机器人视频世界模型(Robot Video World Model)是当前具身智能领域的核心技术。它的作用是让机器人在不真正执行动作的情况下,基于视觉观测与动作序列预测未来的场景变化 ,从而在 "想象" 中完成规划、推理与决策。相比于通用的视频生成,机器人世界模型有着更严格的要求:生成画面必须遵循指令、动作合理、接触真实、物理可信,否则无法用于真实机器人控制。
然而,现有的机器人世界模型研究普遍面临三个难以解决的核心问题,严重制约落地能力。
第一,训练目标与实际决策需求严重错位。当前绝大多数模型以重建损失、感知相似度(如 MSE、LPIPS)或最大似然估计作为训练目标,只关注像素与特征层面的统计相似性,完全不考虑任务是否完成、动作是否正确、物体接触是否合理。这导致模型经常出现 "画面清晰、任务失败、物理失真" 的现象,看似生成质量高,却完全无法用于决策。部分研究尝试使用强化学习,但奖励函数依旧停留在低层视觉指标,无法实现任务对齐。
第二,长时序生成过程存在严重的误差累积。在基于 token 的自回归生成中,每一步预测都依赖前面所有时刻的输出。微小的预测偏差会随着帧数不断叠加、放大,最终导致物体漂浮、穿模、动作断裂、时序混乱。长时序规划几乎无法使用,这成为世界模型走向实用的一大障碍。
第三,精准奖励与高效训练难以兼顾。能够准确判断任务完成度与物理合理性的多模态大模型,普遍参数量大、速度慢、成本高,无法直接嵌入强化学习流程作为在线奖励;而计算高效的低层指标(MSE、SSIM 等)又无法反映任务成败与物理真实性,构成 "奖励对齐困境"。
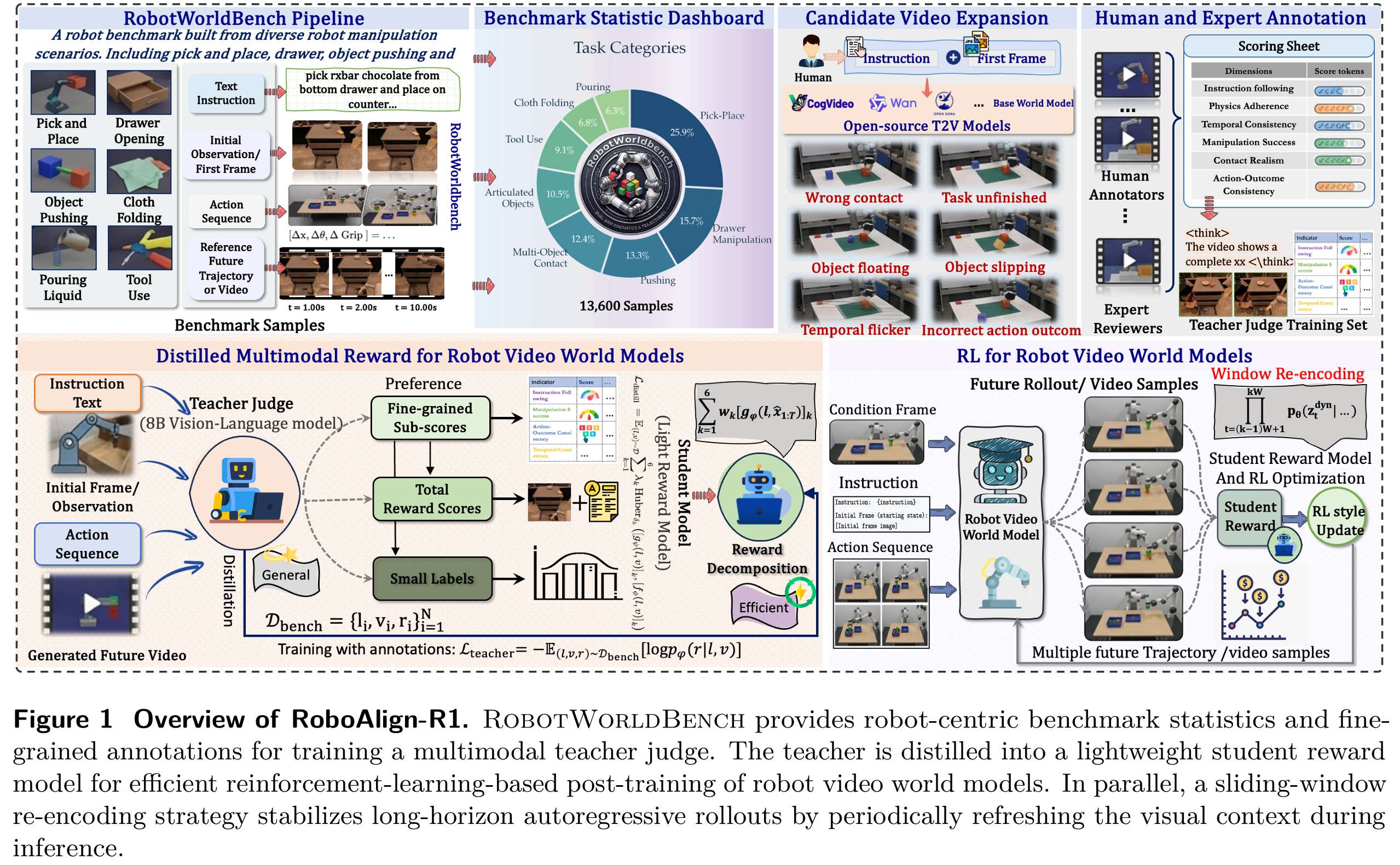
为了系统性解决以上问题,腾讯、清华大学、纽约市立大学等机构联合提出 RoboAlign-R1 框架。该框架的核心思路可以概括为两点:在训练阶段,通过多模态奖励蒸馏 实现任务与物理规则的对齐,让模型学习 "做对、做实";在推理阶段,通过滑动窗口重编码(SWR) 截断误差传播,让模型 "长时序不漂移"。同时,研究团队构建了大规模机器人评测基准 RobotWorldBench,为训练和评估提供高质量数据支撑。

