1.1 具身智能 (Embodied AI)
具身智能的定义、发展历程、核心理念与研究意义
目录
- [1.1.1 定义与发展历程](#1.1.1 定义与发展历程)
- [1.1.2 核心理念](#1.1.2 核心理念)
- [1.1.3 研究意义与应用价值](#1.1.3 研究意义与应用价值)
1.1.1 定义与发展历程
具身智能的概念起源
什么是具身智能?
具身智能 (Embodied Artificial Intelligence, Embodied AI) 是指通过物理身体(机器人)与环境进行交互,从而获得智能行为的人工智能系统。与传统的"离身智能"(Disembodied AI) 不同,具身智能强调智能来源于身体与环境的交互。
核心定义:具身智能是一种能够通过传感器感知环境、通过执行器作用于环境、并在与环境的持续交互中学习和适应的智能系统。
概念的学术起源
具身智能的概念可以追溯到多个学科交叉:
| 学科领域 | 代表人物/理论 | 核心贡献 |
|---|---|---|
| 认知科学 | Rodney Brooks (1986) | "智慧需要身体" - 行为主义机器人学 |
| 哲学 | Maurice Merleau-Ponty | 具身现象学 |
| 心理学 | James Gibson | 生态光学理论、可供性(Affordance) |
| 神经科学 | Antonio Damasio | 躯体标记假说 |
Rodney Brooks 在其经典论文 "Elephants Don't Play Chess" (1990) 中提出:
"The key to intelligence is not in abstract reasoning, but in the ability to interact with the world through a body."
(智能的关键不在于抽象推理,而在于通过身体与世界交互的能力。)
发展时间线
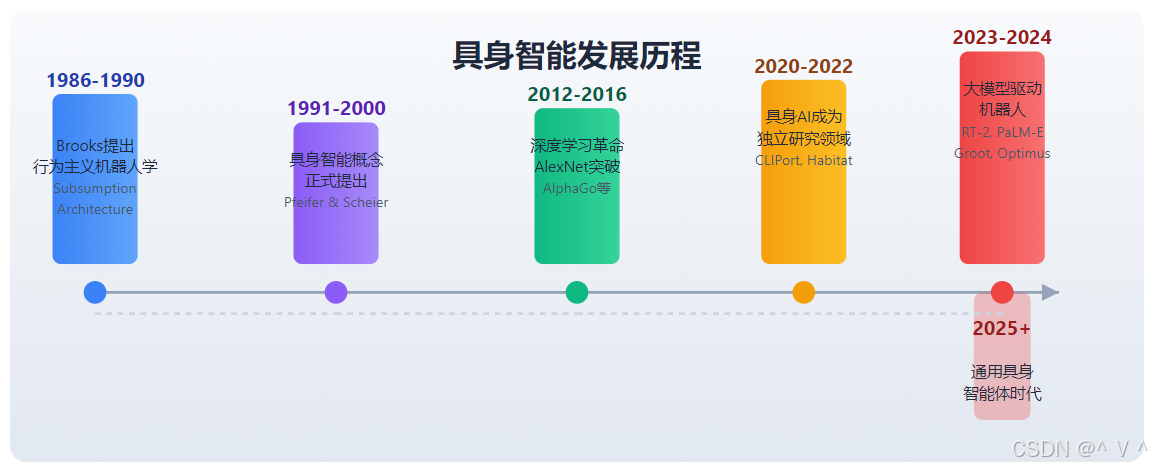
相关论文推荐
- Brooks, R. A. (1991) . "Intelligence Without Representation" - MIT AI Lab
- Pfeifer, R., & Scheier, C. (1999). "Understanding Intelligence" - MIT Press
- Duan, J., et al. (2024) . "A Survey on Embodied AI" - arXiv
从符号AI到具身AI的范式转变
AI发展范式的演进
人工智能的发展经历了多次范式转变:
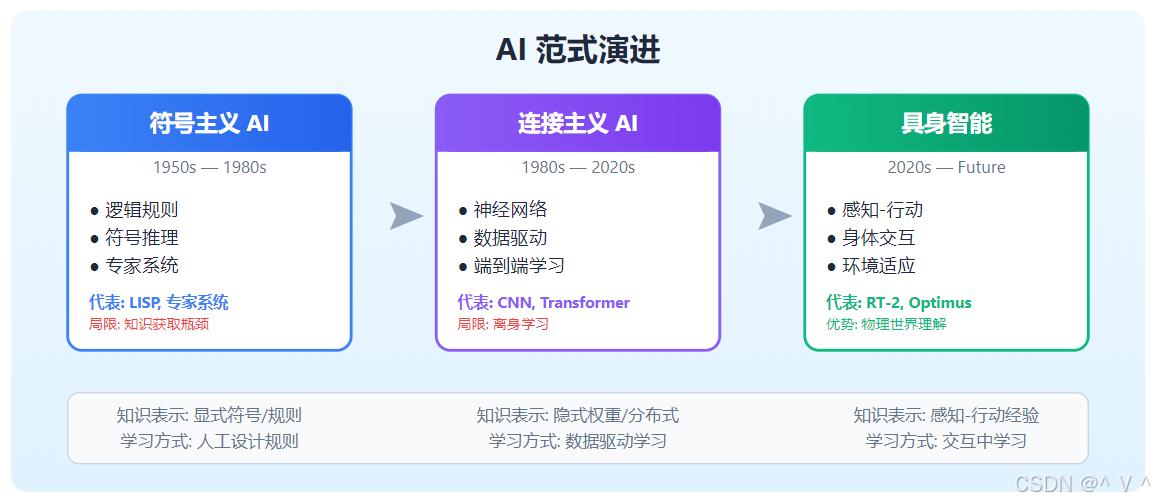
范式对比详解
| 维度 | 符号主义 AI | 连接主义 AI | 具身智能 |
|---|---|---|---|
| 知识表示 | 显式符号、规则 | 隐式权重、分布式表示 | 感知-行动经验 |
| 学习方式 | 人工设计规则 | 数据驱动学习 | 交互中学习 |
| 智能来源 | 逻辑推理 | 模式识别 | 身体-环境交互 |
| 与环境关系 | 隔离、抽象 | 数据接口 | 物理嵌入、实时交互 |
| 典型系统 | 专家系统、定理证明器 | 图像分类、语言模型 | 机器人、自动驾驶 |
| 局限性 | 脆弱、难以扩展 | 缺乏常识、无物理理解 | 数据稀缺、硬件限制 |
范式转变的动因
1. Moravec悖论的启示
Hans Moravec 在1988年提出著名的悖论:
"计算机在执行高级推理任务时表现出色,但在执行低级感知运动任务时却很困难。"
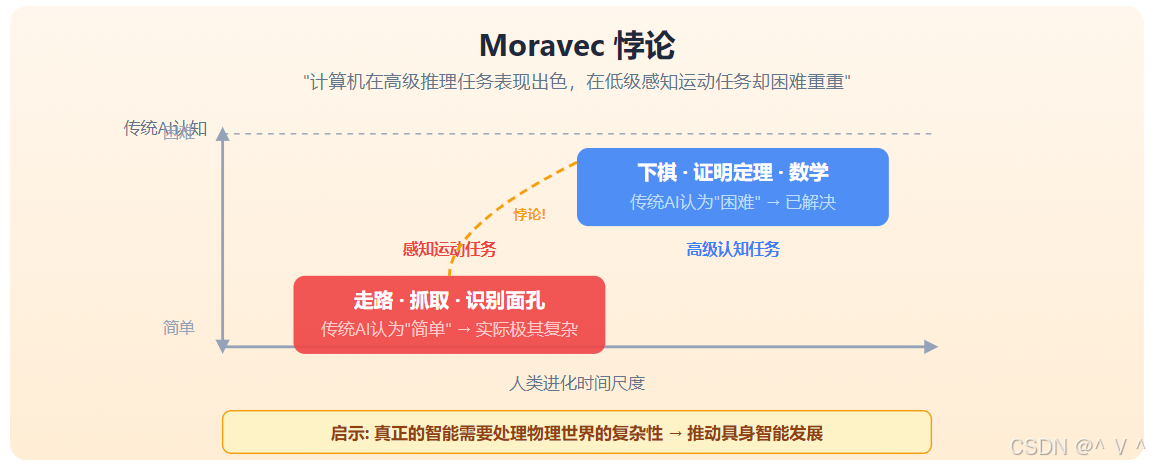
启示:真正的智能需要处理物理世界的复杂性,这推动了具身智能的发展。
2. 大模型的能力瓶颈
GPT-4等大语言模型展现出强大的语言理解和推理能力,但存在明显局限:
- ❌ 无法理解物理常识(如"杯子掉落会碎")
- ❌ 无法在物理世界中执行任务
- ❌ 缺乏空间推理和因果理解
解决方案:将大模型与物理身体结合,形成具身智能系统。
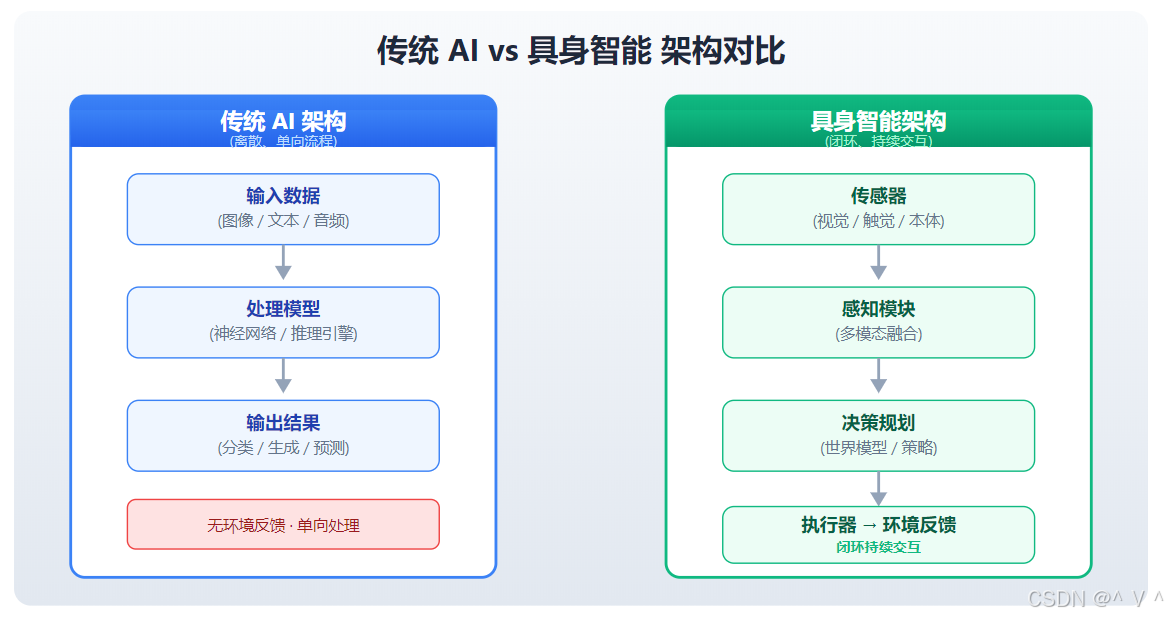
具身智能与传统AI的区别
核心差异对比
| 特性 | 传统AI (离身智能) | 具身智能 |
|---|---|---|
| 存在形式 | 纯软件系统,无物理身体 | 软硬件结合,具有物理身体 |
| 交互方式 | 数据输入输出 | 感知-行动循环 |
| 学习来源 | 静态数据集 | 环境交互经验 |
| 目标导向 | 任务特定优化 | 生存与适应 |
| 错误代价 | 可修正、低风险 | 物理损坏、安全风险 |
| 泛化能力 | 数据分布内泛化 | 跨环境、跨任务泛化 |
架构对比图
数学形式化
传统AI的学习目标 :
min θ E ( x , y ) ∼ D L ( f θ ( x ) , y ) \min_{\theta} \mathbb{E}_{(x,y) \sim \mathcal{D}} \left \\mathcal{L}(f_\\theta(x), y) \\right θminE(x,y)∼DL(fθ(x),y)
其中 D \mathcal{D} D 是静态数据集, f θ f_\theta fθ 是神经网络, L \mathcal{L} L 是损失函数。
具身智能的学习目标 :
max π E τ ∼ π ∑ t = 0 T γ t r ( s t , a t ) \max_{\pi} \mathbb{E}_{\tau \sim \pi} \left \\sum_{t=0}\^{T} \\gamma\^t r(s_t, a_t) \\right πmaxEτ∼πt=0∑Tγtr(st,at)
其中 π \pi π 是策略, τ = ( s 0 , a 0 , s 1 , a 1 , ... ) \tau = (s_0, a_0, s_1, a_1, \ldots) τ=(s0,a0,s1,a1,...) 是轨迹, s t s_t st 是状态, a t a_t at 是动作, r r r 是奖励函数。
关键区别在于:具身智能需要在交互中学习,状态分布由策略本身决定,形成循环依赖。
代码示例:感知-行动循环
python
class EmbodiedAgent:
"""具身智能体的基本框架"""
def __init__(self, sensors, actuators, policy_network):
self.sensors = sensors # 传感器 (相机、触觉等)
self.actuators = actuators # 执行器 (机械臂、轮子等)
self.policy = policy_network # 策略网络
self.memory = [] # 经验记忆
def perceive(self):
"""感知环境状态"""
observations = {}
for name, sensor in self.sensors.items():
observations[name] = sensor.read()
return observations
def decide(self, observations):
"""决策:基于观测选择动作"""
# 结合记忆进行决策
state = self._fuse_observations(observations)
action = self.policy(state)
return action
def act(self, action):
"""执行动作"""
for name, actuator in self.actuators.items():
actuator.execute(action[name])
def learn(self, experience):
"""从交互中学习"""
