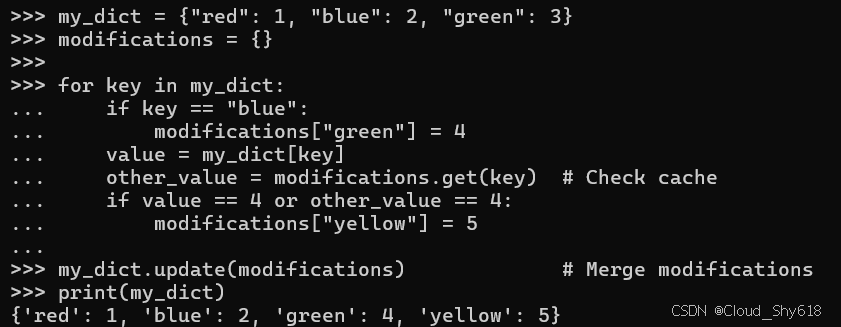
这种类型的和解是有效的,但很难推广到所有情况。在开发这样的算法时,您需要考虑特定的约束。这可能很难做到正确,特别是对于所有边缘情况,因此我建议编写自动化测试来验证正确性(请参阅 Item 109:"优先选择集成测试而不是单元测试")。同样,您可以使用微基准来衡量各种方法的性能并选择最佳的一种(请参阅 Item 93:"使用 timeit 微基准优化性能关键代码")。
注意:
- 在迭代列表、字典和集合时添加或删除元素可能会导致通常难以预测的运行时错误。
- 您可以迭代容器的副本,以避免迭代过程中可能因突变而导致的运行时错误。
- 如果您需要避免复制以获得更好的性能,您可以在第二个容器缓存中暂存修改,然后将其合并到原始容器缓存中。
Item 23:将迭代器传递给 any 和 all 以实现高效的短路逻辑
Python 是构建逻辑推理程序的绝佳语言。例如,假设我正在尝试分析抛硬币的本质。我可以定义一个函数,每次调用时都会返回随机的硬币翻转结果------正面为 True,反面为 False:
import random
def flip_coin():
if random.randint(0, 1) == 0:
return"Heads"
else:
return"Tails"
def flip_is_heads():
return flip_coin() == "Heads"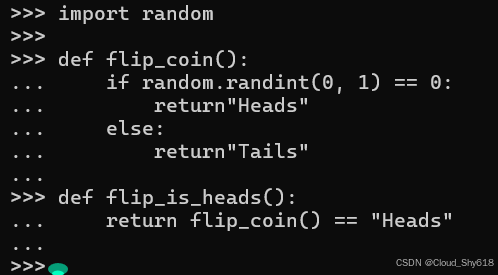
如果我想掷硬币 20 次并查看每个结果是否连续正面,我可以使用简单的列表推导式(请参阅 Item 40:"使用推导式而不是 map 和过滤器")和使用 inoperator 进行隶属测试(请参阅 Item 57:"从自定义容器类型的 collections.abc 类继承"):
flips = [flip_is_heads() for _ in range(20)]
all_heads = False not in flips然而,这 20 次抛硬币的序列只产生正面的概率大约是百万分之一------极其罕见。如果抛硬币的成本很高,那么我几乎总是会在列表理解中浪费大量资源进行不必要的工作,因为即使在看到反面结果后,它也会继续抛硬币。 我可以通过使用一个循环来改善这种情况,该循环一旦看到非正面结果就终止硬币翻转序列:
all_heads = True
for _ in range(100):
if not flip_is_heads():
all_heads = False
break虽然这段代码更高效,但它比之前的列表理解要长得多。为了保持代码简短,同时提前结束执行,我可以使用 all 内置函数。所有步=步骤通过迭代器,检查每个项目是否为真(有关背景,请参阅 Item 7:考虑简单内联逻辑的条件表达式),如果不是,则立即停止处理。all 始终返回 True 或 False 的布尔值,这与 andl 逻辑运算符返回最后测试的值的方式不同:
print("All truthy:")
print(all([1, 2, 3]))
print(1 and 2 and 3)
print("One falsey:")
print(all([1, 0, 3]))
print(1 and 0 and 3)
>>>
All truthy:
True
3
One falsey:
False
0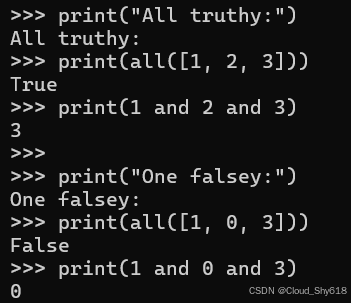
使用 all 内置函数,我可以使用生成器表达式重写硬币翻转循环(请参阅 Item 44:"考虑大型列表推导式的生成器表达式")。 一旦 flip_is_heads 函数返回 False,它将停止进行更多的硬币翻转:
all_heads = all(flip_is_heads() for _ in range(20))至关重要的是,如果我传递列表推导式而不是生成器表达式(请注意周围 和 方括号的存在),代码将创建一个包含 20 个硬币翻转结果的列表,然后再将它们传递给 all 函数。计算结果将是相同的,但代码的性能会差得多:
all_heads = all([flip_is_heads() for _ in range(20)]) # Wrong或者,我可以使用生成的生成器函数(请参阅 Item 43:"考虑生成器而不是返回列表")或任何其他类型的迭代器来实现类似的效率:
def repeated_is_heads(count):
for _ in range(count):
yield flip_is_heads() # Generator
all_heads = all(repeated_is_heads(20))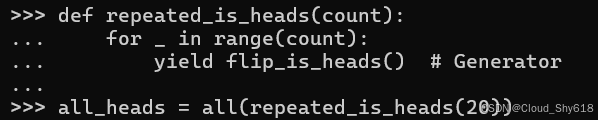
一旦 repeated_is_heads 函数产生一个 False 值,all 内置函数将停止向前移动生成器迭代器并返回 False。传递给 all 的生成器迭代器的引用将被丢弃并被垃圾回收,确保循环永远不会完成(有关详细信息,请参阅 Item 89:"始终将资源传递到生成器并让调用者在外部清理它们")。
有时,您会拥有一个与 flip_is_heads 行为方式相反的函数,大多数情况下返回 False,仅在满足特定条件时返回 True。 在这里,定义了一个具有以下行为的函数:
def flip_is_tails():
return flip_coin() == "Tails"为了使用这个功能来检测连续的磁头,all 是无用的。 相反,可以使用 any 内置函数。 any 看似逐步执行迭代器,但它在看到第一个真值时终止。 any 总是返回一个布尔值,与它镜像的 or 逻辑运算符不同:
print("All falsey:")
print(any([0, False, None]))
print(0 or False or None)
print("One truthy:")
print(any([None, 3, 0]))
print(None or 3 or 0)
>>>
All falsey:
False
None
One truthy:
True
3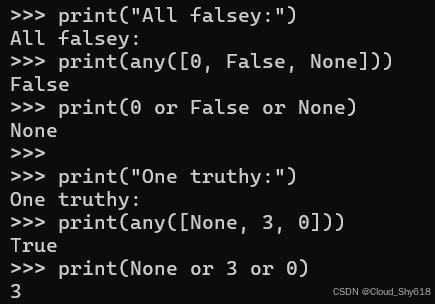
对于 any,可以在生成器表达式中使用 flip_is_tails 来计算与以前相同的结果:
all_heads = not any(flip_is_tails() for _ in range(20))或者可以创建一个类似的生成器函数:
def repeated_is_tails(count):
for _ in range(count):
yield flip_is_tails()
all_heads = not any(repeated_is_tails(20))那么什么时候应该选择 any 或 all?这取决于您正在做什么以及测试您关心的条件的难度。如果您想以 True 值提前结束,请使用 any。如果您想以 False 值提前结束,请使用 all。最终,这些内置函数是等效的,正如布尔逻辑的德摩根定律所证明的那样:
for a in(True, False):
for b in(True, False):
assert any([a, b]) == (not all([not a, not b]))
assert all([a, b]) == (not any([not a, not b]))无论如何,您应该能够找到一种方法,通过适当地使用 "any" 或 "all" 来最大程度地减少所做的工作量。还有其他内置模块,用于以智能方式操作迭代器和生成器,以最大限度地提高性能和效率(请参阅 Item 24:"考虑使用 itertools 来使用迭代器和生成器")。
注意:
- 如果提供的所有项均为真,则 all 内置函数返回 True。一旦遇到 false 项,它就会停止处理输入并返回 False。
- any 内置函数的工作原理类似,但逻辑相反:如果所有项均为 false,则返回 False,一旦看到 true 值,它就会提前以 True 结束。
- any 和 all 始终返回布尔值 True 或 False,与 or 和 and 逻辑运算符不同,后者返回需要测试的最后一项。
- 在列表推导式中使用 any 或 all 而不是在生成器表达式中使用会破坏这两个函数的效率优势。
Item 24:考虑使用 itertools 来使用迭代器和生成器
itertools 内置模块包含大量可用于组织迭代器和与迭代器交互的函数(有关信息,请参阅 Item 43:"考虑生成器而不是返回列表"和 Item 21:"在迭代参数时做好预备"):