实验结果表明,RoboAlign-R1 在六维度综合评分上超越最强基线 10.1%,操作准确率提升 7.5%,指令遵循提升 4.6%;SWR 策略仅增加约 1% 推理延迟,就使 SSIM 提升 2.8%、LPIPS 下降 9.8%。该工作首次实现 "对齐训练 + 稳定推理" 的完整方案,让机器人世界模型真正具备可落地、可决策、可长时序运行的能力。
主要创新方法
RoboAlign-R1 整体架构由骨干世界模型、奖励对齐后训练、滑动窗口重编码三部分组成,逻辑严密、层次清晰,形成从特征建模、目标对齐到长时序稳定的完整链条。
骨干网络:Token 化机器人视频世界模型
RoboAlign-R1 以Tokenize--Predict--Decode 范式为基础架构,将视觉观测与机器人动作统一建模为离散 token 序列,实现高效的时序预测。
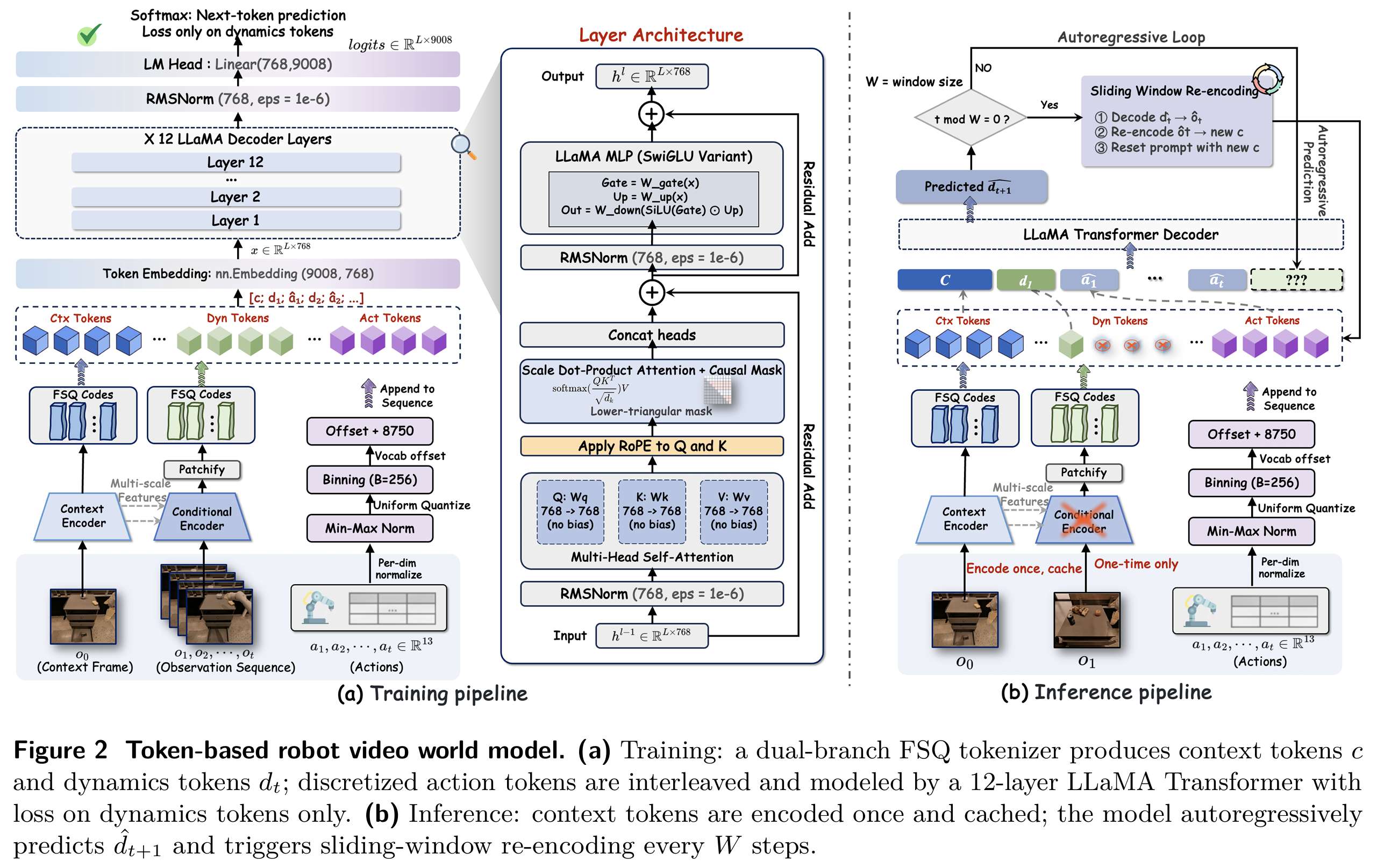
首先,模型使用双分支视觉 tokenizer 对视频进行编码。其中,上下文分支将第一帧编码为上下文 token z c t x z^{ctx} zctx,用于保留场景初始信息;动态分支将后续每一帧编码为动态 token z t d y n z_t^{dyn} ztdyn,只建模画面随时间的变化量,降低冗余信息。
同时,连续动作向量被归一化、均匀分箱,转化为离散动作 token。视觉 token 与动作 token 按照时序交错拼接,形成统一序列:
s = z c t x , z 1 d y n , a \^ 1 , z 2 d y n , a \^ 2 , ... , z T d y n , a \^ T s = \left z\^{ctx}, z_1\^{dyn}, \\hat{a}_1, z_2\^{dyn}, \\hat{a}_2, \\dots, z_T\^{dyn}, \\hat{a}_T\\right s=zctx,z1dyn,a\^1,z2dyn,a\^2,...,zTdyn,a\^T
随后,模型使用 12 层 LLaMA 结构的因果 Transformer 对序列进行建模,学习视觉与动作的联合概率分布。基础训练的损失函数为标准自回归预测损失:
L A R = − ∑ t = 1 T log p θ ( z t d y n ∣ z c t x , z < t d y n , a ^ ≤ t ) \mathcal{L}{AR} = -\sum{t=1}^{T} \log p_{\theta}\left(z_t^{dyn} \mid z^{ctx}, z_{< t}^{dyn}, \hat{a}_{\le t}\right) LAR=−t=1∑Tlogpθ(ztdyn∣zctx,z<tdyn,a^≤t)
这一骨干网络能够较好地学习视觉时序变化规律,但由于训练目标仅关注统计拟合,不具备任务与物理层面的对齐能力,因此需要后续的奖励对齐训练进行强化。
核心创新一:奖励对齐后训练(Reward-Aligned Post-Training)
奖励对齐后训练是 RoboAlign-R1 最核心的创新,其目标是让世界模型不再只是 "拟合画面",而是以任务成功、物理合理为目标进行优化。整个流程分为基准构建、教师评判训练、奖励蒸馏、强化学习后训练四个步骤。
构建机器人专用基准:RobotWorldBench
为了给奖励模型提供高质量监督信号,研究团队从 RT-1、BridgeData V2、CALVIN、LIBERO 四个主流机器人数据集中,构建了规模达 10000 条标注视频--指令对的基准数据集。每条数据包含语言指令、操控视频以及六维度细粒度标注分数:指令遵循、操作成功、动作--结果一致性、时序一致性、接触真实性、物理合理性。该基准是奖励模型训练的基础,也是模型评估的标准。
训练多模态教师评判模型:RoboAlign-Judge
以 Qwen3-VL-8B-Thinking 为基础模型,研究团队在 RobotWorldBench 上进行微调,使其能够输入指令与视频序列,输出结构化的六维评分。教师模型的训练目标为最大化标注分数的似然概率:
L t e a c h e r = − E ( l , v , r ) ∼ D b e n c h log p ϕ ( r ∣ l , v ) \mathcal{L}{teacher} = -\mathbb{E}{(l,v,r) \sim \mathcal{D}_{bench}} \left \\log p_{\\phi}(r \\mid l, v) \\right Lteacher=−E(l,v,r)∼Dbenchlogpϕ(r∣l,v)
经过微调后的 RoboAlign-Judge 具备高精度的任务理解、物理合理性判断与时序一致性评估能力,能够给出接近人类专家的细粒度评分。但由于模型体积大、推理速度慢,无法直接用于强化学习的在线奖励计算。
奖励蒸馏:轻量级学生奖励模型
为了在保持评判精度的同时提升运行效率,研究团队将 8B 参数的教师模型蒸馏为仅 98M 参数的轻量级学生奖励模型 g ψ g_ψ gψ。学生模型采用视觉--文本双编码器结构,输入指令与视频,直接输出归一化后的六维评分。
蒸馏过程使用加权 Huber 损失进行回归学习,使学生模型拟合教师模型的评分分布:
L d i s t i l l = E ( l , v ) ∑ k = 1 6 λ k Huber ( g ψ ( l , v ) k , s ~ k ( l , v ) ) \mathcal{L}{distill} = \mathbb{E}{(l,v)} \sum_{k=1}^{6} \lambda_k \operatorname{Huber}\left( g_{\psi}(l, v)_k, \tilde{s}_k(l,v) \right) Ldistill=E(l,v)k=1∑6λkHuber(gψ(l,v)k,s~k(l,v))
其中 s ~ k \tilde{s}_k s~k是教师模型输出分数经归一化后的值。蒸馏后的学生奖励模型速度达到 50 视频/秒,奖励计算成本降低 10 倍以上,能够高效嵌入强化学习流程。
GRPO 强化学习后训练
使用学生奖励模型输出的六维评分构建综合奖励函数:
R ( x ^ 1 : T ) = ∑ k = 1 6 w k ⋅ g ψ ( l , x \^ 1 : T ) k R(\hat{x}{1:T}) = \sum{k=1}^{6} w_k \cdot g_{\\psi}(l, \\hat{x}_{1:T})_k R(x^1:T)=k=1∑6wk⋅gψ(l,x\^1:T)k