self.memory.append(experience)
# 强化学习更新
self.policy.update(experience)
def step(self):
"""感知-决策-行动 循环"""
# 1. 感知
obs = self.perceive()
# 2. 决策
action = self.decide(obs)
# 3. 行动
self.act(action)
# 4. 获取反馈并学习
reward, next_obs, done = self.get_feedback()
self.learn((obs, action, reward, next_obs, done))
return done1.1.2 核心理念
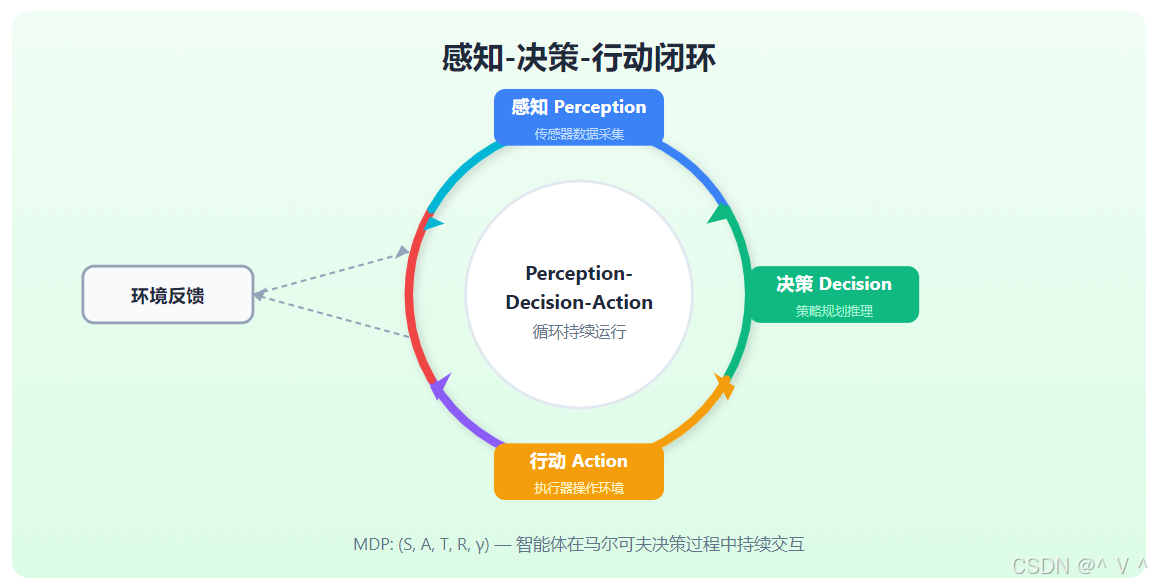
感知-决策-行动闭环
核心概念
感知-决策-行动闭环 (Perception-Decision-Action Loop) 是具身智能的基本运行模式,描述了智能体与环境持续交互的循环过程。
数学描述
感知-决策-行动闭环可以用马尔可夫决策过程 (MDP) 形式化:
MDP = ( S , A , T , R , γ ) \text{MDP} = (\mathcal{S}, \mathcal{A}, \mathcal{T}, \mathcal{R}, \gamma) MDP=(S,A,T,R,γ)
其中:
- S \mathcal{S} S:状态空间 (环境所有可能状态)
- A \mathcal{A} A:动作空间 (智能体可执行动作)
- T : S × A → S \mathcal{T}: \mathcal{S} \times \mathcal{A} \rightarrow \mathcal{S} T:S×A→S:状态转移函数
- R : S × A → R \mathcal{R}: \mathcal{S} \times \mathcal{A} \rightarrow \mathbb{R} R:S×A→R:奖励函数
- γ \gamma γ:折扣因子
闭环动力学:
s t + 1 ∼ P ( s t + 1 ∣ s t , a t ) s_{t+1} \sim P(s_{t+1} | s_t, a_t) st+1∼P(st+1∣st,at)
a t ∼ π ( a t ∣ s t ) a_t \sim \pi(a_t | s_t) at∼π(at∣st)
r t = R ( s t , a t ) r_t = R(s_t, a_t) rt=R(st,at)
各组件详解
1. 感知 (Perception)
感知模块负责将原始传感器数据转换为有意义的状态表示:
z t = f ϕ ( sensor_data t ) z_t = f_\phi(\text{sensor\_data}_t) zt=fϕ(sensor_datat)
常见的感知模态:
| 感知模态 | 传感器 | 处理方法 | 输出表示 |
|---|---|---|---|
| 视觉 | RGB相机、深度相机 | CNN、ViT、SAM | 图像特征、深度图 |
| 触觉 | 力传感器、触觉阵列 | MLP、GNN | 接触力、物体属性 |
| 听觉 | 麦克风阵列 | 音频编码器 | 声源定位、语音 |
| 本体感知 | IMU、编码器 | 状态估计器 | 姿态、速度 |
代码示例:多模态感知融合
python
import torch
import torch.nn as nn
class MultimodalPerception(nn.Module):
"""多模态感知融合模块"""
def __init__(self,
visual_dim=512,
tactile_dim=128,
proprioceptive_dim=64,
fusion_dim=256):
super().__init__()