import itertools每当您发现自己正在处理棘手的迭代代码时,都值得再次查看 itertools 文档,看看其中是否有任何内容可供您使用(请参阅 https://docs.python.org/3/library/itertools.html)。以下部分描述了您应该了解的三个主要类别中最重要的功能。
将迭代器链接在一起
itertools 内置模块包含许多用于将迭代器链接在一起的函数。
chain
it = itertools.chain([1, 2, 3], [4, 5, 6])
print(list(it))
>>>
[1, 2, 3, 4, 5, 6]
该函数还有一个替代版本,chain.from_iterable,它使用迭代器的迭代器并生成一个包含迭代器所有内容的扁平化输出迭代器:
it1 = [i * 3 for i in ("a", "b", "c")]
it2 = [j * 2 for j in ("x", "y", "z")]
nested_it = [it1, it2]
output_it = itertools.chain.from_iterable(nested_it)
print(list(output_it))
>>>
['aaa', 'bbb', 'ccc', 'xx', 'yy', 'zz']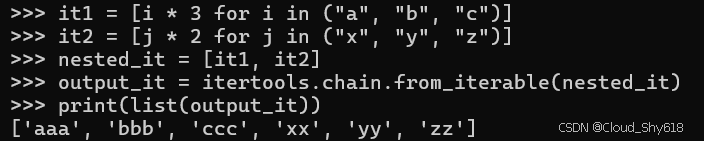
repeat
使用 repeat 永久输出单个值或使用第二个可选参数指定最大次数:
it = itertools.repeat("hello", 3)
print(list(it))
>>>
['hello', 'hello', 'hello']
cycle
使用 cycle 永远重复迭代器的项目:
it = itertools.cycle([1, 2])
result = [next(it) for _ in range(10)]
print(result)
>>>
[1, 2, 1, 2, 1, 2, 1, 2, 1, 2]
tee
使用 tee 将单个迭代器拆分为第二个参数指定数量的并行迭代器。如果迭代器不以相同的速度前进,则该函数的内存使用量将会增加,因为需要缓冲来临时存储待处理的项目:
it1, it2, it3 = itertools.tee(["first", "second"], 3)
print(list(it1))
print(list(it2))
print(list(it3))
>>>
['first', 'second']
['first', 'second']
['first', 'second']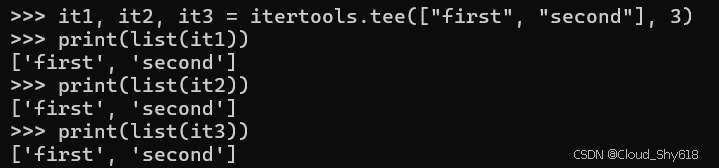
zip_longest
当迭代器耗尽时,zip 内置函数的变体返回一个占位符值,如果迭代器具有不同的长度,则可能会发生这种情况(请参阅 Item 18:"并行使用 zip 处理迭代器",了解 strict 参数如何提供类似的行为):
keys = ["one", "two", "three"]
values = [1, 2]
normal = list(zip(keys, values))
print("zip: ", normal)
it = itertools.zip_longest(keys, values, fillvalue="nope")
longest = list(it)
print("zip_longest:", longest)
>>>
zip: [('one', 1), ('two', 2)]
zip_longest: [('one', 1), ('two', 2), ('three', 'nope')]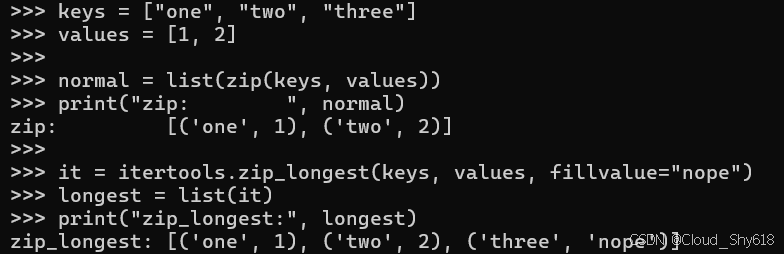
从迭代器中过滤项目
itertools 内置模块包含许多用于从迭代器中过滤项目的函数。
islice
使用 islice 按数字索引对迭代器进行切片而不进行复制。您可以指定结束、开始和结束,或者开始、结束和步长。 islice 的行为与标准序列切片和跨步的行为类似(请参阅 Item 14:"了解如何切片序列"和 Item 15:"避免在单个表达式中跨步和切片"):
values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
first_five = itertools.islice(values, 5)