模型采用 GRPO(Group Relative Policy Optimization)进行稳定的强化学习后训练,在保证生成分布与预训练模型不过度偏离的前提下,最大化综合奖励。为避免因分布偏移导致的奖励作弊问题,研究团队引入在线迭代蒸馏机制:每经过固定次数的策略更新,就使用教师模型重新对新生成的样本进行打分,更新学生奖励模型,保持奖励信号长期精准、对齐。
通过这一整套机制,世界模型从单纯的时序生成,转变为面向任务成功、物理真实的决策式预测模型。
核心创新二:滑动窗口重编码 SWR(Sliding Window Re-encoding)
SWR 是一项无需训练、低开销、即插即用的推理策略,专门解决自回归长时序误差累积问题。
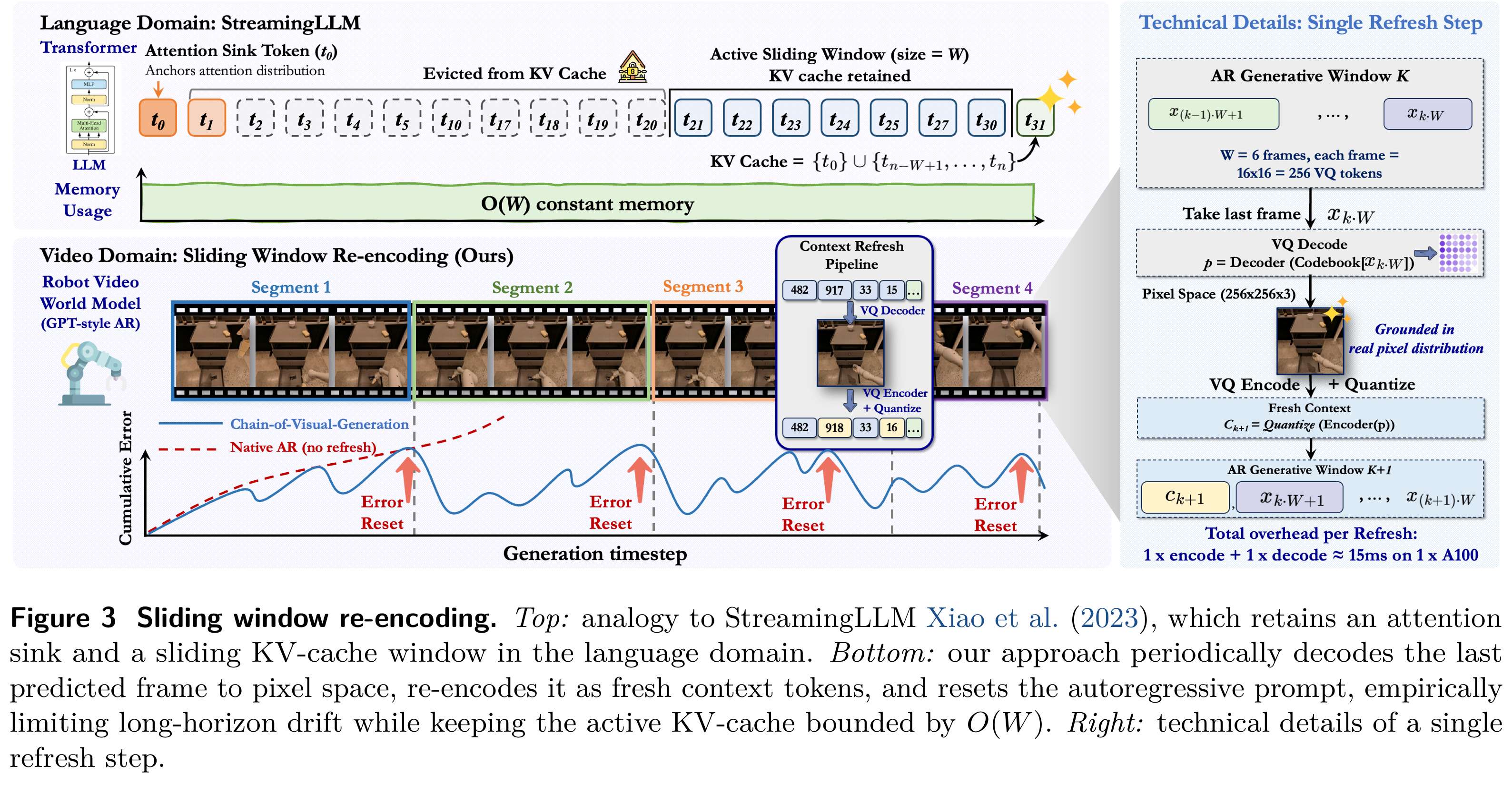
其核心思想非常直观:定期截断历史误差,用最新生成的帧刷新上下文,让误差不再无限传递。具体执行流程如下:
将长视频按固定窗口大小 W 划分为多个片段;
在每个窗口内进行正常自回归生成;
窗口结束时,将最后一帧解码为像素,重新编码为新的上下文 token;
以新上下文为起点继续下一段生成,重复直至完成。
上下文刷新的过程可表示为:
x ^ k W = D v i s ( z k c t x , z ^ ( k − 1 ) W + 1 : k W d y n ) , z k + 1 c t x = T v i s ( x ^ k W ) \hat{x}{kW} = \mathcal{D}{vis}\left( z_k^{ctx}, \hat{z}{(k-1)W+1:kW}^{dyn} \right), \quad z{k+1}^{ctx} = \mathcal{T}{vis}\left( \hat{x}{kW} \right) x^kW=Dvis(zkctx,z^(k−1)W+1:kWdyn),zk+1ctx=Tvis(x^kW)
从理论上可以证明,SWR 将预测误差限制在窗口范围内,最大误差不再随总帧数 T 增长,而标准自回归生成的误差则随 T 线性增长。这从根本上抑制了长时序漂移。