# 视觉编码器 (基于预训练的视觉模型)
self.visual_encoder = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(128, visual_dim)
)
# 触觉编码器
self.tactile_encoder = nn.Sequential(
nn.Linear(100, 64), # 假设触觉传感器有100个通道
nn.ReLU(),
nn.Linear(64, tactile_dim)
)
# 本体感知编码器 (关节角度、速度等)
self.proprioceptive_encoder = nn.Sequential(
nn.Linear(20, 32), # 假设有20个关节状态
nn.ReLU(),
nn.Linear(32, proprioceptive_dim)
)
# 多模态融合
self.fusion = nn.Sequential(
nn.Linear(visual_dim + tactile_dim + proprioceptive_dim, 256),
nn.ReLU(),
nn.Linear(256, fusion_dim)
)
def forward(self, visual_input, tactile_input, proprioceptive_input):
"""融合多模态感知"""
# 编码各模态
v_features = self.visual_encoder(visual_input)
t_features = self.tactile_encoder(tactile_input)
p_features = self.proprioceptive_encoder(proprioceptive_input)
# 拼接并融合
combined = torch.cat([v_features, t_features, p_features], dim=-1)
fused_state = self.fusion(combined)
return fused_state2. 决策 (Decision)
决策模块基于当前状态选择最优动作:
a t ∗ = arg max a Q ( s t , a ) a_t^* = \arg\max_a Q(s_t, a) at∗=argamaxQ(st,a)
决策方法分类:

3. 行动 (Action)
行动模块将决策转换为物理世界的具体操作:
τ ( t ) = g ( a t , robot_state ) \tau(t) = g(a_t, \text{robot\_state}) τ(t)=g(at,robot_state)
行动类型:
| 行动类型 | 描述 | 示例 |
|---|---|---|
| 离散动作 | 预定义的有限动作集合 | 移动方向(上/下/左/右) |
| 连续动作 | 连续值动作空间 | 关节角度、速度 |
| 参数化动作 | 动作类型+参数 | 抓取(位置, 姿态, 力度) |
| 层次化动作 | 高层任务→低层执行 | "打开门"→导航→抓取→转动 |
具身认知理论
理论基础
具身认知 (Embodied Cognition) 是认知科学的核心理论,认为认知不仅发生在大脑中,而是身体、环境和大脑三者共同作用的结果。
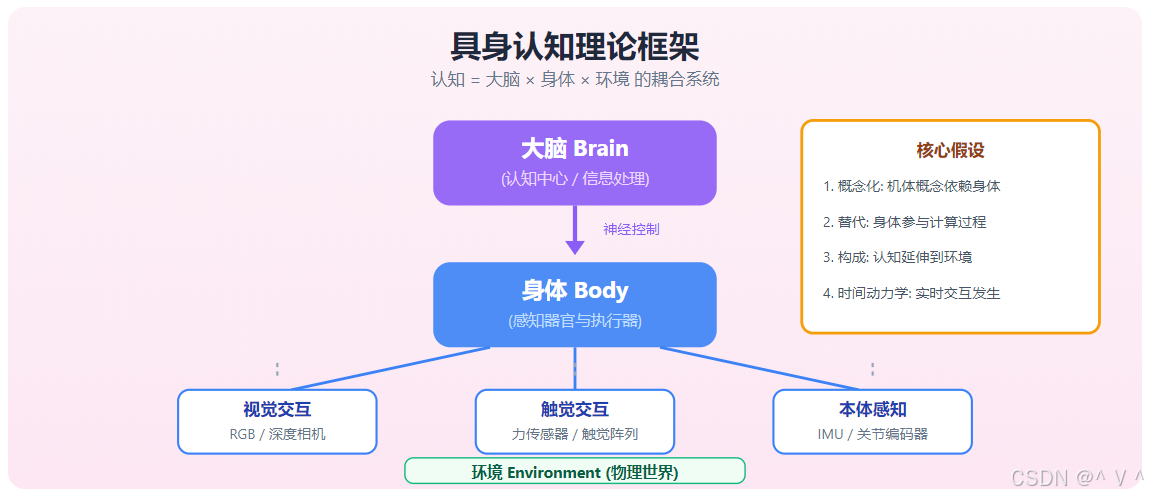
具身认知的四个核心假设
| 假设 | 内容 | 具身智能启示 |
|---|---|---|
| 概念化假设 | 机体概念依赖身体结构 | 机器人的形态影响其认知 |
| 替代假设 | 认知过程中身体参与计算 | 传感器-执行器耦合设计 |
| 构成假设 | 认知延伸到环境 | 利用环境作为计算资源 |
| 时间动力学假设 | 认知在实时交互中发生 | 在线学习能力 |
可供性理论
可供性 (Affordance) 由心理学家 James Gibson 提出,是具身认知的核心概念:
定义:可供性是环境相对于智能体的行为可能性,它既取决于环境的物理属性,也取决于智能体的能力。