print("First five: ", list(first_five))
middle_odds = itertools.islice(values, 2, 8, 2)
print("Middle odds:", list(middle_odds))
>>>
First five: [1, 2, 3, 4, 5]
Middle odds: [3, 5, 7]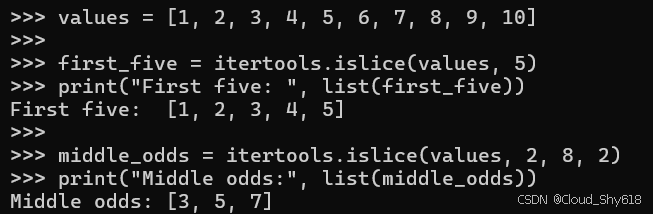
takewhile
takewhile 从迭代器中返回项目,直到谓词函数为某个项目返回 False,此时迭代器中的所有项目都将被消耗但不会返回(有关定义谓词的更多信息,请参阅 Item 39:"在粘合函数中首选 functools.partialover lambda 表达式"):
values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
less_than_seven = lambda x: x < 7
it = itertools.takewhile(less_than_seven, values)
print(list(it))
>>>
[1, 2, 3, 4, 5, 6]
dropwhile
dropwhile 与 takewhile 相反,它会跳过迭代器中的项目,直到谓词函数第一次返回 False,此时将返回迭代器中的所有项目:
values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
less_than_seven = lambda x: x <7
it = itertools.dropwhile(less_than_seven, values)
print(list(it))
>>>
[7, 8, 9, 10]
filterfalse
filter false 与 filter 内置函数相反,当谓词函数返回 False 时,它返回迭代器中的所有项目:
values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
evens = lambda x: x % 2 == 0
filter_result = filter(evens, values)
print("Filter: ", list(filter_result))
filter_false_result = itertools.filterfalse(evens, values)
print("Filter false:", list(filter_false_result))
>>>
Filter: [2, 4, 6, 8, 10]
Filter false: [1, 3, 5, 7, 9]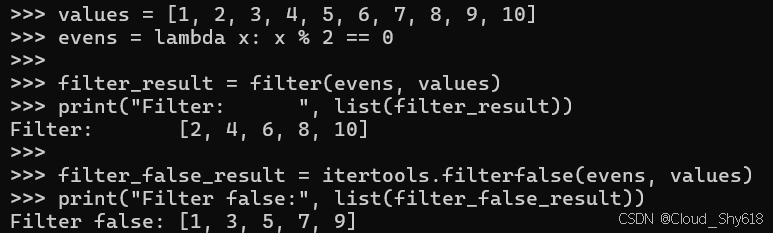
从迭代器生成项的组合
itertools 内置模块包含许多用于从迭代器生成项目组合的函数。
batched
使用批处理创建一个迭代器,该迭代器从单个输入迭代器输出固定大小、不重叠的项目组。第二个参数是批量大小。当一起处理数据以提高效率或满足其他约束(例如数据大小限制)时,这尤其有用:
it = itertools.batched([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
print(list(it))
>>>
[(1, 2, 3), (4, 5, 6), (7, 8, 9)]如果条目不能完美划分,则迭代器生成的最后一个组可能小于指定的批量大小:
it = itertools.batched([1, 2, 3], 2)
print(list(it))
>>>
[(1, 2), (3,)]pairwise
当您需要迭代输入迭代器中的每对相邻项时,请使用 pairwise。这些对包括重叠,因此除了末端之外的每个项目在输出迭代器中出现两次:一次在一对的第一个位置,另一次在第二个位置。当编写需要逐步遍历连续的顶点或端点集的图遍历算法时,这会很有帮助:
route = ["Los Angeles", "Bakersfield", "Modesto", "Sacramento"]
it = itertools.pairwise(route)
print(list(it))
>>>