在工程上,SWR 具有三大优势:无需训练、延迟增加低于 1%、显存占用显著降低。它让机器人世界模型在长序列预测中保持动作连贯、接触稳定、物理可信。
方法整体总结
RoboAlign-R1 实现了三大突破:
用蒸馏多模态奖励解决训练错位,让模型以任务与物理为优化目标;
用在线迭代蒸馏保证奖励精准,避免模型作弊与分布偏移;
用滑动窗口重编码解决长时序漂移,以极低开销实现稳定预测。
三者结合,构成了可落地、高性能、高效率的机器人世界模型训练与推理体系。
实验分析
本文实验设计全面、对比基线丰富,覆盖闭源视频模型、开源视频模型、机器人世界模型三类方法,并从六维任务评分、低层视觉指标、长时序稳定性、消融实验四个维度验证效果。
六维度综合评分
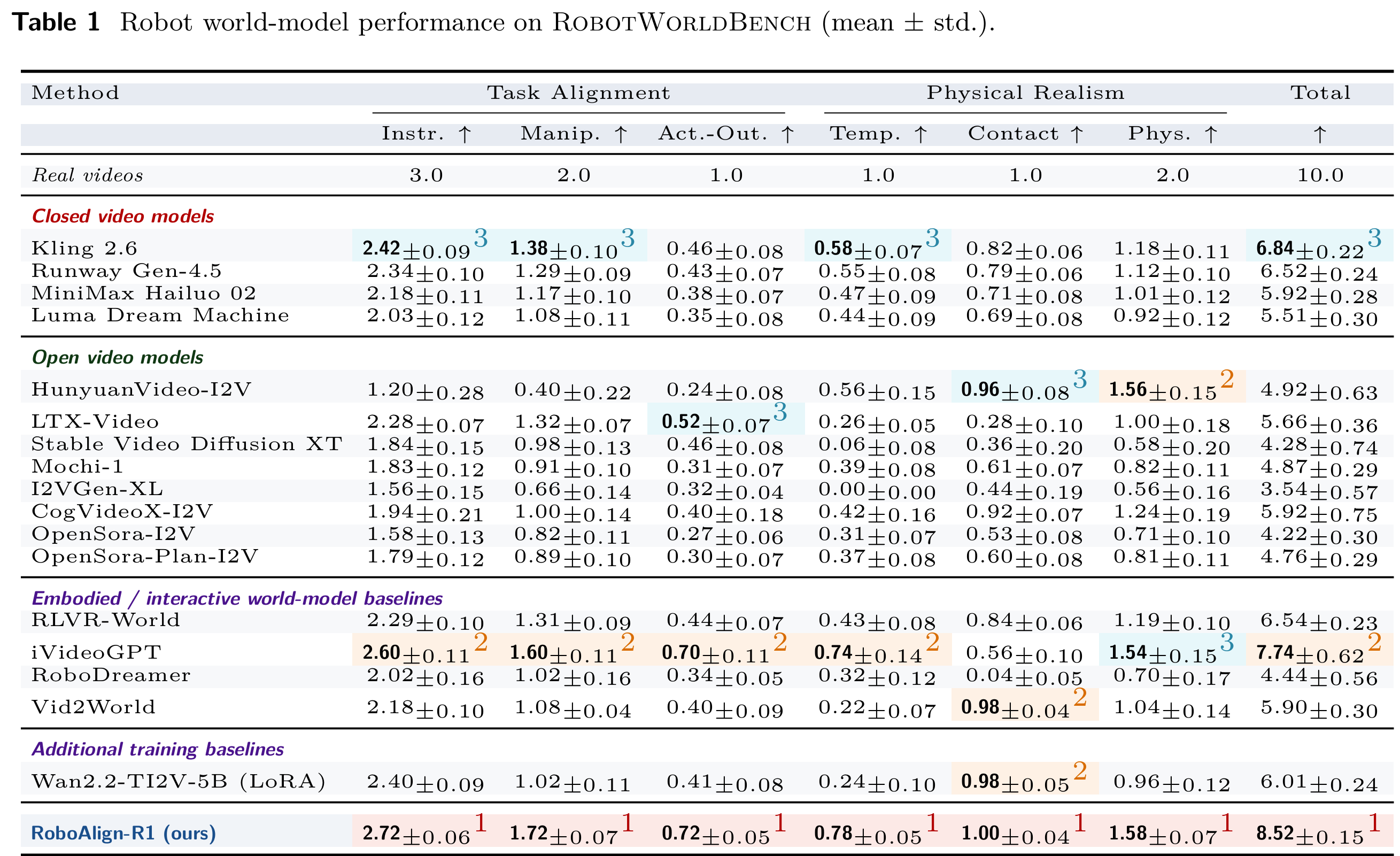
实验在 RobotWorldBench 上进行六维度细粒度打分,总分上限 10。结果显示:
- RoboAlign-R1 总分达到 8.52 ,显著超过最强基线 iVideoGPT 的 7.74,相对提升 10.1%;
- 在指令遵循上达到 2.72,相对提升 4.6%;
- 在操作准确率上达到 1.72,相对提升 7.5%;
- 时序一致性、接触真实性、物理合理性等维度也均为最优。
同时,RoboAlign-R1 明显优于 Kling 2.6、Runway Gen-4.5、MiniMax 等商业闭源视频生成模型,说明专用化对齐训练比通用生成模型更适合机器人场景。
这一结论也被外部 VLM 交叉验证 和盲态人工评估再次确认,排名完全一致,证明表 1 的分数可靠。
低层视觉指标
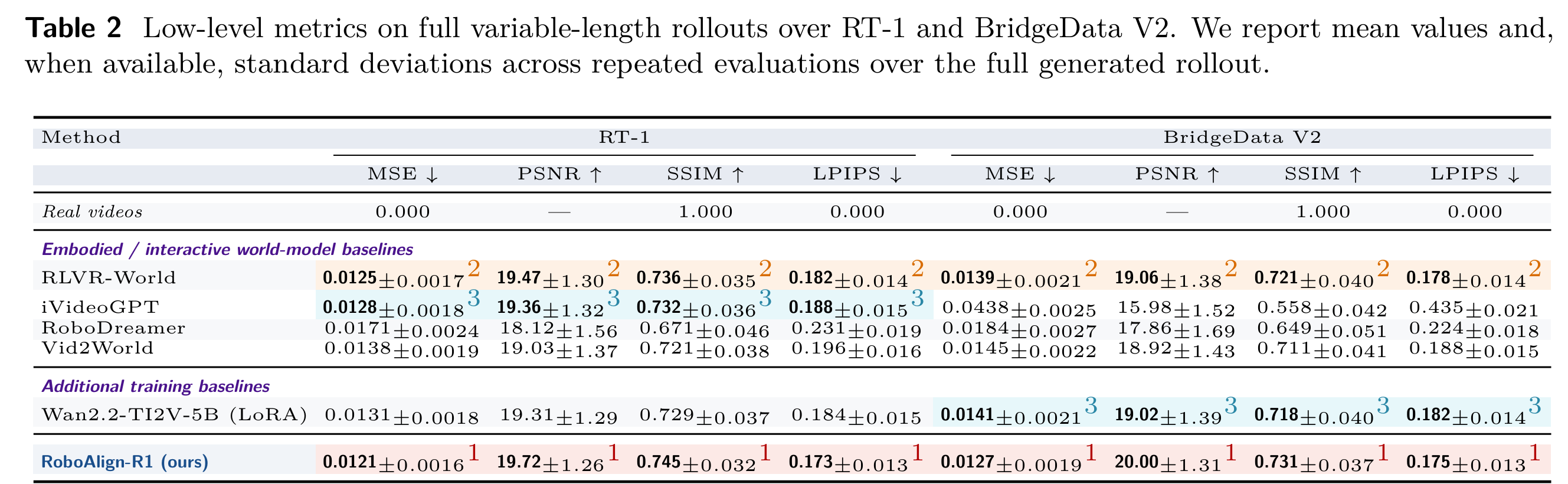
在传统像素级指标上,团队在 RT-1 和 BridgeData V2 两个数据集上进行测试。结果显示:
- RoboAlign-R1 在 MSE、PSNR、SSIM、LPIPS 全部四项指标上均取得最优;
- 在 RT-1 上 LPIPS 低至 0.173,BridgeData V2 上 MSE 低至 0.0127;