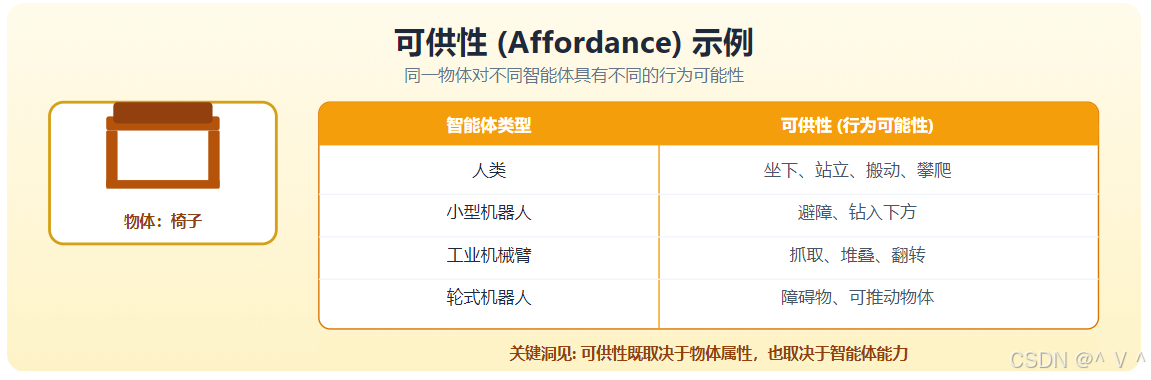
可供性的数学描述:
Affordance ( o , a ) = { ( b i , c i ) ∣ agent a can perform b i on object o with condition c i } \text{Affordance}(o, a) = \{(b_i, c_i) | \text{agent } a \text{ can perform } b_i \text{ on object } o \text{ with condition } c_i\} Affordance(o,a)={(bi,ci)∣agent a can perform bi on object o with condition ci}
代码示例:可供性检测网络
python
class AffordanceDetector(nn.Module):
"""可供性检测网络:预测物体相对于机器人的行为可能性"""
def __init__(self, object_encoder, robot_encoder, num_affordances=10):
super().__init__()
self.object_encoder = object_encoder # 物体特征编码器
self.robot_encoder = robot_encoder # 机器人能力编码器
# 可供性预测头
self.affordance_head = nn.Sequential(
nn.Linear(object_encoder.dim + robot_encoder.dim, 256),
nn.ReLU(),
nn.Linear(256, num_affordances),
nn.Sigmoid() # 二分类:是否具有该可供性
)
# 可供性条件预测(执行条件)
self.condition_head = nn.Sequential(
nn.Linear(object_encoder.dim + robot_encoder.dim, 256),
nn.ReLU(),
nn.Linear(256, num_affordances * 4) # 4个条件参数
)
def forward(self, object_obs, robot_state):
"""
Args:
object_obs: 物体观测 (点云、图像等)
robot_state: 机器人状态 (能力、姿态等)
Returns:
affordances: 可供性概率
conditions: 执行条件参数
"""
obj_features = self.object_encoder(object_obs)
robot_features = self.robot_encoder(robot_state)
combined = torch.cat([obj_features, robot_features], dim=-1)
affordances = self.affordance_head(combined)
conditions = self.condition_head(combined)
return affordances, conditions
def get_available_actions(self, object_obs, robot_state, threshold=0.5):
"""获取可执行的动作列表"""
affordances, conditions = self.forward(object_obs, robot_state)
available = (affordances > threshold).nonzero()
return [(a.item(), conditions[a.item()]) for a in available]身体-环境交互的重要性
为什么身体-环境交互至关重要?