[('Los Angeles', 'Bakersfield'), ('Bakersfield', 'Modesto'), ('Modesto', 'Sacramento')]
accumulate
通过应用带有两个参数的函数,accumulate 将迭代器中的一项折叠为运行值。 它输出每个输入值的当前累积结果:
values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
sum_reduce = itertools.accumulate(values)
print("Sum: ", list(sum_reduce))
def sum_modulo_20(first, second):
output = first + second
return output % 20
modulo_reduce = itertools.accumulate(values, sum_modulo_20)
print("Modulo:", list(modulo_reduce))
>>>
Sum: [1, 3, 6, 10, 15, 21, 28, 36, 45, 55]
Modulo: [1, 3, 6, 10, 15, 1, 8, 16, 5, 15]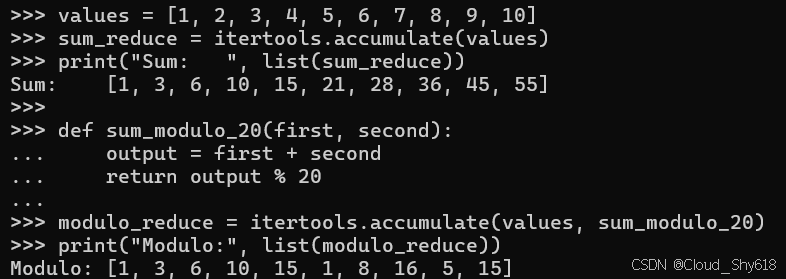
这本质上与 functools 内置模块中的 reduce 函数相同,但输出一次生成一个步骤。默认情况下,如果未指定二元函数,它将对输入求和。
product
Product 返回来自一个或多个迭代器的项目的笛卡尔积,这是使用深层嵌套列表推导式的一个很好的替代方案(请参阅 Item 41:"在推导式中避免两个以上的控制子表达式"了解为什么要避免这些):
single = itertools.product([1, 2], repeat=2)
print("Single: ", list(single))
multiple = itertools.product([1, 2], ["a", "b"])
print("Multiple:", list(multiple))
>>>
Single: [(1, 1), (1, 2), (2, 1), (2, 2)]
Multiple: [(1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')]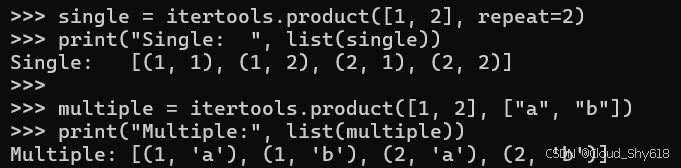
permutations
permutations 返回长度为 N(第二个参数)的唯一有序排列,其中包含来自迭代器的项:
it = itertools.permutations([1, 2, 3, 4], 2)
print(list(it))
>>>
[(1, 2),
(1, 3),
(1, 4),
(2, 1),
(2, 3),
(2, 4),
(3, 1),
(3, 2),
(3, 4),
(4, 1),
(4, 2),
(4, 3)]
combinations
组合返回长度为 N(第二个参数)的无序组合,其中包含来自迭代器的不重复项:
it = itertools.combinations([1, 2, 3, 4], 2)
print(list(it))
>>>
[(1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)]
combinations_with_replacement
combinations_with_replacement 与 combinations 相同,但允许重复值。此函数与排列函数之间的区别在于,此版本允许相同的输入在输出组中重复多次(即,请参阅下面输出中的 (1, 1)):
it = itertools.combinations_with_replacement([1, 2, 3, 4], 2)
print(list(it))
>>>
[(1, 1),
(1, 2),
(1, 3),
(1, 4),
(2, 2),
(2, 3),
(2, 4),
(3, 3),
(3, 4),
(4, 4)]
注意:
- 用于处理迭代器和生成器的 itertools 函数主要分为三类:将迭代器连接起来、筛选它们所输出的项以及生成项的组合。
- 官方文档中还提供了更为高级的功能、额外的参数以及实用的范例。