- 优于 iVideoGPT、RLVR-World、RoboDreamer 等所有具身世界模型基线。
这说明:对齐任务与物理规则,并不会牺牲画质,反而因为动作与接触更稳定,画面整体一致性更好。
长时序稳定性与 SWR 效果
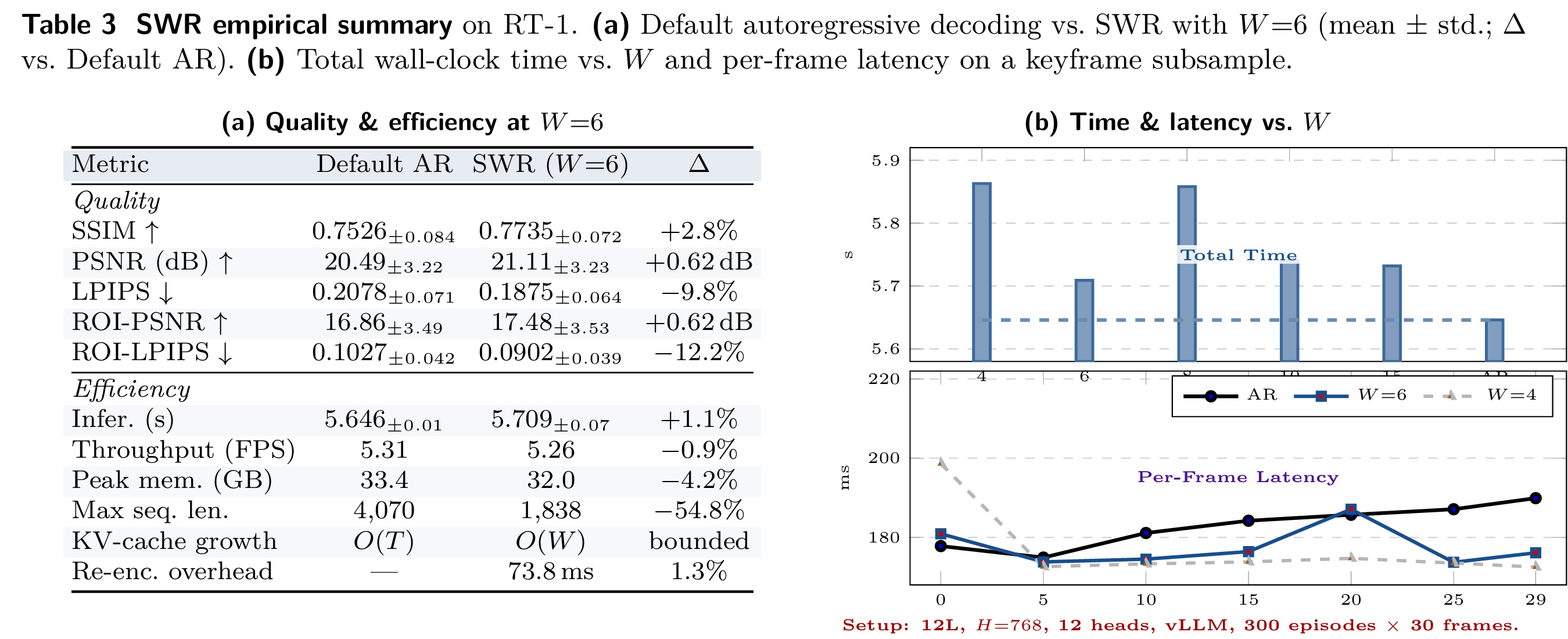
团队在 RT-1 上对比标准自回归生成与 SWR(窗口 = 6),结果清晰展示在表 3 (a) 和表 3 (b):
- 使用 SWR 后,SSIM 提升 2.8%,LPIPS 下降 9.8%;
- 感兴趣区域 ROI-LPIPS 下降 12.2%,操控区域质量提升更明显;
- 总推理时间从 5.646s 变为 5.709s,仅增加 1.1%;
- 峰值内存下降 4.2%,最大序列长度下降 54.8%,显存更友好。
图 7 进一步给出定性对比:SWR 明显缓解了长时序画面抖动、物体漂移、姿态错乱等问题,动作流程更连贯、物理更可信。
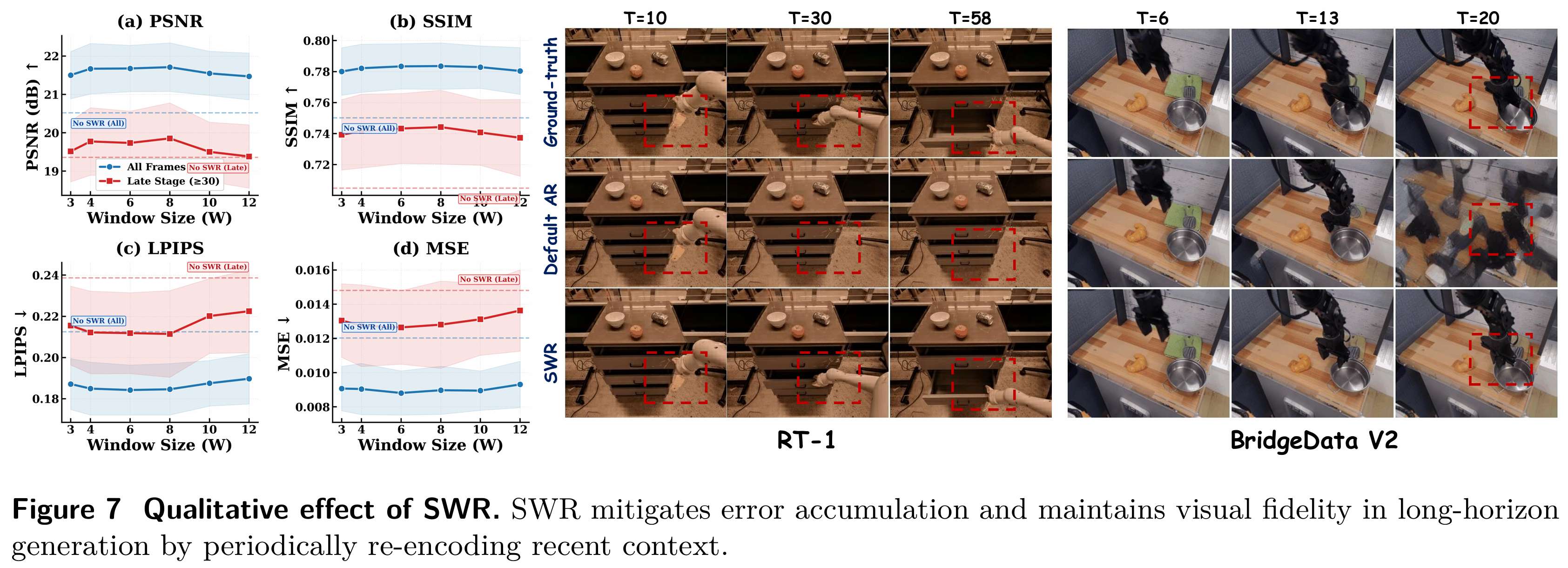
实验充分说明:SWR 是性价比极高的长时序优化策略,可以直接落地使用。
关键消融实验
奖励类型对比
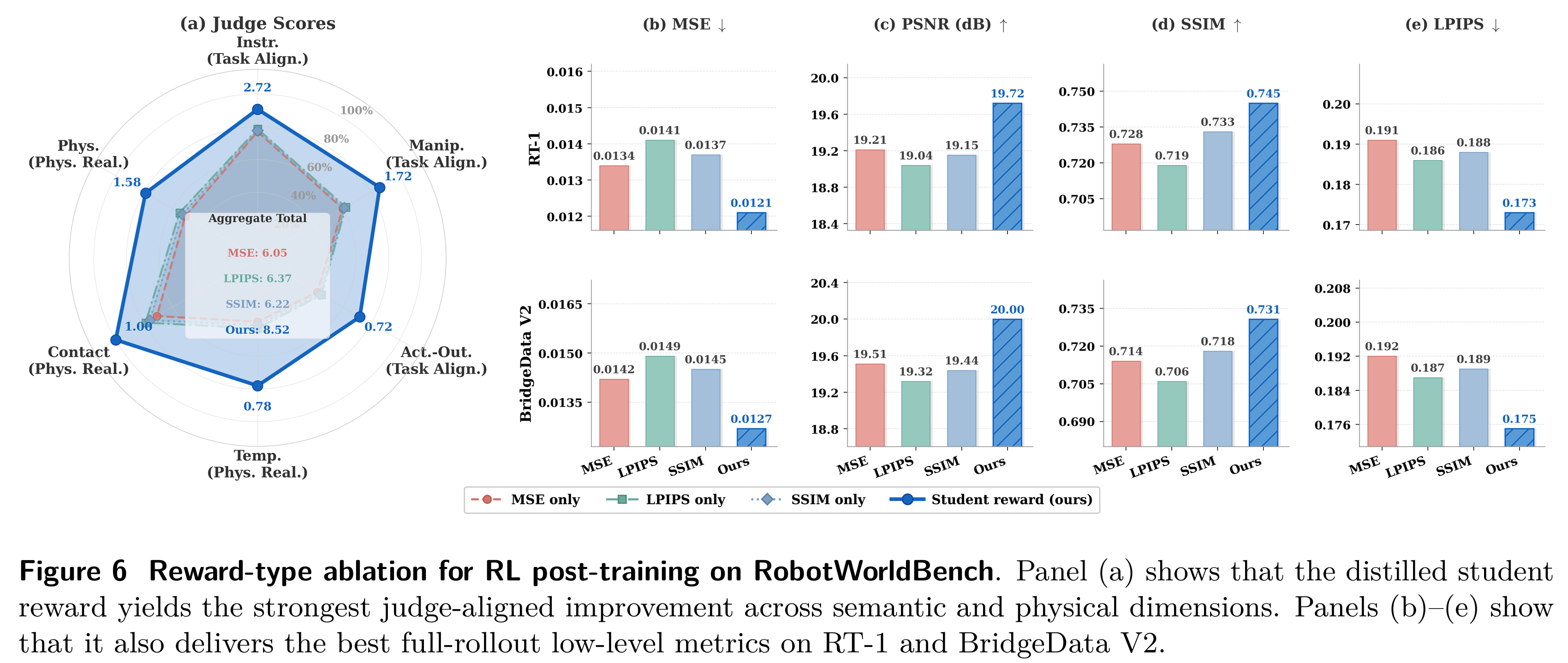
团队对比蒸馏奖励、LPIPS、MSE、SSIM 等单一奖励。结果显示:蒸馏多模态奖励大幅领先所有低层指标,综合得分相对提升 33.8%,证明高层任务与物理奖励不可替代。
在线迭代蒸馏
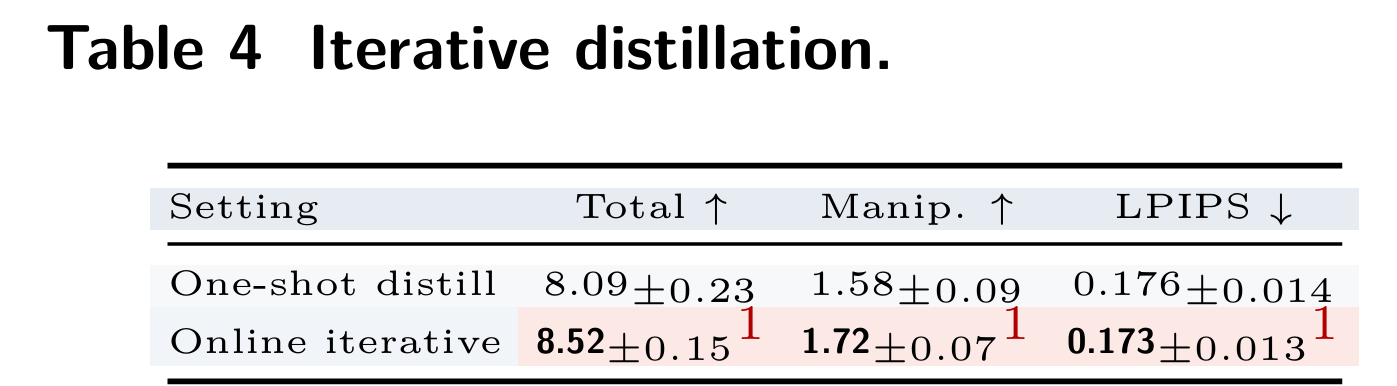
开启在线迭代蒸馏后,总分从 8.09 提升到 8.52,操作成功率从 1.58 提升到 1.72,同时 LPIPS 进一步下降,说明该机制有效抑制奖励漂移与模型作弊。
窗口大小消融
窗口 W=4、6、8、10、15 对比如图3所示,W=6 在效果与速度之间取得最佳平衡,是最优默认配置。
定性可视化结果
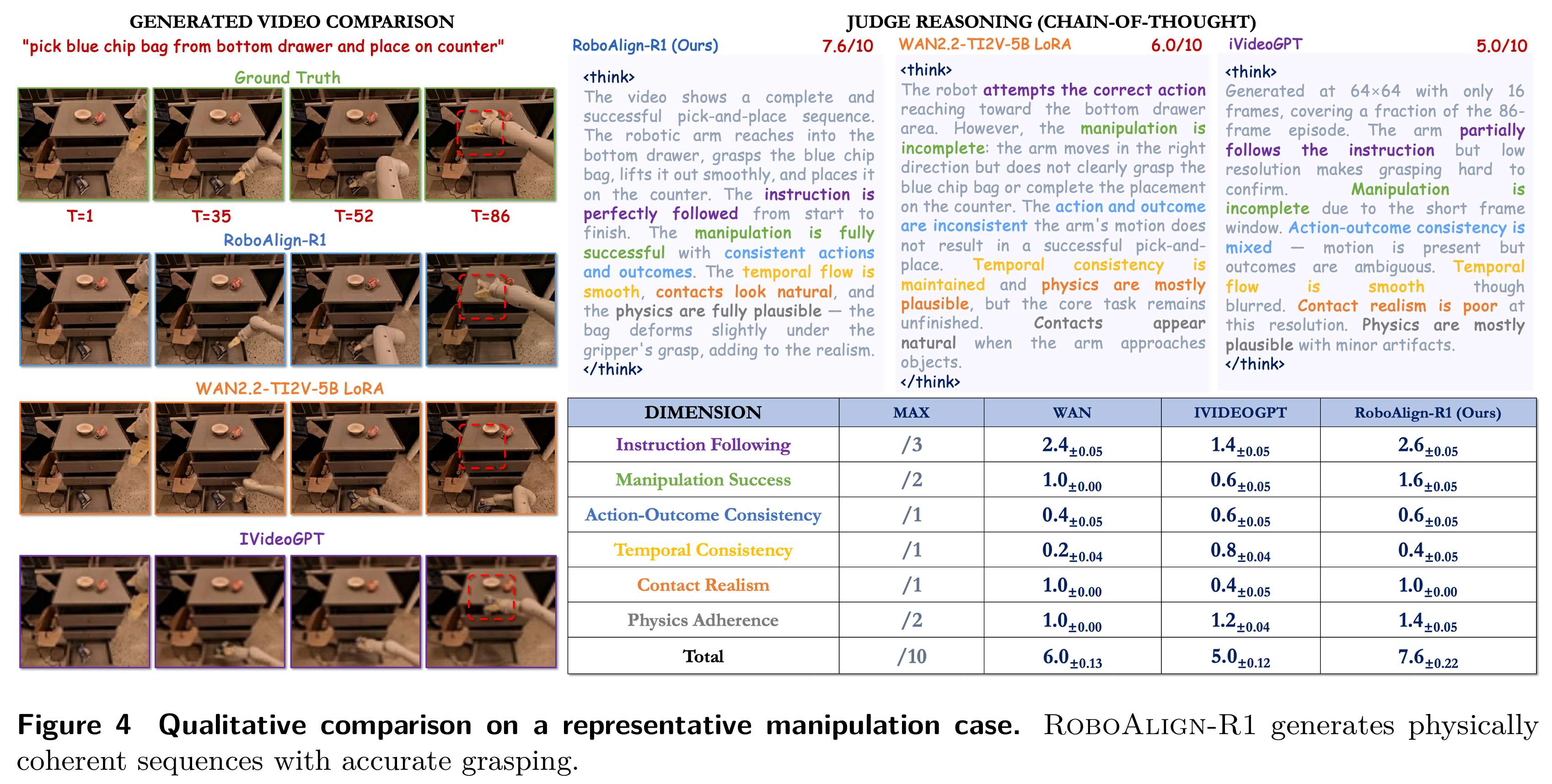

从图 4 和图 5 的样例可以直观看到:
- 基线模型常常出现模糊、纹理闪烁、物体形变、接触不稳定;
- RoboAlign-R1 生成的视频抓取准确、接触自然、纹理清晰、背景稳定;
- 在 "从抽屉取物""移动物体" 等典型任务中,动作流程更符合人类预期与物理规则。
总结与展望
总结
RoboAlign-R1 面向机器人视频世界模型,提出了一套训练对齐 + 推理稳定的完整方案,解决了当前领域最核心的痛点:
提出蒸馏多模态奖励对齐框架,让世界模型从 "像素拟合" 升级为 "任务与物理对齐",综合性能提升 10.1%;
构建 RobotWorldBench 基准与高效奖励蒸馏流程,为机器人世界模型提供标准化数据与评测方案;
提出 滑动窗口重编码 SWR,以极低开销解决长时序漂移,让模型真正具备长时序预测能力。
整体来看,RoboAlign-R1 让机器人世界模型第一次同时实现:画质好、指令准、操作稳、物理真、长时序不崩,是从 "生成式视觉模型" 迈向 "决策式世界模型" 的关键一步。
展望
未来工作可以沿着以下方向推进:
拓展更多机器人形态与场景,从单臂桌面操作扩展到移动操作、双臂协作、灵巧手、户外环境;
验证下游控制与规划收益,将优化后的世界模型真正用于策略学习、物理规划、闭环控制;
更强的物理与几何对齐,结合物理引擎、几何约束、多模型集成评判,进一步提升真实性;
更高效的端到端学习,将奖励模型与世界模型联合优化,简化训练流程;
更强泛化能力,面向新物体、新环境、新任务实现零样本/小样本泛化,向通用机器人世界模型迈进。
长期来看,RoboAlign-R1 所代表的 "对齐训练 + 稳定生成" 范式,不仅适用于机器人,还可推广到自动驾驶、数字孪生、工业仿真等需要精准物理预测的领域,成为下一代物理 AI 的重要基础。
重磅!
全网首个!具身智能开源知识库来啦(技术/产业/投融资/上下游)
推荐阅读
VLA+RL方向首个系统教程来啦!Online RL/Offline RL/test time RL等~
我们用低成本的机械臂完成pi0/pi0.5/GR00T/世界模型等VLA任务~
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~