1. 智能的涌现
智能不是预先编程的,而是在与环境的交互中涌现 出来的。这被称为涌现智能 (Emergent Intelligence)。
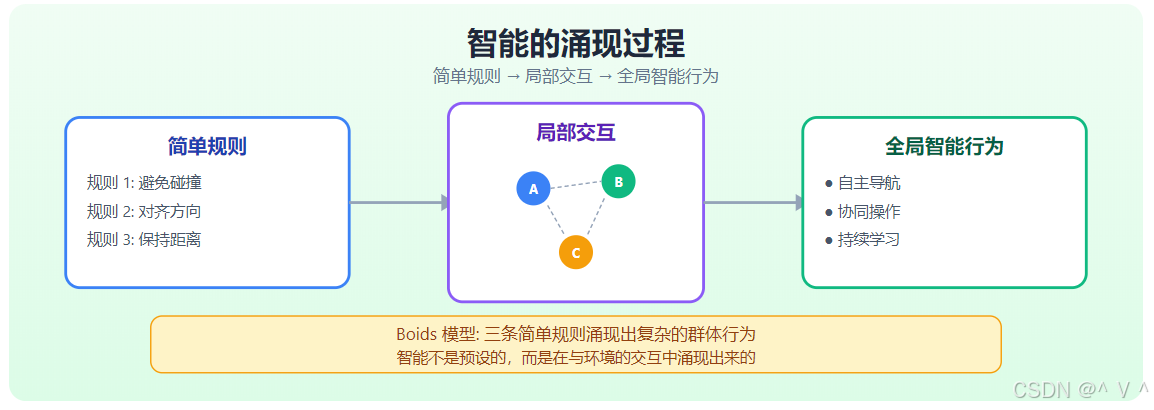
2. 学习效率
通过与环境的交互,智能体可以获得即时反馈,比从静态数据集中学习更高效:
交互学习效率 ∝ 信息增益 交互成本 \text{交互学习效率} \propto \frac{\text{信息增益}}{\text{交互成本}} 交互学习效率∝交互成本信息增益
主动学习示例:智能体可以主动探索不确定的区域,获得更多信息。
3. 泛化能力
身体-环境交互提供了多模态、多任务的学习机会:
泛化能力 = f ( 交互多样性 , 任务相关性 , 适应速度 ) \text{泛化能力} = f(\text{交互多样性}, \text{任务相关性}, \text{适应速度}) 泛化能力=f(交互多样性,任务相关性,适应速度)
Sim-to-Real:交互学习的挑战与解决方案
由于真实世界交互成本高、风险大,通常需要在仿真环境中训练,然后迁移到真实世界。

代码示例:域随机化
python
import numpy as np
from dataclasses import dataclass
@dataclass
class DomainRandomizationConfig:
"""域随机化配置:在仿真中随机化各种参数以增强泛化能力"""
# 物理参数随机化
mass_range: tuple = (0.8, 1.2) # 物体质量随机范围
friction_range: tuple = (0.5, 1.5) # 摩擦系数随机范围
# 视觉参数随机化
lighting_range: tuple = (0.3, 1.0) # 光照强度
color_jitter: float = 0.1 # 颜色抖动
texture_randomize: bool = True # 纹理随机化
# 动力学参数随机化
action_noise: float = 0.05 # 动作噪声
observation_noise: float = 0.02 # 观测噪声
class DomainRandomizer:
"""域随机化器:在仿真训练时随机化环境参数"""
def __init__(self, config: DomainRandomizationConfig):
self.config = config
def randomize_physics(self, object_props):
"""随机化物理参数"""
randomized = object_props.copy()
# 随机化质量
randomized['mass'] *= np.random.uniform(*self.config.mass_range)
# 随机化摩擦系数
randomized['friction'] *= np.random.uniform(*self.config.friction_range)
return randomized
def randomize_visuals(self, image):
"""随机化视觉参数"""
# 光照变化
lighting = np.random.uniform(*self.config.lighting_range)
image = image * lighting
# 颜色抖动
if self.config.color_jitter > 0:
noise = np.random.randn(*image.shape) * self.config.color_jitter
image = np.clip(image + noise, 0, 1)
return image
def add_noise_to_action(self, action):
"""添加动作噪声"""
noise = np.random.randn(*action.shape) * self.config.action_noise
return action + noise
def add_noise_to_observation(self, observation):
"""添加观测噪声"""
noise = np.random.randn(*observation.shape) * self.config.observation_noise
return observation + noise1.1.3 研究意义与应用价值
通用人工智能的必经之路
为什么具身智能是AGI的关键?
1. 物理常识的获取
真正的通用智能必须理解物理世界的基本规律:
| 物理常识 | 描述 | 具身学习的优势 |
|---|---|---|
| 重力 | 物体会下落 | 通过交互自然学习 |
| 碰撞 | 物体碰撞会反弹 | 主动探索学习 |
| 材质 | 软硬、轻重、粗糙光滑 | 触觉反馈学习 |
| 因果关系 | 推动导致移动 | 干预实验学习 |
2. 世界模型的构建
具身智能通过交互构建世界模型,这是AGI的核心能力:
世界模型 : s t + 1 = f ( s t , a t ) \text{世界模型}: s_{t+1} = f(s_t, a_t) 世界模型:st+1=f(st,at)
图灵奖得主Yann LeCun的观点:
"AI系统需要学习世界模型,而最好的方式是通过与世界的交互。具身智能是实现AGI的关键路径。"
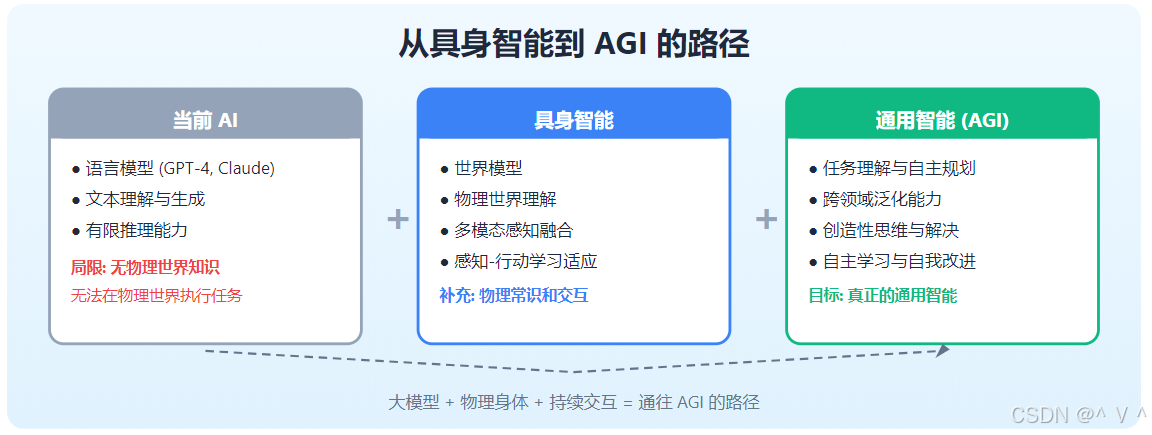
3. 持续学习与适应
具身智能体能够在终身交互中持续学习:
θ t + 1 = θ t + α ∇ θ L ( s t , a t , r t , s t + 1 ) \theta_{t+1} = \theta_t + \alpha \nabla_\theta \mathcal{L}(s_t, a_t, r_t, s_{t+1}) θt+1=θt+α∇θL(st,at,rt,st+1)
这与人类的学习模式一致:学习即生存。
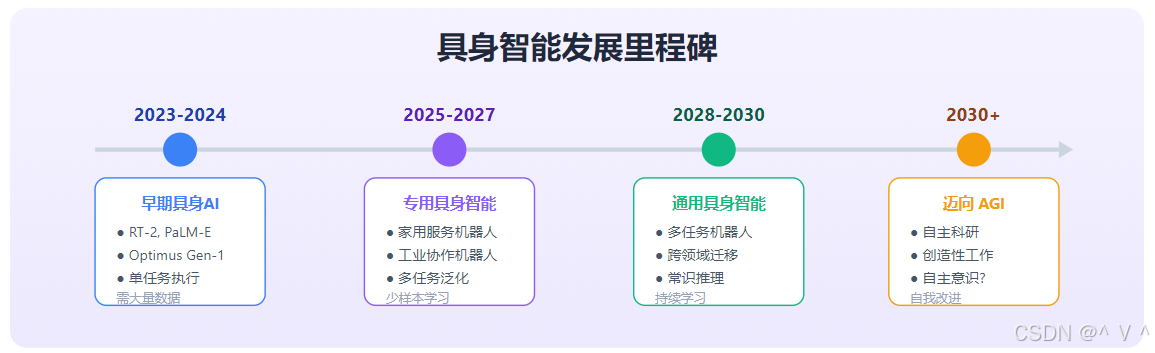
AGI时间线预测
工业自动化与机器人
应用场景
| 应用领域 | 具体场景 | 技术要求 | 代表产品 |
|---|---|---|---|
| 制造装配 | 零件装配、焊接、喷涂 | 高精度、高重复性 | ABB、KUKA机械臂 |
| 物流仓储 | 分拣、码垛、搬运 | 动态环境适应 | Amazon机器人 |
| 质量检测 | 缺陷检测、尺寸测量 | 视觉识别 | 工业视觉系统 |
| 柔性制造 | 多品种小批量生产 | 快速切换任务 | 自适应生产线 |
具身智能带来的变革

代码示例:工业机器人任务规划
python
class IndustrialRobotPlanner:
"""工业机器人任务规划器"""
def __init__(self, robot_arm, vision_system):
self.robot = robot_arm
self.vision = vision_system
self.world_model = WorldModel()
def plan_assembly_task(self, task_specification):
"""规划装配任务"""
# 1. 感知当前场景
scene = self.vision.get_scene_point_cloud()
objects = self.vision.detect_objects(scene)
# 2. 理解任务目标
goal_state = self.parse_task_goal(task_specification)
# 3. 使用世界模型进行规划
plan = self.world_model.plan(
initial_state=objects,
goal_state=goal_state,
constraints=self.robot.get_constraints()
)
# 4. 生成轨迹
trajectories = []
for step in plan:
traj = self.robot.generate_trajectory(
start=step['start'],
goal=step['goal'],
obstacles=scene
)
trajectories.append(traj)
return trajectories
def execute_with_adaptation(self, trajectories):
"""带自适应的执行"""
for traj in trajectories:
for waypoint in traj:
# 实时感知
current_state = self.vision.get_current_state()
# 检查是否需要调整
if self.need_adaptation(current_state, waypoint):
# 在线重新规划
new_traj = self.replan(current_state, waypoint)
traj = self.merge_trajectories(traj, new_traj)
# 执行
self.robot.move_to(waypoint)
# 获取反馈
feedback = self.robot.get_feedback()
self.world_model.update(feedback)智能助手与服务机器人
应用场景分类
1. 家庭服务机器人
| 功能 | 描述 | 技术挑战 |
|---|---|---|
| 家务清洁 | 扫地、拖地、整理 | 复杂环境导航、物体识别 |
| 烹饪助手 | 食材准备、烹饪操作 | 精细操作、食谱理解 |
| 老人护理 | 监护、辅助移动、提醒 | 安全交互、情感支持 |
| 儿童陪伴 | 教育、娱乐、监护 | 个性化交互、安全约束 |
2. 商业服务机器人
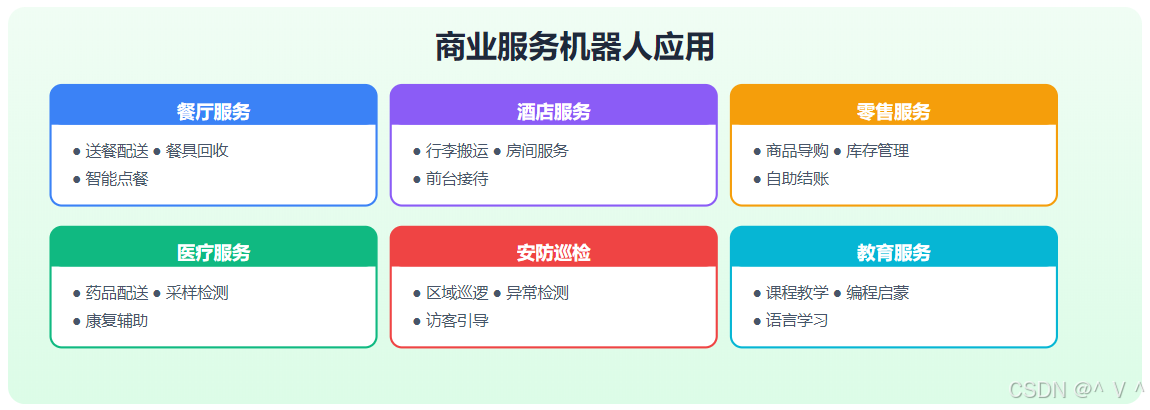
代表性产品
| 产品 | 公司 | 功能 | 特点 |
|---|---|---|---|
| Tesla Optimus | Tesla | 通用任务执行 | 大模型驱动、量产目标 |
| Figure 01 | Figure AI | 工业与家庭服务 | OpenAI合作、人形设计 |
| Digit | Agility Robotics | 物流搬运 | 双足行走、商业化部署 |
| Atlas | Boston Dynamics | 高动态运动 | 运动能力强、演示为主 |
| Pepper | SoftBank | 商业接待 | 情感交互、已停产 |
| CyberOne | 小米 | 智能家居控制 | 小米生态整合 |
人机交互设计
具身智能服务机器人需要良好的人机交互能力:
python
class ServiceRobotHCI:
"""服务机器人人机交互模块"""
def __init__(self):
self.speech_recognizer = SpeechRecognizer()
self.speech_synthesizer = SpeechSynthesizer()
self.gesture_recognizer = GestureRecognizer()
self.emotion_detector = EmotionDetector()
self.dialog_manager = DialogManager()
def interact(self):
"""主交互循环"""
while True:
# 多模态感知
speech = self.speech_recognizer.listen()
gesture = self.gesture_recognizer.detect()
emotion = self.emotion_detector.detect()
# 理解用户意图
intent = self.dialog_manager.understand(
speech=speech,
gesture=gesture,
emotion=emotion
)
# 生成响应
response = self.dialog_manager.generate_response(intent)
# 多模态输出
self.speech_synthesizer.speak(response.text)
self.display_expression(response.expression)
self.execute_gesture(response.gesture)
# 执行任务
if intent.needs_action:
self.execute_task(intent.action)参考论文与资源
必读论文
-
Brooks, R. A. (1991) . "Intelligence Without Representation" - MIT CSAIL
- 具身智能的理论奠基之作
-
Pfeifer, R., & Bongard, J. (2006). "How the Body Shapes the Way We Think" - MIT Press
- 具身认知的全面介绍
-
Duan, J., et al. (2024) . "A Survey on Embodied AI: Platforms, Datasets and Future Directions" - arXiv
- 具身智能最新综述
-
Brohan, A., et al. (2023) . "RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control" - arXiv
- 大模型驱动机器人的突破性工作
-
Driess, D., et al. (2023) . "PaLM-E: An Embodied Multimodal Language Model" - arXiv
- 多模态具身大模型